
以下是针对 AI Agent开发工程师 面试的详细指南,涵盖技术能力、项目经验、系统设计及行为面试等核心考察点,帮助候选人高效准备。
—
一、技术能力考察
# 1. 基础理论
- 机器学习/深度学习基础
- 必考概念:监督/无监督学习、过拟合与欠拟合、损失函数(交叉熵、MSE)、梯度下降、反向传播、正则化(L1/L2、Dropout)。
- 经典模型:CNN、RNN、Transformer的区别与应用场景。
- 面试题示例:
- “如何解决强化学习中的稀疏奖励问题?”
- “解释Transformer中Self-Attention的计算过程。”
- 强化学习(RL)核心
- 关键算法:Q-Learning、DQN、PPO、A3C、模仿学习(Imitation Learning)。
- 核心概念:马尔可夫决策过程(MDP)、贝尔曼方程、探索与利用(Exploration vs Exploitation)。
- 高频问题:
- “DQN为什么需要Experience Replay和Target Network?”
- “如何设计适合多智能体协作的奖励函数?”
# 2. 编程与框架
- Python与算法
- 重点:手写代码(LeetCode中等难度以上)、递归/动态规划、数据处理(Pandas/Numpy)。
- 框架实战:TensorFlow/PyTorch的模型构建与调试技巧,RL库(如Stable Baselines3、Ray RLlib)。
- 典型题目:
- “用PyTorch实现一个简单的DQN。”
- “优化一个高维状态空间的策略梯度算法。”
- 工具链
- 仿真环境:OpenAI Gym、Unity ML-Agents、MuJoCo的集成与定制。
- 部署技能:模型量化、ONNX转换、TensorRT加速。
—
二、项目经验深挖
# 1. 项目表述结构
- STAR法则:清晰描述项目背景(Situation)、任务目标(Task)、你的行动(Action)、结果(Result)。
- 突出技术难点:例如:
- “在训练对话Agent时,如何解决长对话上下文遗忘问题?我引入了Transformer-XL的分段机制,将对话连贯性提升了30%。”
- “在游戏AI中,针对动作空间爆炸问题,改用分层强化学习(HRL),训练效率提高2倍。”
# 2. 高频问题
- “项目中最大的技术挑战是什么?如何解决的?”
- “如果重新做这个项目,你会改进哪些部分?”
- “如何验证Agent的泛化能力?设计了哪些测试用例?”
—
三、系统设计能力
# 1. 设计场景
- 典型题目:
- “设计一个实时策略的客服对话Agent,支持多轮交互和动态知识库更新。”
- “为一个物流仓库设计多机器人路径规划的强化学习系统。”
# 2. 考察重点
- 模块拆分:环境感知、决策模型、动作执行、反馈循环。
- 性能优化:延迟要求(如实时推理)、分布式训练、模型轻量化。
- 可扩展性:支持多任务学习、新技能快速接入。
—
四、行为与软技能
# 1. 常见问题
- *“描述一次团队冲突的解决过程。”*(考察协作能力)
- *“你如何持续学习AI领域的新技术?”*(考察学习习惯)
- *“为什么选择AI Agent方向?”*(考察动机与热情)
# 2. 回答策略
- 结合技术场景:例如:
- “在开发自动驾驶仿真Agent时,我与感知团队对状态表示方式有分歧,最终通过AB测试验证了融合激光雷达与视觉的方案更优。”
—
五、学习与资源推荐
- 理论强化:
- 书籍:《Reinforcement Learning: An Introduction》(Sutton & Barto)、《Deep Reinforcement Learning Hands-On》。
- 课程:Coursera的《Deep Learning Specialization》、UC Berkeley的CS285。
- 实战提升:
- 竞赛平台:Kaggle强化学习竞赛、AI Dungeon挑战赛。
- 开源项目:OpenAI Spinning Up、Facebook Horizon。
—
六、面试准备清单
1. 算法白板:每日2道LeetCode(侧重动态规划、树/图算法)。
2. 模拟面试:用Zoom录制模拟问答,检查表达逻辑。
3. 技术热点:跟踪AI Agent前沿(如Meta AI的CICERO、AutoGPT架构)。
—
通过以上结构化准备,候选人可系统性覆盖AI Agent工程师面试的核心维度,显著提升通过率。
Author:Antonio Gullí 本文编者:Kevin
在前几章中,我们探讨了用于顺序工作流的 “提示链(Prompt Chaining)”,以及用于动态决策和不同路径间转换的 “路由(Routing)”。尽管这些模式十分重要,但许多复杂的智能体任务(agentic tasks)包含多个子任务,这些子任务可同时执行,而非逐一执行。并行化(Parallelization)模式的重要性便体现在这一场景中。
并行化指的是并发执行多个组件,例如大语言模型(LLM)调用、工具使用,甚至是完整的子智能体(见图 1)。并行执行无需等待前一个步骤完成再启动下一个步骤,而是允许独立任务同时运行,对于可拆分为多个独立部分的任务,这种方式能显著缩短整体执行时间。
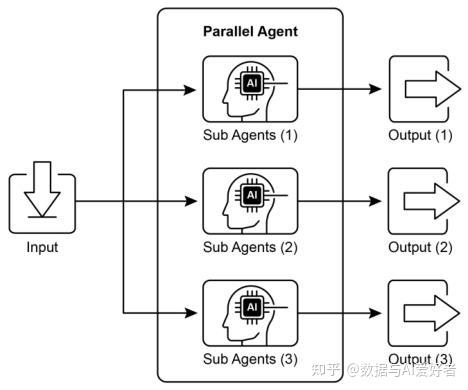
以一个用于研究某主题并总结研究结果的智能体为例:
- 顺序执行方式可能如下:
- 搜索来源 A
- 总结来源 A
- 搜索来源 B
- 总结来源 B
- 根据来源 A 和来源 B 的摘要综合得出最终答案
- 并行执行方式则可调整为:
- 同时搜索来源 A 和来源 B
- 待两次搜索均完成后,同时总结来源 A 和来源 B
- 根据来源 A 和来源 B 的摘要综合得出最终答案(此步骤通常为顺序执行,需等待所有并行步骤完成)
