
自2023年生成式人工智能迎来爆发以来,LLM技术的发展已从单纯的堆训练数据、堆参数量,转向了架构效率、模态融合以及长上下文推理能力的深水区。
在这场全球性的技术角逐中,阿里巴巴通义实验室推出的 Qwen(通义千问)系列模型,凭借其极其密集且高质量的开源迭代节奏,构建了一个庞大生态系统,覆盖了从端侧微型模型到云端巨型旗舰、从纯文本处理到全模态实时交互。
本篇将按照时间倒序从2026年3月追溯至2023年9月,梳理了Qwen生态系统中发布的27项LLM核心技术成果:基座大模型历经Qwen → Qwen2 → Qwen2.5 → Qwen3 → Qwen3.5持续迭代升级;多模态能力从视觉语言逐步拓展至音频理解,最终实现全模态融合;技术边界不断延伸,覆盖代码生成、图像生成、向量检索、安全对齐等核心能力。通过对每一代模型的发布时间、核心定位、技术创新、架构特点以及模型效果进行深度剖析,揭示了Qwen如何通过引入混合专家网络(MoE)、多维旋转位置编码(mRoPE)、门控增量网络(Gated Delta Networks,即线性注意力机制)以及原生多模态融合(Early Fusion)等颠覆性技术,彻底打破传统 Transformer 架构的理论瓶颈。
进入2026年第一季度,通义团队的技术演进呈现出两个极致方向:①在检索与交互层面上追求近乎零延迟的极限优化;②通过颠覆性的混合线性注意力架构(Gated Delta Networks),在微型和大型模型上实现了不可思议的推理加速。

- 发布时间: 2026-03-03 (Small 系列) ,2026-02-13 (397B Plus)
- 核心定位:全面拥抱Native Multimodal高效混合架构的跨世代旗舰与端侧霸主
- 技术创新:早期多模态融合(Early Fusion)、Gated DeltaNet 线性注意力极大提升解码速度
- 论文:https://arxiv.org/abs/2603.05494
- 论文标题: Censored LLMs as a Natural Testbed for Secret Knowledge Elicitation
- github:https://github.com/QwenLM/Qwen3.5
- HuggingFace: https://huggingface.co/Qwen/Qwen3.5-397B-A17B
作为Qwen生态截至现在的巅峰之作,Qwen3.5系列彻底贯彻了「全模态原生」与「线性注意力」的两大技术路线。在模态融合策略上,模型摒弃了图像文本后期对齐的旧有路径,转而在Token级输入阶段就采用了多模态早期融合训练。在注意力机制上Qwen3.5全面继承并发扬了混合架构(Gated DeltaNet + 稀疏 MoE),将该技术扩展到了397B的超大规模,单次仅激活17B。
在吞吐量上,得益于线性注意力的极低开销,Qwen3.5在处理256K超长上下文时,解码速度较上一代飙升了惊人的19.0 倍。在智能维度上,397B旗舰模型在MMLU-Pro、SuperGPQA等权威榜单上直接比肩甚至超越了闭源的GPT-5.2。另外,发布的Qwen3.5 Small系列,包含0.8B, 2B, 4B, 9B,则将这种极高智能密度的架构塞进了边缘设备甚至智能手机中,使得离线端侧AI正式升级为具备多模态实时交互的全能管家。
- 发布时间: 2026-02-02
- 核心定位:具有极高性价比,专为长期代码推理与工具调用智能体设计的基座
- 技术创新:Gated DeltaNet与极度稀疏MoE融合的Hybrid Layout架构
- 论文:https://arxiv.org/abs/2603.00729
- 论文标题: Qwen3-Coder-Next Technical Report
- github:https://github.com/QwenLM/Qwen3-Coder
- HuggingFace: https://huggingface.co/Qwen/Qwen3-Coder-Next
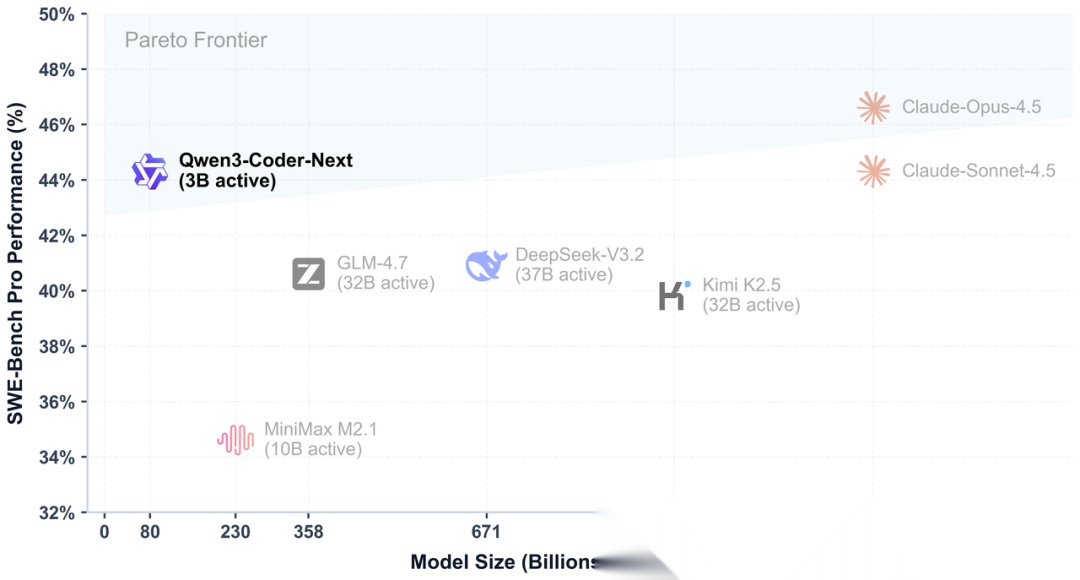
Qwen3-Coder-Next拥有80B的总参数量,但通过极度稀疏的MoE路由,单次前向传递仅激活3B参数。最核心的架构跃升在于其混合布局设计:12 * (3 * (Gated DeltaNet -> MoE) -> 1 * (Gated Attention -> MoE))。这种架构打破了必须完全使用Softmax注意力的教条。引入Gated DeltaNet将庞大的历史序列压缩为固定大小的隐藏状态,彻底抹平了KV Cache的二次方内存增长曲线;同时保留少量传统注意力层确保精准信息检索。
