
大家好,我是二哥呀。
最近一直在琢磨一个问题:怎么让 Agent 更丝滑地操作浏览器。
之前给大家提过 Chrome Devtools MCP——体验下来就很不错。
https://paicoding.com/article/detail/10720
除此之外,很多 Agent 都内置了 Puppeteer、Playwright、browser-use 这些工具。
但本质上还是通过截图 → 识别 → 点击这个流程来完成的。token 烧得快,响应还慢。
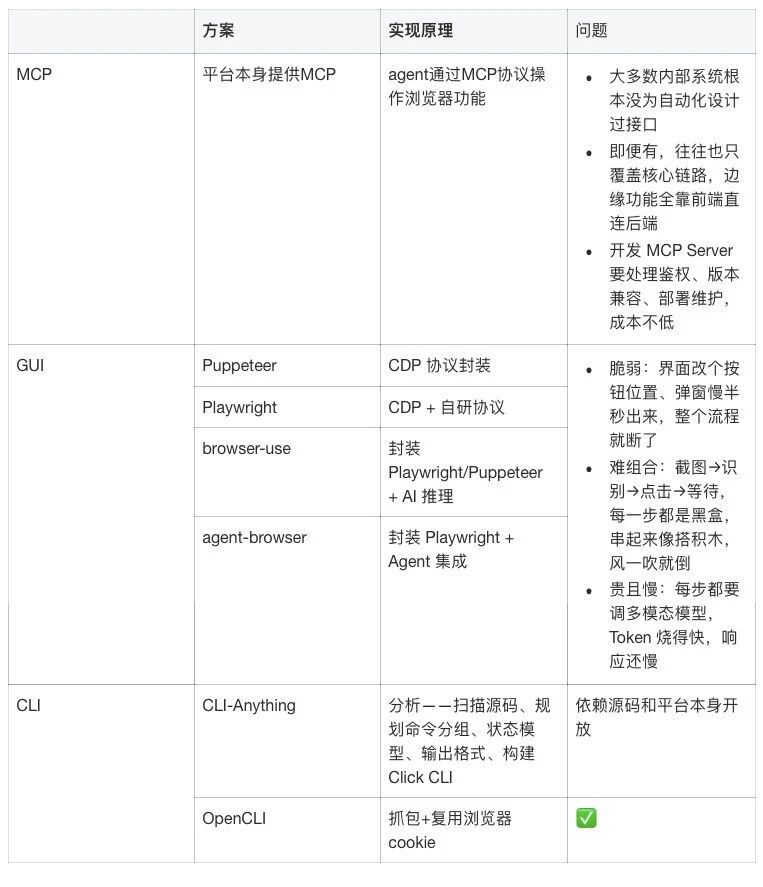
OpenCLI 的思路完全不一样——不走 MCP,不搞 GUI 自动化。走的是把网站的 API 接口抓出来,封装成确定性的 CLI 命令。
我体验了一下,确实有点东西。
OpenCLI 的 slogan 是“Make Any Website & Tool Your CLI”——把任意网站和工具变成你的命令行。核心理念就一句话:别让 LLM 去操作网页,让 CLI 去调接口。
GitHub 地址:https://github.com/jackwener/opencli
从 3 月 14 号发布 v0.1.0 到现在 v1.7.3,一个月时间迭代了 80 多个版本,在 AI 的加持下,现在的代码迭代是真的猛。