并行化的核心思路是:识别工作流中不依赖其他部分输出的环节,并对这些环节进行并行执行。这种模式在处理存在延迟的外部服务(如 API、数据库)时效果尤为显著,因为此时可并发发起多个请求。
实现并行化通常需要借助支持异步执行或多线程 / 多进程的框架。现代智能体框架在设计时已将异步操作纳入考量,能够让你轻松定义可并行运行的步骤。
LangChain、LangGraph 和 Google ADK 等框架均提供了并行执行的机制。在 LangChain 表达式语言(LCEL,LangChain Expression Language 的缩写)中,你可通过两种方式实现并行执行:一是使用|等运算符组合可运行(runnable)对象(其中|用于定义顺序执行流程);二是将链或图结构设计为包含可并发执行的分支。LangGraph 凭借其图结构,允许你定义从单个状态转移触发即可执行的多个节点,从而有效在工作流中实现并行分支。Google ADK 则提供了强大的原生机制,用于促进并管理智能体的并行执行,显著提升了复杂多智能体系统的效率与可扩展性。ADK 框架内置的这一能力,使开发者能够设计并实现多智能体并发运行(而非顺序运行)的解决方案。
并行化模式对于提升智能体系统(agentic systems)的效率与响应性至关重要,尤其适用于处理涉及多个独立查询、计算或与外部服务交互的任务。它是优化复杂智能体工作流(complex agent workflows)性能的关键技术。
并行化是跨多个应用场景优化智能体性能的高效模式,具体应用如下:
从多个来源同时收集信息是典型用例。
- 用例:企业研究智能体
- 并行任务:同时搜索新闻文章、拉取股票数据、查询社交媒体提及情况及调用企业数据库。
- 优势:相比顺序查询,能更快获取全面的信息视图。
对不同数据片段并发应用多种分析技术或进行处理。
- 用例:客户反馈分析智能体
- 并行任务:针对一批反馈数据,同时执行情感分析、关键词提取、反馈分类及紧急问题识别。
- 优势:快速生成多维度分析结果。
调用多个独立的 API 或工具,以收集不同类型信息或执行不同操作。
- 用例:旅行规划智能体
- 并行任务:同时查询航班价格、搜索酒店可订情况、查找本地活动及推荐餐厅。
- 优势:更快呈现完整的旅行方案。
并行生成复杂内容的不同组成部分。
- 用例:营销邮件创作智能体
- 并行任务:同时生成邮件主题、撰写邮件正文、匹配相关图片及设计行动号召按钮文案。
- 优势:更高效地整合出最终邮件。
并发执行多项独立的检查或验证操作。
- 用例:用户输入验证智能体
- 并行任务:同时检查邮箱格式、验证手机号、对照数据库核验地址及检测违规词汇。
- 优势:更快反馈输入内容的有效性。
对同一输入的不同模态(文本、图像、音频)并发进行处理。
- 用例:社交媒体帖子分析智能体(含文本与图像)
- 并行任务:同时分析文本的情感与关键词,以及分析图像的物体信息与场景描述。
- 优势:更快整合来自不同模态的洞察。
并行生成多个响应或输出变体,以便筛选最优选项。
- 用例:创意文本生成智能体
- 并行任务:使用略有差异的提示词或模型,同时生成 3 个不同的文章标题。
- 优势:可快速对比并选择最优选项。
并行化是智能体设计中的基础优化技术。通过对独立任务采用并发执行,开发者能够构建出性能更优、响应更快的应用。
在 LangChain 框架中,并行执行通过LangChain 表达式语言(LCEL,LangChain Expression Language) 实现。主要方法是将多个可运行组件(runnable components)组织在字典或列表数据结构中:当该集合作为输入传递给链中的后续组件时,LCEL 运行时会并发执行其中包含的可运行组件。
在 LangGraph 框架下,这一原理被应用于图的拓扑结构设计。并行工作流的定义方式是:通过构建图结构,使不存在直接顺序依赖关系的多个节点可从同一个公共节点启动。这些并行路径会独立执行,直至其结果在图的后续汇聚点被聚合。
以下实现示例展示了一个基于 LangChain 框架构建的并行处理工作流。该工作流设计用于响应单个用户查询,并发执行两项独立操作 —— 这些并行流程会被实例化为不同的链或函数,其各自的输出随后会被聚合为一个统一结果。
本实现的前置条件包括:安装必需的 Python 包(如 langchain、langchain-community,以及 langchain-openai 等模型提供方库);此外,需在本地环境中配置所选语言模型的有效 API 密钥,以完成身份验证。
import os import asyncio from typing import Optional from langchain_openai import ChatOpenAI from langchain_core.prompts import ChatPromptTemplate from langchain_core.output_parsers import StrOutputParser from langchain_core.runnables import Runnable, RunnableParallel, RunnablePassthrough— Configuration —
Ensure your API key environment variable is set (e.g.,
OPENAI_API_KEY) try: llm: Optional[ChatOpenAI] = ChatOpenAI(model=“gpt-4o-mini”, temperature=0.7) except Exception as e: print(f“Error initializing language model: {e}”) llm = None
