
在学习强化学习过程中,总会遇到智能体(agent)的概念,但没有看到一个定义来描述什么是智能体。可否认为智能体是一个算法模型呢
强化学习的问题背景是一个二元结构,environment和agent。agent,也称为player,就是指是那个能与environment交互,具有改变environment状态能力的本体。基本上这种改变是借助于action实现的。因此,狭义的理解,智能体就是那个将observation映射到action的几个layer构成的网络模型。
可以理解为算法模型。
训练好的智能体:经梯度反向传播优化后的模型参数和模型本身结构。
比如Actor-Critic结构中,就可以把智能体看为Actor,因为Actor模型的输入是状态,输出是动作,同时强化学习中的策略也可以是Actor模型,训练好的策略就是通过梯度优化后的Actor模型参数。
简单而言智能体(agent)就是根据输入状态,输出动作,具体输出什么动作是根据策略决定,即训练好的模型参数前向计算得到。
爬一手好线杆:入坑强化学习的一些不成熟建议强化学习并不是某一种特定的算法,而是一类算法的统称,本文会着重讲清楚这类算法最常规的设计思路和大致框架,使用非常容易理解的语言带你入门强化学习。
强化学习在近些年得到了越来越多的关注。虽然现在关于强化学习的资料有很多,但是许多读者仍然觉得强化学习入门比较困难,许多时候有一种似懂非懂或者 “知其然而不知其所以然”的感觉。 甚至一些读者认为强化学习是一个黑盒子,很多东西数学上是解释不清的,这其实是一种误解。事实上,强化学习有很强的数学性和系统性,也正因为如此入门强化学习的门槛并不低。终于有本书把强化学习的数学原理一次性讲清楚了!
那有没有一套能够从零开始、从数学角度、结合大量例子、循序渐进地揭示 强化学习的本质原理的开源教程呢?
免费开源教程获取地址:
如果你学习的时候喜欢刨根问底、追求 “知其然并知其所以然”,相信这个课程能很好地帮助你透彻理解强化学习!
首先需要明确一个基本的问题:什么是强化学习?
强化学习是智能体在与环境的互动中为了达成目标而进行的学习过程。
举个超级玛丽游戏的例子,我们需要让智能体Agent,通过和环境Environment的互动中,进行学习,从而通关。
这里提到了强化学习中非常基础的三个元素Agent,Environment和Goal。
基本元素
1. Agent:这里智能体就是玛丽这个人物(或者是我们玩家),可以操作玛丽进行移动或者射击等行为Action;
2. Environment:环境就是游戏引擎,这个环境中包括了各种要素,比如敌人,金币,台阶,砖块,花朵蘑菇等等,这个环境会实时改变,而这种改变是学习之前智能体不能完全预见的,这个环境的每一时刻,都可以用一个状态变量State来描述;
3. Goal:目标就是玩家的目标,这里可以是用最快的速度通关,也可以是花费最少的生命代价通关,也可以是获得最多的金币通关。需要注意的是,这里的目标是最终的目标,而不是每一个时刻的目标,每一个时刻的目标可以称为Reward或者Return,和Goal完全不同,是两个概念,需要着重区分。当然Goal,即最终目标,也可以换算成每一个时刻的Reward做累积,但无论如何,这里的Goal是一个全过程、全局的量。
我们在介绍以上三个基本元素时,又提到了以下三个主要的元素State,Action,Reward。
主要元素
1. State: 状态。State是描述环境在某个时刻的变量,不同时刻的环境状态可能不同,请思考:下一个时刻的状态和什么有关?答案是:下一个时刻的状态和上一个时刻的状态有关,同时和上一个时刻的智能体动作Action有关。由于每一个时刻状态都是一个符合某种分布的随机变量,那么t 时刻的状态可以记作 S_t ;
2. Action:行动。Action是描述智能体和环境互动的要素。Action可以是有限种且离散的,比如超级玛丽中玩家的操作方式,上、下、左、右、大跳、小跳、射击一共七种。当然Action也可以是无限种且连续的,比如某些游戏中智能体的步幅、力度等。那么 t 时刻的智能体的行动实际上是一个符合某种分布的随机变量,可以记作 At ;
3. Reward: 奖励。奖励是智能体或者玩家当前时刻衡量对未来最终Goal的贡献,通俗来说,有点类似“小目标”。具体举例来说,玛丽拾取金币,Reward=1,玛丽通关,Reward=,当然这种情况大概率发生在以通关为最终目标的学习过程中,需要注意的是,Reward是玩家根据行动后下一个时刻的状态来定义的,因此也可以说Reward是由状态State决定的。再举一个例子,围棋游戏中,某时刻智能体吃掉系统对手的棋子时,Reward可以为0,也可以为负,这是因为就整体战略上来说一时吃对面的子,未必导致最终会占领最大的地盘,存在弃小争大的可能,也就是说,在和环境的互动中,贪心策略往往不是最合理的,而reward往往可能具有延迟的性质。
