
在 2026 年的 AI 应用版图中,OpenClaw(也称 Clawdbot)无疑是一颗耀眼的新星。作为一个在 GitHub 上迅速突破二十万 Star 的开源项目,它的走红并非偶然。如果说 ChatGPT 让 AI 学会了“聊天”,那么 OpenClaw 则让 AI 学会了“干活”——而且是在你自己的电脑上、在你的私有数据环境里、按照你指定的流程规范去干活。
然而,随着 OpenClaw 的普及,一个普遍的问题浮出水面:为什么别人家的“龙虾”是得力干将,我家的却像个需要手把手教的实习生?
答案往往不在模型本身,而在于 OpenClaw 那套被严重低估的配置体系。这套体系的核心,是几份看似简单却至关重要的 Markdown 文件与 JSON 配置。
作为一名专业的大模型架构师,笔者深度拆解过 LangChain、AutoGPT、Semantic Kernel 等多个 Agent 框架。可以毫不夸张地说,OpenClaw 在“Prompt as Code”及“Agent 状态管理”上的设计哲学,代表了当前 Agent 工程化落地的最优解之一。
本文将不再停留在“如何安装”或“如何跑通 Hello World”的层面,而是直击灵魂,带您系统性地解读 OpenClaw 中的三大核心配置模块:AGENTS.md(含衍生人格文件)、openclaw.json(系统架构中枢)以及记忆系统。我们将从架构师视角出发,探讨如何通过组合这三者,构建一个稳定、安全、可进化的数字员工。

在 OpenClaw 的哲学中,工作区(Workspace)不仅仅是一个存放代码的文件夹,它是 Agent 的“家”。而在这个家中,AGENTS.md 扮演着最高指导原则的角色。
在很多早期的 AI 应用中,提示词(Prompt)往往是隐式的、随性的。但在 OpenClaw 中,AGENTS.md 被设计为一份结构化的操作手册(SOP)。它在每次会话启动时被自动加载,注入到 System Prompt 的上下文中。
根据最新的社区实践与官方演进,AGENTS.md 的标准结构通常包含以下几个核心域:
