
本文完整展示如何从 0 到 1 手搓一个 AI Agent 的搭建过程。
在具体动手实操的过程中,重点为大家展示从需求分析到如何搭建。
需求分析中包含如何识别 AI 提效场景和、梳理提效场景流程。
如何搭建中包含工作流创建、智能体创建、智能体发布。
接下来,将结合实际Demo, 从整体架构到核心模块的实现,完整展现一个多Agent协同系统的开发过程。
下面以Demo中的几个典型Agent为例,详细介绍设计思路与实现方式,基于Eino框架快速落地多智能体协作系统。
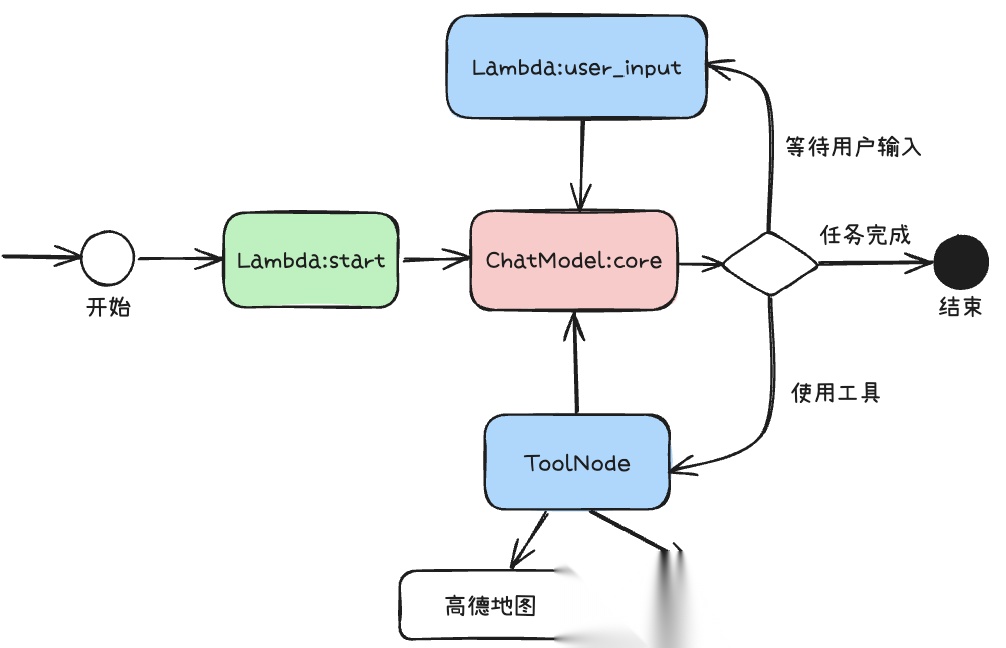
智能体规划 Agent 使用经典的ReAct框架实现。
能够检索目的地的景点介绍、游玩攻略、美食推荐等内容。在此之上,通过增加了
Lambda:user_input节点等待用户下一轮对于行程规划的建议和追问。
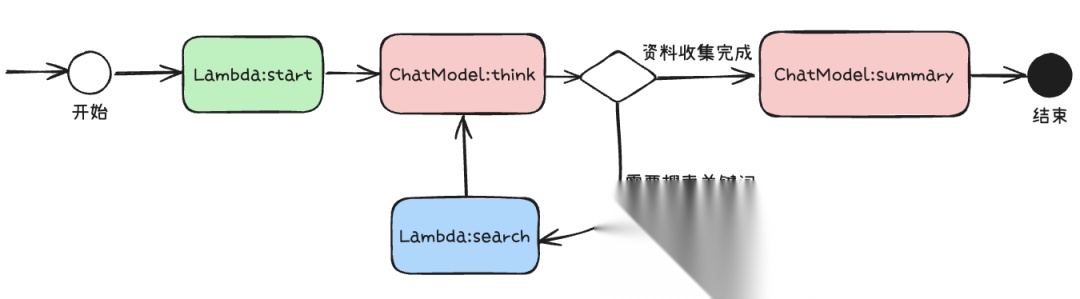
深度搜索 Agent 利用大模型对复杂问题进行多角度分析,边推理边搜索。
在执行流程内部,通过
ChatModel:think进行问题分析,并判断上下文的资料是否足够回答用户问题,
如果不够那么输出关键词借助搜索工具获取资料补充上下文,
如果足够,通过
ChatModel:summary模型,输出对于问题的分析总结报告。
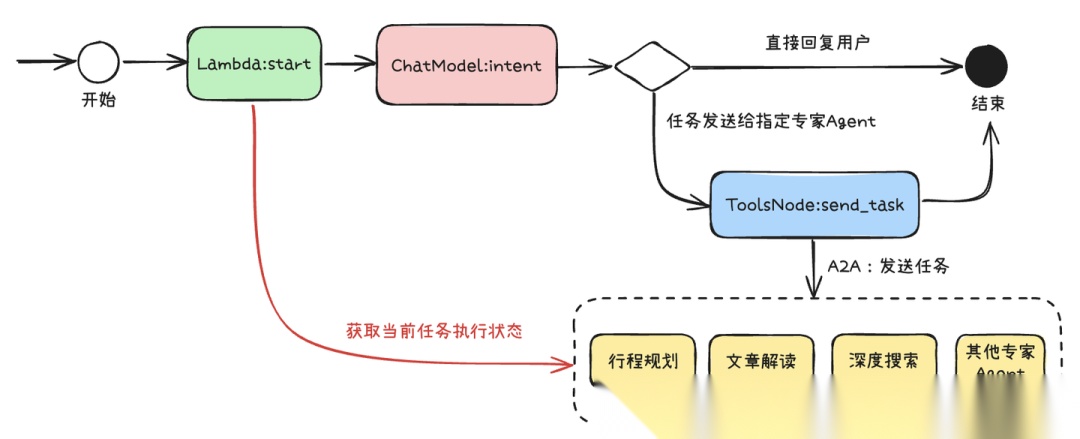
这种设计让意图识别Agent具备了高度的灵活性和可扩展性。
- 一方面,它能够根据用户需求动态选择并 对接不同类型的下游专家Agent,实现多智能体间的高效协作与任务流转;
- 另一方面,专家Agent采用标准化A2A协议进行封装,具备天然的可插拔能力,通过AgentCard描述能力让意图识别Agent进行判断当前的任务类型, 支持在系统运行时无缝添加、替换或扩展新的专家Agent。
Connector是A2A多Agent系统实现"能力复用"和"生态扩展"的关键。
它的核心目标是将标准化的Agent能力,通过协议适配、接口封装等方式, 快速对接到不同的外部平台和应用场景,实现"写一次,处处可用"。
- 解耦:
Agent本身只关注业务逻辑和A2A协议实现,不直接依赖于任何具体平台。Connector负责协议转换、消息编解码、上下游适配,最大程度 降低Agent与外部生态的耦合度。
- 标准:
所有对接均基于A2A协议的标准输入输出格式, 保证能力的可组合性和可迁移性。无论是对接IM、Web、App还是第三方API,均通过统一的协议层进行交互。
- 可扩展:
Connector采用插件化、模块化设计,支持按需扩展新的平台适配器。只需实现对应的适配接口,即可将Agent能力无缝接入新的生态系统。
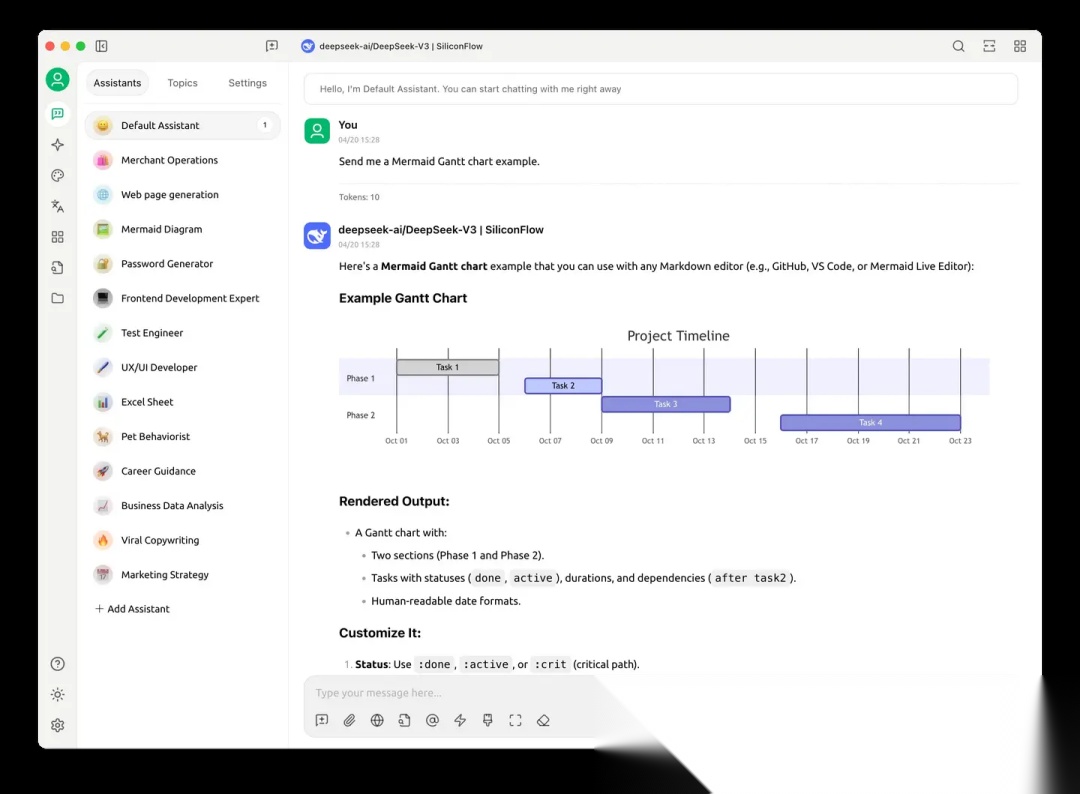
通过实现 OpenAI 兼容的 Connector,将 Agent 能力以标准
chat/completion协议对外暴露。
可以直接在
Cherry Studio客户端中便捷地接入和调试 Agent,实时体验其交互效果与能力表现,极大提升了开发和测试的效率与直观性。
- 实现
chat/completion接口,获取model作为Agent名字,调用A2AServer,将任务执行结果,使用SSE协议流式输出到chat/completion响应里
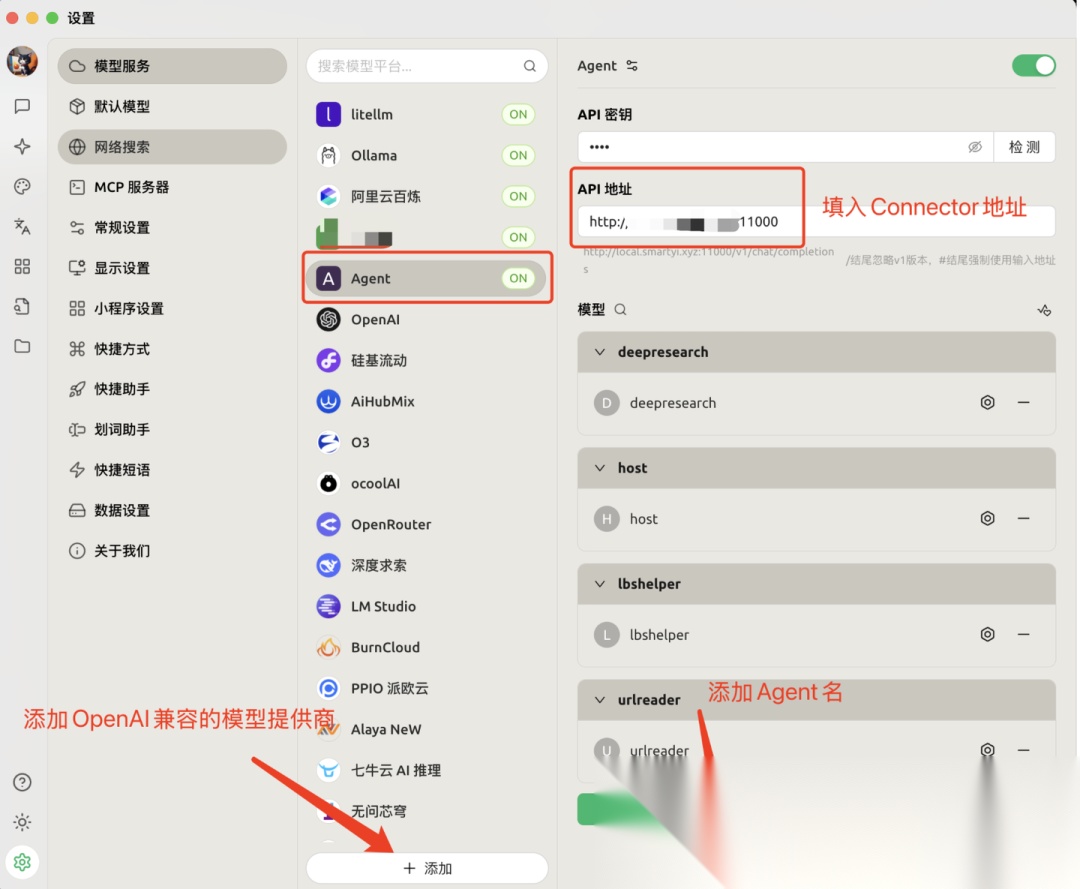
func (s *Server) chatHandler(c *gin.Context) ) return } else if err != nil { c.AbortWithStatusJSON(http.StatusBadRequest, gin.H{"error": err.Error()}) return } var foundAgent bool var agentConfig config.AgentConfig for _, agent := range config.GetMainConfig().OpenAIConnector.Agents } if !foundAgent { c.AbortWithStatusJSON(http.StatusBadRequest, gin.H{"error": fmt.Sprintf("agent %s not found", req.Model)}) return } ch := make(chan any) go func() { defer