
刚刚,谷歌正式揭秘最新的图像生成与编辑模型nano-banana,它就是Gemini 2.5 Flash Image,为之前原生图像模型Gemini 2.0 Flash的升级版。新模型带来了多项强大功能:可以将多张图片融合为一张;保持角色一致性,从而支持更丰富的故事表达;使用自然语言进行精准的图像变换;利用 Gemini 的世界知识进行图像生成与编辑。
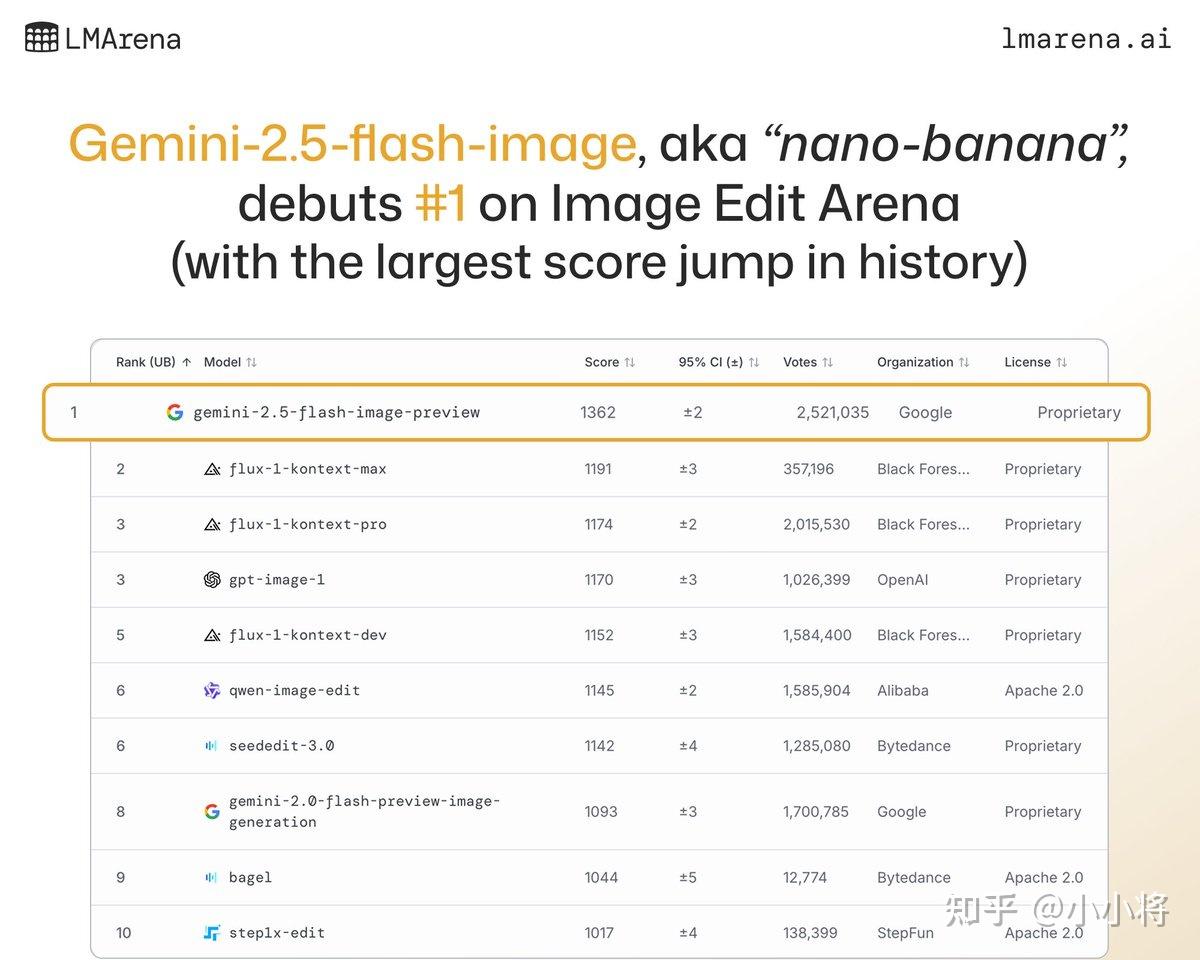
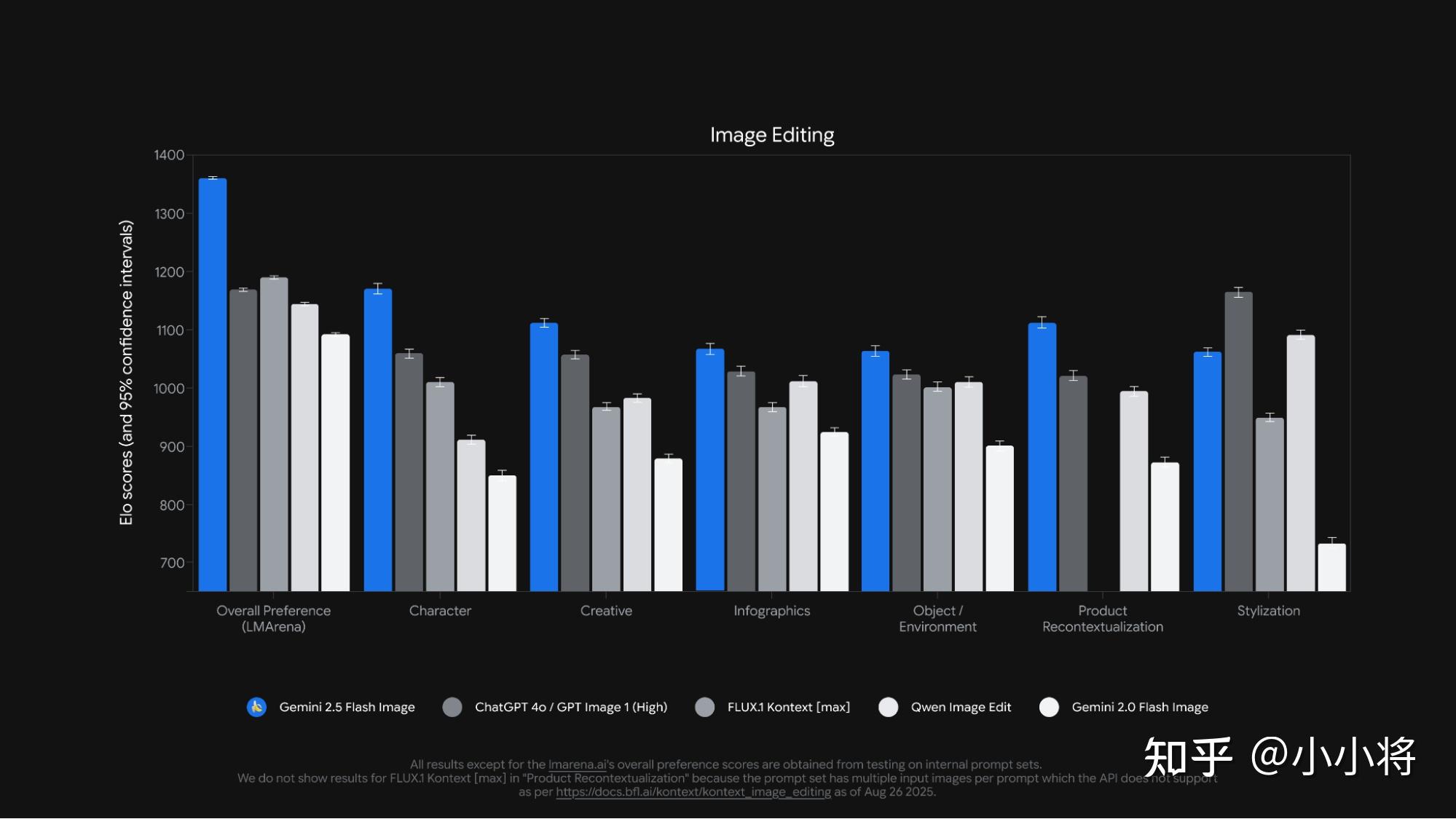
Gemini 2.5 Flash Image经过超过250万的投票,在LMArena的图像编辑排行榜上超过Flux-Kontext和GPT-Image-1,位居第一:
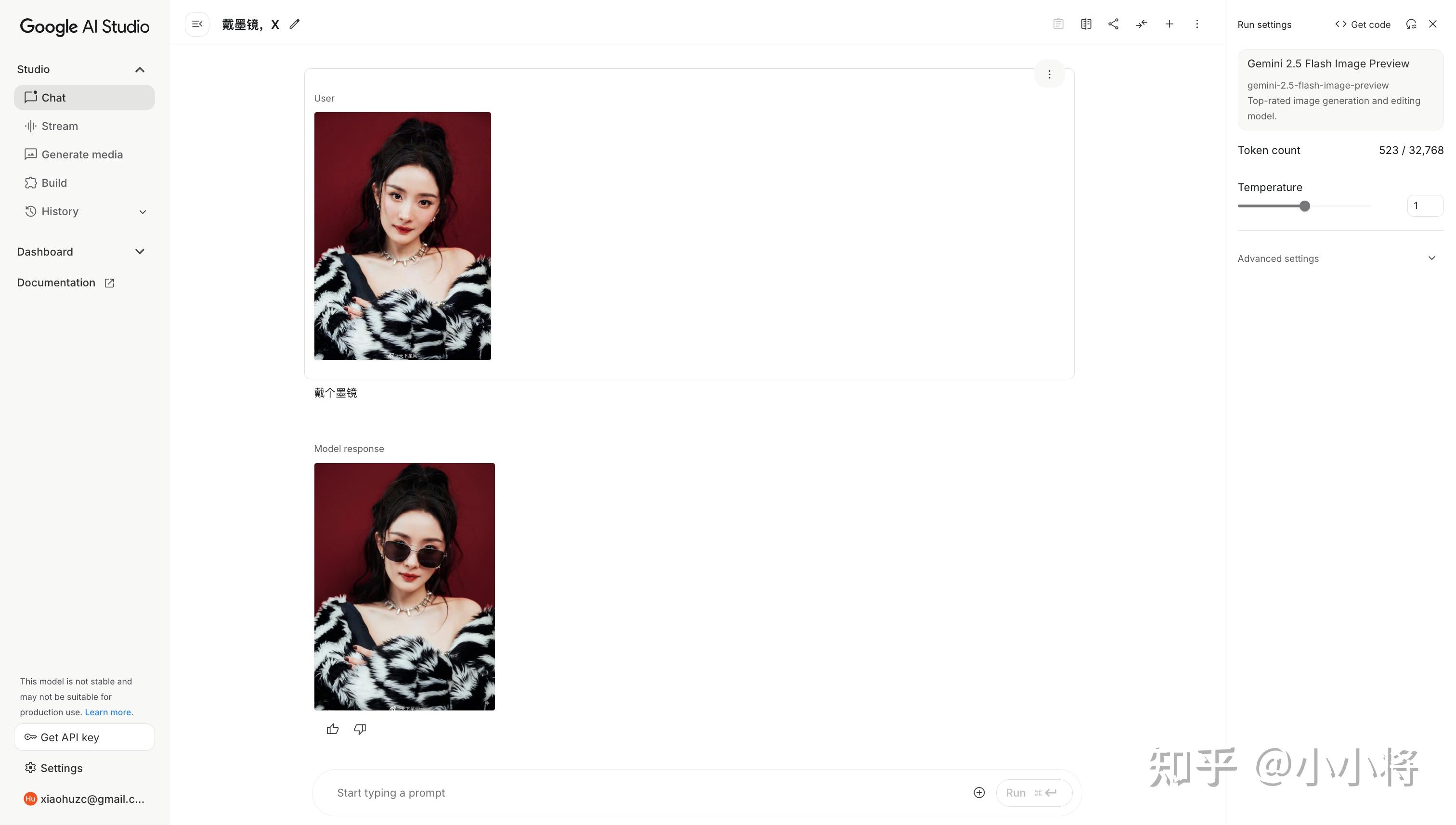
当前新模型也已经开放,在Google AI Studio 可直接使用:
而且支持API调用,Gemini 2.5 Flash Image 的API定价为 $30/百万tokens,每张图片约消耗 1290 个输出 token,即每张图片约 0.039 美元。输入与输出的其他模态则和 Gemini 2.5 Flash 的定价标准一致。

Gemini 2.5 Flash Image的主要亮点如下所示:
在图像生成中,一个核心挑战是如何在多个提示词和编辑过程中维持角色或对象的外观一致性。