
工作中要做一个桌面控制相关需求,试了下ClawHub现有Desktop Control skill,发现都有一些不好用的地方,或者与macOS系统不够适配,因此写了一个新skill供大家使用和交流
- 这个Skill主要链路如下:

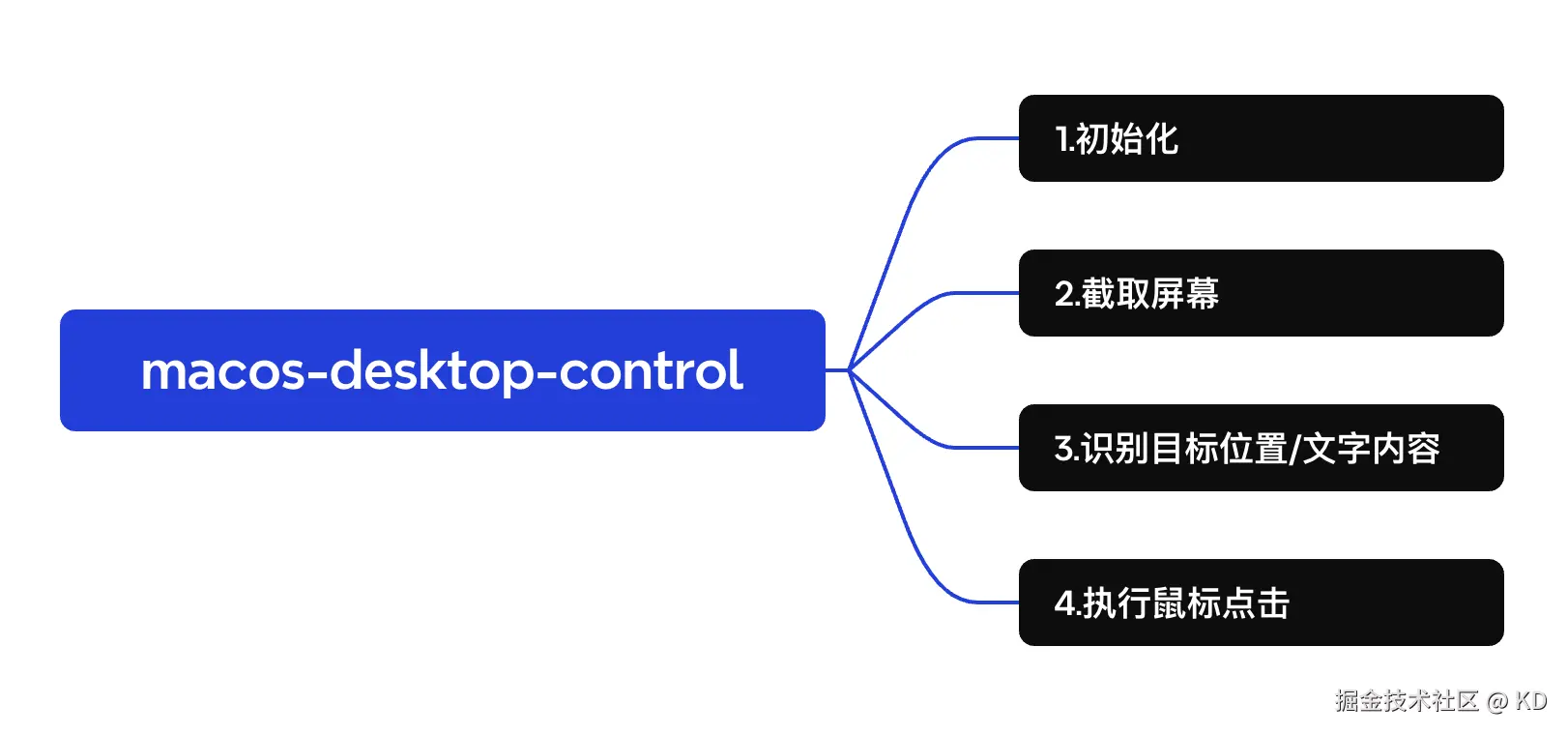
这一步是最关键的,也是很多现有skill缺失的一步。第一版本先只做Retina屏兼容
在 macOS 上,即使截图和点击都用 Python,也仍然需要先确认几件事情:
截图图像尺寸是多少
屏幕逻辑尺寸是多少 鼠标点击使用的坐标系是什么
原因是,在 Retina 屏、缩放显示器、多屏环境下,截图图片的像素尺寸和 pyautogui.size() 返回的逻辑屏幕尺寸可能不同。
比如 Retina 屏上经常会出现这种情况:
截图图像尺寸:2880 × 1800
逻辑屏幕尺寸:1440 × 900
这意味着截图里的 2 个 pixel,才对应 macOS 逻辑坐标里的 1 个 point。
如果直接拿截图上的像素坐标去点击,就可能点偏。
所以初始化阶段要做的事情是:
用 Python 获取截图尺寸和逻辑屏幕尺寸,计算两者之间的缩放比例,并把结果保存到文件中,供后续流程使用。
截图这一步继续使用 Python 的 pyautogui。
关键点是:截图之后,把图片 resize 到 pyautogui.position() 和 pyautogui.click() 使用的坐标系。
示例代码如下:
import pyautogui
img = pyautogui.screenshot()
screen_w, screen_h = pyautogui.size()
把截图 resize 到 pyautogui.position() / click() 使用的坐标系
img = img.resize((screen_w, screen_h))
img.save("screen_logical.png")
这一步看似简单,但非常关键。
如果我们后续所有识别都基于 screen_logical.png,那识别结果天然就在逻辑坐标系里,后面的点击会简单很多。
也就是说,我们把坐标统一这件事放到了截图阶段完成:
截图原始尺寸:2880 × 1800
逻辑屏幕尺寸:1440 × 900 resize 后图片:1440 × 900 OCR / OpenCV 返回坐标:逻辑坐标 pyautogui.click 使用坐标:逻辑坐标
这样整个 skill 的坐标系统会更稳定。
识别定位可以分成两类:
文字识别:OCR
图像识别:OpenCV
这两种能力覆盖了大多数桌面自动化场景。
OCR 文字定位
OCR 适合查找界面上的文字,比如按钮文案、菜单项、标题、标签等。
例如:
查找"确定"
查找"发送" 查找"登录" 查找"保存"
流程大致是:
读取 screen_logical.png
运行 OCR 找到匹配文本 返回文字区域中心点
