
4 月 8 日,智谱正式开源了 GLM 最新的 5.1 版本。GLM-5.1 是一次方向极其明确的版本更新——将模型的能力重心推向了一个具体问题:能否在长时间任务中持续工作,并且持续产生有效结果。

作为基于 GLM-5 后训练演进而来的旗舰模型,GLM-5.1 把重点放在了转向长时间任务中的有效性提升上。而从结果来看,这一方向已经带来了相当直接的性能回报。在最具代表性的工程类基准测试中,GLM-5.1 取得了目前开源模型中的顶级成绩:
在 SWE-Bench Pro上以 58.4 分登顶,超过 GPT-5.4 与 Claude Opus 4.6;同时在 Terminal-Bench 2.0 与 NL2Repo 等任务中保持全球前三、开源第一的综合表现。这意味着,在“真实软件工程问题”这一最接近生产环境的维度上,开源模型首次真正进入第一梯队。
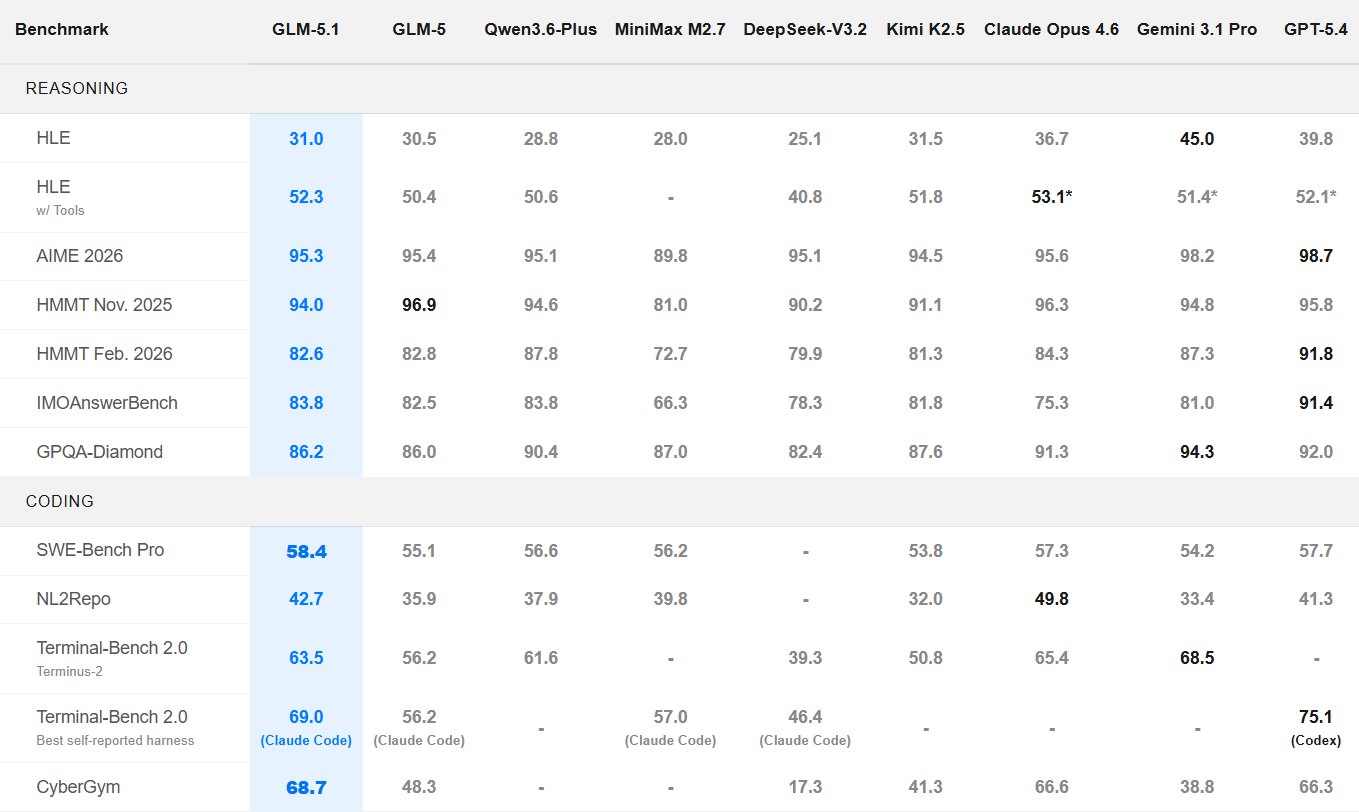
相比更强的代码生成能力,GLM-5.1 还有一个更值得关注的标签:长程任务(Long-Horizon Task)能力。
不同于以往以分钟为单位的交互式调用,GLM-5.1 可以在单次任务中持续长时间运行,在数百到上千轮迭代中,自主完成“实验 → 分析 → 调整 → 再验证”的完整循环。这种能力在实测场景中被具体化:在没有明确评价指标的情况下,模型连续运行 8 小时,从零构建出了一个完整的 Web 版 Linux 桌面系统。