传统的 GUI 自动化是让 AI 看截图、点按钮、填表单,每一步都要调用视觉模型。OpenCLI 的思路是:网页上看到的所有数据,背后都有 API 接口在返回。我不去操作界面,直接调接口拿数据,跳过整个 GUI 层。
就像你想知道二哥的狗腿子是谁,GUI 自动化是教一个人打开 Chrome、跳转到百度搜索、输入关键词、截图、用 OCR 识别文字;OpenCLI 是直接调搜索 API,一个 HTTP 请求搞定。
安装很简单,直接在 Agent 中输入下面的提示词:
查看 https://github.com/jackwener/opencli 然后安装,告诉我如何使用。 
装完之后要在 Chrome 打开 chrome://extensions,开启“开发者模式”,点“加载已解压的扩展程序”,选择 Chrome/Chromium 的 unpacked 目录,Agent 已经帮我们下载解压到这个目录了。
选择后就可以看到了。
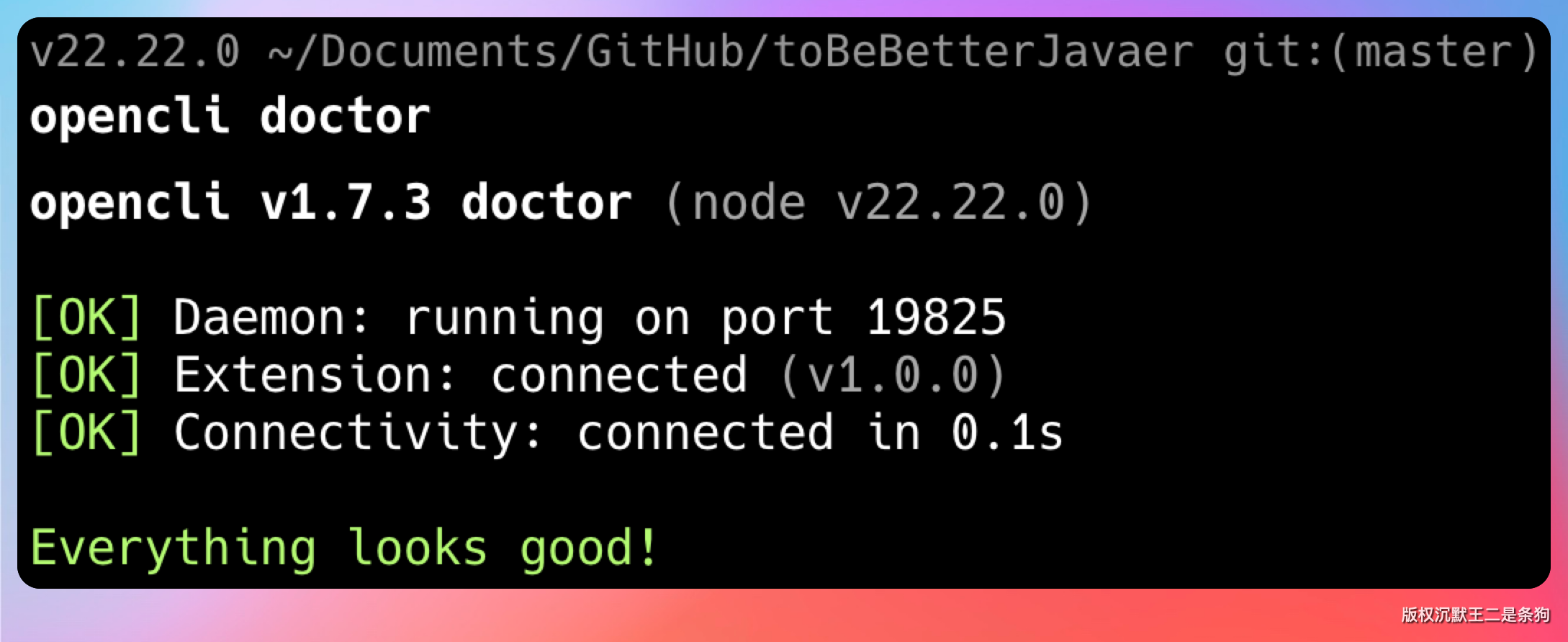
完事再执行 opencli doctor 确认一下:
opencli doctor 全部绿灯就说明可以用了。
我们来试试 B 站:
opencli bilibili hot --limit 10 输出格式支持纯文本和 JSON,JSON 格式方便后续给 Agent 使用。
