
看了沐神的讲解,恍然大悟,b站可以不刷,但沐神一定要看。
在统计模型中,通过方差和偏差来衡量一个模型。
1 方差和偏差的概念

2 均方误差(Mean-Square error,MSE)
在统计模型评价中时,评价一个点估计的坏时,通常使用点估计 y ^ \hat{y} y^和参数真值 y y y的距离,最常用的函数是距离的平方,由于估计量 y ^ \hat{y} y^具有随机性,每次采样的点都不一样,所以可以对该函数求期望,即表示在不同的采样点下具有的误差,这就是下式给出的均方误差:

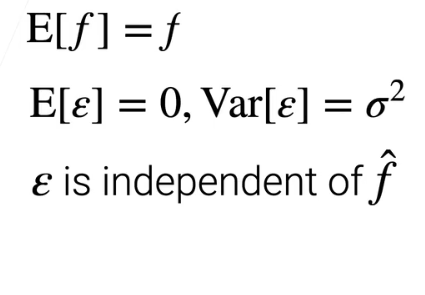
以上就得到了均方差是由偏差、方差和数据本身的噪音的组合。
3 偏差—方差均衡(Tradeoff)
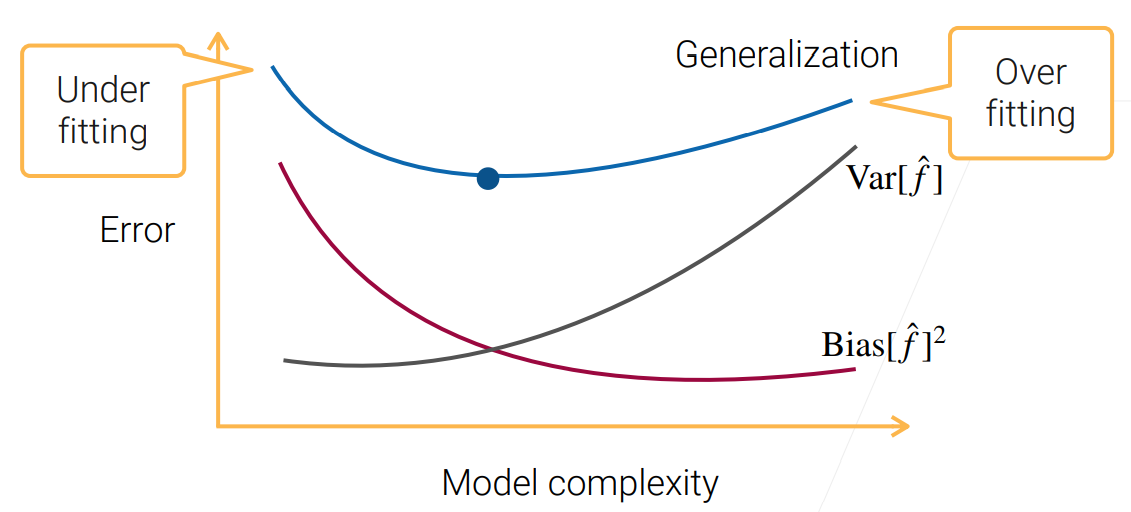
对于样本数据,如果选择的模型过于简单,学不到很多信息,此时模型的预测值和真实值误差很大,也就是偏差很大,随着模型的复杂度提升,学到的信息也越来越多,使得偏差逐渐降低。
同样的,随着模型复杂的提升,数据相对模型而言变得简单,使得模型学到了更多的数据噪音,方差也就越来越大。

泛 化 误 差 = 数 据 本 身 噪 声 + 偏 差 + 方 差 \color{red}泛化误差=数据本身噪声+偏差+方差 泛化误差=数据本身噪声+偏差+方差
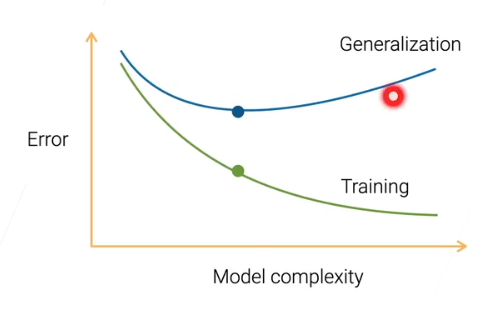
如下图蓝线,所以需要在中间位置找到一个合适的模型复杂度,使得泛化误差尽可能地小。过于简单导致欠拟合,过于复杂导致过拟合。
这也就是我们常说的训练误差随着模型复杂度地提升而降低,而泛化误差会逐渐增大。训练误差更多和偏差相关,偏差越小,模型就越能拟合训练数据。
3 降低偏差和方差
对于偏差,偏差过高是由于模型地复杂度不够,所以通过增加模型复杂度来降低bias,比如在神经网络中,增加模型层数和隐藏神经元个数。也可以他通过集成学习地方法来,比如Boosting。关于集成学习的文章
对于方差,方差过高是由于模型过于复杂,通过降低模型地复杂度来实现。比如加入正则来限制参数的学习范围,使得方差降低。集中方法中的Bagging也可以降低方差。
对于 σ 2 \sigma^2 σ2,该项主要是由于数据本身的噪声产生,虽然在统计学里面,该项不可降低。但在实际中,可以通过改善数据来降低噪音。

从方差和偏差角度解读Boosting和Bagging

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/25440.html