这体现出的是 GLM-5.1 与前代模型,甚至与一部分同级别模型之间最核心的差异——模型不再只是执行任务,而是开始具备把任务不断做好的能力。
此外,作为一个采用 MIT 协议开源、并在编程基准上进入全球第一梯队的模型,GLM-5.1 也进一步压缩了开源与闭源之间的能力差距。
一方面,它在编程这一高价值场景中,首次实现了对顶级闭源模型的单项超越;另一方面,模型完全基于国产算力训练完成,并许可证开源,在可用性与商业化路径上进一步降低门槛。
这使得 GLM-5.1 的影响不再局限于更强的国产模型,而是在于开源模型在关键能力维度上正重新定义技术边界。
接下来,302.AI将通过一系列案例,对其进行实测,看看它在真实开发场景中的表现究竟如何。
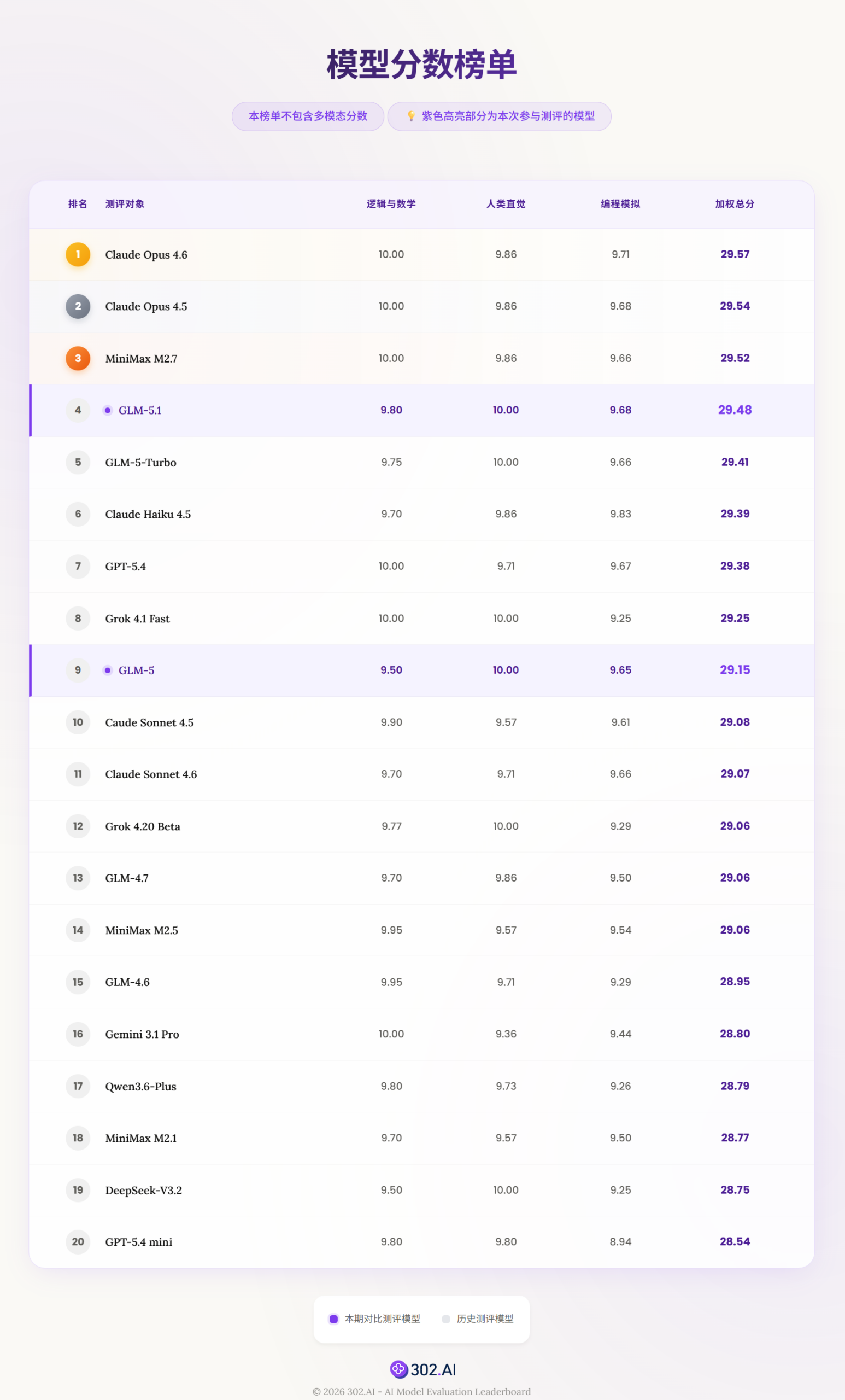
本评测侧重模型对逻辑,数学,编程,多模态,人类直觉等问题的测试,非专业前沿领域的权威测试。旨在观察对比模型的进化趋势,提供选型参考。
本次测评使用302.AI收录的题库进行独立测试。模型分别就逻辑与数学(共10题),人类直觉(共7题)以及编程模拟(共12题)进行案例测试,对应记分规则取最终结果,下文选取代表性案例进行展示。