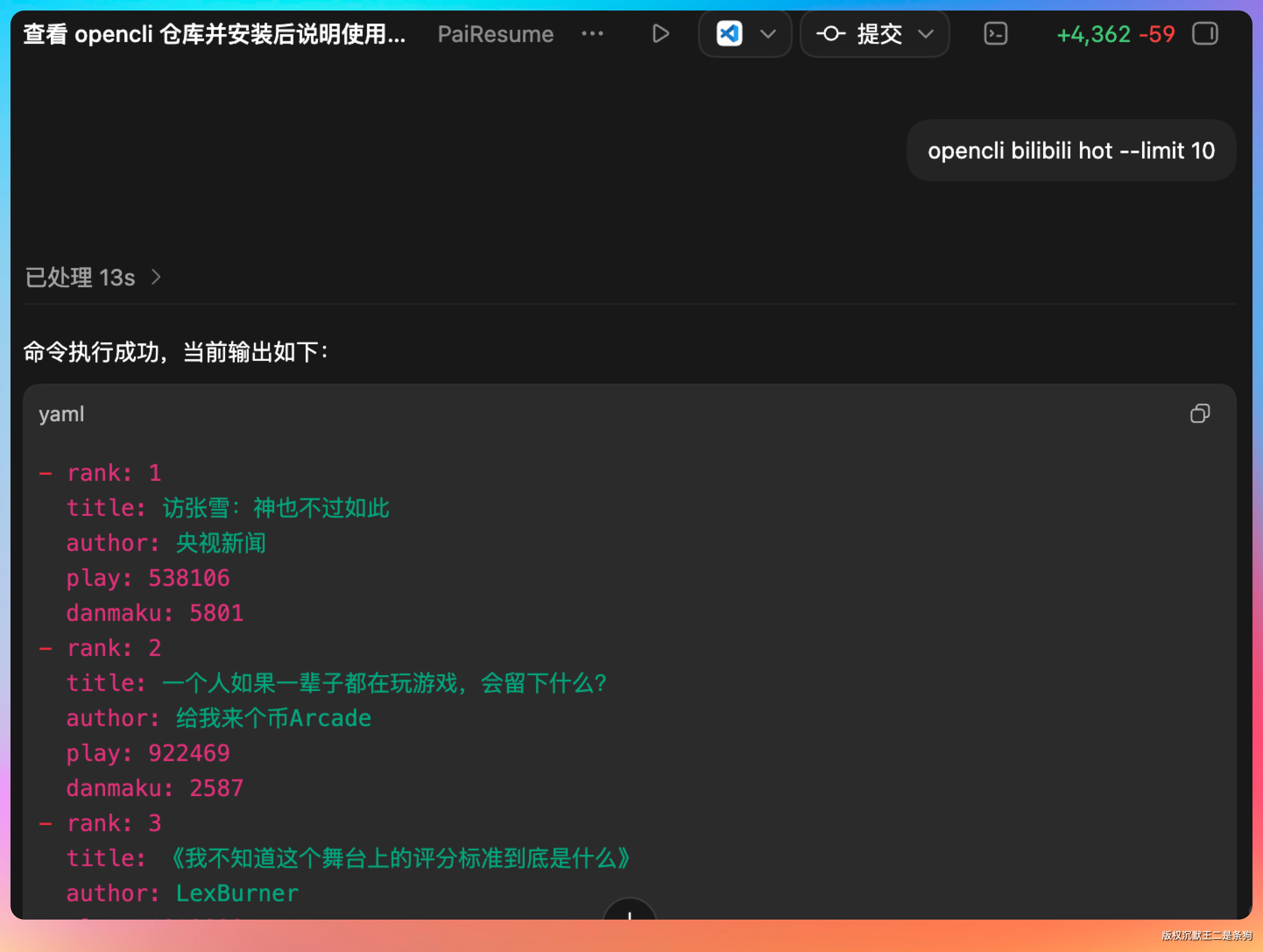
速度很快。这些命令跑起来基本就是 HTTP 请求的耗时,一两秒搞定。
我想知道小红书、V2EX、知乎上有没有人在讨论 AI Agent 相关的话题,看看用户的真实需求是什么。
以前做这个事情,要么自己一个个平台去搜,要么用 web-access Skill 让 Agent 开浏览器去翻。
现在用 OpenCLI,三条命令搞定:
opencli xiaohongshu search "AI Agent" -f json --limit 10 opencli v2ex search "AI Agent" --limit 10 opencli zhihu search "AI Agent" -f json --limit 10 因为我没有登录小红书,所以失败了。
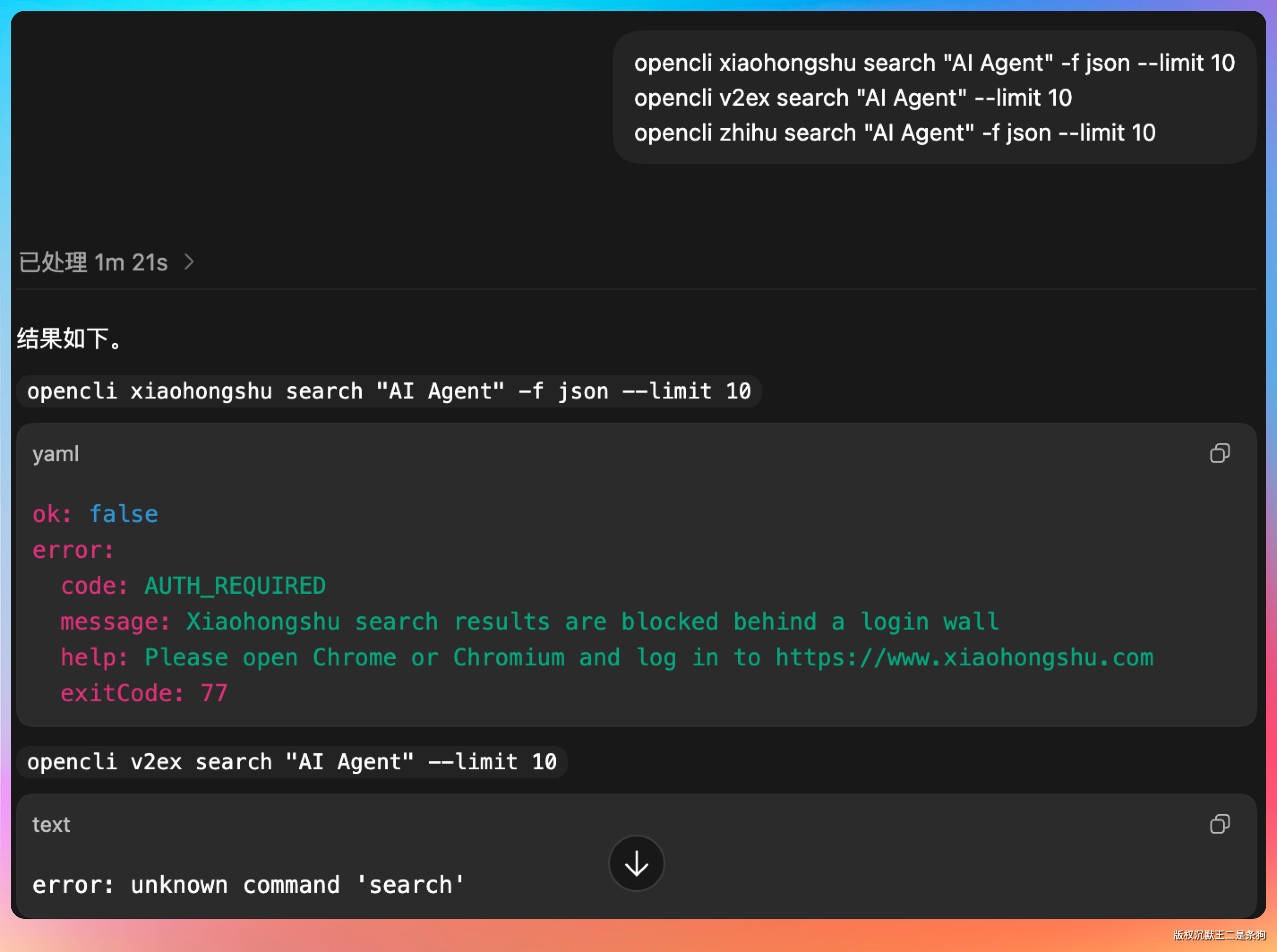
OK,我重新登录小红书后,可以搜到内容了。
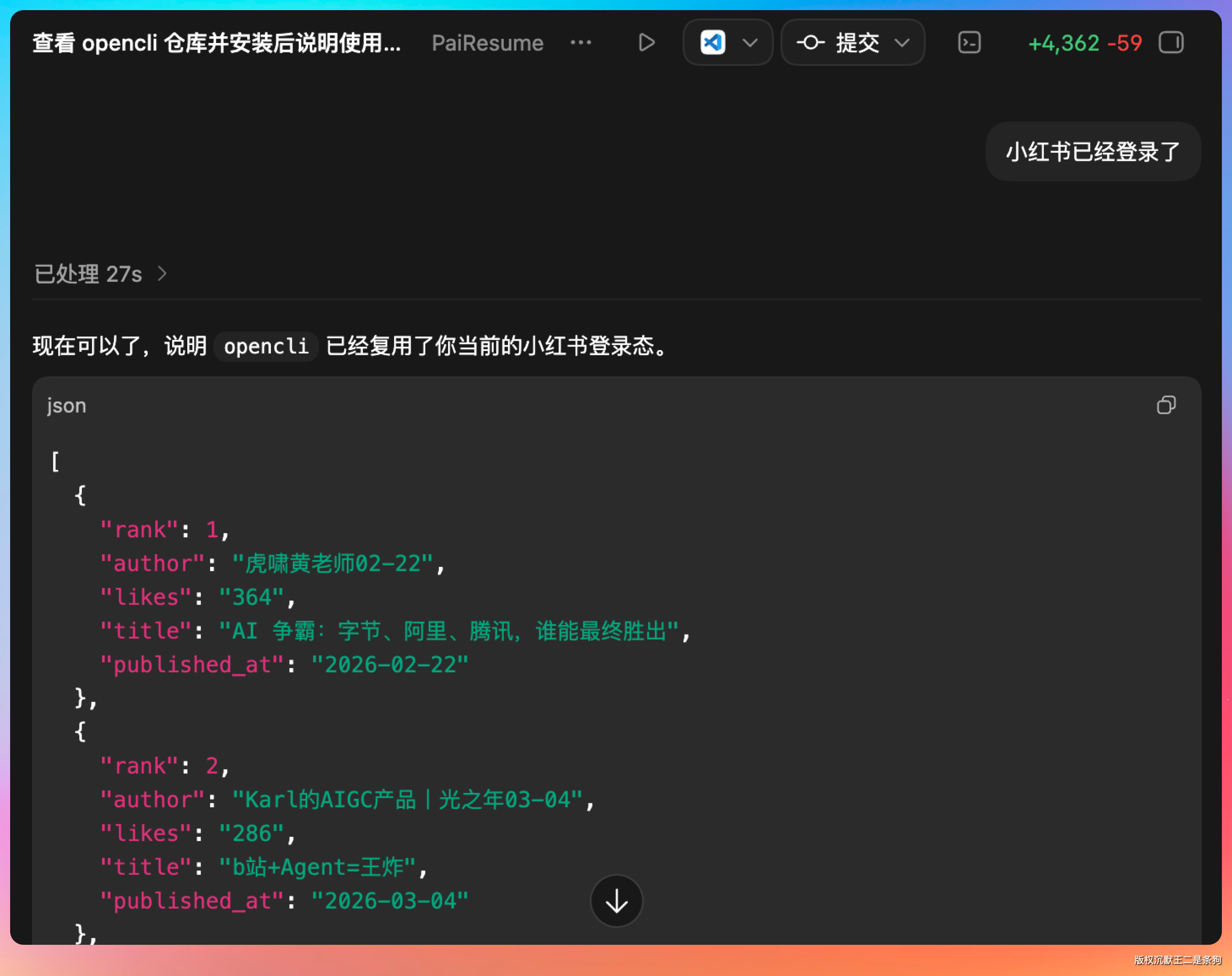
更妙的是,因为输出是结构化的 JSON,我可以直接把结果喂给 Codex,让它帮我整理成表格。
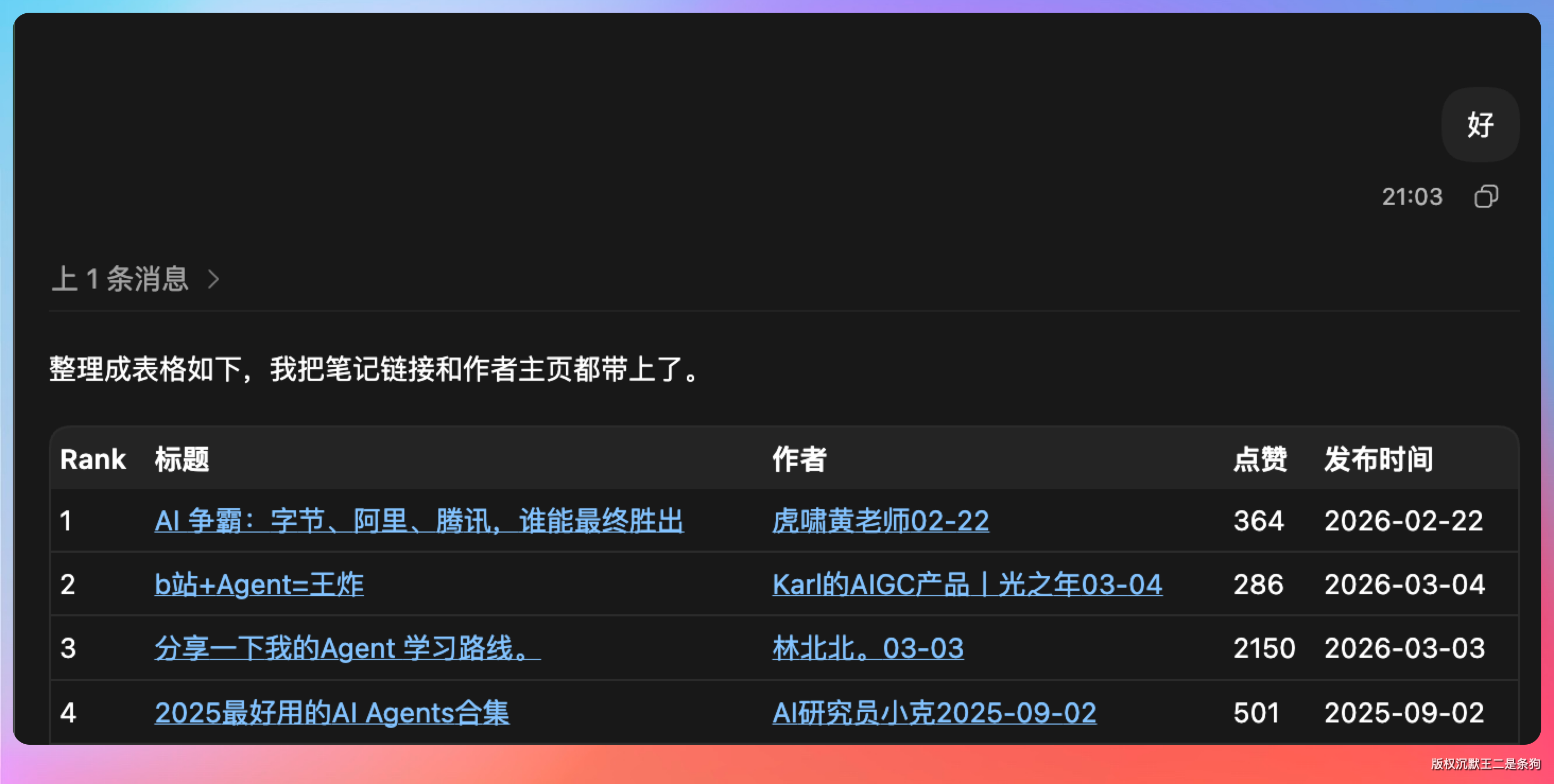
