
大家好,我是 Guide。前面分享过 和 ,分别覆盖了 JetBrains 体系和 VS Code 体系下的 AI 辅助编码。这篇换个角度,聊聊 Claude Code 接入第三方模型 的实战体验。
Claude Code 本身是 Anthropic 官方的 CLI 编码工具,但它支持通过环境变量切换底层模型。这意味着你不必局限于 Claude 系列,完全可以接入其他模型来使用。本文以 GLM-5.1 作为示例,但接入方式是通用的——换成其他兼容模型,流程基本一致。
我选了两个比较有代表性的复杂场景来验证:
- 场景一:从零搭建一个基于 Arthas 的 JVM 智能诊断 Agent,涵盖技术选型、架构设计、编码落地的完整流程
- 场景二:在百万级数据量的既有订单系统中定位并治理慢查询,考验 AI 对现有代码库的理解和增量优化能力
一个是从零开始的工程交付,另一个是面对既有系统的性能治理,正好覆盖 AI 辅助编程的两种典型工作模式。
在正式开始之前,需要完成 Claude Code 与第三方模型的对接。整个配置过程分三步:
第一步:安装 Claude Code
npm i -g @anthropic-ai/claude-code@latest第二步:安装 cc-switch 完成模型切换(macOS 用户可通过 homebrew 安装,详情参考 cc-switch 官方文档:https://github.com/farion1231/cc-switch/blob/main/README_ZH.md)
第三步:按照模型提供方的说明,完成 Claude Code 内部模型环境变量与目标模型的对应关系配置。以 GLM-5.1 为例,参考:https://docs.bigmodel.cn/cn/coding-plan/tool/claude
配置过程截图如下:
点击加号添加模型:
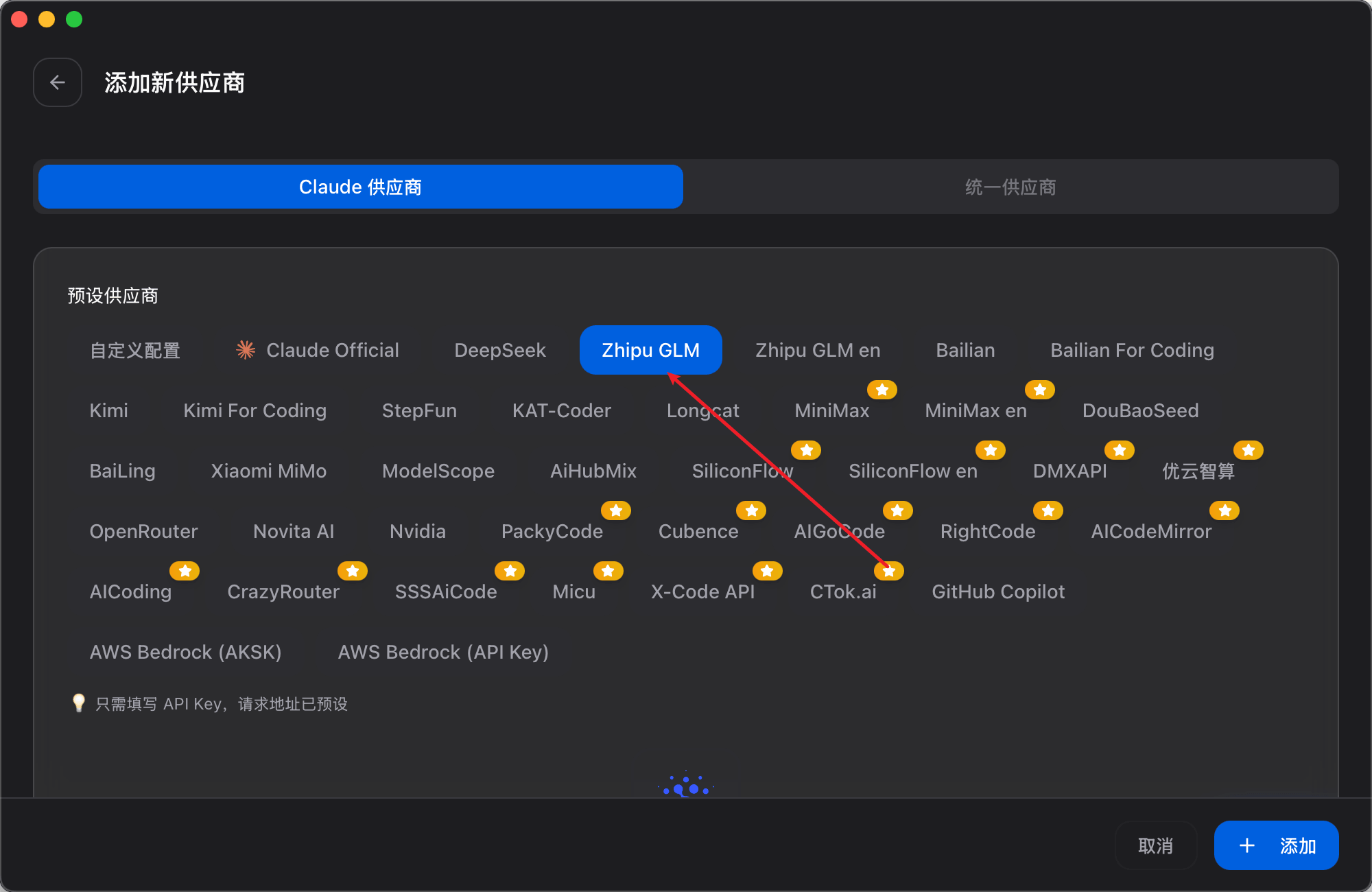
选择对应的模型:
配置参数:
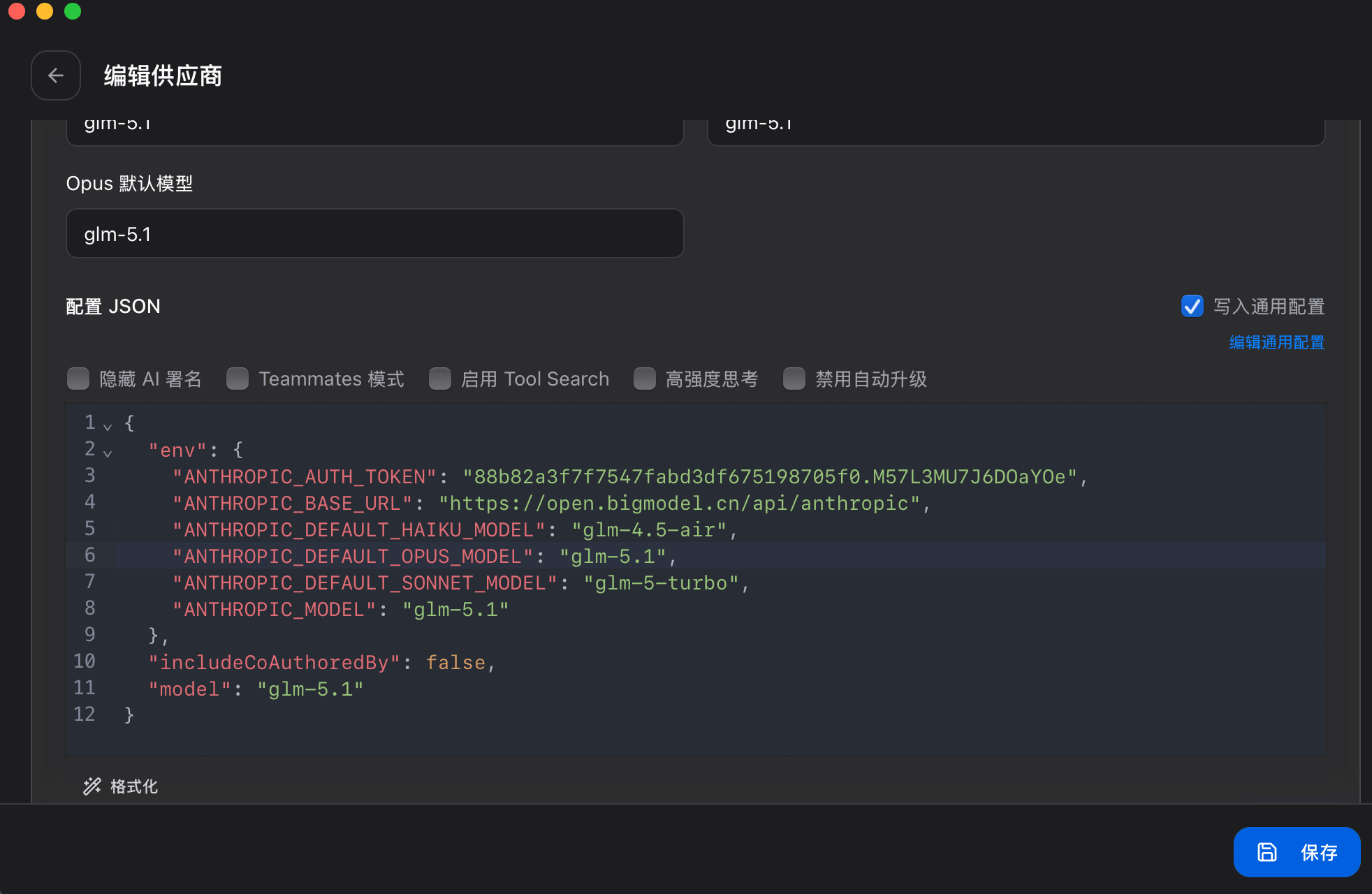
Claude Code 内部模型环境变量与目标模型对应关系的 JSON 配置:
如果你更偏向页面开发,推荐通过 VSCode + Claude Code for VS Code 方式进行交互和编码验收。完成插件安装之后,可以直接在 IDE 中与模型对话和代码审查,相对于 CLI 界面会更直观一些:
JVM 线上诊断一直以来都是 Java 开发最棘手的问题。在传统开发模式下,面对性能瓶颈或线上故障,研发人员的排查路径基本固定:
- 查看 Grafana 监控面板,初步定位异常方向
- 登录线上服务器,排查 CPU、内存、GC 等各项指标
- 明确 Java 应用层面的问题后,启动 Arthas 执行一系列诊断指令,逐步缩小问题范围
- 定位到具体代码段,分析根因并制定修复方案
在 AI 出现以前,这套流程虽然繁琐,但确实是最直接有效的手段。但随着业务复杂度的攀升和故障响应时效要求的提高,传统模式的弊端越来越明显:
- 监控指标过于主观:面对 CPU 飙升、内存泄漏、OOM 等千奇百怪的问题,监控面板上的指标繁多,研发人员往往依赖经验做主观推断,缺乏系统化的诊断方法论
- 诊断链路过于冗长:从 Grafana 面板到线上服务器再到 Arthas 诊断,整个排查链路涉及多个工具的切换和衔接,不仅耗时,对于紧急的线上故障止血来说显得非常低效
