
随着 Claude Code、Codex 这类 AI 编程助手深度融入日常开发流程,一个被忽视的问题逐渐浮现:我们到底消耗了多少 Token?花了多少钱?缓存有没有生效?哪个项目最费 Token?
这些问题的答案,其实就藏在本地日志里,但原始数据难以直观感知。市面上也没看到太好的相关项目,于是就打算自己搞一个。
TokenDash 是一个开源的本地 Web Dashboard,专门用于可视化 Claude Code 和 OpenAI Codex 的 Token 使用统计。它通过读取本地日志文件获取数据,在浏览器中呈现为清晰、可交互的分析面板。
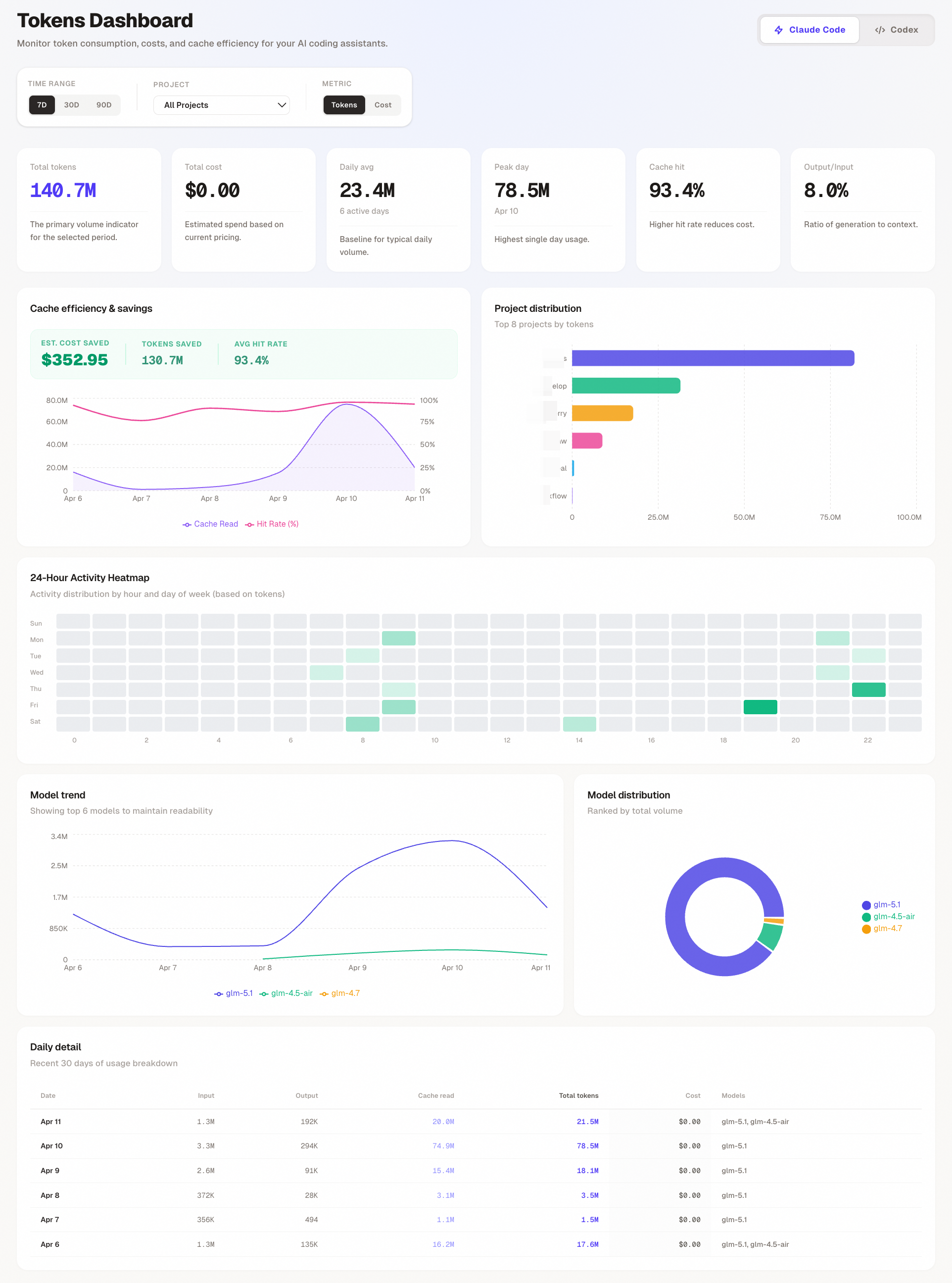
TokenDash 的分析能力建立在对 Claude Code 和 Codex 本地日志的精确解析之上。两种 Agent 的数据存储方式截然不同,TokenDash 为它们设计了独立的提取方式。
Claude Code 在运行过程中,会将每一次对话交互以 JSONL(JSON Lines)格式写入本地磁盘。存储路径为:
~/.claude/projects/
/
.jsonl
其中
是工作目录的编码形式。例如你在 ~/my-project 目录下启动 Claude Code,日志会存放在:
~/.claude/projects/-xx-my-project/
.jsonl
每个 JSONL 文件中,每一行都是一个独立的 JSON 对象,代表一个事件。TokenDash 关注的核心事件类型是 assistant(即模型响应事件),其数据结构大致如下:
{ "type": "assistant", "timestamp": "2026-04-10T14:30:00.000Z", "message": { "model": "claude-sonnet-4-6", "usage": { "input_tokens": 15200, "output_tokens": 3800, "cache_creation_input_tokens": 8000, "cache_read_input_tokens": 12000 } } } TokenDash 的提取流程:
- 扫描目录:遍历
~/.claude/projects/下所有子目录,找到全部.jsonl文件 - 解析事件:逐行读取 JSONL,使用 Zod Schema 校验数据结构,筛选
type: "assistant"且message.usage存在的记录 - 聚合统计:按时间戳将记录归入对应的小时桶(Hour Bucket),累加各类 Token 数量
- 项目映射:目录名解码回项目名,支持按项目过滤分析
Codex 的日志存储路径为:
~/.codex/sessions/
.jsonl
与 Claude Code 不同,Codex 的日志按会话(Session)组织,而非按项目。每个会话文件中包含多种事件类型:
// 会话元数据 {"type": "session_meta", "payload": {"id": "abc123", "cwd": "/home/user/project", "timestamp": "..."