Gemini 2.5 Flash Image可以将同一个角色置于不同环境中;在全新场景下从多个角度展示同一产品;或生成一致的品牌素材,同时始终保持主体形象不变。



 https://www.zhihu.com/video/1943814527239033045
https://www.zhihu.com/video/1943814527239033045 除了角色一致性之外,该模型在遵循视觉模板方面同样表现出色,例如房地产房源卡片、统一的员工工牌,或是 整套商品目录的动态产品展示图。

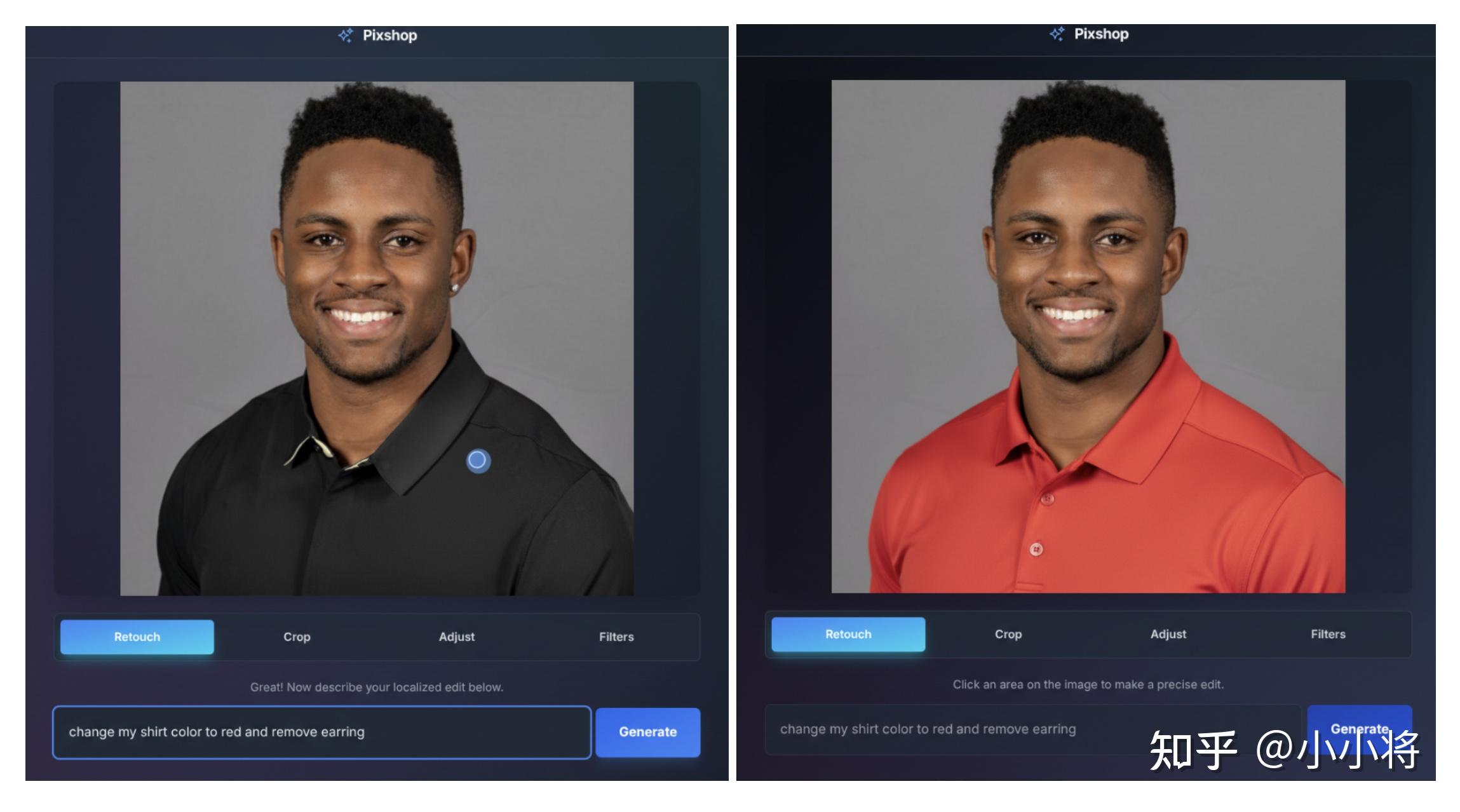
