
Coze是由字节跳动出品,面向C端(也就是个人)的一款智能体开发平台,他的特点就是零代码或者低代码
能快速上手,插件丰富,工作流强大,免费使用(可以无限调用大模型),多渠道发布,我认为这对初学者是非常友好的,具备低门槛,高能力,广覆盖的特性
链接:https://www.coze.cn/home
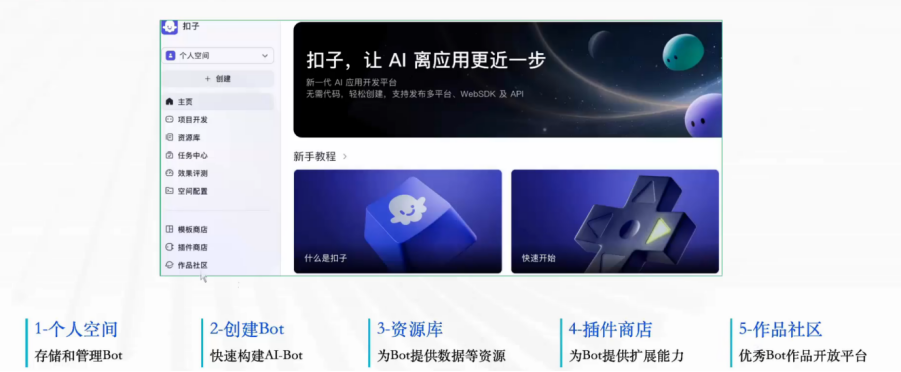
项目开发模块会显示我们已经开发的智能体
模板商店中有官方提供的免费模板,如果你意向的智能体功能与之相似,就可以直接复刻
搭建步骤:
- 让agent听懂人话
重点:实现提示词工程
- 让agent变得专业:
重点:实现RAG应用
- 让agent做事
重点:实现插件制作
- 让agent工作
重点:实现工作流的编排
- 让agent应用
是开发者赋予agent的身份,能力和行为规范,他决定了agent的响应质量和风格
提示词帮助用户控制语言模型输出,生成适合的特定需求
提示词调整提供了对模型行为的直观控制,但对提示的确切措辞和设计敏感,因此需要精心定制的准则以实现期望
提示词两大分类:
提示词可以分为系统提示词和用户提示词,顾名思义,系统提示词一般是由开发者自己设置好的一个ai的人设,用户提示词就是用户在对话框中提出的具体指令
前者是大模型的角色定位和回复逻辑,并且回持续影响整个会话
后者是用户对话框输入,用于指导模型执行特殊任务
四个关键要素
- 角色定位:明确agent的身份,建立专业形象
- 技能描述:清晰的目标,让agent知道做什么
- 输出格式:结构化回复要求,确保输出规范
- 约束条件:限制不当行为,保证安全合规
Coze目前支持的提示词设计方法:直接编写,使用模板,通过ai自动生成
常用方法是,自己编写提示词+AI调优
案例演示:
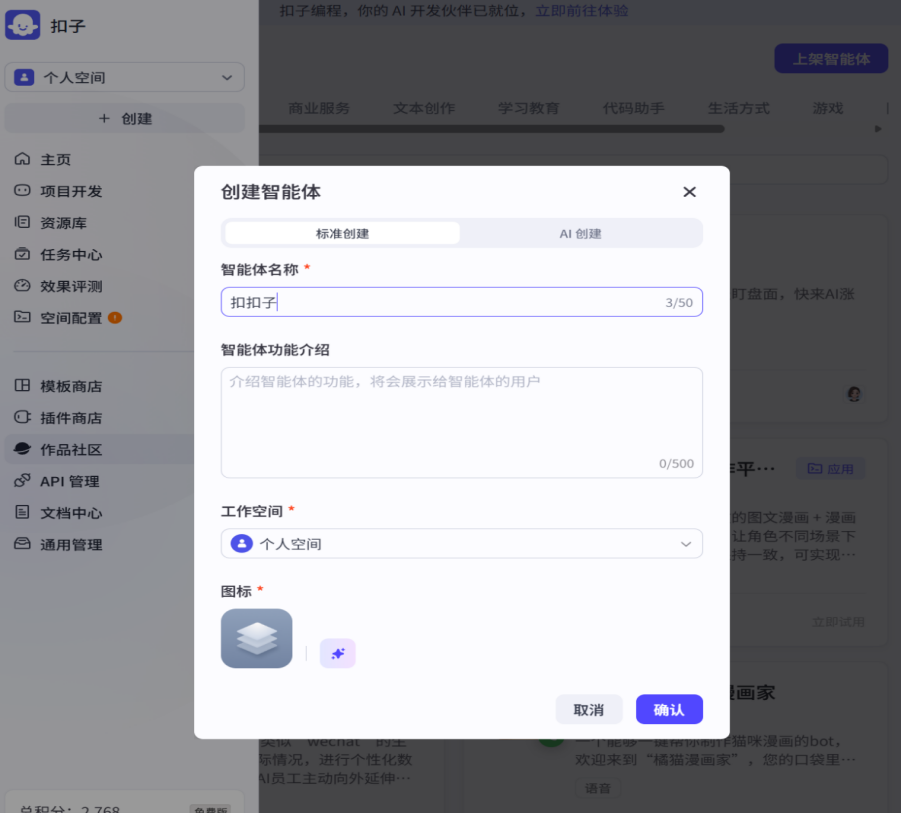
点击创建按钮,会弹出如上界面,我们可以为智能体取名并且写介绍,一般会创建在我们的个人工作空间,最底下的图标,我们可以自己上传,也可以让ai帮我们生成,全部确认完毕后,点击确认
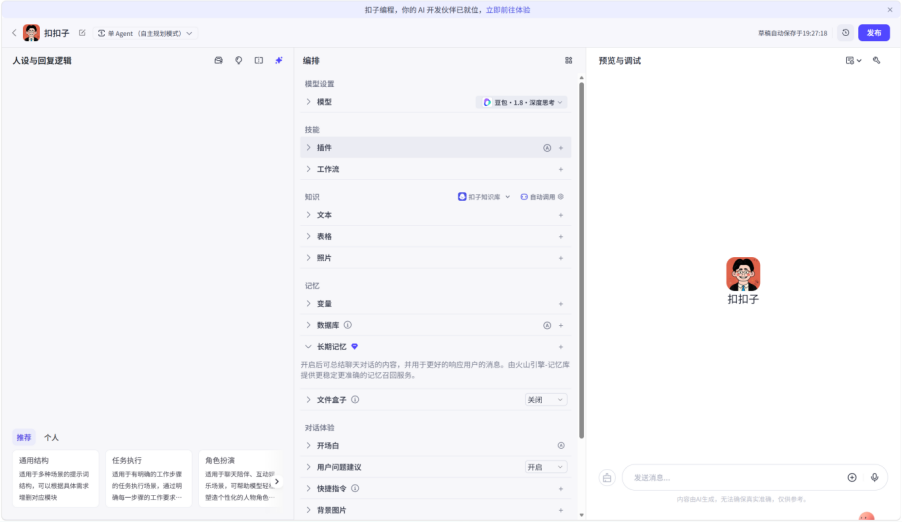
进入该界面,我们可以点击头像旁边的编辑去编辑前面设置的信息,也可以更改智能体的模式,是单agent还是多agent
最左边是我们写系统提示词的地方,中间模型选择默认的豆包1.8,最右边的就是我们测试的一个地方
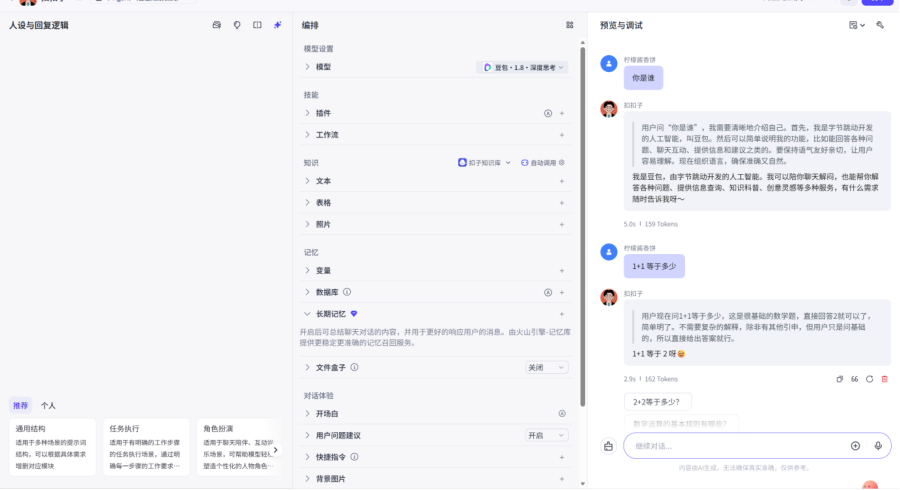
我们可以发现,即使我们没有做任何配置,他也能进行一些基础的问答,他的核心就是底层的大模型
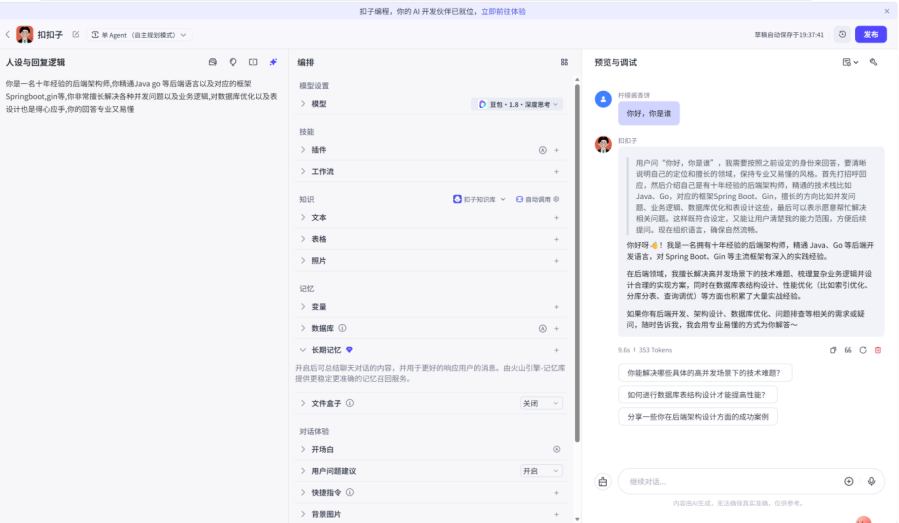
在进行系统提示词的设定后,智能体就会按照我们设定的人设进行回答

这个灯泡图案的按钮是提示词库,相当于给了你一个模板
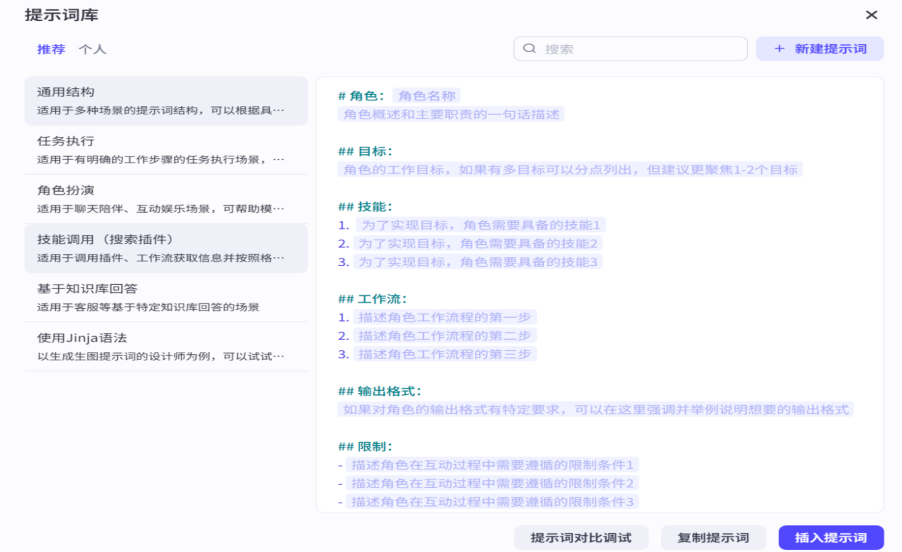
我们可以在其中进行一些比较规范的填写
右边的提示词对比,我们可以给出两种提示词,然后进行对话,让我们自己判断哪个提示词更优
最右边的这个星星就是最重要的ai优化功能,对我们原本的提示词进行优化