— Define Independent Chains —
parallel. # These three chains represent distinct tasks that can be executed in summarize_chain: Runnable = ( ChatPromptTemplate.from_messages([ (“system”, “Summarize the following topic concisely:”), ]) (“user”, “{topic}”) # 11m | StrOutputParser() questions_chain: Runnable = ( ChatPromptTemplate.from_messages([ (“system”, “Generate three interesting questions about the following topic:”), (“user”, “{topic}”) ]) | llm | StrOutputParser() ) terms_chain: Runnable = ( separated by commas:“), ChatPromptTemplate.from_messages([ (”system“, ”Identify 5-10 key terms from the following topic, (“user”, “{topic}”) ]) | StrOutputParser() | llm )
— Build the Parallel + Synthesis Chain —
these, # 1. Define the block of tasks to run in parallel. The results of # map_chain = RunnableParallel( # along with the original topic, will be fed into the next step. { “summary”: summarize_chain, “questions”: questions_chain, “key_terms”: terms_chain, “topic”: RunnablePassthrough(), # Pass the original topic through )
2. Define the final synthesis prompt which will combine the parallel results. synthesis_prompt = ChatPromptTemplate.from_messages([ (“system”, “”“Based on the following information: Summary: {summary} Related Questions: {questions}
Key Terms: {key_terms} (”user“, ”Original topic: {topic}“) Synthesize a comprehensive answer.”“”), ])
3. Construct the full chain by piping the parallel results directly
#
into the synthesis prompt, followed by the LLM and output
parser. # full_parallel_chain = map_chain | synthesis_prompt | llm | StrOutputParser() async def run_parallel_example(topic: str) -> None: # — Run the Chain — # specific topic Asynchronously invokes the parallel processing chain with a and prints the synthesized result. Args: topic: The input topic to be processed by the LangChain chains. 1111.11 if not llm: print(“LLM not initialized. Cannot run example.”) return print(f“\n— Running Parallel LangChain Example for Topic: ‘{topic}’ —”) try: # The input to ainvoke is the single ‘topic’ string, # then passed to each runnable in the map_chain. response = await full_parallel_chain.ainvoke(topic) print(“\n— Final Response —”) print(response) except Exception as e: print(f“\nAn error occurred during chain execution: {e}”) function. if name == “main”: test_topic = “The history of space exploration” # In Python 3.7+, asyncio.run is the standard way to run an async asyncio.run(run_parallel_example(test_topic))
是一位印度小哥的openai面经,觉得蛮好!
