
近期,某顶级 AI Agent 研究团队的一个工业级 Harness 项目源码在开发者社区中引起广泛关注。这个项目是一个基于 TypeScript 的 CLI 形态 AI Coding Agent,其工程规模和架构成熟度令社区印象深刻:
"REPL.tsx 单文件 875KB,我以为我看错了小数点。这不是代码,这是一部长篇小说。"
— HN 评论
社区普遍认为,这份源码不仅仅展示了一个产品的实现细节,更像是一本关于如何构建工业级 AI Agent 的技术教科书。
这份源码的规模令人印象深刻——约 1,900 个文件、512,000+ 行代码,完整涵盖了一个工业级 AI Coding Agent 的全部实现细节。对于 AI Agent 的开发者来说,这不啻于拿到了一份由顶级团队验证过的"生产级架构蓝图"。
我们可以从中看到:
- 🧠 顶级团队如何设计一个 Agent Harness 的核心 Loop
- 🛡️ 工具系统的 fail-closed 安全模型如何实现
- ⚡ 50 万行代码级别的 CLI 应用如何做到亚秒级启动
- 🐝 多 Agent 编排(Agent Swarms)的工程实现方式
- 🎮 用 React 写终端 UI 到底是什么体验(答案是:875KB 的 REPL.tsx)
- 🥚 隐藏在代码深处的 Easter Eggs:宠物精灵、梦境系统、年度回顾…
本文将对这份源码进行全面架构拆解,从启动流程到查询引擎,从工具系统到权限模型,再到那些藏在角落里的惊喜彩蛋——最终提炼出构建顶级 Harness 工程的方法论。文章面向有经验的开发者,假设读者了解 TypeScript、React 和 LLM API 基础概念。
阅读指南:全文分为 8 个 Part,每个 Part 可独立阅读。如果时间有限,建议优先阅读 Part 4(查询引擎)和 Part 8(隐藏彩蛋)。如果你是架构师,Part 7 的方法论总结不容错过。
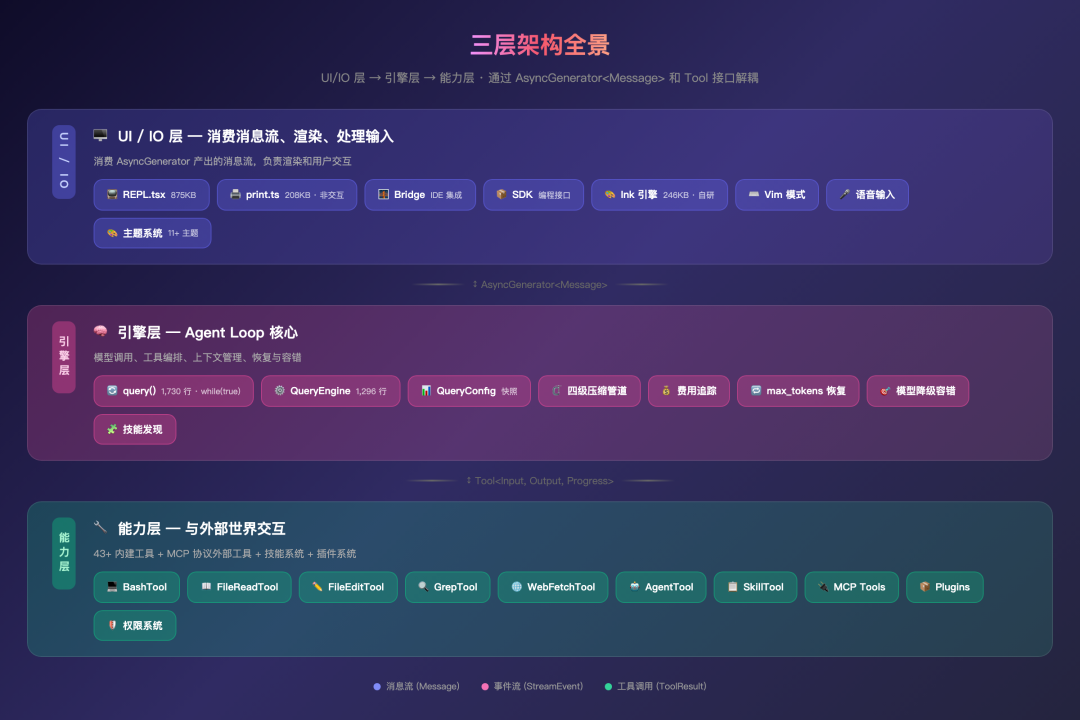
项目三层架构全景
"50 万行 TypeScript,43 个工具,80 个斜杠命令——这不是一个 CLI 工具,这是一个操作系统。"
— 某 HN 评论者
先看几个震撼的数字——当社区第一次跑 cloc 看到结果时,很多人以为统计工具出了 bug:
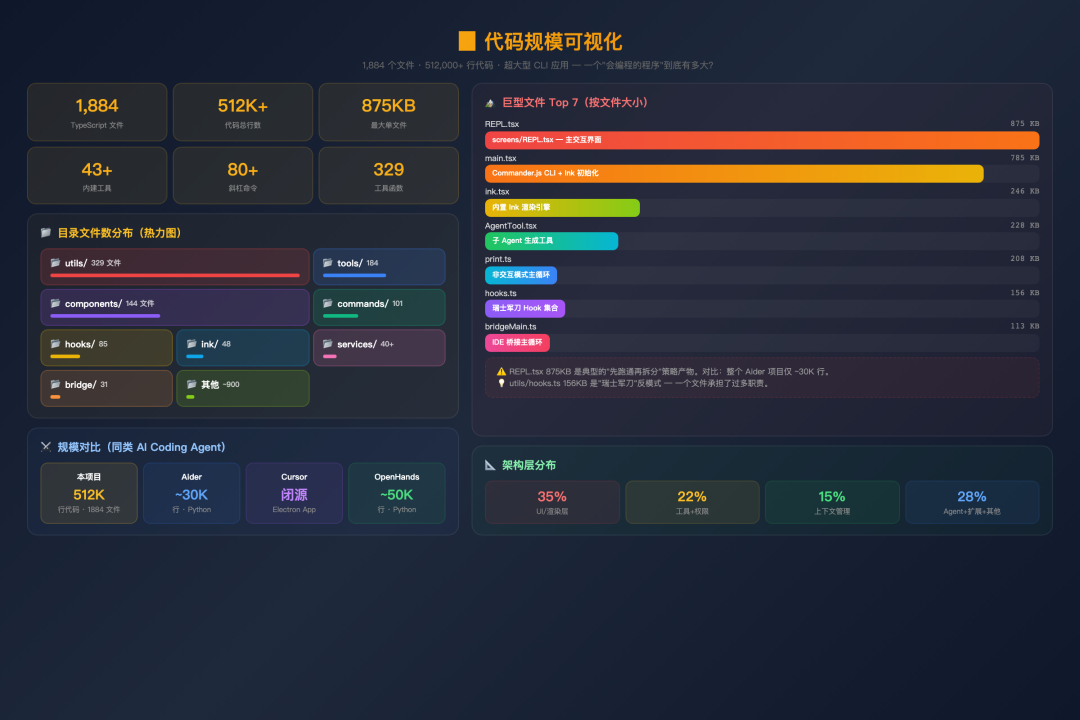
代码规模可视化
.ts + ~552 个
.tsx =
1,884 个文件 代码总行数
512,000+ 行 最大单文件
screens/REPL.tsx —
875 KB(约 25,000 行) 第二大文件
main.tsx —
785 KB(约 4,684 行,编译后膨胀) 系统提示模板
constants/prompts.ts —
53 KB 工具定义目录
src/tools/ —
43 个子目录,184 个文件 斜杠命令
src/commands/ —
101 个子目录/文件,80+ 个命令 React Hooks
src/hooks/ —
85 个文件 UI 组件
src/components/ —
144 个文件 Utility 函数
src/utils/ —
329 个文件
这是一个超大型 CLI 应用——它的代码量超过了大多数 Web 应用的前后端总和。
在源码中翻看 package.json 和构建配置,你会发现一个有趣的现象——这不是一个"什么流行用什么"的技术栈,而是一个每个选型都能追溯到具体性能瓶颈的技术栈:
strict 模式确保类型安全
终端 UI React + Ink 用 React 组件模型构建 TUI,复用 Web 生态的状态管理和组件化思想。但该项目
内置了自己的 Ink 渲染引擎(
src/ink/),而非使用 npm 上的 Ink 包
CLI 解析 Commander.js (extra-typings) 成熟、轻量、TypeScript 友好。
extra-typings 插件提供完整的类型推导
Schema 校验 Zod v4 工具输入校验、配置校验、Hook schema 校验。Zod 的 TypeScript-first 设计与项目的类型优先理念一致
代码搜索 ripgrep 通过
GrepTool 提供极速代码搜索能力。ripgrep 是目前最快的正则搜索工具
协议 MCP SDK + LSP MCP(Model Context Protocol)实现外部工具集成;LSP(Language Server Protocol)提供代码智能
API 客户端 官方模型 SDK 官方 SDK,直接调用模型 API,支持流式响应
遥测 OpenTelemetry + gRPC 行业标准的可观测性框架,但
延迟加载(~400KB OTel + ~700KB gRPC 按需导入)
特性标记 GrowthBook 支持 A/B 测试和渐进式发布。大量功能通过
feature() 门控
认证 OAuth 2.0 + JWT + macOS Keychain 企业级认证方案,Keychain 集成确保凭据安全存储
把 src/ 展开后的第一感觉是——这比很多中型 SaaS 公司的整个后端都大。但令人意外的是,它的组织方式却出奇地清晰:
src/ ├── main.tsx # 主入口(Commander.js CLI 解析器) ├── QueryEngine.ts # 查询引擎(LLM 交互核心) ├── query.ts # 查询循环(AsyncGenerator 实现) ├── Tool.ts # 工具类型定义与 buildTool 工厂 ├── tools.ts # 工具注册表 ├── commands.ts # 命令注册表 ├── context.ts # 系统/用户上下文收集 ├── cost-tracker.ts # 费用追踪 │ ├── entrypoints/ # 入口点(cli.tsx, init.ts, mcp.ts, sdk/) ├── bootstrap/ # 启动状态(state.ts 54KB — 全局原子状态) ├── tools/ # 43 个工具实现(BashTool, FileEditTool...) ├── commands/ # 80+ 斜杠命令(/commit, /review, /compact...) ├── services/ # 外部服务集成(API, MCP, OAuth, 压缩...) ├── components/ # 144 个 Ink UI 组件 ├── hooks/ # 85 个 React Hooks ├── screens/ # 全屏 UI(REPL, Doctor, Resume) ├── state/ # 状态管理(极简 Store 模式) ├── types/ # TypeScript 类型定义 ├── utils/ # 329 个工具函数(最大的目录) │ ├── bridge/ # IDE 桥接(VS Code, JetBrains 集成) ├── coordinator/ # 多 Agent 协调器 ├── tasks/ # 任务系统(6 种 TaskType) ├── plugins/ # 插件系统 ├── skills/ # 技能系统(Markdown 驱动的能力扩展) ├── memdir/ # 持久化记忆管理 ├── keybindings/ # 键绑定系统 ├── vim/ # Vim 模式仿真 ├── ink/ # 内置 Ink 渲染引擎 ├── query/ # 查询管道(config, deps, stopHooks) ├── remote/ # 远程会话管理 ├── cli/ # 非交互模式(print.ts 208KB) ├── migrations/ # 配置迁移(11 个脚本) ├── buddy/ # 伴侣精灵(Easter egg) └── voice/ # 语音输入支持关键架构洞察:
- 入口分层:
entrypoints/cli.tsx→main.tsx→setup.ts,三层入口分别处理 fast-path、CLI 解析、会话初始化 - 核心与外围分离:
query.ts+QueryEngine.ts+Tool.ts构成核心引擎,其他模块都是外围 - utils 膨胀问题:
src/utils/有 329 个文件、远超其他目录,说明工具函数缺乏进一步的模块化。utils/hooks.ts单文件 156KB,是典型的"瑞士军刀"反模式
将该项目与其他主流 AI Coding 工具进行对比:
该项目在工程复杂度上远超同类——它不只是一个 CLI 工具,而是一个完整的 Agent 平台。
从 Part 1 可以提炼出几个核心设计决策:
- Bun 而非 Node.js:对 CLI 工具来说,冷启动性能是决定用户体验的第一要素。Bun 的启动速度优势和内置 bundler 的 dead code elimination(
feature()门控)使其成为最优选择 - React 写终端 UI:虽然 875KB 的 REPL.tsx 令人窒息,但 React 的组件化和声明式 UI 确实适合构建复杂的交互界面。内置 Ink 引擎(而非依赖 npm 包)说明 团队需要对渲染层有完全的控制权
- TypeScript strict 模式:50 万行代码的可维护性完全依赖类型系统。从
DeepImmutable到z.infer再到泛型Tool,类型贯穿了每一层 - 极简自研 Store:没有使用 Redux/Zustand,而是用 34 行代码 实现了一个符合
useSyncExternalStore契约的 Store(src/state/store.ts)。这对性能敏感的 CLI 应用来说是正确的选择——第三方状态库的 overhead 在这里是不可接受的
CLI 工具的启动速度是用户体验的生死线。该项目为此设计了一套精密的分层启动架构,核心思想是:能不加载的就不加载,能并行的就并行,能延迟的就延迟。
"我做了个实验,
agent --version只要 12ms。作为对比,node --version要 50ms。他们到底怎么做到的?"
