
本文后面的内容还是基于claudecode 命令行界面的方式来进行阐述的。
本文以 mac 系统为例,安装在搞定网络环境的情况下只有一个命令
sudo npm install -g @anthropic-ai/claude-code
执行这个命令之前你需要确保电脑安装了node.js 可以额外加下面的命令行提升下载速度
npm config set registry https://registry.npmmirror.com
安装完成之后打开终端输入claude即可出现下面的界面,至此也就安装好了
安装好了以后,其实是无法回答问题的,因为这时候还没配置大模型的服务能力,这时候推荐先下载一个 CC-switch (github.com/farion1231/…)这个工具可以方便切换 claude 使用的模型,然后就看自己的需求了有条件的就上国外的模型,没条件的就用国内的智谱 MiniMax 千问等模型都是可以的,使用 cc-switch 去填写这些模型的配置信息,之后就可以正常使用 claudecode 了。
在前言的部分中我们可以看到图形化界面提供了很多的斜杠指令,对话框里输入 / 就能看到一堆内置指令。看着多,但其实日常翻来覆去用的就下面这几个。
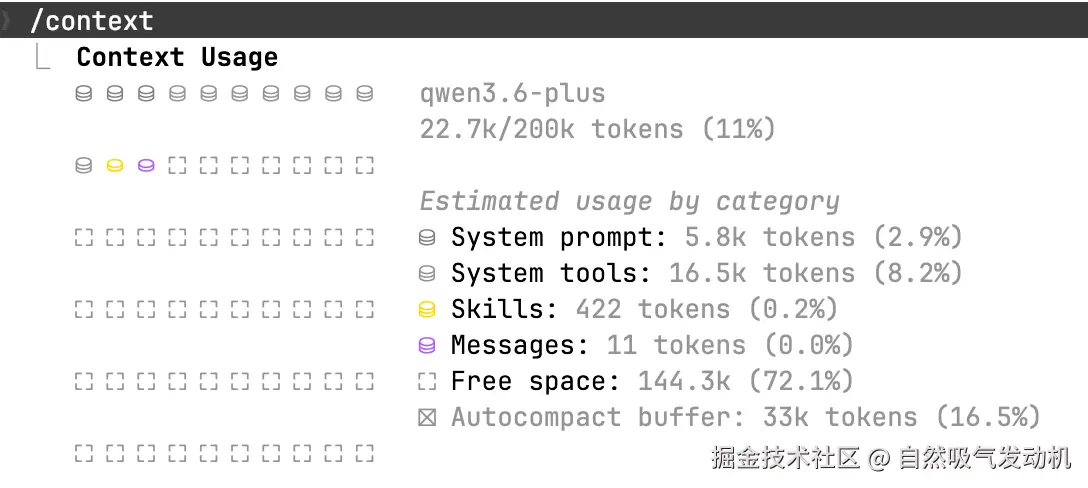
1.1 /context
看看当前会话的上下文情况。长时间对话之后,如果感觉 Claude 开始"记不得"前面说啥了,敲一下 /context 看看,如果发现上下文都塞满了,需要先 /compact 再继续聊。
1.2 /compact
压缩长对话,把上下文腾出空间来。还能指定保留重点:
/compact focus on the database migration plan
比如你正在重构一个模块,聊了几十个来回,Claude 已经开始前后矛盾地给建议了------这时候用 /compact focus on 重构方案 把早期的拉扯清掉,只留下最终方案。
1.3 /diff
交互式地看代码改了什么。提交前最好过一遍。
让 Claude 改了一堆文件,拿不准到底动了啥?敲 /diff 逐个文件看一遍,心里有底了再 commit。
1.4 /rewind
回滚到之前的对话点,文件改动也能一起还原。就当是对话和代码的撤销键。
比如 AI 给你改了一堆,结果你一看都不符合我的心意 这时候与其一个个文件手动还原,可以直接 /rewind 回到重构之前的状态。
1.5 /btw
顺便问点啥,不会打断当前对话的上下文流。
正在讨论数据库表设计,突然想确认下 Java 的一个知识点 ——用 /btw 插一嘴,问完接着回到主线。
1.6 /export
把对话导出来,存文件或复制到剪贴板都行:
/export auth-refactor-v2.md
讨论出了一个不错的架构方案,想连决策过程一起导出来,可以考虑这个命令
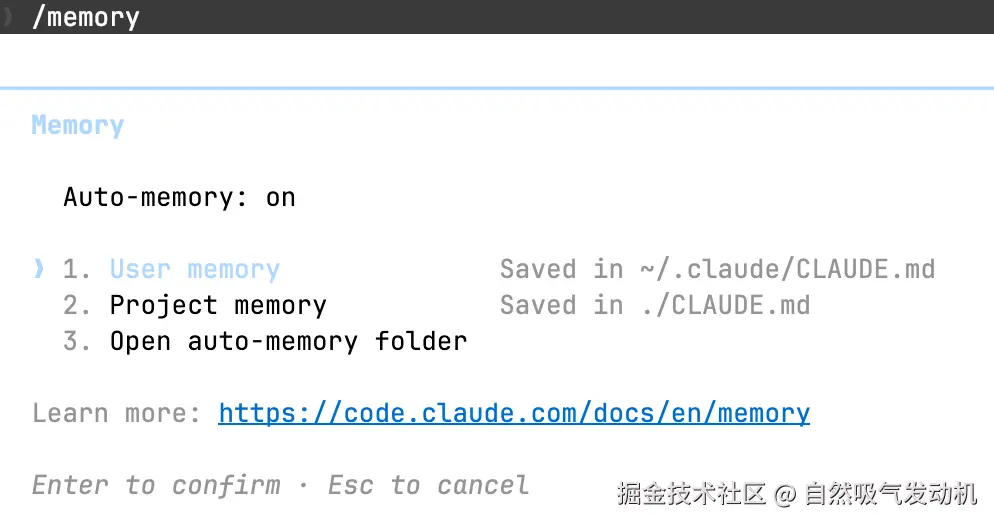
1.7 /memory
查看和管理 Claude 记下来的关于你的偏好。比如你发现它老用英文回你,但你想用中文——/memory 看一下有没有"用中文回复"这条记忆,没有的话新建一条。
1.8 其他
除此以外还有下面的斜杠指令可能会在日常中用到,读者可以自行体验下
最后这些斜杠命令都是可以自定义的 ,大家可以在 .claude/commands/ 目录来 定义自定义命令,同样的也是一个有格式要求的 md 文件,大家可以找下网上的资料看下如何来编写这样的一个 markdown 文件,笔者暂时未使用自定义命令。
