
smp
- 中断
在对称多处理(smp)下,传统的8259A中断控制器被升级成了APIC
(高级可编程中断控制器)。APIC分为本地APIC和全局APIC,通过专有的总线通讯。每个CPU配备一个本地APIC并且由自己的时钟中断,当外部有中断请求时,全局APIC可以决定发给某一个本地APIC或全部的本地APIC。 进程描述符创建在用户空间,真正在内核空间的是thread_info描述符(内有指针指向进程描述符)和进程对应的内核栈,他们紧挨着并正好占用一页。当内核栈不够时可以使用每个cpu专用的硬中断栈和软中断栈。系统调用和通常的异常统称为异常。中断可以抢占异常,异常不能抢占中断。和异常有关的内核控制路径最多只有两条,即先是系统调用,然后缺页异常。 - 调度
在smp系统中,pcb需要添加has_cpu和processor属性,分别表示是否在运行和在哪个cpu上运行,当某个cpu在schedule()中切换到next进程是,就将next进程的has_cpu和processor属性设置成相应值。在shcedule之前和之后都无条件打开本地cpu中断。 - 软中断、tasklet、工作队列
为了减少中断处理函数的响应时间,把那些可以推迟执行的工作交给软中断、tasklet、工作队列来执行。软中断需要用到三个关键数据结构:
thread_info描述符中的preempt_count字段用来记录当前cpu被抢占的状态

讯享网
抢占是指进程在内核状态被其它进程替换,比如A正在运行异常处理程序,这时中断发生,唤醒B进程并替换A进程。 硬中断和软中断处理程序都不能抢占。从异常处理程序返回时,会检查是否应该进行进程切换。tasklet是在软中断的基础上实现的,但是它维护了两个标志,TASKLET_STATE_SCHED表示当前tasklet已经被激活,TASKLET_STATE_RUN表示当前tasklet已经被某个cpu运行,准备运行tasklet的时候会检查TASKLET_STATE_RUN,防止不同cpu运行同一个tasklet。
工作队列由工作线程执行,可以支持抢占。每一个cpu有一个工作线程,对应cpu_workqueue_struct结构,内部的work_list记录了真正需要执行的函数以及数据。由于工作队列和软中断都是由内核线程执行的,所以都访问不到用户空间。
- 内核同步
缓存一致性协议(MESI)
数据加载的流程:1.将程序和数据从硬盘加载到内存中
2.将程序和数据从内存加载到缓存中(目前多三级缓存,数据加载顺序:L3->L2->L1)
3.CPU将缓存中的数据加载到寄存器中,并进行运算
4.CPU会将数据刷新回缓存,并在一定的时间周期之后刷新回内存
当变量的大小超过一个缓冲行时,只能用总线加锁的方式保持同步。
状态 描述 监听任务 M 修改(Modify) 该缓存行有效,数据被修改了,和内存中的数据不一致,数据只存在于本缓存行中 缓存行必须时刻监听所有试图读该缓存行相对应的内存的操作,其他缓存须在本缓存行写回内存并将状态置为E之后才能操作该缓存行对应的内存数据 E 独享、互斥(Exclusive) 该缓存行有效,数据和内存中的数据一致,数据只存在于本缓存行中 缓存行必须监听其他缓存读主内存中该缓存行相对应的内存的操作,一旦有这种操作,该缓存行需要变成S状态 S 共享(Shared) 该缓存行有效,数据和内存中的数据一致,数据同时存在于其他缓存中 缓存行必须监听其他缓存使该缓存行无效或者独享该缓存行的请求,并将该缓存行置为I状态 无效(Invalid) 该缓存行数据无效 当变量a在cpu1处于共享状态S时,cpu1对其进行修改,a在cpu1变为M状态,cpu2上处于共享态的变量a监听到这一修改后,状态变为Invalid。这时cpu2对a的任何修改都不会同步到主存。 而cpu1的a变量同步到主存后变为独享E状态。 cpu2通过总线嗅探机制得知变量a在主存上的值已被修改,会重新加载变量a,这时cpu1和cpu2上的a变量同时变为S状态。注意:当多个S状态都准备进入M状态时,由总线进行仲裁。M状态时,在未把变量更新到内存之前,不允许其他对该内存的操作。