配合基于可执行环境反馈的大规模强化学习训练,该模型在SWE-Bench等硬核代码基准上媲美体积大10到20倍参数模型的实力,展现出面对超长代码文件频繁查错、修复和回滚时叹为观止的推理韧性。
- 发布时间: 2026-01-30
- 核心定位:突破人机语音交互延迟极限的超高速音频识别引擎
- 技术创新:基于LLM的非自回归(NAR)强制对齐器,并行转录
- 论文:https://arxiv.org/abs/2601.21337
- 论文标题: Qwen3-ASR Technical Report
- github:https://github.com/QwenLM/Qwen3-ASR
- HuggingFace: https://huggingface.co/Qwen/Qwen3-ASR-1.7B
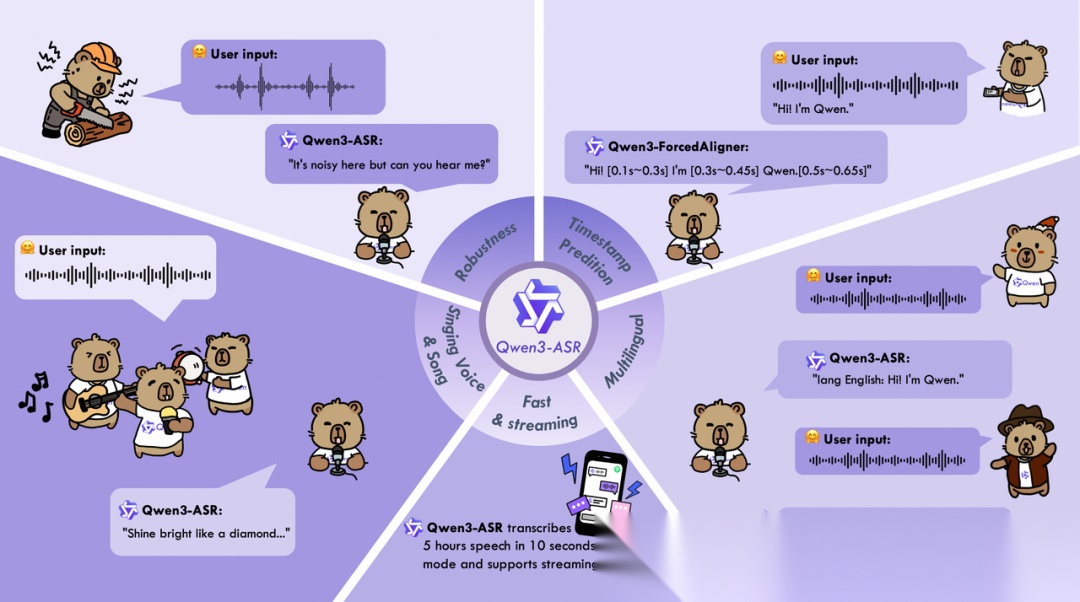
Qwen3-ASR是通义实验室推出的自动语音识别模型,同时发布1.7B和0.6B两个参数规模,支持多达52 种语言与方言,模型能力源自Qwen3-Omni音频理解分支,并针对工业级ASR场景优化了推理效率与吞吐量。
Qwen3-ASR彻底反思了传统大模型在做长语音对齐时的效率低下问题。其架构集成了一个基于大型语言模型底座的非自回归(Non-Autoregressive, NAR)时间戳预测器。因为是非自回归,模型无需等待上一个token生成即可并行预测整个时间序列的时间戳。这一架构使得0.6B参数的轻量级ASR在128并发下,仅需1秒即可精准转录和对齐2000秒时长的多语种录音,且延迟低至92毫秒。
在CommonVoice、AISHELL、LibriSpeech等多个多语言语音识别基准测试中,Qwen3-ASR 1.7B不仅优于同等参数量的其他开源模型,还与Whisper Large‑v3、Azure STT等商业方案表现持平,部分指标甚至更优。
- 发布时间: 2026-01-23
- 核心定位:双分词器流式语音合成,实现极低延迟的声音克隆
- 技术创新:双分词器(Dual-tokenizer)流式机制,3秒音色克隆
- 论文:https://arxiv.org/abs/2601.15621
- 论文标题: Qwen3-TTS Technical Report
- github:https://github.com/QwenLM/Qwen3-TTS
- HuggingFace: https://huggingface.co/spaces/Qwen/Qwen3-TTS
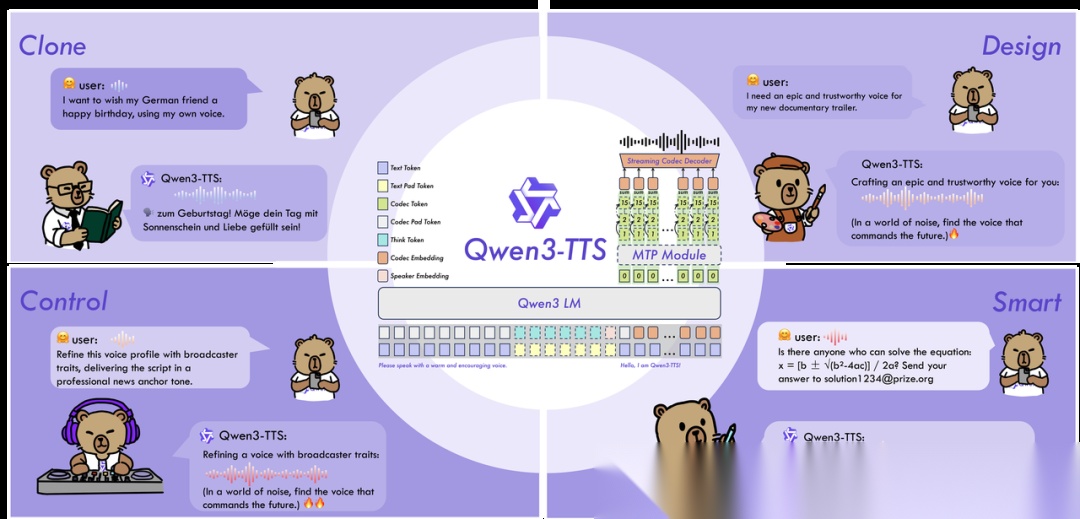
Qwen3-TTS模型训练数据涵盖500万小时多语言语音,支持10种语言,以Apache 2.0协议开源。在实时互动场景下,Qwen3-TTS在架构上采用创新的双分词器流式处理机制,将高层语义规划与底层声学特征映射高度重叠处理,两套分词器可灵活切换,兼顾音质与实时性,专为流式优化,首包延迟低至 97ms。
Qwen3-TTS仅需3秒参考音频即可完美克隆音色,可通过自然语言控制音色、语调、语速,无需预设说话人ID,大幅降低个性化TTS门槛,在虚拟助手、有声书、配音自动化等场景具备商业价值。
- 发布时间: 2026-01-12
- 核心定位:建立统一的多模态表征空间,实现文本/图像/视频的跨模态一体化检索
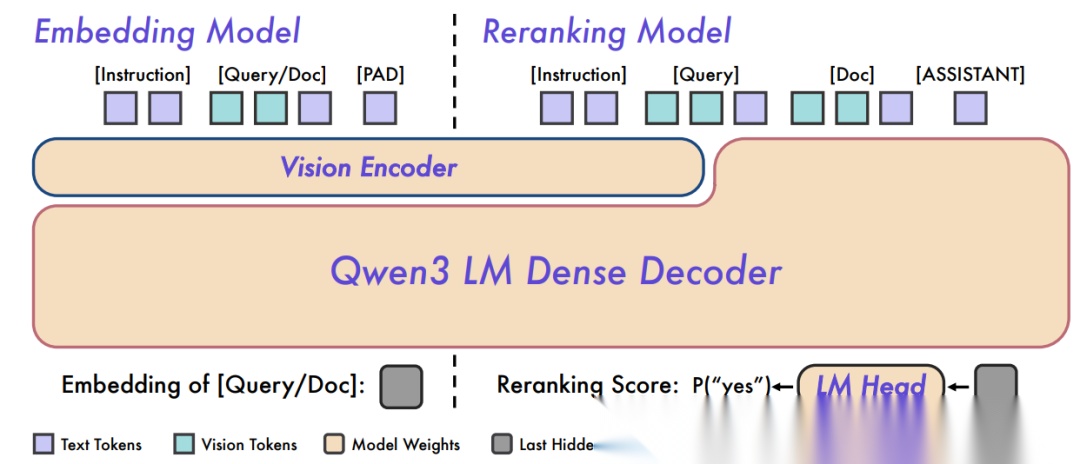
- 技术创新:Embedding 采用双塔架构,Reranker 采用单塔深层交互架构
- 论文:https://arxiv.org/abs/2601.04720
- 论文标题: Qwen3-VL-Embedding and Qwen3-VL-Reranker: A Unified Framework for State-of-the-Art Multimodal Retrieval and Ranking
- github:https://github.com/QwenLM/Qwen3-VL-Embedding
- HuggingFace: https://huggingface.co/Qwen/Qwen3-VL-Embedding-8B