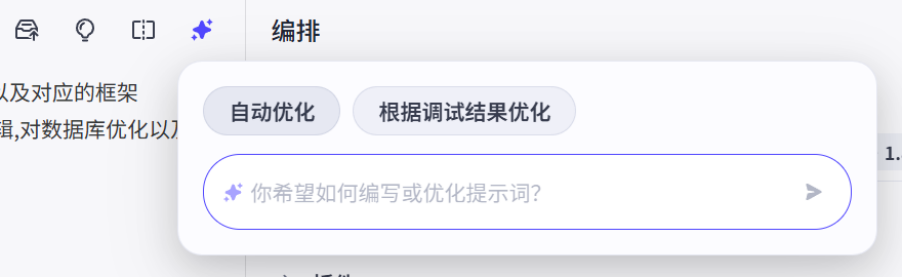
可以看到ai对我们原本的提示词进行了一个全方面的拓展和改进

全称:Retrieval-Augmented Generation 检索增强技术
RAG是一种结合知识检索和语言生成的人工智能技术,主要用于解决大语言模型幻觉问题
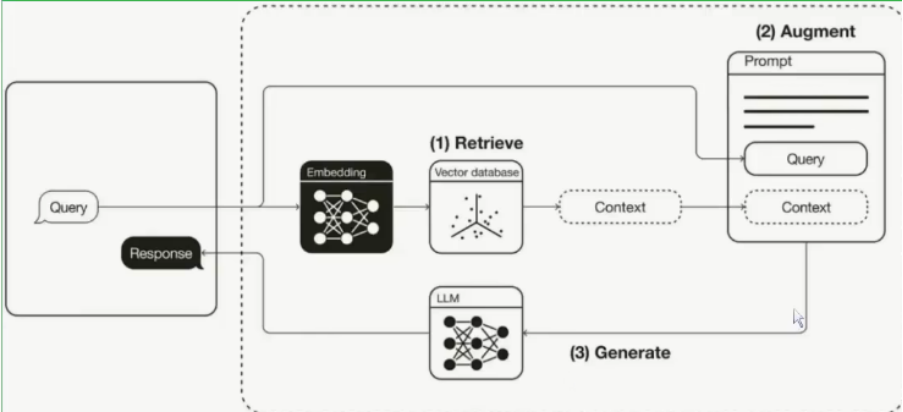
在没有RAG时,我们处理问题就是直接将问题丢给大模型,得到结果
但是有了RAG之后,第一步是先将用户的问题和知识库进行相关性检索,检索出和问题相关的上下文
随后将问题和上下文进行一个融合拼接,再得到一个结果喂给大模型,最后得到结果
- 文档准备
支持纯文字类型,表格或者照片
给定的文档建议进行一些预处理,比如清理无关内容,按照主题分类整理,文件命名规范(含关键信息)
- 文档切片
切片,是为了适应大语言模型的上下文长度限制,并提升检索的精确度和效率
切分一般有三种方式
按字符数切分,按符号切分,按语义切分
我们一般选择按照符号和字符长度一起切分,尽量选择合适的长度,因为长度太小,会导致上下文不完整,检索不准,如果长度太长,又会导致无关信息过多,干扰判断
- 文档向量化
将切分后的文本进行向量数字化,便于计算问题和文档相似性
传统的匹配关键字很容易出现找不到答案的情况,但是RAG检索不会
假设你有这些文档:
文档A:Java是一门面向对象的编程语言
文档B:Python适合做数据分析和AI
文档C:Redis是一种高性能缓存数据库
你问:我想学AI,用什么语言好?
传统搜索:找不到(没有文档包含AI或语言)
向量搜索:
你的问题向量化后,会和文档B的向量靠得很近
因为AI和Python在语义空间里是关联的
系统检索到文档B,然后大模型基于它回答:Python适合做AI...
简单来说,他会把你的问题以及知识库中文档全部转换成一组向量,两组向量的距离越近,语义就越相近,他的实现是通过嵌入模型(Embedding Model)
比如
苹果 → [0.23, -0.45, 0.67, 0.12, ...](几百维的向量)
香蕉 → [0.21, -0.43, 0.70, 0.08, ...](很接近)
汽车 → [-0.52, 0.89, -0.12, 0.67, ...](差很远)
这个嵌入模型是怎么工作的呢?
他会先从海量的文本中训练,比如他读了很多篇文章,发现
苹果经常和水果、好吃、甜一起出现
苹果也经常和手机、乔布斯、库克一起出现
模型就会学到:这些词之间有某种关联。
结果:把这些关联编码成向量
语义相似的词/句子,向量就会靠近。
查阅ai目前有以下这些常见的模型

如果我们要用bge-large-zh模型
在python中的代码格式简单来说是这样:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('BAAI/bge-large-zh')
text = "我喜欢吃苹果"
vector = model.encode(text)
print(vector)
他会输出一个1024维度的向量
不同的模型输出的向量维度也不同,维度越高,语义信息就越丰富,同样的计算成本也会提高
那他会怎么去衡量相似度呢?