— @nicolo_ribaudo
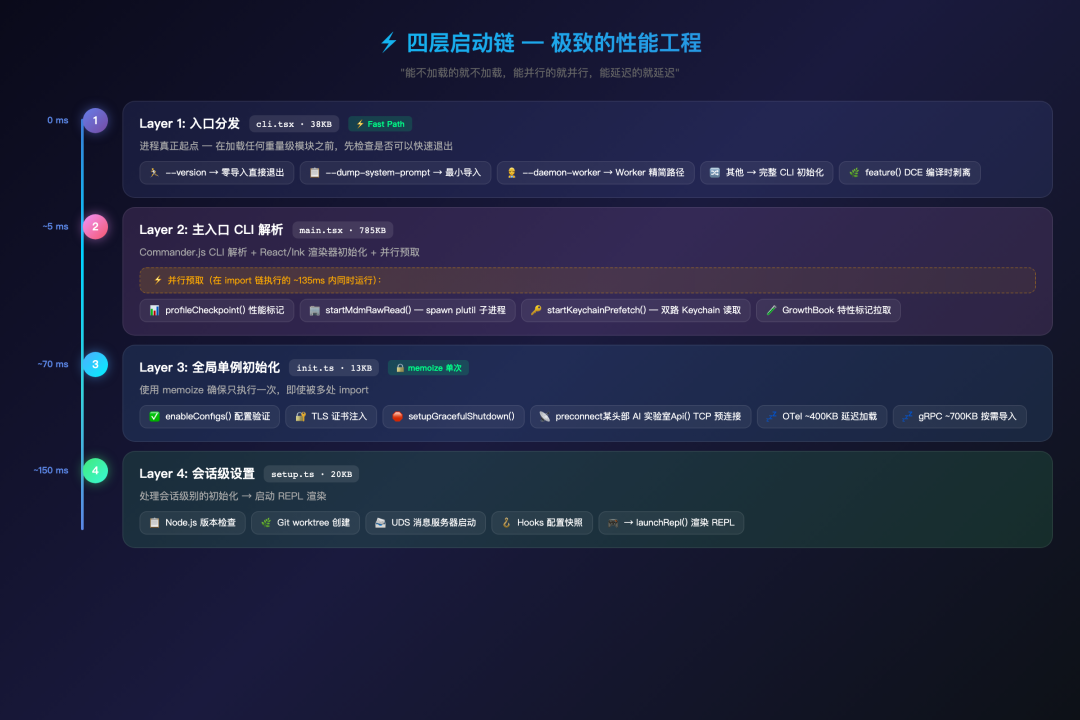
四层启动链
Layer 1: entrypoints/cli.tsx — 入口分发
这是进程的真正起点。它的核心设计是 Fast Path 优先——在加载任何重量级模块之前,先检查是否可以快速退出:
# Python 伪代码重构 -- 展示核心设计思路 # Fast Path: 零模块加载,直接输出版本号退出 if args[0] in ('--version', '-v'): print(f"{BUILD_VERSION} (Agent CLI)") # 版本号在构建时内联 sys.exit(0)所有后续路径都使用延迟导入(lazy import),确保只加载当前路径需要的模块:
# Python 伪代码重构 -- 展示核心设计思路 # 每个路径只按需导入对应模块 if is_feature_enabled('DAEMON') and args[0] == '--daemon-worker': from daemon.worker_registry import run_daemon_worker # 延迟导入 await run_daemon_worker(args[1]) returnfeature() 是 Bun bundler 的编译时特性门控——不激活的代码在构建时被完全剥离(Dead Code Elimination),不会出现在最终产物中。
Layer 2: main.tsx — 主入口(4,684 行)
这是 CLI 解析和 UI 渲染器初始化的核心。它在模块加载阶段并行启动三个耗时操作:
# Python 伪代码重构 -- 展示核心设计思路 # 这三个任务在所有后续 import 之前并行启动! mark_checkpoint('main_entry') # 标记入口时间 mdm_task = asyncio.create_task(read_mdm_settings()) # 并行启动 MDM 子进程 keychain_task = asyncio.create_task(prefetch_keychain()) # 并行启动 Keychain 双路读取这是并行预取(Parallel Prefetch) 模式:MDM 设置读取需要 spawn 一个子进程(plutil on macOS),Keychain 读取需要两次同步 spawn(OAuth token + legacy API key)。如果串行等待,这些操作会增加 ~65ms 启动延迟。通过在模块评估阶段就启动它们,这些 I/O 操作与后续 ~135ms 的 import 链并行执行。
Layer 3: entrypoints/init.ts — 全局初始化
使用 memoize 确保只执行一次(即使被多处 import):
# Python 伪代码重构 -- 展示核心设计思路 @run_once # 等价于 memoize,确保只执行一次 async def initialize(): validate_configs() # 验证配置 apply_safe_env_variables() # 安全环境变量 apply_extra_ca_certs() # TLS 证书(必须在首次握手前) setup_graceful_shutdown() # 优雅退出 # OpenTelemetry (~400KB) 此处延迟加载... configure_global_agents() # 代理配置 start_loading_policy_limits() # 组织策略限制 preconnect_model_api() # API 预连接(仅建立 TCP,不发请求)注意 preconnectModelApi() — 它在初始化阶段就建立 TCP 连接(不发送请求),这样当真正需要调用 API 时,TLS 握手已经完成。
Layer 4: setup.ts — 会话设置
处理会话级别的初始化,包括 Node.js 版本检查、Git worktree 创建、UDS 消息服务器启动、Hooks 配置快照等。
该项目对重量级模块采用极致的延迟加载:
-p)完全不加载 内部命令模块
insights.ts 113KB 懒加载 shim,用户执行
/insights 时才加载 Sentry 较大
is_feature_enabled() 特性开关,外部构建剥离
# Python 伪代码重构 -- 展示核心设计思路 # 懒加载 shim:命令定义是同步的,实际逻辑延迟到首次调用时导入 usage_report = async def _lazy_load_insights(args, context): from commands.insights import handler # 首次调用时才导入 113KB 模块 return await handler.get_prompt(args, context)- Fast Path 模式:将最常用的快速操作(
--version)放在最前面,零依赖直接返回。这在所有 CLI 工具中都应该是标配 - 并行预取 vs 串行阻塞:Keychain、MDM、GrowthBook 的并行启动节省了关键路径上的 60-100ms
is_feature_enabled()特性开关的 DCE:构建工具在构建时根据特性标记剥离整个代码块。这意味着外部用户拿到的构建产物中不包含内部工具(如REPLTool、TungstenTool)memoize单例模式:init()、getCommands()、getUserContext()等函数都用memoize包裹,确保重量级初始化只执行一次,后续调用直接返回缓存值
工具系统是该项目的能力基座——模型通过工具与外部世界交互。这个系统的设计融合了类型安全、fail-closed 安全默认、条件编译三大理念。
"看完他们的 buildTool() 默认值设计,我回去把自己项目的权限系统全部重写了。Fail-closed 不是一个理念,是一种信仰。"
— @LangChainDev

工具系统架构
每个工具都是一个实现了 Tool
泛型接口的对象,定义在 src/Tool.ts(793 行)中:
type Tool< Input extends AnyObject = AnyObject, Output = unknown, P extends ToolProgressData = ToolProgressData, > = 每个方法都有明确的职责,关键设计点:
inputSchema:使用 Zod 模型定义,提供运行时校验和静态类型检查checkPermissions:工具特定的权限逻辑,在通用权限系统之上isConcurrencySafe:控制流式并行执行——只有标记为并发安全的工具才能与其他工具并行isDestructive:标记不可逆操作(delete、overwrite、send),影响权限策略toAutoClassifierInput:为 auto 模式的安全分类器提供紧凑表示
buildTool() 是所有工具的必经工厂函数,它提供安全默认值:
# Python 伪代码重构 -- 展示核心设计思路 TOOL_DEFAULTS = { "isEnabled": lambda: True, "isConcurrencySafe": lambda: False, # 假设不安全 "isReadOnly": lambda: False, # 假设会写入 "isDestructive": lambda: False, "checkPermissions": lambda input: # 交给通用权限系统 Promise.resolve({ behavior: 'allow', updatedInput: input }), "toAutoClassifierInput": lambda: '', # 跳过分类器 "userFacingName": lambda: '', } def buildTool(def): return {TOOL_DEFAULTS, userFacingName: lambda: def.name, def}Fail-Closed 原则:isConcurrencySafe 默认 False(假设不安全),isReadOnly 默认 False(假设会写入)。这意味着忘记设置这些字段的工具会被当作最受限的情况处理——安全优先。
src/tools.ts(390 行)中的 getAllBaseTools() 是所有工具的唯一来源:
# Python 伪代码重构 -- 展示核心设计思路 def getAllBaseTools(): Tools return [ AgentTool, BashTool, (hasEmbeddedSearchTools() ? [] : [GlobTool, GrepTool]), # 条件排除 FileReadTool, FileEditTool, FileWriteTool, NotebookEditTool, WebFetchTool, WebSearchTool, TodoWriteTool, SkillTool, AskUserQuestionTool, (process.env.USER_TYPE == 'ant' ? [ConfigTool, TungstenTool] : []), # 内部工具 (SleepTool ? [SleepTool] : []), # feature() 门控 (MonitorTool ? [MonitorTool] : []), (isAgentSwarmsEnabled() ? [TeamCreateTool, TeamDeleteTool] : []), # 更多条件工具 ]条件加载有三种机制:
is_feature_enabled()编译时特性开关:SleepTool = import_module('tools.SleepTool') if is_feature_enabled('PROACTIVE') else None— 外部构建中完全不存在os.environ运行时开关:os.environ.get('USER_TYPE') == 'ant'— 内部用户独有的工具- 特性检测开关:
has_embedded_search_tools()— 当搜索工具已嵌入二进制时,跳过独立的 Glob/Grep
assembleToolPool() 将内建工具与 MCP 工具合并,是工具系统的最终出口:
# Python 伪代码重构 -- 展示核心设计思路 def assemble_tool_pool(perm_context, mcp_tools): """合并内建工具与 MCP 工具,分区排序保 prompt cache 稳定性""" builtin = get_tools(perm_context) allowed_mcp = filter_by_deny_rules(mcp_tools, perm_context) # 关键:内建和 MCP 分别排序后拼接,不混合排序 sorted_builtin = sorted(builtin, key=lambda t: t.name) sorted_mcp = sorted(allowed_mcp, key=lambda t: t.name) combined = sorted_builtin + sorted_mcp return deduplicate_by_name(combined)关键设计:内建工具和 MCP 工具分别排序后拼接,而非混合排序。这是为了 prompt cache 稳定性——API 端的缓存策略在最后一个内建工具处放置断点,混合排序会在添加/删除 MCP 工具时使所有下游缓存失效。
StreamingToolExecutor(src/services/tools/StreamingToolExecutor.ts)是工具执行的核心创新:
# Python 伪代码重构 -- 展示核心设计思路 type ToolStatus = 'queued' | 'executing' | 'completed' | 'yielded' class StreamingToolExecutor: private tools = [] private siblingAbortController: AbortController # 兄弟级取消 addTool(block, assistantMessage): void isConcurrencySafe = toolDefinition.isConcurrencySafe(parsedInput.data) this.tools.push({ id, block, status: 'queued', isConcurrencySafe, }) void this.processQueue() private canExecuteTool(isConcurrencySafe): boolean executing = this.tools.filter(t => t.status == 'executing') return executing.length == 0 || (isConcurrencySafe && executing.every(t => t.isConcurrencySafe))并发控制规则:
- 并发安全工具(如
GlobTool,GrepTool,FileReadTool)可以彼此并行执行 - 非并发工具(如
BashTool,FileEditTool)必须独占执行 - 当一个 Bash 工具出错时,
siblingAbortController会取消所有兄弟工具,但不会终止父级(query.ts不会结束回合)
这意味着当模型同时请求读取 3 个文件时,这 3 个读取操作会真正并行执行,而不是排队等待。
BashTool Shell 命令执行 否 否
FileReadTool 文件读取(支持图片、PDF、notebook) 是 是
FileEditTool 部分文件修改(字符串替换) 否 否
FileWriteTool 文件创建/覆盖 否 否
GlobTool 文件模式匹配搜索 是 是
GrepTool ripgrep 内容搜索 是 是
AgentTool 子 Agent 生成 否 否
SkillTool 技能执行 否 否
WebFetchTool URL 内容获取 是 是
WebSearchTool Web 搜索 是 是
TodoWriteTool 待办列表管理 否 否
MCPTool MCP 服务器工具调用 视工具而定 视工具而定
AskUserQuestionTool 向用户提问 否 是
SendMessageTool 跨 Agent 消息传递 否 否
- Fail-Closed > Fail-Open:
buildTool()的默认值全部偏向保守。这是安全系统设计的黄金法则——遗漏不会导致权限逃逸 - 编译时 + 运行时双重开关:
is_feature_enabled()用于构建产物的 DCE,os.environ用于运行时的特性开关。两层开关确保内部功能不会暴露给外部用户 - 排序稳定性 = 缓存效率:工具列表的排序策略直接影响 API prompt cache 的命中率。这种"看似无关紧要的排序"背后是真金白银的成本节约
- 并发安全标记是工具自己声明的:通过
isConcurrencySafe方法,每个工具根据自己的输入判断是否可以并行。例如FileReadTool总是安全的,但BashTool根据命令内容判断
如果说工具系统是 该项目的"手脚",那么查询引擎就是它的"大脑回路"。query.ts(1,730 行)和 QueryEngine.ts(1,296 行)构成了整个 Agent 的核心循环——它决定了模型如何思考、何时行动、怎样恢复。
"看完 query.ts 的 AsyncGenerator 设计,我终于理解了为什么所有 Agent 框架都在重新发明这个轮子——因为他们没有发明对。"
— @swyx
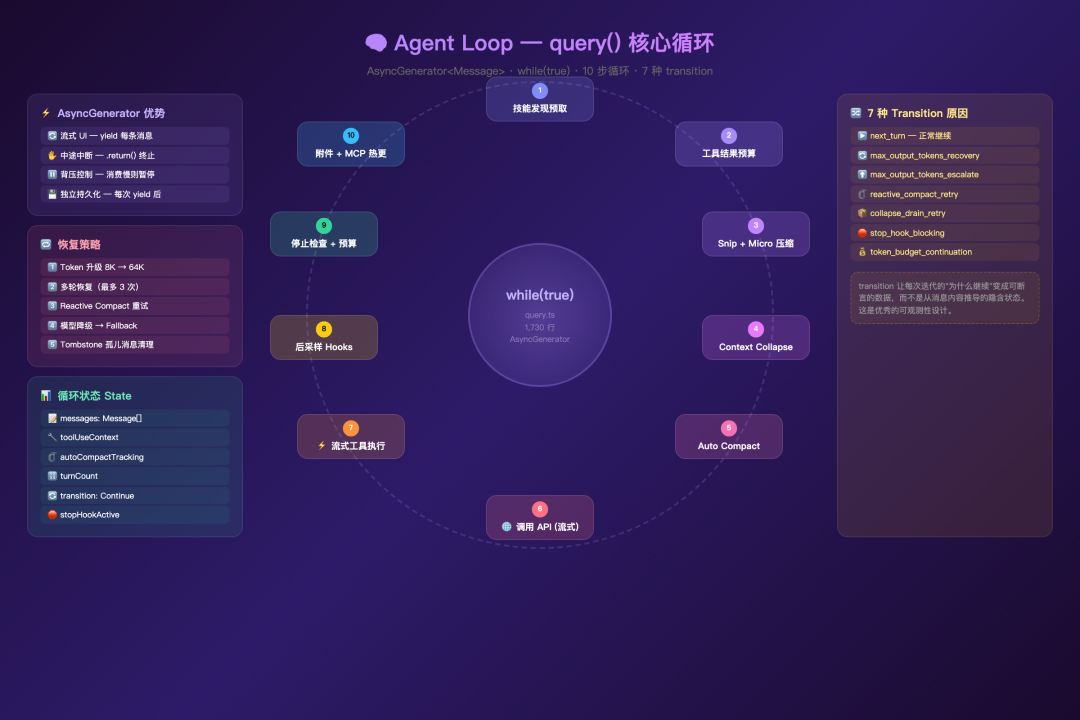
Agent Loop 核心循环
query() 函数是一个异步生成器(async generator),这是整个架构最核心的设计决策:
# Python 伪代码重构 -- 展示核心设计思路 async def query(params): AsyncGenerator< StreamEvent | RequestStartEvent | Message | TombstoneMessage | ToolUseSummaryMessage, Terminal > # 状态初始化 while(true) # 1. 技能发现预取 # 2. 工具结果预算应用 # 3. Snip 压缩 # 4. 微压缩(microcompact) # 5. 上下文折叠(Context Collapse) # 6. 自动压缩(autocompact) # 7. 阻塞限制检查 # 8. 调用 API(流式) # 9. 流式工具执行 # 10. 后采样 Hooks # 11. 中断处理 # 12. 停止 Hooks # 13. Token 预算检查 # 14. 附件消息(记忆预取、技能发现、命令队列) # 15. 刷新工具列表(MCP 热更新) # 16. 继续下一轮为什么选择异步生成器?