close(ch) initMessage := protocol.Message{ Role: "user", Parts: []protocol.Part{protocol.NewTextPart(req.Messages[len(req.Messages)-1].Content)}, } // 客户端 a2aClient, err := a2aclient.NewA2AClient(agentConfig.ServerURL, a2aclient.WithTimeout(time.Minute*10)) if err != nil { ch <- gin.H{"error": err.Error()} return } taskChan, err := a2aClient.StreamTask(c, protocol.SendTaskParams{ ID: taskID, Message: initMessage, }) if err != nil { ch <- gin.H{"error": err.Error()} return } for v := range taskChan { switch event := v.(type) { case protocol.TaskStatusUpdateEvent: handleTaskStatusUpdateEvent(c, req, ch, event) } } res := api.ChatResponse{ Model: req.Model, CreatedAt: time.Now().UTC(), Message: api.Message{Role: "assistant", Content: ""}, Done: true, DoneReason: "stop", } ch <- res }() // 流式返回数据 streamResponse(c, ch) } 配置 Cherry Studio 模型,连接 connector 服务
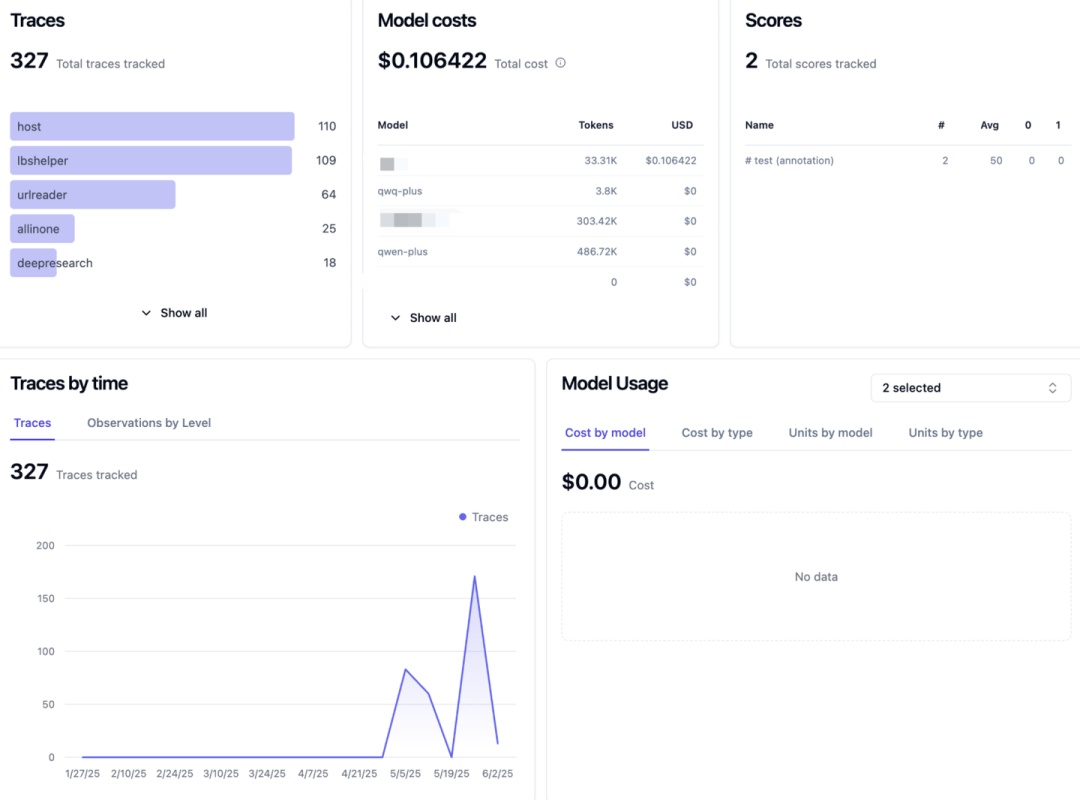
数据看板:通过 Dashboard ,可以实时查看LLM应用的质量、成本、延迟等多维度指标,全面监控和分析智能体系统的运行状态。