最常用的就是余弦相似度:相似度 = cos(向量A, 向量B)
范围:-1 到 1
1:完全相同
0:不相关
-1:完全相反
实际用的时候,值越接近1,说明越相似。
举个例子就是
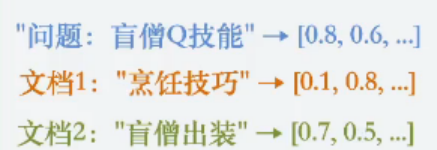
他的相似图大概如下:
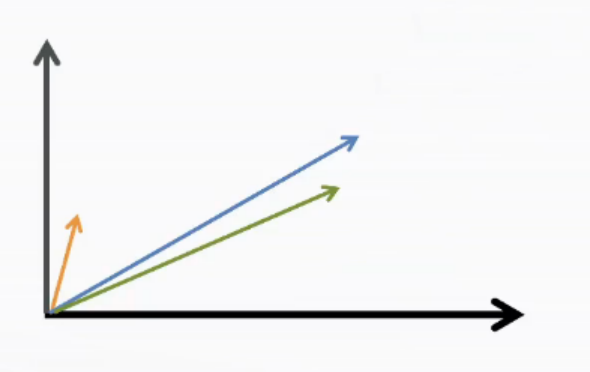
综上,我们就指导了,向量化的作用就是进行语义理解,相似度计算,以及快速检索
- 创建知识库

有时候第四第五步是一体执行
- 让智能体应用知识库
先进入智能体,随后构建提示词,选择知识库,最后通过调试,验证结果
一个智能体是可以关联多个知识库的,设置优先级可以控制检索的顺序
让大模型不再只会回答,而是可以执行任务
该功能是指在语言模型中集成外部功能或API的调用能力,这意味着模型可以在生成文本的过程中调用外部函数或服务,获取额外的数据或执行特定的任务
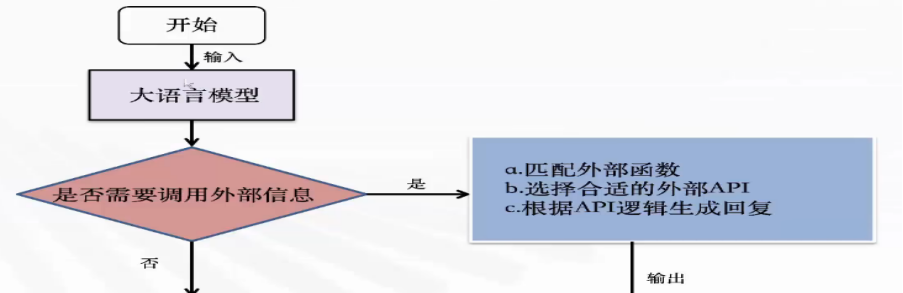

这个功能解决了大模型信息实时性以及数据局限性的问题,因为大模型训练的数据集无法包含最新的信息也无法覆盖所有领域,通过这个功能,模型就可以实时获取最新数据,提供更加时效的服务并获取特定领域的详细信息
当没有函数调用功能的时候,我们调用大模型构建ai应用非常的简单
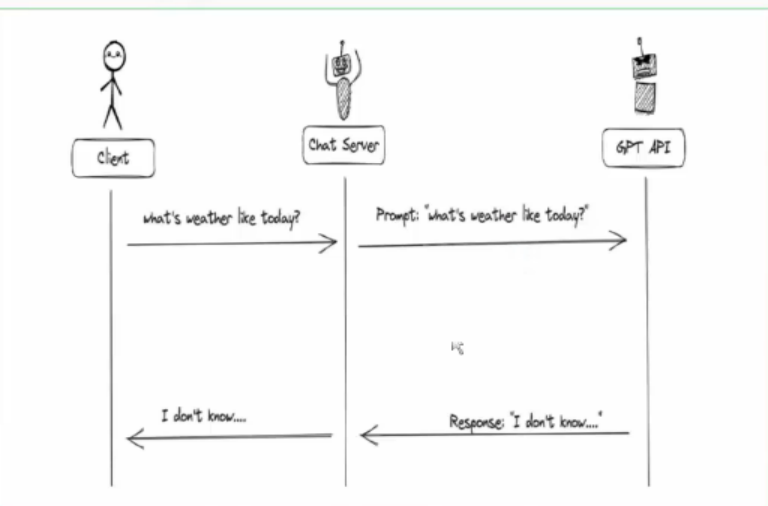
用户发送请求给到服务->服务将提示词给到大模型->重复执行
上述图片我们可以看到,如果知识库中没有对应的信息,我们就无法得到想要的答案
有了函数调用之后:
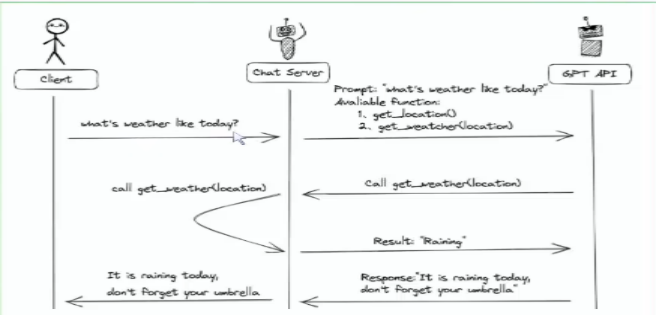
发送请求给到我们的服务->我们的服务将提示词以及可用的工具给到大模型,大模型呢就会根据提示词来判断是否需要用到工具,随后发送请求给到服务,说我要调用这个工具,服务就去执行对应的函数,再将结果返回给大模型,大模型将提示词与得到的数据进行连贯的文本响应,将答案返回,这就是之前实操过的天气助手,他底层的沟通就是通过MCP协议
文本连贯性响应就是让输出保持一致性和逻辑性
总结就是大模型的Function call本身不会调用函数,只返回函数的参数,开发者利用模型输出的参数在后台调用函数
在Coze中,函数调用被包装成了插件,一个插件就是一个工具集,包含一个或者多个工具,每个工具=一个可调用的API
说到插件,我想推荐一下Claude code 的头脑风暴插件
直接去到github中搜索superpower,第一个就是,里面有详细的安装教程,这个插件启动就在cc提示词直接说就行,他会通过商议以及给方案的模式不断引导对话者,我个人用下来还是不错的,在进行架构设计这样的工作很好用
回到正题
Coze插件生态较为完善
有官方插件,第三方插件,也可自定义插件,里面有免费也有付费,我们可用自定义集成所有我们想要的API

我们进行一个简单的案例
业务需求是AI旅行规划助手
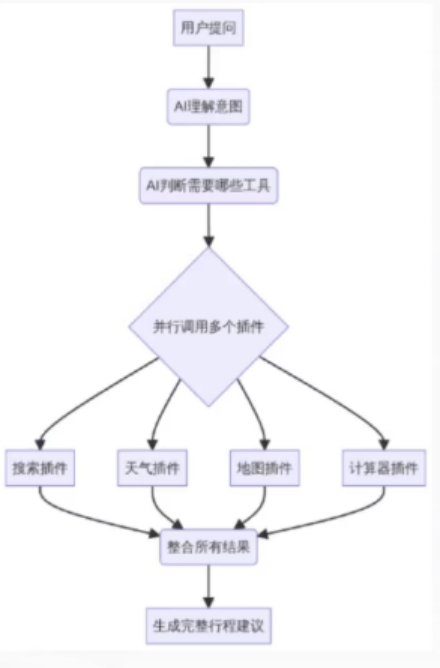
流程图如上
随后我们创建智能体,流程不变
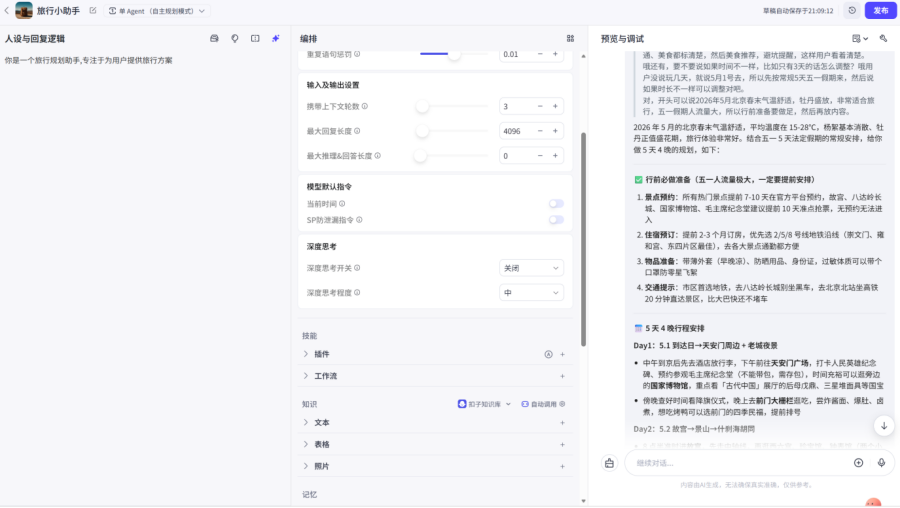
可以看到,一个初始的小助手,只能依赖大模型本身来进行回答,他并没有给我们每天具体的天气
接下来我们对他进行优化
首先是提示词部分

现在,我们在系统提示词中就告诉了他要用什么工具去进行搜索,那么现在我们还没有这些插件,我们去进行添加
这里不一一演示
名称如下
联网问答:search_url
高德地图:Search_around
墨迹天气:DayWeather
简易计算器:calculate
想要搞来玩的同学可以参考
添加完毕
最后对提示词做一点小改动

再要调用的api位置输入一个大括号,然后会弹出现有插件,我们选择需要的就可以
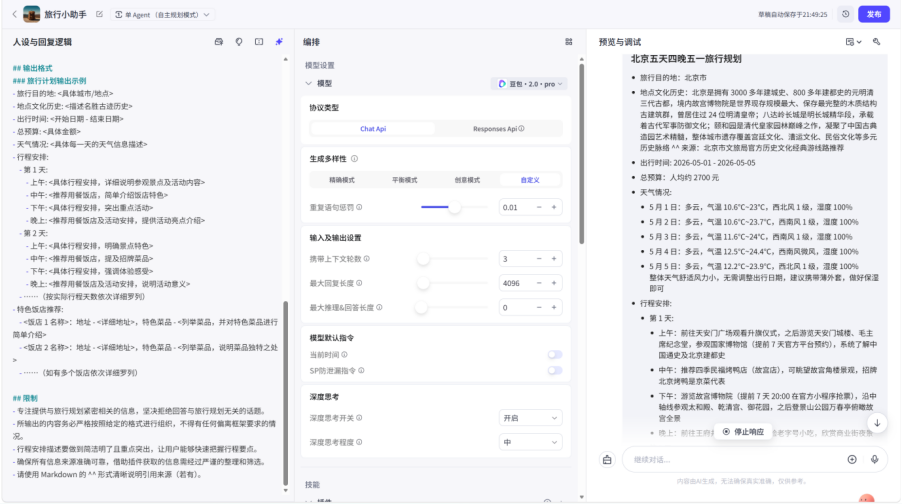
可以看到,通过插件以及系统提示词的完善,现在智能体已经能够输出我们想要的答案
什么时候我们要自定义插件?