- 流式 UI 更新:
yield每条消息,调用方通过async for实时消费并渲染 - 中途中断:用户按 Ctrl+C 时,生成器可以在任意
yield点被.close()终止 - 背压控制:消费方处理慢时,生产方自然暂停(不会缓冲无限消息)
- 每条消息独立持久化:每次
yield后,消息可以被写入 transcript
循环的可变状态被封装在一个 State 对象中,每次迭代从中解构:
# Python 伪代码重构 -- 展示核心设计思路 type State = { messages: Message[] toolUseContext: ToolUseContext autoCompactTracking: AutoCompactTrackingState | undefined maxOutputTokensRecoveryCount: number # 最多恢复 3 次 hasAttemptedReactiveCompact: boolean turnCount: number transition: Continue | undefined # 上一次迭代为何继续 pendingToolUseSummary: Promise | undefined stopHookActive: boolean | undefined }transition 字段记录了上一次迭代的"继续原因"——这是一个精妙的设计,让测试可以断言恢复路径被触发,而无需检查消息内容:
# Python 伪代码重构 -- 展示核心设计思路 type Continue = { reason: 'next_turn' } | { reason: 'max_output_tokens_recovery'; attempt: number } | { reason: 'max_output_tokens_escalate' } | { reason: 'reactive_compact_retry' } | { reason: 'collapse_drain_retry'; committed: number } | { reason: 'stop_hook_blocking' } | 随着对话变长,上下文窗口逐渐耗尽。该项目设计了四级压缩管道来应对——这是整个系统最优雅的"渐进降级"设计之一:

四级压缩管道
- Level 1 — Snip Compact:基于标记的历史裁剪。在消息流中找到 snip 边界标记,移除标记之前的消息。最轻量,无需 API 调用。
- Level 2 — Micro Compact:缓存编辑压缩。利用 API 的 cache editing 能力,在不破坏整体缓存的情况下删除特定工具调用的结果。
- Level 3 — Context Collapse:上下文折叠。将多轮工具调用结果折叠为摘要,但保留结构。这是一个读时投影——折叠视图在每次发送前重新计算,原始消息仍然保存在 REPL 的完整历史中。
- Level 4 — Auto Compact:全量摘要压缩。当上下文接近窗口限制时,使用 LLM 生成对话摘要替换历史消息。这是最重的操作,但也是最后的防线。
# Python 伪代码重构 -- 展示核心设计思路 # 自动压缩阈值计算 def getEffectiveContextWindowSize(model): reservedTokensForSummary = Math.min( getMaxOutputTokensForModel(model), 20_000, # 基于 p99.99 数据(17,387 tokens) ) contextWindow = getContextWindowForModel(model, getSdkBetas()) # 支持环境变量覆盖 override = process.env.AGENT_AUTO_COMPACT_WINDOW if (override) contextWindow = Math.min(contextWindow, parseInt(override)) return contextWindow - reservedTokensForSummary当模型输出被截断时(stop_reason === 'max_output_tokens'),该系统有三层恢复策略:
- Token 升级:如果使用了默认的 8K 上限,先尝试升级到 64K,重新发送同一个请求
- 多轮恢复(最多 3 次):注入恢复消息,要求模型从中断处继续
# Python 伪代码重构 -- 展示核心设计思路 recoveryMessage = createUserMessage( content: `Output token limit hit. Resume directly — no apology, no recap of what you were doing. ` + `Pick up mid-thought if that is where the cut happened. Break remaining work into smaller pieces.`, isMeta, )- 放弃:3 次恢复后仍然截断,surface 错误
# Python 伪代码重构 -- 展示核心设计思路 # 流式响应中检测到 fallback for await (message of deps.callModel( )): if (streamingFallbackOccured) # 为孤儿消息生成 tombstones(thinking blocks 有签名,不能跨模型重放) for (msg of assistantMessages) yield { type: 'tombstone', message: msg } # 清空状态,重置 StreamingToolExecutor assistantMessages.length = 0 streamingToolExecutor?.discard() streamingToolExecutor = new StreamingToolExecutor(tools, canUseTool, context)当主模型过载时,API 返回 FallbackTriggeredError,该系统会:
- 为所有已产出的消息生成 tombstone(告知 UI 移除这些消息)
- 清空 assistant 消息和工具结果
- 丢弃流式工具执行器并创建新的
- 切换到 fallback 模型重试
- 如果有 thinking 签名(模型绑定),strip 签名块防止 400 错误
QueryEngine(src/QueryEngine.ts)封装了完整的查询生命周期,每个对话一个实例:
# Python 伪代码重构 -- 展示核心设计思路 class QueryEngine: private mutableMessages: Message[] private abortController: AbortController private totalUsage: NonNullableUsage private readFileState: FileStateCache async *submitMessage(prompt, options?): AsyncGenerator # 1. 处理用户输入(slash 命令解析、附件处理) # 2. 构建系统提示词 # 3. 注册结构化输出强制执行 # 4. 进入 query() 循环 # 5. 处理每条消息(持久化、费用累计、权限追踪) # 6. 检查预算限制QueryEngine 提供了依赖注入能力——测试可以通过 QueryDeps 注入 fake 依赖:
# Python 伪代码重构 -- 展示核心设计思路 # src/query/deps.ts — 只有 34 行 type QueryDeps = { callModel: typeof queryModelWithStreaming microcompact: typeof microcompactMessages autocompact: typeof autoCompactIfNeeded uuid: lambda: string }这避免了测试中常见的 mock 模式——使用函数签名类型引用确保依赖签名与真实实现同步,不会因为重构而静默破坏测试。
QueryConfig(src/query/config.ts)在查询入口处一次性快照不可变环境状态:
# Python 伪代码重构 -- 展示核心设计思路 type QueryConfig = { sessionId: SessionId gates: { streamingToolExecution: boolean # Statsig 门控 emitToolUseSummaries: boolean # 工具使用摘要 isAnt: boolean # 内部用户 fastModeEnabled: boolean # 快速模式 } }为什么快照而不是实时读取?因为 Statsig/GrowthBook 的值可以在会话中变化(服务端推送),如果每次迭代都读取,同一个查询的不同迭代可能行为不一致,导致难以复现的 bug。快照确保一个 query() 调用内的行为是确定性的。
除了客户端的 token 估算,该系统还支持 API 侧的 task_budget:
# Python 伪代码重构 -- 展示核心设计思路 # 每次 compact 后计算剩余预算 if (params.taskBudget): preCompactContext = finalContextTokensFromLastResponse(messagesForQuery) taskBudgetRemaining = Math.max( 0, (taskBudgetRemaining ?? params.taskBudget.total) - preCompactContext, )这个预算会随请求发送到 API(output_config.task_budget),服务端据此控制总输出量。compact 后由于服务端看不到被摘要掉的历史,客户端需要手动计算并传递 remaining。
- 异步生成器是 Agent Loop 的**抽象:它天然支持流式、中断、背压,比 callback 或 Observable 更简洁。
yield from实现了子生成器委托(如handleStopHooks),保持了控制流的清晰 - 四级压缩管道体现了"渐进降级"思想:从轻量裁剪到全量摘要,每一级都有明确的触发条件和回退路径
- 配置快照 > 实时读取:在长时间运行的循环中,快照关键配置可以避免由外部状态变化引起的不确定行为
- 依赖注入而非 mock:
QueryDeps的 4 个字段覆盖了测试中最常 mock 的依赖,用函数签名类型引用保持类型同步 - transition 追踪是优秀的可观测性设计:它让每次循环迭代的"为什么继续"变成了可断言的数据,而不是需要从消息内容推导的隐含状态
该项目不只是一个单一 Agent——它是一个完整的多 Agent 平台,支持子 Agent 生成、团队协作、后台任务、甚至"梦境"模式。
"等一下,他们的任务系统里有一个叫 'dream' 的类型?该系统会做梦??"
— 某 AI 研究员在 Twitter 的反应

多 Agent 编排架构
src/Task.ts 定义了七种任务类型,每种都有独立的生命周期管理:
# Python 伪代码重构 -- 展示核心设计思路 type TaskType = | 'local_bash' # Shell 命令(后台进程) | 'local_agent' # 本地子 Agent(独立进程) | 'remote_agent' # 远程 Agent(WebSocket 连接) | 'in_process_teammate' # 进程内队友(共享内存) | 'local_workflow' # 本地工作流脚本 | 'monitor_mcp' # MCP 监控任务 | 'dream' # "梦境"任务(后台分析) type TaskStatus = 'pending' | 'running' | 'completed' | 'failed' | 'killed'任务 ID 设计非常考究——每种类型有独立的前缀字母:
# Python 伪代码重构 -- 展示核心设计思路 TASK_ID_PREFIXES = { local_bash: 'b', # b12345abc local_agent: 'a', # a12345abc remote_agent: 'r', # r12345abc in_process_teammate: 't', # t12345abc local_workflow: 'w', # w12345abc monitor_mcp: 'm', # m12345abc dream: 'd', # d12345abc }8 个字符的随机后缀使用 [0-9a-z] 字母表(36^8 ≈ 2.8 万亿组合),足以抵抗暴力枚举攻击(symlink 攻击场景)。
AgentTool(src/tools/AgentTool/AgentTool.tsx,228 KB)是最复杂的工具之一。模型通过调用 AgentTool 生成子 Agent,子 Agent 拥有自己的对话历史和工具集。
子 Agent 的关键约束:
- 工具白名单:子 Agent 不能使用
AgentTool(防止递归生成)、TeamCreateTool、TeamDeleteTool等管理工具 - 权限继承:子 Agent 继承父级的权限上下文
- 独立的 AbortController:子 Agent 可以被独立取消
当 AGENT_COORDINATOR_MODE=1 时,主线程变成协调器,只负责分配任务,所有实际工作由 worker Agent 完成:
# Python 伪代码重构 -- 展示核心设计思路 # src/coordinator/coordinatorMode.ts def getCoordinatorUserContext(mcpClients, scratchpadDir?): if (!isCoordinatorMode()): return workerTools = isEnvTruthy(process.env.AGENT_SIMPLE) ? ['BASH_TOOL_NAME', 'FILE_READ_TOOL_NAME', 'FILE_EDIT_TOOL_NAME'].sort().join(', ') : Array.from(ASYNC_AGENT_ALLOWED_TOOLS) .filter(name => !INTERNAL_WORKER_TOOLS.has(name)) .sort().join(', ') return coordinatorContext: `Workers spawned via AgentTool have access to: $workerTools`协调器模式下的工具分配:
- 协调器线程:只有
AgentTool+TaskStopTool+SendMessageTool - Worker Agent:拥有
ASYNC_AGENT_ALLOWED_TOOLS中的所有工具(Bash、File Read/Edit/Write、Grep、Glob 等)
这种分离确保协调器不会自己动手——它只负责高层决策和任务分配。
通过 TeamCreateTool 和 TeamDeleteTool,该项目支持团队级并行工作:
- 主 Agent 可以创建"团队",spawn 多个 teammate
- Teammates 通过
SendMessageTool进行跨 Agent 消息传递 InProcessTeammateTask在同一进程内运行(共享内存),适合轻量协作RemoteAgentTask通过 WebSocket 连接远程 Agent,支持跨机器协作
进程内 Teammate 的通信通过 Unix Domain Socket (UDS) 实现:
# Python 伪代码重构 -- 展示核心设计思路 # 会话初始化时启动 UDS 消息服务器 if is_feature_enabled('UDS_INBOX'): from utils.uds_messaging import start_uds_messaging, get_default_socket_path await start_uds_messaging( socket_path or get_default_socket_path(), is_explicit=(socket_path is not None), )DreamTask 是一个独特的任务类型——它在后台运行分析任务,类似于模型在"做梦"。这可能用于:代码理解、依赖分析、或预测性的上下文准备。
- 任务类型的枚举设计:7 种明确的 TaskType 比 "generic task + metadata" 更安全——每种类型有独立的 spawn/kill 逻辑,不会出现类型混淆
- Coordinator 模式的关注点分离:协调器不拥有文件操作工具,确保决策层和执行层分离。这与微服务架构中的"控制面 vs 数据面"理念一致
- UDS 通信 vs HTTP:进程内 teammate 使用 Unix Domain Socket 而非 HTTP,避免了 TCP/IP 栈的 overhead(~50μs vs ~500μs RTT)
- ID 前缀设计是运维友好的:看到
b12345abc就知道是 bash 任务,看到a12345abc就知道是 agent 任务,无需查询数据库
"等一下,他们用 React 写终端 UI?而且还不是用 npm 上的 Ink,是自己 fork 了一套?246KB 的渲染引擎?这到底是 CLI 工具还是浏览器?"