Gemini 2.5 Flash Image 支持通过自然语言实现精准定向变换与局部编辑。例如,该模型可以模糊图像背景、清除T恤上的污渍、从照片中移除整个人物、改变主体姿态、为黑白照片上色,或通过简单提示实现您能想象到的任何编辑效果。
谷歌在 AI Studio 中构建了照片编辑模板应用,同时提供用户界面和基于提示的双重控制方式。
传统图像生成模型虽擅长创作美学图像,却缺乏对现实世界的深度语义理解。Gemini 2.5 Flash Image 可以依托 Gemini 的世界知识体系来进行图像创作。比如Gemini 2.5 Flash Image 可以推理出图像中某一时刻之前或之后可能发生的情景:在生成了气球飘向仙人掌的第一张画面后,可以让它去想象接下来可能发生的场景(气球爆炸):

为验证此能力,谷歌在 Google AI Studio 中开发了模板应用,将简单画布转化为交互式教育辅导工具。该应用展示了模型在单步骤中实现多项能力:解读手绘图表、解答现实世界问题,以及执行复杂编辑指令。
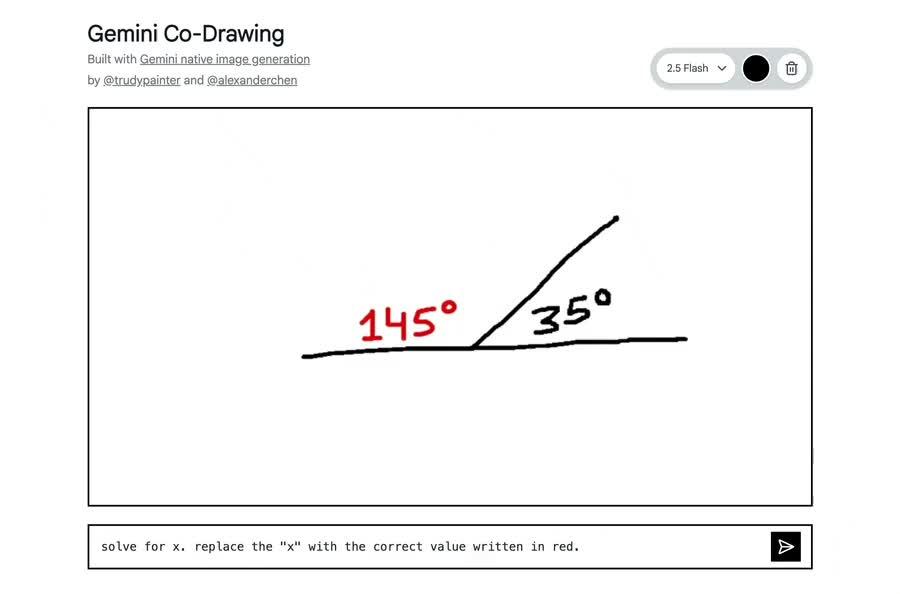 https://www.zhihu.com/video/1943814915325408280
https://www.zhihu.com/video/1943814915325408280 Gemini 2.5 Flash Image 能够理解并融合多个输入图像。只需通过单一提示,即可将物体嵌入场景、采用新配色方案或纹理重新装饰房间,并实现多图像无缝融合。