说真的,往后去,这种“CLI 取数据”的方式,才是 Agent 最喜欢的方式。
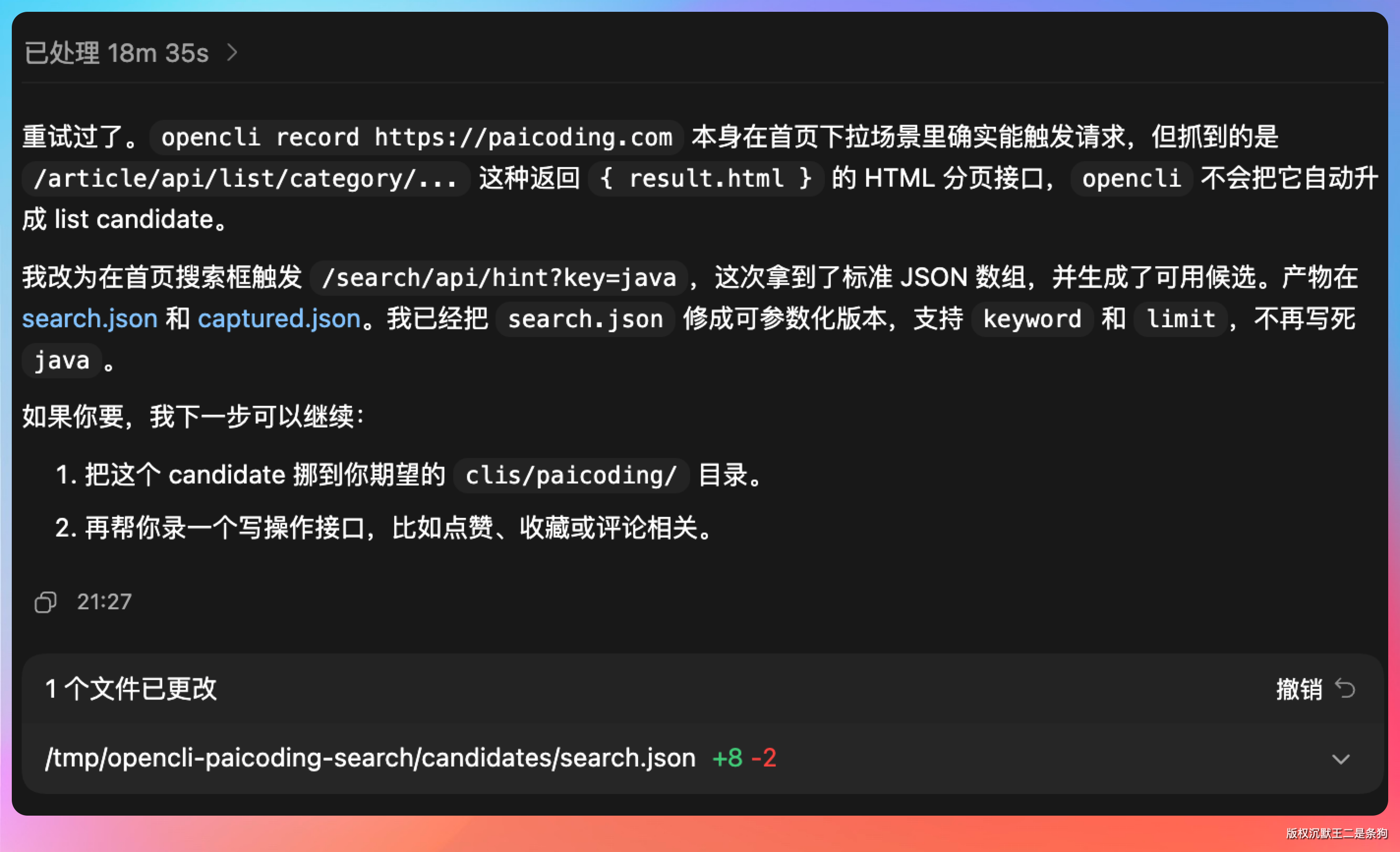
我还试了 record 命令,可以给一个还没有适配器的网站生成适配器。
这次我选了技术派(paicoding.com)。
opencli record https://paicoding.com 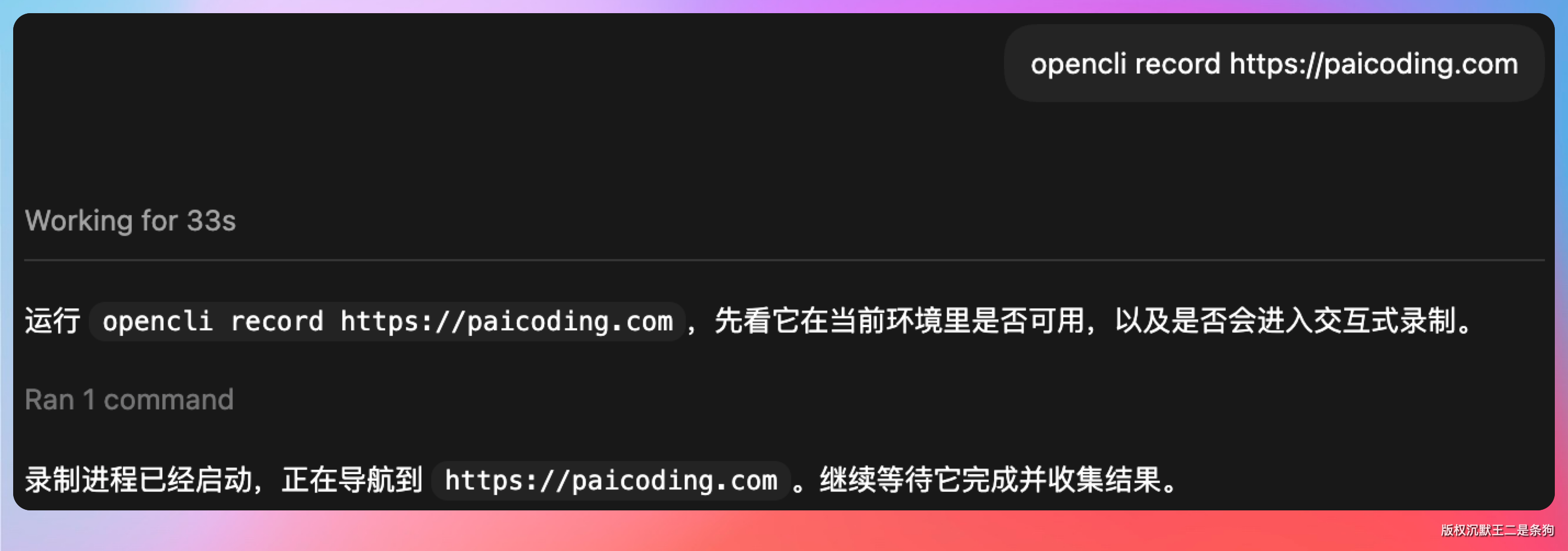
命令执行后,OpenCLI 自动打开了一个浏览器窗口,注入 fetch/XHR 拦截器。然后在页面上正常操作——点首页的文章列表,翻一页,点进一篇文章详情。
OpenCLI 在后台默默记录这些操作触发的所有 API 请求。60 秒后自动停止,生成了几个候选的 YAML 适配器草稿。
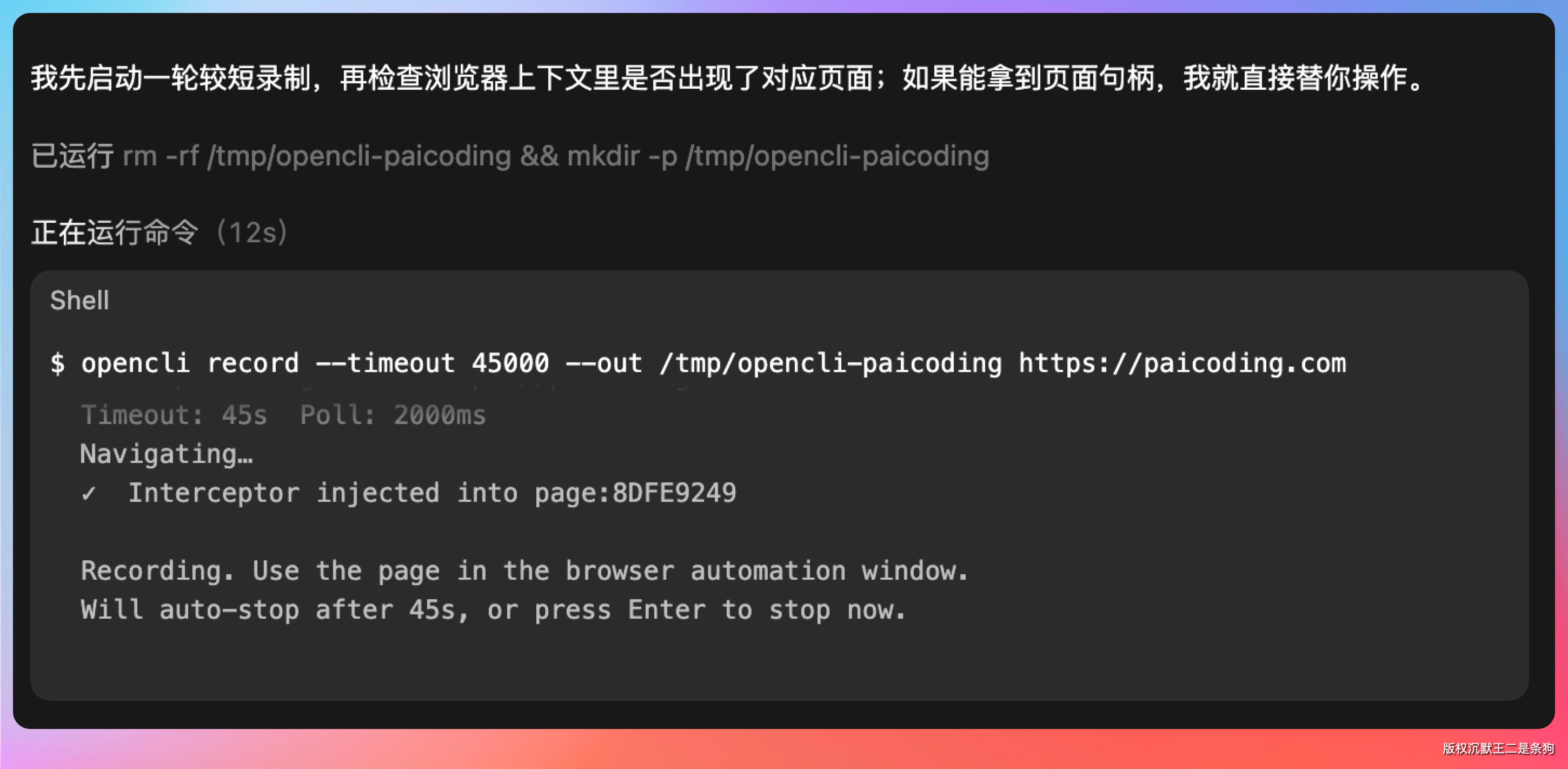
它识别出了文章列表接口和文章详情接口,连请求参数和响应字段的映射都帮我生成好了。
整个过程不需要我去浏览器的 Network 面板翻请求,不需要我分析 API 文档,OpenCLI 用拦截器把整个活儿都干了。
这个 record 命令的底层原理也挺有意思:它会在页面里注入一段 JavaScript,重写 window.fetch 和 XMLHttpRequest.prototype.open,所有经过这两个入口的网络请求都会被拦截记录。每 2 秒轮询一次捕获的请求列表,60 秒后自动结束。
