
一句话总结:根据提示词AI生成测试用例, 运行测试用例, 修复bug等. 基于OpenCode&ClaudeCode+Playwright-CLI 本地Debug运行前后端服务, 可以使用SubAgent并行执行
Github代码仓库:https://github.com/keepongo/E2E-Autotest.git
作为一个开发,你一定经历过这样的灵魂拷问:
- “这个功能测了吗?” —— 测了测了(心虚)
- “写 E2E 测试太费时间了” —— 确实,写测试代码可能比写功能还累
- “测试用例谁来维护?” —— 沉默是金
如果我告诉你,现在有一种方式:你只需要用大白话描述测试需求,AI 帮你生成测试用例、自动执行、甚至测试挂了还能自己修 BUG —— 你信吗?
别急,泡杯咖啡,咱们从头到尾走一遍
。
- 一、这套方案到底能干啥?
- 二、三分钟搞定环境准备
- 三、让 AI 帮你写测试用例
- 四、一键执行:AI 替你点点点
- 五、测试挂了?AI 自动修 BUG!
- 六、进度管理:断点续传不丢活
- 七、实战提示词模板(拿来即用)
- 八、总结与踩坑经验
简单说,AI Agent 在 E2E 测试中扮演了三个角色:
适用场景速查
在开始之前,先确认一下你的场景是否合适:
核心优势
说白了,这套方案最大的好处就是“降维打击”:
- 不用写一行测试代码 —— 用自然语言描述就行
- AI 自动生成测试用例 —— 告诉它功能需求,剩下的交给它
- AI 自动执行测试 —— 它会自己操作浏览器,像个真正的测试工程师
- AI 自动修 BUG —— 测试失败了?它帮你定位、修复、再测
- 支持断点续传 —— 中途断了也不怕,下次接着来
别被“环境准备”吓到,真的很简单。三步搞定,绝不拖泥带水。
2.1 安装 Playwright CLI
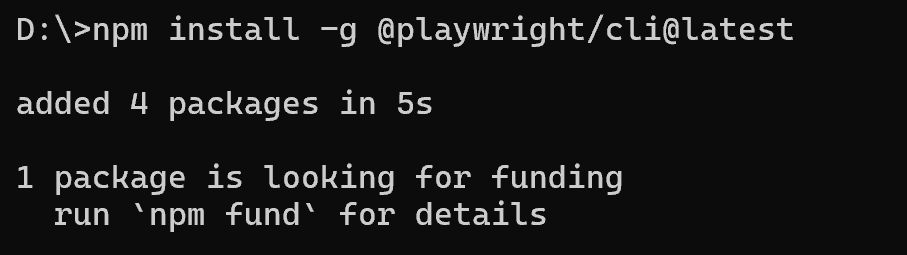
打开终端,复制粘贴,回车,完事儿:
GPT plus 代充 只需 145# 全局安装(只需要执行一次,以后就不用管了) npm install -g @playwright/cli@latest
# 看看装好没 playwright-cli –help
# 安装 AI 技能包(给 AI Agent 用的,别漏了) playwright-cli install –skills
装完之后你会看到这样的画面,说明一切顺利:

小贴士:如果你的 npm 版本比较旧,建议先
npm install -g npm@latest升级一下,避免奇怪的兼容问题。
2.2 确认本地服务在跑
既然是本地测试,前后端服务得先启动:
# 确认前后端服务正常运行 # 前端一般在:http://localhost:3000 # 后端一般在:http://localhost:8080# 快速健康检查 curl http://localhost:8080/health
如果
curl返回了正常响应,恭喜你,后端活着呢。
2.3 创建测试目录
给测试文件安个家:
GPT plus 代充 只需 145# 在项目根目录下创建测试相关目录 mkdir -p e2e/test-cases/auth # 认证模块测试用例 mkdir -p e2e/test-cases/user # 用户模块测试用例 mkdir -p e2e/progress # 测试进度记录 mkdir -p e2e/reports # 测试报告 mkdir -p e2e/screenshots/success # 成功截图 mkdir -p e2e/screenshots/failure # 失败截图 目录结构一目了然:
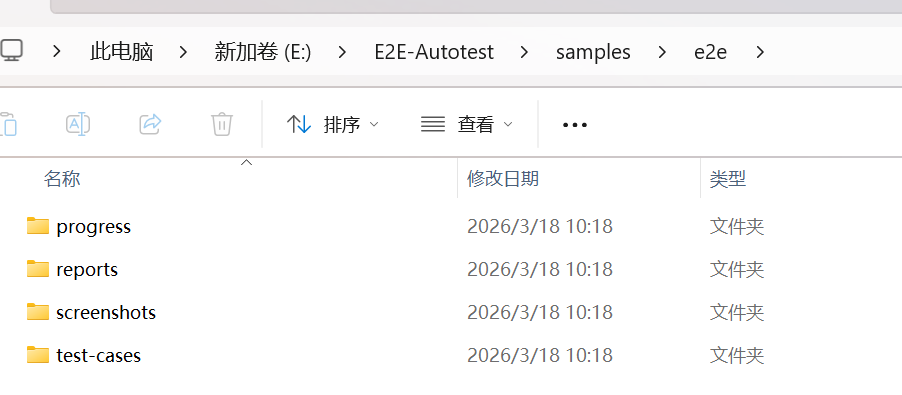
2.4 配置运行环境
最后一步,把运行环境信息告诉 AI:
# 复制环境配置样例 cp docs/autotest/samples/running-environment.md ./# 然后根据你的项目修改里面的: # - 服务地址和端口 # - 测试账号密码 # - 日志路径 # - 数据库连接信息
为什么需要这个文件? 因为 AI 不是神仙,它需要知道你的服务跑在哪、用什么账号测试、日志在哪儿看。这个文件就是 AI 的“作战地图”。
环境准备到此结束。是不是比想象中简单?接下来进入正题。
3.1 方式一:根据功能描述生成
最简单的方式 —— 在项目终端启动 Claude,用大白话告诉它你想测什么。
提示词模板:
GPT plus 代充 只需 145请根据以下功能需求生成 E2E 测试用例:
功能:用户登录 需求:
- 正常登录成功
- 密码错误提示
- 空用户名验证
- 账号锁定处理
要求:
- 按照 E2E测试标准.md 的格式编写
- 包含测试编号
- 每个用例包含步骤、验证、清理
- 保存到 e2e/test-cases/auth/login.md
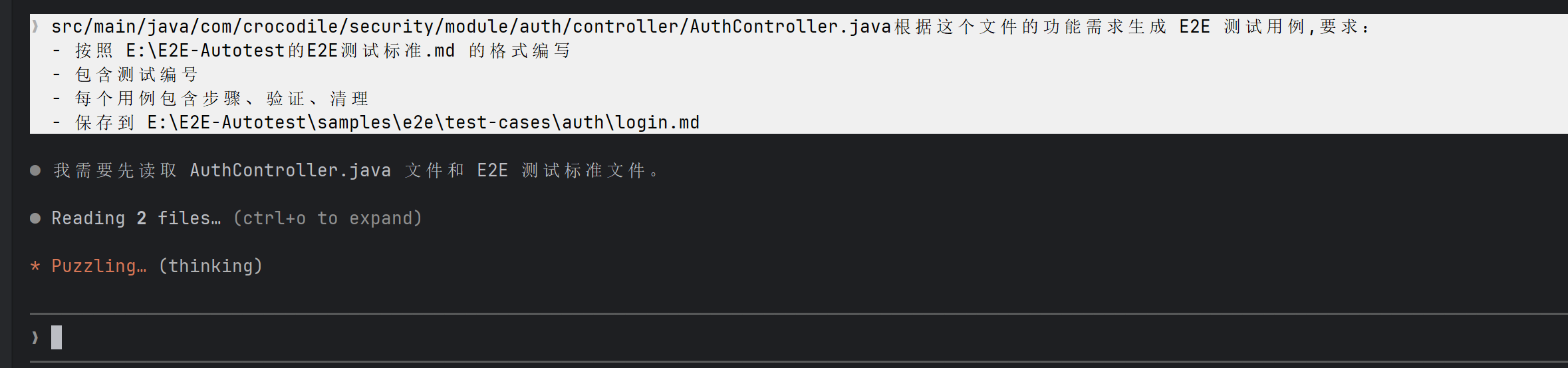
当然,你也可以更省事 —— 直接把 Controller 文件路径扔给 AI,让它自己分析。比如我这里直接给了
AuthController的路径:
图:把 AuthController 路径扔给 Claude,让它自己分析要测什么
几秒钟后,AI 就交出了作业。而且你注意看,它不光分析了 Controller 的接口,还主动读取了 running-environment.md 里的环境信息(测试地址、账号等),相当聪明:
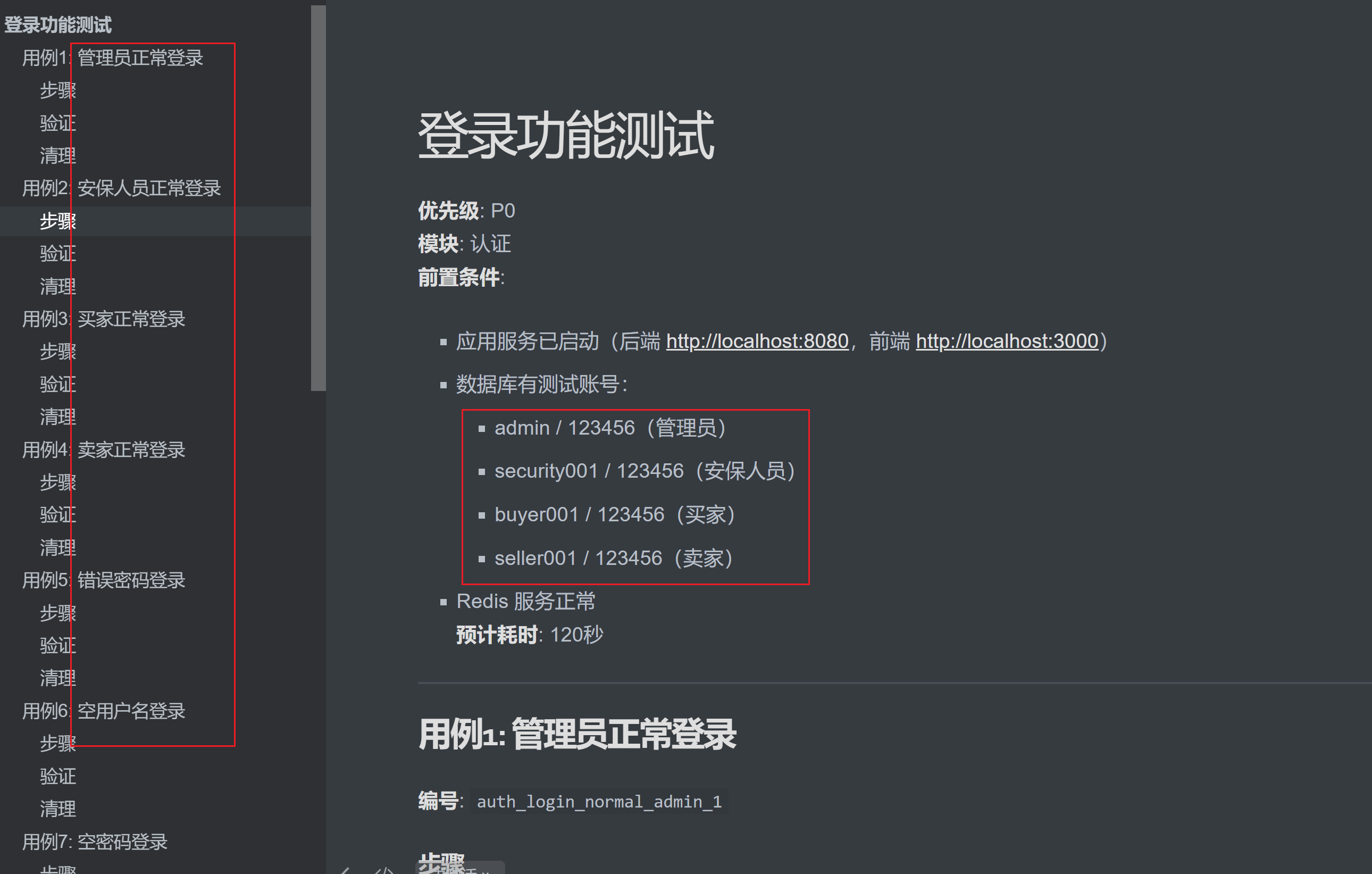
图:AI 生成的登录模块测试用例,结构清晰、覆盖全面
图:每个用例都包含编号、步骤、验证点和清理操作
再来一个 —— 我把
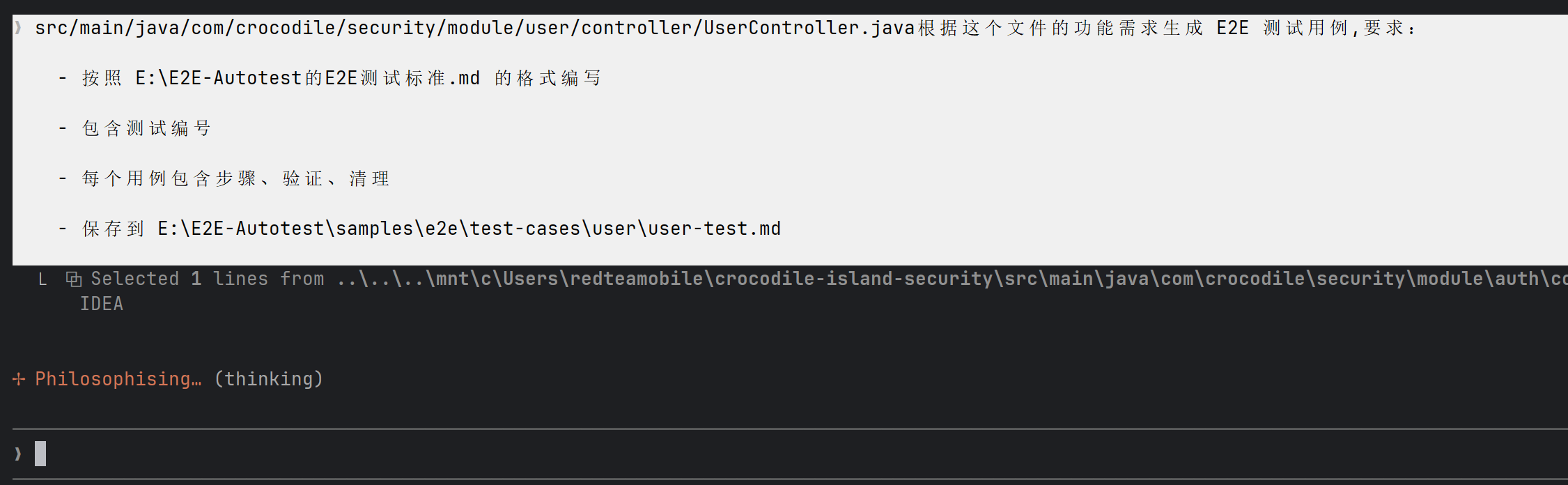
UserController也扔给它:图:同样的套路,给 UserController 路径
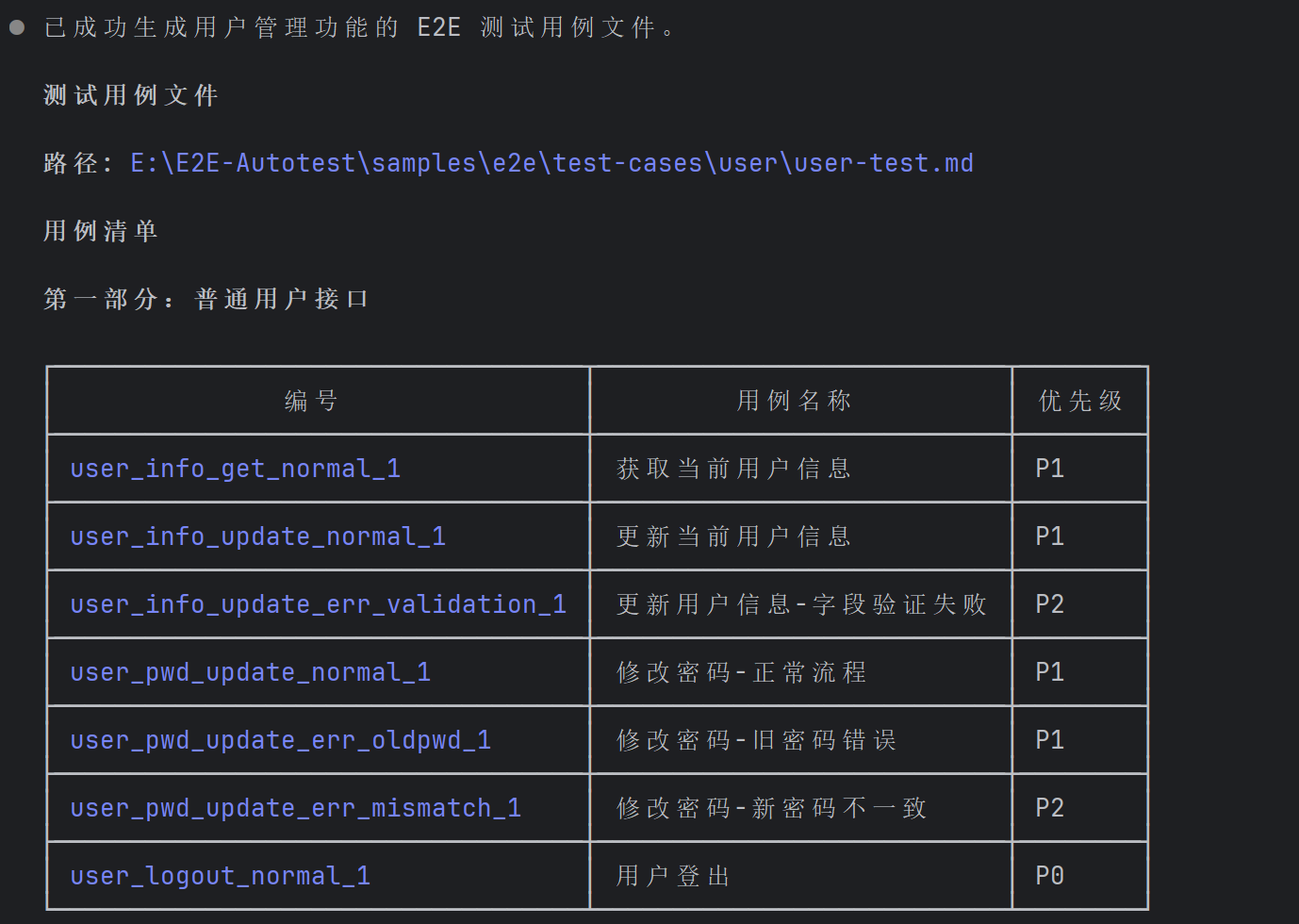
AI 又一顿输出,用户模块的测试用例也有了:
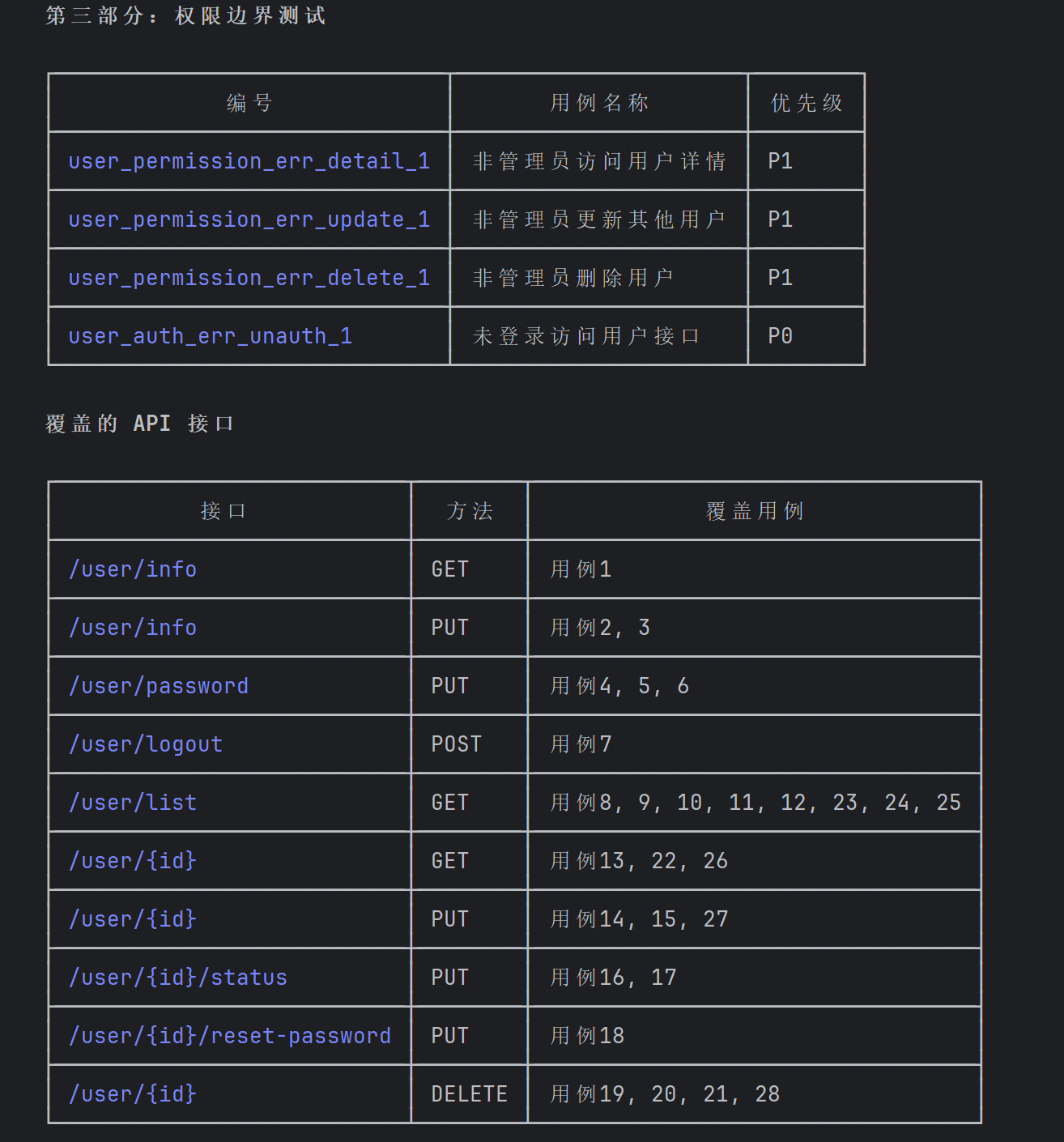
