
在人工智能,尤其是大模型应用的浪潮中,我们的工作重心正在从提示工程逐步转向代理工程。
简单来说,提示工程是指导大模型去完成单一轮次的特定需求。而代理工程则更进一步,它侧重于通过建立适当的框架、方法和心理模型来有效地设计、编排整个复杂的任务流程。
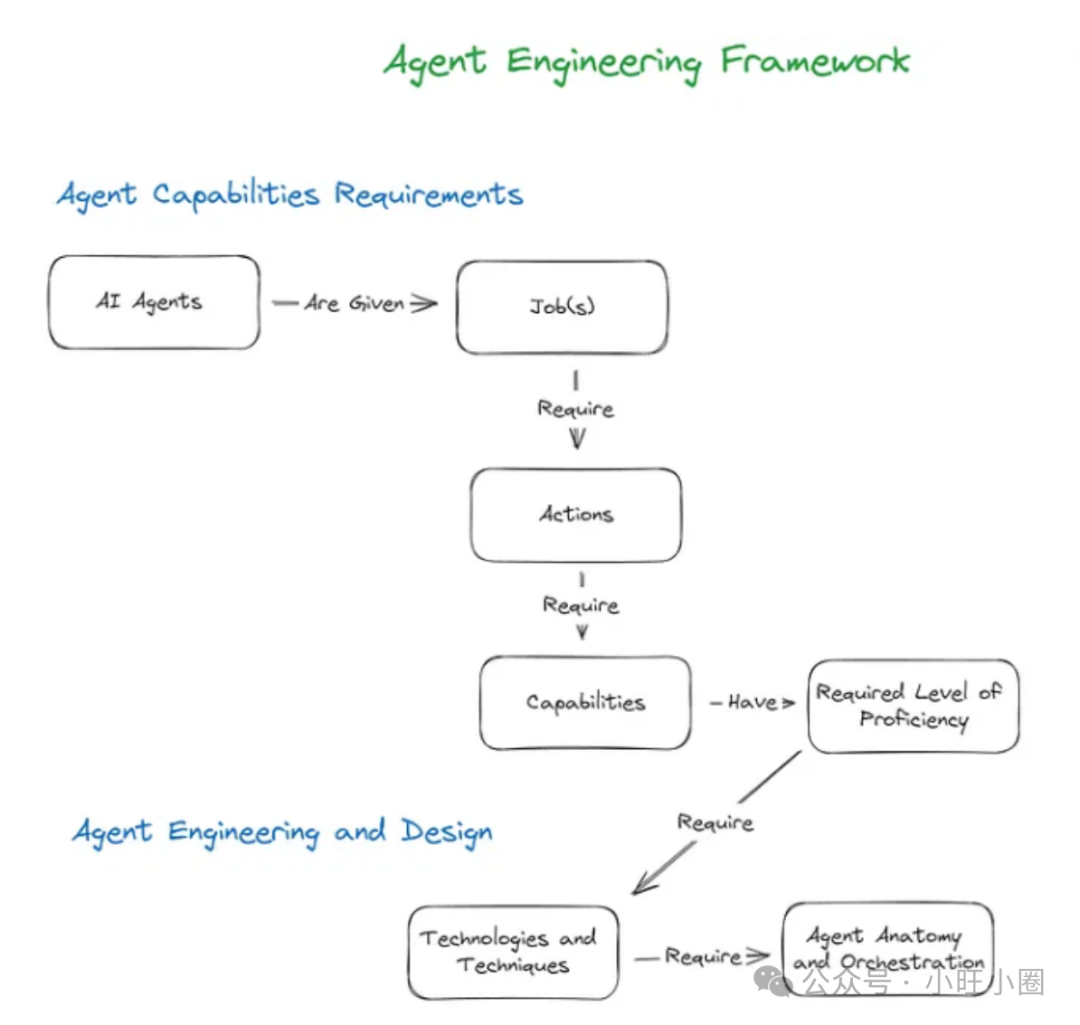
如上图所示,整个框架清晰地描绘了从赋予AI代理任务到技术实现的递进关系。它始于一个目标——AI代理被赋予特定的工作(Job(s))。为了完成工作,代理需要执行一系列操作(Action(s)),而每个操作背后都对应着所需的特定能力(Capabilities)及其熟练程度(Required Level of Proficiency)。
那么,如何让代理拥有这些能力并达到熟练程度呢?这依赖于各种技术与技巧(Technologies and Techniques),而它们的有效整合又必须通过精确的编排(Orchestration)来实现。整个过程环环相扣,共同构成了AI智能体高效运作的基础系统。
设计AI代理,首先要明确它究竟要做什么。这个高级目标可以分解为一系列具体的工作和任务。让我们用一个生活化的例子来感受一下这个过程:
假设“我”萌生了去北京旅游的想法。按照常规思路,我会进行以下准备:
想法1:首先,我需要了解北京的热门景点并制定一个旅**程。 行动1:我会在小红书上搜索相关的旅游攻略。 观察1:根据攻略,我制定了一个为期三天的旅游计划。接下来,我需要考虑如何到达北京,这意味着我得订购机票。 想法2:我需要预订飞往北京的机票。 行动2:我现在使用携程APP来订购机票。 观察2:机票已经订好,我已经能够到达北京了。既然计划在那里停留三天,我还需要解决住宿的问题。 想法3:接下来,我要预订酒店,以确保北京行的住宿安排。 行动3:我在飞猪APP上搜索并预订了北京的酒店。 观察3:酒店预订已确认。 结论:现在所有的准备工作都已完成,我可以放心出发了。这个过程清晰地展示了思考、行动、观察、再思考的循环。如果我们想让一个大语言模型来模拟这个自主规划过程,就需要通过提示工程来引导它。