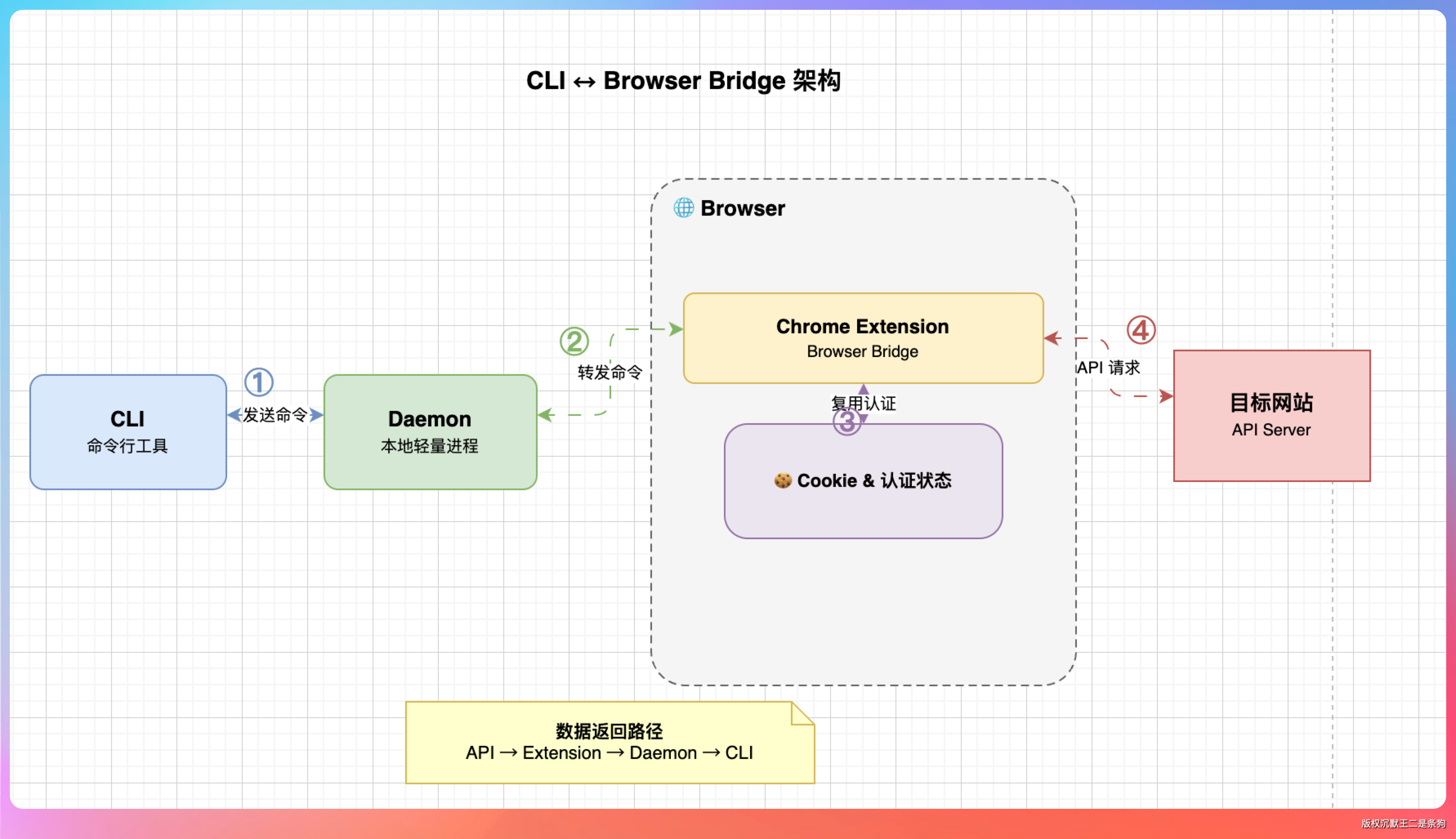
OpenCLI 最有意思的技术点就是 Browser Bridge 架构。
传统的抓包工具(比如 Charles、Fiddler)需要配置代理、装证书,操作门槛高。OpenCLI 用了一个更巧妙的方式——Chrome 扩展。
整个架构分两部分:
一个轻量级的 Daemon 进程跑在本地,负责接收 CLI 命令。一个 Chrome 扩展(Browser Bridge)注入到所有浏览器标签页里,充当 CLI 和浏览器之间的通信桥梁。
CLI 发命令给 Daemon,Daemon 转发给 Chrome 扩展,扩展用浏览器已有的 cookie 和认证状态去请求目标网站的 API,拿到数据后原路返回。
这里面最关键的是认证策略,OpenCLI 把网站的认证难度分成了四级:
第一级,Public。完全公开的接口,直接 HTTP 请求就行,不需要任何认证。HackerNews 的热帖接口就是这种。
第二级,Cookie。需要带浏览器 cookie 才能访问的接口。大部分中文平台(B 站、知乎、小红书)都是这种。OpenCLI 通过 Chrome 扩展拿到 cookie,请求时自动带上。