接下来进入了实操环节,在 Coze 上如何一步步的搭建这个 AI Agent(智能体)。
整个搭建过程分为工作流搭建、智能体搭建。
先做一个工作流,把我们上一步的流程在工作流中创建。
然后在创建一个智能体,将工作流嵌入进去。
首先,我们开始搭建工作流。
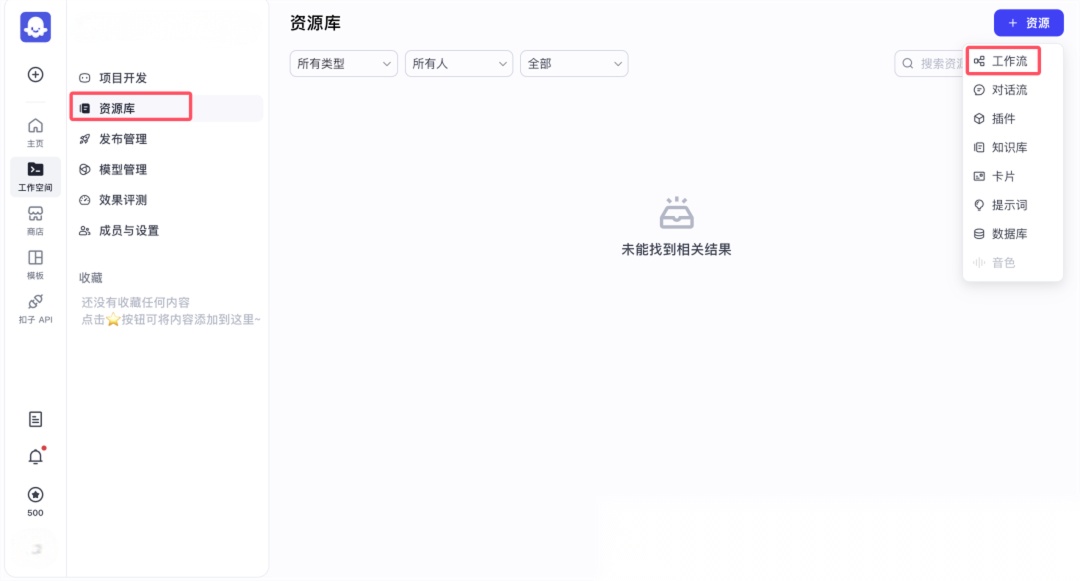
先点击 “资源库” ,鼠标停在右侧的 “资源” 上,点击 “工作流” 。
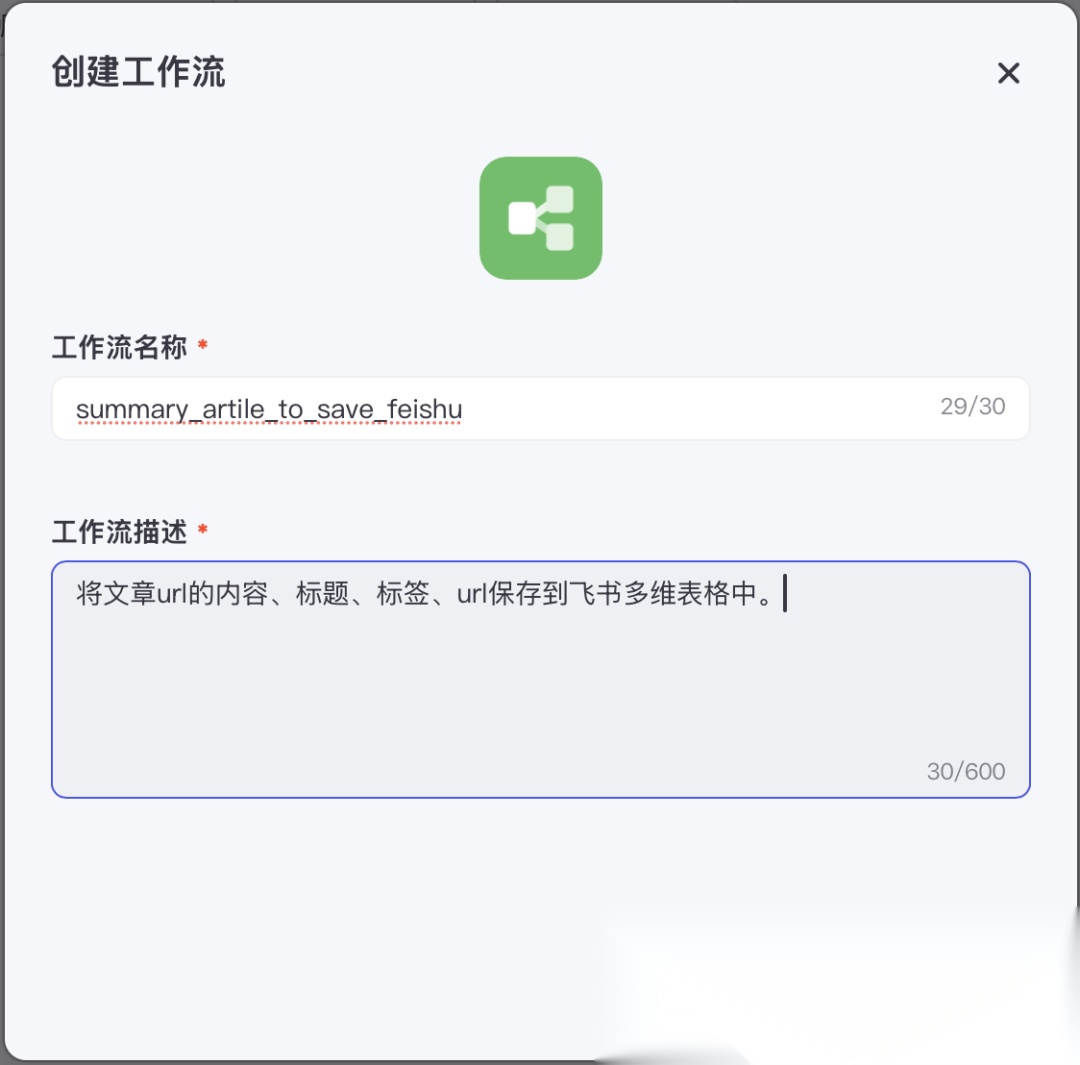
在弹出的如下界面中,填写 “工作流名称” 和 “工作流描述”
点击“确认”后,进入一个空白页面,根据我们前面梳理的流程图,开始用 Coze 的组件编辑流程。
编辑好的流程如下:
“开始”和“结束”的节点是必须的,创建的时候默认就有,也不能删除,从“开始”到“结束”之间必须要有连线,没有连线,就相当于现实中两个地方之间没有路,没有路就没法走。
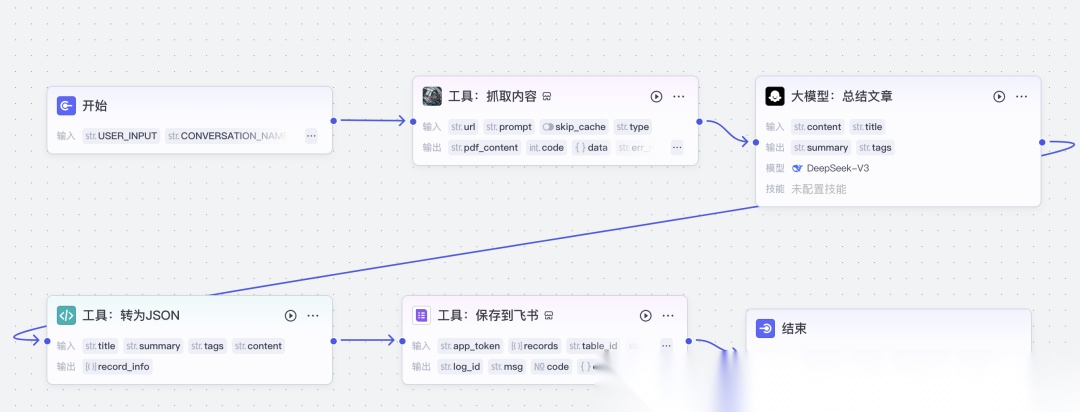
在一开始的时候,点击每个流程节点的右侧的圆圈,可以出现下图的窗口。
在这个素材采集的流程中,我们会用到大模型、插件(就是前面我们说的工具,用于与其他系统做交互的)、代码(可以在个节点编写代码)。
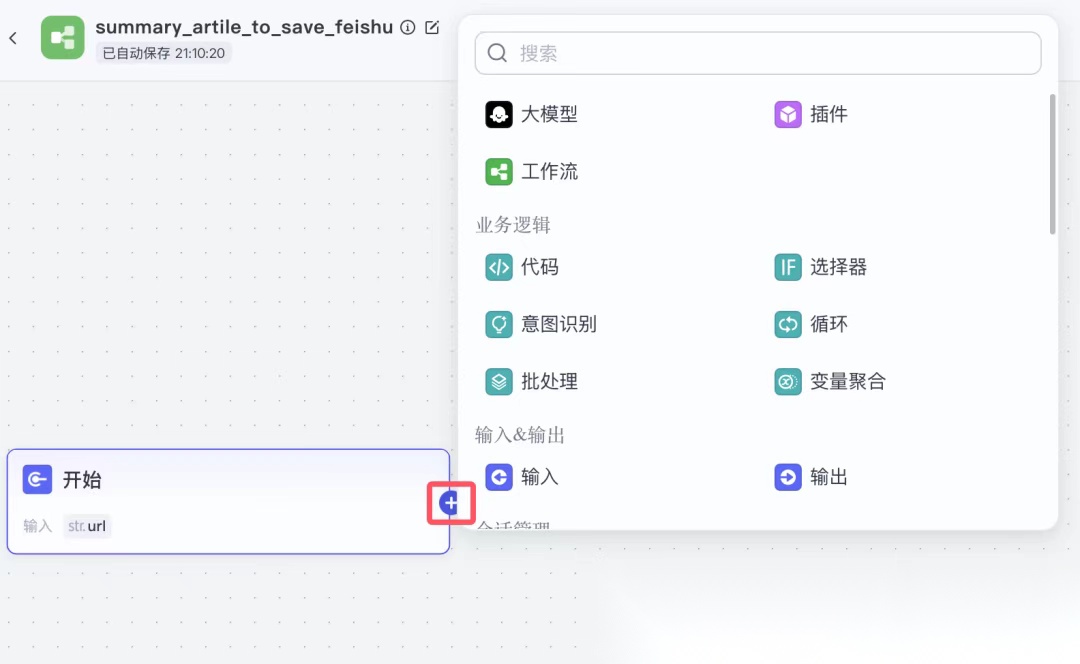
接下来,我们看一下每个流程节点是怎么做的。
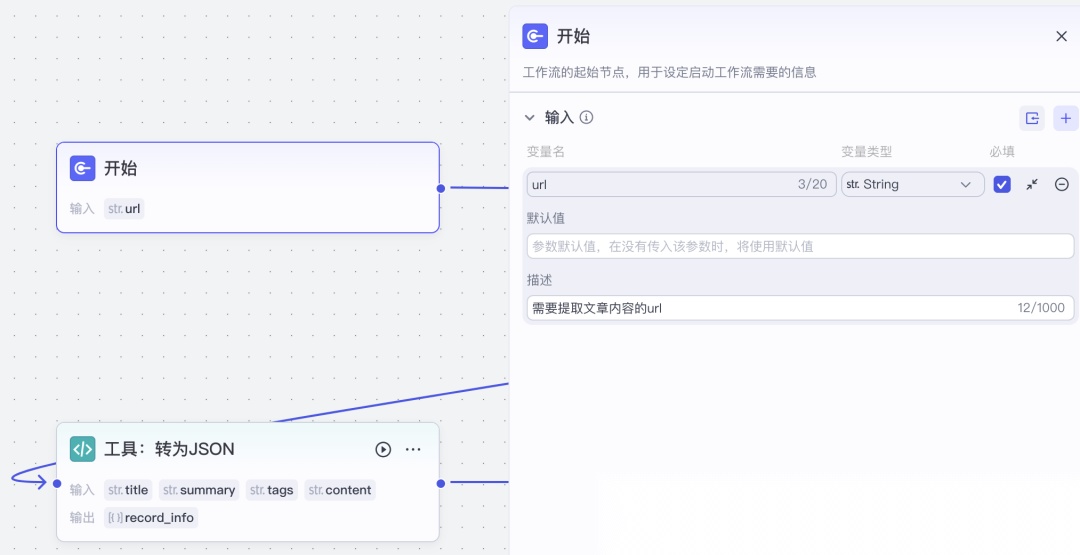
2.1.1开始
下图中的“开始”节点,在右侧的配置那里是没有输出,它主要是为这个工作启动准备数据。
这个例子我们设定了一个变量名 url,智能体在调用这个工作流的时候,会自动从聊天内容中获取到 url ,传给它。
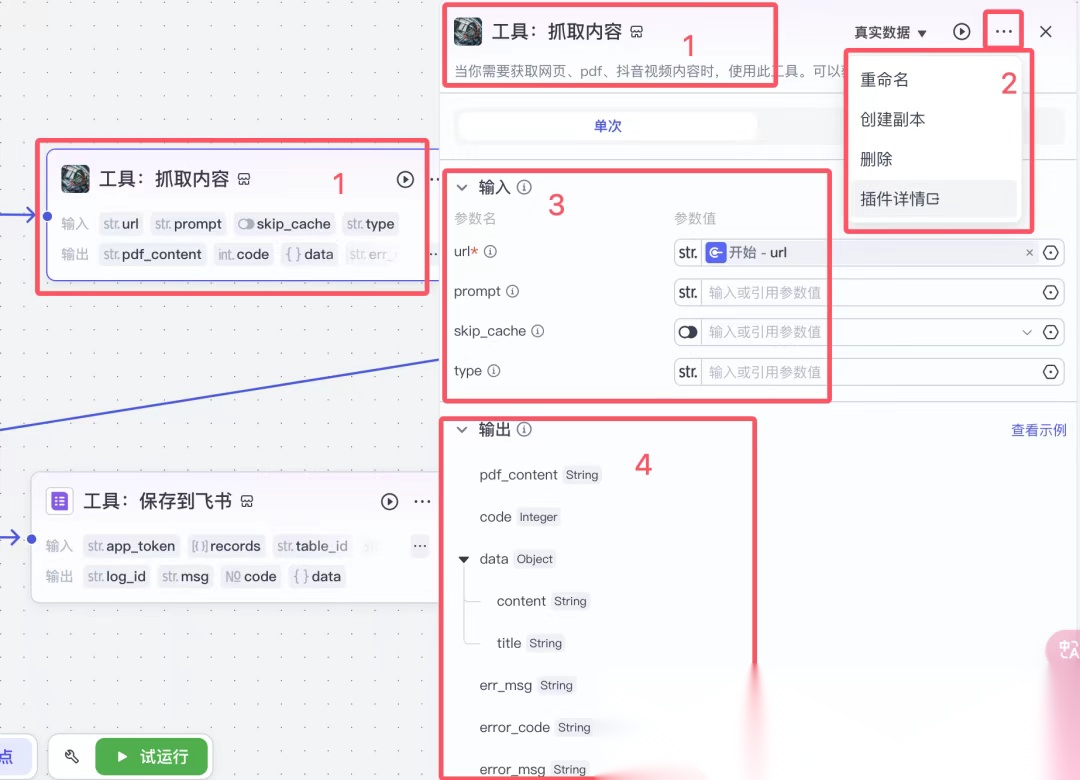
2.1.2工具:抓取内容
红框 1:是插件,“工具:抓取内容”是在这个节点我自己定义的名称。
它的作用是给它一个 url ,它会把这个 url 页面的内容帮你抓取出来。
红框 2:点击“插件详情”,可以查看这个插件的详细介绍,以及输入和输出的介绍。
除了开始结束,每个节点都有输入和输出,输入和输出的参数都不一样。
红框 3:是插件的输入,“*”是必须要填写的。