GPT plus 代充 只需 145prompt = """ 你需要在“思考、行动、观察、回答”的循环中运行。 在循环的最后,你需要输出一个答案。 使用“思考”来描述你对被问及问题的思考。 使用“行动”来执行可用的行动之一。 “观察”将是执行这些行动后的结果。 “回答”将是对观察结果的分析。 你的可用行动有: 小红书: 例如:小红书: 北京旅游攻略 通过小红书API搜索,并返回北京旅游攻略和推荐。 携程: 例如:携程: 前往北京的航班 通过携程API搜索,并找到前往北京的可用航班。 尽可能使用小红书和携程API进行查询。 示例会话: 问题: 我正计划去北京旅游,我应该先做什么? 思考: 我应该在小红书上查找关于访问北京的景点和攻略。 行动: 小红书: 北京旅游攻略 观察: 搜索返回了北京的热门旅游攻略和必游景点的列表。 回答: 首先,你可以在小红书上了解北京的必游景点和旅游攻略。接着,在携程上查找可用的前往北京的航班,并考虑住宿选择。 ....... """
你可以把代理工程理解为更加复杂的提示工程。它的关键跃迁在于:不再是提供一个简单的任务描述,而是明确界定代理的职责,详尽规划完成任务所需的操作步骤,并清晰定义执行这些操作所必备的能力,从而构建一个高级的、可执行的认知模型。这种复杂且结构化的提示之所以有效,其核心思想源于 ReAct 框架。
ReAct 框架的名称来源于 Reason(推理) 和 Act(行动) 的结合。它的灵感正来自于人类如何和谐地结合思维与行动来完成任务——就像上面“我想去北京旅游”的例子一样。
Reason 部分基于一种关键的推理技术——思想链(Chain-of-Thought, CoT)。CoT 是一种提示工程技术,通过将复杂问题分解为多个连续的、逻辑性的思维步骤,来帮助大语言模型进行推理。
这种方法具体包括:
- 分解问题:将复杂任务拆解成更小、更易处理的子问题。
- 顺序思维:每一步的推理都建立在上一步的结果之上,从而构建出一条完整的逻辑链。
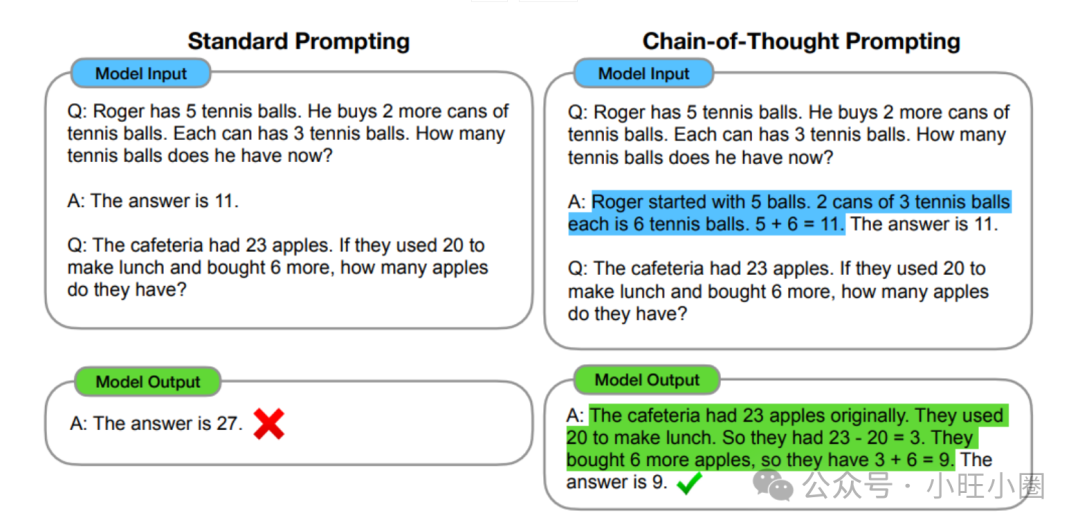
然而,纯粹的CoT提示存在局限:大模型在推理的中间阶段仍然可能产生“幻觉”或传播错误。为了弥补这一缺陷,Google DeepMind团队提出了ReAct框架。
ReAct 的核心创新在于引入了 “思考-行动-观察” 的循环。代理不仅进行内部推理(Thought),还会根据推理结果采取外部行动(Action),然后观察行动的结果(Observation),并基于新的观察进行下一轮思考。这个迭代过程使代理能够根据实时反馈动态调整其策略。