— 某资深前端开发者的困惑
该项目使用 React + Ink 构建终端 UI——但它不是简单地引用了 Ink npm 包,而是完全内置了自己的 Ink 渲染引擎(src/ink/,48 个文件,核心文件 246KB)。这个决策背后的信号很明确:当你的产品需要对渲染层有完全的控制权时,fork 比依赖更高效。
src/ink/ 目录包含 48 个文件,是一个完整的终端渲染引擎:
ink.tsx
246 KB 核心渲染引擎
screen.ts 48 KB 屏幕管理(区域裁剪、虚拟化)
render-node-to-output.ts 62 KB 虚拟 DOM 节点 → 终端输出
selection.ts 34 KB 文本选择系统
output.ts 26 KB 输出缓冲区管理
log-update.ts 27 KB 增量屏幕更新
parse-keypress.ts 23 KB 键盘输入解析
reconciler.ts 14 KB React Reconciler
dom.ts 15 KB 虚拟 DOM
styles.ts 20 KB 样式系统(Flexbox 布局)
为什么内置而不用 npm 包?原因可能包括:
- 性能定制:246KB 的 ink.tsx 包含了大量针对该项目场景的优化
- Bug 修复自主权:不受上游发布周期限制
- 功能扩展:如点击事件(
ClickEvent)、终端焦点检测(TerminalFocusEvent)、超链接支持等 - 构建优化:与 Bun bundler 的 tree-shaking 深度集成
src/screens/REPL.tsx 是整个项目最大的单文件——875 KB。它是主交互界面的核心,包含:
- 消息渲染与虚拟滚动
- 输入框管理(包括 Vim 模式)
- 工具权限对话框
- 模型切换
- 会话管理
- 后台任务面板
- MCP 服务器管理
- ...以及更多
这是一个值得警惕的反模式——单个组件 875KB 意味着极高的认知负担和维护成本。但在快节奏的创业公司中,这种"先跑通再拆分"的策略并不罕见。
该系统有一套自己的终端设计系统:
src/components/design-system/ ├── ThemeProvider.tsx # 主题提供者(支持 11+ 主题) ├── ThemedBox.tsx # 带主题的盒子组件 ├── ThemedText.tsx # 带主题的文本组件 ├── Dialog.tsx # 对话框 ├── FuzzyPicker.tsx # 模糊搜索选择器 ├── Tabs.tsx # 标签页 ├── ProgressBar.tsx # 进度条 ├── StatusIcon.tsx # 状态图标 ├── Divider.tsx # 分割线 ├── ListItem.tsx # 列表项 └── ...ThemeProvider 通过 React Context 注入主题配置,ThemedBox 和 ThemedText 根据当前主题自动应用颜色。这与 Web 端的 Styled Components / CSS Variables 模式异曲同工。
src/keybindings/ 实现了一套完整的键绑定框架:
keybindings/ ├── defaultBindings.ts # 默认键绑定(11 KB) ├── loadUserBindings.ts # 用户自定义绑定加载 ├── parser.ts # 快捷键字符串解析("Ctrl+Shift+P" → 结构化表示) ├── resolver.ts # 冲突解决 ├── validate.ts # 绑定验证(13 KB) ├── schema.ts # Zod schema ├── KeybindingContext.tsx # React Context └── KeybindingProviderSetup.tsx # Provider 初始化支持用户通过配置文件自定义键绑定,并自动检测与默认绑定的冲突。
src/vim/ 实现了一个完整的 Vim 仿真:
motions.ts— 移动命令(h/j/k/l, w/b/e, 0/$, gg/G)operators.ts— 操作符(d, c, y, p 及其组合)textObjects.ts— 文本对象(iw, aw, i", a", ip, ap 等)transitions.ts— 模式转换(Normal → Insert → Visual → Command)types.ts— 完整的 Vim 状态类型定义
这不是一个玩具级的 Vim 仿真——它支持操作符 + 动作的组合(如 diw 删除内部单词),以及文本对象的完整语义。
src/bridge/(31 个文件)是 该项目与 IDE 扩展(VS Code, JetBrains)之间的双向通信层:
bridgeMain.ts
113 KB 桥接主循环
replBridge.ts
98 KB REPL 会话桥接
remoteBridgeCore.ts 39 KB 远程桥接核心
sessionRunner.ts 18 KB 会话执行管理
jwtUtils.ts 9 KB JWT 认证
trustedDevice.ts 8 KB 设备信任管理
桥接系统支持两种模式:
- 本地桥接:CLI 在本地运行,通过 IPC 与 IDE 扩展通信
- 远程桥接:CLI 运行在远程服务器,通过 WebSocket + JWT 认证与本地 IDE 通信
- 记忆系统(
src/memdir/):持久化记忆管理,支持团队记忆同步。模型可以将学到的知识存储到~/.agent/memory/,在后续会话中自动回忆 - 历史记录(
src/history.ts):JSONL 格式存储在~/.agent/history.jsonl,支持粘贴内容引用(大文本通过 hash 存储到外部 paste store),使用文件锁防止并发写入 - 伙伴精灵(
src/buddy/):一个 Easter egg——CompanionSprite.tsx(45KB)实现了一个终端中的小精灵动画 - 语音输入(
src/voice/):通过流式 STT(Speech-to-Text)支持语音输入
- 内置渲染引擎是大胆但合理的选择:当你的产品对渲染性能有极致要求、且需要频繁修复上游 bug 时,fork 比依赖更高效。但维护成本不可忽视
- REPL.tsx 的 875KB 是技术债务:即使在快速迭代阶段,单文件超过 100KB 都应该触发重构警报。这个文件可能需要拆分为 10+ 个独立模块
- Vim 模式的 ROI 值得商榷:完整 Vim 仿真的开发和维护成本很高,但对于面向开发者的 CLI 工具来说,它的存在本身就是一种"我们理解你"的信号
- 桥接系统的分层设计非常干净:本地 IPC / 远程 WebSocket + JWT / 设备信任,三层安全模型各司其职
"LangChain 做了一个实验:同一个模型,仅改变外部 Harness,TerminalBench 排名从第 30 跃升到第 5。瓶颈从来不在模型智能,而在基础设施。"
— LangChain Blog, 2026
2026 年初,一个新术语席卷了整个 AI 工程圈:Harness Engineering(驾驭工程)。
Mitchell Hashimoto(HashiCorp 创始人)在博客里首次提出这个概念,OpenAI 紧接着发布了"5 人团队 5 个月产出百万行代码"的实验报告,某头部 AI 实验室发布了《Effective Harnesses for Long-Running Agents》,Martin Fowler 旗下的 Birgitta Böckeler 撰写了深度分析……一时间,所有顶级团队都在讨论同一个问题:
Agent = Model + Harness。模型是引擎,Harness 是缰绳、护栏和高速公路。
而当我们深入该项目的 512K 行源码时,惊讶地发现——这不是一个"应用了 Harness Engineering 理念的项目",而是这个理念最完整的工业级实现。它的代码中,模型调用相关的部分不到 5%,剩下 95% 全部是 Harness。

Harness Engineering 六大支柱 × 该项目落地映射
范式演进的三部曲:
Harness Engineering 的核心哲学用八个字概括:"人类掌舵,Agent 执行"。它不试图让模型"变聪明",而是通过工程手段,让一个"已经很聪明但不可预测"的模型在约束和反馈中稳定工作。
"Agent 的每一次失败,都是环境设计不完善的信号。正确的回应不是换更强的模型,而是重新设计它运行的环境。"
— Cassie Kozyrkov
综合 OpenAI、某头部 AI 实验室、Martin Fowler、LangChain、Latent Space 和 Cassie Kozyrkov 六方文献,Harness Engineering 可以提炼为六大工程支柱。下面我们逐一解析每个支柱在 该项目源码中的具体实现——这不是抽象理论,而是从 512K 行生产代码中提取的工程实践。
支柱一:上下文架构 🗺️
核心理念:精准设计进入模型上下文的信息。研究表明,当上下文窗口利用率超过 40% 时,模型推理质量显著下滑。
该项目的实现是教科书级的——它构建了一条完整的四级压缩管道(详见 Part 4.3),从轻量裁剪到全量摘要,渐进降级:
Snip Compact → Micro Compact → Context Collapse → Auto Compact 零API调用 缓存编辑 读时投影 LLM摘要 (最轻量) (最重,最后手段)但这只是压缩端。注入端同样精心设计:
- 分层记忆系统:
PROJECT.md自动加载 →memdir/持久化知识库 → Session 记忆(自动失效)→ Repo 级知识 - 按需注入:技能系统通过
SkillTool按需发现和注入,而非启动时全量加载 getEffectiveContextWindowSize():动态计算可用上下文窗口,为摘要预留min(maxOutput, 20000)tokens(基于 p99.99 数据 17,387 tokens)
这与 LangChain Deep Agents 的策略高度一致——LangChain 在工具结果超过 20,000 tokens 时卸载到文件系统,该项目则通过 Context Collapse 在读时投影为摘要视图。两者殊途同归:永远不要让上下文窗口变成垃圾场。
支柱二:架构约束 ⛓️
核心理念:用代码和工具强制执行规则,而非依赖 prompt 的"软约束"。依赖模型"自律性"是不可靠的。
该项目在这个支柱上的投入极重——整个权限系统就是一个五层纵深防御体系:
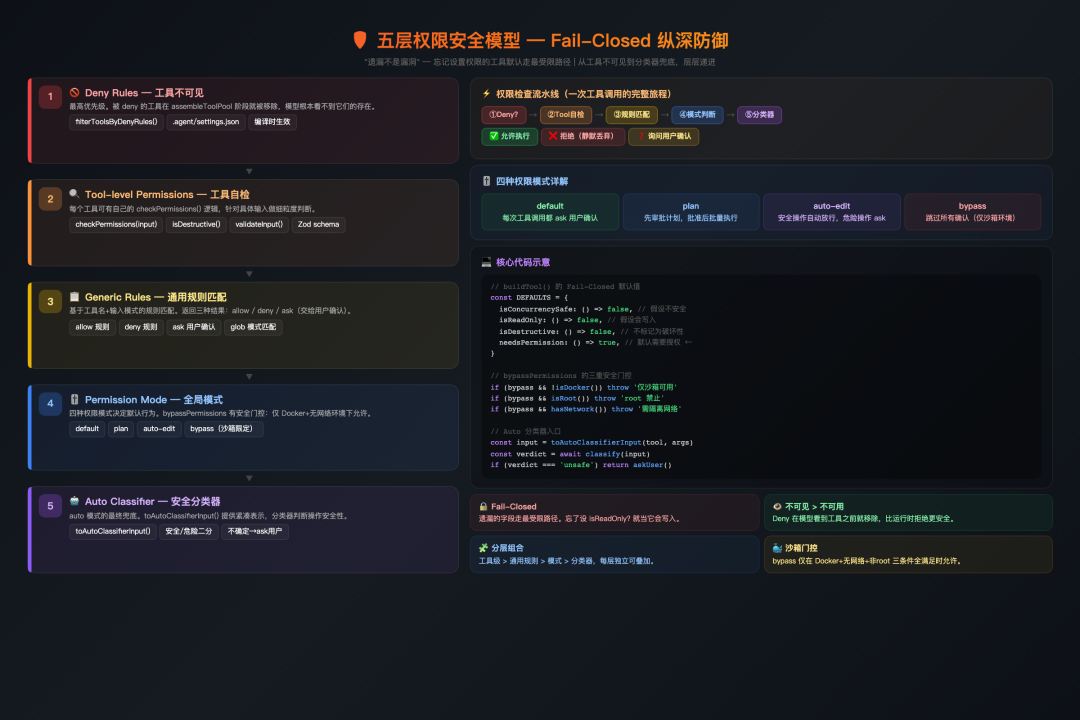
五层权限安全模型
层层递进:Deny Rules(不可见)→ Tool-level Permissions(自检)→ Generic Rules(规则匹配)→ Permission Mode(模式判断)→ Auto Classifier(分类器兜底)。
buildTool() 工厂函数的Fail-Closed 默认值是这个支柱最精髓的体现:
# Python 伪代码重构 -- 展示核心设计思路 DEFAULTS = { "is_concurrency_safe": lambda _: False, # 假设不安全 "is_read_only": lambda _: False, # 假设会写入 "is_destructive": lambda _: False, }忘了设置?那就走最受限路径。遗漏不是漏洞。
OpenAI 的方法是用确定性 Linter 强制执行层级依赖,该项目的方法是用 Pydantic Schema + 编译时 is_feature_enabled() 特性开关 + 五层权限模型。两者的共同点是:用机器约束代替人的自律。
支柱三:自验证循环 🔄
核心理念:在执行流程中内置验证检查点,防止死循环与静默失败。
这是 该项目源码中最被低估的设计。query() 的 while(true) 循环有 16 个步骤,其中只有步骤 8 是"调用模型",其余 15 个全是验证和修复逻辑:
# Python 伪代码重构 -- 展示核心设计思路 # 简化的 query() 循环结构 while True: # 1-2: 前置预取与预算(技能/工具结果) # 3-6: 上下文预处理(Snip/Micro/Collapse/Auto 压缩) # 7: 阻塞限制检查 # ★ 8: 调用 API(唯一的模型交互!) # 9: 流式工具执行 # 10: 后采样 Hooks(stop_hooks 验证) # 11: 中断处理 # 12: 停止 Hooks(含 max_tokens 恢复) # 13: Token 预算检查 # 14: 附件消息注入(记忆/技能/命令队列) # 15: MCP 工具热更新 # 16: transition 追踪(记录"为什么继续")transition 字段是验证循环的精华——它不是一个调试工具,而是一个可断言的状态机:
# Python 伪代码重构 -- 展示核心设计思路 CONTINUE_REASONS = [ "next_turn", # 正常下一轮 "max_tokens_recovery", # 截断恢复(含 attempt 计数) "reactive_compact_retry", # 反应式压缩重试 "collapse_drain_retry", # 折叠排空重试 "stop_hook_blocking", # 停止 Hook 阻塞 "token_budget_continuation", # Token 预算续传 ]测试可以直接断言"这次循环是因为 max_tokens 恢复才继续的",而不需要从消息内容中反向推导。这与 Birgitta Böckeler 提出的"生成者与评估者分离"高度契合——stopHooks 系统允许注入外部验证逻辑,让用户或外部系统充当"评估者"角色。
支柱四:上下文隔离 🧊
核心理念:多 Agent 协作时保持每个 Agent 的上下文纯净,防止跨边界信息污染导致级联故障。
该项目在这个支柱上有三层隔离设计:
- 进程级隔离:
AgentTool生成的子 Agent 拥有完全独立的上下文窗口、消息历史和AbortController。子 Agent 的错误不会传播到父级(query.ts不会因为子 Agent 出错而终止回合) - 通信接口化:Agent Swarms 中的 Teammates 通过
SendMessageTool传递结构化消息,而非共享原始上下文。Unix Domain Socket (UDS) 保证了 ~50μs 的通信延迟(vs HTTP 的 ~500μs) - Coordinator 模式的控制面/数据面分离:
# Python 伪代码重构 -- 展示核心设计思路 # 协调器线程只有 3 个工具 coordinator_tools = [AgentTool, TaskStopTool, SendMessageTool] # Worker 有完整的工具集 worker_tools = [BashTool, FileReadTool, FileEditTool, FileWriteTool, GrepTool, GlobTool, ...]协调器不能自己动手——它只负责分配任务和检查结果。这与微服务架构中"控制面不处理数据"的理念完全一致。该团队在《Effective Harnesses》中也推崇类似的双层 Agent 架构(初始化 Agent + 编码 Agent),该项目则把它做到了 6 种 TaskType 的完整体系。
支柱五:熵治理 ♻️
核心理念:对抗系统状态的自然熵增——随着任务执行,上下文变得越来越混乱,记忆碎片化,文档腐烂。
这是该项目最前卫的设计所在——AutoDream 梦境系统(详见 Part 8.2)本质上就是一个自动化熵治理引擎:
/compact + Auto Compact 手动或上下文接近窗口限制
知识沉淀
memdir/ 持久化写入 Agent 主动调用
状态清理 Session 记忆自动失效 会话结束
后台整合 AutoDream 4 阶段 24h + 5 sessions 双重门控
碎片整理 Dream Phase 4: Prune & Index AutoDream 最后阶段
OpenAI 用"后台清洁 Agent"自动偿还技术债务,该项目的 AutoDream 做的是同样的事——但对象不是代码,而是 AI 的记忆。它借鉴了认知科学中的记忆巩固理论:人类在 REM 睡眠阶段重播白天经历,将短期记忆转化为长期记忆。AutoDream 对 AI 做了同样的事。
