
前几天看“讲桌派直播”,解博老师分享了《如何把Python讲成各学科的刚需课程》。解老师分享的“数学运算”,“随机掷骰子”和“自制生词本”等案例都非常精彩,尤其是“自制生词本”,能够把一篇课文的单词都分离出来,去掉熟悉的单词以后,就制作好了专属生词本,可以帮助孩子们学习英语,具有实际意义。
“自制生词本”案例给了我很大的启发,我觉得自己应该能够做一个类似“百词斩”的多功能单词本。说干就干。我很快从网上下载了一个英语单词库(约14000个单词),开始了我的创作。
下面,就请跟着我,一起体验这场编程之旅吧。
“Python算法之旅”微信群等着你
讯享网



扫码加入“Python算法之旅”微信群,和斌哥面对面交流,更多资料和更有趣的话题等你一起来分享。
素材准备:
1. 单词库word_bank.txt(可以到Python算法之旅知识星球下载)。
2. 熟词本recited_words.txt,用来存储已经背下来的单词(先新建该文本文件,内容可以为空)。
2. 错题本error_words.txt,用来存储拼错的单词(先新建该文本文件,内容可以为空)。
项目目标:
一、单词本功能:
1. 英汉互译;
2. 输入新文章,生成生词本;
3. 查询熟词本、错题本和生词本中的单词;
4. 将单词加入熟词本(从错题本和生词本中删除该单词);
5. 分别从熟词本、错题本或生词本中随机抽选单词默写或填空,记录答对题目数量,并将拼错单词加入错题本。
二、单词本界面:
使用tkinter模块,做一个简单的图形界面,以便进行各种操作。界面如下图所示:
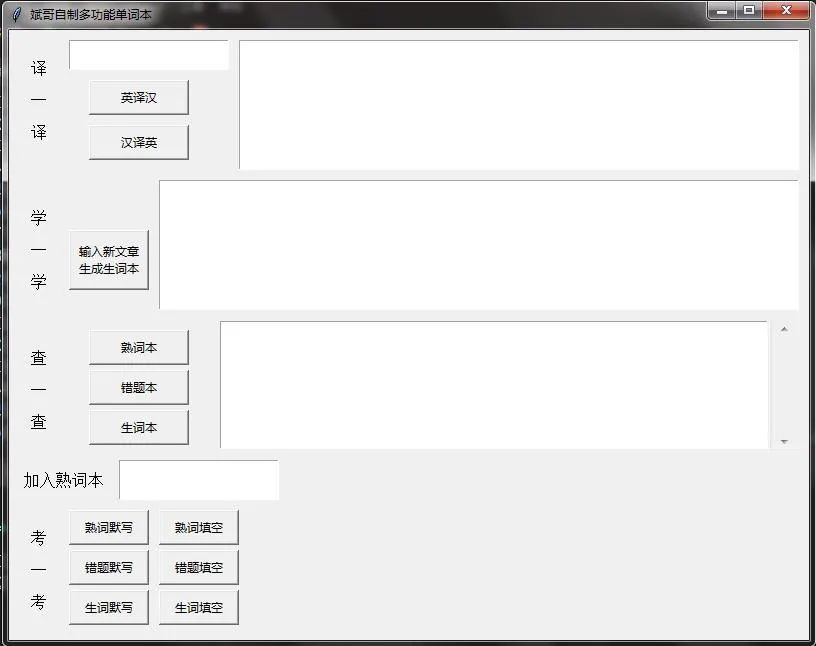
说明:因为我是初次使用tkinter模块,它的很多功能都不了解,我也是匆匆忙忙看了一下tkinter模块的介绍,然后边做边学,因此我的代码肯定还有多不足之处。同时我也想让本文起到抛砖引玉的作用,促进一大批优秀作品的产生。
项目实施过程:
一、从文件中读取单词库、熟词本和错题本内容。
1. 代码:
word_bank =build_word_bank('word_bank.txt')recited_words =build_word_bank('recited_words.txt')error_words =build_word_bank('error_words.txt')new_words = {} #生词本,用来存储新学单词讯享网
2. 解析:
分别用字典word_bank, recited_words,error_words和new_words存储单词库、熟词本、错题本和生词本的单词,其中前三个的数据从各自对应的文本文件中读取,new_words的信息需要等用户输入新文章以后才能生成,故暂时为空。
3. 自定义函数解析:
讯享网'''函数功能:从文本文件读入单词(每行一个单词,包括英文单词,音标,词性和对应的汉语翻译),存储到字典中,每个字典元素的键是一个字符串(英文单词),值是一个元组,该元组有2个元素,分别是单词的音标和汉语翻译(包括词性)。函数名:build_word_bank(textFile:str)->dict参数表:textFile-- 存储了单词的文本文件名。返回值:存储了单词的字典。示例:textFile='word_bank.txt',则返回整个单词库。'''def build_word_bank(textFile): with open(textFile, 'r', encoding='utf8') as f: words = f.read().splitlines()#读取所有行并返回列表 lib = {} for word in words: word = word.encode('utf-8').decode('utf-8-sig').strip() p1, p2 = word.index('['), word.index(']') lib[word[:p1].rstrip()] = (word[p1:p2+1], word[p2+1:])return lib
注释:p1和p2分别定位到音标的左右边界,以便把单词分成3个部分,其中word[:p1]表示英文单词部分,可以作为字典元素的键;元组(word[p1:p2+1], word[p2+1:])作为字典元素的值,分别存储了单词的音标和汉语翻译(包括词性)。
二、译一译:中英文互译。
1. 操作方法:
从文本框text1输入英文单词,点击"音译汉"按钮,则在文本框text2中显示该单词完整信息;从文本框text1输入中文词语,点击"汉译英"按钮,则在文本框text2中显示包含该中文词语的一个或多个单词的完整信息,每行输出一个单词。
2. 自定义函数解析:
'''函数功能:从文本框text1读取英文单词,在单词库找到该单词完整信息,并显示在文本框text2中。函数名:e2c()参数表:因为text1和text2都是全局变量,故无需参数。返回值:无返回值。示例:从文本框text1中输入"good",点击"音译汉"按钮,则在文本框text2中显示" good [gud] a.好;优良的"。'''def e2c(): key = text1.get().strip() if key: ans = word_bank.get(key, ('','wrong word!')) text2.delete(1.0, END) text2.insert(1.0, ' ' + ' '.join((key, ans[0], ans[1]))) '''函数功能:从文本框text1读取中文词语,在单词库找到该单词完整信息,并显示在文本框text2中。函数名:c2e()参数表:因为text1和text2都是全局变量,故无需参数。返回值:无返回值。示例:从文本框text1中输入"中国",点击"汉译英"按钮,则在文本框text2中显示" Chinese ['tʃai'ni:z] n.中国人 China ['tʃainә] n.中国 "。'''def c2e(): val = text1.get().strip() if val: ans = {} for k, v in word_bank.items(): if val in v[1]: ans[k] = v if not ans: #没有找到与该中文词语匹配的英文单词 ans[val] = 'wrong word!' text2.delete(1.0, END) n = len(ans)#总共有n个匹配的英语单词 for k, v in ans.items(): for i in v[::-1]: if i: text2.insert(1.0, i + ' ') text2.insert(1.0, ' ' + k + ' ') n -= 1 if n > 0: #每输出一个单词都要换行,最后一个除外 text2.insert(1.0, '\n')注释:“中译英”的方法是在单词库中查看包含该中文词语的汉语翻译,if val in v[1],即表示该单词的汉语翻译包含待翻译的中文词语,则输出该单词。每个中文词语可以匹配多个英文单词。
三、学一学:输入新文章,生成生词本。
1. 操作方法:
从文本框text3输入英文文章,点击"输入新文章生成生词本"按钮,则在列表框list1中显示所有新单词完整信息,每行输出一个单词。

2. 自定义函数解析:
讯享网'''函数功能:从文本框text3读取英文文章,对比单词库和熟词本,生成生词本,并显示在列表框list1中。函数名:show_new_words()参数表:因为word_bank,recited_words,new_words,text3和list1都是全局变量,故无需参数。返回值:无返回值。'''def show_new_words(): words = text3.get('0.0', 'end').split() for i, v in enumerate(words): if not v[-1].isalpha():#去除尾部标点符号 words[i] = v[:-1] global new_words #全局变量,用来存储生词本 new_words = {} for word in words: word2 = word.lower() word3 = word.capitalize() word4 = word.upper() #判断单词word及其变式是否存在于单词库且不在熟词本中 if word in word_bank and word not in recited_words: new_words[word] = word_bank[word] elif word2 in word_bank and word2 not in recited_words: new_words[word2] = word_bank[word2] elif word3 in word_bank and word3 not in recited_words: new_words[word3] = word_bank[word3] elif word4 in word_bank and word4 not in recited_words: new_words[word4] = word_bank[word4] list1.delete(0, END) words = sorted(new_words.items())#将生词本排序后依次插入到列表框中 for k, v in words: word = ' ' + k + ' ' for i in v: word += i + ' ' list1.insert(END, word)
注释:show_new_words函数先把text3中的各个单词提取出来存储到列表words中,考虑到文章中的单词书写在大小写字母方面可能存在不规范问题,为避免漏掉单词,需要做容错处理,故设置了3个变量word2, word3和word4来存储单词word的3种可能变形。然后判断该单词是否存在于单词库中,同时判断是否存在于熟词本中,若存在于单词库且不在熟词本中,说明是一个生词,则将其加入到生词本中。最后将生词本排序后依次插入到列表框中显示出来。
四、查一查:显示熟词本、错题本或生词本中的全部单词。
1. 操作方法:
点击“熟词本”、“错题本”或“生词本”按钮,则在列表框list1中显示所有对应单词,每行输出一个单词。
2. 自定义函数解析:
'''函数功能:点击“熟词本”、“错题本”或“生词本”按钮,则在列表框list1中显示所有对应单词。函数名:show_words(type_flag:str)参数表:type_flag-- 对应3种单词本的变量名字符串,只可能是'recited_words','error_words'或'new_words'。返回值:无返回值。'''def show_words(type_flag:str): if type_flag == 'recited_words': words = sorted(recited_words.items()) elif type_flag == 'error_words': words = sorted(error_words.items()) else: words = sorted(new_words.items()) list1.delete(0, END) for k, v in words: word = ' ' + k + ' ' for i in v: word += i + ' ' list1.insert(END, word)注释:点击不同按钮传送不同参数到本函数,根据参数找到对应的字典,在对字典进行排序以后,将各单词插入到列表框List1中。
五、加一加:将单词添加到熟词本,并从对应错题本或生词本中删除该单词。
1. 操作方法:
从文本框text_recited_word输入一个新单词,按下回车键后,系统在单词库中找到该单词,在文本框右侧显示该单词的全部信息,并添加到熟词本。若输入的单词不在单词库中,则显示“不存在单词*”,并不予记录。
2. 绑定键盘事件:
讯享网text_recited_word.bind('',add_recited_word)
从文本框text_recited_word输入一个新单词,按下回车键后,调用函数add_recited_word。
3. 自定义函数解析:
'''函数功能:从文本框text_recited_word输入一个新单词,按下回车键后,将该单词加入到熟词本,并从对应错题本或生词本中删除该单词。函数名:add_recited_word(event)参数表:event-- 回调函数,当按下回车键时,它会被自动调用。返回值:无返回值。'''def add_recited_word(event): word = text_recited_word.get().strip() if word in word_bank: #将正确的单词存储到已背诵单词本,并及时写入到文本文件中 if word not in recited_words: recited_words[word] = word_bank[word] with open('recited_words.txt', 'a', encoding='utf8') as f: f.write(''.join([word,recited_words[word][0],recited_words[word][1]]) + '\n') info = word #在文本框右侧新建一个标签,显示被记录单词的详细信息 for i in recited_words[word]: info += i + ' ' label_word = Label(root, text=info, font=30) label_word.place(x=280, y=430, width=520, height=40) #从对应错题本或生词本中删除该单词 if word in new_words: del new_words[word] if word in error_words: del error_words[word] with open('error_words.txt', 'w', encoding='utf8') as f: for k, v in error_words.items(): f.write(' '.join([k, v[0],v[1]]) + '\n') else: label_word = Label(root, text=f'不存在单词:{word} ',font=30, fg='red') label_word.place(x=330, y=430, width=550, height=40)注释:本函数是一个事件绑定函数,当在文本框text_recited_word中按下回车键后它会自动调用一个回调函数。函数会判断输入的单词是否正确(即能否在单词库中找到),如果是正确的单词,且熟词本中尚未存储该单词,则将其存储到字典recited_words,并及时写入到文本文件recited_words.txt中。最后从对应错题本或生词本中删除该单词。
六、考一考:分别从熟词本、错题本或生词本中随机选择一个单词默写或填空。
1. 操作方法:
点击“熟词默写”、“错题默写”或“生词默写”按钮,则分别从熟词本、错题本或生词本中随机选择一个单词默写,软件会显示该单词的中文意思(含词性),用户在右侧的文本框中输入英文单词,按下回车键后,系统对答案进行判断,若答案正确则显示“正确”和答对的次数,否则用红色字体显示正确的单词。
“熟词填空”与“熟词默写”的区别在于,“熟词填空”会给出不完整的英文单词,并用星号代替要填写的字母,用户在右侧的文本框中输入英文单词,并按下回车键。
2. 点击按钮事件:
讯享网bt61 =Button(root, text ="熟词默写", command=lambda:test('recited_words')) bt62 =Button(root, text ="熟词填空", command=lambda:test('recited_words_fill'))