data-pid=“Q3fCcRk”>将以上描述总结成一个过程,就是某时刻t ,Agent观察到Environment的状态 s_t ,从而采取行动Actiona t ,而Environment针对Agent的行动,会更新状态为 s{t+1},Agent获得奖励 r_t。这里之所以用小写字母是因为其并非随机变量,而是确定的观测值或者采样值了。这一过程用下图可以说明。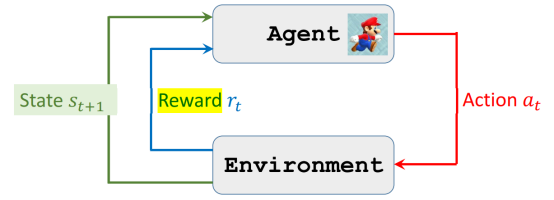
我们在描述智能体和环境的互动过程中时,又涉及了两个核心的问题:玩家如何行动?玩家如何评估当前状态的奖励?接下来需要介绍以下两个强化学习中核心的元素。
核心元素
1. Policy:策略。Policy可以被认为是一个函数,输入是状态 s 和行动a,输出是该行动在该状态下的实施概率。一般将该策略函数记作π。即 π(s,a)\rightarrow [0,1] 或 π(a|s)=P(A=a|S=s)。举例来说,还是拿超级玛丽游戏为例,当前状态是游戏画面,该策略函数可以根据该画面计算不同的玩家行动的实施采样概率,比如左:0.2,上:0.7,右:0.1,即该场景下玩家采取的行动有20%可能是向左,有70%的可能是向上,有10%的可能是向右,如下图所示。

从原则上来说,对于固定的状态State,玩家采取的行动Action不应该是确定的,而应该是一个随机变量,玩家学习的应该是这个随机变量的更合理的一个分布。
所以,整个过程应该是,玩家观测到环境的状态 s_1,从而根据策略函数 π 采样一个行动 a_1 ,环境会更新状态为 s_2 ,此时玩家获得奖励 r_1,然后玩家根据观测到的环境状态 s_2,继续根据策略函数π 采样下一个行动 a_2,…依此进行,直到环境告诉玩家终止。如下图所示。

那么如何判断一个策略的好坏呢,我们就需要引出下一个核心元素,价值。
2. Value:价值。Value是衡量当前时刻直到结束时所有累计Reward的总和,由于Reward是依赖于State和Action的,所以Reward也是随机变量,而Value是累计的Reward,所以我们用记号 U 表示。即 U_t=Rt+R{t+1}+R{t+2}+…+R{n} 。但这没有考虑Reward的时间价值,明显现在的奖励比未来的奖励更重要(可以用存钱得利息来理解),因此更合理的定义应该是U_t=Rt+gamma R{t+1}+{gamma}^2 R{t+2}+…+{gamma}^{n-t} R{n},这里gamma是折旧率。因此价值越大,意味着未来获得的奖励累计总和会越多,玩家会更倾向于这种结果。
因此我们可以提出下一个很关键的函数:Value Function 价值函数。
先喝口水,慢慢来说
Q:首先请问,当前的价值依赖于什么?
A:答:依赖于当前直到未来结束所有的奖励。那这些奖励分别又依赖于当前到未来结束的状态和行动。
因此,我们可以得到:价值由当前直到未来结束所有的环境状态和玩家行动来决定。但这难以计算。我们注意到,除了当前的状态和行动,未来的状态和行动也都是随机变量,实际上其分布也由当前的状态和行动决定,因此我们可以简单计算价值的期望!
即 E(U_t) 可以用 S_t 和 At来表示!这种关系就是行动价值函数 Action-Value Function!我们用 Q{π} 表示。
Q_{π}(s_t,a_t)=E(U_t|S_t=s_t,A_t=at)
进一步的,我们固定状态,对所有行动求期望和,会得到状态价值函数 State-Value Function!我们用V{π} 表示。
V_{π}(st)=E[Q{π}(st,A)]
总结来说,给定一个策略函数 π ,行动价值函数 Q{π}(s,a) 可以衡量智能体在状态 s 下实施行动 a的好坏。而状态价值函数V_{π}(s) 可以衡量智能体在状态 s 的当下形势好坏。因此,衡量一个策略函数的好坏可以用以下指标:
ES[V{π}(S)]
到这里我们就基本介绍完了。但可能有的读者还是觉得有点疑惑,那说了这么半天,智能体怎么和环境进行互动学习呢?
其实强化学习的基本框架已经介绍给大家了。
提示一下,智能体既可以学习策略函数 π 直接来和环境互动学习,也可以 学习行动价值函数 Q_{π},选择使得价值最大的路径来和环境互动学习,这就是两种不同的强化学习方法了,分别叫做Policy-Based 和Value-Based方法。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/246756.html