题库地址:https://docs.google.com/spreadsheets/d/1sBxs60yWsxc9I5Va8Rjc1_le1Omg2hOXbwqOzpImZio/edit?gid=0#gid=0
💡记分规则:
按满分10分记分,设定对应扣分标准,最终取每轮得分的平均值。
编程案例分数评级:
⭐⭐⭐⭐⭐ S 级(封神): 行业标杆,重新定义标准。
⭐⭐⭐⭐ A 级(卓越): 生产力合格,无明显短板。
⭐⭐⭐ B 级(优秀): 表现中规中矩,存在短板。
⭐⭐及以下 C级(不合格): 不可用,存在明显问题。
GLM-5.1 完整推测出两种情况

GLM-5 只推测出了一种情况

GLM-5.1 绘制的图形构造已经没有太大问题,自行车结构也较为稳定,相对运动方向合理,但鹈鹕腿部与踏板连接问题仍未完美处理。

GLM-5 绘制的鹈鹕骑车,动态但原地踏步,运动状态实现较差,

附 Claude Opus 4.6 效果:画面构成细节更丰富,但依然处理不好腿部和踏板连接问题。

GLM-5.1 的输出在视觉上独具氛围感,细看花田建模略草率,但加分点也很明确:三个风车的转动效果是错落呈现的。

GLM-5 输出的图形大部分由色块组成,效果较差。