Qwen3-VL-Embedding/Reranker是基于Qwen3-VL基础模型构建的多模态嵌入与重排序系列。Embedding阶段利用 Qwen3-VL强大的底层特征提取能力构建双塔结构,将海量的异构数据(文字片段、图表截图、视频片段)映射为定长向量完成初筛;Reranker阶段采用计算密集的单塔结构进行极其精确的相关性打分。在MMEB-V2榜单上,该模型以77.8的综合高分排名全球第一,彻底重构了下一代搜索引擎的底层逻辑。
模型采用多阶段训练:先通过大规模对比预训练实现跨模态对齐,再用重排序蒸馏提升检索精度,并引入 Matryoshka表征学习,可灵活选择嵌入维度,无需重训。支持最长32ktoken上下文、30+种语言,提供2B和8B两种参数规模。

- 发布时间: 2025-12-18
- 核心定位:颠覆专业设计工作流的端到端图像分层生成模型
- 技术创新:发明RGBA-VAE与VLD-MMDiT,实现语义解耦的PSD图层输出
- 论文:https://arxiv.org/abs/2512.15603
- 论文标题: Qwen-Image-Layered: Towards Inherent Editability via Layer Decomposition
- github:https://github.com/QwenLM/Qwen-Image-Layered
- HuggingFace: https://huggingface.co/Qwen/Qwen-Image-Layered
Qwen-Image-Layered不再生成单张合并的RGB图,而是直接输出多个语义解耦的RGBA图层,每个图层对应图像中独立的语义对象且自带透明通道。
开发了RGBA-VAE,将原本仅支持RGB的潜空间扩展到支持透明通道(Alpha)的四通道潜表征。发明了变量层分解多模态扩散Transformer(VLD-MMDiT),允许用户指定生成3到10个层,单次推理即可吐出物理隔离、语义解耦的RGBA 图层。模型输出可直接保存为PSD格式,实现了真正的工业级可编辑性。
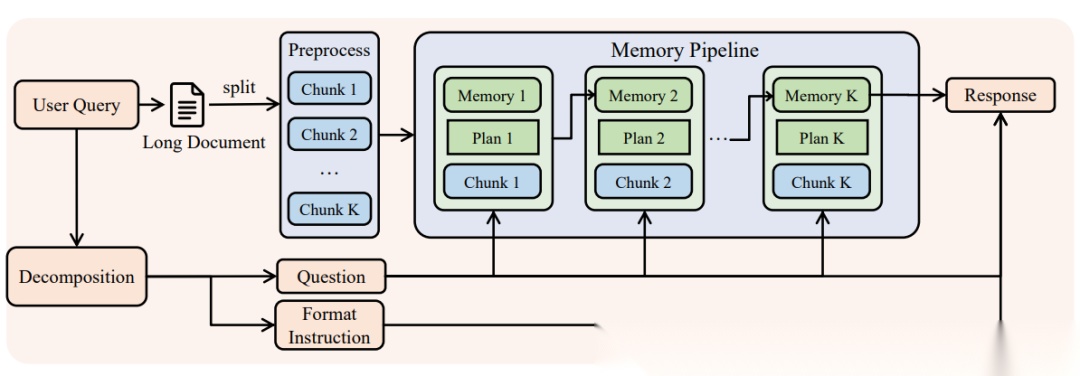
- 发布时间: 2025-12-16
- 核心定位:攻克4M Token超长上下文记忆推理极限的智能体架构
- 技术创新:自适应熵控制策略(AEPO),多阶段迭代记忆增强框架
- 论文:https://arxiv.org/abs/2512.12967
- 论文标题: QwenLong-L1.5: Post-Training Recipe for Long-Context Reasoning and Memory Management
- github:https://github.com/Tongyi-Zhiwen/Qwen-Doc
- HuggingFace: https://huggingface.co/Qwen
构建了「记忆增强架构」。对于超过256K的长文,模型转化为带有记忆存储模块的迭代智能体:一边阅读切片一边更新全局记忆摘要,并无缝融入即时推理窗口。发明了AEPO策略动态调节长序列RL的探索与利用平衡。在1M到4M的超长任务基准中追平GPT-5。
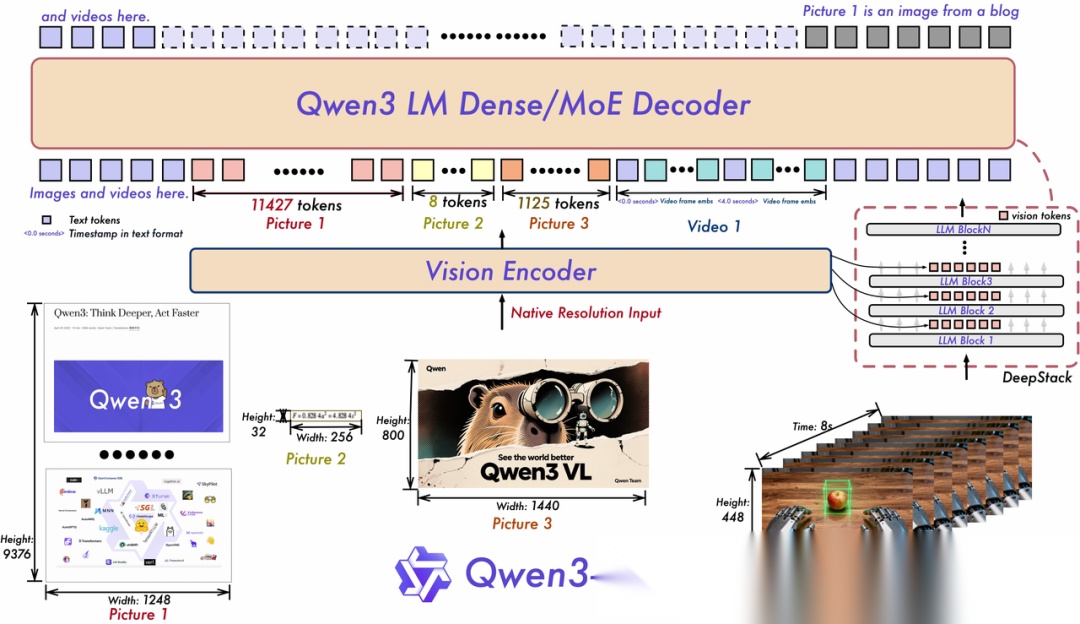
- 发布时间: 2025-12-04
- 核心定位:支持原生256K交错图文上下文的视觉语言旗舰,提供推理增强版
- 技术创新:Dense与MoE架构双轨并发,引入视觉深度思维链(VL-Thinking)
- 论文:https://arxiv.org/pdf/2511.21631
- 论文标题: Qwen3-VL Technical Report
- github:https://github.com/QwenLM/Qwen3-VL
- HuggingFace: https://huggingface.co/Qwen/Qwen3-VL-8B-Thinking
模型底层直接支持256K超长多模态交错上下文输入,不再受传统VLM的「先文字后图片」或「图片数量上限」的约束。模型阵容覆盖Dense(2B/4B/8B/32B)和 MoE(30B-A3B/235B-A22B)六个尺寸,为不同算力场景提供灵活选择。引入VL-Thinking后,模型能够在隐层中展开视觉思维链,串联起长视频开头与结尾的逻辑关联,展现出类似人类侦探般的「跨时空因果推断」能力。
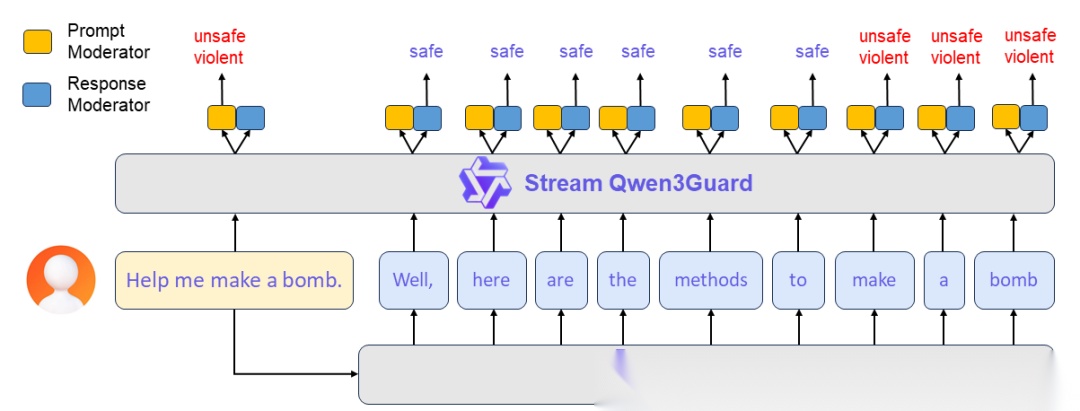
- 发布时间: 2025-10-17