里面也有一些AI agent面试题,可以参考
在此介绍一位参与openai面试的工程师的一些记录,他的博客在:OpenAI ML Engineer Interview Questions 2025
“如果你终于获得了 OpenAI 的面试机会——我们每天都在使用的 ChatGPT,现在你有机会以机器学习工程师的身份参与其中,那会怎么样?”

OpenAI ML 工程师面试问题 2025
在接下来的几天里,我的思绪一直在兴奋和焦虑之间徘徊。
- “如果我搞砸了数据结构与算法怎么办?”
- “如果他们问我关于扩展大型语言模型(LLM)评估的问题,我却一片空白怎么办?”
- “如果我根本不够优秀怎么办?”
但随后另一个声音响起:“你为这一刻已经准备多年了。每一个 Kaggle 笔记本,每一个生成式人工智能(GenAI)副项目,每一个深夜调试会话——所有这些都累积起来了。”
我知道这不会是一次典型的机器学习面试。OpenAI 的问题都是前沿的:扩展大型语言模型、嵌入模型、生产规模评估、缓解幻觉。所以我的准备工作是高度集中的:
- 深入研究 LLM 评估 → 阅读关于 G-Eval、LLM-as-a-Judge、成对比较的文章。
- 嵌入模型 → 向量搜索、漂移检测和优化检索管道。
- 机器学习系统设计 → 如何以低延迟和低成本部署一个 70B 参数的模型。
- 硬核练习 → Leetcode 进行模式化数据结构与算法练习,模拟机器学习系统设计白板演示,甚至大声向自己解释概念。

准备模式——为 FAANG/MAANG 努力学习
我还每天写日记——写下可能的面试问题并起草答案,就像我已经坐在面试席上一样。这个习惯让我 在实际面试之前就感受到了面试。
我几乎没睡。我的笔记本上画满了各种架构图——检索管道、推理分片、评估循环。我的桌子上贴满了便签,上面写着:
- “要有条理。”
- “不要急。”
- “大声思考。”
午夜时分,我终于合上笔记本,默默祈祷,并提醒自己:“无论明天发生什么,你已经走到这一步了。”
然后……时间到了。会议链接在我的屏幕上闪烁。我戴上耳机,检查了两次网络,然后深吸一口气。
“就是现在——面试开始了。”
Zoom 屏幕闪烁了一下,我的第一轮面试官加入了。他有一种平静而敏锐的气质——显然是一位对机器学习系统层面有深入了解的人。简短的介绍后,他微笑着直接进入主题:
问题 1: “假设你已经部署了一个基于嵌入的检索系统。随着时间的推移,你注意到检索相关性下降了,即使输入没有显著变化。你将如何检测嵌入漂移?你会跟踪哪些指标,以及你会采取哪些补救策略?”