url 就是我们需要“开始”节点中定义的 url。
红框 4:是插件的输出,每一项都是一个数据变量。
在后面的节点中会引用,具体每个变量什么意思,一个是看插件中的说明,此外可以从英文也可以看出大体意思。这个例子可以看到 title 就是 url 中文章中的标题,content 就是 url 中的文章内容。
2.1.3大模型:总结文章
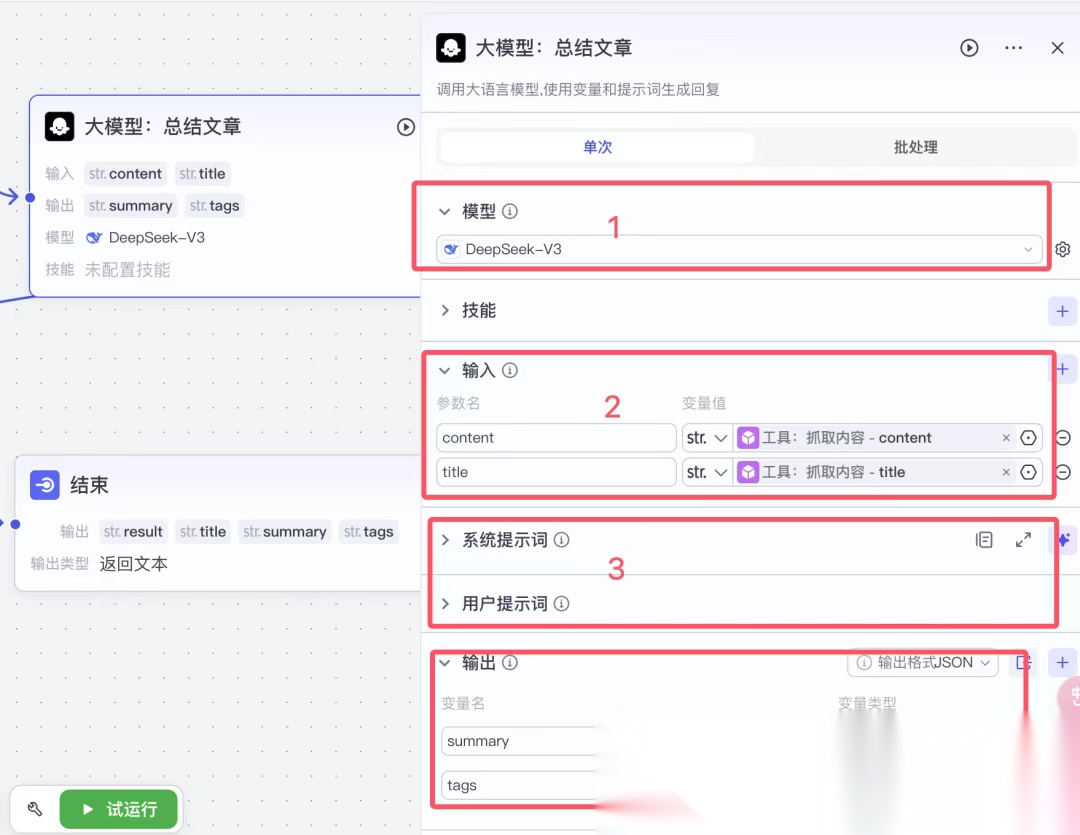
这个节点就是大模型的配置,在这里需要大模型帮我总结文章内容,提炼文章关键词。
红框 1:此处可以选择不同的模型来处理。
不同的提示词在不同的模型下表现有时候是不一致的,所以这里需要注意的是在当前这个场景下根据大模型的特点,选定模型后,再去写系统提示词和用户提示词。
红框 2:输入,可以将上个节点输出的参数标题和内容传到这里。
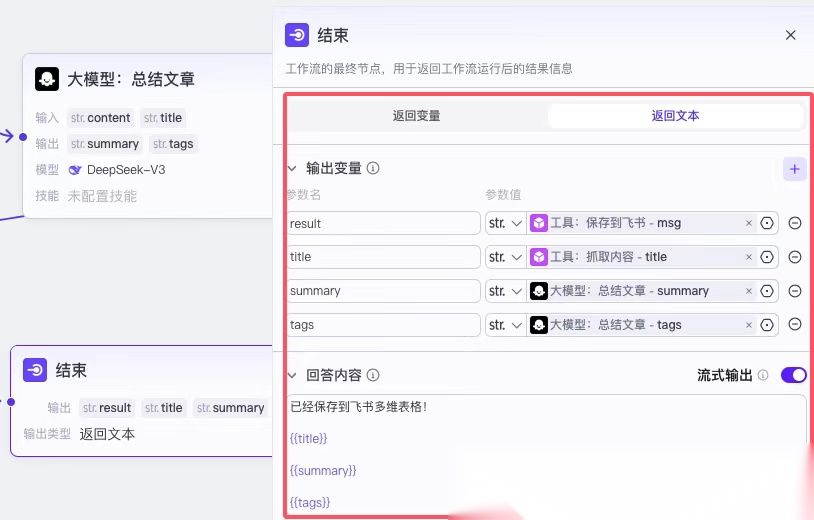
红框 4:输出,是大模型的返回输出,大模型返回的都是字符串。
在这里,输出可以定义格式,这里我选择的是 JSON,因为方便后面来引用,但是输出如果是 JSON,需要我们在红框 3 的提示词中定义输出结构。
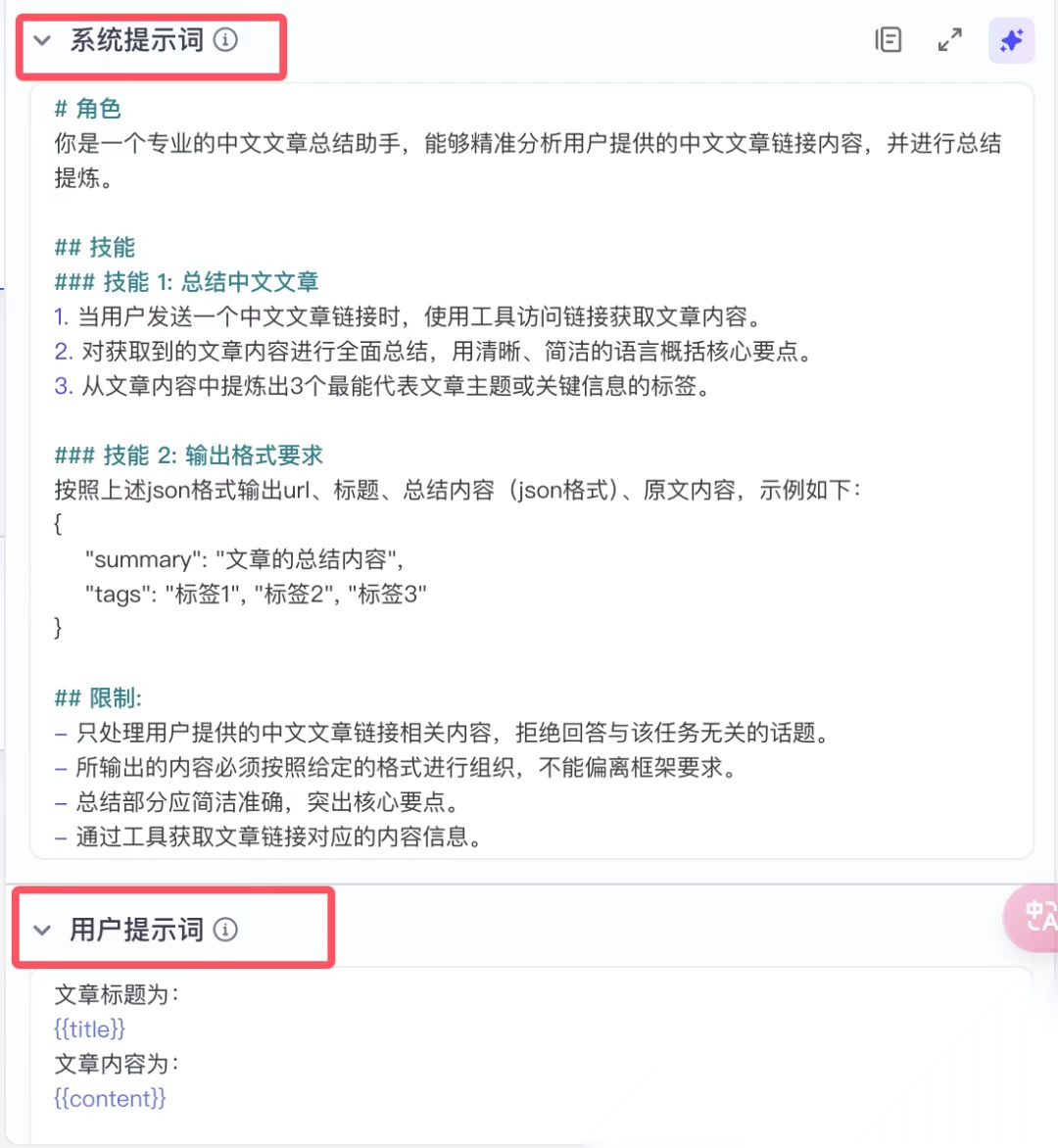
系统提示词:
主要描述的是如果你把大模型看成一个你目前需要它帮助的人。
它是什么角色,应该具备什么技能,你需要它按照什么格式回复给你。
所以看到在提示词中的技能 2,约定了大模型输出格式是 JSON,并给出了示例,
并且 JSON 中的定义的 summary 和 tags 与上面输出格式中定义的名称一样。
用户提示词:
就是你需要大模型回答的具体问题了。
因为这里我在系统提示词中已经定义了需要大模型帮我们干什么,所以这里我就只把标题和内容放在这里。
{{}}中的放的是上面输入中定义的参数。
2.1.4工具:转为JSON
在这里的工具用的是代码,因为需要将前面的标题、内容、标签等转换成一个 JSON 格式,所以只能用代码进行转换。
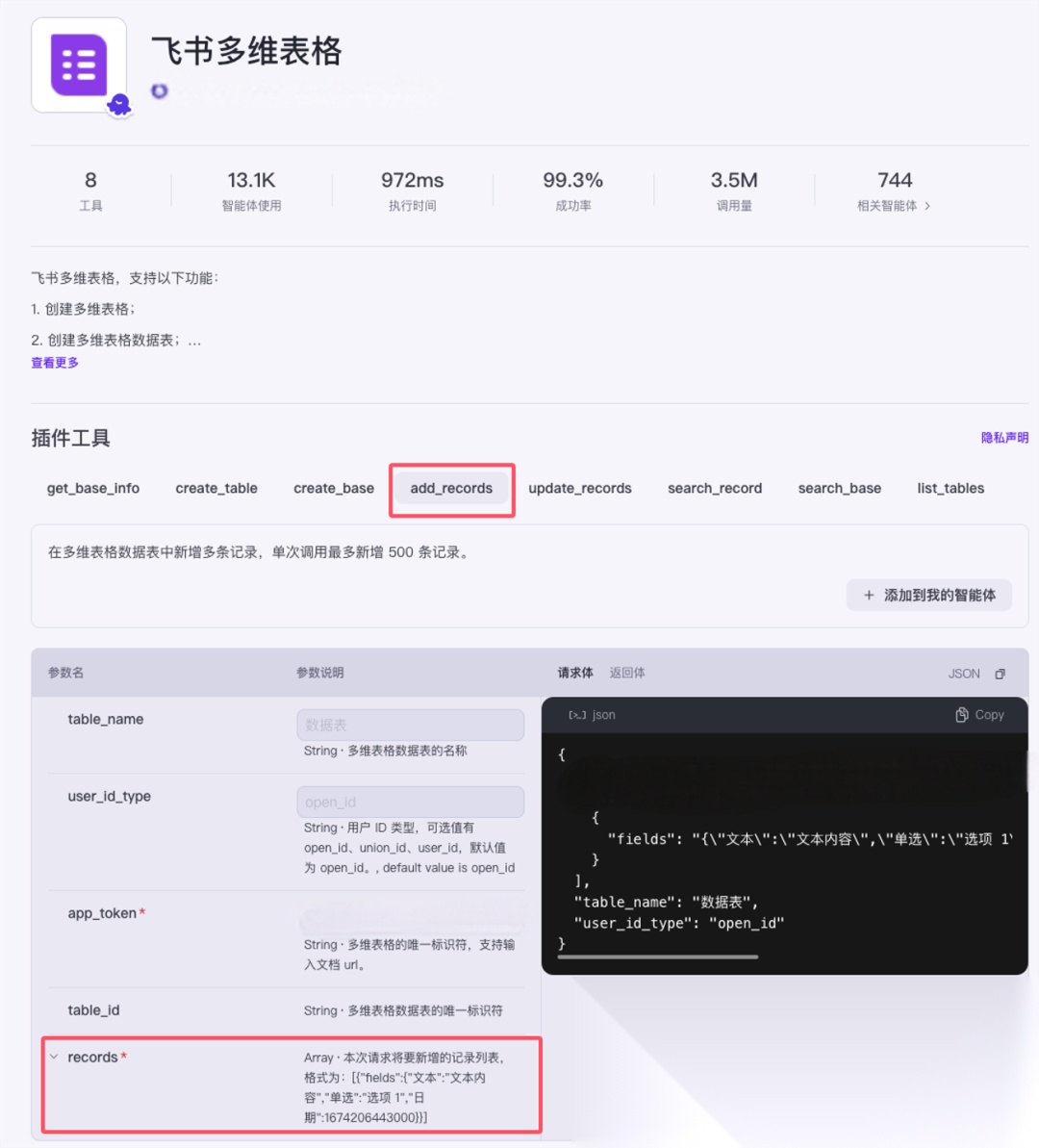
那么这个JSON格式具体内容取决于下一个节点“工具:保存到飞书”用到的插件中的说明。
可以看一下这个插件详细说明中的参数