附 Claude Opus 4.6 效果:细节元素较齐全,视觉风格上略显粗糙。

GLM-5.1 输出效果:
✅ 优势项:
❌ 缺陷:
GLM-5 输出效果:
视觉设计更前卫,但是细节把控有瑕疵,例如模态框内容单一、深色模式切换按钮不可用。
附 Claude Opus 4.6 输出效果:
视觉设计高级,整体呈现出一种冷静内省的侘寂风或极简主义美学,代码结构优雅简洁,也因极简而牺牲了一些细节(如模态框文字内容单一机械)
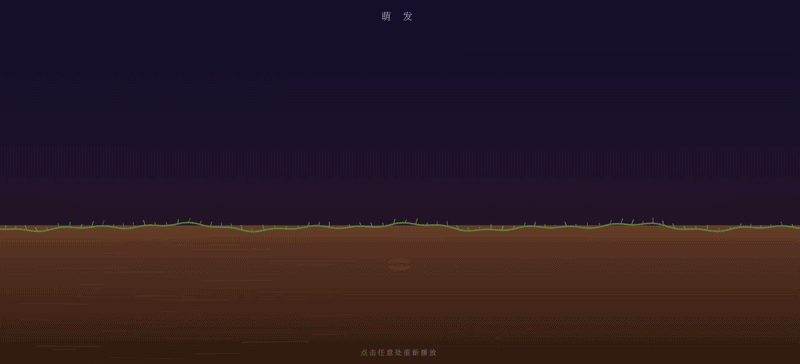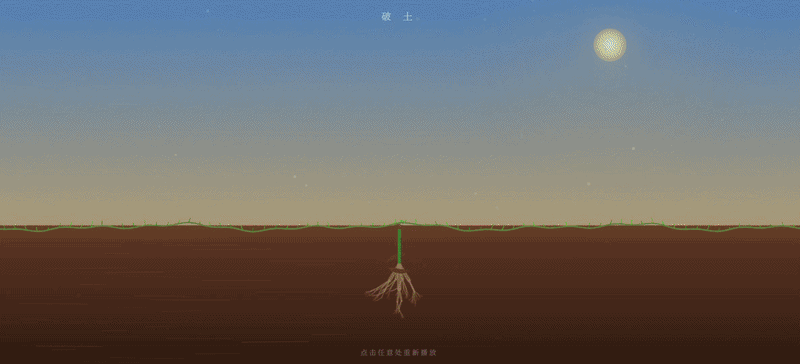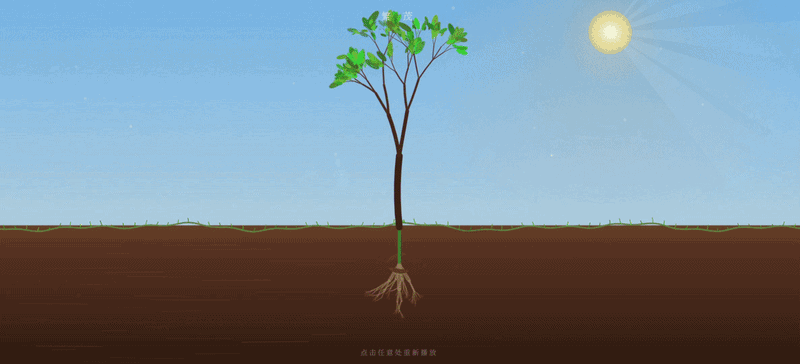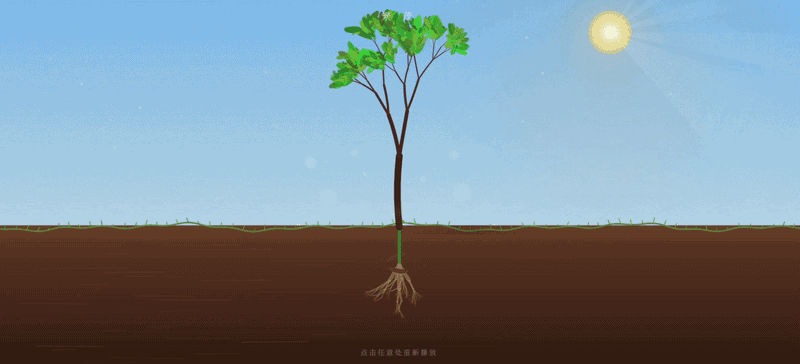
GLM-5.1 输出效果:
✅ 优势项:
- 光照与氛围实现是最大亮点。背景实现非常细节(包括天空渐变、远景山丘、地面雾气、丁达尔光柱等效果)
- 每个阶段的出现和消失(如种子的渐隐、树苗的覆盖)都用了
clamp和ease函数进行平滑插值,没有生硬的切换感
❌ 缺陷:

GLM-5 输出效果:
输出的粒子数量和特效复杂度控制得较好,在视觉效果和性能之间取得了不错的平衡,只在视觉表现和细节上逊色于 GLM-5.1。
