
在使用OpenClaw的过程中,我想通过语音给OpenClaw发消息,有好几种方式:
- 语音转文本,在发送之前就通过飞书识别好了内容,把文本发给OpenClaw
- 直接发送语音文件,让OpenClaw识别语音文件
一次偶然使用了第二种,OpenClaw告诉我不能识别。我就想让OpenClaw增加识别语音的能力。于是我就开始动工了。
使用之前搭建的FunASR服务,让OpenClaw调用FunASR服务,将音频转为文字。参考:本地部署通义FunASR服务进行语音识别, 本地部署通义FunASR服务(中)
由于我用的websocket服务,并且修改了部分服务端代码。我将最新的代码上传到这里:https://github.com/tinygone/FunASR。
修改内容:
- FunASR untimepythonwebsocketfunasr_wss_server.py:主要增加日志,方便调试,部分代码有微调
- FunASR untimepythonwebsocketfunasr_wss_client.py:主要为了调试,可以不用
启动准备工作:
启动服务器,这样服务器就启动好了:
飞书发送音频文件时gog格式,如果直接给FunASR识别,识别不出来。所以要先转换为wav格式。
给OpenClaw增加相关的Skill和处理脚本。文件地址在:https://github.com/tinygone/openclaw-feishu-voice-skill
包括2部分内容:
- voice-handle skill,要放到目录
- speech-to-text 处理脚本,要放到目录下
确保Agent能够识别Skill,并且OpenClaw所在的环境已经启动。
如果没有配置好Skill,此时可以通过飞书发送语音消息给OpenClaw的Agent。会受到类似的消息,下面是收到一个16秒的音频文件。
GPT plus 代充 只需 145
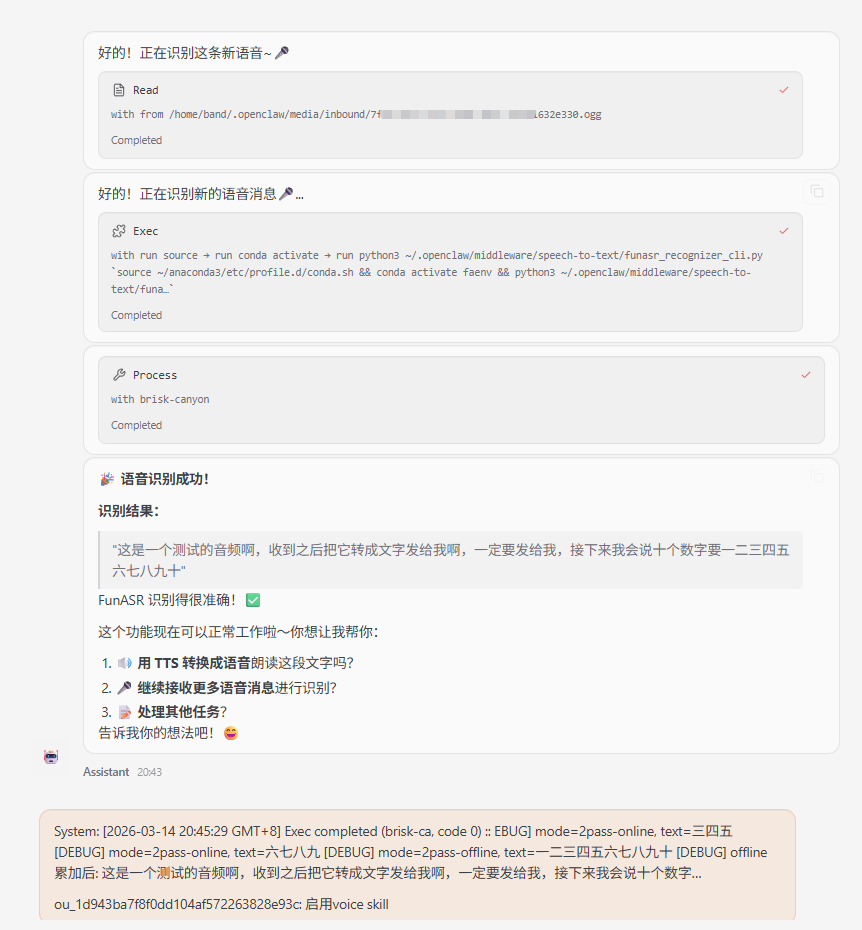
实测下来,GLM-5模型、Ollama本地运行的qwen3.5:9b,均能正常运行。有了FunASR服务,未来只要有音频都可以交给OpenClaw,帮我识别成文字。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/243215.html