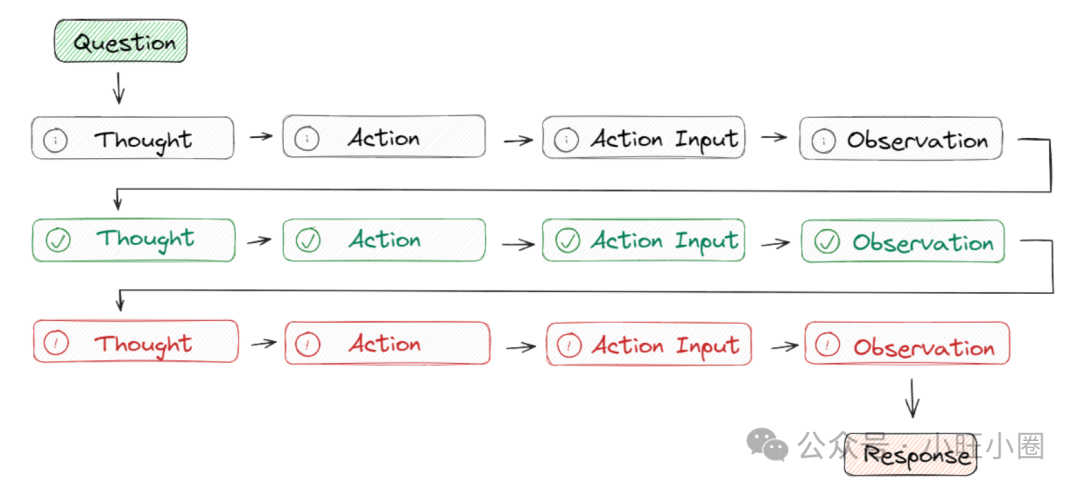
在这个循环中:
- Question:用户提出的任务或问题。
- Thought:分析现状,决定下一步要采取的行动,相当于制定或调整计划。
- Action:执行一个具体的、有预定义范围的操作(如调用API、查询工具)。
- Observation:获取执行动作后外部环境返回的结果。
- 重复此过程,直至任务完成,最终输出 Response。
让我们看一个更通用的ReAct提示词示例:
prompt= ”“” 您在一个由“思考、行动、观察、回答”组成的循环中运行。 在循环的最后,您输出一个答案。 使用“思考”来描述您对所提问题的思考。 使用“行动”来执行您可用的动作之一。 “观察”将是执行这些动作的结果。 “回答”将是分析“观察”结果后得出的答案。 您可用的动作包括: calculate(计算): 例如:calculate: 4 * 7 / 3 执行计算并返回数字 - 使用Python,如有必要请确保使用浮点数语法 wikipedia(维基百科): 例如:wikipedia: Django 返回从维基百科搜索的摘要 如果有机会,请始终在维基百科上查找信息。 示例会话: 问题:法国的首都是什么? 思考:我应该在维基百科上查找关于法国的信息 行动:wikipedia: France 然后您应该调用适当的动作,并从结果中确定答案 您然后输出: 回答:法国的首都是巴黎 “””如上例所示,在ReAct框架下构建Agent,我们需要清晰地定义两件事:代理的身份与任务,以及完成任务所需的工具。代理身份通常通过系统角色(System Role)设定,而工具的定义与使用,则与我们熟知的Function Calling技术紧密相关,只不过在代理框架下,这些工具被集成到了“行动-观察”的循环之中,以实现更动态、更复杂的问题解决能力。
如果你对如何利用LangChain等框架将这些理论付诸实践感兴趣,欢迎在云栈社区与更多开发者交流探讨。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/248880.html