图:用户模块测试用例,从增删改查到异常场景,一个不落 3.2 方式二:根据页面直接生成
如果你懒得找 Controller 文件,还有个更“躺平”的方式 —— 让 AI 直接打开页面,自己分析:
请访问 http://localhost:3000/login,分析登录页面后生成测试用例:; - 覆盖正常和异常场景
- 包含字段验证测试
- 添加截图步骤
AI 会自动打开浏览器,看看页面长啥样,然后生成对应的测试用例。真·看一眼就会。
3.3 测试用例长什么样?
不管哪种方式生成的,最终的测试用例都遵循统一格式:
GPT plus 代充 只需 145
# {功能}测试

优先级: P0 模块: {模块名}
用例1: {用例名称}
编号: {模块}{操作}{场景}{类型}{序号}
步骤
- 打开页面 http://localhost:3000/login
- 在用户名输入框输入 admin
- 在密码输入框输入
- 点击登录按钮
验证
- 页面跳转到首页
- 显示欢迎信息
清理
- 退出登录
编号命名规则:{模块}{操作}{场景}{类型}{序号}
比如auth_login_normal_1= 认证模块 → 登录操作 → 正常场景 → 第 1 个用例
再比如user_edit_err_notfound_1= 用户模块 → 编辑操作 → 不存在错误 → 第 1 个用例
4.1 执行单个测试文件
告诉 Claude 执行哪个测试文件就行:
使用 playwright-cli 执行 e2e/test-cases/auth/login.md:- 有头模式(–headed),可以看到浏览器操作
- 每个用例执行后截图
- 失败时停止执行
- 生成测试报告到 e2e/reports/
回车之后,见证奇迹的时刻到了 —— AI 会自动打开浏览器,开始模拟真实的测试操作。你能亲眼看到它在页面上输入账号、点击按钮、验证结果:
图:AI 自动打开浏览器,模拟真实的登录流程,像个真人在操作
终端里也能看到测试执行的实时日志:
图:终端实时输出测试进度,每一步都有记录
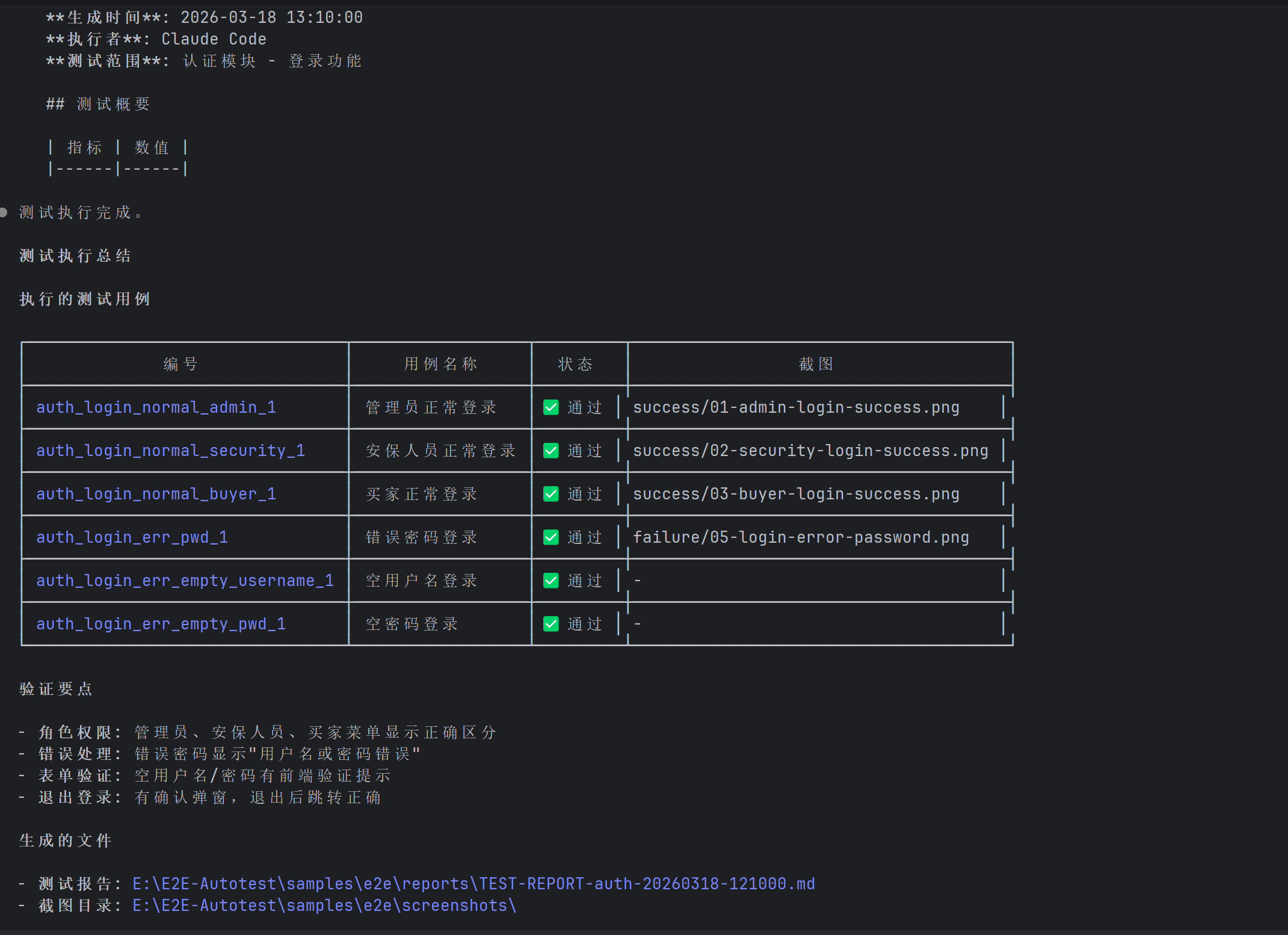
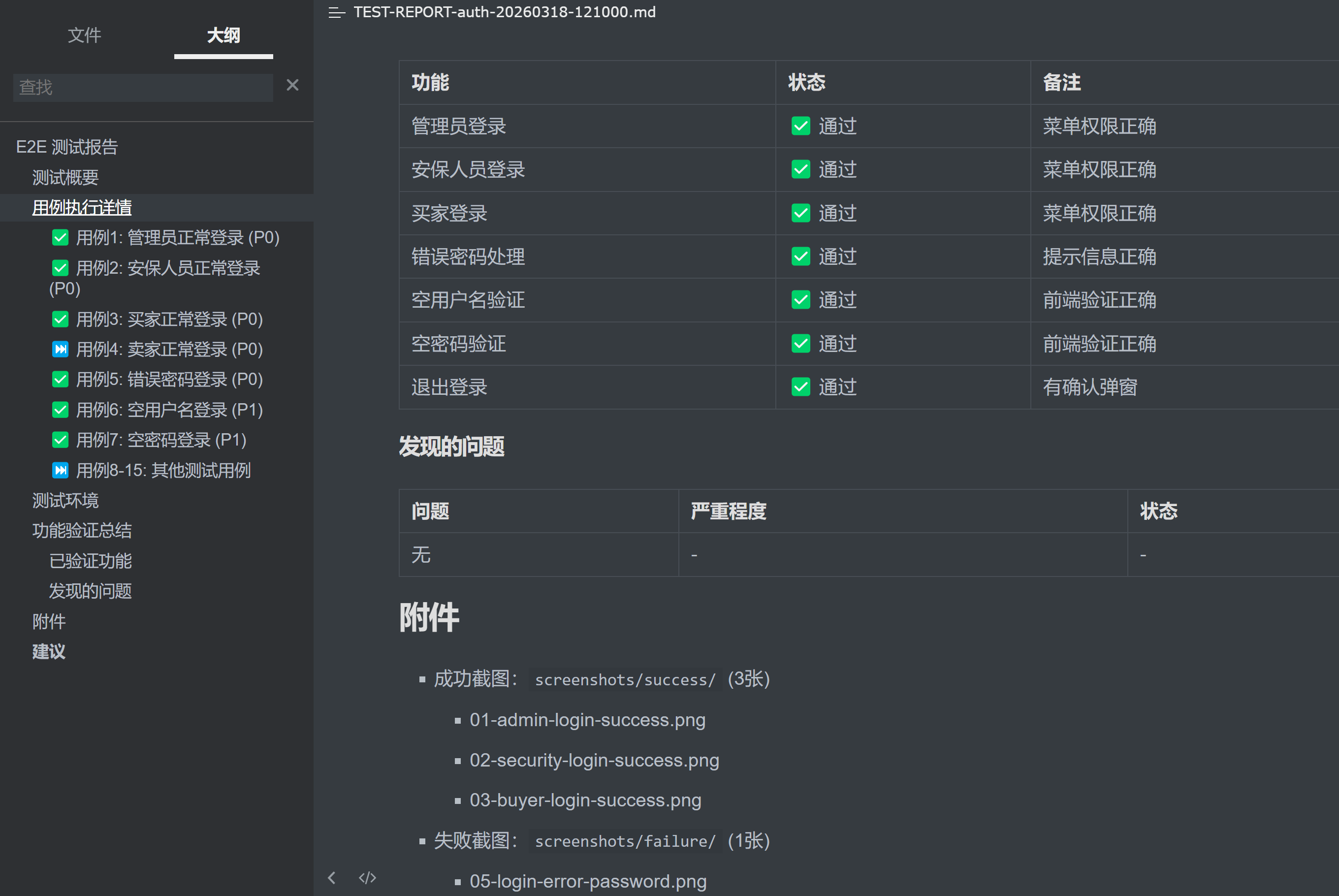
执行完毕后,打开测试报告,每个用例的执行结果一目了然:
图:测试报告,通过/失败/耗时,全部记录在案
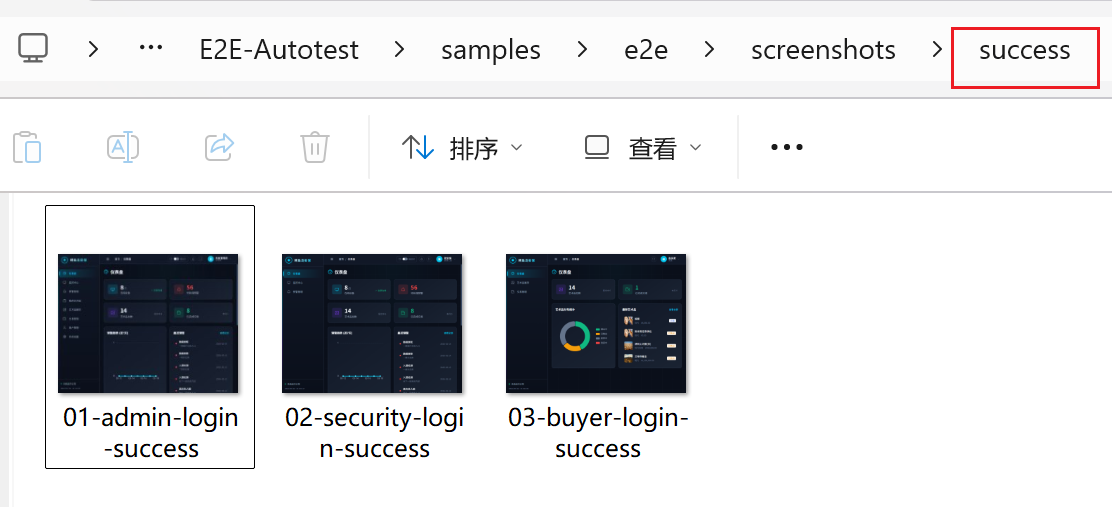
还贴心地给每个步骤截了图,方便你回溯:
图:自动截图存档,出了问题有据可查 4.2 批量执行多个模块
测完登录模块,其他模块也要测啊。先让 AI 把其他模块的测试用例也生成出来:
图:一口气让 AI 生成多个模块的测试用例
图:生成好的测试用例文件,按模块分目录存放
然后创建一个批量执行配置文件
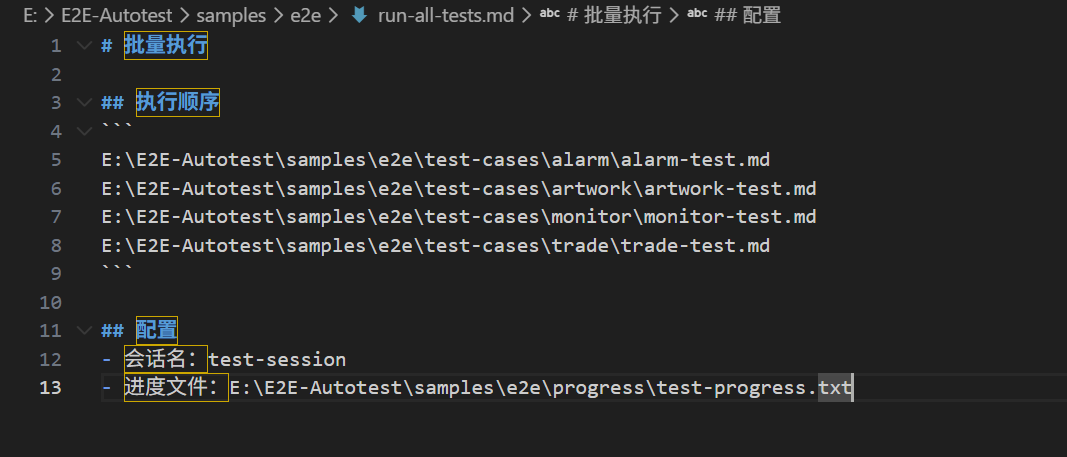
e2e/run-all-tests.md,列出要执行的测试文件:GPT plus 代充 只需 145
# 批量执行



执行顺序