Claude 有两套持久化机制,一个叫 Memory ,一个叫 CLAUDE.md,它俩互补。我们先讲 CLAUDE.md 这个文件
CLAUDE.md 这是一个你主动写的 Markdown 文件,分三个层级:
越具体的优先级越高:子目录 > 项目 > 全局。
这个文件可以在项目的目录下面执行 /init 来自动生成,当然自己写也是完全 OK 的
Memory 则是在 Claude 在对话中自动记下来的碎片信息------你纠正过它什么、你喜欢什么工作方式之类的。保存在 ~/.claude/projects/ 目录下,用 /memory 命令管理。
简单说:CLAUDE.md 是你主动写的"规矩",Memory 是 Claude 自己记的"笔记"。两个东西每次启动时都会自动加载,不用操心。
开一个新项目,想让团队用起来体验统一一些,推荐在项目的根目录下面放这几个文件:
最基本的
项目根目录/
├── CLAUDE.md # 技术栈、构建命令、代码规范 └── .claude/
└── settings.json # 项目级配置和钩子
CLAUDE.md 写点啥都行,比如:
# 项目上下文
技术栈
- 前端:React + TypeScript
- 后端:Java
构建命令
- 开发:
npm run dev
- 构建:
npm run build
代码规范
- 使用中文注释
- 不要使用 emoji
可选的
.claude/
├── rules/ # 目录级规则,进到这个路径才触发 ├── skills/ # 自定义斜杠命令 └── CLAUDE.md # 子目录级指令
当然了如果每个开发都有自己的偏好设置则可以继续添加下面的这两个文件
CLAUDE.local.md # 个人偏好
.claude/settings.local.json # 个人设置
这两个记得加到 .gitignore 里。
团队其他人 clone 下来之后,Claude Code 会自动读取这些文件,不用额外配置。
一般情况下比较推荐的是在一个空的文件夹里面,先创建一个.claude 目录,后面项目需要的 skill agent 等什么东西都可以放到这里这样不会污染全局
对话里输入 ! 加命令,就能在当前项目目录执行:
!ls -la
命令的输出会回到对话里,Claude 能看到并基于结果继续分析。跑久了的命令可以按 Ctrl+B 放后台,用 Ctrl+X Ctrl+K 终止所有后台代理。
日常最常用的是:
!curl [http://localhost:3000/health](http://localhost:3000/health`)
简单来说使用 ! 可以保证我的命令执行的输出结果会被记忆到大模型的上下文中,这个才是和我们在普通 shell 中直接执行命令的一个重要区别
另外一个重要的符号就是 @ 这个符号可以直接引用一个目标文件,比如
@markdown-note/ 统计下这个文件夹下有多少个 md 文件
5.1 SKILL
SKILL 这个概念也是一个目前比较火的热词,本节简单讲下怎么在 claude 中配置和使用 SKILL
首先我们可以使用斜杠指令 /skills 看下当前claude code 启用了哪些 skill,skill 的启用有两种方式一种是直接输入 skill 对应的斜杠指令,另一种是在和大模型对话的过程中,大模型在自动选取合适的 skill 进行调用。