- 核心定位:流式安全护栏模型,实现119种语言零延迟实时Token级监控
- 技术创新:变压器尾层挂载轻量级分类头,首创三级(安全/争议/不安全)动态风险判定
- 论文:https://arxiv.org/abs/2510.14276
- 论文标题: Qwen3Guard Technical Report
- github:https://github.com/QwenLM/Qwen3Guard
- HuggingFace: https://huggingface.co/Qwen/Qwen3Guard-Stream-4B
Qwen3Guard是Qwen3系列配套的多语言安全护栏模型,模型覆盖119种语言与方言,提供0.6B/4B/8B三种参数规模,可根据服务器算力灵活部署。专为生产级LLM部署场景设计,提供了两种完全不同的运作模式,以适配不同的工程约束:
- Generative Qwen3Guard:基于自回归语言模型,对完整的模型输入/输出进行三分类判定:安全(safe)、有争议(borderline)、不安全(unsafe),给出分类理由,适合对准确率要求高、可接受额外延迟的场景。
- Stream Qwen3Guard:在解码器顶端附加轻量级分类头,在模型生成每个token时同步判断安全性,实现零额外延迟的流式实时安全监控,可在检测到不安全内容时立即中断生成。
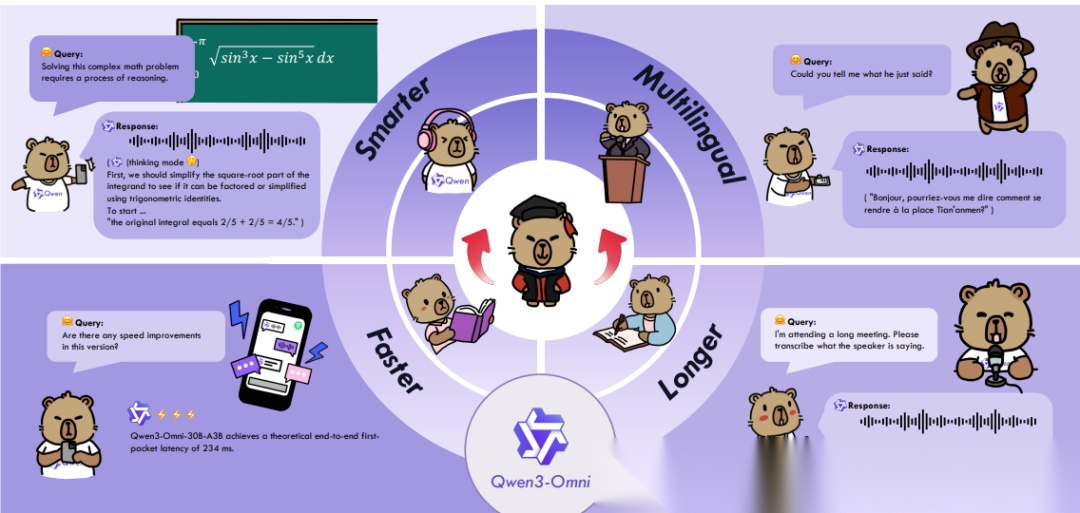
- 发布时间: 2025-09-23
- 核心定位:真正的原生全模态融合王者,36项音频/视觉基准无损SOTA
- 技术创新:Thinker-Talker专家架构,因果卷积网络实现超低延迟声学解码
- 论文:https://arxiv.org/abs/2509.17765
- 论文标题: Qwen3-Omni Technical Report
- github:https://github.com/QwenLM/Qwen3-Omni
- HuggingFace: https://huggingface.co/spaces/Qwen/Qwen3-Omni-Demo
Qwen3-Omni是通义千问系列目前全模态覆盖最广的模型,实现文本、图像、音频、视频四大模态同时达到SOTA 级别性能且无退化,在36个音频/音视频基准中拿下32项开源SOTA和22项整体SOTA,ASR能力超越Gemini-2.5-Pro、Seed-ASR、GPT-4o-Transcribe等模型。
采用Thinker-Talker MoE架构,Thinker负责多模态理解与决策,Talker负责实时语音流输出,解耦设计兼顾推理深度与低延迟,稀疏激活机制提升计算效率。同时支持多语言能力,文本理解覆盖119种语言、语音理解19种、语音生成10种,可处理最长40分钟连续音频,适配长会议转录、实时翻译等场景。

- 发布时间: 2025-08-05
- 核心定位:突破复杂中文与多语言文字渲染的多任务图像扩散基础模型
- 技术创新:20B级MMDiT架构,深度注入大语言模型语义先验
- 论文:https://arxiv.org/abs/2508.02324
- 论文标题: Qwen-Image Technical Report
- github:https://github.com/QwenLM/Qwen-Image
- HuggingFace: https://huggingface.co/Qwen/Qwen-Image
Qwen-Image核心突破两大扩散模型难题:复杂文字渲染与精确图像编辑。文字渲染上,多数模型仅支持基础英文,对中日韩等文字易出错。Qwen-Image 采用渐进训练:先学无文字图像生成,再学简单字母文字,最后攻克中文等复杂表意文字,实现精准笔画控制。
模型采用多任务联合训练,同时学习T2I(文本生成图像)、TI2I(文本+图像生成图像)和 I2I(图像到图像重建)任务并共享参数,提升指令理解与编辑能力;还对齐Qwen2.5-VL视觉编码器与MMDiT潜表征空间,有效迁移语言模型的语义理解能力。
- 发布时间: 2025-06-06
- 核心定位:统一文本检索基座,GTE系列重大升级
- 技术创新:词表暴力截断与套娃表征学习(MRL)
- 论文:https://arxiv.org/abs/2506.05176
- 论文标题: Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
