
很多人现在已经不满足于“在一个网页里和一个 AI 聊天”了。
更理想的状态是:我可以直接在 WhatsApp、Telegram、Discord,甚至 iMessage 里调度自己的 AI;这个 AI 不只是会聊天,还能分角色、分工作区、分权限,必要时还能拉起多个 agent 并行协作。
OpenClaw 就是为这件事准备的。
它本质上是一个自托管的 AI Gateway。你可以把它理解成一个“消息入口 + Agent 路由层 + 会话中枢”:上面接各种聊天渠道,下面接模型、工具和工作区,中间负责会话、权限、路由和多 agent 协作。
如果你正想搭一个真正能长期用、能分身、能控权限的 AI 助手体系,这篇文章可以直接当入门手册。欢迎来 云栈社区 分享你的实践。
一句话概括:适合想把 AI 从“单点工具”升级成“个人或团队 AI 基础设施”的人。
那么,哪些人或者场景特别适合用它呢?
- 你希望通过聊天软件随时调用 AI,而不是每次都打开网页或 IDE
- 你需要一个长期在线、带会话记忆、可接工具的 agent
- 你希望把“家庭助手”“工作助手”“运维助手”“研究助手”拆成不同 agent,互不串线
- 你需要多账号、多渠道、多工作区并存
- 你希望 agent 之间不仅隔离,还能协作
OpenClaw 的核心价值不只是“能接聊天平台”,而是它把 agent、workspace、session、tools、routing 这些原本零散的能力,做成了一个统一入口。
截至 2026 年 3 月 14 日 我核对官方文档时,OpenClaw 推荐的前置条件是:
- Node.js
- macOS / Linux / Windows
- Windows 场景官方更推荐跑在
最省事的安装方式是官方安装脚本:
安装完成后,直接跑初始化向导:
GPT plus 代充 只需 145
这个向导会帮你做几件关键事情:
- 配置基础认证
- 安装并启动 Gateway 服务
- 初始化常见渠道配置
- 给后续 Control UI 和 agent 运行准备基础环境
装好以后,用下面两个命令确认状态:
如果一切正常,浏览器会打开 Control UI。默认地址通常是:
GPT plus 代充 只需 145
如果你已经有 Node 环境,也可以手动安装:
如果终端提示 ,通常是全局 npm 的 bin 没进 ,可以补一行:
GPT plus 代充 只需 145
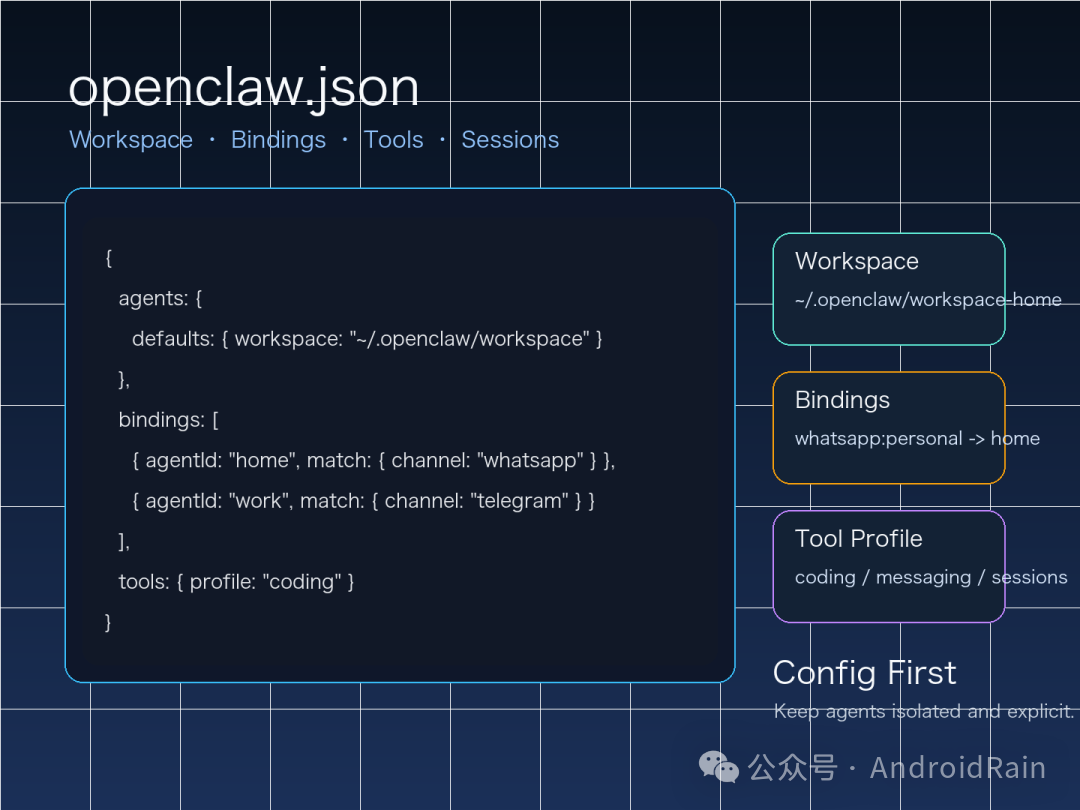
OpenClaw 的主配置文件默认在:
这个文件支持 ,所以比标准 JSON 更友好,能写注释,也更适合长期维护。
如果你不想手改文件,OpenClaw 也提供了几种配置方式:
GPT plus 代充 只需 145
一个最小可用配置大致像这样:
这里有三个值得先记住的点:
模型、工具、会话策略、渠道接入、权限控制、多 agent 路由,基本都能在这里定义。
官方文档说明 Gateway 会监控配置文件变更并自动应用,这对线上微调非常友好。
OpenClaw 对配置做的是严格校验。只要有未知字段、类型不对或者值不合法,Gateway 就会拒绝启动。这一点对生产环境反而是好事。排错时优先跑:
GPT plus 代充 只需 145
如果你的配置越来越大,还可以用 拆分文件:
这非常适合把“渠道配置”“agent 配置”“安全策略”拆开维护。
OpenClaw 的多 agent 设计,最值得重视的一点是:一个 agent 不是一个名字,而是一整套独立上下文。
官方文档里,“一个 agent”默认至少包含这些东西:
- 独立 workspace
- 独立
- 独立 session store
- 独立 persona 文件与技能加载范围
- 独立的 auth profile 读取路径
也就是说,多 agent 的重点不是“多几个机器人”,而是让每个 agent 都变成一个真正隔离的工作单元。
最简单的方式是直接走 CLI:
GPT plus 代充 只需 145
如果你想边创建边绑定渠道账号,也可以加 :
下面是一个很实用的双 agent 示例:
GPT plus 代充 只需 145
这段配置背后的思路很简单:
- 家庭号进
- 工作号进
- 两边工作区、上下文、会话和工具权限都分开
OpenClaw 的绑定不是“模糊匹配”,而是有明确优先级的。文档里的原则可以简单理解成:
- 先看 这种更具体的目标匹配
- 再看 Discord/Slack 这类组织级信息
- 再看
- 再看渠道级兜底
- 最后才回落到默认 agent
这意味着你完全可以做出很精细的路由策略,比如:
- 同一个渠道里,不同账号走不同 agent
- 同一个账号里,不同群或不同用户走不同 agent
- 没匹配上的流量再回到默认 agent
这是多 agent 最容易踩坑的一点。
官方文档明确提醒:不要在多个 agent 之间复用同一个 ,否则会引发认证、会话和状态冲突。想共享凭据,应该复制对应认证文件,而不是直接共用目录。
很多人第一次接触 OpenClaw,以为多 agent 只有“路由隔离”这一种玩法。其实不止。
如果从架构层面看,OpenClaw 里常见的多 agent 协作主要有三层。
