
Superpowers - 01 让 AI 真正“懂工程”:Superpowers 软件开发工作流深度解析
Superpowers - 02 用 15 个技能给你的 AI 装上「工程大脑」:Superpowers 快速开始深度解析
Superpowers - 03 一文搞懂 Superpowers:面向多平台 AI 编码助手的安装与实践指南
Superpowers - 04 从“会写代码”到“会做工程”:Superpowers 工作流引擎架构深度剖析
Superpowers - 05 构建一个“会自己找插件用”的 Agent:深入解析 Superpowers 的技能发现与激活机制
Superpowers - 06 从文档到“结构契约”:Superpowers 技能剖析与 Frontmatter 深度解读
Superpowers - 07 从 SessionStart Hook 看 Superpowers:把「技能库」变成「行为操作系统」
Superpowers - 08 在 AI 时代重写「需求评审会」:深入解读 Superpowers 的头脑风暴与设计规范机制
Superpowers - 09 从构思到落地:如何用「计划编写与任务粒度」驾驭 AI 时代的软件开发
Superpowers - 10 用 Subagent 驱动开发,把「AI 写代码」变成一条严谨的生产流水线
Superpowers - 11 从计划到落地:深入解析 Superpowers 的「内联执行计划」工作流
Superpowers - 12 没有失败测试,就没有生产代码:从 Superpowers 看“铁律级”测试驱动开发
Superpowers - 13 系统化调试:用一套“四阶段流程”终结瞎猜式修 Bug
Superpowers - 14 从「尽早审查、频繁审查」到系统化流水线:Superpowers 代码审查工作流深度解析
Superpowers - 15 用 Git Worktrees 打造“无尘室”开发环境:从 Superpowers 实践谈起
Superpowers - 16 用好「finishing-a-development-branch 」这最后一步:从混乱收尾到可复用的工程化流程
面向读者:AI 应用开发者、提示词工程/Agent 工程从业者、技术负责人,以及希望用 LLM 标准化团队流程的开发者。
在很多团队里,「技能(skill)」这个词还停留在比较模糊的层面:要么是几行提示词,要么是一段散落在 Wiki 或 README 里的经验总结。 但在 Anthropic 超能力(superpowers)体系里,「自定义技能」被提升到了与代码同等级别的工程工件:它们要可发现、可复用、可测试,甚至要遵守测试驱动开发(TDD)的铁律。
这篇文章基于 Anthropic 官方的「Writing Skills」技能以及相关**实践文档,系统拆解:如何把「写技能」当成一项严肃的软件工程活动来做。 如果你正在为 Claude、其他 LLM 或自研 Agent 系统设计技能体系,这篇文章可以作为端到端的实践指南。
在超能力系统里,自定义技能是这样的东西:
- 它不是一次性提示,而是封装了技巧、思维模型、参考文档的「知识工件」;
- 它被存放在
skills/目录下,以SKILL.md为核心入口,可以附带脚本、长文档等支持文件; - 它的直接用户不是人,而是未来的 Claude 实例:Claude 需要通过搜索、匹配、读取这些技能来指导自己的行为。
换句话说,一个好的技能应该能做到:
- 当 Claude 遇到某类问题时,能主动「想到」这份技能;
- 读完技能后,行为发生明显改善且可复现;
- 新的 Agent / 新的对话会话中,仍能被发现并正确应用。