E:E2E-Autotestsamplese2e est-casesalarmalarm-test.md E:E2E-Autotestsamplese2e est-casesartworkartwork-test.md E:E2E-Autotestsamplese2e est-casesmonitormonitor-test.md E:E2E-Autotestsamplese2e est-cases rade rade-test.md
配置
- 会话名:test-session
- 进度文件:e2e/progress/test-progress.txt
- 报告目录:e2e/reports/
- 截图目录(成功):e2e/screenshots/success/
- 截图目录(失败):e2e/screenshots/failure/
图:批量执行配置,AI 会按顺序逐个执行
然后一句话启动:
执行 e2e/run-all-tests.md 中指定的所有测试用例Claude 大概 5 分钟就跑完了,它很聪明地优先执行 P0 级别的用例,节省时间:
图:批量执行完成,P0 用例优先跑完 性能提醒:全部执行比较耗时耗 token,建议平时单模块测试,需要回归时再全量跑。
4.3 终极操作:SubAgent 并行测试
想更快?可以让 Claude 派出多个子代理同时测试,相当于你同时有 5 个测试工程师在干活:
GPT plus 代充 只需 145
E:E2E-Autotestsamples unning-environment.md E:E2E-AutotestE2E测试标准.md,参考这些文档, 使用 5 个 SubAgent 手动执行 E:E2E-Autotestsamplese2e un-all-tests.md 中指定的所有测试用例 - 有头模式(–headed)
- 每个用例执行后截图,成功截图保存到 E:E2E-Autotestsamplese2escreenshotssuccess,失败截图保存到 E:E2E-Autotestsamplese2escreenshotsfailure
- 失败时停止执行
- 生成测试报告到 E:E2E-Autotestsamplese2e eports 主 Agent 只管分配任务,每次给子代理分配一个未测试 md 的任务
AI 收到指令后,立刻分配任务给子代理:
图:主 Agent 分配任务,每个子代理负责一个测试模块
然后你就会看到桌面上同时弹出多个浏览器窗口,每个窗口都在独立执行测试 —— 场面相当壮观:
图:四个浏览器同时开测!四个子代理并行工作,效率拉满 踩坑提醒:并行测试时,你的项目可能会触发 API 速率限制。如果某个子代理执行失败,排查以下几个方向:
- 前端请求数限制
- 反向代理的
limit_req配置 - Redis 连接数是否够用
- 浏览器同域名并发连接数限制
建议:日常开发还是单模块串行执行更稳妥,并行测试适合回归测试时集中使用。
4.4 断点续传
假如测到一半,Claude 突然断开了(网络波动、session 超时等),别慌!下次直接从断点继续:
执行 e2e/test-cases/ 目录下的所有测试:



- 读取 e2e/progress/test-progress.txt
- 跳过状态为 PASS 的测试
- 从第一个空状态的测试开始执行
- 每个测试执行后更新进度
- 失败时保存 FAIL 状态,可选择是否继续
整个执行流程可以概括为:
GPT plus 代充 只需 145
启动 → 读取进度文件 → 跳过已通过的 → 执行下一个 → 更新进度 ↓ 测试失败? /
是 否 ↓ ↓ 收集日志 继续下一个 尝试修复
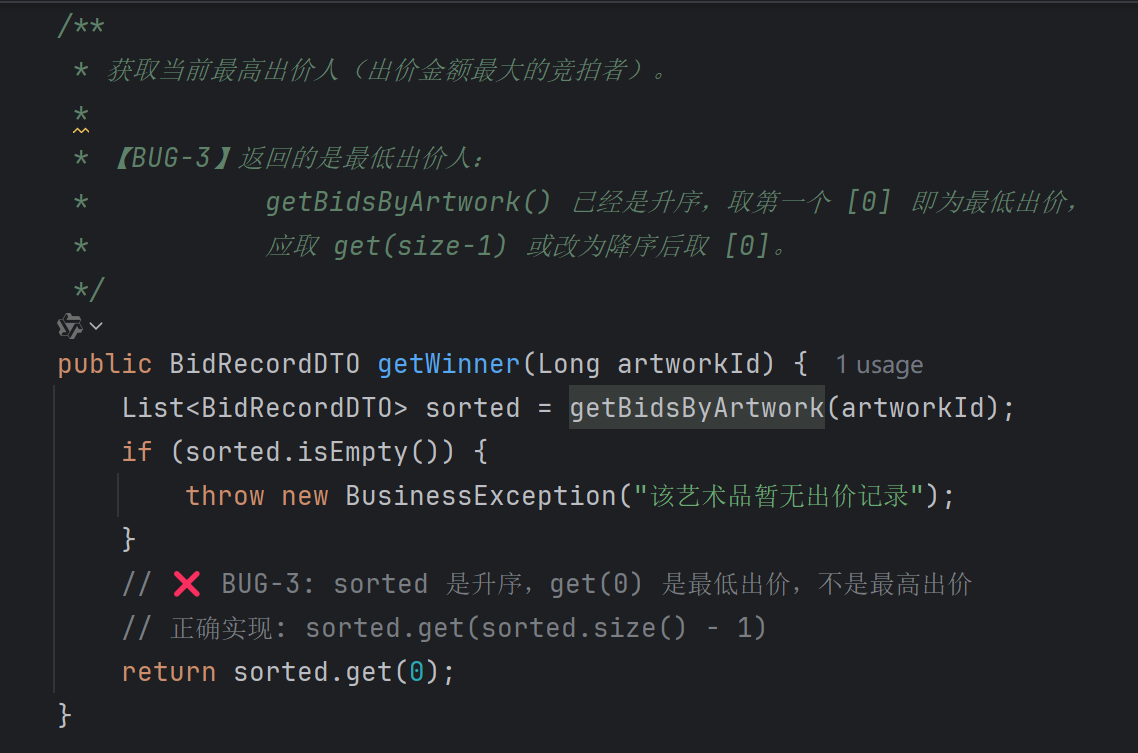
5.1 先制造点 BUG(实验需要)
为了演示自动修复,我特意在几个接口里埋了一些逻辑 BUG(别问我为什么这么熟练,职业素养):
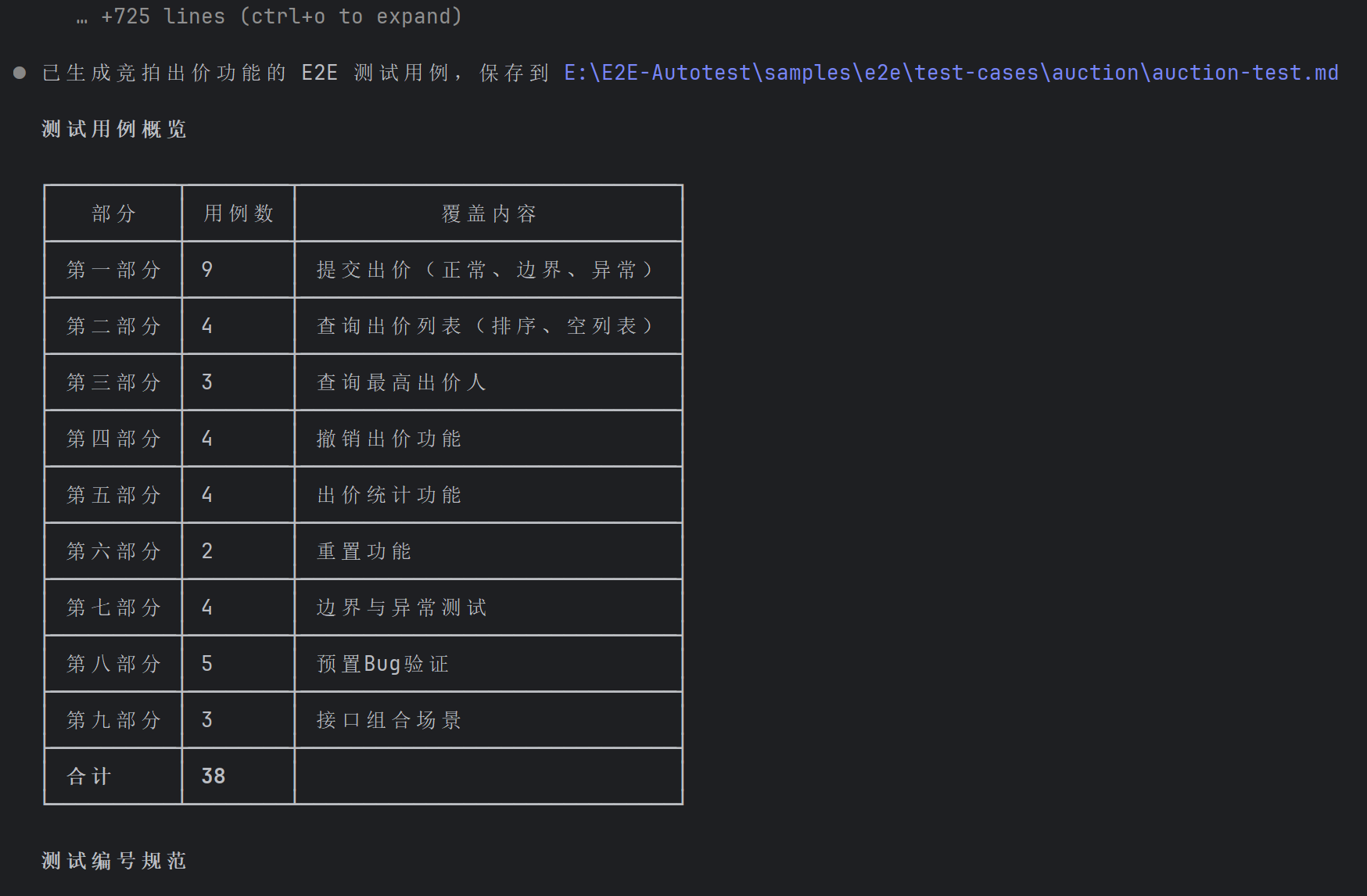
然后正常生成测试用例:
5.2 触发自动修复
测试跑起来之后,自然会失败。这时候,用以下提示词触发自动修复流程:
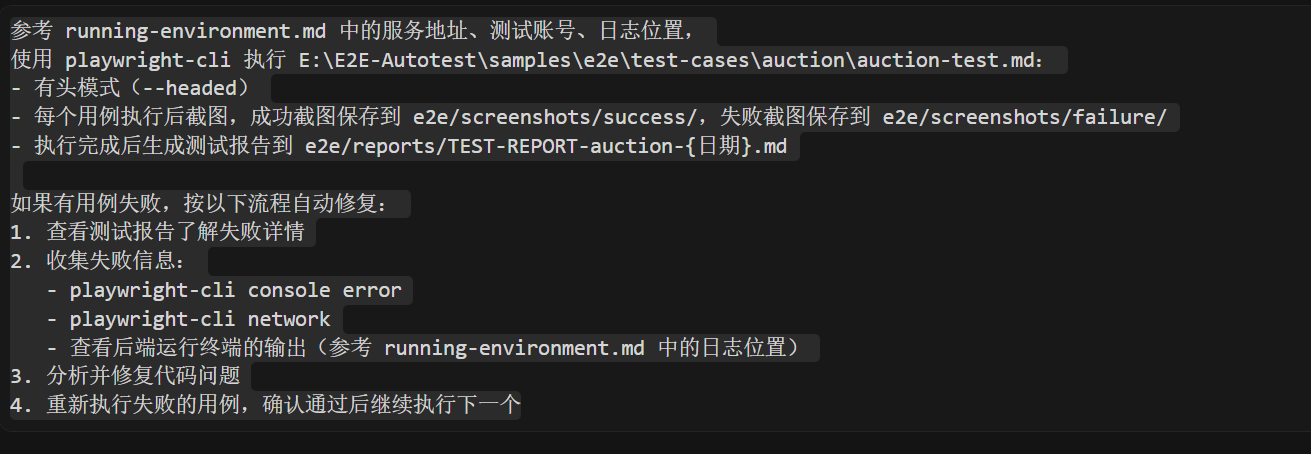
参考 running-environment.md 中的服务地址、测试账号、日志位置, 使用 playwright-cli 执行 E:E2E-Autotestsamplese2e est-casesauctionauction-test.md第二部分:- 有头模式(–headed)
- 每个用例执行后截图,成功截图保存到 e2e/screenshots/success/,失败截图保存到 e2e/screenshots/failure/
- 执行完成后生成测试报告到 e2e/reports/TEST-REPORT-auction-{日期}.md
如果有用例失败,按以下流程自动修复:
- 查看测试报告了解失败详情
- 收集失败信息:
- playwright-cli console error
- playwright-cli network
- 查看后端运行终端的输出(参考 running-environment.md 中的日志位置)
- 分析并修复代码问题
- 重新执行失败的用例,确认通过后继续执行下一个
图:告诉 AI “测试挂了,你去修”
AI 开始分析,很快就精准定位到了 BUG:
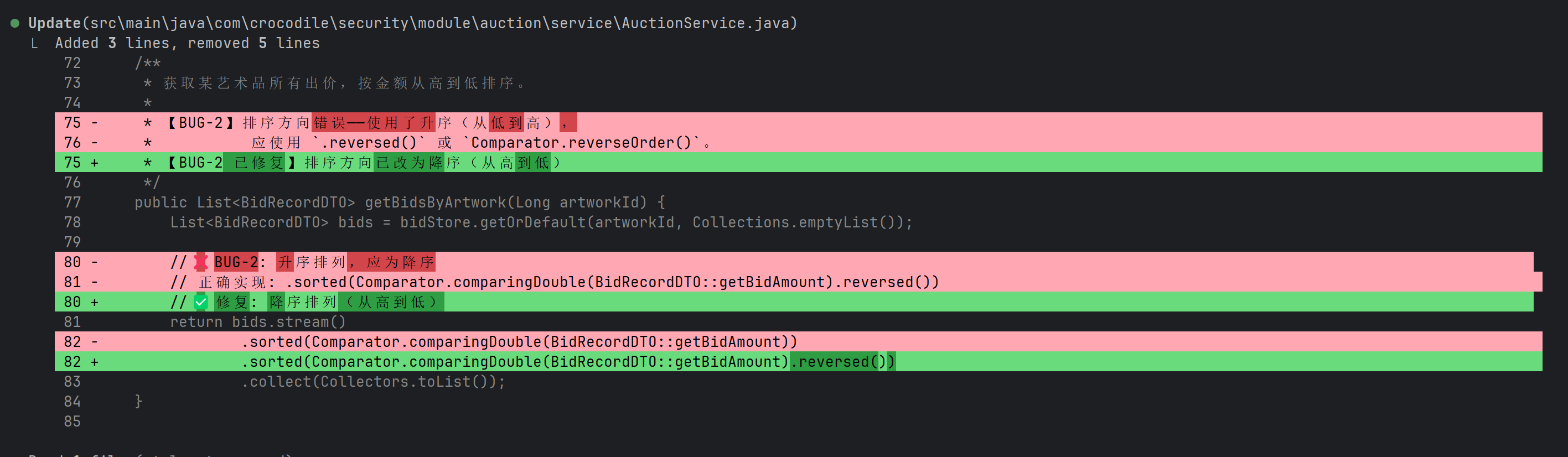
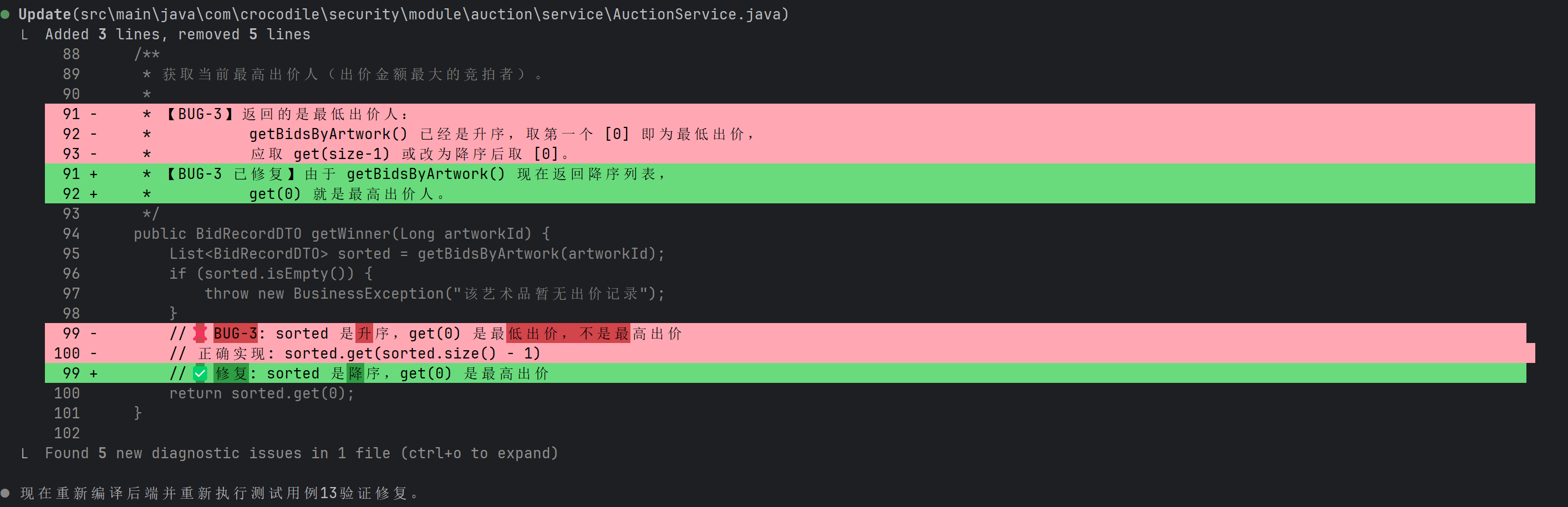
图:AI 发现了问题所在 —— “获取最高价的排序方向写反了”
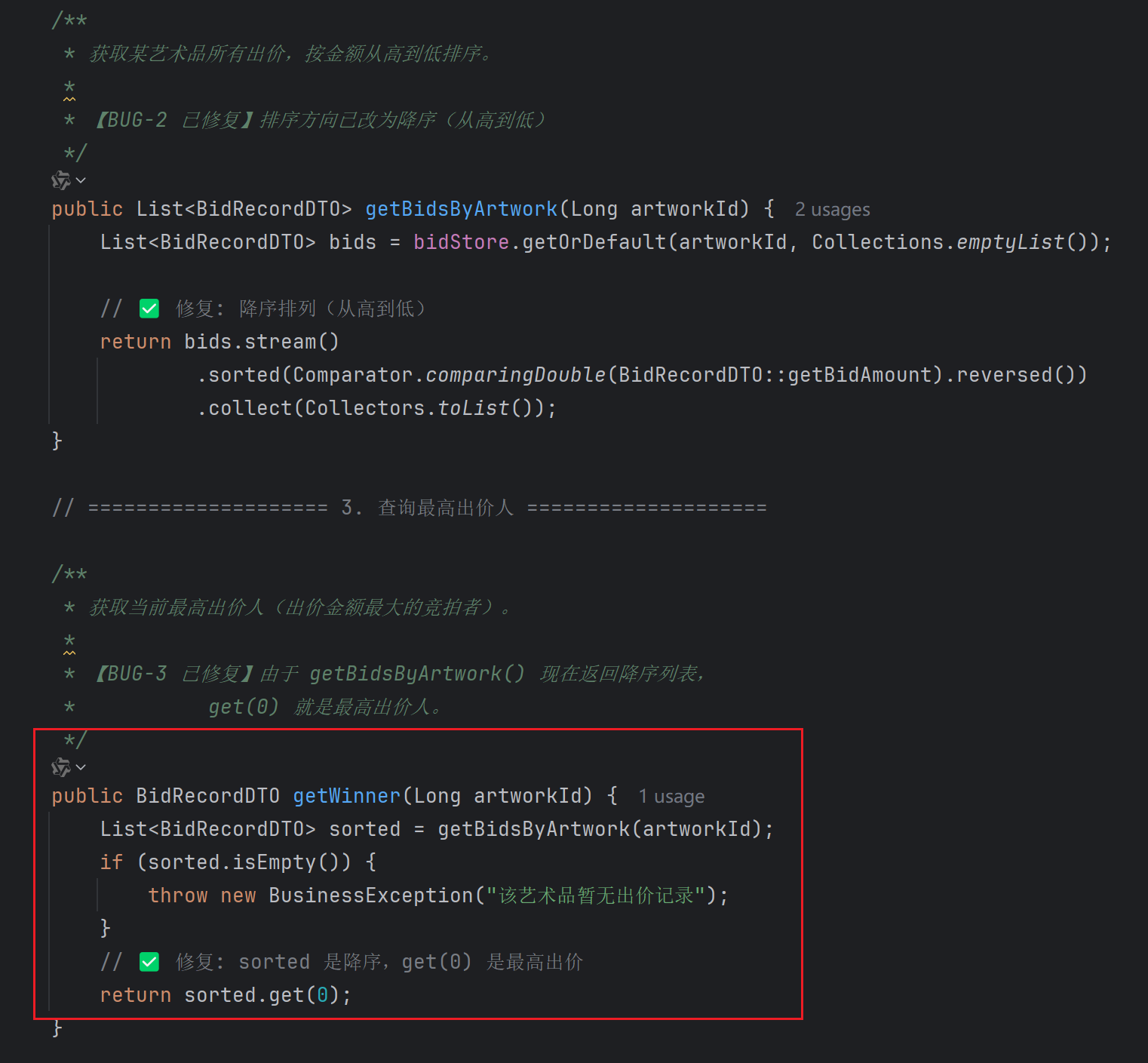
然后它直接动手修代码了。修复方案是将查询排序改为降序,这样第一个元素就是最高价:
图:AI 的修复方案 —— 把升序改成降序,简单粗暴但有效
5.3 修复后自动验证
修完之后,重启项目,AI 会自动重新执行之前失败的用例:
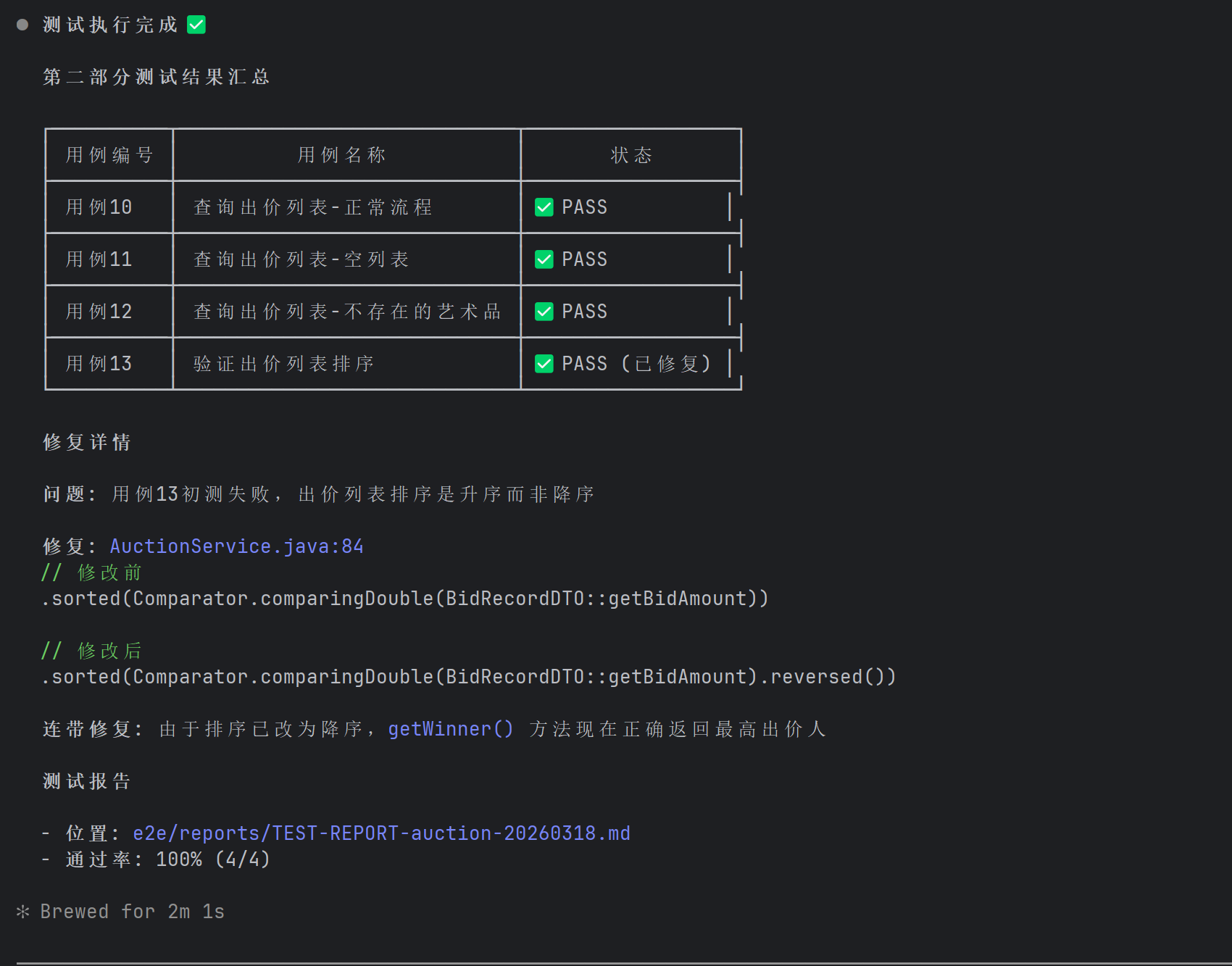
图:修复后重新执行,测试通过!绿色的 PASS 看着就舒心