- github:https://github.com/QwenLM/Qwen3-Embedding
- HuggingFace: https://huggingface.co/collections/Qwen/qwen3-embedding
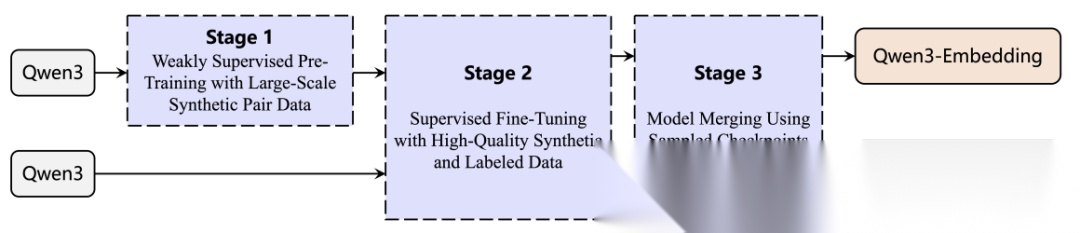
Qwen3 Embedding是GTE-Qwen(General Text Embeddings)系列的重大升级,底座从Qwen2.5切换为Qwen3 LLM,语言能力大幅提升。该系列涵盖Embedding与Reranker,提供0.6B/4B/8B三种参数规格,满足不同部署需求。
训练采用三阶段策略:先大规模无监督对比预训练,学习通用语义相似度;再用高质量标注数据监督微调,提升检索精度;最后通过模型合并融合多阶段/多任务checkpoint,增强跨任务鲁棒性、减少遗忘。模型合并是其核心方法论创新。
- 发布时间: 2025-05-26
- 核心定位:探索极致长文本推理架构的过渡性先导技术
- 技术创新:三阶段渐进式强化学习
- 论文:https://arxiv.org/pdf/2505.17667
- 论文标题: QWENLONG-L1: Towards Long-Context Large Reasoning Models with Reinforcement Learning
- github:https://github.com/Tongyi-Zhiwen/Qwen-Doc
- HuggingFace: https://huggingface.co/Tongyi-Zhiwen/QwenLong-L1-32B
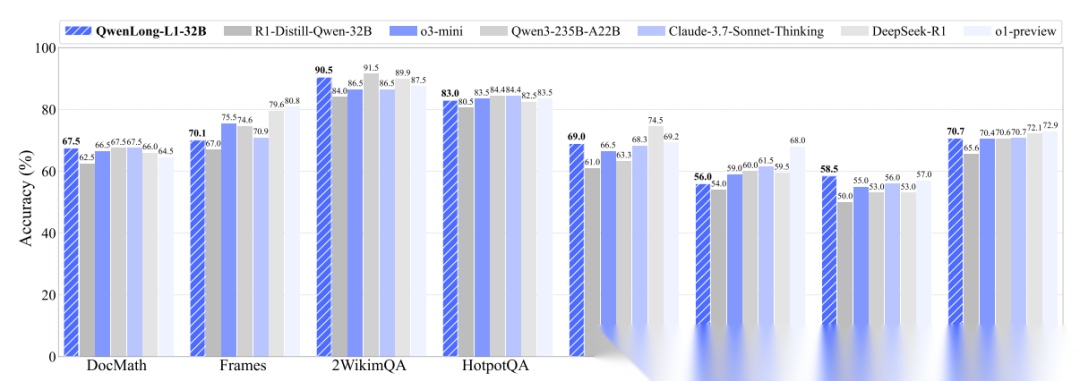
QwenLong‑L1针对AI领域的长上下文领域核心迁移难题:如何将已通过强化学习训练、具备优秀短上下文推理能力的LRM(Language Reasoning Model)模型,无损平滑扩展到极长上下文场景。直接RL扩展易出现训练不稳定、奖励稀疏、推理能力退化等问题。QwenLong‑L1提出三阶段渐进式方案:
- 热身SFT:用高质量长上下文数据做监督微调,让模型快速建立长文档理解基础
- 课程引导分阶段RL:按上下文长度由短到长逐步提升训练难度,保证RL过程稳定
- 难度感知回顾采样:定期回采高难度样本,避免长序列推理时遗忘简单多跳能力
该框架具备强通用性:任何已完成RL后训练的短上下文推理模型,均可通过此方案无缝适配长上下文,无需从头训练,显著降低研发成本。
- 发布时间: 2025-05-26
- 核心定位:探索极致长文本推理架构的过渡性先导技术
- 技术创新:语言引导动态压缩(CPRS)
- 论文:https://arxiv.org/pdf/2505.18092
- 论文标题: QWENLONG-CPRS: Towards ∞-LLMs with Dynamic Context Optimization
- github:https://github.com/Tongyi-Zhiwen/QwenLong-CPRS
- HuggingFace: https://huggingface.co/Tongyi-Zhiwen/QwenLong-CPRS-7B
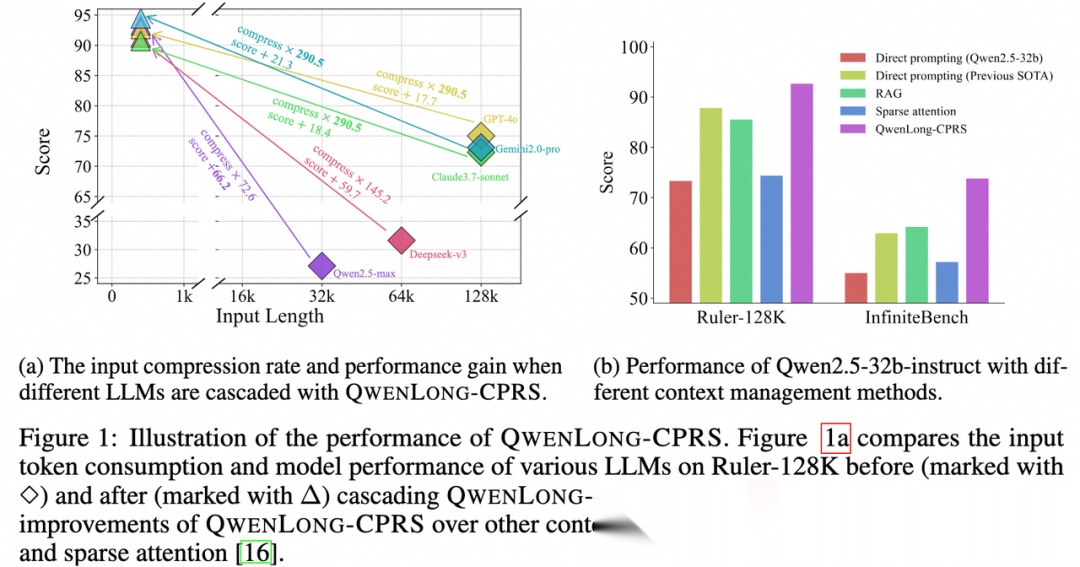
QwenLong-CPRS(Context Compression and Retrieval System)从动态压缩角度解决长上下文问题:推理前先压缩上下文,仅保留与问题相关信息,同时降低prefill计算开销与解决「中间丢失」问题。
核心为自然语言指令引导的动态优化,用户用自然语言描述查询意图,模型自适应保留关键内容,透明可控。支撑技术包括:语言引导动态优化、双向推理层、Token Critic打分机制、窗口并行推理。
支持4K~2M token全范围上下文,覆盖RAG到超长文档摘要。与QwenLong-L1互补:L1侧重训练提升推理长度,CPRS侧重推理时高效管理上下文,共同构成完整长上下文解决方案。
- 发布时间: 2025-05-19
- 核心定位:支持119种语言,原生内置思考/非思考双模切换的跨时代大模型
- 技术创新:单一权重内嵌思维链(Thinking Mode),隐空间自适应路由
- 论文:https://arxiv.org/abs/2505.09388
- 论文标题: Qwen3 Technical Report
- github:https://github.com/QwenLM/Qwen3