store buffer 和 invalid queue的引入把原来的强一致性弱化为最终一致性。写屏障必须强制等待store buffer 中的写事务全部处理完再继续执行后面的指令。运行读屏障指令时,必须先将当前处于失效队列中的写无效事务全部处理完,再继续的执行读屏障后面的指令。写屏障使得更新的数据对所有核心可见,读屏障使得变量能获得最新值。
优化屏障是针对编译器的,它保证原语之前的指令不会跑到原语后面,后面的不会跑到前面。
原子操作是指多个读-修改-写类型的指令不会交错运行,操作码前缀是lock字节的“读-修改-写”指令在多处理器系统中也是原子的。linux内核提供了atomic_t类型的原子操作,并且他们都起内存屏障作用。
抢占式自旋锁: 第一步先禁止抢占,然后利用原子操作读取并设置锁的字段,设置失败则打开抢占,执行循环,之后跳转到第一步。
RCU(读-拷贝-更新): 允许多个读者和一个写者,写者先在数据的副本上更新,等到所有cpu经历过一次上下文切换后再真正更新数据。读者在读期间关闭上下文切换,读完再打开。
信号量必须借助自旋锁,里面有count字段,大于0表示空闲,等于0表示信号忙但是等待队列里并没有进程,小于0表示有进程等待,信号的实现保证count不会小于-1。信号量里的自旋锁只保护其数据结构,而completion完成量是类似于信号量,但是它内部的自旋锁直接用于禁止在同一完成量上并发执行。进程被信号量阻塞后进入TASK_UNINTERRUPTIBLE,其只能被wake_up()唤醒。
大内核锁由信号量实现,并且可以多次申请。获取大内核锁之后,进程可以主动进行调度,信号量自动释放,但是被抢占时信号量不释放。

内存 I/O
- 页框管理
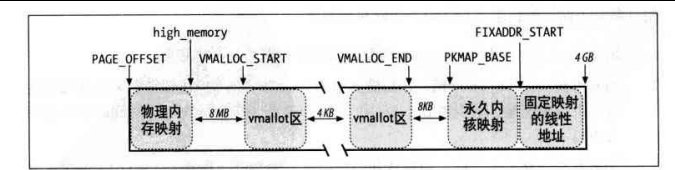
每一个物理页框都对应一个页描述符,记录在mem_map数组中。直接映射0-896mb的物理页框(低端内存)到内核空间(第4个GB), 第4个gb剩余的128mb用来映射高于896的物理页框(高端内存)。mem_map数组分配在低端内存,进程页表分配在高端内存寸中。每个cpu有自己的本地TLB,各个TLB之间不需要同步。页分配过程先分配页描述符,然后建立页框到线性地址(虚拟地址)的映射。
高端内存永久映射: 使用 pkmap_page_table加位图(计数器数组)来建立映射,映射建立后要更新页表项和清空TLB项,最多映射一个页表。
高端内存临时映射: 每个cpu可映射13个页表项。
伙伴系统: 按空闲连续物理内存的大小把它们连接成链表, 比如申请连续64个页框,在64的链表中找不到就在128的链表中找,找到后把128分为两半,一半用于分配,另一半加入64的链表。释放的时候和左右的空闲伙伴合并然后加入高一级的链表。每cpu页框高速缓存: 每个cpu的页框高速缓存中包含一些余弦分配的页框,用于每次对一个页框的请求和释放。 分为热高速缓存和冷告诉缓存,前者页框中的内容很可能在cpu的cache中。
alloc_page内部调用伙伴或每cpu页框高速缓存来分配连续页框。alloc_page可以通过标志位选择从不同的内存区分配页框,之后通过get_address进行映射。
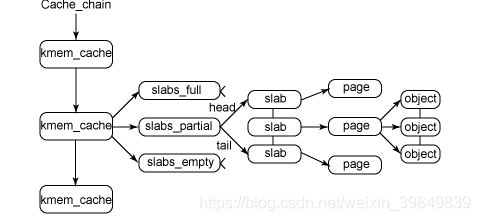
slab
一个slab对应一个或多个页框,并储存同一类型的对象。同一类型的slab被组织在一起,直接才从部分空闲和空slab中申请对象,删除对象时保留其在slab中的空间。每一个kmem_cache描述符用来管理同一类型的slab,kmem_cache(高速缓存描述符)本身也由slab来管理。着色是指随机更改slab中第一个对象的位置,使得对象会被存放在cache中的不同位置。slab机制也有一个本地高速缓存,类似于每cpu页框高速缓存。kmem_cache除了用来管理内核数据结构,还可以用于通用内存分配,26个高速缓存描述符,与其相关的内存区大小为32到字节。kmalloc(size_t size,int flags)就可以调用slab得到通用对象。
非连续内存区