支柱六:可拆卸性 🔌
核心理念:模块化设计,使 Harness 能随模型迭代优雅适配。防止与特定模型深度耦合。
该项目的可拆卸性体现在三个层面:
- 依赖注入:
QueryDeps只有 4 个字段(callModel,microcompact,autocompact,uuid),用函数签名类型引用保持类型同步。替换模型只需替换callModel一个字段 - Skills = Markdown:技能定义不绑定任何特定模型或 API。一个 Markdown 文件可以在不同模型上通用,因为它定义的是流程而非调用方式
- MCP 标准协议:外部工具通过 Model Context Protocol 接入,独立于 该项目的内部实现。MCP 工具可以用任何语言编写,运行在独立进程中
- 模型降级容错:当主模型过载时,自动切换到 fallback 模型,strip thinking 签名块防止 400 错误
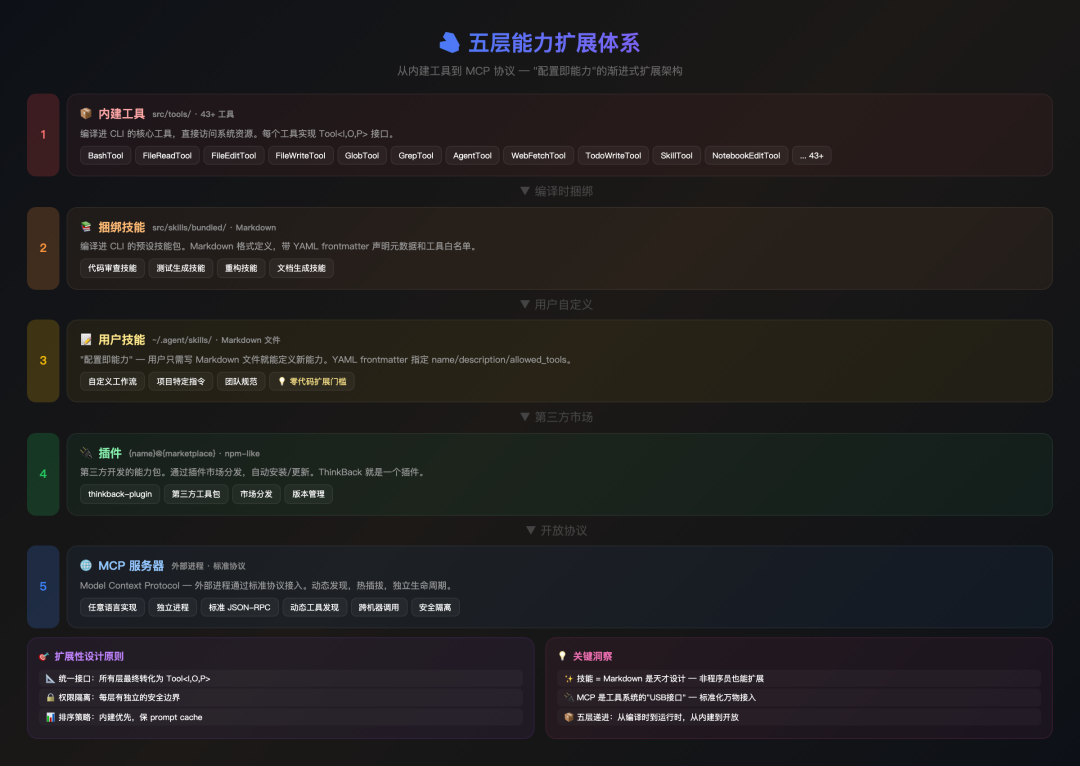
五层能力扩展体系
让我们用一张对比图说明 该项目在 Harness Engineering 六大支柱上的领先程度:
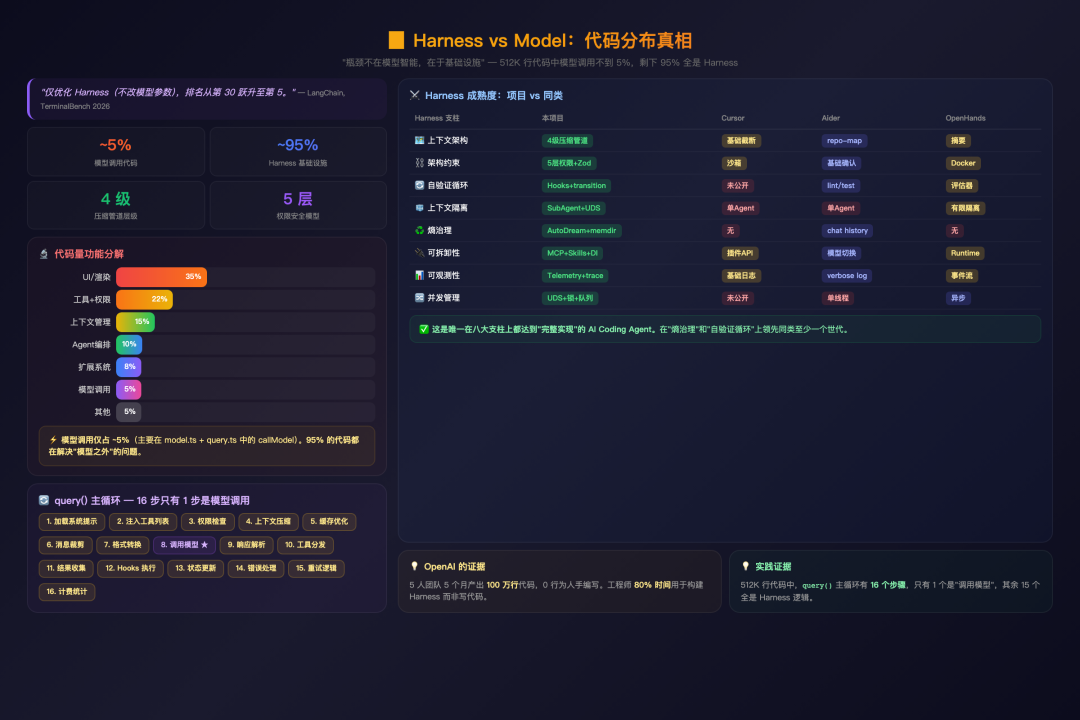
Harness vs Model:代码分布真相
query() 主循环的 16 个步骤中只有 1 个是"调用模型"。512K 行代码中模型调用相关的代码不到 5%。这不是偶然——这是 Harness Engineering 核心论点的最强证据:AI Agent 的瓶颈从来不在模型智能,而在基础设施。
从 该项目中提炼的性能优化不是"锦上添花",而是 CLI 场景下的生存必需——用户对启动延迟的容忍阈值是 200ms:
--version 零导入直接退出
并行预取 ~65ms MDM + Keychain + GrowthBook 在 import 链期间并行
延迟加载 ~1.1MB OTel (~400KB) + gRPC (~700KB) 按需 import
编译时 DCE 整个代码块
feature() + Bun bundler 剥离内部工具
memoize 单例 重复调用
getCommands(),
getUserContext() 只算一次
API 预连接 ~50ms
preconnectModelApi() TLS 预握手
缓存排序 真金白银 工具列表分区排序保 prompt cache 命中率
流式并行 整体延迟
StreamingToolExecutor 边流式边执行
该项目用 34 行代码证明了:你可能不需要 Redux。 这个极简 Store 引发了社区一场关于"最少够用"的热烈讨论。
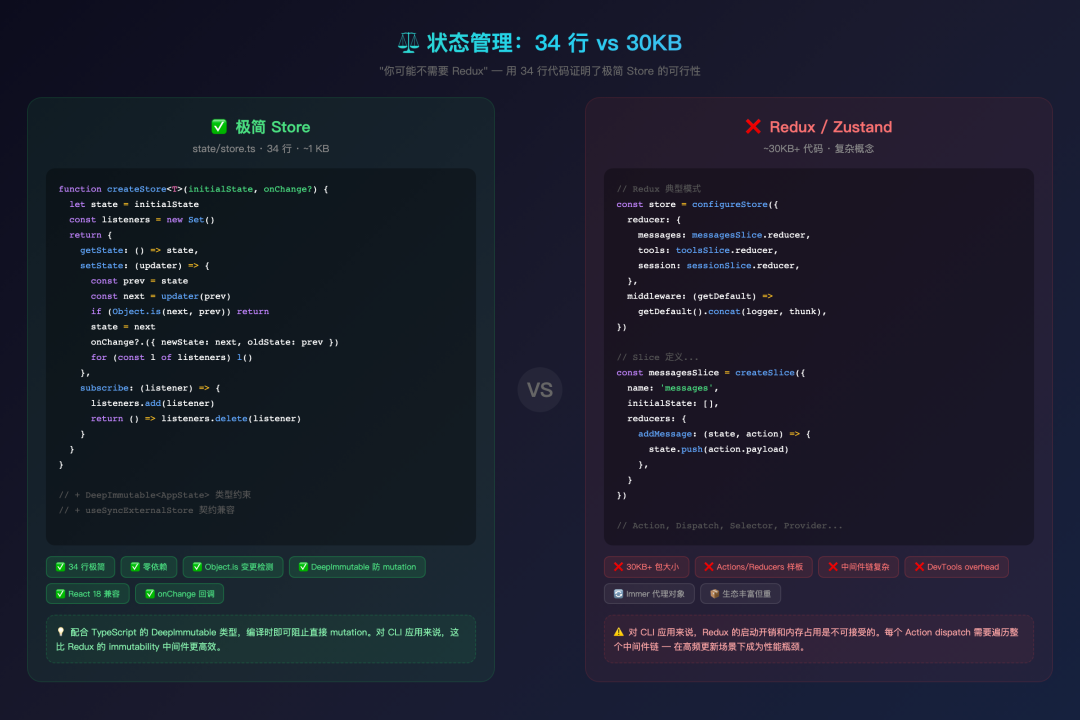
状态管理对比:34 行 vs 30KB
# Python 伪代码重构 -- 展示核心设计思路 class MiniStore: """极简状态管理 — 约 30 行代码实现 Observer 模式""" def __init__(self, initial_state, on_change=None): self._state = initial_state self._listeners = set() self._on_change = on_change @property def state(self): return self._state def set_state(self, updater): prev = self._state next_state = updater(prev) if next_state is prev: # 引用相等则跳过 return self._state = next_state if self._on_change: self._on_change(new=next_state, old=prev) for listener in self._listeners: listener() def subscribe(self, listener): self._listeners.add(listener) return lambda: self._listeners.discard(listener)配合不可变约束(如 @frozen / @dataclass(frozen=True))的类型限制,确保状态只能通过 set_state 修改,且类型系统在静态检查时阻止直接 mutation。对性能敏感的 CLI 应用来说,Redux 的启动开销和中间件链遍历是不可接受的——34 行极简 Store 是更好的选择。
从该项目 512K 行代码和 Harness Engineering 六大支柱中,提炼出最具操作性的 10 条建议:
- 把 95% 的精力放在 Harness 上:模型调用只是冰山一角。压缩、权限、隔离、恢复、熵治理——这些才是决定 Agent 可靠性的关键
- Agent Loop 用异步生成器:它天然支持流式、中断、背压,比 callback 或 Observable 更简洁。该项目的
yield from实现了子生成器委托,保持控制流清晰 - 工具系统 Fail-Closed:
buildTool()的默认值全部偏向保守。安全系统的黄金法则——遗漏不是漏洞 - 权限模型分层纵深:不可见 > 不可用 > 需确认 > 自动分类。Deny 在模型看到工具之前就生效
- 上下文压缩用渐进管道:从 Snip(零 API 调用)到 Auto Compact(LLM 摘要),四级渐进降级
- 配置快照 > 实时读取:
QueryConfig在查询入口一次性快照,避免长运行循环中的外部状态突变 - 上下文隔离用结构化消息:Agent 间通过
SendMessageTool传递结构化消息,不共享原始上下文 - 熵治理要自动化:别指望"定期手动清理"——AutoDream 式的后台整合才是可持续方案
- Skills = Markdown 是**扩展模式:零代码门槛,不绑定模型,可版本化管理
- 测试用依赖注入而非 mock patch:
QueryDeps的 4 个字段用函数签名类型引用保持类型同步,覆盖 80% 测试需求
"每个优秀的工程团队都有自己的幽默感。该团队的幽默感是——给 AI 一只宠物、一个梦境系统、和一个年度回顾。"
— @levelsio
在深入分析了前 7 个 Part 的"正经"架构之后,让我们来聊聊那些藏在代码深处的惊喜。这些功能没有出现在任何官方文档中,它们是源码公开后社区最意想不到的发现。
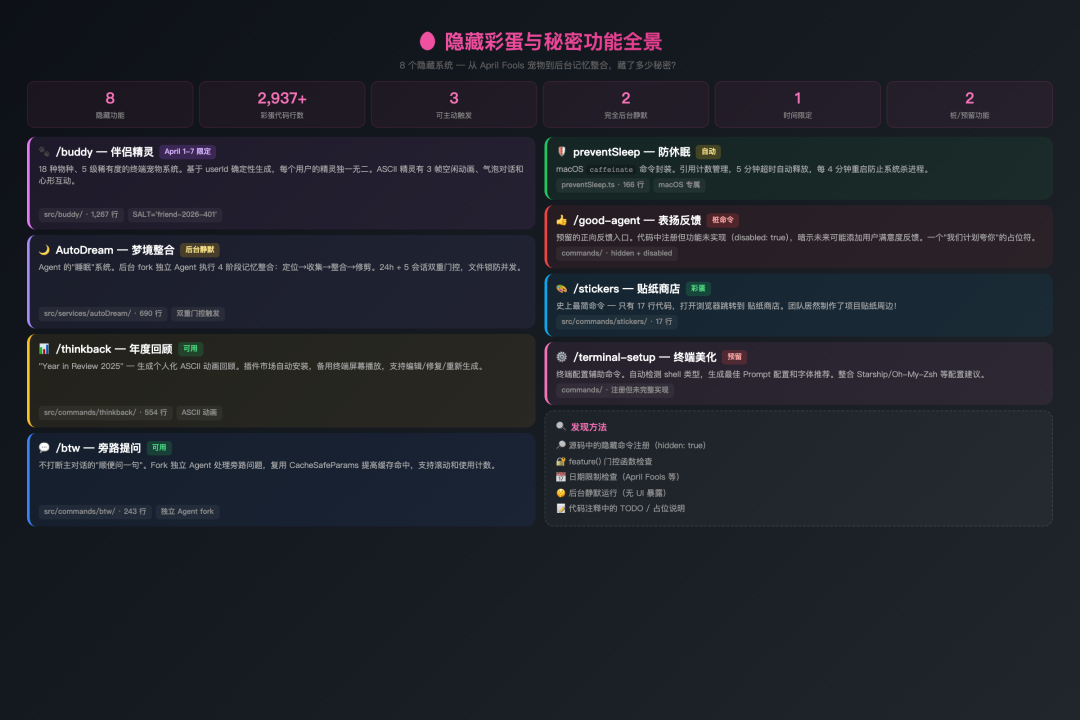
隐藏彩蛋全景
这是源码中最令人惊喜的发现。src/buddy/ 目录下隐藏着一个完整的虚拟宠物系统——每个用户都有一只独一无二的终端精灵在"看着"他们写代码。
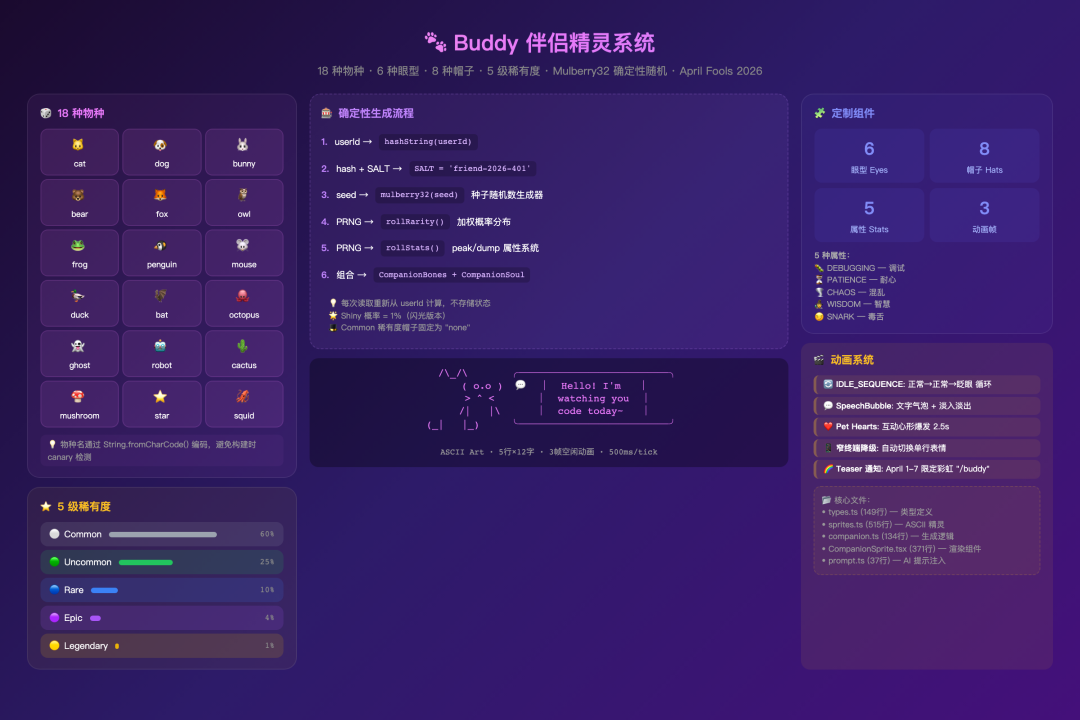
Buddy 伴侣精灵系统
物种与外观系统
Buddy 系统包含 18 种物种,从常见的猫、狗、兔子,到奇异的仙人掌、蘑菇和幽灵。每种物种都有手绘的 ASCII 精灵,5 行 × 12 字符宽,带有 3 帧空闲动画。
一个有趣的实现细节是——物种名称通过 String.fromCharCode() 编码,而不是直接用字符串字面量:
# Python 伪代码重构 -- 展示核心设计思路 # 为什么不直接写 'cat'?因为构建时的 canary 检测会扫描字符串字面量 # fromCharCode 巧妙地绕过了这个检测 SPECIES = [ String.fromCharCode(99, 97, 116), # 'cat' String.fromCharCode(100, 111, 103), # 'dog' # 18 种物种 ]这说明 Buddy 系统可能还处于"秘密开发"阶段,团队不希望它被构建系统的审计工具过早发现。
确定性随机生成
每个用户的精灵是完全确定性的——相同的 userId 永远生成相同的精灵。这通过 Mulberry32 种子随机数生成器实现:
# Python 伪代码重构 -- 展示核心设计思路 SALT = 'friend-2026-401' # 2026 年 4 月 1 日 — April Fools! def roll(userId): bones: CompanionBones; soul: CompanionSoul seed = hashString(userId + SALT) rng = mulberry32(seed) species = SPECIES[Math.floor(rng() * SPECIES.length)] rarity = rollRarity(rng) # 加权随机:60% common → 1% legendary eyes = EYES[Math.floor(rng() * EYES.length)] hat = rarity == 'common' ? 'none' : HATS[Math.floor(rng() * HATS.length)] shiny = rng() < 0.01 # 1% 闪光概率 # 注意 SALT 的值:'friend-2026-401'——4 月 1 日,愚人节。这不仅仅是一个时间彩蛋,更暗示了整个 Buddy 系统可能是 2026 年愚人节的特别项目。事实上,useBuddyNotification.tsx 中有日期检查:彩虹色的 /buddy 提示只在 4 月 1-7 日显示。
稀有度与属性系统
精灵有 5 级稀有度,每级用不同数量的星星表示(从 ☆ 到 ★★★★★),对应不同的终端颜色。属性系统尤其有趣——5 种属性名称暴露了 研发团队工程师的幽默感:
属性使用 peak/dump 系统——每只精灵有一个"巅峰属性"和一个"最差属性",其他随机分布。这意味着你的精灵可能是一只"极其聪明但完全没有耐心"的传说级幽灵,也可能是一只"超级有耐心但啥也不懂"的普通猫。
动画与交互
CompanionSprite.tsx(371 行)实现了一个完整的 React/Ink 动画组件:
- 空闲循环:正常 → 正常 → 眨眼,500ms 一帧
- 气泡对话:精灵会"说话",带淡入淡出效果
- 互动心形:某些操作触发心形爆发动画,持续 2.5 秒
- 窄终端降级:当终端宽度不足时,自动切换为单行表情模式
甚至有一个 prompt.ts 负责将精灵信息注入 AI 的系统提示——也就是说,模型知道你的精灵在旁边看着它回答问题。
如果说 Buddy 是浪漫的彩蛋,AutoDream 则是一个严肃的工程创新——它让该系统在"空闲时"像人类睡眠一样整理和巩固记忆。

AutoDream 梦境系统
触发机制:三重门控
AutoDream 不是随便就能触发的。它有严格的三重门控检查,按顺序执行:
- 时间门控(最先检查):距离上次整合至少 24 小时
- 会话门控:至少经历了 5 次对话会话
- 锁门控:文件锁未被其他进程持有
这种门控设计确保了整合操作既不会太频繁(浪费资源),也不会被跳过太久(记忆碎片化)。
四阶段整合流程
AutoDream 的核心是一个 66 行的 Prompt 模板(consolidationPrompt.ts),指导 fork 出来的 Agent 执行 4 阶段工作:
这个设计的灵感显然来自认知科学中的记忆巩固理论——人类在睡眠的 REM 阶段,大脑会重播白天的经历,将短期记忆转化为长期记忆。AutoDream 对 AI 做了同样的事。
文件锁与回滚
consolidationLock.ts(141 行)实现了一个基于文件 mtime 的锁机制:
- 使用 PID 标识锁持有者
- 超过 1 小时的锁视为 stale(持有者可能已崩溃)
- 失败时执行完整的 rollback 回滚
这是分布式系统中典型的"悲观锁"策略,但用在 AI 的"做梦"系统上,有一种独特的超现实感。
还记得 Spotify Wrapped 和 GitHub Skyline 吗?该项目也有自己的版本——/thinkback 命令生成一段个性化的 ASCII 动画,回顾你 2025 年使用该项目的精彩时刻。
实现细节
src/commands/thinkback/thinkback.tsx(554 行)是一个完整的"微型应用":
- 自动安装:第一次运行时,自动从插件市场下载 thinkback 插件
- 交互菜单:提供 Play(播放)、Edit(编辑)、Fix(修复)、Regenerate(重新生成)选项
- 备用屏幕:使用终端的 Alternate Screen 模式播放动画,播放结束后恢复原始屏幕
- Node 子进程:动画通过独立的 Node 子进程执行,防止阻塞主 REPL
这是一个典型的"过度工程化的彩蛋"——为了一个用户可能只看一次的动画,写了 554 行代码,包含完整的安装流程、错误处理和多选菜单。但正是这种"不必要的认真",让它从一个简单的 gimmick 变成了一个有温度的功能。
在主对话中突然想到一个不相关的问题?不用打断当前的工作流。/btw 会 fork 一个独立 Agent 来处理你的旁路问题。
> 正在帮你重构 auth 模块... > /btw JavaScript 的 WeakRef 和 FinalizationRegistry 有什么区别? > [btw] 正在回答你的旁路问题...(不影响当前任务)技术亮点:
- 独立 Agent:fork 一个新的 query 循环,有自己的消息历史
- CacheSafeParams 复用:精心构造参数以最大化 API prompt cache 命中率
- 使用计数:
btwUseCount追踪使用频率,可能用于后续的产品分析 - 滚动支持:旁路回答支持独立的上下滚动
当该系统在执行长时间任务(比如大型代码库分析)时,你可能已经起身去泡咖啡了。这时候 macOS 的自动休眠可能会中断进程。
preventSleep.ts(166 行)通过 macOS 的 caffeinate 命令阻止休眠:
# Python 伪代码重构 -- 展示核心设计思路 # 引用计数管理 — 多个任务可以同时请求"不要休眠" acquire_prevent_sleep() # ref_count += 1, 如果是第一个,spawn caffeinate release_prevent_sleep() # ref_count -= 1, 如果归零,kill caffeinate实现细节很有意思:
- 引用计数:支持多个任务同时持有"不睡觉"权限
- 5 分钟超时:即使忘记释放,也会在 5 分钟后自动恢复
- 4 分钟重启:每 4 分钟重新 spawn
caffeinate进程,防止被系统杀掉 - 仅 macOS:只在
darwin平台下激活
/stickers:整个项目最短的命令——17 行代码,只做一件事:打开浏览器跳转到贴纸商店。没错,团队甚至为项目制作了实体贴纸周边。
/good-agent:一个"桩命令"——注册了但功能被 disable。代码注释暗示这是一个预留的正向反馈入口。想象一下,当 AI 特别好用时,你可以输入 /good-agent 表扬它。目前是个空壳,但它的存在本身就是一种承诺:"我们计划让你可以夸 AI。"
这些彩蛋不仅仅是好玩——它们反映了深层的工程价值观:
- 确定性胜过随机性:Buddy 系统使用 Mulberry32 种子 PRNG,确保每个用户每次看到的精灵完全一致。这不是"随机宠物",是"你的宠物"
- 认知科学启发的系统设计:AutoDream 的四阶段流程直接映射了人类记忆巩固的 Orient-Gather-Consolidate-Prune 范式
- 过度工程化是一种文化表达:为一个年度回顾动画写 554 行代码,为一个贴纸链接写一个完整的命令——这些都不是"有效率的"做法,但它们传递了一个信号:"我们在乎细节,我们有幽默感"
- 彩蛋的分层访问:有些(如
/btw)任何人都能用,有些(如 Buddy)限定时间窗口,有些(如 AutoDream)完全静默。这种分层设计确保了不同层次的"发现惊喜"
"当你的 AI coding assistant 有一只宠物、会做梦、还有年度回顾——你就知道背后的团队把这件事当成了一个有生命的产品,而不只是一个 API wrapper。"
— @sdks_io
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/255451.html