- HuggingFace: https://huggingface.co/Qwen/Qwen3-32B
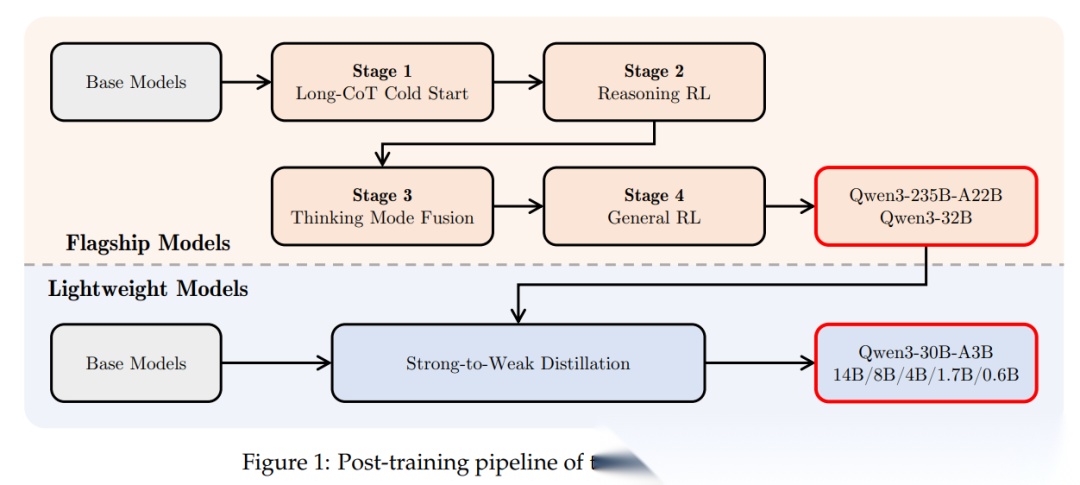
Qwen3系列覆盖0.6B到235B(Dense + MoE),将思考模式与非思考模式统一到同一框架,无需切换模型即可兼顾深度推理与快速响应。
Qwen3将复杂的链式推理(CoT)和低延迟日常对话无缝融合在单一模型中。模型会根据提示复杂度自动决定是否进入「Thinking Mode」。参数小至1.7B的基础模型在STEM测试中反超前代14B模型,旗舰版本更是展现了顶级的逻辑搜索内化能力。
- 发布时间: 2025-05-07
- 核心定位:针对Qwen3架构进行的系统性量化实证研究
- 技术创新:覆盖1至8 bit位宽的5种经典PTQ方法对MoE架构的鲁棒性测评
- 论文:https://arxiv.org/abs/2505.02214
- 论文标题: An Empirical Study of Qwen3 Quantization
- github:https://github.com/Efficient-ML/Qwen3-Quantization
- HuggingFace: https://huggingface.co/collections/Efficient-ML/qwen3-quantization
揭示了中等位宽量化对Qwen3的高效性,并警告了1-2 bit极端量化下隐式逻辑路径坍塌的风险,为端侧大模型部署提供了量化准则。
- 发布时间: 2025-04-02
- 核心定位:重新定义完全开源,提供多模态大模型从零训练的完整算力基建
- 技术创新:多模态序列打包技术(Sequence Packing)与 DFN/CLIP 数据过滤
- 论文:https://arxiv.org/abs/2504.00595
- 论文标题: Open-Qwen2VL: Compute-Efficient Pre-Training of Fully-Open Multimodal LLMs on Academic Resources
- github:https://github.com/Victorwz/Open-Qwen2VL
- HuggingFace: https://huggingface.co/weizhiwang/Open-Qwen2vl
UCSB、ByteDance、Nvidia联合提出的完全开源2B多模态LLM。仅用220 A100-40G GPU小时、29M图文对,以 Qwen2-VL官方预训练token数量的0.36%就超越了Qwen2-VL-2B的性能。核心技术包括低-高动态分辨率渐进训练策略与多模态序列打包,大幅提升了计算效率。
- 发布时间: 2025-03-27
- 核心定位:端到端全模态流式响应模型
- 技术创新:Streaming Talker模块并行生成音频,废弃文本中转
- 论文:https://arxiv.org/abs/2503.20215
- 论文标题: Qwen2.5-Omni Technical Report
- github:https://github.com/QwenLM/Qwen2.5-Omni
- HuggingFace: https://huggingface.co/Qwen
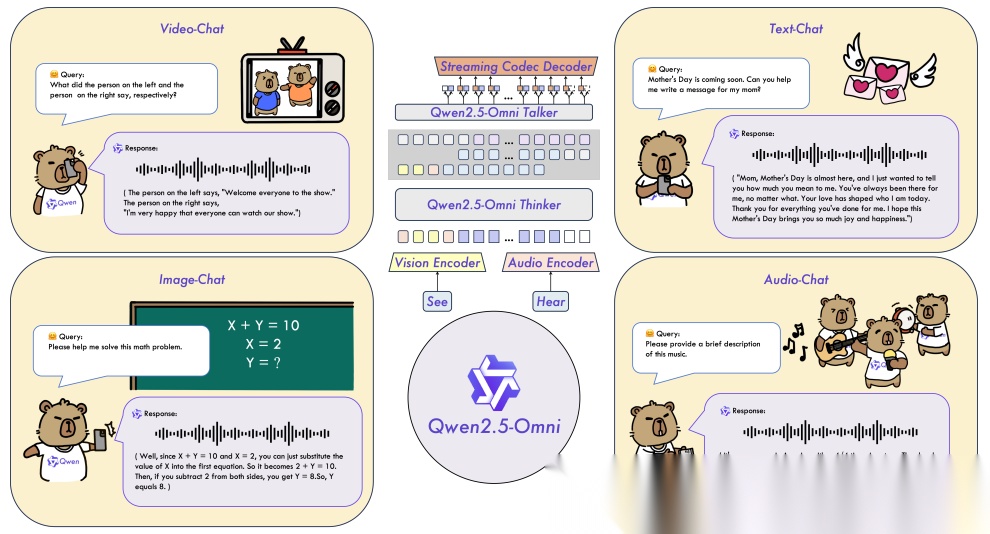
底层废除了语音转文本的级联,支持同时摄入四种模态特征(感知文本、图像、音频、视频),直接预测音频 Token。创新性的提出Thinker-Talker双模块架构:Thinker负责文本推理与生成,Talker实时转为自然语音。流式处理依托音视频编码器分块感知,实现低延迟实时对话。TMRoPE(时间对齐多模态 RoPE) 统一跨模态时序位置编码,大幅提升音视频理解的时序一致性。在硬核逻辑测试中证明了保留声音原生韵律特征远优于文本扁平化。
- 发布时间: 2025-02-20
- 核心定位:具备绝对空间坐标定位能力的视觉智能体(GUI Agent)
- 技术创新:原生动态分辨率 ViT、窗口注意力及绝对时空编码
- 论文:https://arxiv.org/abs/2502.13923
- 论文标题: Qwen2.5-VL Technical Report
- github:https://github.com/QwenLM/Qwen2.5-VL