skill 并不是很高大上的东西,我们可以自己写一个适合自己的 skill,而且一般 skill 都有大致类似的目录结构,写一个 skill 之前我们要考虑这个 skill 是每个项目都可以用还是说只适用于当前项目,这决定了你需要把 skill 文件夹放在哪里。这里假定你做一个只适用于当前项目的 skill,你需要先在当前项目的.claude 目录下创建一个文件夹,比如这里我准备搞一个onboard skill 让新参与项目开发的人员快速了解项目:
mkdir -p .claude/skills/onboard
接下来你需要写一个 SKILL.md 文件,这个文件存在基本规范,文件的前面需要 name 和 description 两个部分,skill 在大模型加载的时候不会把所有提示词都加载进去而是只加载前面的 metadata 的部分。
---
"name": "onboard",
"description": "Help new team members get up to speed with the project"
你是一个项目引导员。请按以下步骤帮助新成员熟悉项目:
- 读取 CLAUDE.md 和项目 README,介绍项目定位和技术栈
- 运行
ls -la 和关键目录结构,解释项目组织方式
- 展示最近的 3 个 commit 和对应的 PR,说明当前开发重点
- 指出代码中容易让人困惑的"历史遗留"部分(如果 CLAUDE.md 有记录)
重新启动 cluade 然后就可以使用这个 skill 了:
/onboard
社区也有现成的 Skill 可以拿来用,clone 到 .claude/skills/ 目录下就行。
更多创建 SKILL 的步骤可以参考官方文档:code.claude.com/docs/zh-CN/…
最后我们也可以更直白的直接用自然语言和 Claude Code 进行沟通,直接让他把之前的交互内容或者指定数据沉淀为 SKILL
这里在我的日常使用中比较推荐使用 playwright-cli 工具,通过这个工具可以直接让 cluade code 在控制台直接去使用浏览器去访问指定网页并总结网页中的内容,实现效果如下:
如果这块如果需要使用的小伙伴比较多 后期准备在 github 上公开我关于playwright-cli 工具的相关skill 供大家使用。
5.2 MCP
MCP(Model Context Protocol)让 Claude 能直接调外部服务——GitHub Issues、数据库、地图 API 之类的。
常用的 mcp 管理命令如下:
claude mcp list # 看看连了哪些
claude mcp get
# 看某个的详情 claude mcp remove
# 移除 /mcp # 进入 cluadecode 之后 在对话里看活动连接
比如我要添加一个高德的 MCP 服务,只需要打开.claude 文件夹中的 setting.json 文件,添加下面的内容(API-Key 需要去高德开放平台去申请)
"mcpServers": {
因为目前市面的上 MCP 服务大多是第三方提供的,所以需要注意安全,具体如下
- 凭证用环境变量存,别硬编码
- 数据库查询用只读权限
- 最小权限原则,能少给就少给 因为有的 mcp 服务是三方的存在安全风险
目前的 mcp 服务只推荐Http 和 Stdio 两种类型不推荐 SSE ,此外我个人觉得目前 AI 的趋势是逐步大量的去使用 CLI 工具,而不再是 MCP,因为 MCP 的使用可能会占据大量的上下文。