附 Claude Opus 4.6 输出效果:
代码架构最清晰,输出了一个优秀的算法演示,展现出极强的复杂算法掌控力,只有视觉表现稍显克制。


以上测评案例本身已经清晰地描摹了模型的能力轮廓,但比起各项维度的性能提升,GLM-5.1 在任务执行方式上的变化更加值得关注:
GLM-5.1 最核心的提升,在于持续工作能力的质量跃升,即模型的能力重心,从单次输出质量转向长时间任务中的有效性。
这一点在复杂任务中尤为明显——模型不是一次性给出答案,而是在逐步逼近一个更合理的解。实测过程中能明显感受到,模型在输出和执行任务时不会急于收敛,而是主动回看关键决策点结果,反复进行验证与自我修正,再继续向前推进,这种“实验 → 分析 → 调整 → 再验证”的完整循环,使得它在长流程任务中不容易早早陷入停滞,并提升了最优解质量。
此外,一个比较明显的体感是,GLM-5.1 在面对连续修改、补充要求时,不容易跑偏或跟丢上下文目标。即使任务被多次打断或叠加新需求,它仍然能维持整体结构的一致性,这本质上反映出了模型在长上下文中具备极强的的状态管理能力。
从整体表现来看,GLM-5.1 的编程能力已经稳稳进入当前第一梯队,尤其是在项目级任务中,表现出很强的结构组织能力与细节补全能力,交付结果甚至与顶尖闭源模型 Claude Opus 4.6 不相上下。