- 高度依赖工程师经验:Arthas 确实是一款强大的 JVM 诊断利器,内置各种增强指令可以深入字节码查看运行时细节。但代价是开发人员必须熟悉各种指令参数和推理路径,才能准确高效地完成问题定位
随着 AI 技术的演进,特别是 Agent 和 Skill 等核心概念的成熟,笔者就有了一个工程化的构想:能否借助 AI 将诊断经验沉淀复用,让 AI 根据既有经验构建明确的决策路径?同时结合它的决策方案赋予对应的工具,使其基于用户给定的服务名和故障表象,自动化连接线上服务器完成诊断,定位具体代码段,最终输出问题根因和解决方案。
有了构想之后,接下来就是技术选型和方案落地。笔者将完整的需求描述交给 AI:
研发一款基于Arthas的智能体诊断工具,该工具需实现以下核心功能: 1. 当用户输入线上故障服务名称及具体故障现象后,系统能够自动定位至目标故障服务器,主动对目标服务进行实时监控与深度分析。 2. 通过集成Arthas的反编译功能,精准定位到引发故障的具体代码段 3. 基于分析结果生成包含问题根因、代码修复建议及实施步骤的完整解决思路。 请提供该工具的技术选型方案,包括但不限于开发语言(优先考虑Java技术栈)、核心框架、数据库表设计、部署架构等,并设计详细的系统实现方案,涵盖功能模块划分、数据流程设计、关键技术难点及解决方案等内容。AI 收到需求后,没有立刻开始写代码,而是先结合项目上下文(完全空的文件夹)进行推理分析,自主完成了一份包含十几个阶段的完整技术方案。这种“给一个目标,AI 自己拆出整条路径”的工作方式,是 AI 辅助编程的核心优势之一——你可以把精力放在需求描述和方案评审上,让 AI 负责路径规划。

AI 结合需求,针对 Agent 拆解出技术选型和 Arthas 集成方案的检索。从检索关键字可以看出,它在方案选取上优先考虑成熟稳定的解决方案:

AI 检索了大量资料和 Arthas 官方文档后,输出了下面这份系统架构设计图。从上到下分三层:用户层输入服务名和故障现象,Agent 层由 Skill 引擎、Arthas HTTP Client 和 AI 分析引擎三大核心模块协同工作,最底层通过 Arthas 内置 HTTP API 对接多个目标服务实例。架构的模块划分和职责边界清晰,从故障输入到定位代码再到生成报告的完整链路设计到位:
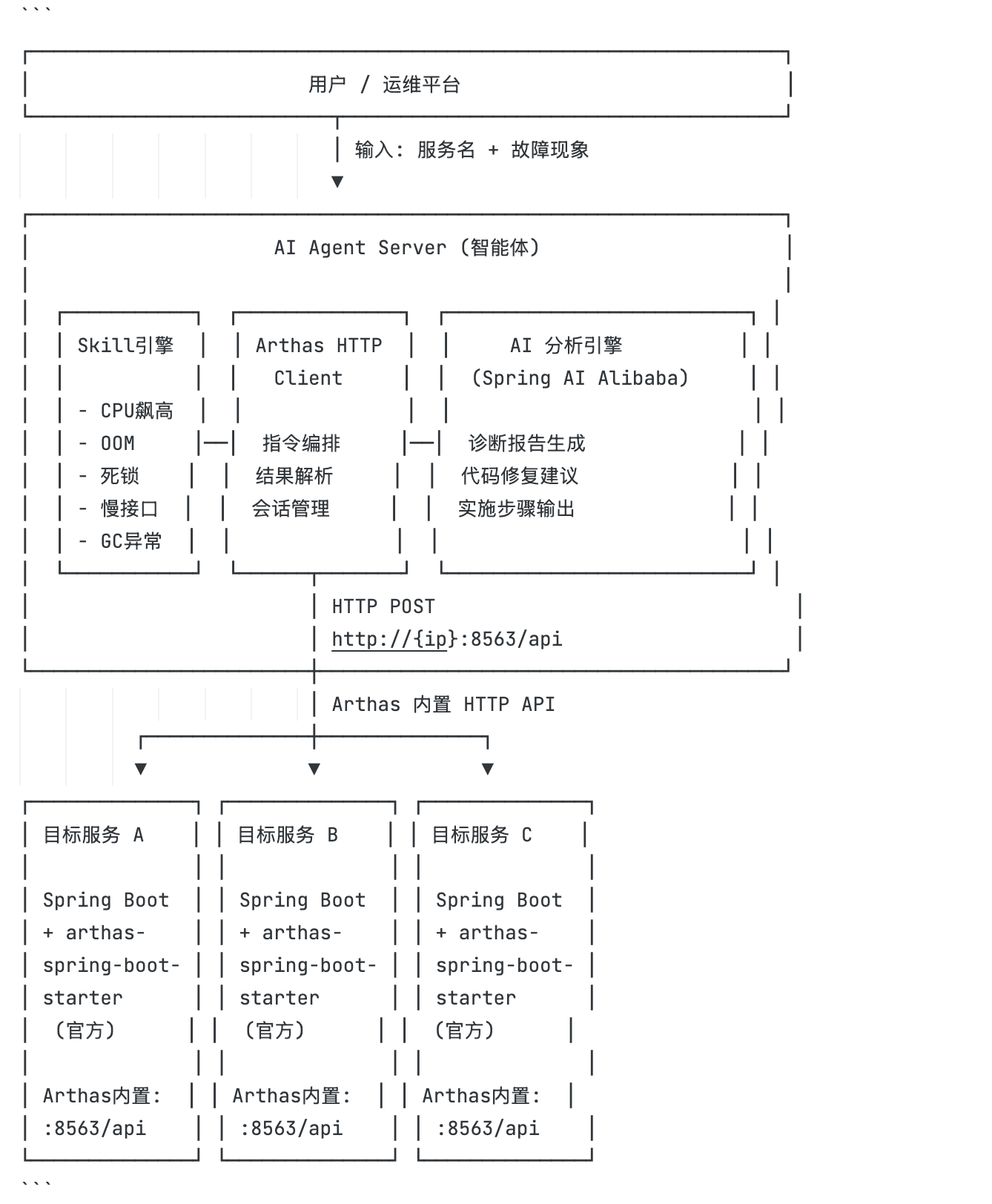
AI 不仅给出了架构图,还进一步拆解了 6 个核心组件的职责分工——从 AI Agent Server 的流程编排,到 Arthas HTTP Client 的会话管理,到 Skill 引擎的诊断步骤链定义,再到 AI 分析引擎的报告生成,每个组件的边界和协作关系都交代得比较清楚:

最后来看最重要的数据流设计。架构设计明确之后,只要数据流链路完整清晰,基本就可以着手开发了。AI 结合一个常见的 RT 超时场景,给出了完整的诊断链路——从 Skill 匹配、诊断步骤执行、问题追踪、根因定位,到 Arthas 反编译和最终的诊断报告输出。AI 针对 Arthas HTTP API 设计了完整的会话模式交互流程(init_session → async_exec → pull_results → interrupt_job → close_session),连watch、trace这类持续监听型命令的异步轮询机制都考虑到了。这一点在评审时需要重点关注——如果 AI 对底层工具的通信模型理解有偏差,后续编码阶段就会出现问题:

其他细节就不多做赘述了。整体来说,架构和数据流链路都比较到位。AI 不仅针对既有需求给出了方案,还主动输出了 6 个后续扩展方向——WebSocket 实时推送、诊断知识库向量化存储、已知 Pattern 的自动修复补丁、告警联动自动触发诊断、自定义 Skill 市场、多语言支持。这些扩展方向都紧扣当前架构的技术延伸:知识库基于现有的诊断报告数据,自动修复基于已有的 Skill 引擎,告警联动基于现有的服务实例查询机制。

确认方案没有问题后,笔者直接下达开发指令:
整体方案没有问题,请完成开发工作吧AI 收到指令后,开始自主编码。按照之前的架构设计,逐模块推进——从父 POM 和 Maven 多模块骨架搭建,到通用工具类、数据模型、数据访问层、Arthas 客户端封装、Skill 引擎、AI 分析引擎、业务逻辑层、Web 控制器,直到启动模块和部署配置,11 个子步骤全部完成:
片刻之后,AI 完成了全部编码工作,并输出了一份详细的交付清单。9 个模块、46 个文件全部到位——从通用工具类到 7 个内置诊断 Skill,从 Arthas HTTP API 的 exec+session 双模式封装到 Spring AI Alibaba 诊断分析器,一个不少:
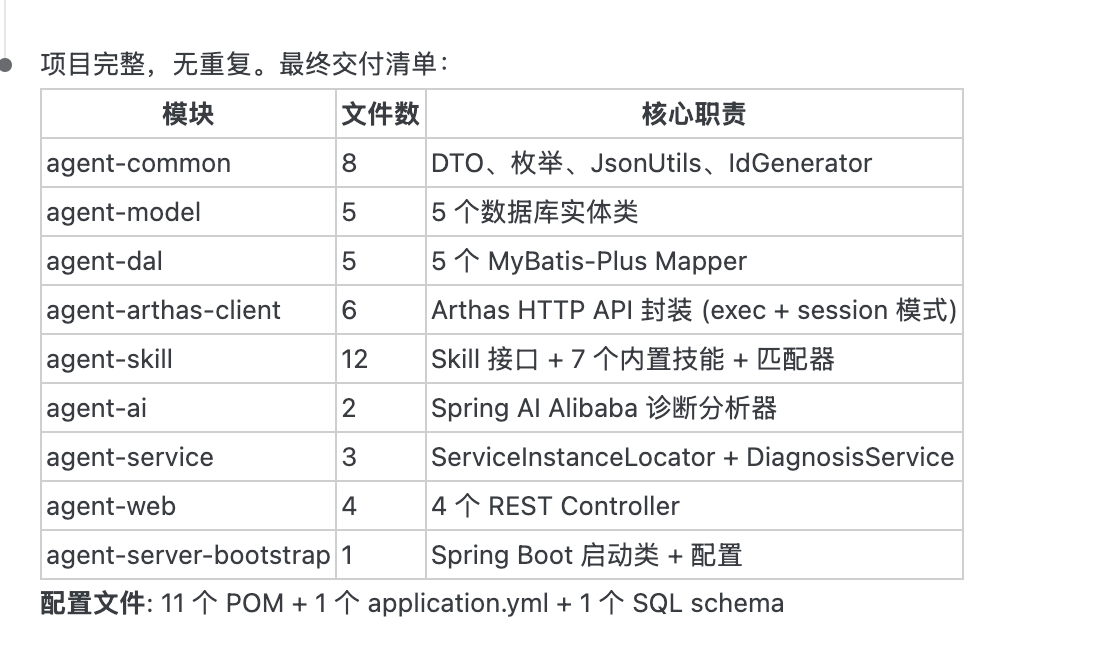
先看整体模块结构,AI 按照 Java 多模块的标准规范完成了工程划分,从上到下严格遵循 common→model→dal→client→skill→ai→service→web→bootstrap 的依赖层级,命名规范统一。
agent-skill 模块值得关注,AI 不仅设计了 Skill 引擎的抽象接口,还内置了 7 个覆盖常见 JVM 故障场景的诊断技能(CPU 飙高、OOM、死锁、慢接口、GC 异常、线程泄漏、类找不到),每个 Skill 都定义了完整的诊断步骤链。这种”框架 + 内置实现”的设计思路,扩展性不错:
jvm-ai-agent/ ├── jvm-ai-agent-server/ # 智能体服务端(核心) │ ├── agent-common/ # 通用模块:工具类、常量、DTO │ ├── agent-model/ # 数据模型:实体、数据库映射 │ ├── agent-dal/ # 数据访问层:Mapper、Repository │ ├── agent-arthas-client/ # Arthas HTTP API 客户端封装 │ ├── agent-skill/ # Skill 引擎(诊断方法论) │ ├── agent-ai/ # AI 分析引擎 │ ├── agent-service/ # 业务逻辑层(含服务实例查询) │ ├── agent-web/ # Web 层:REST API、WebSocket │ └── agent-server-bootstrap/ # 启动模块 │ └── pom.xml # 父 POM再看诊断核心逻辑,AI 严格按照架构设计中定义的数据流完成了完整的诊断业务链开发。整个 executeDiagnosis 方法按照 Skill 匹配、实例定位、诊断链执行、动态命令解析、AI 分析、报告生成的流程推进,异常处理也考虑到了非关键步骤失败时继续执行的容错策略:
- Skill 匹配:通过
DefaultSkillMatcher根据故障现象关键词匹配**诊断技能 - 实例定位:通过
ServiceInstanceLocator根据服务名解析目标实例 IP 和 Arthas 端口 - 诊断链执行:遍历 Skill 定义的诊断步骤链,依次执行 Arthas 命令并收集结果
- 动态命令解析:从 Arthas 输出中提取类名、方法名等上下文变量,注入后续步骤的动态命令模板
- AI 分析报告:将全部诊断数据交给 AI 分析引擎,生成包含根因、修复建议、严重程度的结构化报告
private void executeDiagnosis(DiagnosisRecord record, DiagnosisRequest request) SkillDefinition skill = skillOpt.get(); // …… // 2. 定位目标实例 ServiceRegistry instance = instanceLocator.resolveInstance( request.getServiceName(), request.getInstanceIp()); // …… // 3. 执行诊断步骤链 List<DiagnosticStep> chain = skill.getDiagnosticChain(); StringBuilder allDiagnosticData = new StringBuilder(); String decompiledCode = ""; Map<String, String> contextVars = new HashMap<>(); for (int i = 0; i < chain.size(); i++) // 从结果中提取上下文变量供后续步骤使用 extractContextVars(result, contextVars); } catch (Exception e) { // 非关键步骤失败时继续执行 // …… } } // 4. AI 分析 String report = diagnosisAnalyzer.analyze( request.getSymptom(), allDiagnosticData.toString(), decompiledCode, skill); // 5. 保存报告(从Markdown报告中提取根因、严重程度等结构化字段) // …… // 6. 更新诊断记录状态 record.setStatus(DiagnosisStatus.COMPLETED.getCode()); // …… } catch (Exception e) }在 AI 编码期间,笔者查阅了 Spring AI Alibaba 的官方文档,发现它提供了开箱即用的 Agent Chat UI。与其让 AI 从头生成前端页面,不如直接集成这个现成的交互组件,实现 SSE 流式输出的诊断体验。于是笔者给了一条简短的指令:
根据Spring AI Alibaba官方文档(参考链接https://java2ai.com/docs/frameworks/studio/quick-start:),实现agent智能体交互页面开发工作只给了一个文档链接和一句话,AI 就自己去读官方文档、理解集成步骤、完成了页面开发。这也是使用 AI 辅助编程的一个实用技巧:当你只需要集成某个现成组件时,直接给出文档链接往往比详细描述需求更高效。