非连续内存区,高端内存区的不连续页框映射到内核空间内一段连续的地址(物理内存映射段之上)。 每个非连续内存区都对应着一个vm_struct, 里面有一个数组记录非连续内存区对应的所有page描述符,并且这个数组是动态分配的。非连续内存区用vmalloc()函数分配。 - 进程地址空间
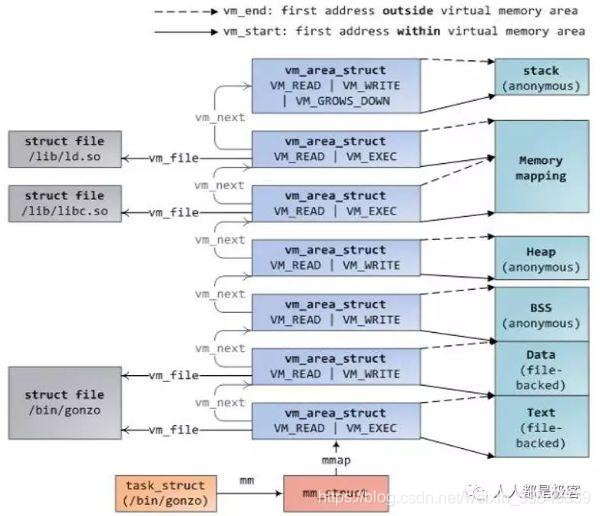
与进程有关的全部信息都包含在内存描述符MM_struct中,进程描述符mm字段指向它。
如果进程在内核态修改了在高端线性区内的页表项,只需要在主内核全局页目录表在swapper_pg_dir中的相应页表,然后进程自己的页表项的present位置空,等到触发缺页异常时再从全局页目录中复制过来。
内存描述符通过mmap字段记录线性区描述符(vm_area_struct)链表:
页表项的Read/write标志等于0,说明相应的页表或页是只读的,否则 是可读写的。线性区有读,写,执行 三种权限。一般情况下线性区和其包含的页表项的权限应该保持一致。但是当两个来自不同进程,但是都拥有写权限的线性区把两个私有页(VM_SHARE标志被清0)装入同一个页框,无论哪一个进程试图改动这个页都应当产生一个异常。总之,线性区具有写和共享两种访问权限,那么,页表项Read/Write位被设置为1。如果线性区具有读或执行访问权限,但是没有同时拥有写和共享访问权限,那么,Read/Write 位被清 0。如果线性区没有任何访问权限,那么,Present位被清0。具体情况交给异常处理程序。比如子进程复制了父进程的页表,并第一次修改某一页,会产生一个异常(因为页表项读写标志位为0),这时内核就把这个页放到一个新的页框,并把标志位置1。 如果是第一个进程访问这个页,那么内核会根据页框对应page描述符引用次数判断要不要使用写时复制。当页表项present标志位为0,此时分为两种情况。ma->vm_ops是vma对应的各种接口的函数列表,如果ma->vm_ops->nopage字段不为空说明线性区映射了磁盘文件,直接调用nopage。否则线性区是一个匿名映射,调用 do_anonymous_page()函数获得一个新的 页框。
- 信号
子进程调用trace后,会阻塞并进入TASK_TRACED状态,所有的信号都发给父进程。gdb的实现:利用fork+execve执行被测试的程序,子进程在执行execve之前调用ptrace(PTRACE_TRACEME),建立了与父进程(debugger)的跟踪关系。子进程遇到int 3后内核会给子进程发送SIGTRAP信号并转发给父进程。在一个线程组中,所有线程的tpid都设置谓领头线程的pid。getpid返回tpid。clone()根据参数的不同可以产生轻量级线程以及子进程。轻量级线程和父进程共享信号描述符(通过将其加入父进程所属线程组),内存描述符和所有页表,打开的文件,用户态栈指针需要父进程提供。
进程描述符里的是私有挂起信号队列,信号描述符里的是共享挂起信号队列。挂起队列元素sigqueue中的siginfo_t是每个信号的实体,记录了信号的编号,发信号的pid,某个内存地址(SIGSEGV信号),以及信号发送者的code
用两个位图来记录各种信号的挂起和阻塞状态,收到一个信号后,如果其对应的阻塞位为1,虽然信号仍然会被加入挂起队列但信号处理程序不会执行。但是收到一个非阻塞信号后, 内核会立即通过wake_up调度目标进程执行信号处理程序,处理完成后把挂起位置0。k_sigction可以指定运行信号处理程序期间需要临时阻塞的信号。SIGKILL和SIGSTOP信号不可以被显式地忽略、捕获或阻塞。 在发送信号时,如果目标的挂起队列中已经有了相同的信号,直接丢弃。通过group_send_sig_info()向线程组发送信号时,输入的参数是进程组中某一个线程,之后信号被加入共享挂起信号队列,然后挑选一个线程来调度执行信号处理程序,如果是SIG_KILL则向组内所有成员发送SIG_KILL信号。
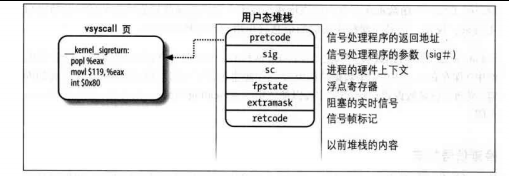