返回结果可以是:
{
"type": "text", "query": "发送", "x": 1200, "y": 820, "confidence": 0.92 }
然后鼠标点击模块直接点击 (1200, 820)。
OCR 的优点是泛化性强。只要界面上有文字,就不需要提前准备模板图。
但它也有局限,比如小字号、低对比度、特殊字体、中文识别质量等,都可能影响结果。
所以 OCR 更适合这类场景:
界面文字清晰
目标按钮有明确文案 需要查找的内容不固定 不想提前维护模板图片
OpenCV 图像定位
OpenCV 更适合查找图标、按钮、头像、固定 UI 区块等视觉目标。
例如:
查找某个 App 图标
查找关闭按钮 查找发送图标 查找某个固定图片区域
典型做法是模板匹配:
读取 screen_logical.png
读取 template.png 使用 OpenCV matchTemplate 找到最高匹配区域 返回中心点
返回结果可以是:
{
"type": "image", "template": "send_button.png", "x": 1185, "y": 835, "confidence": 0.88 }
OpenCV 的优点是对图形元素定位更稳定,不依赖文字识别。
但它也有局限。界面缩放、主题变化、深色模式、按钮状态变化,都可能影响匹配结果。
所以这两种方式最好同时保留:
有文字 → 优先 OCR
有图标 → 使用 OpenCV 复杂场景 → OCR + OpenCV 组合验证
最后一步是鼠标点击。
这里仍然用 Python 实现,继续使用 pyautogui:
import pyautogui
pyautogui.click(x, y)
为了让它更适合作为 skill 使用,点击脚本最好支持命令行参数:
python scripts/mouse/click.py --x 1200 --y 820
也可以增加一些常用选项:
python scripts/mouse/click.py --x 1200 --y 820 --duration 0.1
python scripts/mouse/click.py –x 1200 –y 820 –button left python scripts/mouse/click.py –x 1200 –y 820 –double
这样 OpenClaw 在拿到定位结果后,就可以直接调用点击脚本完成操作。
因为前面的截图和识别都已经统一到了逻辑坐标,所以点击阶段不需要再做复杂转换:
识别结果 x, y → pyautogui.click(x, y)
这也是为什么前面的坐标统一非常重要。
- GitHub :github.com/KD-oauth/ma…
- ClawHub :clawhub.ai/kd-oauth/de…
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/272085.html