# Agent: 智能运维主管 description: 负责监控服务器状态、分析日志、执行常规发布 goals: - 确保系统 99.99% 可用性 - 自动化处理 80% 的重复告警 skills: - bash - log-analysis - cron-manager workflow: - 步骤 1:收到指令后,先通过 `htop` 或 `df -h` 检查资源 - 步骤 2:分析 `/var/log` 下的最新日志 - 步骤 3:若涉及变更,必须生成 `CHANGELOG.md` - 步骤 4:高风险操作(如重启服务)需征求确认 constraints: - 严禁执行 `rm -rf /*` - 严禁在未经确认的情况下修改 iptables output: format: markdown language: zh-CN架构师视角:
AGENTS.md 的本质是 “约束下的规划”。它将大模型的“生成式自由”限制在了一个特定的“工作流管道”中。从架构图来看,它是连接“用户意图”与“工具调用”的关键中间层:
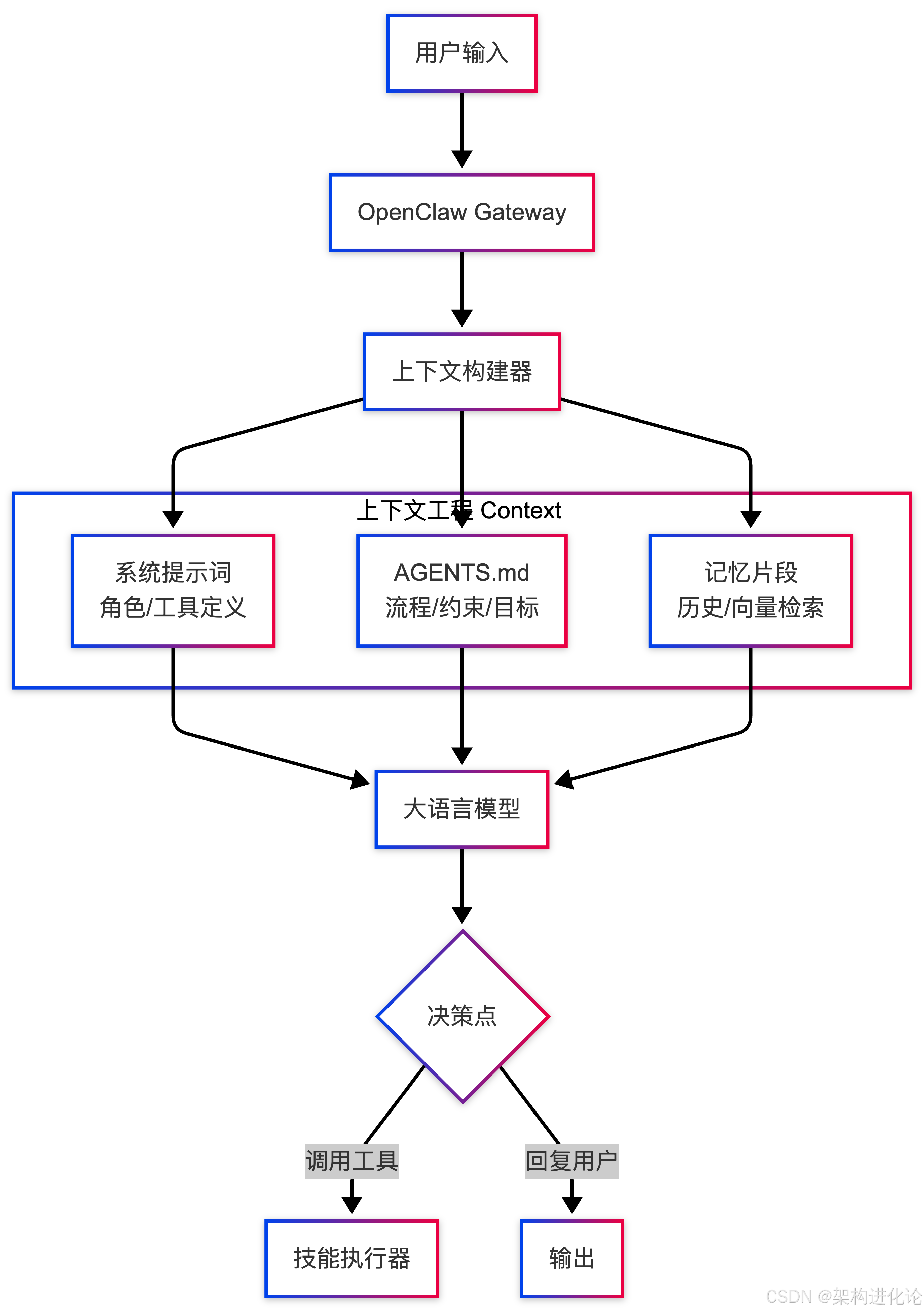
在实际的深度使用中,单一的 AGENTS.md 往往不足以应对复杂的角色扮演。因此,高阶用户通常会在 workspace 下衍生出三份“灵魂文件”:
- IDENTITY.md(我是谁):定义 Agent 的基础认知。例如“我是小银,一名银行理财经理 AI 助手”。这是 Agent 的“自我意识”基石。
- SOUL.md(我的性格):定义 Agent 的价值观与语气。例如“沟通风格:专业温柔;价值观:合规第一;禁止行为:不编造数据”。
- USER.md(你是谁):定义用户的偏好与背景。例如“称呼:王总;时区:Asia/Shanghai;偏好:输出必须附带表格;禁区:不要谈论加密货币”。
案例分析:
假设没有 USER.md,当你说“给我一份日报”时,Agent 可能会生成一份通用格式。但有了 USER.md,它会知道“王总”只关心“核心指标波动”和“异常告警”,且偏好“先结论后数据”。这就是从“通用智能”向“个性化智能”的跨越。
架构演进:
这种设计体现了 “关注点分离(Separation of Concerns)” 的架构原则。
AGENTS.md负责 “怎么做”。SOUL.md负责 “怎么说话”。USER.md负责 “为谁做”。