当进程准备从内核态返回到用户态时,内核会检查要返回的进程的pcb中的signal位图信息,如果当前的pengding表中有标志1,那么内核会把pengding链表中悬挂的信号拿出来进程处理。 信号处理程序在需要在用户态执行,但是从内核态进入信号处理函数后,为中断前运行的普通进程保存的硬件上下文就会丢失,所以在进入信号处理函数前,内核运行setup_frame(),其将普通进程的硬件上下文和信号处理程序的参数以及一个系统调用的返回地址一起压入用户态栈。信号处理程序运行完后通过系统调用的返回地址进入用restore_sigcontext(),它负责将普通进程的硬件上下文恢复到其原有的位置,然后就可以正常地返回普通进程。
- 虚拟文件系统 VFS
可以把不同的文件系统安装到VFS, 安装文件系统的这个目录称为安装点。安装点原来的内容会被隐藏。linux的根目录对应的是根文件系统,一般是ext2. 存放在/dev/fd0 磁盘上的ext2文件系统可以通过以下命令安装在/flp:
mount -t ext2 /dev/fd0 /flp
VFS允许安装多层文件系统,比如一个文件系统的安装点可能成为第二个文件系统的目录。
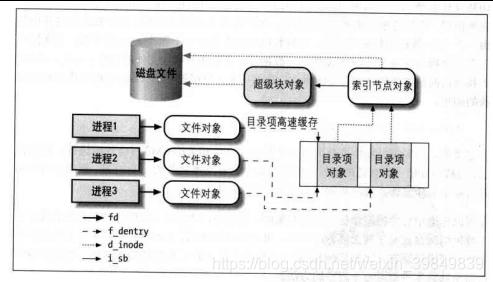
每个文件系统的信息保存在vfsmount 数据结构中,其中最重要的是super_block对象,他是文件系统储存在磁盘上的超级块的映射。文件系统中其它的对象都是动态创建的。比如目录项对象存放文件名和对应文件进行链接的有关信息。一个硬链接对应一个目录项对象。在安装文件系统前必须先注册文件系统。在内核初始化阶段会自动注册已经编译好的文件系统,另外文件系统还可以作为一个模块被动态装入。 - 设备
/dev下存放所有linux可以识别的设备文件,sysfs文件系统中普通文件的主要作用是表示驱动程序和设备的属性。由类型,主设备号,次设备号唯一的标识一个设备。
监控I/O操纵结束有轮询和中断两种模式,中断模式使用自定义foo_dev_t描述符上的信号量使等待i/o结束的进程在队列上睡眠并在唤醒后检查foo_dev_t描述符上的标志位。设备的I/O操作结束后会触发中断,并在中断处理程序中唤醒队列中的进程,把foo_dev_t描述符上的标志位置1. foo_dev_t描述符的地址通常存放在设备文件的文件对象的private_data字段中或一个全局变量中。
内核对设备文件的I/O请求被转交给通用块层,一个请求可能被分为多个I/O操作,因为每个I/O操作只战队磁盘上的一组连续的块。 每个I/O操作在通用块层对应一个bio结构,里面的bio_vec是用于DMA操作的段指针数组。虽然DMA要求磁盘上是相邻的数据,但是内存上的数据可以分散在不同的段上,即所谓的scatter-gather DMA传送方式。DMA一旦被激活就可以自行在I/O设备和ram间传输数据。通用块会把i/o操作加入相应块设备的请求队列中,然后调度层会决定是否合并请求或改变执行顺序。描述块设备的数据结构有两个,一个是struct block_device,用来描述一个块设备或者块设备的一个分区;另一个是struct gendisk,用来描述整个块设备的特性。对于一个包含多个分区的块设备,struct block_device结构有多个,而struct gendisk结构永远只有一个 页高速缓存中的页可以属于普通文件,目录,块设备文件,用户态进程数据以及属于特殊文件系统的页,比如用于进程间通讯。 页高速缓存中的所有页的描述符指针以基树的形式保存在address_space对象中,而address_space对象嵌入在高速缓存所有者的索引节点对象中。基树用页的偏移量检索。偏移量是指页在所有者的磁盘映像中的以页大小为单位的偏移量。
当内核必须单独地访问一个块时(比如文件中有空洞)需要用到块缓存,其包含在叫做"缓冲区页"的专门页中,而缓冲区页保存在页高速缓存中,在同一个页中的块缓存在磁盘中不一定是相邻的。每个块缓冲区的信息都记录在buffer_head类型的缓冲区首部描述符中。在页高速缓存区中搜索某个块缓存时,首先通过块号计算页索引,然后块设备的基树中搜索缓冲区页。获得页描述符之后,内核访问缓冲区首部,它描述了页中块缓冲区的状态。