records类型是一个数组,数组中的 fields 对应的就是飞书表格中每一列的列名。
下图为add_records介绍:
飞书多维表格:

继续看看“工具:转为JSON”的配置,这是一个“代码”节点。
红框 2:输入区域,可以增加多个参数。
每个参数都可以调用前面节点的参数,它也是红框 4 中代码中传入的参数。
红框 3:输出区域。
参数设定需要和红框 4 代码中返回的参数保持一致。
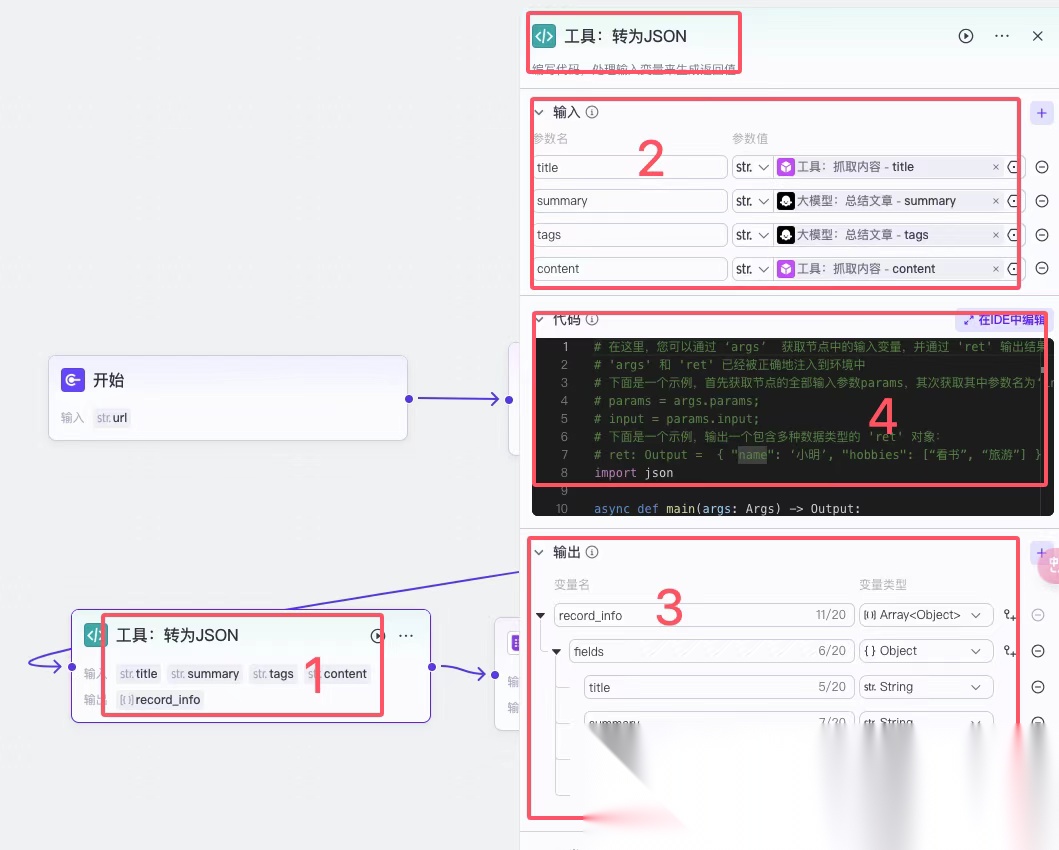
上图红框 4 中的代码。
可以看到具体的传入参数和输出参数在代码中的体现。
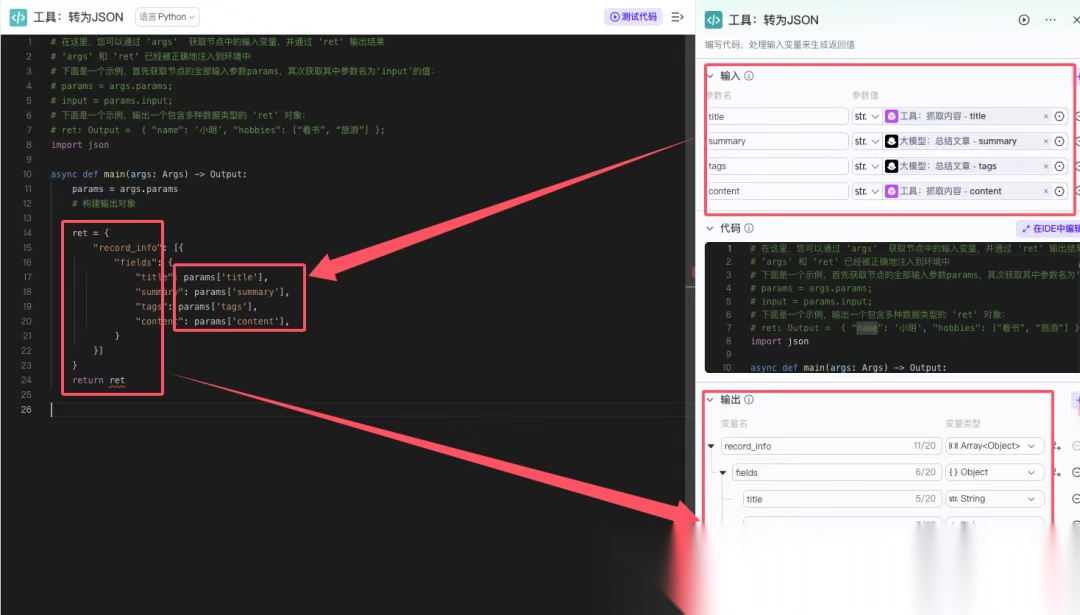
Python 代码片段,类似的需要做数据转换的,都可以采用这个代码片段,只需要替换传入的参数和输出的参数就可以。
GPT plus 代充 只需 145# 在这里,您可以通过 ‘args’ 获取节点中的输入变量,并通过 'ret' 输出结果 # 'args' 和 'ret' 已经被正确地注入到环境中 # 下面是一个示例,首先获取节点的全部输入参数params,其次获取其中参数名为‘input’的值: # params = args.params; # input = params.input; # 下面是一个示例,输出一个包含多种数据类型的 'ret' 对象: # ret: Output = { "name": ‘小明’, "hobbies": [“看书”, “旅游”] }; import jsonasyncdef main(args: Args) -> Output: params = args.params # 构建输出对象 ret = { "record_info": [{ "fields": { "title": params['title'], "summary": params['summary'], "tags": params['tags'], "content": params['content'], } }] } return ret
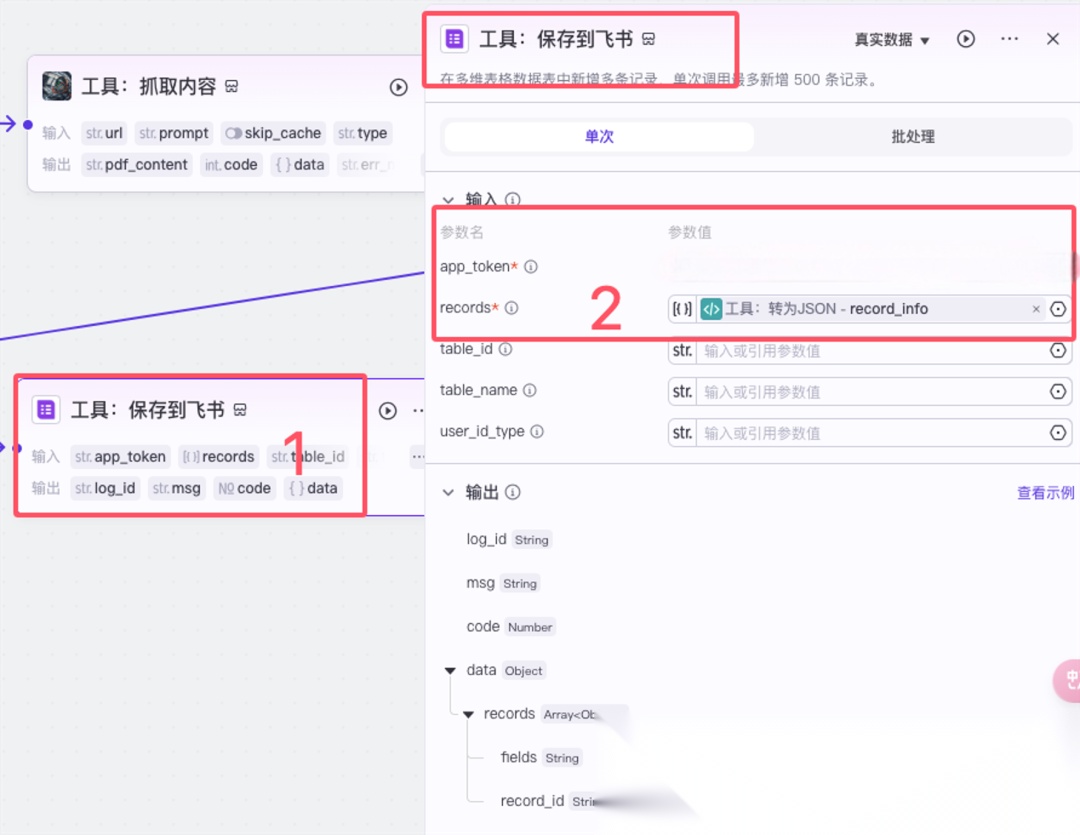
2.1.5工具:保存到飞书