}} // 模型上下文 {"type": "turn_context", "payload": {"model": "gpt-5.4"}} // Token 计数事件 {"type": "event_msg", "payload": {"type": "token_count", "info": { "total_token_usage": {"input_tokens": 5000, "cached_input_tokens": 3000, "output_tokens": 2000, "total_tokens": 10000}, "last_token_usage": {"input_tokens": 500, "cached_input_tokens": 300, "output_tokens": 200, "total_tokens": 1000} }}} TokenDash 的 Codex 数据提取有几个关键设计决策:
- 递归扫描:从
~/.codex/sessions/递归遍历所有子目录,收集全部.jsonl文件 - Token 事件提取:只关注
event_msg → token_count类型的嵌套事件,使用last_token_usage字段(代表最近一次交互的增量 Token) - 不去做重:Codex 每次对话轮次会产生两个 token_count 事件(一个对应推理,一个对应输出完成),它们是独立的计费事件,必须全部累加
- 项目推断:通过
session_meta.payload.cwd字段提取工作目录路径,以路径最后一段作为项目名 - 内置定价:Codex 目前没有官方的用量统计工具,TokenDash 内置了定价计算引擎,直接从原始日志推算费用
Prompt Caching 是现代大模型服务中一项关键的降本机制,Claude Code 和 Codex 都采用了类似的策略,但实现细节有所不同。
大模型每次处理请求时,需要将完整的上下文(系统提示、对话历史、代码文件等)编码为 Token 序列。在一次持续的开发会话中,大量上下文是重复的——系统提示不变、之前的对话历史只增不减。
Prompt Caching 的思路是:将已经编码过的 Token 缓存起来,下次请求如果上下文前缀相同,直接从缓存中读取,跳过重复编码的过程。这不仅降低了延迟,更重要的是大幅降低了成本。下图展示了一次典型对话中缓存是如何逐步累积的:
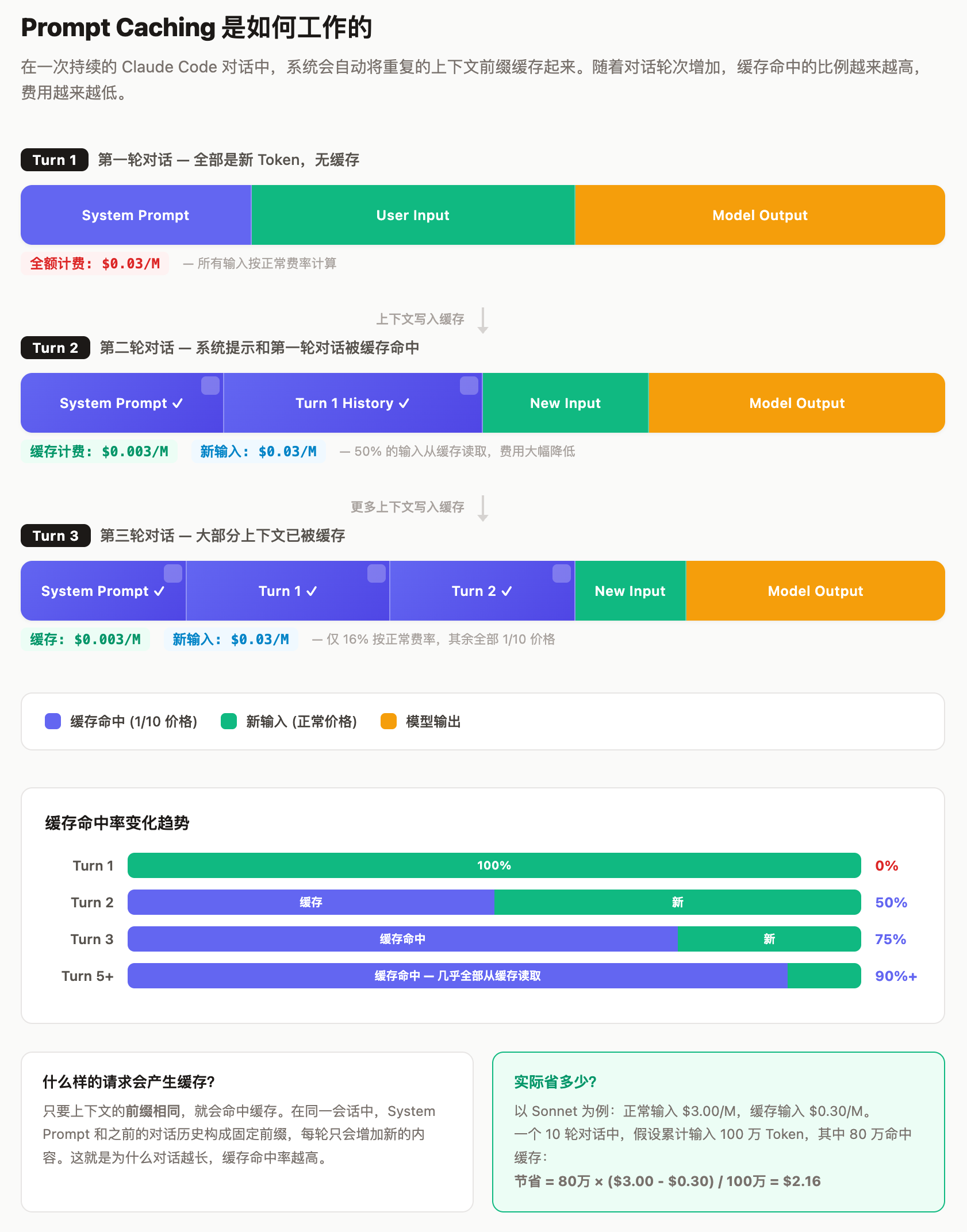
一个常见的疑问是:既然命中缓存了,是不是这部分就完全免费了?缓存只解决了 Token 编码阶段的重复计算,但命中缓存的 Token 仍然需要:
- 通过模型的 Attention 层参与计算:跳过编码不等于跳过推理,Token 仍要参与注意力机制的计算,消耗 GPU 算力
- 占用显存和带宽:KV Cache 需要常驻 GPU 显存,缓存检索也需要内存带宽
- 网络传输:生成的结果仍然需要完整返回
所以 Anthropic 和 OpenAI 的定价策略都是缓存输入按正常价格的 1/10 计费,而非免费。这在业界是通行做法,类似于 CDN 缓存降低了源站压力但仍需支付边缘节点费用。
Claude Code 底层使用 Anthropic API 的 Prompt Caching 功能。每次请求返回的 usage 字段中包含三个与缓存相关的指标:
cache_creation_input_tokens 本次请求中
新写入缓存的 Token 数。这些是首次出现的上下文,需要编码并存入缓存
cache_read_input_tokens 本次请求中
从缓存命中的 Token 数。这些是之前已缓存、本次直接复用的部分
input_tokens 不包含缓存部分的原始输入 Token 数