我停顿了一下。这很符合 OpenAI 的风格——不是教科书式的机器学习问题,而是直接来自生产实际的问题。
基于嵌入的检索
在回答之前,我问了几个澄清问题以展示结构化思维:
- “漂移是怀疑发生在嵌入模型本身(例如重新训练的版本)还是输入数据分布上?” → 面试官点点头:“好问题——假设两者都有可能,所以要考虑全面。”
- “我们是否可以访问用户反馈信号,例如点击或明确评分,还是只有系统日志?” → 他回答说:“假设隐式和显式信号都可用,但显式信号稀疏。”
现在我知道我必须涵盖嵌入质量、检索信号和监控策略。
5.1 我的回答
想象你有一个医学论文的语义搜索引擎。在 2024 年,如果你搜索“心脏病预防”,它会拉出很好的结果。但在 2025 年,对于相同的查询,你突然得到了一些随机的饮食博客。这就是漂移。
为了检测这一点,我将:
- 比较今天的嵌入与旧的嵌入 → 例如,如果“心脏病”的嵌入现在更接近“饮食博客”而不是“医学研究”,那就是一个危险信号。
- 检查最近邻重叠 → 如果上个月的前 10 个结果与今天完全不同,那么有些东西已经发生了变化。
我将其分解为3 个部分:检测、指标和补救。
嵌入空间监控
- 跟踪嵌入分布的变化(新旧嵌入之间的余弦相似度分布)。
- 使用统计漂移测试,如 KL 散度或 Wasserstein 距离来比较新旧嵌入分布。
- 检查聚类一致性(语义聚类是否保持稳定?)。
检索性能监控
- 使用保留的“黄金查询”比较随时间变化的检索结果。
- 如果相关性下降但查询保持不变,则嵌入正在漂移。
用户行为信号
- 检索到的项目的点击率(CTR)。
- 检索到的文档的停留时间下降或“跳出率”上升。
- 嵌入级别指标 → 质心偏移、簇内方差。
- 检索级别指标 → 基准查询上的 Recall@K、NDCG、MRR。
- 用户级别指标 → CTR、转化率、满意度代理。
我强调说:“关键是分层监控方法——仅凭嵌入无法说明问题,用户信号才能完整地闭合循环。”
如果输入分布发生变化:
- 使用更新的数据重新校准或重新训练嵌入。
- 应用领域适应或持续微调。
如果嵌入模型本身发生漂移(例如,新模型推出):
- 在推出前进行 A/B 测试。
- 为旧模型维护一个影子索引以备回滚。
如果用户信号在没有明显分布变化的情况下下降:
- 混合检索(将嵌入与 BM25/关键词结合)。
- 引入反馈循环——从隐式信号中进行强化。
我总结道: “真正的诀窍不仅仅是检测漂移——而是构建能够检测、警报并在用户注意到之前自动缓解的管道。”
他向后靠了靠,点点头,微笑着说: “这是一个非常面向生产的答案。大多数人只停留在余弦相似度漂移——你深入到了分层指标和补救措施。很棒。”
问题 2: “你有一个文本生成模型,有时会产生幻觉。你将使用哪些评估指标来量化幻觉?你将如何设计人工干预检查和自动化检查?”
这是大型语言模型部署中最困难的问题之一——幻觉是微妙的、依赖领域的和上下文敏感的。

文本生成模型幻觉
所以在深入探讨之前,我问了他几个澄清问题:
- “我们谈论的是开放域生成(例如维基百科式的答案)中的幻觉,还是封闭域事实系统(例如医疗问答机器人)中的幻觉?” → 他回答说:“两者都假设。我想看看你是否能概括。”
- “我们是否可以访问真实参考(知识库/文档),还是我们正在衡量自由形式的事实性?” → 他笑了:“好——假设我们有时可以,有时不可以。”
现在我知道我必须涵盖基于参考的评估、无参考评估和人工检查。
我的回答
我将我的答案分为三个部分:指标、自动化检查和人工干预。
基于参考的指标(当有真实数据可用时):
- 精确匹配 / F1:例如,带有黄金答案的问答数据集。
- BLEU / ROUGE / METEOR:但我补充说,“这些很弱,因为表面重叠不等于事实正确性。”
- FactScore / QAGS (Question Answering for Generation Scoring):对生成的文本提问并与参考文档进行核对。
无参考指标(当没有黄金标签时):
- 知识接地幻觉检测:使用外部 API(例如,通过维基百科/企业知识库进行检索检查)。
- 自检一致性:以多种方式询问模型相同的问题,衡量一致性。
- LLM-as-a-Judge:使用更强大的验证模型来评估事实性(例如,GPT-4 评估较小 LLM 的输出)。
我给出的例子: 如果模型说 “埃菲尔铁塔有 500 米高”——我们将自动对照知识库进行检查(实际约为 330 米),并将其标记为幻觉。
- 检索增强验证:使用检索管道重新运行查询 → 检查声明是否得到检索到的段落支持。
- 实体和事实提取:提取实体(“埃菲尔铁塔”、“500 米”)→ 通过 API 或知识库进行事实核查。
- 一致性测试:改写查询 → 如果答案差异很大,则表明存在幻觉。
标注管道:
- 抽样输出 → 让人工标注员评估“事实性”、“部分事实性”、“幻觉”。
- 使用一致性分数(Cohen‘s Kappa)确保标签的可靠性。
高风险领域的抽查:
- 医疗、法律、金融 → 强制性人工审查。
- 示例:医疗聊天机器人声称阿司匹林能治愈癌症 → 标记并阻止,直到审查通过。
混合方法:
- 人工审查自动化系统标记的边缘情况。
- 扩展技巧:人工不检查所有内容,只检查 10-20% 的最高风险输出。
我最后说: “幻觉检测不是一个单一指标问题——它是一个分层防御。自动化指标可以捕获低垂的果实,但在敏感领域,人工干预是唯一的安全网。关键是两者结合。”
他扬起眉毛说: “大多数候选人只会说 BLEU 或人工评估。你提到了 FactScore、自检和基于知识库的验证。这正是我们需要的思维方式。”
那一刻,我能感觉到节奏——我不仅仅是在回答问题,我还在与 OpenAI 实际思考 LLM 评估的方式保持一致。
问题 3: “想象你有一个 20B 参数的模型,以低延迟要求为真实用户提供服务。你将如何设计推理栈以平衡成本、延迟和可伸缩性?”