这层最容易落地,也最稳定。
做法是把不同入口、不同身份、不同任务类型,直接绑定到不同 agent。比如:
- 家庭聊天入口 ->
- 工作 IM 入口 ->
- 运维告警入口 ->
- 内容创作入口 ->
这类协作的优点是:
- 隔离最强
- 容易审计
- 权限边界清晰
- 不容易上下文串线
缺点也很明显:它更像“分流”,不是真正的 agent 间协同推理。
如果你希望 agent A 把任务交给 agent B,或者把消息送到另一个 session 里继续处理,就要用到 OpenClaw 的 session 工具体系:
其中最适合做“两个 agent 之间交接”的,是 。
你可以把它理解成:把一段消息投递进另一个 session,让目标 agent 在自己的上下文里继续处理。
这类方式适合:
- 主 agent 把某个任务转交给专门 agent
- 某个 agent 需要查询另一个 session 的上下文
- 复杂流程里做跨会话接力
如果你准备走这条路,建议先把工具权限配清楚,比如给编排 agent 开 ,给普通执行 agent 只保留必要工具。
这才是 OpenClaw 更有意思的地方。
OpenClaw 原生支持通过 拉起子 agent。子 agent 会在独立 session 里运行,完成后再把结果通告回请求发起方所在的聊天渠道。
如果你愿意把它想象得更直观一点,可以把它理解成:
- 主 agent 负责接需求、拆任务、汇总结果
- 子 agent 负责并发执行具体工作
这时一套很实用的配置可以写成这样:
这几个字段分别解决不同问题:
- :允许子 agent 再继续拉子 agent
- :防止单个编排器无限扩散
- :限制全局并发,避免把机器打满
- :给长任务一个超时兜底
- :任务结束后自动归档子会话
官方还提供了 命令族,用来查看、停止、追踪子 agent 运行状态。这对调试编排链路特别有帮助。
需要注意一个很细但很重要的点:子 agent 的上下文并不会完整继承主 agent 的所有人格文件。文档里明确提到,子 agent 重点注入的是 和 。所以如果你的协作规范、任务分工、输出格式要求很关键,最好写进 ,而不是只写在更“人格化”的文件里。
如果你还想把多 agent 协作进一步沉淀成“可反复执行的流程”,可以继续往上走一步,启用 OpenClaw 的 插件:
GPT plus 代充 只需 145
OpenProse 的思路不是临时拉几个子 agent 干活,而是把协作步骤写进 文件里,让“研究 -> 执行 -> 汇总 -> 审核”变成可复用、可版本管理的工作流。这对内容生产、代码评审、故障排查这类重复流程特别有价值。