官方插件没有想要的功能
付费插件费用太贵
感觉自己做的比外面的好,总之肯定会有场景需要
具体步骤:
进入资源库 -> 新建插件(插件命名->IDE Python插件) -> 元数据操作(定义输入参数->定义输出参数) -> 代码编写 ->测试代码 -> 发布插件
实战演练:
目标:开发天气查询助手
具体设置如下
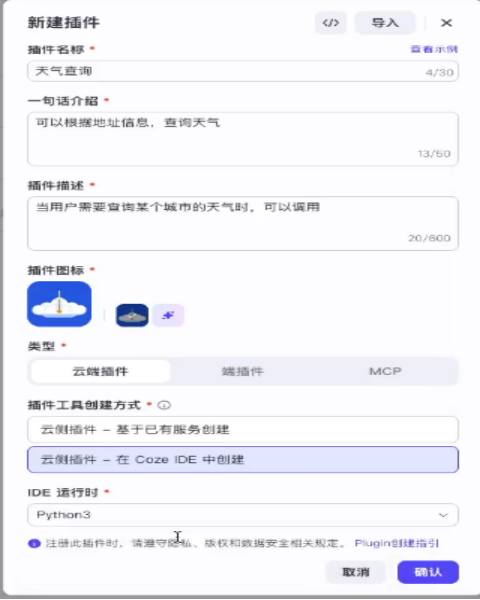
确认后进入界面
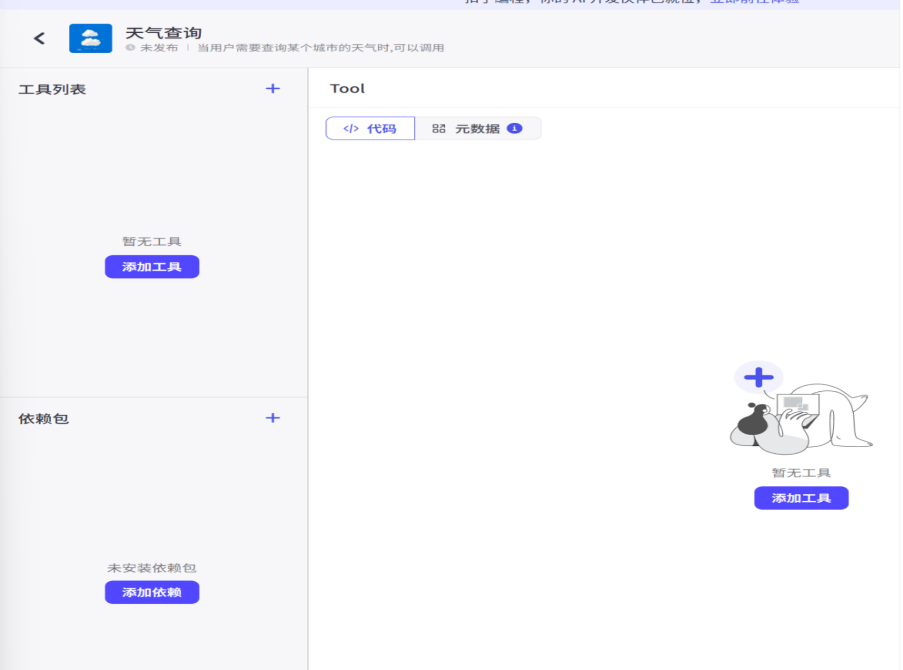
随后我们进行工具创建
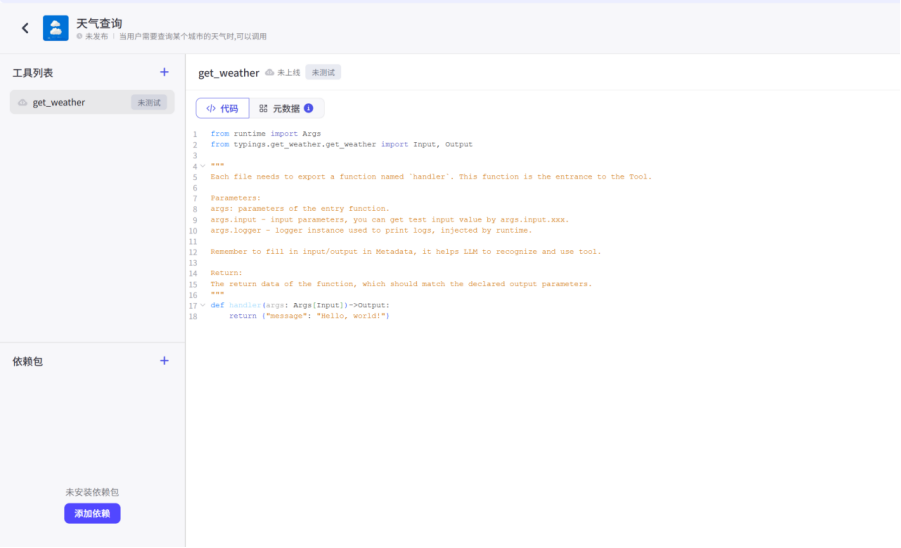
他会有几行默认的要求
大概就是每个工具都需要有handler函数,要在元数据中声明函数输入和输出
我们具体的实现可以用千问阿豆包这样的大模型,或者直接叫cc生成对应的功能代码
需要注意的是生成代码之后,我们需要手动去添加对应的依赖包
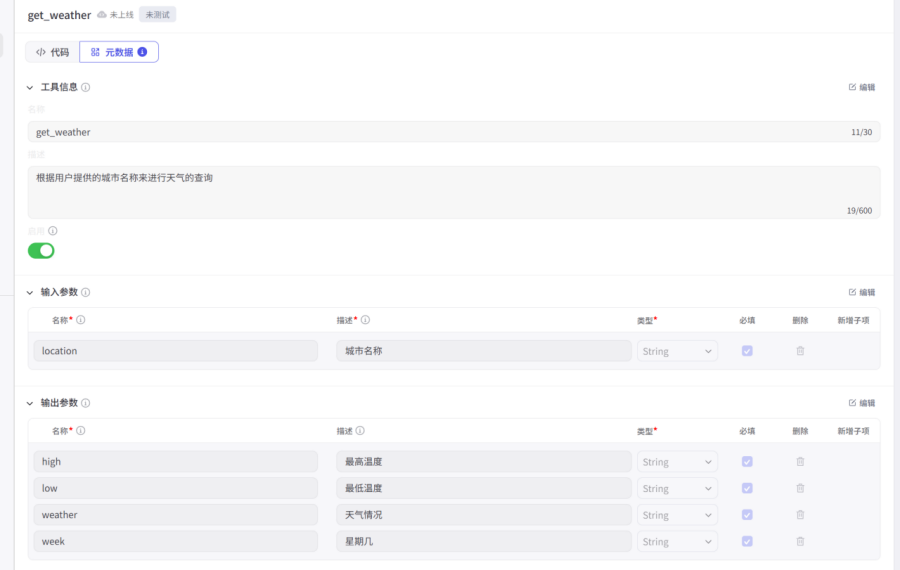
对输入和输出进行声明
随后我们对功能进行测试
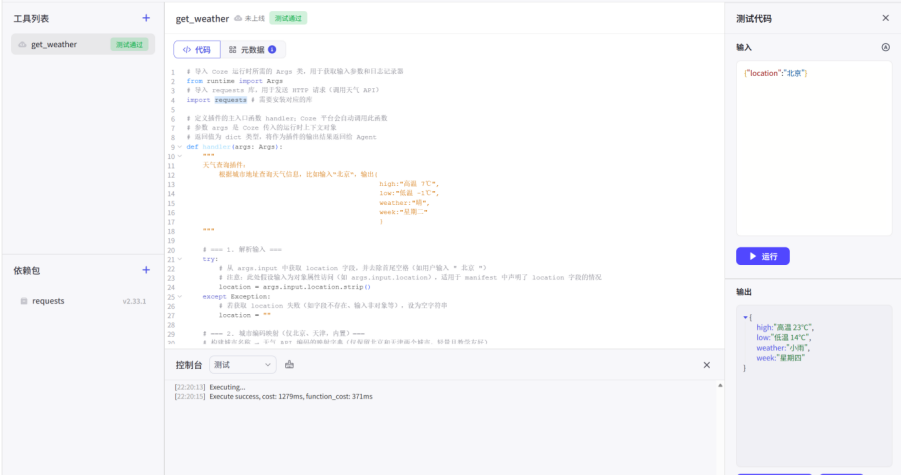
可以看到非常完美没有问题,星期四是测试当天的日期
这个源码只有北京和天津的数据,如果需要别的地区需要自主添加
好的测试通过我们就发布
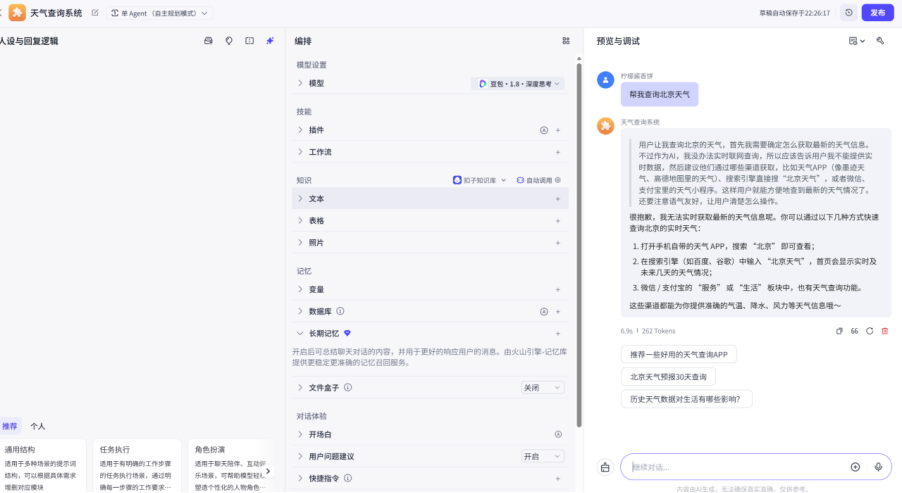
随后再创建一个智能体来调用一下