点击按钮bt61或bt62,都会调用事件方法command=函数名,因为函数需要传值,所以使用了匿名函数返回test及其参数。
3. 自定义函数解析:
'''函数功能:根据参数判断单词来源,在相应的单词本中随机出题,并检查用户提交的单词回答是否正确。若正确则计分,否则显示正确答案,并将该单词加入到错题本。函数名:test(type_flag)参数表:type_flag-- 对应6种出题方式,只可能是'recited_words','recited_words_fill','error_words','error_words_fill'或'new_words','new_words_fill'。返回值:无返回值。'''def test(type_flag): def blank_filling(word):#随机设置填空的位置,用*代替字母 ans = list(word) pos = random.sample(range(len(word)), random.randint(1, len(word)*3//4)) for i in pos: ans[i] = '*' return ''.join(ans) def check(event):#判断答案是否正确 global score nonlocal ansflag if a[0][0] == text_word.get(): #答案正确时显示'正确 + 成绩' if ansflag: #标记ansflag,避免多次按下回车键时重复计分 score += 1 ansflag = False label_ans = Label(root, text='正确 ' + str(score),font=30) label_ans.place(x=640, y=540, width=150, height=40) else: #答案错误时显示正确的单词,并将该单词加入到错题本 word = a[0][0] label_ans = Label(root, text=word, font=30, fg='red') label_ans.place(x=640, y=540, width=150, height=40) if word not in error_words: error_words[word] =word_bank[word] with open('error_words.txt','a', encoding='utf8') as f: f.write(''.join([word,error_words[word][0],error_words[word][1]]) + '\n') if type_flag == 'recited_words': if not recited_words: return a = random.sample(recited_words.items(), 1) label_word = Label(root, text=a[0][1][1], font=30) elif type_flag == 'recited_words_fill': if not recited_words: return a = random.sample(recited_words.items(), 1) label_word = Label(root,text=a[0][1][1]+': '+blank_filling(a[0][0]), font=30) #此处省略分支语句20行,可自行脑补 ansflag = True #标记该单词是否已经提交检查,避免重复计分 label_word.place(x=240, y=500, width=390, height=70) text_word = Entry(root, font=30) text_word.place(x=640, y=490, width=150, height=40) text_word.bind('', check)注释:本函数根据参数判断单词来源,在相应的单词本中随机出题,并检查用户的回答是否正确。设置了2个嵌套函数,其中blank_filling(word)函数在单词word中随机设置填空的位置,用*代替字母,并返回修改后的单词。check(event)函数是回调函数,当按下回车键时,它会被自动调用,判断答案是否正确,并作出相应的处理。全局变量score用来计算得分,nonlocal变量 ansflag用来标记该单词是否已经提交检查,以避免重复计分。
结语:
好了,到这里,就把“多功能单词本”各个模块的功能和代码实现都给大家做了详细的分析了。设计界面布局的代码我没有贴出来,因为我认为页面布局不是我的强项,大家肯定能够写出更精彩的代码。当然,如果你是新手,需要完整的代码,那可以加入“Python算法之旅”知识星球,下载完整的源代码。
需要本文word版的,可以加入“Python算法之旅”知识星球参与讨论和下载文件,“Python算法之旅”知识星球汇集了数量众多的同好,更多有趣的话题在这里讨论,更多有用的资料在这里分享。
我们专注Python算法,感兴趣就一起来!
相关优秀文章:
阅读代码和写更好的代码
最有效的学习方式
算法进化历程1剪刀石头布
算法进化历程2灯泡开关
算法进化历程3相亲数对

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/28041.html