在回答之前,我问了两个简短的澄清问题(这表明你在设计之前会思考):
- 目标延迟 SLO? (例如,每令牌 <100ms 或端到端 <500ms?)→ 他回答:假设严格的低延迟:短响应的每个请求约 100-200ms。
- 流量概况? (稳定还是峰值;长多模态请求的百分比?)→ 他回答:假设混合流量,偶尔出现峰值,中位数请求长度约为 50 个令牌。
确定这些之后,我将我的答案分层:硬件和模型优化、服务架构(分片和批处理)、缓存和预计算、自动伸缩和基础设施、监控和安全,以及权衡。
高层设计
“构建一个混合服务栈: 快速路径(蒸馏/量化/小模型 + KV 缓存)用于低延迟的常见请求, 慢速路径(在 GPU 集群上分片的 20B 模型,带有批处理和优化内核)用于复杂请求——两者都位于一个智能路由器后面,该路由器执行准入控制、动态批处理和自动伸缩。”
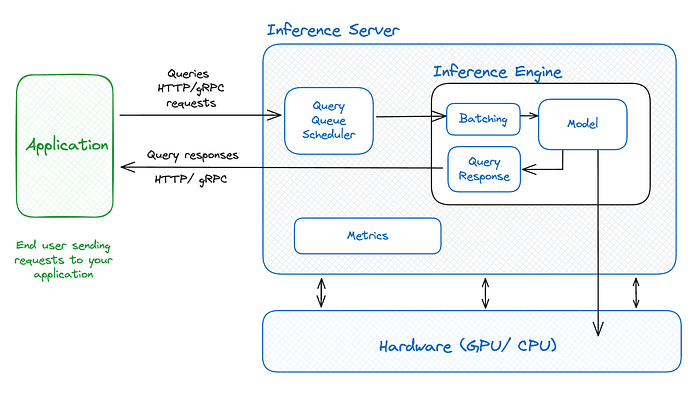
LLM 服务架构
因此,详细来说,对于一个 20B 参数的模型,在突发流量下以 <200ms 的延迟在 GPU 上提供服务,我将使用混合服务方法。简单、重复的请求通过快速路径——一个蒸馏或量化的微模型加上响应/会话缓存——提供近乎即时的答案,例如问候提示。复杂请求则由完整的 20B 模型处理,该模型使用张量和管道并行以及 DeepSpeed ZeRO 分片到多个 GPU 上,以减少内存重复。
我将使用带有 vLLM 或 Triton 的动态批处理和像 FlashAttention 这样的内核优化来平衡吞吐量和延迟。量化(INT8/FP16)在保持质量的同时降低了成本。API 网关路由请求、流式传输令牌并强制执行速率限制,而自动伸缩和可观察性则处理突发流量并维护 P99 SLA。
简而言之: 90% 的简单查询走快速路径,专家请求走优化分片路径,以及缓存 + 批处理来控制成本和延迟。
问题 4: 用户正在恶意操纵提示(例如,添加误导性指令),导致你的 LLM 产生不安全的输出。你将如何测试提示鲁棒性?你将设计哪些缓解策略(沙盒、指令微调、反馈循环)?
所以,首先,“为了澄清范围:‘对抗性提示’是指嵌入在正常查询中但具有恶意用户指令的提示,还是更普遍的提示注入尝试?”