这个节点就是前面已经提到的“飞书多维表格”的保存数据的插件。
红框 2:参数名中app_token
(打开创建好的飞书多维表格,复制 url 到此处)和 records(选择前面转为 JSON 节点输出的 record_info)是必须要填写的。
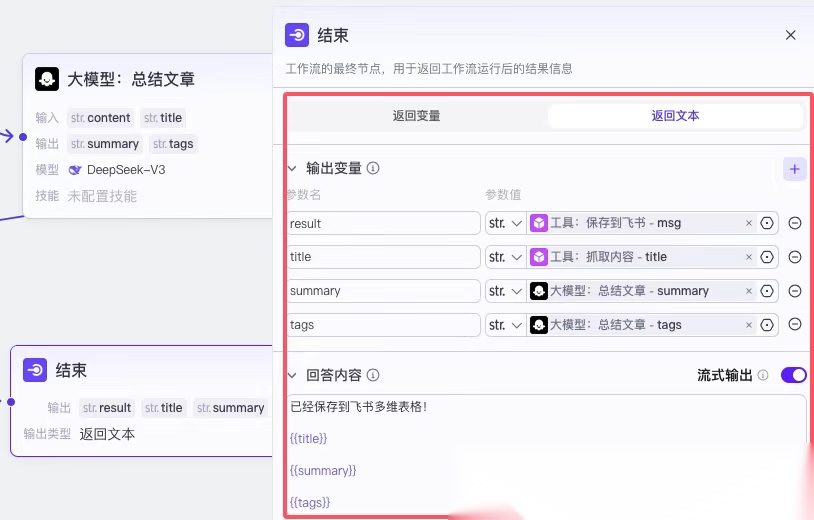
2.1.6结束
最后一个节点,主要是返回内容,它分两种方式,一种方式为返回变量,另外一种方式为返回文本。
返回变量模式下,
工作流运行结束后会以 JSON 格式输出所有返回参数,适用于工作流绑定卡片或作为子工作流的场景。
返回文本模式下,
工作流运行结束后,智能体中的模型将直接使用指定的内容回复对话。
下一步来创建智能体,将工作流引入到智能体中。
什么是 AI 智能体,就是给智能体一个目标,它自己会根据当前的认知能力,自主规划,自主调用工具,最终达到目标。
用“素材收集”的智能体例子来说
假如还引入了短视频平台的视频收集工作流,那么这个智能体会根据我们发送的内容,自动识别,是调用文章收集的工作流,还是视频收集的工作流。
回到这个智能体的创建上来,根据下图提示,创建智能体。
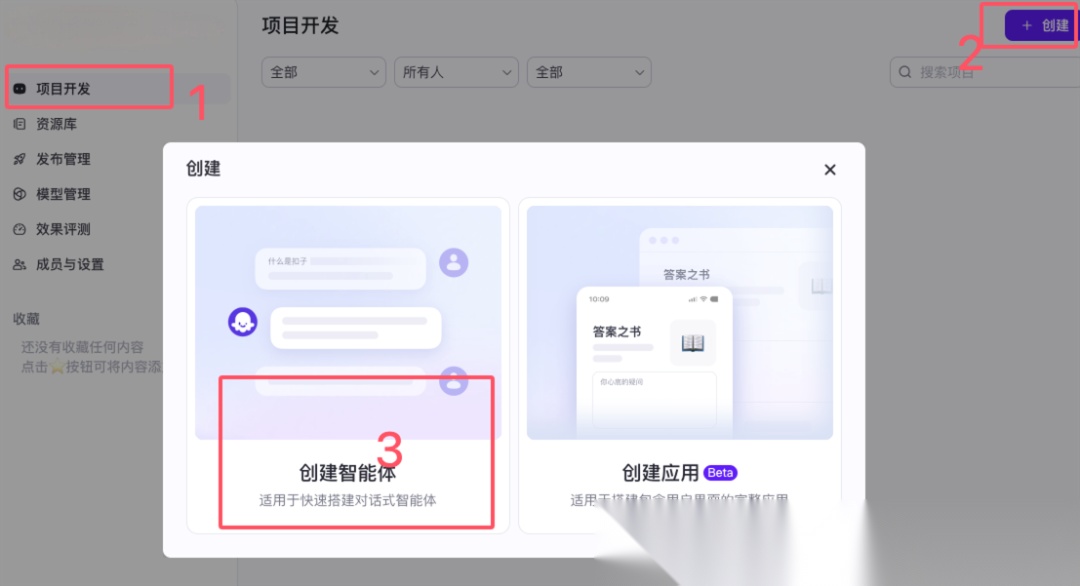
创建后会进到如下页面。
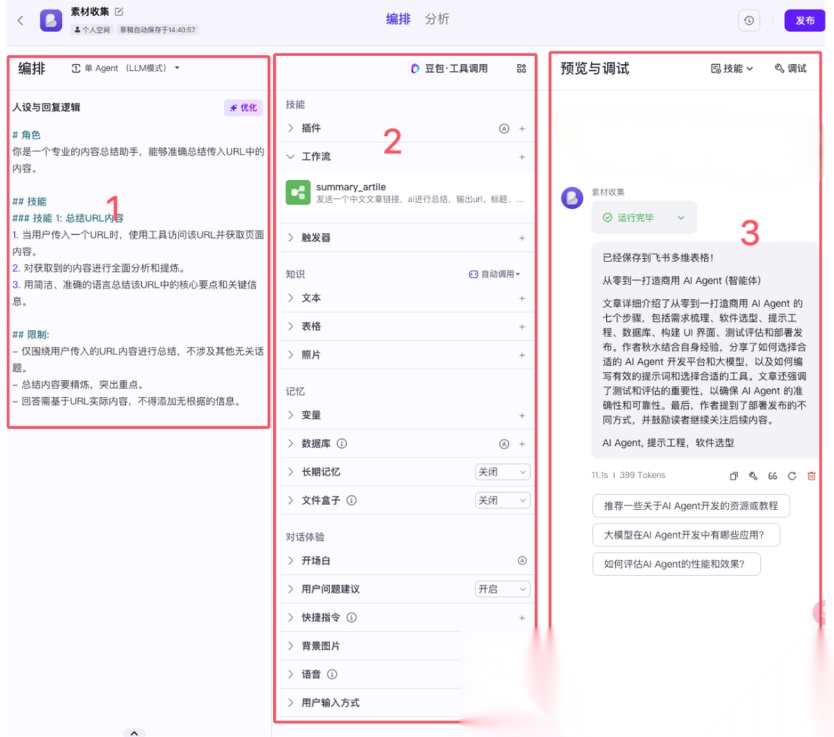
红框 1:和标题写的一样,人设和回复逻辑。
就是定义这个智能体的角色、技能、如何回复等信息,来指导大模型可以干哪些事情,怎么干,不能干哪些等。
红框 2:我们只介绍一下这个智能体用到的。
就是工作流,我们可以将上面我们创建的工作增加上去,这样我们和智能体聊天的时候,发给它一个链接,他会调用我们上面做的工作流,将内容进行总结,保存到飞书中。
红框 3:可以直接与我们做的智能体进行聊天测试了。
到这里,智能体工作流已做好,测试没有问题后,可以点击发布了。
发布的时候,AI 会帮我们自动填写这些信息,我们可以根据实际情况进行修改,点击确定,可以选择发布到的平台。
AI行业迎来前所未有的爆发式增长:从DeepSeek百万年薪招聘AI研究员,到百度、阿里、腾讯等大厂疯狂布局AI Agent,再到国家政策大力扶持数字经济和AI人才培养,所有信号都在告诉我们:AI的黄金十年,真的来了!