「编写技能就是将测试驱动开发(TDD)应用于流程文档。」
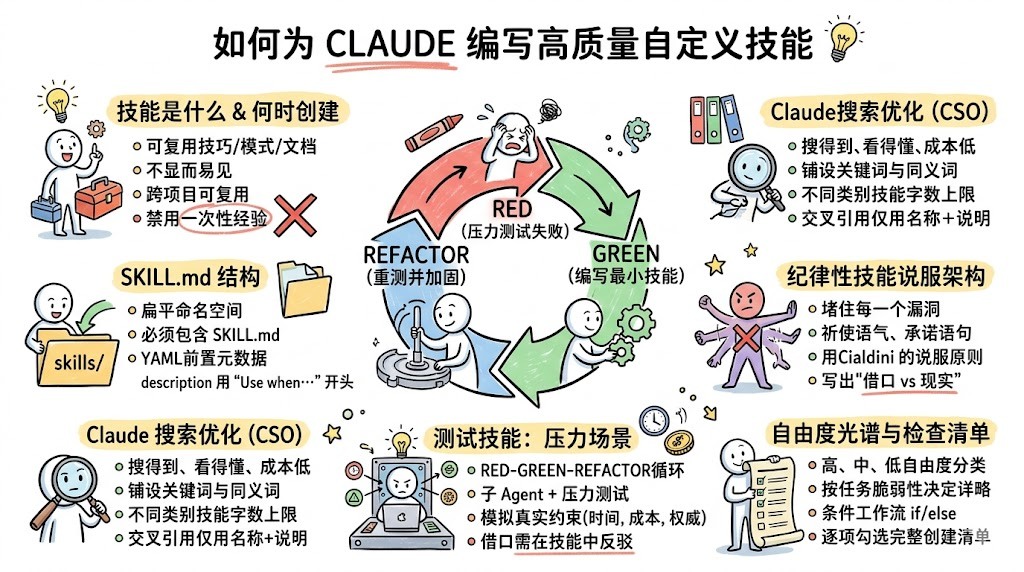
- RED:在「没有这个技能」的前提下,让 Agent 在高压场景里任务失败,观察其错误和借口;
- GREEN:基于这些失败,写一份「最小化技能」,只解决观察到的问题;
- REFACTOR:继续在更高压力下测试,收集新的借口,并在技能中逐条封堵。最终达到「无懈可击」。
这里有两个非常重要的含义:
- 如果你没看见 Agent 在没有技能时是如何失败的,你根本不知道这项技能是否真正起作用。
- 「先写技能再测试」和「修改技能后不重测」都被视为违背 TDD 的工程纪律。
- 技巧(techniques)更像是「可操作的食谱」,例如调试某类问题的步骤。
- 模式(patterns)是抽象的思维框架,例如如何用不变式思考系统测试。
- 参考(reference)则是「字典」,比如 PPTX 操作 API 的集中说明。
不是所有洞察都值得升格为技能, 一个明确的 heuristics:
应该写成技能的场景:
- 这个技巧/模式对你来说并非直觉,你也希望未来的自己或其他 Agent 能重复使用;
- 它会在跨项目被反复引用;
- 它的适用范围足够广,不局限于某个项目或业务;
- 其他 Agent 或团队成员也能从同一份指导中受益。
不应该写成技能的场景:
- 只是某次事故/调试的「故事」;
- 已有权威文档可用(例如标准语言/框架文档),不需要再复制一份;
- 项目特定约定,更适合写在项目的
CLAUDE.md或 README 中; - 完全机械、可由自动化/校验工具来保证的约束(如固定格式的 Lint 规则)。此时应写工具/脚本,而不是写技能。
这背后是一个关键原则:技能要服务于「需要判断力和推理」的场景,而不是替代自动化或复读已有文档。

超能力仓库中,所有技能都放在 skills/ 目录下,采用扁平的命名空间,每个技能至少包含一个 SKILL.md:
skill-name/SKILL.md:必需,作为主要参考入口;skill-name/supporting-file.*:仅在需要时存在,如可复用脚本、超过 100 行的长参考材料。
根据内容规模和形式,组织模式大致有三种:
- 自包含技能:所有内容都写在 SKILL.md,例如
defense-in-depth/; - 带可复用工具的技能:SKILL.md + 一个或多个支持工具脚本,例如
condition-based-waiting/; - 带繁重参考的技能:SKILL.md + 长篇 API 文档或脚本,例如
pptx/。
这里的关键设计思想是:渐进式披露(progressive disclosure)。
- Claude 在判断某个技能是否相关时,优先只加载
SKILL.md; - 只有在明确需要时,才会进一步读取支持文件;
- 如果引用层级太深(SKILL.md → advanced.md → details.md),Claude 会倾向于用
head -100之类的「部分读取」,导致关键信息被截断。
这意味着:
- 尽量让重要语义集中在
SKILL.md; - 支持文件层级最多一层,避免多级嵌套;
- 引用支持文件时,要假设它们可能不会被完整读完——关键逻辑不要藏在第 200 行以后。
每个 SKILL.md 顶部有一段 YAML frontmatter,至少包含两个字段:
name 仅限字母、数字、连字符;不允许括号或特殊字符 标识与交叉引用
description 必须以 “Use when…” 开头;使用第三人称;建议 < 500 字符 被 Claude 用来判定是否加载技能
总长度(包括 name 和 description)限制在 1024 字符以内。