- 文件读写
文件的潜在用户有三种类型,文件的拥有者,和拥有者同组的用户,剩下的用户。 每种类型有读写执行三种权限,所以文件的访问权限需要九种不同的二进制来标记。还加上两种标记,suid表示进程执行文件时获得可执行文件拥有者的uid, sgid表示进程获得执行文件所有者的组ID。文件空洞:假设文件10个块大小,并且只在最后一个块有数据,前九个块在索引节点的i_block数组上对应元素为0,这些文件块被称作文件空洞。只有在写这些文件块时才会分配给它们磁盘内的逻辑块。
对于写操作,首先用generic_file_aio_write_nolock()更新页高速缓存并将涉及的页标记为脏。 如果文件设置了O_SYNC标志,强制flush所有脏页和索引节点,阻塞当前进程直到I/O数据传输结束。不管是普通文件还是块设备文件,都以块为单位写入。
内存映射:
内存映射分为私有和共享,只有共享内存映射能写内存。创建内存映射需要提供文件描述符,文件内偏移量,要映射的文件部分的长度,可选的起始线性地址,以及一些标志位。 利勇缺页异常处理程序和文件系统的nopage真正给线性区分配页框。进程可以使用msync()系统调用把属于共享内存映射的所有脏页刷新到磁盘,脏页是指页表项dirty标志位1的页,找到脏页后清空dirty位,设置页描述符pg_dirty标志,然后刷新TLB, 方便下一次写操作设置dirty标志位。
直接I/O和内存映射区别,内存映射是磁盘到内核缓存然后再通过映射到用户态内存,直接I/O直接从磁盘到用户态。直接IO就是的内核缓冲区省略了(因为内核缓冲啥时候刷盘是由内核决定的具有不确定性。


 非连续内存区,高端内存区的不连续页框映射到内核空间内一段连续的地址(物理内存映射段之上)。 每个非连续内存区都对应着一个vm_struct, 里面有一个数组记录非连续内存区对应的所有page描述符,并且这个数组是动态分配的。非连续内存区用vmalloc()函数分配。
非连续内存区,高端内存区的不连续页框映射到内核空间内一段连续的地址(物理内存映射段之上)。 每个非连续内存区都对应着一个vm_struct, 里面有一个数组记录非连续内存区对应的所有page描述符,并且这个数组是动态分配的。非连续内存区用vmalloc()函数分配。



 监控I/O操纵结束有轮询和中断两种模式,中断模式使用自定义foo_dev_t描述符上的信号量使等待i/o结束的进程在队列上睡眠并在唤醒后检查foo_dev_t描述符上的标志位。设备的I/O操作结束后会触发中断,并在中断处理程序中唤醒队列中的进程,把foo_dev_t描述符上的标志位置1. foo_dev_t描述符的地址通常存放在设备文件的文件对象的private_data字段中或一个全局变量中。
监控I/O操纵结束有轮询和中断两种模式,中断模式使用自定义foo_dev_t描述符上的信号量使等待i/o结束的进程在队列上睡眠并在唤醒后检查foo_dev_t描述符上的标志位。设备的I/O操作结束后会触发中断,并在中断处理程序中唤醒队列中的进程,把foo_dev_t描述符上的标志位置1. foo_dev_t描述符的地址通常存放在设备文件的文件对象的private_data字段中或一个全局变量中。
 页高速缓存中的页可以属于普通文件,目录,块设备文件,用户态进程数据以及属于特殊文件系统的页,比如用于进程间通讯。 页高速缓存中的所有页的描述符指针以基树的形式保存在address_space对象中,而address_space对象嵌入在高速缓存所有者的索引节点对象中。基树用页的偏移量检索。偏移量是指页在所有者的磁盘映像中的以页大小为单位的偏移量。
页高速缓存中的页可以属于普通文件,目录,块设备文件,用户态进程数据以及属于特殊文件系统的页,比如用于进程间通讯。 页高速缓存中的所有页的描述符指针以基树的形式保存在address_space对象中,而address_space对象嵌入在高速缓存所有者的索引节点对象中。基树用页的偏移量检索。偏移量是指页在所有者的磁盘映像中的以页大小为单位的偏移量。