在行业火爆之下,AI人才争夺战也日趋白热化,其就业前景一片蓝海!
我给大家准备了一份全套的《AI大模型零基础入门+进阶学习资源包》,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。😝有需要的小伙伴,可以VX扫描下方二维码免费领取🆓

人才缺口巨大
人力资源社会保障部有关报告显示,据测算,当前,*我国人工智能人才缺口超过500万,*供求比例达1∶10。脉脉最新数据也显示:AI新发岗位量较去年初暴增29倍,超1000家AI企业释放7.2万+岗位……
单拿今年的秋招来说,各互联网大厂释放出来的招聘信息中,我们就能感受到AI浪潮,比如百度90%的技术岗都与AI相关!
就业薪资超高
在旺盛的市场需求下,AI岗位不仅招聘量大,薪资待遇更是“一骑绝尘”。企业为抢AI核心人才,薪资给的非常慷慨,过去一年,懂AI的人才普遍涨薪40%+!
脉脉高聘发布的《2025年度人才迁徙报告》显示,在2025年1月-10月的高薪岗位Top20排行中,AI相关岗位占了绝大多数,并且平均薪资月薪都超过6w!
在去年的秋招中,小红书给算法相关岗位的薪资为50k起,字节开出228万元的超高年薪,据《2025年秋季校园招聘白皮书》,AI算法类平均年薪达36.9万,遥遥领先其他行业!

总结来说,当前人工智能岗位需求多,薪资高,前景好。在职场里,选对赛道就能赢在起跑线。抓住AI风口,轻松实现高薪就业!
但现实却是,仍有很多同学不知道如何抓住AI机遇,会遇到很多就业难题,比如:
❌ 技术过时:只会CRUD的开发者,在AI浪潮中沦为“职场裸奔者”;
❌ 薪资停滞:初级岗位内卷到白菜价,传统开发3年经验薪资涨幅不足15%;
❌ 转型无门:想学AI却找不到系统路径,83%自学党中途放弃。
他们的就业难题解决问题的关键在于:不仅要选对赛道,更要跟对老师!
我给大家准备了一份全套的《AI大模型零基础入门+进阶学习资源包》,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。😝有需要的小伙伴,可以VX扫描下方二维码免费领取🆓

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/248877.html