前面讲的东西已经能覆盖大部分日常场景了,本节介绍一些稍微进阶一点的内容
6.1 Hooks
Hook 绑定在特定事件上,事件发生时自动执行脚本,不需要你手动触发。配置在 .claude/settings.json 里:
], "Notification": [ ] }
}
几个常用的 Hook 类型:
6.2 Plugin
Plugin 给 Claude 添加原本没有的工具或数据源。最常见的形式就是前面讲过的 MCP Server,但也有其他方式:
一句话总结就是 plugin 是一系列 skills、mcp 、 agents 、hooks 的集合体
可以自己开发 Plugin 详情参考 :code.claude.com/docs/zh-CN/… ,笔者目前暂未实际开发过插件
可以使用下面的命令来安装 cluadecode 的官方插件
/plugin install github@claude-plugins-official
然后输入/plugin 就可以查找插件了
6.3 agents
agents 也被称作(subAgents) 意思就是让多个agent 并行行动,同时每个 agent 都有自己的上下文窗口,我们在 claude 终端输入 /agents 就可以当前有哪些 agent 可用
同样的我们也可以创建 Agent ,按照不同的使用范围,我们可以在 {project}/.claude/agents/ 创建也可以在 ~/.claude/agents/ 创建,主要就是写一个 md 文件,这个文件的格式是固定的,比如下面的这个样子
---
name: researcher memory: user description: Long-running research assistant with persistent notes tools: Read,Write,Bash,Grep model: sonnet permissionMode:inherit
skills: pdf
You are a research assistant. ……
上面的 metadata 部分是给大模型读取的,使用的时候比较简单可以这样去使用
claude --agents researcher "研究一下 xxx"
Claude Code 与传统辅助编程工具最大的区别在于它不是一个"插件"或"建议面板",而是一个具备完整开发循环能力的 AI 开发助手——能读代码、能跑命令、能直接改文件。掌握它不需要死记硬背所有命令,而是要理解几个核心机制
- 上下文管理是关键能力,善用 /context、/compact、/rewind 能让长对话始终保持高质量输出
- CLAUDE.md + Memory 双轨机制让个人偏好和团队规范都能被 Claude 自动遵循
- ! 和 @ 符号是日常最高频的交互方式,一个负责执行,一个负责引用
- Skill / MCP / Hook / Agent 这些进阶能力可以根据需求渐进式引入,不必一上来就全部配齐
对于刚开始接触 Claude Code 的同学,建议先从最基础的斜杠指令和文件引用用起,跑通"提问 → 执行 → 验证 → 提交"的完整开发循环后再逐步探索进阶玩法。工具只是手段,真正提效的是 AI 与开发者之间建立的默契。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/261136.html