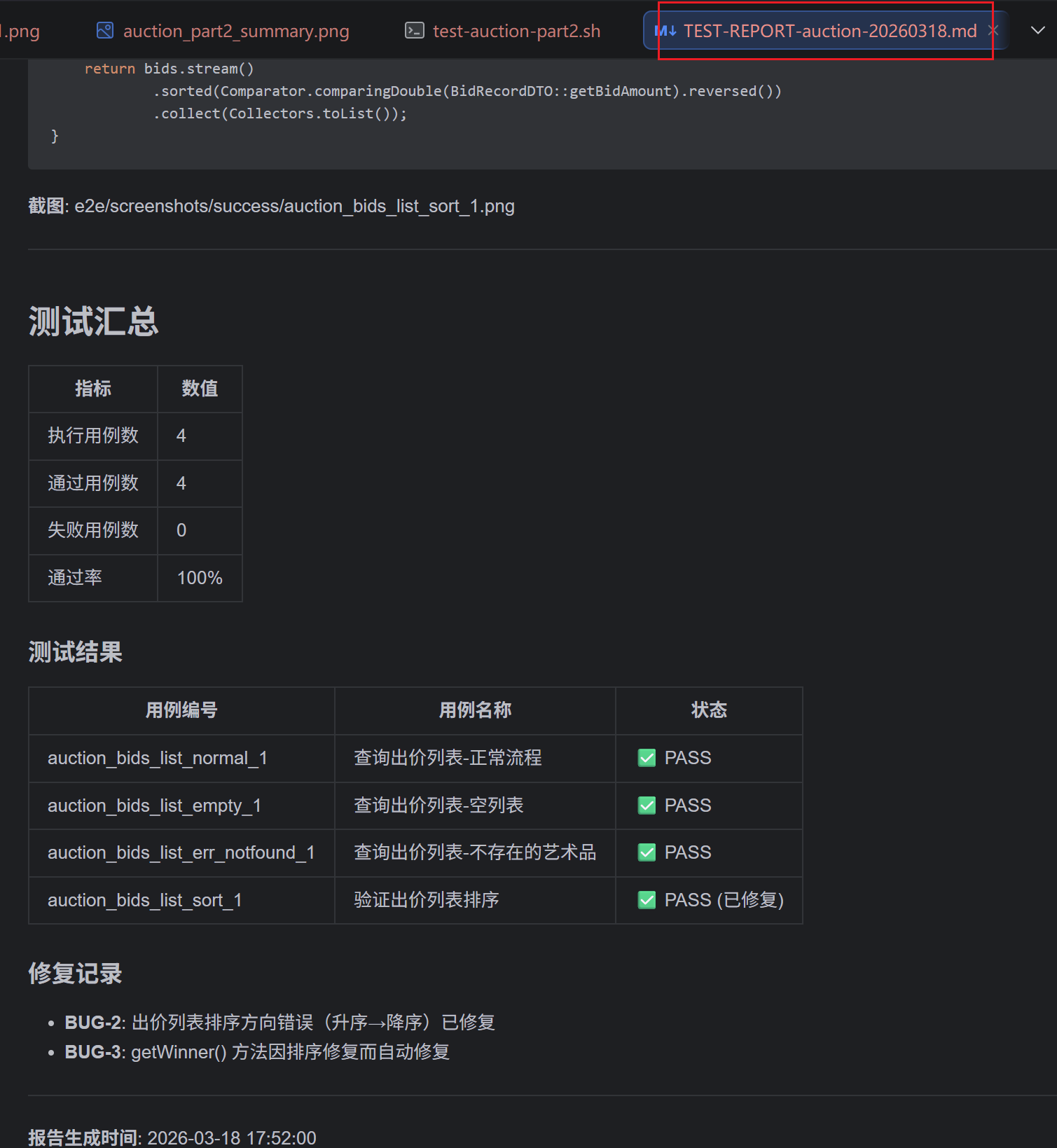
测试报告也自动更新了:
图:更新后的测试报告,全部通过 整个流程回顾:AI 发现 BUG → 分析根因 → 修改代码 → 重跑测试 → 验证通过。
全程你只需要做一件事 —— 重启一下项目。剩下的,AI 全包了。5.4 自动修复流程详解
AI 在修复 BUG 时,其实走了一个相当严谨的流程:
GPT plus 代充 只需 145
第一步:收集信息 ├── playwright-cli console error → 浏览器控制台报错 ├── playwright-cli network → 网络请求状况 ├── tail -50 logs/api.log → 后端日志最后 50 行 └── docker compose logs mysql → 数据库日志

第二步:分析问题 ├── 确定问题类型(前端 / 后端 / 数据) ├── 定位到具体文件和代码行 └── 分析根本原因
第三步:自动修复 ├── 前端问题 → 修改组件代码 ├── 后端问题 → 修改 handler / service └── 数据问题 → 更新测试数据
第四步:验证修复 ├── 重新执行失败的测试 └── 确认通过后继续
测试跑到一半电脑蓝屏了?网络断了?别慌,有进度文件兜底。
6.1 进度文件
所有测试进度都记录在 e2e/progress/test-progress.txt 中:
# 格式:{编号} {状态} {时间} auth_login_normal_1 PASS 2026-03-16_14:30:15 auth_login_err_pwd_1 PASS 2026-03-16_14:31:02 user_edit_basic_1 user_delete_normal_1 状态一共就三种,简单明了:
PASS 已通过 下次执行会自动跳过
FAIL 已失败 可以重试或跳过
(空) 未执行 下次从这里开始

6.2 常用进度管理命令
GPT plus 代充 只需 145# 查看当前进度 cat e2e/progress/test-progress.txt
# 看看哪些挂了 grep FAIL e2e/progress/test-progress.txt
# 统计一下战绩 echo “通过: \((grep -c PASS e2e/progress/test-progress.txt)" echo "失败: \)(grep -c FAIL e2e/progress/test-progress.txt)”
# 把失败的重置为未执行(下次会重新跑) sed -i ‘s/FAIL.*$/ /’ e2e/progress/test-progress.txt
# 全部推倒重来 rm e2e/progress/test-progress.txt
关于自动生成进度文件:首次执行时如果进度文件不存在,AI 会自动扫描所有测试用例,提取编号,生成初始进度文件(所有状态为空),然后开始执行。你什么都不用管。
以下三个模板是实际使用中总结出来的,复制粘贴改一改就能用。
