
一、数据结构是计算机存储、组织数据的方式。是指相互之间存在一种或多种特定关系的数据元素的集合,通常情况下,精心选择的数据结构可以带来更高的运行或者存储效率
二、常见的数据结构之栈:
1.数据进入栈模型的过程称为:压/进栈
2.数据离开栈模型的过程称为:弹/出栈
3.栈是一种数据先进后出的模型
三、常见的数据结构之数组 :
1.查询数据通过索引定位,查询任意数据耗时相同,查询效率高
2.删除数据时,要将原始数据删除,同时后面每个数据前移,删除效率低
3添加数据时,添加位置后每个数据后移,再添加元素,添加效率极低
4.数组是一种查询快,增删慢的模型
四、常见数据结构之链表:
数据结构与java基础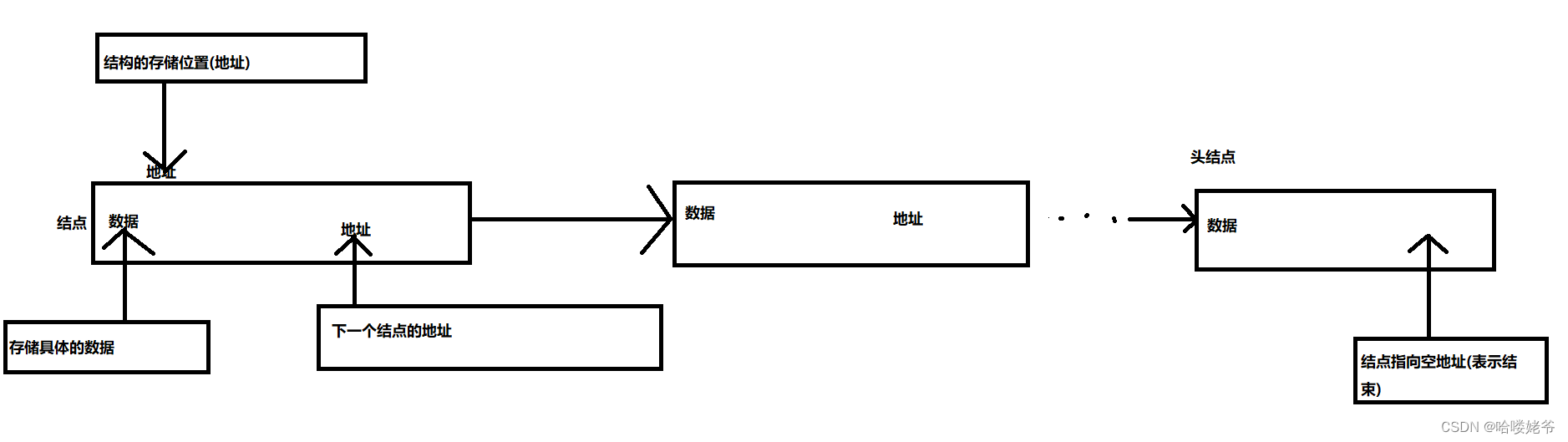
1.示意图:

1.存储一个数据A,保存在地址11位置
2.再存储一个数据C,保存在地址37位置
3.再存储一个数据D,保存在地址96位置
4.查询数据D是否存在,必须从头(hello)开始查询
5.查询3个数据,必须从头(hello)开始查询
五、总结 :
1.链表是一种增删快的模型(对比数组)
2.链表是一种查询慢的模型(对比数组)
List集合子类
一、List集合常用子类:ArrayList、LinkedList:
1.ArrayList:底层数据结构是数组,查询快、增删慢
2.LinkeaList:底层数据结构是链表,查询慢、增删快
二、LinkedList集合的特有方法:
讯享网1.public void addFirst(E e):在该列表开头插入指定的元素
2.public void addLast(E e):将指定的元素追加到此列表的末尾
讯享网
3.public E getFirst():返回此列表中的第一个元素
4.public E getLast():返回此列表中的最后一个元素
讯享网
5.public E removeFirst():从此列表中删除并返回第一个元素
6.public E temoveLast():从此列表中删除并返回最后一个元素
三、ArrayList构造方法:
1.public ArrayList():创建一个空的集合对象
四、ArrayList常用方法:
1.public boolean add(E e):将指定的元素追加到此集合的末尾
2.public void add(int index,E element):在此集合中的指定位置插入指定的元素
3.public boolean remove(Object o):删除指定的元素,返回是否删除成功
4.public E remove(int index):删除指定索引处的元素,返回被删除的元素
5.public E set(int index,E element):修改指定索引处的元素,返回被修改的元素

6.public E get(int index):返回指定索引处的元素
7.public int size():返回集合中的元素的个数
Set集合
一、Set集合特点:
1.不包含重复元素的集合
2.没有带索引的方法,所以不能使用用普通for循环遍历
二、哈希值 :
1.哈希值:是JDK根据对象的地址或者字符串或者数字算出来的int类型的数值
2.Object类中有一个方法可以获取对象的哈希值:
public int hashCode():返回对象的哈希值
三、对象的哈希值特点:
1.同一个对象多次调用hashCode()方法返回的哈希值是相同的
2.默认情况下,不同对象的哈希值是不同的。而重写hashCode()方法,可以实现让不同对象的哈希值相同
HashSet集合
一、HashSet集合特点:
1.底层数据结构是哈希表
2.对集合的迭代顺序不作任何保证,也就是说不保证存储和取出的元素顺序一致
3.没有带索引的方法,所以不能使用普通for循环遍历
4.由于是Set集合,所以是不包括重复元素的集合
二、HashSet集合添加一个元素的过程 :

二、HashSet集合存储元素:
1.要保证元素唯一性,需要重写hashCode()和equals()
三、哈希表 :
1.JDK8之前,底层采用数组+链表实现,可以说是一个元素为链表的数组
2.JDK8之后,在长度比较长的时候,底层实现了优化
LinkedHashSet集合
一、LinkedHashSet集合特点:
1.哈希表和链表实现的Set接口,具有可预测的迭代次序
2.由链表保证元素有序,也就是说元素存储和取出顺序是一致的
3.由哈希表保证元素唯一,也就是说没有重复元素
TreeSet集合
一、TreeSet集合特点:
1.元素有序,这里的顺序不是指存储和取出的顺序,而是按照一定的规则进行排序,具体排序方式取决于构造方法:
TreeSet():根据其元素的自然排序进行排序
TreeSet(Comparator comparator):根据指定的比较器进行排序
2.没有索引的方法,所以不能使用普通的for循环遍历
3.由于是Set集合,所以不包含重复元素的集合
二、自然排序Comparable和比较器排序Comparator结论:
1.用TreeSet集合存储自定义对象,无参构造方法的使用是自然排序对元素进行排序的
2.自然排序,就是让元素所属的类实现Comparable接口,重写compareTo(T o)方法
3.重写方法时,一定要注意排序规则必须按照需求的主要条件和次要条件来写
1.用TreeSet集合存储自定义对象,带参构造方法使用的是比较器排序对元素进行排序的
2.比较器排序,就是让集合构造方法接收Comparator来实现类对象,重写compare(T o1,T o2)方法
3.重写方法时,一定要注意排序规则必须按照需求的主要条件和次要条件来写
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/3386.html