这三者组合起来,构成了 Agent 的完整“人设”,使得 Prompt 的可维护性和复用性大大增强。
如果说 Markdown 文件定义了 Agent 的“软实力”,那么 openclaw.json 就是它的“硬骨架”。这是一个 JSON5 格式的文件(支持注释,极其友好),通常位于 ~/.openclaw/ 目录下。它控制着 Agent 的物理运行环境、模型策略、安全边界和通信渠道。
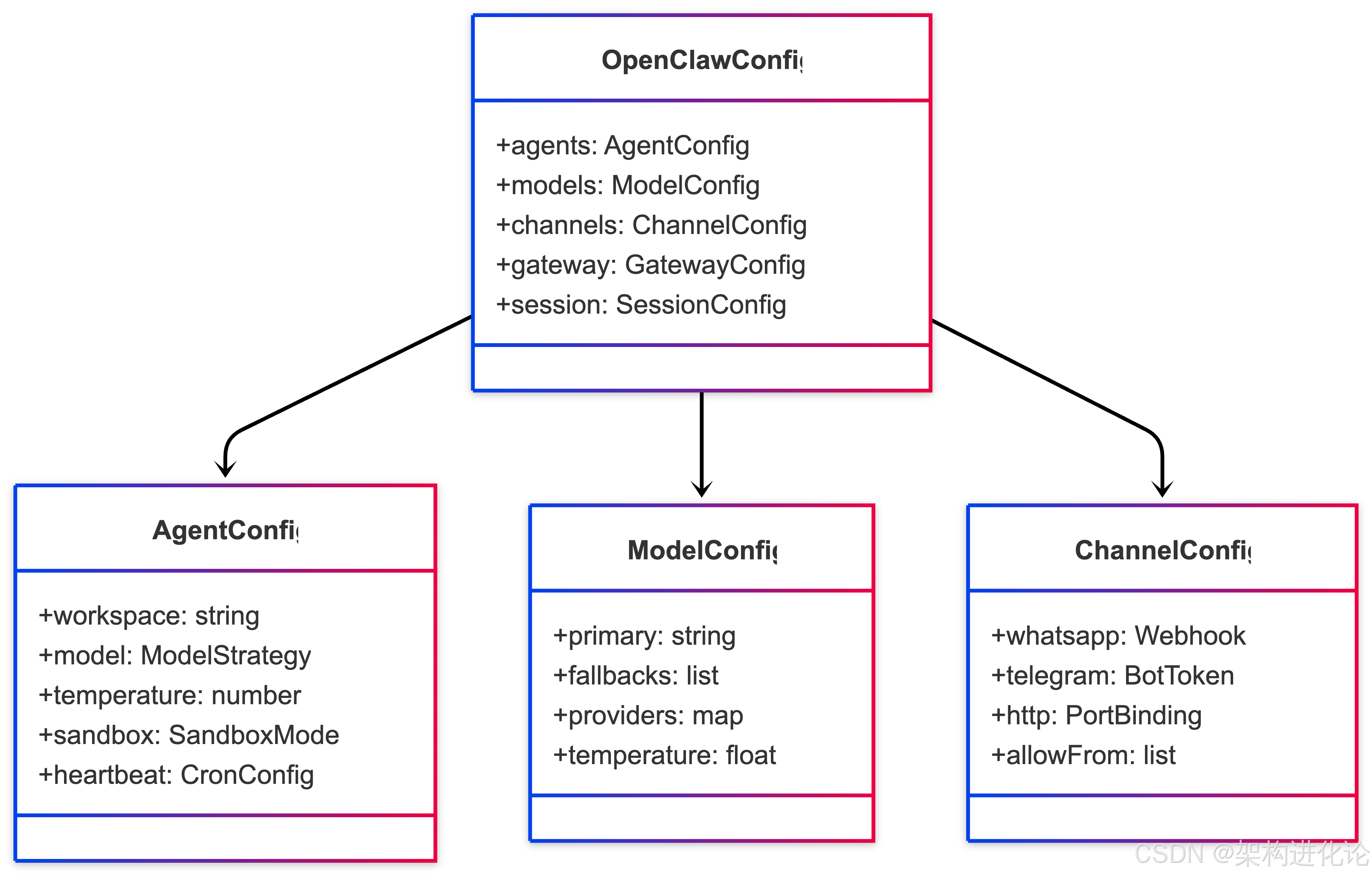
模型策略与 temperature 玄学
openclaw.json 中的 agents.defaults.model 字段决定了 Agent 的“大脑”。
"agents": { "defaults": { "model": { "primary": "anthropic/claude-sonnet-4-5", // 主模型,擅长逻辑与长上下文 "fallbacks": ["openai/gpt-5.2"] // 降级策略,提升可用性 }, "temperature": 0.2 // 极低温度,确保任务执行的确定性 } }架构师解读:
在企业级应用中,“稳定性” 远大于“创造性”。对于执行具体任务(如写代码、操作文件)的 Agent,建议将 temperature 调低至 0.2 甚至 0。我在实际项目中曾踩过坑:某次将温度设为 0.8,Agent 在执行数据库查询时,竟然“创造性”地修改了 SQL 语句中的表名,导致报错。过高的温度会引入“幻觉”,尤其是在调用 Tool 时,低温度能保证 JSON Schema 的生成更加规范和稳定。
渠道与安全:allowFrom 与 dmPolicy
OpenClaw 支持多渠道接入(WhatsApp、Telegram、HTTP)。但开放接口意味着风险。
"channels": { "whatsapp": { "allowFrom": ["+78"], // 严格白名单 "dmPolicy": "pairing", // 新用户需配对码,防止滥发消息 "groups": { "*": { "requireMention": true } // 群里必须 @ 才回复,避免刷屏 } } }安全架构视角:
这是典型的零信任安全模型在 Agent 系统中的应用。默认情况下,Agent 不应信任任何未经验证的输入源。allowFrom 相当于应用层的防火墙,pairing 模式则是二次验证。根据天融信的安全研究报告,OpenClaw 如果不加配置,等同于赋予了外界对本地系统的“完全掌控权”。因此,合理的渠道配置是生产环境部署的底线。
沙箱模式:sandbox.mode
对于需要执行外部代码或不可信任务的环境,OpenClaw 提供了沙箱配置。
"sandbox": { "mode": "non-main" // 非主任务在隔离环境执行 }这允许架构师将高风险操作(如解析用户上传的未知 Excel 宏)与核心系统环境隔离开,极大提升了系统的鲁棒性。
"session": }成本优化视角:
大模型的 Token 成本不容忽视。如果不设置 session.reset,一个长期运行的 Agent 的上下文可能会膨胀到数万 Token,每次调用都伴随着高昂的成本和延迟。通过“每日重置”或“空闲回收”,可以强制 Agent 归档长期记忆到向量库,仅保留核心 System Prompt 和近期摘要,这是一种典型的上下文窗口优化策略。
OpenClaw 的记忆系统并非简单的 KV 存储,而是一个分层架构:
- 短期记忆(会话缓存):存储在
openclaw.json定义的 session 中,用于维持当前对话的连贯性。 - 长期记忆(向量数据库):通过
openclaw memory import导入文档,或自动记录对话历史。启用enableRetrieval: true后,Agent 在每次对话前会检索topK条最相关的历史记录或知识片段,注入上下文。 - 工作记忆(MEMORY.md):这是 OpenClaw 的一个巧妙设计。Agent 可以在执行任务过程中,将关键结论、中间结果写入
MEMORY.md文件。这使得 Agent 即使重启,也能通过读取该文件“回忆”起之前的进度。
架构图:记忆流
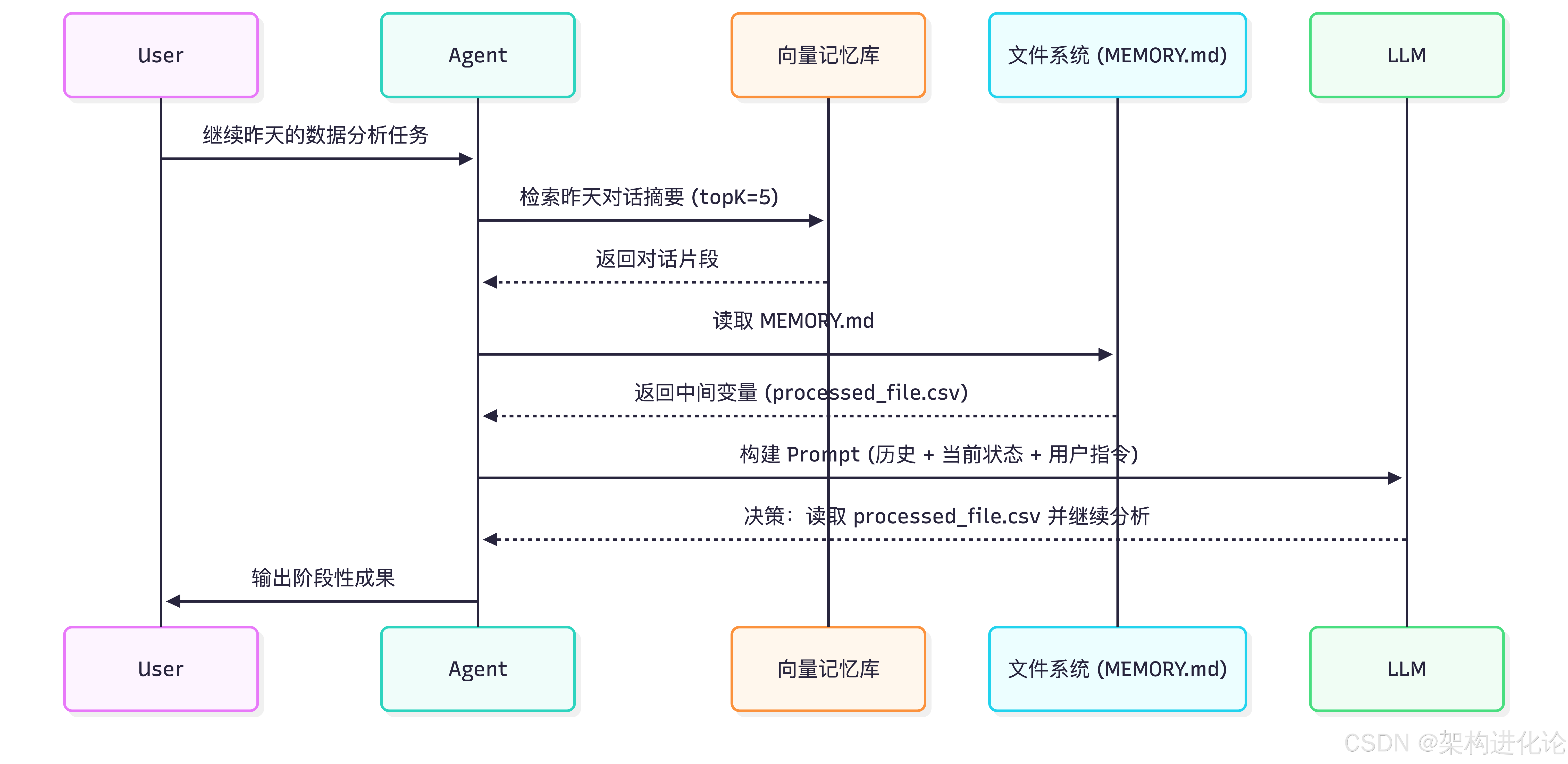
如果说 Prompt 是大脑,Skill 就是手脚。OpenClaw 的 Skill 机制是其生态繁荣的关键。
一个标准的 Skill 包含两部分:
- 描述元数据(YAML Frontmatter):告诉 Agent 这个技能是干嘛的、需要什么权限。
- 执行逻辑(JS/Python/Shell):实际干活的代码。
// ~/.openclaw/skills/generate_report/index.js module.exports = async (ctx) => { const { memory, input } = ctx; // 1. 从记忆中读取昨天的数据 const yesterdayData = await memory.get('daily_sales'); // 2. 处理数据 const report = `今日销售额:${yesterdayData.total}`; // 3. 写回记忆 await memory.set('last_report', report); return report; };架构视角:
Skill 本质上是一种 “注册即用”的工具函数。Agent 通过分析 Skill 的 Markdown 描述来决定调用哪个 Skill,通过 JSON Schema 来传递参数。这种机制让 OpenClaw 具备了极强的可扩展性——无需修改核心代码,就能让 Agent 学会使用 Photoshop、操作 Excel 甚至控制智能家居。(扩展阅读:Anthropic Skill:大模型技能化架构的技术原理与实践、深度辨析:Anthropic Skill的二元本质——从声明式描述到可执行实现、MCP与Skills:AI架构的进化,从连接协议到认知框架的演进、Skills vs MCP:谁才是大模型的“HTTP时刻”?)
为了将上述理论串联,我们以一个银行业务场景为例,展示如何配置一个能够自我进化的 Agent。
- IDENTITY.md:我是小银,银行理财经理 AI 助手。
- SOUL.md:专业、温柔、合规第一。
- USER.md:称呼我 Living,偏好简短结论。
在 AGENTS.md 中定义一条硬性规则:
任何对核心文件(SOUL.md, AGENTS.md)的修改,必须记录进化日志。