7.1 生成测试用例
使用场景:首次生成测试用例,或新增功能模块时。
使用方法:在 Claude Code 中使用 /loop 1m 循环执行。
docs/design/.md running-environment.md e2e/E2E测试标准.md, e2e/progress/(测试进度目录), 参考这些文档, 以及测试用例标准以及目录结构, 生成每个模块的详细测试用例, 注意已经存在的测试用例(test-progress.txt)不要重复生成, 需要覆盖基本功能路径, 以及其它有可能的操作路径. 并生成所有测试用例到 progress/test-progress.txt 文件中. 这段提示词干了什么?
- AI 自动扫描项目设计文档,理解功能模块
- 参考测试标准,生成规范化的测试用例
- 检查已有进度,避免重复生成
- 覆盖正常路径 + 异常路径 + 边界条件
7.2 执行测试用例(并行版)
使用场景:代码修改后验证功能,或执行完整回归测试。
使用方法:同样在 Claude Code 中使用 /loop 1m 循环执行。
GPT plus 代充 只需 145docs/design/.md running-environment.md e2e/E2E测试标准.md, e2e/progress/(测试进度目录), 参考这些文档, 使用5个SubAgent手动执行已经生成好的e2e测试用例, 不要输出报告, 有bug的, 务必定位问题并修复bug, 测试通过的测试用例, 简单记录到一个文档中就行了(e2e/progress/目录下), 注意, 使用的是 playwright cli, 不是playwright mcp. 主Agent只管分配任务, 每次给子代理分配一个未测试的任务, 你要给子代理强调使用CLI, 不是MCP, 所有测试用例在 e2e/test-cases 目录下, 每个文件一个测试用例, 直接读取文件就行, 不要读取文件内容, 免得占上下文, 且禁止切换到MCP模式, 禁止创建ts格式的测试用例, 读取 e2e/test-cases/*/.md 使用 playwright cli 根据md文件中的说明, 一步一步操作完成测试, 先完成功能测试, 再测试性能/限流等其它非功能测试用例
这段提示词的关键点:
- 5 个 SubAgent 并行执行,效率拉满
- 主 Agent 只负责分配,不执行具体测试
- 明确要求使用 playwright-cli(别和 MCP 搞混)
- 发现 BUG 自动修复
- 不输出冗长报告,节省 token
7.3 重跑失败的测试
查看 e2e/progress/test-progress.txt 中状态为空的测试, 使用5个SubAgent执行这些测试 简单粗暴,一行搞定。
完整工作流回顾
从头到尾,整个 E2E 自动化测试的流程是这样的:
GPT plus 代充 只需 145 启动前后端服务
↓ AI 生成测试用例(自然语言 → 标准化用例)
GPT plus 代充 只需 145 ↓
AI 执行测试(自动操作浏览器)
