
大家好,今天咱们不聊那些让人头秃的数学公式,来聊聊一个让 AI Agent终于有点“人味儿”的新框架——RETROAGENT。

大家都知道,现在的 LLM Agent虽然能干活,但有个大毛病:健忘且固执。
你让它玩个游戏,它要么撞南墙不回头(陷入局部最优),要么每次重来都像失忆一样,完全忘了上次是怎么死的。这就好比一个学生,每次考试都靠蒙,蒙对了就完事,从来不复盘错题本。
上海 AI Lab 和新加坡国立大学的研究者们看不下去了,反手甩出了一个新框架 RETROAGENT。它的核心思想就一个:别光想着解题,要学会进化!
怎么进化?靠“复盘”。而且是通过双重内在反馈(Dual Intrinsic Feedback)来复盘。
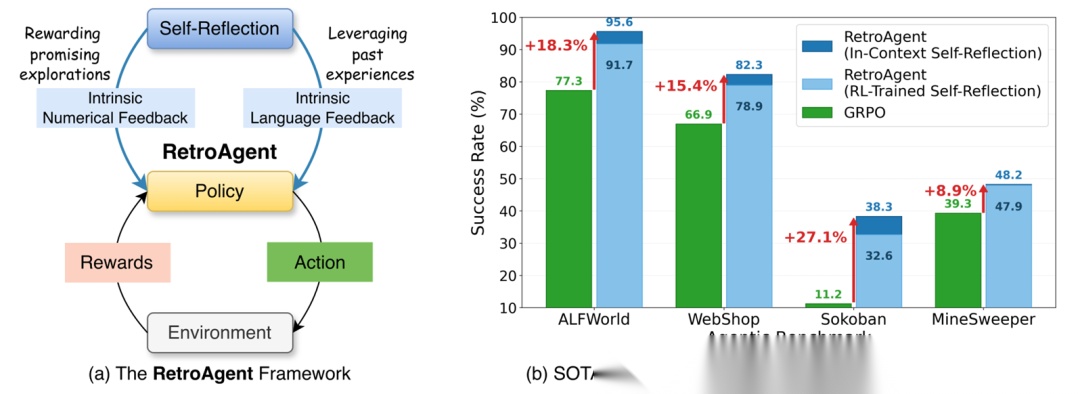
目前的强化学习(RL)训练范式,大多只关注“把任务做完”。一旦找到一条能通的路,Agent 就懒得探索其他可能性了。这导致两个问题:
- 太保守:容易收敛到次优策略,明明有更爽打法,它不用。
- 记不住:知识都藏在模型参数里,没法 explicit(显式)地调用过去的经验。
这就好比你打游戏,通关了就删存档,下次玩还得重新摸索 BOSS 技能。
RETROAGENT 引入了一个事后自省机制(Hindsight Self-Reflection)。每次 episode 结束,Agent 都要写“复盘报告”,生成两种反馈:
1. 内在数值反馈(Intrinsic Numerical Feedback)
“虽然你没通关,但这波操作很帅!”
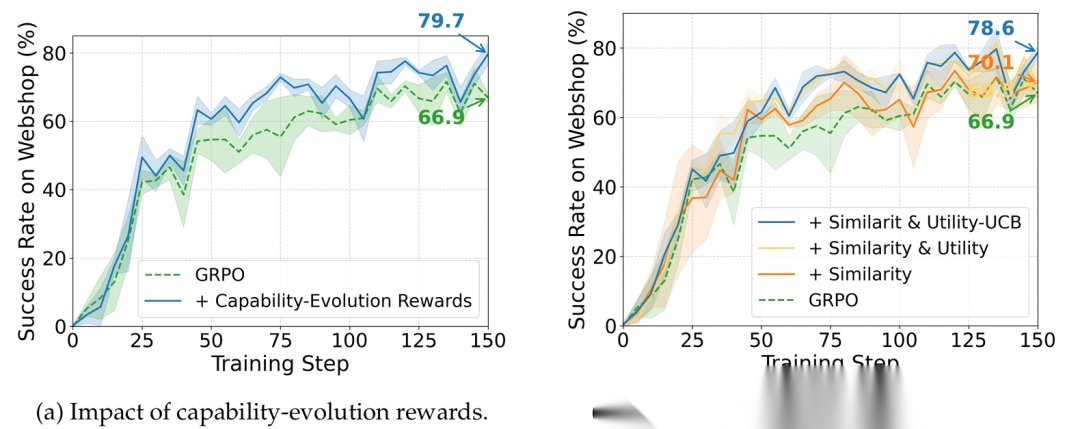
传统的 RL 只有通关才有奖励(稀疏奖励)。但 RETROAGENT 会说:哪怕你最后挂了,但你比上次多推了一个箱子,多找了一个物品,这就值得奖励! 这叫能力进化奖励(Capability-Evolution Reward)。它鼓励 Agent 去探索那些“虽败犹荣”的路径,防止过早躺平。
2. 内在语言反馈(Intrinsic Language Feedback)
“上次在这里踩坑了,这次记得绕路。”
Agent 会把过去的成功和失败 distilled(蒸馏)成自然语言的经验教训,存进一个记忆缓冲区(Memory Buffer)。 下次遇到类似任务,它不是瞎猜,而是先去查“错题本”。
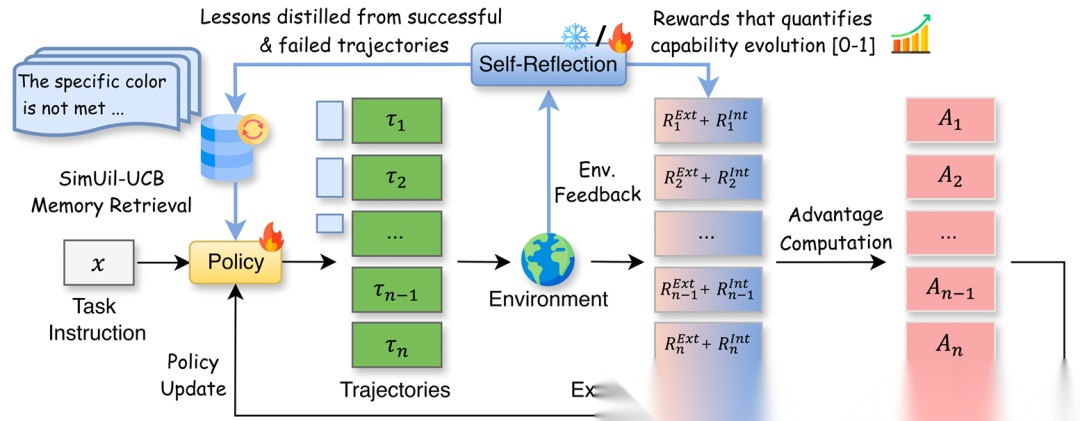
光有记忆不够,还得会查。如果每次只查最相似的记忆,容易陷入思维定势。 RETROAGENT 提出了一个听起来很高大上的策略:SimUtil-UCB(相似性与效用感知的上置信界)。
说人话就是,查记忆时考虑三点:
- 相关性:这事儿跟当前任务像不像?
- 效用性:这条经验以前好不好用?
- 探索性:有些经验虽然好久没用了,但说不定有奇效,也得试试。