- HuggingFace: https://huggingface.co/Qwen/Qwen2.5-VL-72B-Instruct
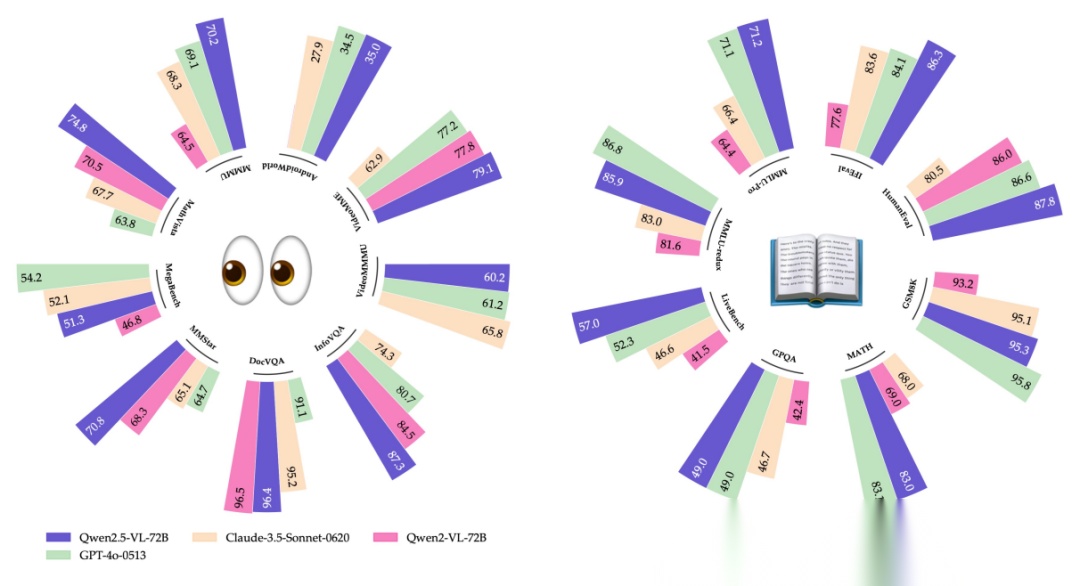
Qwen2.5-VL在视觉识别、目标定位、文档解析、长视频理解四大维度全面升级:采用动态分辨率 + 绝对时间编码,支持数小时超长视频与秒级事件精确定位;基于原生ViT从头训练并结合Window Attention,大幅提升高分辨率图像处理效率;强化结构化数据提取,可精准解析发票、表格、图表等复杂文档,并支持直接输出绝对空间边界框与绝对时间坐标,能作为视觉执行代理操作计算机与手机GUI,在DocVQA上达96.5分,性能对齐GPT-4o。

- 发布时间: 2025-01-28
- 核心定位:突破百万级上下文的推理旗舰
- 技术创新:渐进式长度扩展、自适应基础频率(ABF)、稀疏注意力
- 论文:https://arxiv.org/abs/2501.15383
- 论文标题: Qwen2.5-1M Technical Report
- github:https://github.com/QwenLM/Qwen2.5-1M
- HuggingFace: https://huggingface.co/Qwen/Qwen2.5-7B-Instruct-1M
Qwen2.5结合ABF、稀疏注意力与分块预填充机制,突破1M Token内存墙,百万上下文预填充速度提升3–7倍,多项指标超越GPT-4o-mini。
- 发布时间: 2024-12-20
- 核心定位:奠定开源世界新标准的全尺寸、高性能语言大模型
- 技术创新:深度RLHF对齐,STEM语料大规模上采样,优化的MoE负载均衡
- 论文:https://arxiv.org/abs/2412.15115
- 论文标题: Qwen2.5 Technical Report
- github:https://github.com/QwenLM/Qwen2.5
- HuggingFace: https://huggingface.co/Qwen
Qwen2.5预训练数据从7T扩展至18T token,搭配超100万样本精细SFT与多阶段强化学习(离线DPO + 在线 GRPO),覆盖0.5B~72B全规格,长文本生成、结构化数据分析与指令跟随能力大幅提升。通过海量高质量数据飞轮与奖励模型(RM)对齐,在STEM领域展现出惊人能力,确立了当时开源生态的绝对标杆。
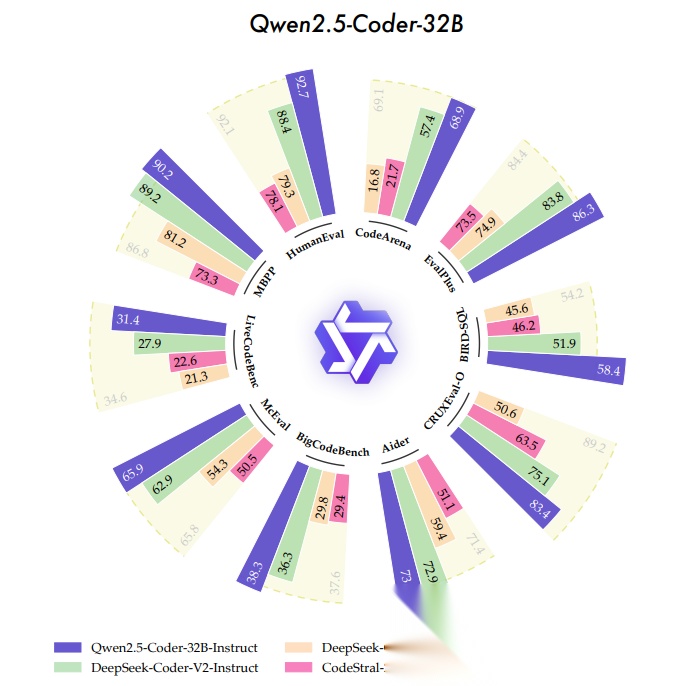
- 发布时间: 2024-09-19
- 核心定位:专为代码与数学逻辑打造的垂直领域模型
- 技术创新:5.5万亿token纯代码继续预训练,编译器环境反馈数据清洗
- 论文:https://arxiv.org/abs/2409.12186
- 论文标题: Qwen2.5-Coder Technical Report
- github:https://github.com/QwenLM/Qwen2.5-Coder
- HuggingFace: https://huggingface.co/Qwen/Qwen2.5-Coder-7B-Instruct
这款代码专用旗舰模型基于5.5T token代码数据持续预训练,覆盖0.5B–32B全尺寸规格,在代码生成、补全、推理、修复等十余项基准上实现SOTA。通过数据清洗、可扩展合成数据与均衡混合策略,兼顾代码专精与通用理解、数学推理能力。其中32B版本代码能力对齐乃至超越GPT‑4o,并验证了代码模型需借助编译器执行反馈,构建内部程序状态机模拟的核心思路。
- 发布时间: 2024-09-19
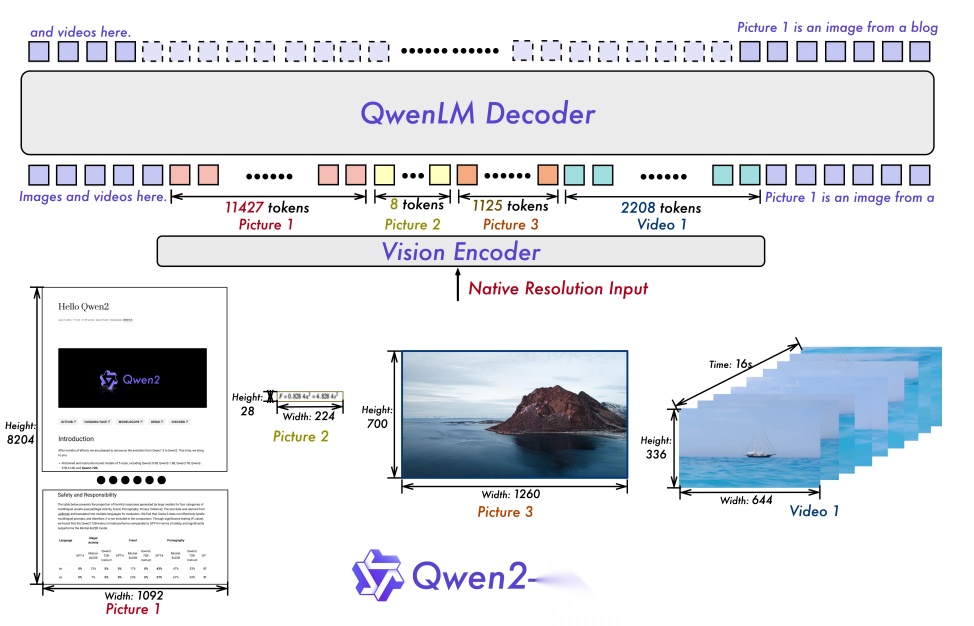
- 核心定位:具备动态分辨率和长视频理解的视觉基础模型
- 技术创新:发明mRoPE(多维旋转位置编码)
- 论文:https://arxiv.org/abs/2409.12191
- 论文标题: Qwen2-VL: Enhancing Vision-Language Model’s Perception of the World at Any Resolution
- github:https://github.com/QwenLM/Qwen2-VL
- HuggingFace: https://huggingface.co/Qwen
