
马年春晚千问火出圈,大模型小白也想在本地部署一个尝尝鲜。正好千问发布了具有颠覆架构的Qwen3.5大模型的4个端侧小模型版本,而有了轻量级推理引擎llama.cpp后,本地化部署比去年可简单多了,几乎不需要怎么配置,安排!
这4款小模型即0.8B、2B、4B 和 9B,也就是说,这4款模型的参数为8亿到90亿。千问3.5采用全新的混合注意力架构后,整体性能有了非常大的提升,4B和9B的跑分达到了传统模型20B到80B的水平,非常具有性价比。
而且全系原生支持视觉模态,每一款都具备图文理解能力,这在端侧小模型中相当罕见。此外,它们还延续了统一的视觉-语言基础(Vision-Language Foundation)以及原生支持 256K 超长上下文的特性,全系搭载了以 DeltaNet 为核心的混合注意力(Hybrid Attention)架构。非常适合端侧部署,正好搭配现在正火的OpenClaw使用(另文说明)。
一,模型规格与架构对比
这四款模型虽然使用了完全相同的 Qwen3_5 For Conditional Generation 架构,主要在层数和隐藏维度上做了不同程度的缩放。
核心参数速览
配置项
Qwen3.5-0.8B
Qwen3.5-2B
Qwen3.5-4B
Qwen3.5-9B
层数
24
24
32
32
隐藏层维度
1024
2048
2560
4096
视觉层数
12
24
24
27
视觉隐维度
768
1024
1024
1152
词表大小
248,320
248,320
248,320
248,320
最大上下文
256K
256K
256K
256K
可以看到,0.8B 和 2B 系列同样是 24 层的 Transformer 架构,但 2B 版本的隐藏层维度直接翻倍,视觉层数也变得更深;而到了 4B 和 9B,模型深度扩展到了 32 层,整体表达能力上了一个新台阶。
二,模型下载
Qwen 官方发布的是 HuggingFace 格式的权重(safetensors),这种格式主要面向 GPU 推理(vLLM、SGLang、Transformers 等框架)。对于没有高端 GPU 的普通玩家来说,GGUF 格式更适合本地部署。尤其如果你是AMD显卡用户,GGUF+OPENCL模式还可以免去复杂的Rocm配置,并提供更高的运行速度。
而 Unsloth 就是目前开源社区做 GGUF 量化做得最好的团队之一,他们有一套叫 Dynamic 2.0 的量化方案——核心思路是把模型中重要的层(比如注意力层的关键权重)保留更高精度(8-bit 甚至 16-bit),不重要的层大胆压缩。这样做的好处是:4-bit 量化下的表现,几乎逼近 FP16 原始精度。
Unsloth 的Qwen模型都发布在Huggingface上,需要科学上网,可以使用国内的镜像:
GPT plus 代充 只需 145