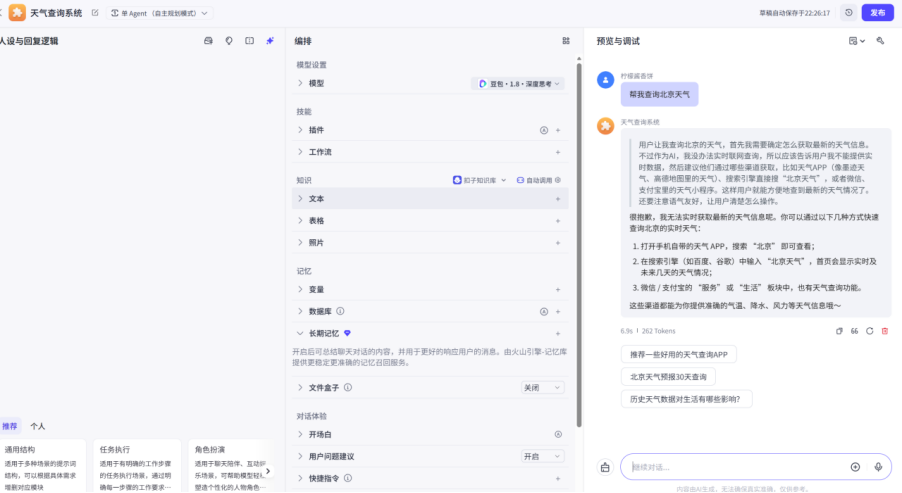
首先可以看到没有插件的智能体无法查询
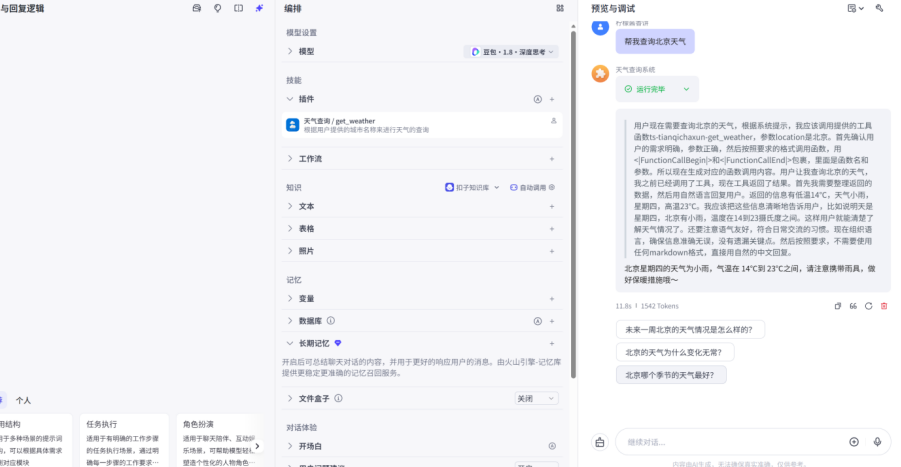
安装插件之后,智能体就成功调用了并返回了结果
将一个复杂的任务分解成一系列可管理的,按顺序或按条件执行的步骤,并通过图形化界面将这些步骤连接起来,有两种形式:对话流和工作流
节点是工作流的核心组件,每个节点是一个具有特定功能的独立组件,负责处理数据,执行任务
不同的节点有不同的功能,比如流程控制,能力调用,数据处理等等
我们就是要将这些不同功能的节点连接起来,从而精确的控制数据流向和任务执行顺序.实现复杂的业务逻辑
工作流常见的四种形式:
- 多步骤任务
特征:需要按顺序执行多个操作
案例:生成行业分析报告
步骤:搜索资料、提取信息、整理成文、格式化输出
- 条件分支
特征:根据不同情况走不同路径
案例:智能客服分流
步骤:判断问题类型、选择处理方式、返回结果
- 批量处理
特征:对多个对象执行相同操作
案例:批量生成图片
步骤:读取提示词列表、逐个生成图片、汇总输出
- 数据转换
特征:多环节的数据清洗与加工
案例:表格数据分析
步骤:读取数据、清洗格式、计算统计、可视化呈现
Step 1:创建工作流
操作路径:资源库 → +资源 → 工作流
设置内容:
工作流名称(清晰明确)
功能描述(帮助AI理解)
Step 2:编排工作流
核心操作:
在可视化画布中添加节点
连接节点形成数据流
配置每个节点的输入输出参数
设置内容:
开始节点 → LLM节点 → 插件节点 → 结束节点
Step 3:测试并发布
测试方法:点击测试按钮 → 输入测试数据 → 检查节点状态
发布流程:
测试通过后点击发布
发布后其他用户可以使用该工作流
核心功能设计:
- 智能意图识别
- 知识库智能检索:
命中相关内容->基于内容回答
未命中相关内容->基于通用知识回答
工作流程:
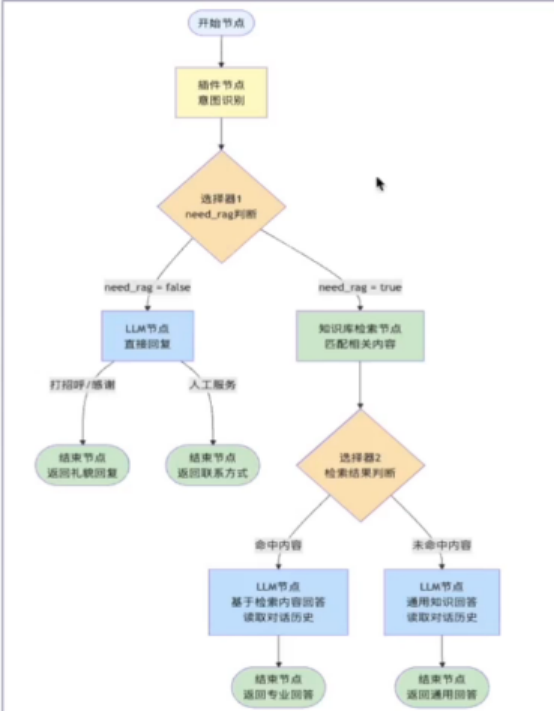
接下来开始进行创建,流程还是和之前一样
可以看到这个智能体我们选择了对话流的模式,界面与之前有所不同
未配置对话流他是无法工作的
我们选择创建对话流
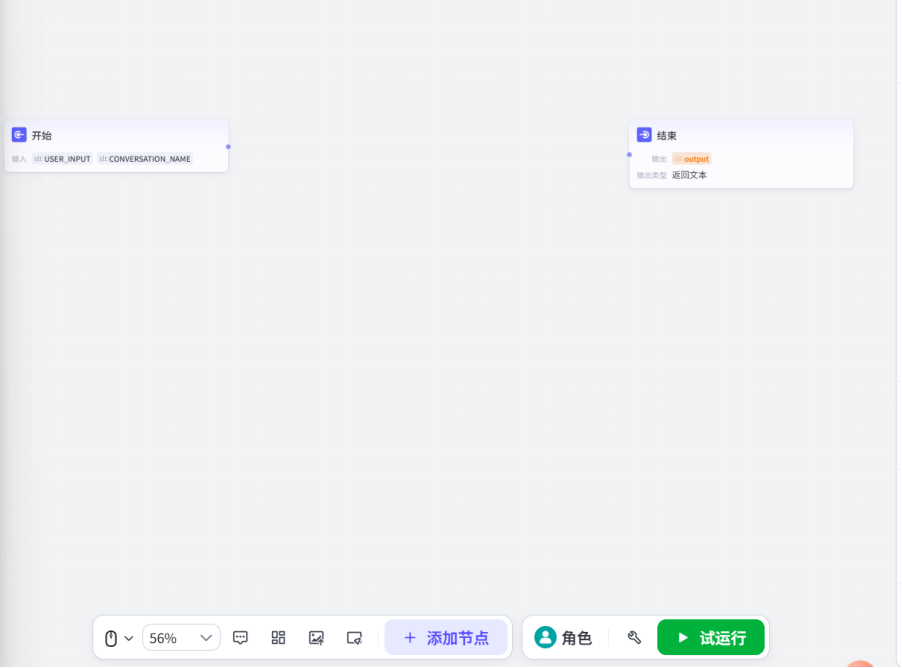
之后我们进入这个界面,可以看到默认就有两个节点
开始节点中有用户输入和对话名称,这个不是重要的,重要的是我们的意图识别,作为一个客服,用户无非就三种常见需求,打招呼,找人工,问问题
他问问题时,我们才去进行RAG检索
那怎么去做这个意图识别呢
我们就需要去添加插件节点,其中的主要插件由我们自己定义
我们将鼠标放在下方添加节点,选择插件,然后创建插件,他会进入到我们的资源库,我们创建插件的流程与之前一样
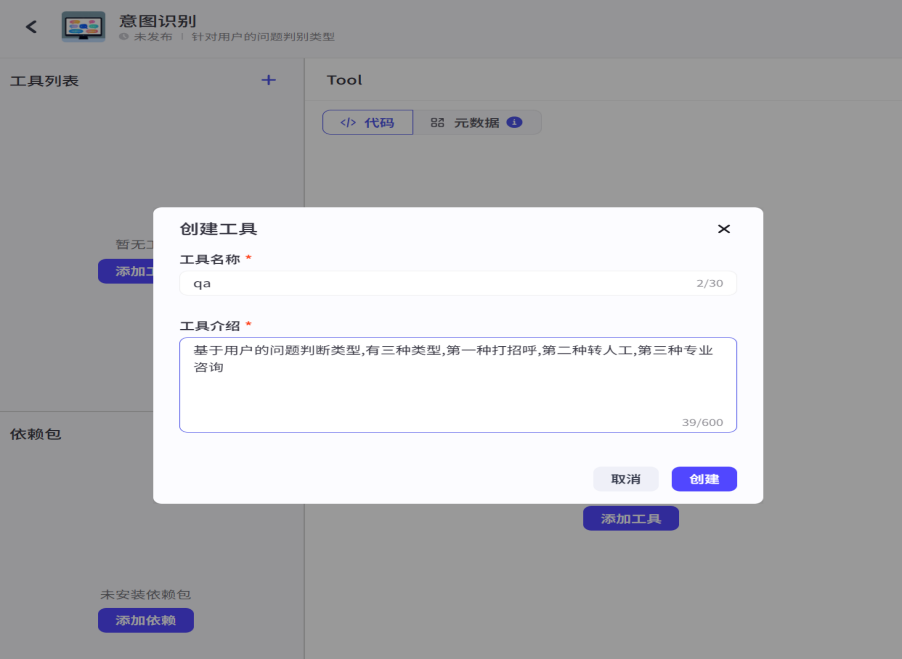
注意元数据的部分要定义好