这就好比选餐厅,不能只去离家最近的(相关性),也不能只去吃过最好吃的(效用性),偶尔也得尝尝新开的小店(探索性),以免错过美食。
光说不练假把式,咱们直接看数据。研究者在四个硬核任务上 tested 这个框架:ALFWorld(家务)、WebShop(网购)、Sokoban(推箱子)、MineSweeper(扫雷)。
基线模型用的是强大的 GRPO 和 Qwen-2.5-7B。结果呢?RETROAGENT 直接碾压。
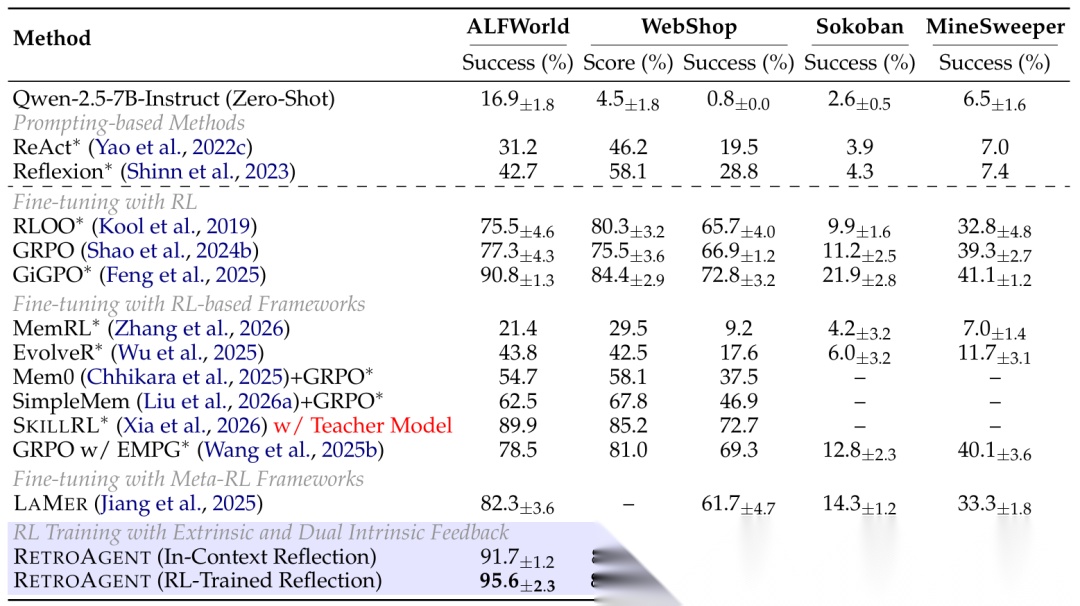
看看这提升幅度:
- ALFWorld: 比 GRPO 高了 +18.3%
- WebShop: 高了 +15.4%
- Sokoban: 高了 +27.1% (推箱子可是规划难题啊!)
- MineSweeper: 高了 +8.9%
而且,这货不仅训练时强,测试时适应能力(Test-Time Adaptation) 也极强。给它多次尝试机会,它能把成功率刷到接近 100%。这说明它真的学会了“吃一堑长一智”。
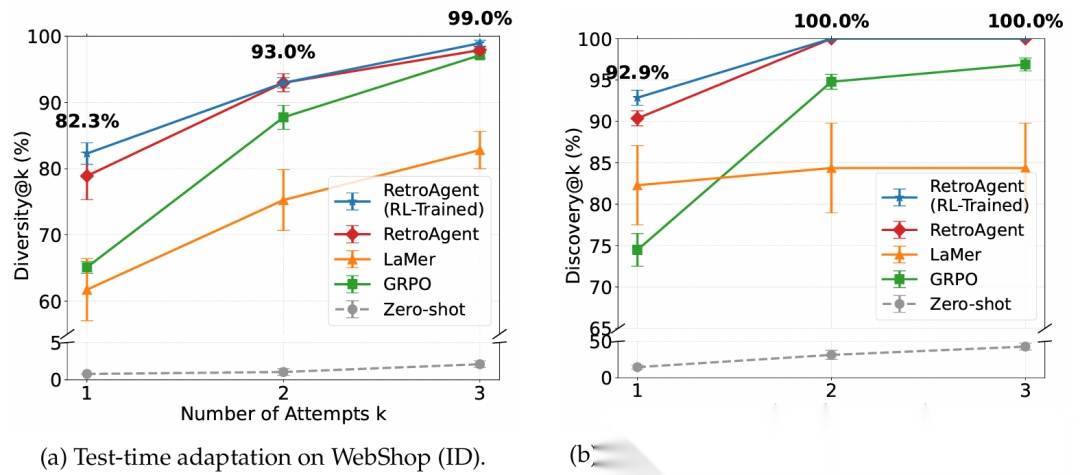
如果你是想复现的开发者,这里有几个关键点值得注意:
- 双变体设计:
- In-Context 版本:直接用 Prompt 让模型反思,简单粗暴有效。
- RL-Trained 版本:把反思能力也当成一个策略,用 REINFORCE 算法一起训练。虽然训练成本高一点,但效果更稳,反思能力会随着策略一起进化。