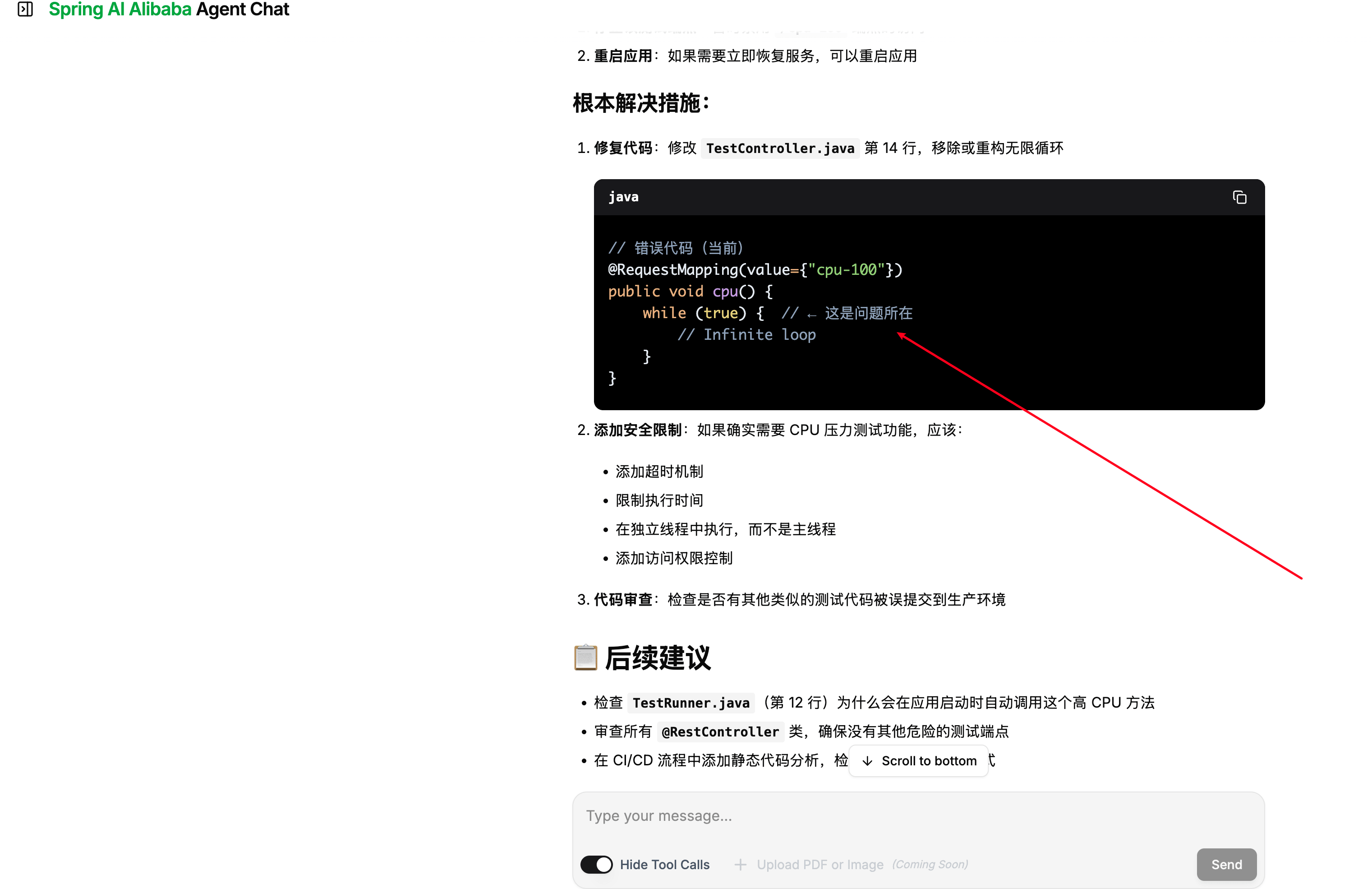
到这里,一个完整的智能诊断 Agent 就构建完成了。为了验收功能,笔者在本地起了一个 CPU 飙升的测试接口:
@Slf4j @RestController public class TestController { @RequestMapping("cpu-100") public void cpu() { while (true){ } } }启动 Agent 服务,访问 http://localhost:{应用端口}/chatui/index.html,在聊天框输入:order-service 程序CPU飙升,请协助排查。Agent 在收到故障表象后,完成了完整的诊断链路——先通过 Dashboard 获取概览定位到 CPU 占用最高的线程 ID,再基于线程栈帧信息定位到问题代码段,最后通过 Arthas 反编译(jad)输出热点代码并生成包含根因分析和修复建议的完整诊断报告。整个过程 Agent 全程自主完成,SSE 流式输出让每一步诊断进度都清晰可见:
如果说场景一验证的是 AI“从 0 到 1 的规划与交付能力”,那场景二要验证的就是另一个维度:在一个已有一定复杂度的代码库中,AI 能否准确理解既有架构、定位问题、并完成增量优化。
这是一个基于 Spring Boot + MyBatis 的订单查询服务(glm-testing-service),核心业务围绕订单的查询和分析展开,包含四个接口:
数据库中灌入了百万级测试数据,对应的表结构如下:
CREATE TABLE(ordersidBIGINT PRIMARY KEY AUTO_INCREMENT,order_noVARCHAR(64) NOT NULL,user_idBIGINT NOT NULL,statusTINYINT NOT NULL DEFAULT 0,total_amountDECIMAL(10,2) NOT NULL,product_nameVARCHAR(256) NOT NULL,categoryVARCHAR(64) NOT NULL,create_timeDATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP,update_timeDATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, UNIQUE KEYuk_order_no(order_no), KEYidx_user_id(user_id), KEYidx_status(status), KEYidx_category(category), KEYidx_create_time(create_time) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
项目通过 AOP 切面自动记录每个接口的执行耗时,用于快速定位性能瓶颈:
@Around("controllerPointcut()") public Object printExecutionTime(ProceedingJoinPoint joinPoint) throws Throwable { long startTime = System.currentTimeMillis(); Object result = joinPoint.proceed(); long costTime = System.currentTimeMillis() - startTime; log.info("[{}] {}.{} 耗时: {}ms", Thread.currentThread().getName(), className, methodName, costTime); return result; }向数据库灌入百万级测试数据后,对搜索订单接口进行压测。该接口涉及关键词模糊匹配+时间区间+金额过滤的组合查询,例如下面这个搜索请求:
curl -X POST http://localhost:8080/api/orders/search -H "Content-Type: application/json" -d ‘{"startTime": "2025-01-01", "endTime": "2026-12-31", "minAmount": 500, "productName": "蓝牙", "pageNum": 1, "pageSize": 10}’系统日志直接输出了刺眼的慢查询告警:
[http-nio-8080-exec-1] OrderController.searchOrders 耗时: 18375msLIKE ‘%蓝牙%’的全表扫描导致接口耗时近 18 秒,当前业务接口的实现性能完全无法满足线上要求:

笔者直接将系统日志中的慢查询告警丢给 AI,让其结合项目既有代码完成推理分析和优化方案设计:
针对系统日志中记录的"[http-nio-8080-exec-1] OrderController.searchOrders 耗时: 18375ms"这一慢查询接口问题,对订单业务进行全面梳理分析并提供优化建议。AI 定位到目标业务代码,结合 SQL 和表结构,从索引设计维度给出了系统性的解决方案:

同时给出了分阶段优化建议和预期效果:

确认方向后,笔者给出最终优化指令:
请结合项目现有技术栈,对慢查询模块进行系统性优化AI 逐个梳理了每个接口的业务逻辑和查询细节。优化步骤自底向上,从数据库层面一路推进到应用层面,方案涵盖以下几个关键点:
数据库层面——新增 5 个精准索引:
- 全文索引
ft_product_name(ngram 解析器,支持中文分词)替代LIKE ‘%xxx%’全表扫描 - 复合索引
idx_create_time_amount覆盖时间+金额的 WHERE 和 ORDER BY,避免 filesort - 覆盖索引
idx_search_covering让 COUNT 查询不回表 - 组合索引
idx_user_status_category优化多条件筛选 - 覆盖索引
idx_status_category_amount优化品类聚合统计