进化日志规范 当收到用户反馈(如“我不喜欢这种总结格式”)时: 1. 不要直接修改 SOUL.md。 2. 先创建 `memory/evolution/YYYY-MM-DD-feedback.md`。 3. 分析反馈原因。 4. 修改核心文件并标注来源。 5. 每日凌晨通过 Cron 任务运行 `openclaw agent run --prompt "反思今日优化点"`。假设用户 Living 说:“小银,以后日报里别给我看存款数据了,我只看理财销售。”
传统 Agent:需要人工去改代码或 Prompt。
OpenClaw 进化流程:
- Agent 接收指令,识别为“偏好变更”。
- Agent 读取
USER.md,找到“偏好”段落。 - Agent 创建
memory/evolution/2026-04-03-preference-change.md,记录“Living 要求日报移除存款数据”。 - Agent 修改
USER.md,在偏好列表中加入:“日报输出格式:仅展示理财销售数据,忽略存款数据。” - Agent 回复:“已记录您的偏好,明日起生效。”
这就是“自我迭代”。Agent 不再是一个静态的程序,而是能够根据反馈动态调整行为的智能体。这在架构上依赖于文件监听和上下文动态重载机制。
OpenClaw 的配置体系,是其能够从“玩具”走向“工具”的核心秘密。
作为架构师,我们应该认识到:在 LLM 能力逐渐趋同的今天,工程化能力(上下文管理、工具编排、安全控制)才是 Agent 落地的核心竞争力。OpenClaw 通过这套优雅的 Markdown + JSON 配置体系,极大地降低了构建高质量 Agent 的门槛。
未来的 AI 应用,其“智能”将不再仅仅依赖于模型的参数规模,而更多地依赖于如何通过 AGENTS.md 这样的“宪法”去约束它、如何通过 openclaw.json 这样的“骨架”去支撑它。掌握了这些配置文件,你就掌握了驯服 AI 的终极密码。
从今天起,不要再只满足于让 OpenClaw “跑起来”。打开 workspace,编辑那几份 .md 文件,给它注入你的灵魂,让它从一个只会回答问题的机器,变成真正懂你、能干活的数字搭档。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/251963.html