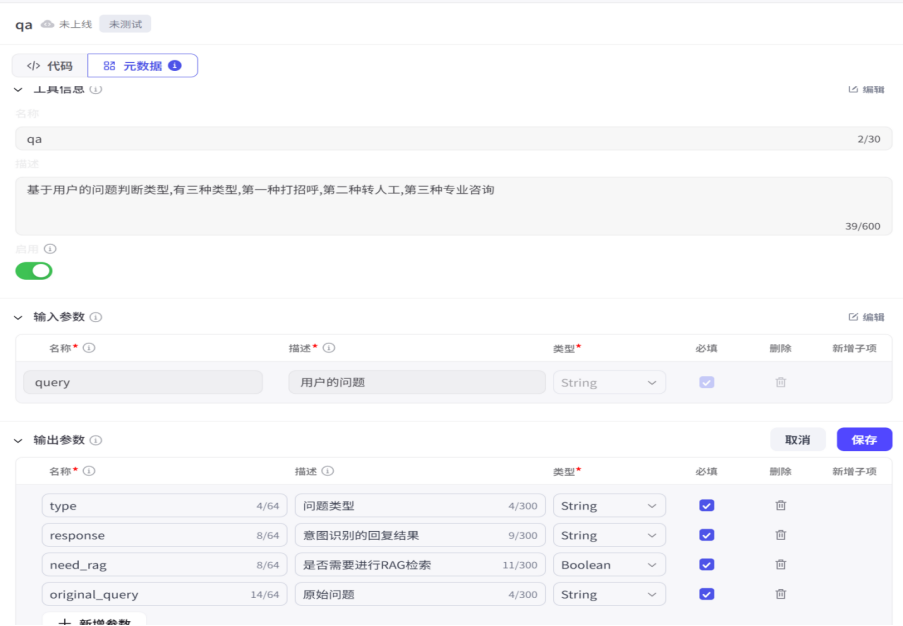
随后将代码进行测试,其实这种意图识别我们利用大模型来做会好一些,不过这也只是为了熟悉流程,我们测试完毕之后就可以发布,对应的代码我会一并发在群里
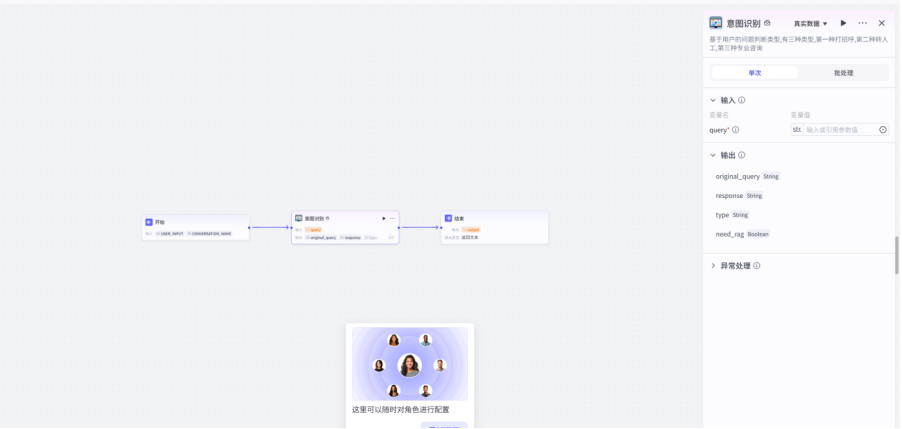
接下来将插件添加,我们在拖拉拽操作之后呢,要对意图识别节点的输入进行一个定义,选择的是开始节点的用户输入部分,同样的结束节点也需要定义,定义为识别的回复结果部分
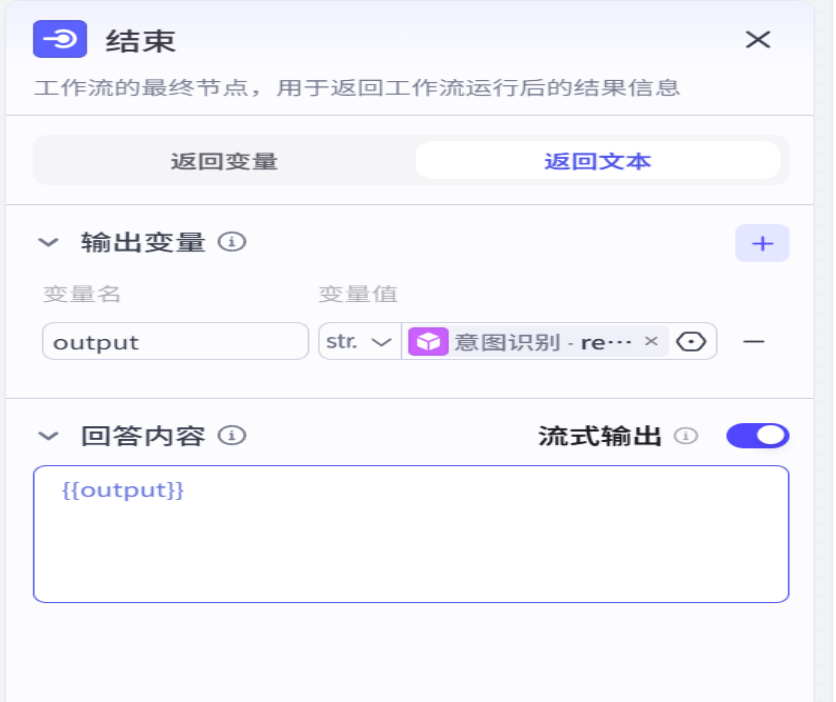
添加完毕后,我们试运行
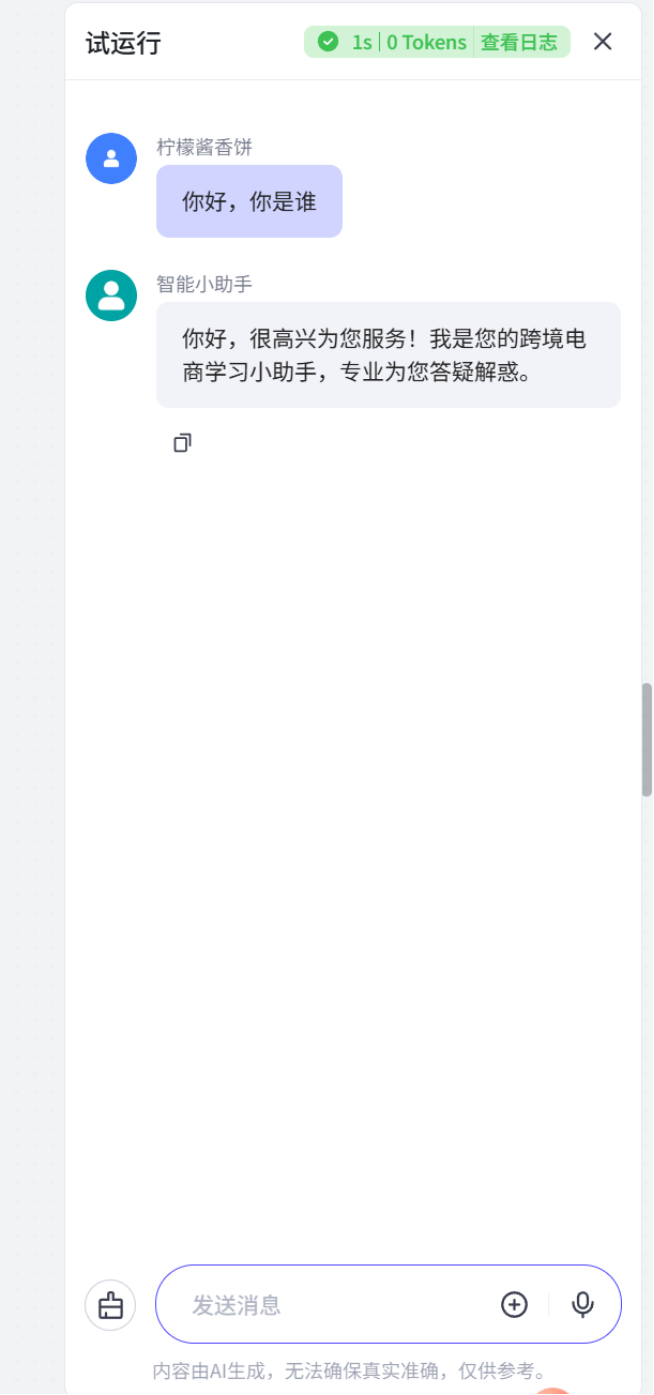
可以看到,这个对话流已经建好了
接下来我们进行知识库的构建,去实现RAG检索
根据前面所说,我们的意图识别可能会有三种结果,所有我们要添加一个选择器节点,去分析是否需要进行RAG检索
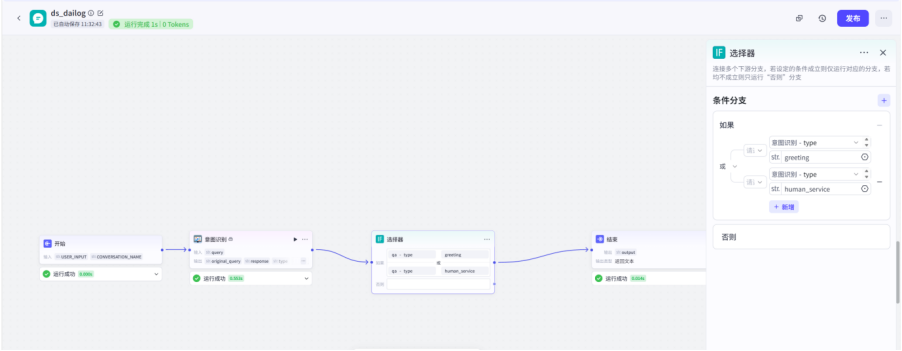
同样的,选择器的输入也需要定义,我们是判断问题的类型,类型的名称要与插件中定义的一致
接下来我们先添加一个知识库检索节点,再去创建我们对应的知识库
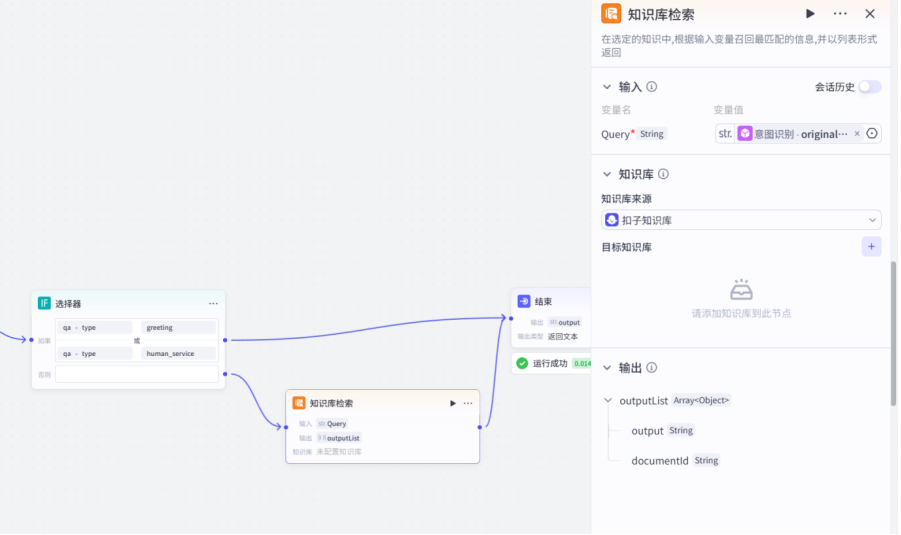
注意这里要选择的输入是原始问题
接下来创建知识库
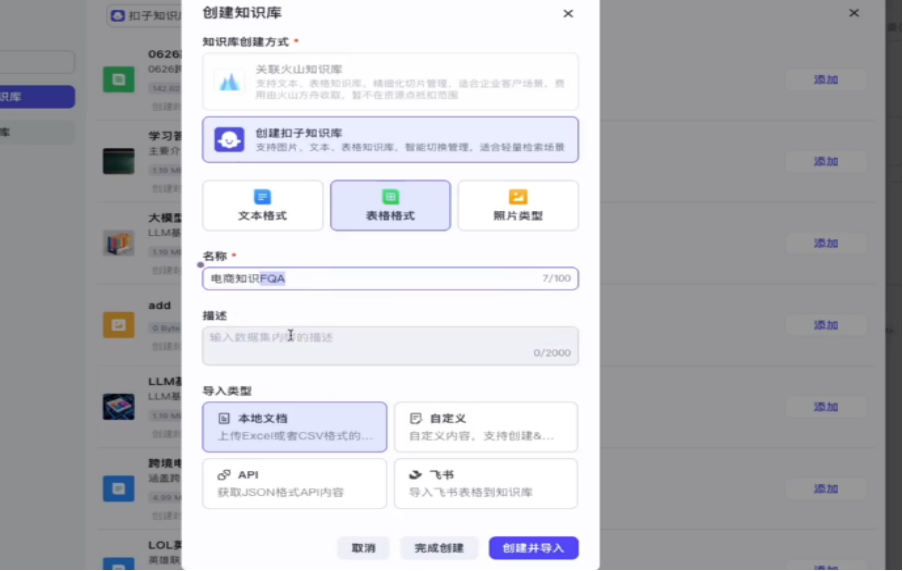
选择表格形式