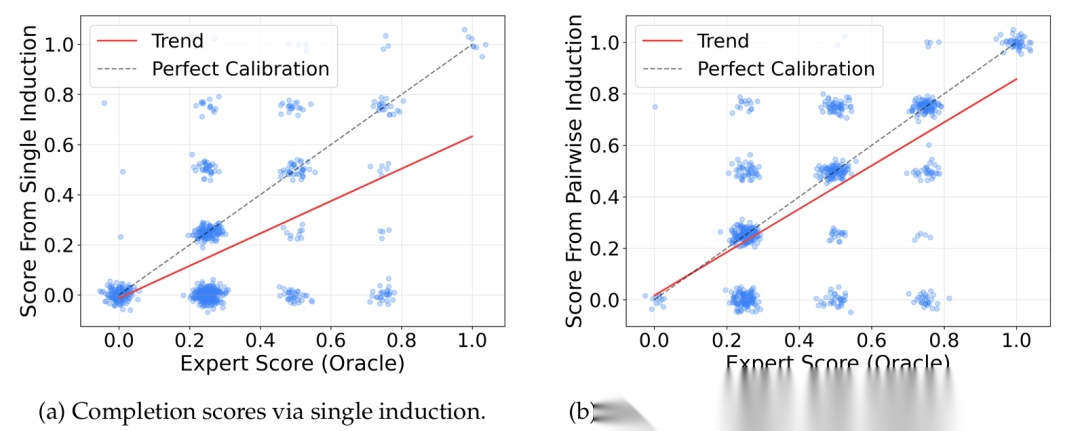
- 记忆检索的平衡: 论文里有个有趣的发现,如果只检索“最相似”的记忆,效果反而可能下降。必须加上 UCB 的探索 bonus,才能避免模型过度依赖某几条旧经验。
- 成对归纳(Pairwise Induction): 在反思时,让模型对比“成功轨迹”和“失败轨迹”,比单看一条轨迹生成的经验质量更高。这就像老师批改作业,有标准答案对照,改得更准。
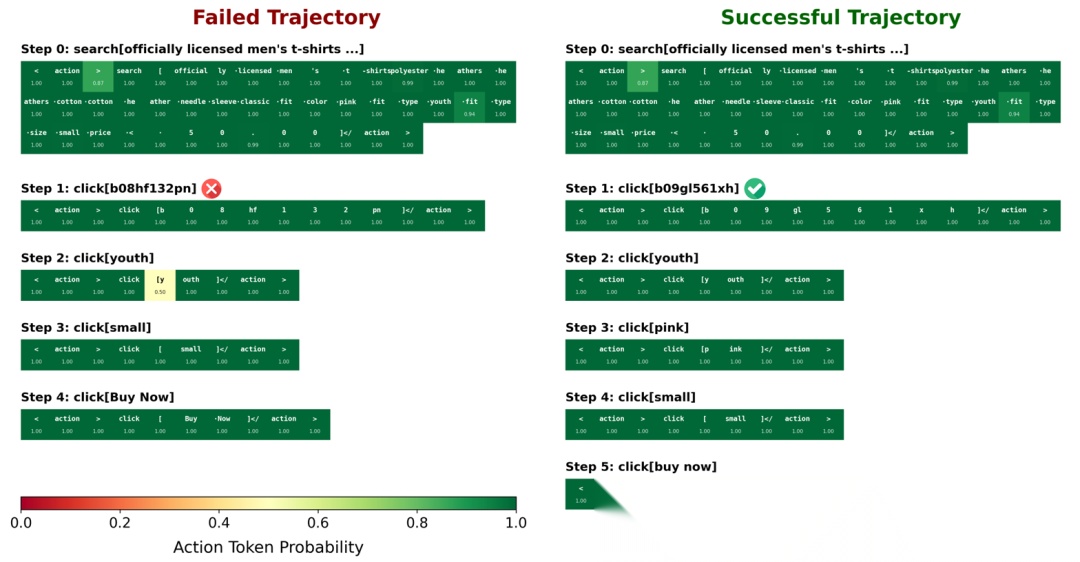
RETROAGENT 最迷人的地方在于,它把 AI 的目标从 Solving(解决) 变成了 Evolving(进化)。
以前的 Agent 是“一次性筷子”,用完即弃;现在的 Agent 开始有了“经验条”,能持续适应新环境,甚至能泛化到没见过的场景(OOD Generalization)。
当然,这还不是终点。论文最后也提到,如何更好地平衡“反思目标”和“决策目标”的多任务优化,还有多智能体场景下的应用,都是未来的坑(哦不,是方向)。
总的来说,这是一篇让 Agent 真正拥有“长期记忆”和“自我改进”能力的佳作。对于想做 Agent 落地的朋友,这个双重反馈 + 记忆检索的思路,绝对值得抄进你的作业本里。
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/246955.html