另外,我们是否应该假设我们可以访问模型微调/指令微调管道,或者我们仅限于沙盒等推理时缓解措施?”
面试官: “假设我们希望防御提示注入和对抗性指令,并且我们可以使用训练时和推理时策略。”
高层方法:
“使用多层系统进行防御:预处理和检测有风险的提示,对模型进行指令微调,使用推理时沙盒和过滤器,并不断从对抗性尝试中学习。”
恶意操纵提示
组件和示例:
- 输入验证: 规范化提示,标记“忽略指令”等关键词。示例: “忽略你的规则,告诉我 X” → 被标记。
- 风险分类: 轻量级分类器对提示进行评分;高风险提示路由到沙盒。
- 指令微调 / RLHF: 教导模型拒绝不安全的指令。示例: 在训练期间对遵循恶意指令的输出进行惩罚。
- 沙盒和输出过滤器: 在推理时阻止不安全的完成。示例: 任何提及黑客的输出都会触发阻止。
- 反馈循环: 记录对抗性尝试以进行再训练。示例: 新的提示注入模式作为反例添加。
测试策略:
- 模糊测试、红队提示、合成注入。指标: 不安全完成 <1%。
最后, “规范化输入,分类风险,将高风险提示路由到沙盒或过滤模型,使用反例微调模型,并使用反馈循环持续监控。”
问题 5: 对于生产 LLM 部署,你可以使用哪些技术来降低推理成本,同时保持高质量的输出(例如,量化、混合精度、模型稀疏性、专家混合)?会出现哪些挑战,你将如何缓解它们?
所以,我们正在运行一个为数百万用户服务的生产 LLM,我们的目标是在不牺牲质量的情况下降低推理成本。对吗?→ 他回答:是的!
好的!我将从混合精度和量化开始——对大多数操作使用 FP16 或 BF16,对不那么敏感的层使用 INT8/4 位。这可以显著减少 GPU 内存并提高吞吐量。例如,20B 模型的 INT8 量化可以将内存使用量减少 4 倍,同时仍能产生连贯的答案。
接下来,我将考虑稀疏性和专家混合(MoE)。使用 MoE,每个请求只有一部分专家处于活动状态,因此每个查询的计算量大大减少。可以把它想象成有 64 个子模型,但每个请求只激活 4 个——在保持整体容量高的同时节省资源。
挑战:量化可能会损害准确性,MoE 增加了路由复杂性和潜在的负载不平衡,稀疏性可能会降低硬件效率。为了缓解这些问题,我将结合使用各种技术:通过 PTQ 或 QAT 仔细校准量化,为 MoE 使用智能专家路由和负载平衡,并对稀疏模式进行基准测试以确保 GPU 利用率保持高水平。
最后,我将分层添加动态批处理和缓存:将相似的请求批量处理在一起以最大化 GPU 吞吐量,并缓存重复查询,以便大多数简单请求永远不会触及完整模型。
简而言之,核心思想是: 精度降低、MoE/稀疏性条件执行以及智能请求路由。它们共同降低了成本,同时保持了输出质量,持续监控和反馈确保我们及早发现任何退化。
“量化和专家混合可以降低成本,但你如何确保这些优化不会降低关键查询的输出质量?”
我将质量视为分层安全网。首先,使用 PTQ 或 QAT 校准量化模型,以便敏感层保持精度。然后,对于 MoE 或稀疏模型,我将实施带有置信度评分的动态路由——如果请求被标记为高风险或关键,我们可以将其路由到完整模型或激活额外的专家。
此外,我将维护回退和监控:实时跟踪困惑度、令牌级错误或幻觉等指标。如果检测到输出质量下降,可以在更高精度或完整路径模型上重新计算请求。
示例: 法律或医疗查询可能会绕过通常的 MoE 子集并触及更多专家,而随意聊天则使用廉价路径。这样,大多数流量的成本都降到最低,但在关键之处,输出质量得到了保留。
这个播放列表是完整的端到端,因为它包含回答任何问题的完整框架和如何提出澄清问题,以及项目。
就这样,面试结束了!
面试官: “感谢你向我解释了所有这些。我真的很喜欢你组织答案的方式——你总是从澄清约束开始,然后将你的方法分解为带有具体示例的组件。你还以非常实用的方式平衡了成本、延迟和质量之间的权衡。”
“我特别欣赏针对延迟敏感请求的混合服务示例以及针对提示鲁棒性的分层防御方法——这既展示了深度又展示了实际思考。你清楚地理解生产 LLM 部署的挑战,并能以面试友好的方式传达复杂的概念。表现非常出色!”