 内存映射分为私有和共享,只有共享内存映射能写内存。创建内存映射需要提供文件描述符,文件内偏移量,要映射的文件部分的长度,可选的起始线性地址,以及一些标志位。 利勇缺页异常处理程序和文件系统的nopage真正给线性区分配页框。进程可以使用msync()系统调用把属于共享内存映射的所有脏页刷新到磁盘,脏页是指页表项dirty标志位1的页,找到脏页后清空dirty位,设置页描述符pg_dirty标志,然后刷新TLB, 方便下一次写操作设置dirty标志位。
内存映射分为私有和共享,只有共享内存映射能写内存。创建内存映射需要提供文件描述符,文件内偏移量,要映射的文件部分的长度,可选的起始线性地址,以及一些标志位。 利勇缺页异常处理程序和文件系统的nopage真正给线性区分配页框。进程可以使用msync()系统调用把属于共享内存映射的所有脏页刷新到磁盘,脏页是指页表项dirty标志位1的页,找到脏页后清空dirty位,设置页描述符pg_dirty标志,然后刷新TLB, 方便下一次写操作设置dirty标志位。epoll
非阻塞和异步,非阻塞虽然虽然会马上返回,但需要进程自己通过轮询的方式检查数据是否准备好,而异步会主动通过信号通知进程。
多路复用,一个进程同时监听多个文件描述符,阻塞在select,poll或epoll函数上,等到有一个文件描述符准备好了就继续运行。
int select (int maxfdp, fd_set *readfds, fd_set *wri tefds, fd_set errorfds, struct
t irnevaltirneout) ;
select需要把等待不同事件的文件描述符按类放入集合中, select返回后需要用户去检查每个描述符。
int poll(struct pollfd * fds,unsigned int nfds ,int t timeout);
poll出入pollfd结构体数组,每个pollfd包含一个文件描述符,一个注册事件掩码events和一个结果事件掩码revents。 poll返回时会修改结果事件掩码,返回值是revents 域不为0的文件描述符个数。
在调用epoll之前需要为事件表新建个描述符
int epoll_create( int size )
如果需要等待一个事件就把epoll_event结构注册到事件表中
int epoll_ctl( int epfd,int op,int fd,struct epoll_event event )
epoll_event中包括事件掩码(可以设置ET,LT),及poll_data_t结构,其中包含文件描述符。
int epoll_wait( int epfd,struct epoll_event* events,int maxevents, int timeout );
该函数返回就绪的文件描述符的个数,并把就绪事件复制存入events指向的数组中,这样用户就不用了遍历所有的文件符了。
epoll可以分为ET和LT模式,而select和poll都属于LT模式。
当epoll工作在ET模式下时,对于读操作,如果read一次没有读尽buffer中的数据,那么下次将得不到读就绪的通知,造成buffer中已有的数据无机会读出,除非有新的数据再次到达。
所以ET模式下,要求一直调用read知道返回错误,这要求描述符处于非阻塞条件下,否则read在读到报错之前会阻塞。
epoll 给每一个描述符分配一个epitem数据结构
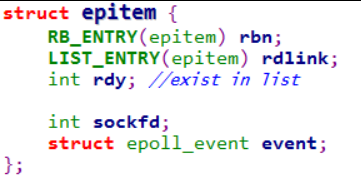
其中有两个用于红黑树和列表的节点元素,通过红黑树可以用fd检索epitem。在TCP中插入回调函数,执行时修改epitem中的event并把epitem插入就绪列表中,等到用户调用epoll_wait时,把就绪列表中每个epitem的event拷贝到用户的events数组中。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/36077.html