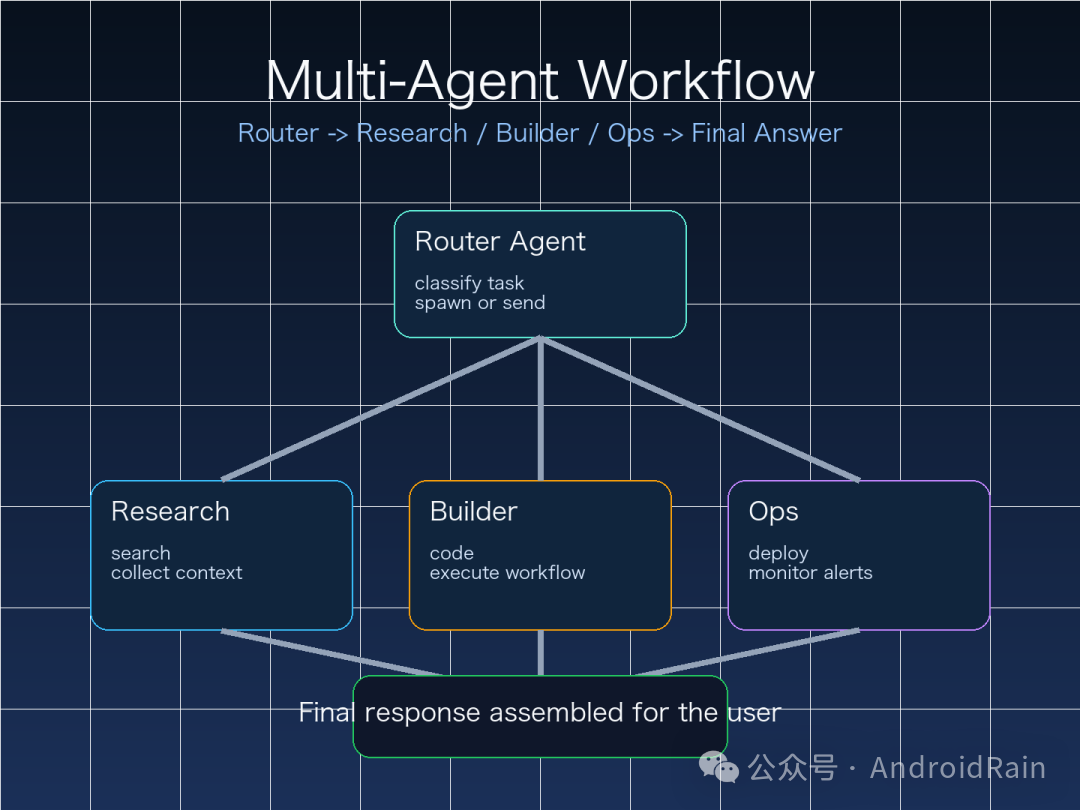
如果你是第一次搭,别一上来就建十几个 agent。更稳的做法是先从“四角架构”开始:
- :负责接收请求、判断分流
- :负责搜索、检索、资料整理
- :负责代码、脚本、自动化执行
- :负责部署、监控、告警处理
推荐做法是:
- 外部消息先路由到
- 根据任务类型决定是自己处理,还是调用 /
- 资料型任务交给
- 执行型任务交给
- 风险高、权限高的动作交给
- 最后由 汇总结果后对外回复
这样做的好处是:
- 对用户来说,入口仍然只有一个
- 对系统来说,内部职责已经拆开
- 后续要扩展写作 agent、客服 agent、数据 agent,都很容易
如果工作区、认证、会话、工具权限不分开,多 agent 只会变成看起来热闹,实际上互相污染。
OpenClaw 支持全局和 per-agent 的工具策略。真正上线时,建议:
- 面向外部聊天的 agent 优先用 或精简 allowlist
- 能执行命令的 agent 才开 或
- 风险动作通过单独 agent 承担
很强,但如果不限制 和 ,很容易让系统进入“任务风暴”。
如果多个真实用户会共用同一个入口,建议认真检查 、发送策略和 allowlist,不要让不同人的上下文混在一起。
很多安装失败、配置错误、兼容问题,最先给出有效线索的不是日志硬翻,而是 。
如果你只是想“找一个 AI 聊聊天”,OpenClaw 可能有点重。
但如果你想要的是一个真正能承载长期工作流的 AI 基础设施,一个可以连接聊天渠道、管理会话、隔离 agent、再把多个 agent 编排起来协同工作的系统,那 OpenClaw 值得认真搭一次。这种对 人工智能 工作流进行结构化管理的思路,非常有价值。
它最有价值的地方,不在于“又一个 AI 工具”,而在于它把 AI 从单点能力变成了一个可配置、可路由、可协作的运行环境。
- 对个人开发者来说,这意味着你终于可以把“AI 助手”变成“AI 系统”。
- 对小团队来说,这意味着你可以开始搭建真正属于自己的多 agent 基础设施。
如果你接下来准备上手,我建议先做这三件事:
- 先跑通单 agent + 一个聊天入口
- 再拆出 两个隔离 agent
- 最后再引入 做并行协作
按这个顺序,成功率会高很多。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/241942.html