一次典型的 Claude Code 对话中,随着轮次推进,缓存命中率会逐渐升高。第一轮几乎无缓存(所有上下文都是新的),到第五轮时,系统提示和前四轮对话都可能被缓存命中。
TokenDash 中的缓存节省费用计算:
Cost Saved = cacheReadTokens / 1,000,000 × \(3.0 × 0.9 这里的 \)3.0/M 是 Claude Sonnet 的标准输入价格,0.9 是正常输入价格与缓存输入价格(\(0.30/M)之间的差额比例。即每命中 100 万缓存 Token,大约节省 \)2.70。
Codex 采用类似策略,日志中通过 cached_input_tokens 字段记录缓存命中的 Token 数。TokenDash 的定价引擎在计算费用时,对缓存输入和非缓存输入采用不同费率:
Cost = (inputTokens - cachedInputTokens) × $2.50/M // 非缓存输入 + cachedInputTokens × $0.25/M // 缓存输入 + outputTokens × $15.00/M // 输出 以 gpt-5.4 为例,缓存输入单价 $0.25/M 仅为正常输入 $2.50/M 的 1/10。
理解缓存策略后,可以从使用习惯层面优化:
- 保持会话连续性:在同一段对话中持续工作,而非频繁开启新会话。新会话的上下文无法复用旧缓存
- 减少系统级变更:系统提示的修改会使已有缓存失效
- 关注 Cache Hit Rate 趋势:在 TokenDash 的缓存效率面板中观察命中率变化,如果某天骤降,可以回溯是否因为切换了工作模式
理解指标的统计口径,是正确使用分析工具的前提。以下是 TokenDash 各项核心指标的统计规则。
TokenDash 将 Token 分为四类进行统计:
Total Tokens 的计算公式为:
Total Tokens = Input Tokens + Output Tokens + Cache Read Tokens 注意:Cache Creation Tokens 不计入 Total Tokens,因为它们代表的是缓存写入行为,而非实际消耗。
两种 Agent 采用完全不同的定价链路。
Claude Code:ccusage 多模式计费
TokenDash 调用 ccusage daily --breakdown 获取已计算好的费用数据。ccusage 本身支持三种计费模式:
costUSD,没有则按 Token × 模型定价计算 日常使用
calculate 忽略预计算值,全部按 Token × LiteLLM 数据库的模型定价重新计算 跨时期一致性对比
display 仅展示预计算的
costUSD,缺失的显示 $0.00 核对官方账单
其中 calculate 模式的计算公式为:
totalCost = inputTokens × inputPrice + outputTokens × outputPrice + cacheCreateTokens × cacheCreatePrice + cacheReadTokens × cacheReadPrice 每种 Token 类型都有独立的单价,定价数据来自 LiteLLM 数据库,支持所有 Claude 模型(Opus 4.6、Sonnet 4.6、Haiku 4.5 等),并会定期自动更新。
以 Claude Sonnet 4.6 为例,参考定价:
Codex:内置定价引擎
Codex 目前没有官方的用量统计 CLI,TokenDash 为它内置了独立的定价计算引擎:
Cost = (inputTokens - cachedInputTokens) × input_rate + cachedInputTokens × cached_rate + outputTokens × output_rate 当前内置的模型定价:
需要注意,目前 Codex 定价引擎仅配置了 gpt-5.4 一个模型的明确费率,其他模型(如 gpt-5.4-mini)会 fallback 到与 gpt-5.4 相同的默认费率。如果 Codex 后续支持更多模型,需要更新代码中的 MODEL_PRICING 配置。
两个平台的缓存输入单价均为正常输入的 1⁄10,这是 Anthropic 和 OpenAI 统一采用的缓存折扣策略,也是缓存命中率值得重点关注的原因。
Cache Hit Rate = Cache Read Tokens / (Cache Read Tokens + Input Tokens) × 100% 分母是「缓存读取 + 正常输入」的总量,分子是命中缓存的部分。这个比率越高,说明重复上下文被有效复用的比例越大,实际支出越低。
Output/Input Ratio = Output Tokens / Input Tokens × 100% 这个指标反映模型每次接收单位输入时产生的输出量。比值高意味着模型在「多做事」,比值低可能意味着大量上下文被反复传递但输出较少,是优化 Prompt 效率的参考之一。
热力图按小时粒度对数据进行分桶聚合:
- 横轴:0-23 时(24 个小时)
- 纵轴:周日到周六(7 天)
- 颜色深浅:该时段内 Token 或费用的消耗量,颜色越深表示使用越密集
数据来源是 Claude Code 和 Codex 的会话日志,每条记录根据时间戳归入对应的「星期 × 小时」格子中。悬停可查看具体数值。
TokenDash 会从日志中提取每条记录使用的模型名称(如 claude-sonnet-4-6、claude-opus-4-6、gpt-5.4 等),然后:
- 分布饼图:按模型聚合 Total Tokens 或 Cost,展示占比
- 趋势折线图:按日期展示每个模型的用量变化,最多展示 Top 6 模型以保证可读性
模型名称会自动缩写(如 claude-sonnet-4-6 → Sonnet 4.6),避免图表标签过长。
仅 Claude Code 支持项目维度分析(Codex 也支持,但基于 session 的 cwd 字段推断项目名)。
项目选择器中列出所有检测到的项目,选择特定项目后:
- 所有图表和 KPI 数据仅展示该项目的数据
- 项目分布柱状图会替换为「Per-model breakdown」,展示该项目内各模型的 Token 构成(Cache Read / Input / Output 堆叠柱状图)
推荐全局安装
# 安装成功会自动打开 dashboard npm install -g @zhangferry-dev/tokendash # 后续查看直接运行 cli 命令即可 tokendash 项目地址:https://github.com/zhangferry/tokendash,欢迎 Star 🌟
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/260527.html