下载Qwen3.5-9B-Q4_K_M.gguf文件,这是4-bit优化版,质量与速度兼顾,约5.3G。
而8-bit传统量化版约9G,推理速度会慢一倍
附注:GGUF量化命名规则
三,安装llama.cpp
llama.cpp是由Georgi Gerganov创建的轻量级推理引擎,它是基于C/C++语言编码实现的LLM框架,支持大模型 的训练和推理,专注于在本地硬件环境(比如个人电脑、树莓派等)上高效运行LLM模型。
llama.cpp框架目前支持的大模型有LLaMA系列、Qwen系列、Gemma系列、LLaVA系列等。
llama.cpp框架支持运行在CPU、GPU、嵌入式等设备上,对消费级硬件和资源受限的边缘计算设备支持较好。
3.1 下载预编译的llama.cpp (Windows版本)
下载页面:https://github.com/ggerganov/llama.cpp/releases
选择下载:
llama-bxxxx-bin-win-vulkan-x64.zip (带GPU电脑)
llama-bxxxx-bin-win-sycl-x64.zip (带Nvidia或Intel GPU电脑)
llama-bxxxx-bin-win-cpu-x64.zip (无GPU电脑)
链接(例如AMD显卡电脑):
https://github.com/ggml-org/llama.cpp/releases/download/b8226/llama-b8226-bin-win-vulkan-x64.zip
3.2 配置启动
解压llama.cpp到 E:AIllama.cpp
拷贝模型文件到 E:AImodels Qwen3.5-9B-Q4_K_M.gguf
在powershell或者cmd窗口里输入如下指令即可运行:
E:AIllama.cppllama-cli.exe -m E:AImodelsQwen3.5-9B-Q4_K_M.gguf
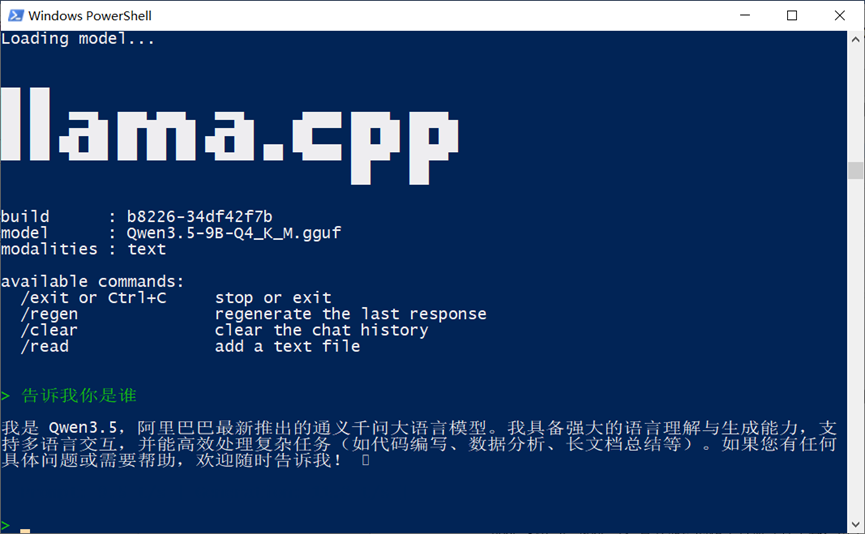
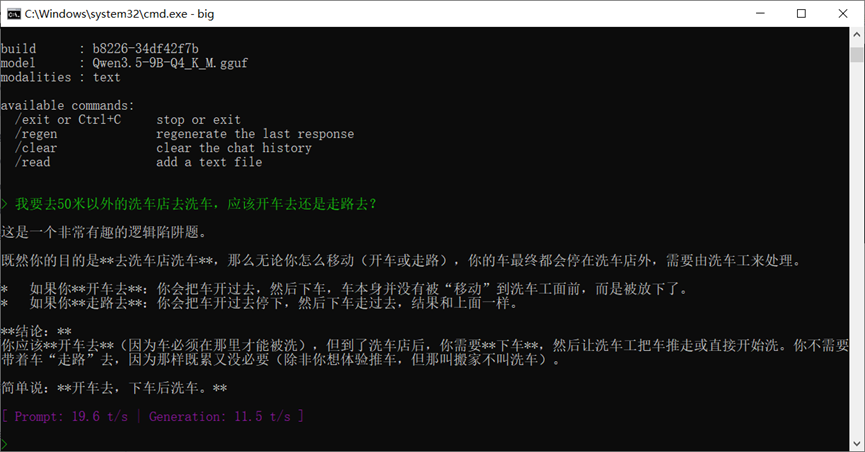
可见,模型的响应速度可以达到10-20Tokens/s,我的使用感受和普通网页版模型已经很接近了。
关键是,免费、可控,安全!
3.3 优化
每次输入指令比较麻烦,可以创建启动脚本:
大内存和8G显存 big.bat:
GPT plus 代充 只需 145
* 参数说明:^ 一行写不下时,多行当作一行指令的标识符
-ngl 999:尝试将所有层 offload 到 GPU(如果显存不够会自动降低)
16G内存和4G显存 small.bat:
Windows注册表优化(可选):
GPT plus 代充 只需 145
下一篇:
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/236100.html