无论是页面构建、动画实现还是逻辑推理类问题,其交付的共同特征都是:倾向于把东西做完整,并在过程中不断补齐细节。从具体案例来看,这一特征在大多数场景下属于优势项,比如网页、动画、交互类任务中,模型往往会主动构建精美的交互细节、增强视觉表现力,交付结果别具“氛围感”。
而这种优势主要作用于工程执行与优化路径上,在某些极限设计感或高度抽象的表达,例如案例 3 中特别要求“克制”的视觉风格取舍上,以及案例 4 中动用大量代码实现的细节堆砌上,模型的输出会偏向于“做满”而不是“做减”,有一种“用力过猛”的趋势。
由此可见,GLM-5.1 的交付表现更偏完整交付而非单点极限。换句话说,GLM-5.1 更像一个执行力很强的工程型模型,而不是刻意追求某一维度极致表达的模型。
说回开发者最关注的话题,放在更大的语境下看,GLM-5.1 的意义在于:其在编程这一最接近真实生产环境的场景中,已经能够与顶级闭源模型正面对比,并在部分关键基准上实现反超——这种原本只存在于闭源阵营中的领先表现,这一次站在了开源模型这一边。
结合其开源属性与实际可用性,带来的变化是直接且现实的:开源模型不再只是性价比权衡之下的被动选择,而开始成为可以进入实际生产流程的优质选择。