谷歌在 Google AI Studio 中构建了模板应用,支持通过拖拽产品至新场景,快速生成逼真的融合图像。
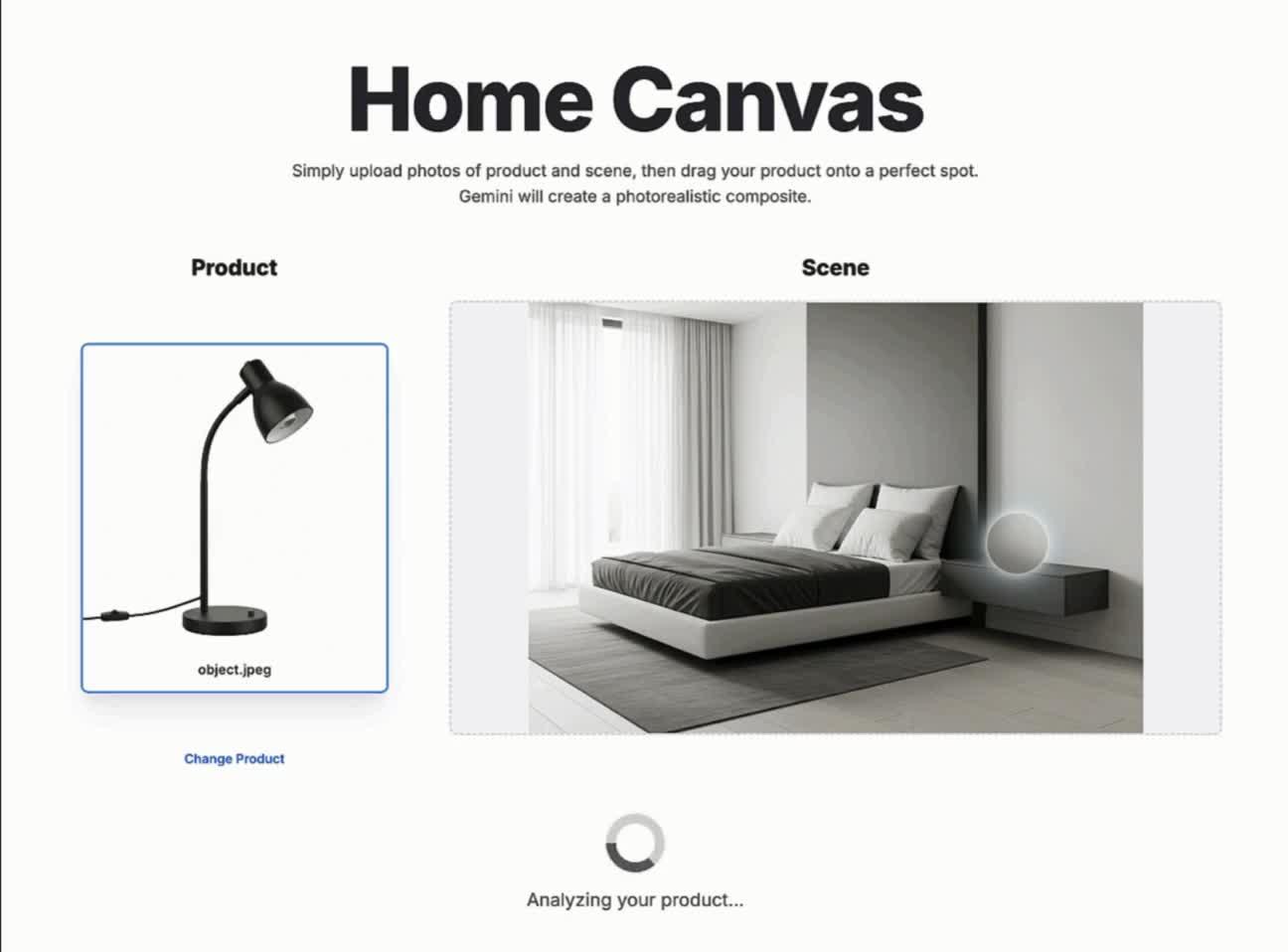 https://www.zhihu.com/video/1943815086872462422
https://www.zhihu.com/video/1943815086872462422 下面我是我在 Google AI Studio 上实测的单图编辑例子,整体一致性还可以,不过风格转换效果弱一些:


基于原生多模态的图像生成看起来才是未来!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/226440.html