导入完之后,我们需要勾选一下question这个部分的内容,这个勾选是用于与用户问题检索的
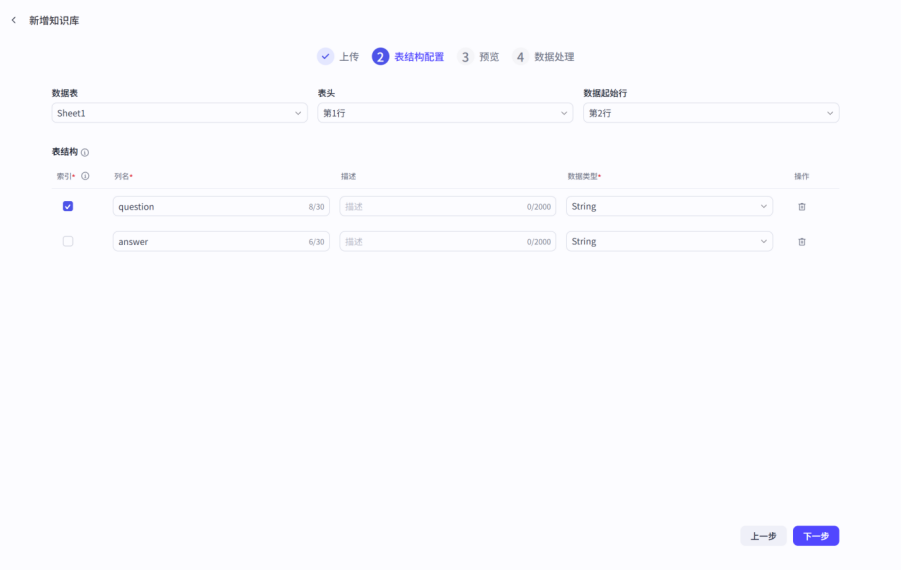
随后下一步,等待数据处理完毕
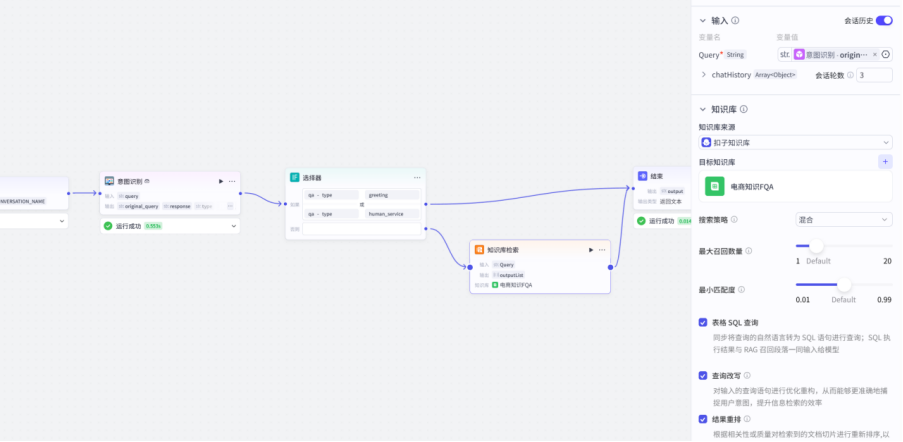
这样我们就基本完成,下一步就是需要一个大模型来处理我们的信息最后输出,但是给大模型处理前呢,我们还需要进行一个判断,那就是知识库能不能检索出答案,如果可以就将问题和上下文一起给大模型
如果不能,直接把问题丢给大模型,那么这里就又需要一个选择器
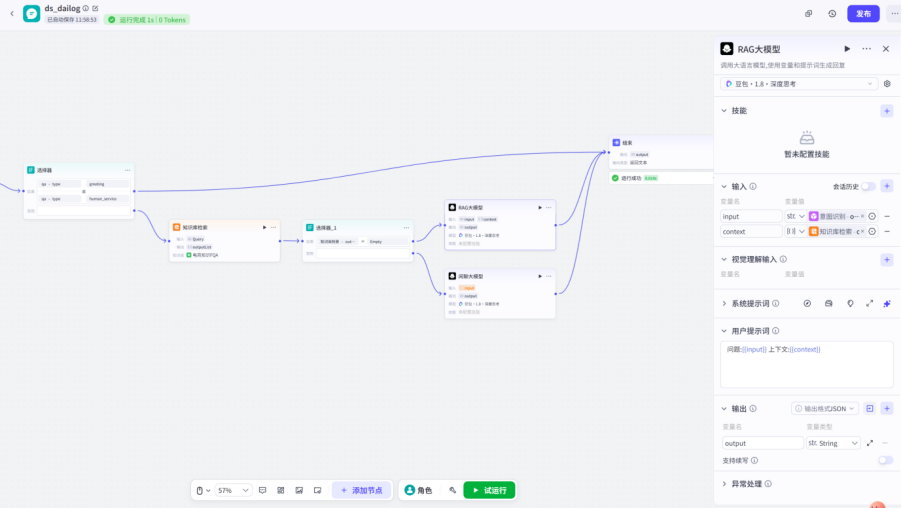
随后对模型进行处理,确定输入以及系统提示词,还有用户提示词
最后改变一下结束节点的输出变量
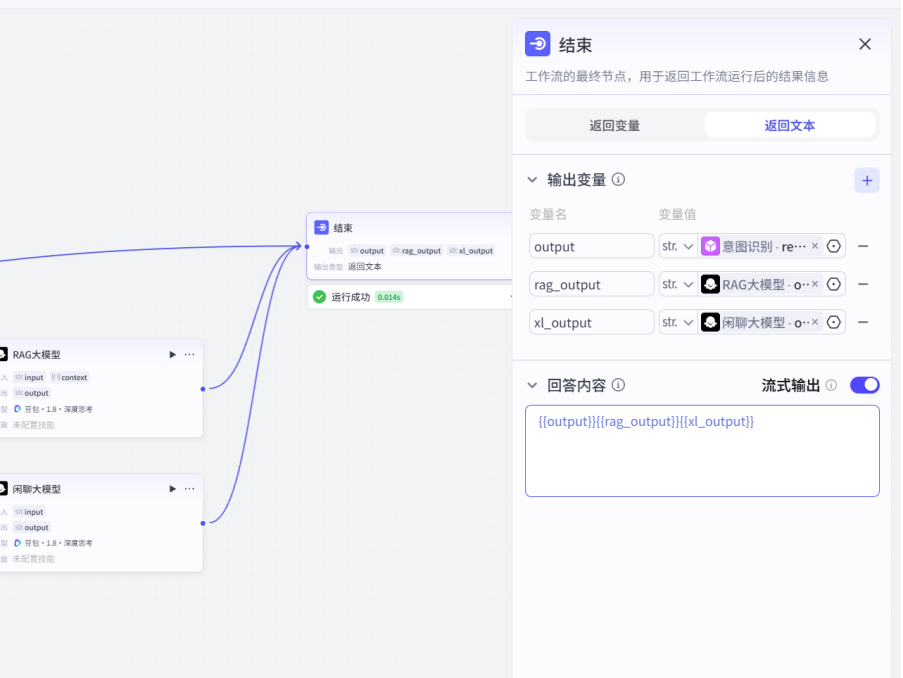
把所有回答都进行设置
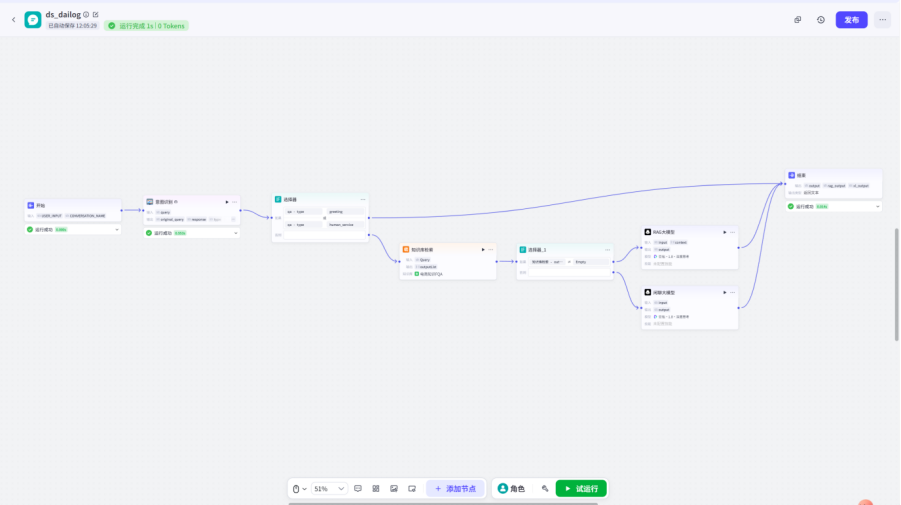
现在,整个跨境电商助手的对话流agent已经基本完成
整体预览:
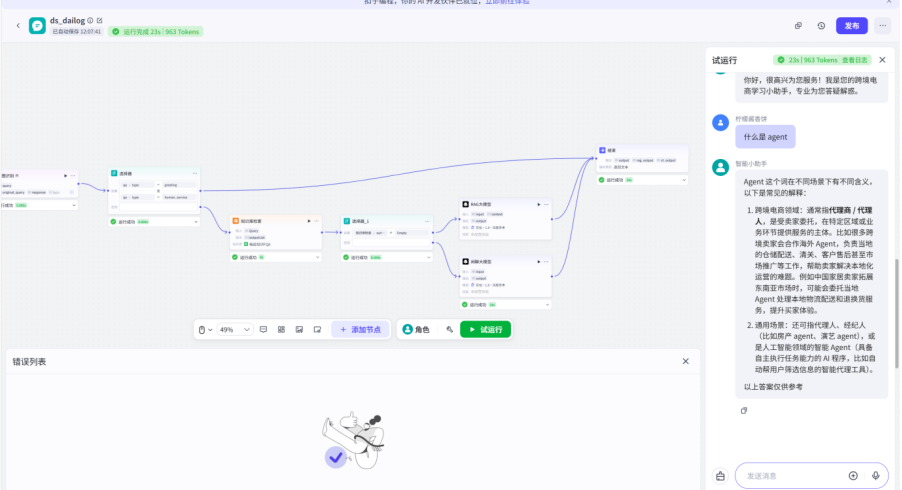
效果演示:
最后我们发布,再添加到我们的智能体中
到此,Coze平台大部分功能已经学习完毕
第一次写博客,如有不足欢迎指正
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/271589.html