ALTER TABLE orders ADD FULLTEXT INDEX ft_product_name (product_name) WITH PARSER ngram; ALTER TABLE orders ADD INDEX idx_create_time_amount (create_time DESC, total_amount); ALTER TABLE orders ADD INDEX idx_search_covering (create_time, total_amount, product_name); ALTER TABLE orders ADD INDEX idx_user_status_category (user_id, status, category); ALTER TABLE orders ADD INDEX idx_status_category_amount (status, category, total_amount);应用层面——SQL 和 Service 层同步优化:
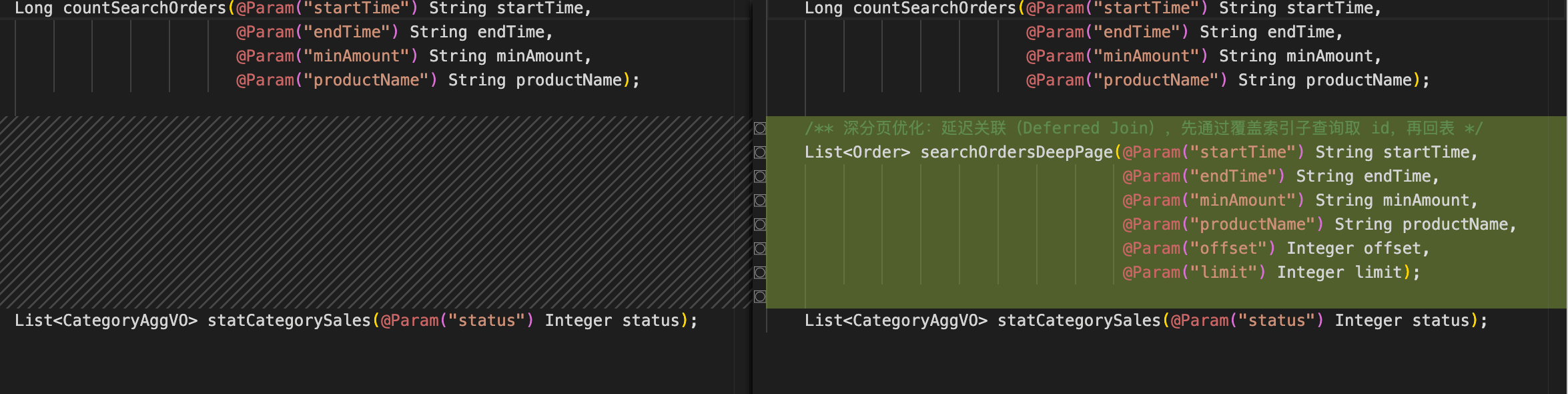
LIKE ‘%xxx%’替换为MATCH … AGAINST全文检索- 深分页场景自动切换延迟关联(Deferred Join),通过覆盖索引子查询先定位主键再回表
- 按需 COUNT:默认不查总数,仅前端显式传
needTotal=true时才执行
下面是 AI 输出的索引优化方案,5 条 DDL 语句全部给出,且每个索引的设计都有明确的优化目标:

从代码 diff 可以直观地看到,AI 在既有代码中进行增量迭代,将LIKE模糊查询替换为全文检索,同时保留原有业务逻辑不变:
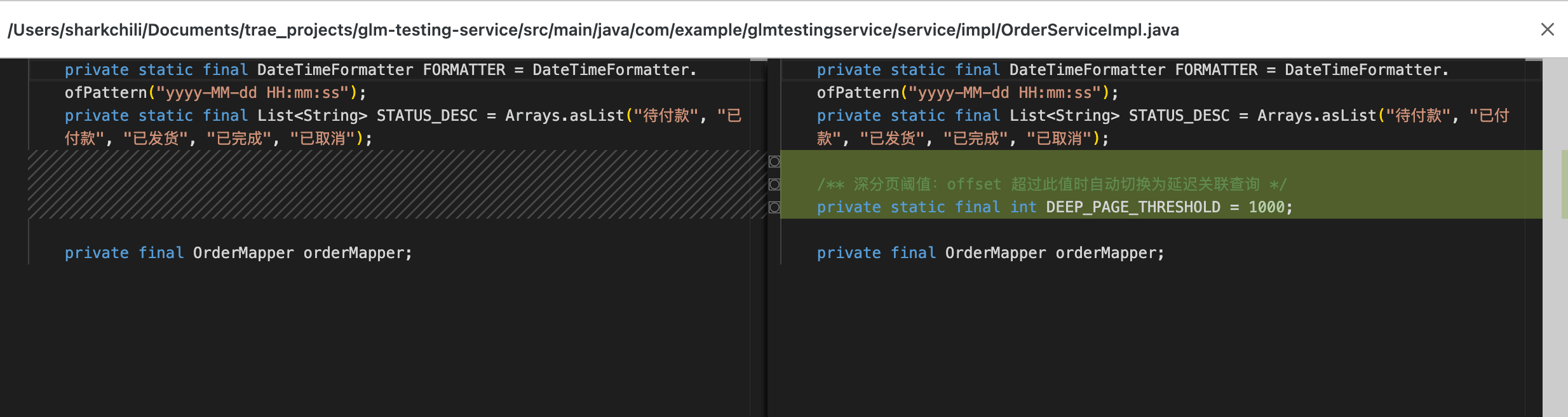
对于深分页的问题,AI 结合当前百万级数据量给出了具体的分页阈值——当 offset 超过 1000 时自动切换为延迟关联查询(Deferred Join),浅分页走普通查询,深分页走覆盖索引子查询先定位主键再回表:
/ 深分页阈值:offset 超过此值时自动切换为延迟关联查询 */ private static final int DEEP_PAGE_THRESHOLD = 1000; // 深分页(offset > 1000)走延迟关联,浅分页走普通查询 boolean isDeepPage = offset > DEEP_PAGE_THRESHOLD; List<Order> orders; if (isDeepPage) { orders = orderMapper.searchOrdersDeepPage(…); } else { orders = orderMapper.searchOrders(…); }AI 在这个方案中结合具体数据量给出了阈值策略。在评审这类方案时,建议关注阈值的合理性——1000 这个值在百万级数据量下是合理的,但如果你的数据量是千万级或十万级,可能需要调整。
全部优化完成后,AI 输出了最终的优化效果总结,涵盖各接口的优化前后对比:

完成改造后再次对接口进行压测,效果如下。接口经过预热后耗时稳定控制在 300ms 以内,从 18375ms 降至 300ms 以内,性能提升超过 60 倍。 整个过程中,笔者做的事情只有三件:给出问题、评审方案、验收结果。

通过两个场景的实战,总结一下使用 Claude Code + 第三方模型辅助编程的经验和思考。
做得好的地方:
- 快速验证架构构想:场景一中,从需求描述到完整的技术方案和架构设计,整个过程不到 10 分钟,对快速验证技术可行性很有帮助