这里尤其要强调:description 是整个技能中最重要的一行,它只回答一个问题——
「Claude 现在应该阅读这份技能吗?」
几个对比示例:
- ❌
description: Use when executing plans - dispatches subagent per task with code review between tasks
→ 太抽象,没有明确触发条件,还提前暴露工作流细节。
- ✅
description: For async testing - ✅
description: Use when tests have race conditions, timing dependencies, or pass/fail inconsistently
经验结论是:当 description 企图总结整个 workflow 时,Claude 会「只看这一行就凭想象执行」,从而跳过完整正文。
所以 description 应重点描述「触发条件(when)」而不是「怎么做(how)」。
一套推荐的 SKILL.md 模板结构:
* name: Skill-Name-With-Hyphens description: Use when [specific triggering conditions and symptoms] * # Skill Name # Overview 用 1-2 句话说明这是什么、解决什么问题。 # When to Use - 何时使用(可以在这里用小型内联流程图表示决策) - 典型症状和用例 - 何时不该使用 # Core Pattern (for techniques/patterns) - 修改前/修改后的代码对比,或者核心操作步骤 # Quick Reference - 适合快速浏览的表格或要点列表 # Implementation - 简单场景用内联代码/示例 - 复杂逻辑指向支持文件 # Common Mistakes - 容易犯错的地方及修复方法 # Real-World Impact (optional) - 真实场景中的收益、效果 其设计目标很明确:服务于 Claude 的「快速发现 → 快速扫描 → 精准执行」流程:
- 通过 description 判断是否应该加载技能;
- 略读 Overview 看是否匹配当前问题;
- 在 Quick Reference 里快速找到相关模式或步骤;
- 真正执行时再读 Implementation 和示例。
从人的视角来看,这也非常符合技术文档写作的好习惯:先说明「是什么」「何时用」再给「怎么做」「容易错」。
传统 SEO 是面向搜索引擎用户;CSO(Claude Search Optimization)则是面向未来的 Claude 实例:让技能在真实对话中更容易被搜索到、被判定为相关。
Claude 会用用户对话中的语言去搜索技能,因此技能文本里需要有策略地埋入可搜索关键词。
建议从四类关键词入手:
"Hook timed out",
ENOTEMPTY,
race condition 描述、概述 症状
flaky,
hanging,
zombie,
pollution When to Use、描述 同义词
timeout/hang/freeze,
cleanup/teardown/afterEach 正文各处 工具 实际命令、库名、文件类型 Implementation 部分
实践含义是:写技能时,不要只写抽象术语,要把开发者真实会说出口的报错、症状、口语化描述放进去。
上下文窗口是稀缺资源,技能中的每个 token 都在和对话历史、其他技能元数据竞争。
配套的优化策略包括:
- 细节说明挪到工具的