第三级,Header。除了 cookie 还需要额外的认证头,比如 Bearer token、CSRF token。一些后台管理系统会用这种方式。
第四级,Intercept。最难搞的一类——接口在页面内部能正常调用,但从外部直接请求就会失败。这种情况下 OpenCLI 会在页面级别做拦截,注入代码去捕获请求。
opencli cascade 命令可以自动探测目标网站属于哪一级,自动选择最合适的认证策略。
还有一个细节——OpenCLI 做了反检测处理。很多网站会检测自动化工具的痕迹,比如 navigator.webdriver 属性、window.chrome 对象、插件列表是否正常。OpenCLI 在请求时会 patch 这些特征:把 navigator.webdriver 设为 false,伪造插件列表,清理 ChromeDriver 和 Playwright 的全局变量,甚至会从 Error 的 stack trace 里剔除 CDP 相关的帧。
这套反检测机制不是万能的(真正硬核的反爬还是能识别),但对大多数平台的基础检测来说足够了。
OpenCLI 目前预置了 87+ 个网站适配器,覆盖面挺广的。
中文平台这边,B 站、知乎、小红书、微博、豆瓣、V2EX、即刻、京东、淘宝、知识星球、脉脉、贝壳、幕布、小鹅通都有。海外平台包括 Twitter/X、Reddit、HackerNews、YouTube、Amazon、GitHub Trending、Binance。