尤其是在长程任务能力逐渐成为核心指标的背景下,GLM-5.1 所展现出的,是一种更接近“可替代一段时间人类工作”的能力形态。
正如智谱官方所说:
“GLM-5.1不只是一个更强的模型,而是一种新的技术范式的开启。此刻,尝试给它一个指令,然后离开 8 小时。”
届时,真正被改变的已不再是模型,而是工作方式。
步骤指引:对话框内选择模型菜单
输入glm即可获取相应版本调用
步骤指引 :应用超市→聊天机器人→立即体验
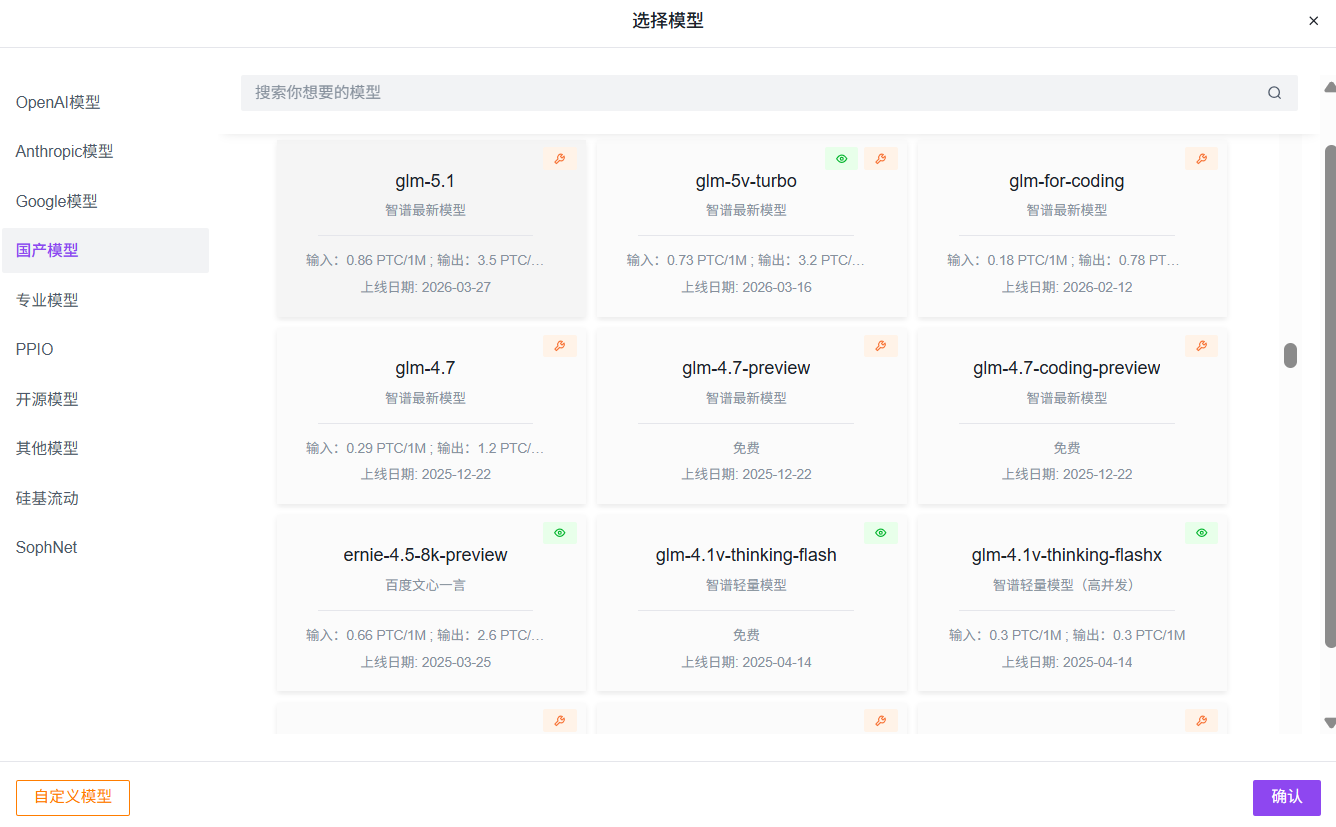
选择模型:国产模型→glm-5.1→确认
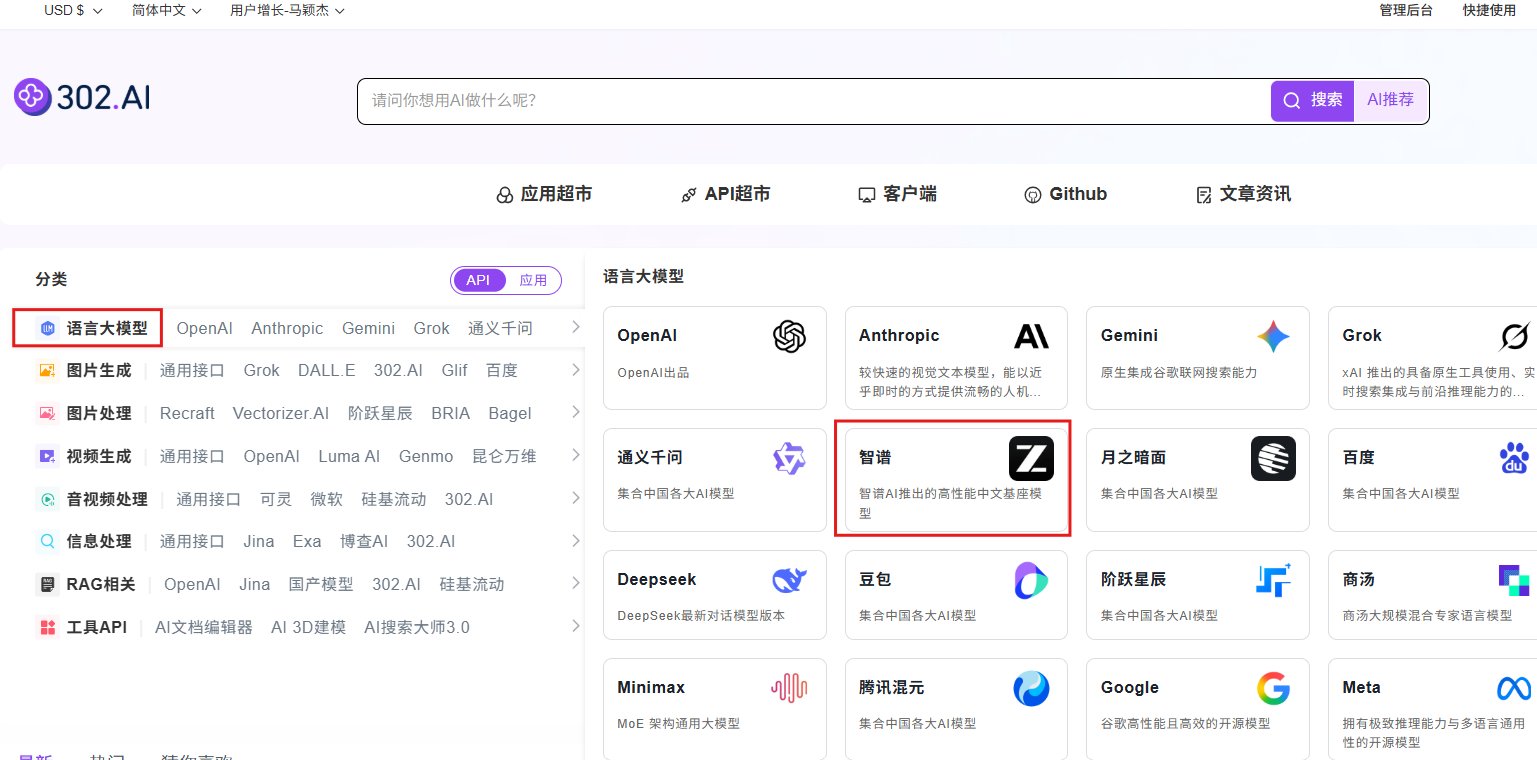
步骤指引:API超市→语言大模型→智谱→glm-5.1
点击【Playground】在线调用 API
想即刻体验 GLM-5.1 模型?
👉立即注册免费试用302.AI,开启你的AI之旅!👈
为什么选择302.AI?
● 灵活付费:无需月费,按需付费,成本可控
● 丰富功能:从文字、图片到视频,应有尽有,满足多种场景需求
● 开源生态:支持开发者深度定制,打造专属AI应用
● 易用性:界面友好,操作简单,快速上手

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/264948.html