--help或脚本注释里; - 通过交叉引用其他技能来避免复制同样的工作流描述;
- 精简示例数量,优先留下质量最高的一两个示例;
- 使用
wc -w skills/path/SKILL.md等命令主动检查篇幅。
很多人会习惯在 Markdown 里直接用 @path/to/file 来做引用,但这里强烈不推荐这么做:
@skills/.../SKILL.md会强制立即加载那个文件,可能瞬间占掉 20 万个 token 的上下文。- 更好的做法是只提及技能名称,再用显式「必需子技能」的形式提示,例如:
REQUIRED SUB-SKILL: Use superpowers:test-driven-development。
有一类技能非常特殊:它们专门用于强制某种行为规则,例如 TDD、完成前验证(verification-before-completion)等。
对于这类技能,仅仅写清楚「流程」是不够的,因为:
- Agent 具有一定的自主推理能力,会在时间压力、上级指令、沉没成本等因素下,为「不遵守规则」寻找看似合理的借口;
- 如果技能没有预判并封堵这些借口,最终的执行效果会非常差。
为此,Anthropic 引入了 Cialdini 的七大说服原则,并在 2025 年、28000 次对话实验中验证了其对 LLM 合规率的影响——从 33% 提升到 72%。
在实践中,这意味着写纪律性技能要更「强硬」,用明确的命令式语气、零容忍例外,且经常以 checklist 和红旗(Red Flags)形式出现。
为了系统对抗合理化,四个加固动作:
- 显式禁止各种变通方式
示例对比非常直观:
- 脆弱版本:
Write code before test? Delete it. - 加固版本:
逐条点名常见借口:保留作参考、边写测试边改、只看不改等。Write code before test? Delete it. Start over. No exceptions: - Don't keep it as "reference" - Don't "adapt" it while writing tests - Don't look at it - Delete means delete
- 脆弱版本:
- 一条原则切断「字面 vs 实质」争论
在 TDD、完成前验证等技能里增加一条基础原则:
「违反规则的字面意义就是违反规则的实质精神。」
这直接堵住了「我虽然没按步骤做,但精神上是遵守的」这类辩解。
- 构建「借口 vs 现实」对照表
把在 RED 阶段观察到的每个借口都写进表格,并给出直截了当的反驳,例如:
借口 现实 “Too simple to test” 简单代码一样会出错,测试只要 30 秒。 “I’ll test after” 测试后置无法保证正确行为,只是事后解释。 “Tests after achieve same goals” 测试后置 = 「这段代码是干什么的?」;测试前置 = 「这段代码应该干什么?」 - Red Flags:一看到就要「停下重来」的信号
使用类似这样的片段:
# Red Flags - STOP and Start Over - Code before test - "I already manually tested it" - "Tests after achieve the same purpose" - "This is different because..." All of these mean: Delete code. Start over with TDD.让 Agent 在高压状态下仍然有一个极其简单的「自查触发器」。
「测试不是可选项,而是技能架构的基础。」
对每个技能,都必须经历:
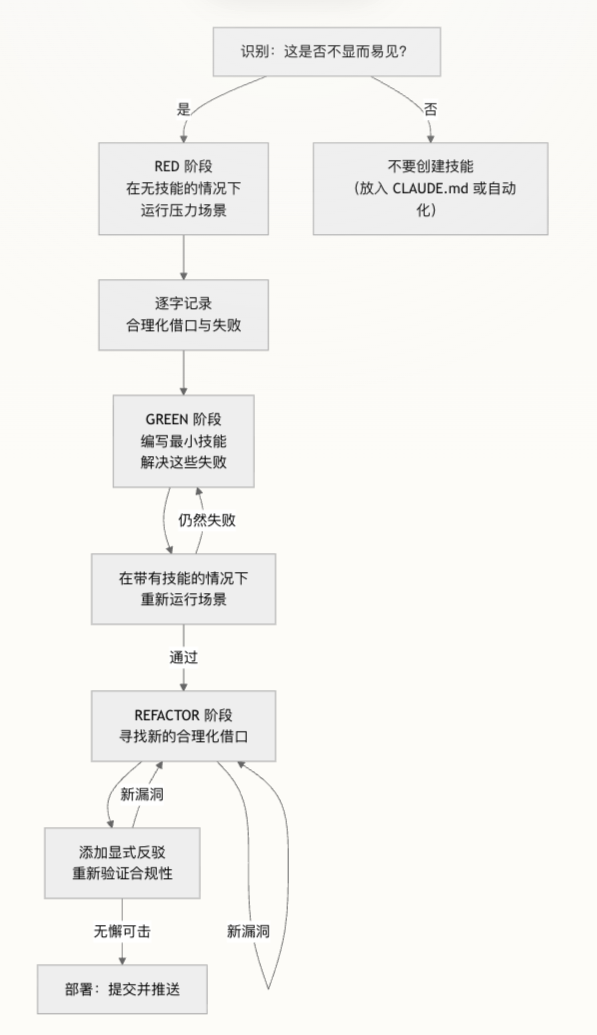
- RED:在没有技能的情况下运行压力场景,记录失败模式和借口;
- GREEN:写最小技能,解决这些明确失败,再带技能重跑场景;
- REFACTOR:加入更多压力组合,捕获新的合理化方式,将其写进技能(规则、借口表、红旗列表、keywords 等)并再次重测,直至「无懈可击」。
根据技能类型的不同,测试重点有所区别:
好的压力场景至少要同时包含几个真实约束:
- 时间压力:紧急上线、部署窗口即将关闭;
- 沉没成本:已经写了大量代码,回头重来意味着「浪费」;
- 权威压力:资深同事/上级要求「先上线再说」;
- 经济/职业压力:项目失败可能影响公司生死或个人晋升;
- 疲劳:已是加班深夜,只想赶紧收工;
- 社交压力:坚持流程看起来很「教条」;
- 实用主义:自我辩解「现实一点,不要教条」。
设计原则包括:
- 强迫具体选择(A/B/C),不要问太抽象的「你觉得应该怎么办」;
- 使用实际路径/项目名,而不是泛泛的「某个项目」;
- 让 Agent 真正做出行动决策,而不仅仅是「说明正确答案」。
所有在 RED 阶段出现的合理化借口必须在 REFACTOR 阶段被处理——要么写进规则,要么写进借口表/Red Flags,要么作为 CSO 关键词出现。绝不允许有一个借口「悬空」。
Anthropic 官方文档提出了一个非常实用的概念:自由度(degree of freedom)。
一个形象比喻:
- 两侧是悬崖的窄桥 → 需要坚固护栏(低自由度);
- 广阔平地 → 给大致方向即可(高自由度)。
换到技能设计里:越脆弱的任务,技能越要写得「死」;越开放的问题,技能越要保留判断空间。
在具体写作层面,可以组合使用三种内容模式:
- 模板模式(templates)
- 适合输出格式(报告、邮件、PR 描述等);
- 根据自由度设置严格程度:有的字段强制要求,有的可以选填。
- 示例模式(examples)
- 对质量敏感的输出,最好给一个「完整、真实、可运行」的示例;
- 一个高质量、贴近真实的单语言例子,远比多个平庸、多语言示例有用。
- 条件工作流模式(conditional workflows)
- 当存在决策分支时,用清晰的条件引导 Agent;
- 类似「如果 A,则走路径 X;否则如果 B,则走路径 Y」。
针对代码示例,有一个非常重要的经验:不要为了「覆盖更多语言」而牺牲质量。 Claude 自身具备相当的语言迁移能力,你只要选一个领域最相关的语言写好例子即可,比如:
- 测试技巧 → TypeScript
- 系统调试 → Shell/Python
- 数据处理 → Python。
流程图是把双刃剑:一方面可以清晰呈现决策路径,另一方面消耗大量 token,且维护成本高。
只在以下场景使用流程图:
- 存在非显而易见的决策点,且容易出错;
- 存在可能「提前退出」的流程循环,需要明确何时继续、何时停止;
- 需要在 A/B/C 方案间作选择,且条件复杂。
不要在以下场景使用流程图:
- 纯参考性信息(用表格/列表即可);
- 代码示例(用 Markdown 代码块更易复制与阅读);
- 简单线性流程(用有序列表即可);
- 标签没有语义,仅是
step1、helper2等。
为了更容易理解流程图,还可以定义一套 Graphviz 形状语义约定:
- 菱形(diamond):问题或条件判断;
- 方框(box):操作;
- 椭圆(ellipse):状态或开始/结束;
- 纯文本节点:命令或简单说明;
- 八边形(红色填充):警告节点;
- 双圆圈:入口/出口点。
这种统一的视觉语言能显著降低理解成本,也利于在多个技能之间复用相似的流程图风格。