每个适配器本质上是一个 YAML 文件,定义了一个 pipeline:fetch → extract → transform → output。比如 B 站热搜的适配器大致长这样:
name: bilibili commands: hot: url: https://api.bilibili.com/x/web-interface/ranking/v2 auth: public extract: $.data.list transform: title: $.title play: $.stat.view url: https://www.bilibili.com/video/{{$.bvid}} 声明式的,不需要写一行代码。
如果想给一个还没有适配器的网站创建适配器,OpenCLI 提供了 record 命令:
opencli record https://example.com 它会打开一个自动化窗口,注入 fetch/XHR 拦截器,捕获你在页面上操作时产生的所有 API 调用,然后自动生成候选的 YAML 适配器。你只需要在页面上正常操作——搜索、翻页、点击——OpenCLI 在后台默默记录,60 秒后自动生成适配器草稿。
GUI 放入界面是给人看的,不是给程序操作的。按钮位置变了、弹窗多了一层、加载速度波动了,自动化脚本就挂了。
browser-use 这类 AI 驱动的方案稍微好一点,但每一步都要调视觉模型,token 烧得快,响应也慢。
CLI 方案(OpenCLI)的优势是同一条命令,永远返回相同结构的数据。
但 CLI 方案也有明显的短板——只能操作已适配的网站。87 个适配器听起来不少,但互联网上的网站何止千万。遇到没适配的网站,要么自己用 record 录一个,要么就只能换方案了。
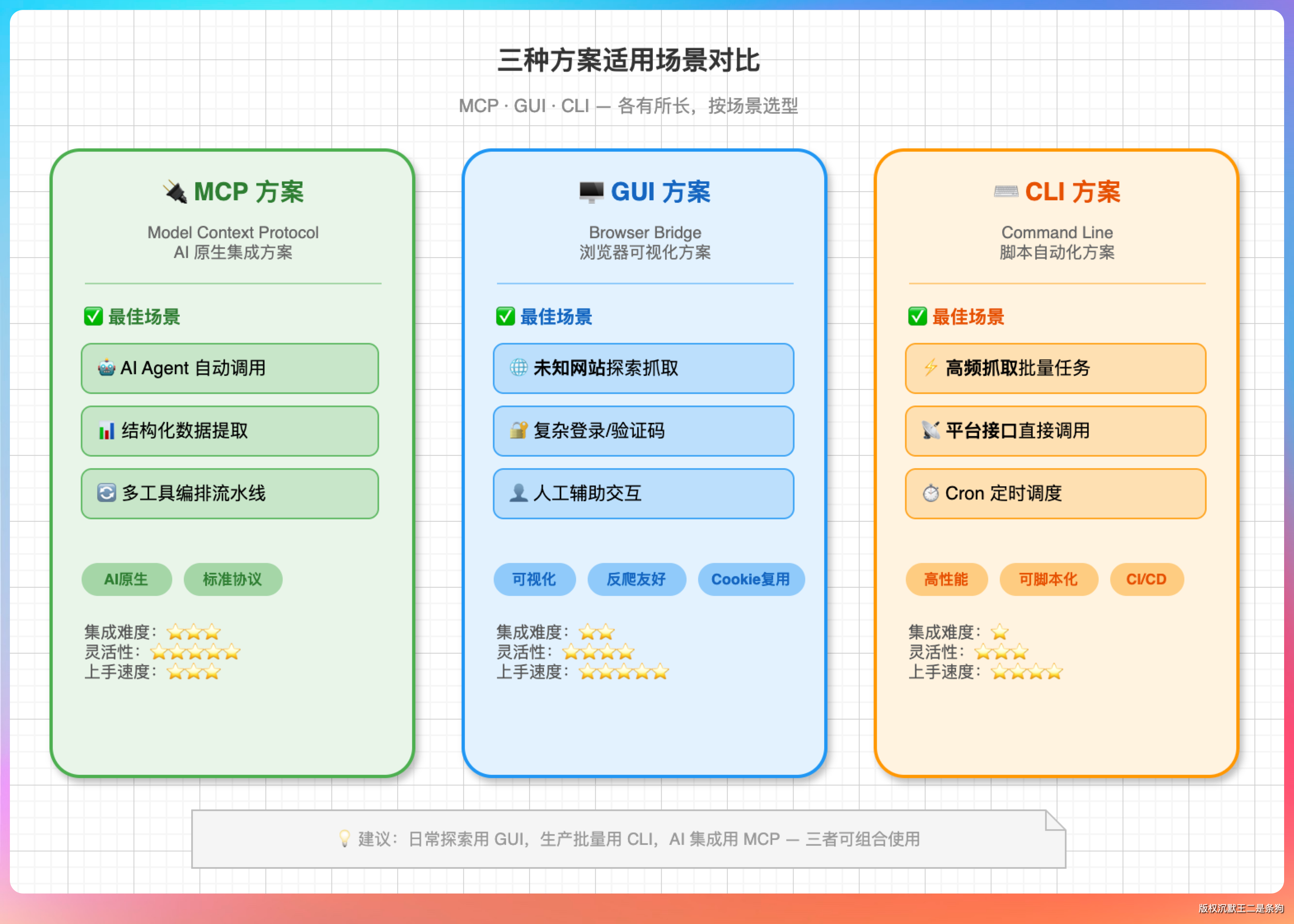
搭配使用,才是当前最务实的 Agent 工具层策略。不要把鸡蛋放在一个篮子里,要根据具体场景选择最合适的方案。
说到底,工具是为场景服务的,不存在银弹。
从 GUI 自动化到 OpenCLI,Web 自动化的解决方案越来越适配 Agent 了。
这也是为什么 CLI 越来越火的原因。
LLM 负责思考和决策,CLI 负责执行和获取数据。各司其职,效率最大化。
【真正好的工具,不是功能多,而是让每一步操作都变得确定。】
CLI 和 JSON,天生对 Agent 友好。
我们下期见。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/266970.html