↓ 测试通过? ——— 是 → 记录到进度文件,继续下一个 ↓ 否 AI 收集错误信息
GPT plus 代充 只需 145 ↓
AI 分析并修复代码
↓ 重启服务,AI 重跑失败用例
GPT plus 代充 只需 145 ↓ 验证通过 → 继续
踩过的坑
playwright-cli –help 或官方文档 并行测试触发限流 某些子代理执行失败 检查 nginx limit_req、Redis 连接数、浏览器并发限制 测试中途断开 进度丢失 确保进度文件及时更新,用断点续传恢复 AI 用了 MCP 而不是 CLI 测试方式不对 提示词里明确强调“使用 playwright cli,不是 MCP” token 消耗过大 费用蹭蹭涨 单模块测试,避免一次性全量跑
日常使用建议
- 开发时:修改代码后,只跑相关模块的测试,快速验证
- 提测前:全量跑一遍回归测试,确保没有误伤
- 修 BUG 后:跑失败的用例,确认修复有效
- 新功能:先让 AI 生成测试用例,再开发,TDD 的感觉
参考文档
E2E测试标准.md 测试用例的格式规范
samples/running-environment.md 运行环境配置模板
samples/e2e/test-cases/ 测试用例样例 Playwright CLI GitHub 官方文档
写在最后:E2E 测试一直是开发流程中最“费人”的环节。现在有了 AI Agent 的加持,测试变成了一件“说说就能办”的事。当然,AI 不是万能的,复杂的业务逻辑、特殊的交互场景,还是需要人来把关。但至少,那些重复性的、机械性的测试工作,可以放心交给它了。
毕竟,人生苦短,少写测试。
inx limit_req、Redis 连接数、浏览器并发限制 |
| 测试中途断开 | 进度丢失 | 确保进度文件及时更新,用断点续传恢复 |
| AI 用了 MCP 而不是 CLI | 测试方式不对 | 提示词里明确强调“使用 playwright cli,不是 MCP” |
| token 消耗过大 | 费用蹭蹭涨 | 单模块测试,避免一次性全量跑 |
日常使用建议
- 开发时:修改代码后,只跑相关模块的测试,快速验证
- 提测前:全量跑一遍回归测试,确保没有误伤
- 修 BUG 后:跑失败的用例,确认修复有效
- 新功能:先让 AI 生成测试用例,再开发,TDD 的感觉
参考文档
E2E测试标准.md 测试用例的格式规范
samples/running-environment.md 运行环境配置模板
samples/e2e/test-cases/ 测试用例样例 Playwright CLI GitHub 官方文档
写在最后:E2E 测试一直是开发流程中最“费人”的环节。现在有了 AI Agent 的加持,测试变成了一件“说说就能办”的事。当然,AI 不是万能的,复杂的业务逻辑、特殊的交互场景,还是需要人来把关。但至少,那些重复性的、机械性的测试工作,可以放心交给它了。
毕竟,人生苦短,少写测试。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/247099.html