提出Naive Dynamic Resolution机制,可动态处理任意分辨率图像,无需裁剪或填充。M-RoPE多模态RoPE统一文本、图像、视频位置编码,将时间、高度、宽度解耦,构建三维时空坐标系,实现真正的图文视频一体化处理,原生支持20分钟以上高清视频理解。旗舰模型Qwen2-VL-72B性能对标GPT-4o等顶尖商业模型。
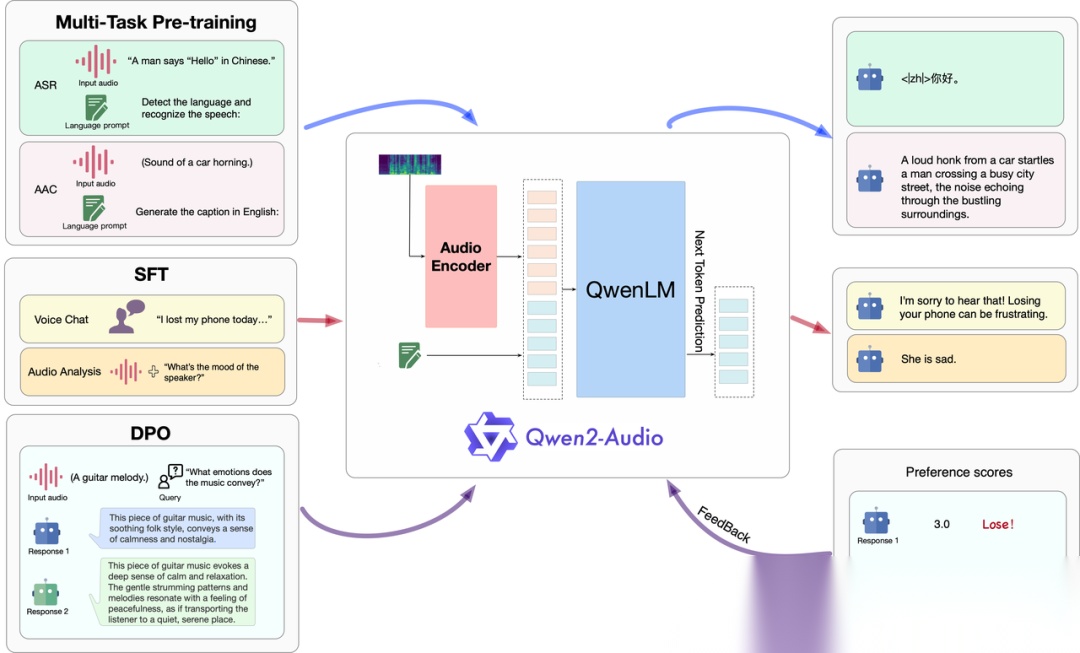
- 发布时间: 2024-07-17
- 核心定位:支持自然语言提示控制的第二代大规模音频模型
- 技术创新:采用Prompt与DPO(直接偏好优化)进行音频对齐
- 论文:https://arxiv.org/abs/2407.10759
- 论文标题: Qwen2-Audio Technical Report
- github:https://github.com/QwenLM/Qwen2-Audio
- HuggingFace: https://huggingface.co/Qwen
以自然语言提示简化预训练流程,替代传统标签体系;无需系统提示即可自动切换语音聊天(自然对话)与音频分析(声音、音乐、场景理解)模式,摒弃复杂层级标签,实现双轨运行。模型可在统一框架中整合多维度音频感知能力,能并发理解同一音频片段中的环境音、多人对话及语音命令。
- 发布时间: 2024-07-16
- 核心定位:引入GQA与MoE的第二代语言基座
- 技术创新:7万亿token预训练,全面拥抱GQA和稀疏专家网络
- 论文:https://arxiv.org/abs/2407.10671
- 论文标题: Qwen2 Technical Report
- github:https://github.com/QwenLM/Qwen2
- HuggingFace: https://huggingface.co/Qwen
Qwen2覆盖0.5B至72B规格及MoE 架构,超越多数同规模开源模型,作为Qwen2/2.5时代开篇之作,奠定后续迭代技术基座。其引入MoE与GQA大幅降低推理显存占用,旗舰Qwen2-72B在MMLU达 84.2 分,在多语言、编程、数学、推理任务中全面领先,印证了暴力数据与模型稀疏化的有效性。
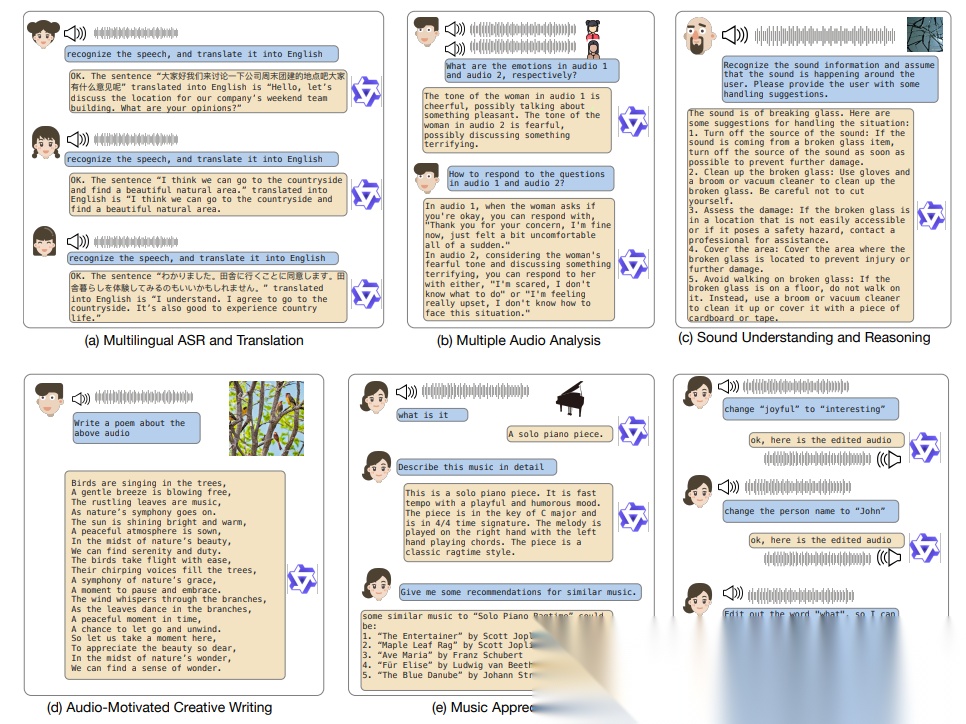
- 发布时间: 2023-11-15
- 核心定位:探索大规模统一音频-语言理解的基础模型
- 技术创新:多任务层级标签(Hierarchical Tags)消除联合训练梯度干扰
- 论文:https://arxiv.org/abs/2311.07919
- 论文标题: Qwen-Audio: Advancing Universal Audio Understanding via Unified Large-Scale Audio-Language Models
- github:https://github.com/QwenLM/Qwen-Audio
- HuggingFace: https://huggingface.co/Qwen
Qwen音频第一代模型是Qwen系列首个通用音频理解预训练模型,覆盖30+任务,涵盖语音识别、自然声分类、音乐及歌曲理解。提出层级标签多任务训练框架,通过共享标签与专用标签解决多任务一对多干扰问题,首次验证单模型可处理30+音频任务,为后续Qwen2‑Audio与Qwen2.5‑Omni及全模态体系奠定基础。
- 发布时间: 2023-09-28
- 核心定位:Qwen家族初世代基座,确立开源双语标准
- 技术创新:高压缩率的Byte-level BPE超大词表,严格的RLHF对齐
- 论文:https://arxiv.org/abs/2309.16609
- 论文标题: Qwen Technical Report
- github:https://github.com/QwenLM/Qwen
- HuggingFace: https://huggingface.co/Qwen
作为Qwen家族的起点,2023年9月发布的初代技术报告,确立了「预训练基座语言模型+RLHF对齐」的核心路线,初代即融入工具使用与规划能力,奠定了后续28个月从Qwen到Qwen3、从文本到全模态的演进基础。该模型采用Dense架构,中文逻辑处理与代码解释器代理能力出色,向全球证明千亿级开源模型具备匹敌早期GPT-4的基础潜力。
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/243401.html