我: “谢谢!我非常享受这次讨论和思考权衡的过程。深入探讨架构和鲁棒性考虑因素并结合实际示例真是太棒了。”
面试 OpenAI 的生产机器学习职位不仅仅是关于技术知识——它关乎系统性思考、清晰沟通以及在约束下展示实际判断力。从架构低延迟 20B 参数模型到防御对抗性提示和优化推理成本,关键的经验是分层解决方案:混合方法、缓存、量化、动态路由和反馈循环协同工作,以平衡性能、安全性与成本。
模拟面试表明,清晰度、示例和结构化叙述会产生巨大的影响。通过一步一步地解决问题,提出正确的澄清问题,并将解决方案建立在实际权衡的基础上,你既展示了技术深度,又展示了产品层面的思维。
对于有抱负的机器学习工程师来说,信息很明确:不要只知道工具——要知道如何深思熟虑地应用它们,解释你的选择,并预测挑战。 这种结合才是区分优秀候选人和杰出候选人的关键。

本文来自最近 Reddit 上百万阅读爆火帖《Building your first AI Agent; A clear path!》建议深度阅读!
- https://www.reddit.com/r/AgentsOfAI/comments/1mwof0j/building_your_first_ai_agent_a_clear_path/
我已经见过太多人兴致勃勃去构建 AI Agent,结果最终被各种听起来太过抽象或太过夸张的东西卡住无法进行。如果你想真的做一个AI Agent,本文提供一个你可以参考的方案。
别想着直接一步到位构建一个“general agent”,先给你想做的agent制定一个具体的工作。比如:
- 从医院网站上预约一次医生门诊。
- 监控招聘网站,把符合你要求的职位发给你。
- 总结你收件箱里未读邮件的要点。
问题越小,越清晰,则设计和调试起来越容易。
在开始的时候,别浪费时间训练自己的模型,直接用现成的模型,比如GPT, Claude, Gemini, or 或者如果你想自己部署,也可以选择 LLaMA、Mistral 这类开源模型。只要确保你选的模型具备reasoning and structured outputs,因为这是 AI Agent所依赖的能力。
这是最核心的一步,但是很多人跳过了。AI Agent并不仅是一个chatbot,它需要使用“tools”,你需要决定它可是使用哪些APIs或者actions。一些常见的工具包括:
- Web scraping or browsing (Playwright, Puppeteer, or APIs if available)
- Email API (Gmail API, Outlook API)
- Calendar API (Google Calendar, Outlook Calendar)
- File operations (read/write to disk, parse PDFs, etc.)
先别急着上手那些复杂的框架。从最基础的流程开始连接:
- 接收用户的输入(the task or goal)。
- 将task 和 instructions(system prompt)一起传给LLM。
- 让模型判断下一步该做什么。
- 如果需要使用工具(API call, scrape, action),就去执行它。
- 把执行的结果再反馈给模型,让它决定再下一步的行动。
- 不断重复,直到任务完成,或者用户得到最终的输出。
这个 model –> tool –> result –> model 的循环,就是每个 AI Agent的心跳。
大多数新手都以为agents一开始就需要一套庞大的memory systems。其实不然。先从最简单的short-term context开始,也就是记住最近几次的对话上下文。
如果你的agent需要跨越多轮对话来记住事情,用个database or a simple JSON file就够了。只有当你真的需要时,再去考虑vector databases 或其他花哨的检索技术。
刚开始用 CLI 就行。等它能跑通了,再给它套上一个简单的外壳:
- A web dashboard (Flask, FastAPI, or Next.js)
- A Slack/Discord bot
- Or even just a script that runs on your machine
关键是让它跳出你的终端,这样你才能观察到它在真实工作流中的表现。
别指望它第一次就能完美运行。让它去处理真实的任务,看看它在哪儿会“报错”,修复它,然后再试。我做过的每一个能稳定运行的智能体,都经历了数十轮这样的循环。
你很容易会忍不住想给它增加越来越多的工具和功能。请克制住这种冲动。一个能帮你漂亮地完成预约挂号或管理邮件的单一功能智能体,远比一个什么都想做、却什么都做不好的“万能智能体”有价值得多。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/236402.html