「反模式清单」,这些做法会积极损害技能质量:
example-js.js、
example-py.py、
example-go.go 各语言都平庸,维护负担巨大 在流程图中写代码
step1 [label=“import fs”] 无法复制粘贴,难以阅读,浪费 token 泛泛的标签
helper1、
step3 无语义信息,理解困难 把工作流塞进 description
description: dispatches subagent per task… Claude 会直接按描述执行而跳过正文 深度嵌套引用 SKILL.md → advanced.md → details.md 促使 Agent 部分读取,丢失关键信息 写时效性信息 「在 2025 年 8 月前使用旧 API」 快速过期,污染技能 术语不一致 URL/API route/path/endpoint 混用 概念模糊,降低理解和执行精度
从 RED → GREEN → REFACTOR 到最终部署,大致需要确认以下事项(节选):
- 已针对目标场景设计压力场景,纪律性技能至少包含 3 种以上压力组合;
- 已在无技能情况下运行场景,并逐字记录失败和借口;
- YAML 前置元数据已配置好:符合命名规则、
description以Use when…开头,且不包含工作流摘要; - 技能正文中已埋入关键搜索关键词(错误信息、症状、同义词、工具);
- 至少有一个高质量示例(而非多个平庸、多语言示例);
- 已在带技能的情况下重跑场景,并验证合规性;
- 已构建合理化借口表和 Red Flags 列表,并将其纳入技能正文;
- 有 Quick Reference 表和 Common Mistakes 部分;
- 无叙事性故事,无时效性信息,术语统一;
- 仅在确有必要时使用流程图,且遵循 Graphviz 约定;
- 所有测试通过后,才提交到 Git 并推送。部署未经测试的技能 = 部署未经测试的代码。
将整个「编写自定义技能」的实践串起来,可以看到一个非常清晰的转变:
- 技能不是一次性提示,而是长生命周期的工程工件:需要命名规范、目录结构、测试和版本控制;
- 写技能的过程本身就是 TDD:一定要先看见失败,再写技能,最后用压力测试证明它真的起作用;
- 真正难的是对抗「合理化借口」:你要像防御性编程那样,预判每一种规避、偷懒、打折执行的路径,并用规则、表格、红旗逐一封堵;
- 技能需要强 CSO 意识:写的时候就要想到「未来的 Claude 会用什么词来搜到我」,从而在语料中埋下合适的错误信息、症状和同义词;
- 自由度设计直接决定可用性:有些场景必须「写死」,有些场景则要留给 Agent 自主发挥,关键是根据任务脆弱性选择合适的粒度。
如果你正在构建基于 Claude 或其他大模型的工程化工作流,可以尝试从一个具体场景出发(例如「后端服务的 TDD 规范」、「生产变更流程」),按照本文的思路设计一个完整技能:
- 用 RED-GREEN-REFACTOR 观察 Agent 如何在没有技能时失败;
- 在
skills/下创建一个带有高质量SKILL.md的技能目录; - 按推荐模板写 Overview/When to Use/Core Pattern/…;
- 用子 Agent 压力测试,把所有借口塞进借口表与 Red Flags;
- 对照「完整创建清单」逐项勾选,最后再部署到团队的技能库中。
当你第一次看到「有技能」与「无技能」两个 Agent 在同一压力场景下表现的巨大差异时,你大概率会认同:写技能,确实值得像写一段关键业务代码那样严肃对待。

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/271177.html