- 多层级方案输出:慢查询场景中,数据库层面的索引优化和应用层面的 SQL 重构同步推进,覆盖比较全面
- 结合数据量做决策:场景二中针对百万级数据量给出了深分页阈值,而不是简单套用通用方案
需要注意的地方:
- 架构方案需要人工评审:AI 给出的架构设计和数据流看似完整,但细节上可能存在问题。比如场景一中 Arthas HTTP API 的会话模式设计,需要你理解 Arthas 的通信模型才能判断其合理性
- 长链路执行中偶尔断链:在复杂的持续编码任务中,AI 有时会在后半程遗忘前面的设计约束。建议将复杂任务拆分成明确的阶段,每个阶段独立确认
- 代码风格与工程规范:生成的代码结构合理,但与个人/团队既有规范的契合度需要磨合。场景一中有部分命名和文件组织就需要手动调整
- 方案选择的权衡:AI 会给出多个方案,但不会替你做权衡。比如场景二中全文索引 vs ES 的选择、延迟关联 vs 游标分页的取舍,这些需要根据业务场景判断
- 需求描述要具体:场景一中完整的需求 prompt 直接决定了架构方案的质量,模糊的需求只会得到模糊的方案
- 分阶段确认:复杂项目不要一次性让 AI 从头到尾生成,技术选型 → 架构设计 → 编码实现,每个阶段独立评审
- 关键决策人工把控:架构层面的选择(如缓存策略、分页方案)需要根据业务场景判断,AI 无法替你做
- 善用文档链接:当需要集成某个现成组件时(如场景一的 Spring AI Alibaba),直接给出文档链接比详细描述需求更高效
Claude Code 接入第三方模型后,在 Agent 模式下的上下文理解、任务拆解、代码生成形成了比较完整的工作流。两个场景跑下来,AI 辅助编程确实能显著缩短“从想法到代码”的时间。
但工具终究只是工具。回顾本文的两个场景:
- 场景一中的 JVM 智能诊断 Agent,需要对 Arthas 的通信模型、JVM 诊断方法论有清晰认知,才能评审 AI 给出的架构方案是否合理——Arthas HTTP API 的会话生命周期管理、Skill 引擎的诊断步骤链设计,这些都需要你来把关。
- 场景二中的慢查询治理,需要对 MySQL 索引原理、全文检索机制、深分页优化策略有深入理解,才能判断 AI 给出的优化方案是否适用于你的业务场景——比如全文索引在写入频繁的场景下可能带来性能损耗,延迟关联的阈值需要根据实际数据量调整。
AI 编程工具正在改变开发者的工作方式——从“写代码的人”变成“评审代码的人”。但评审的前提,是你比 AI 更懂你在做什么。
- GLM-5.1 Coding Plan 上线公告:https://docs.bigmodel.cn/cn/coding-plan/
- Claude Code 安装指南:https://docs.anthropic.com/en/docs/claude-code
- cc-switch 模型切换工具:https://github.com/farion1231/cc-switch
- Spring AI Alibaba 官方文档:https://java2ai.com/docs/
- Arthas 官方文档:https://arthas.aliyun.com/doc/
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/253549.html