
要说AI领域在2025年已经过去的两个月里最大的新闻,那必须要数Deepseek的横空出世了。如果我没记错的话,这是大模型流行起来之后,第一次有中国人自研的大模型以极低的成本和亮眼的性能震撼了世界,造成了如此巨大的影响。

除了性能的优异,Deepseek的开源策略也在民间掀起了一股本地部署潮,不管你是有超强算力的服务器集群,还是带显卡的各种PC,都可以部署不同量级的Deepseek模型。
或许有人会问,既然我上一个网站就能用到满血的Deepseek了,为啥还要跑在我自己的电脑上呢?
核心原因之一,就在于信息的保密和隐私的保护。在大模型刚刚火热的时候,就经常有因为AI泄密的新闻。企业员工保密意识不够,直接将机密信息传给在线大模型,上传之后,这些信息就进了别家公司的数据库。
更要命的是,这些信息很可能会成为大模型下一步训练的资料,被模型记录下来,之后你甚至可以直接从大模型口中问出这些信息。当时很多人就尝试询问chat GPT各家的商业机密,竟然真的有回答,虽然里面大部分是模型自己编的,但谁也没法保证里面没有真的。
上面是对公司来说的。对个人,如果你是一个小说家,想用AI来帮你拓展大纲,你就必须把你的灵感交给大模型,如果是在线的,你也没法保证你珍贵的灵感会不会被大模型吸收,然后分享给其他人。同理,不管你是什么职业,在用云端大模型做真正生产力的事情时,都会有信息泄露的担忧。更何况云端服务器还经常会遇到繁忙情况,如果在工作紧急或者灵感乍现的时候,AI却宕机无响应,真的能把人干崩溃。
除此之外,云端大模型的使用前提是有网络连接,在一些没有网络的地方,比如航班,野外等工作场景,云端大模型也是无法正常部署的,只有本地大模型依然能顺畅运行。还有,如果你在学习大模型,本地部署对你来说更是一条必经之路。
本地部署的这些优势,让各家PC和芯片厂家嗅到了机会。近两年AIPC概念火热,各家芯片厂都在大力增强处理器的AI性能,甚至那些不带独显的全能本和轻薄本,都能跑起性能不低的模型。

更可怕的是,由于核显的共享内存往往会比甜品级显卡的显存要大,这些核显本在某些场景下可能还有优势。下面我就用我目前在测的轻薄本,一步一步教大家要怎么在本地部署Deepseek-R1,跑起来效果如何,看看当前最新的AI PC处理器能有多强的AI性能。
接下来我们直接进入部署过程吧,为了让大家能尽可能参考,我会把每一步都详细记录下来,让大家跟着就能做。
此时我们使用的是英特尔的酷睿Ultra9 285H处理器。部署的第一步是安装好驱动,显卡性能挺受驱动影响的,更新到最新的驱动可以让你的核显有最好的性能和兼容性。这里放一个官网链接,大家别找错了。
官网驱动地址
更新完驱动之后,就是配置环境,安装框架,大模型只是模型数据,想让它跑起来,还需要一个框架提供运行环境,这里选择ollama-ipex-llm,ipex-llm是英特尔基于 PyTorch 开发的专业优化库,对酷睿Ultra200H兼容性比较好。大家可以进入下面的Github发布界面,下载windows最新的包。
ipex-llm
下载解压最新的ollama-ipex-llm,可以看到一堆文件,在里面点击start-ollama.bat
点击之后,会弹出一个命令行界面,显示下面这样的信息,就说明ollama运行成功了,下面可以进行下一步,但是要特别注意,这个界面不要关掉,一关掉ollama就没了。
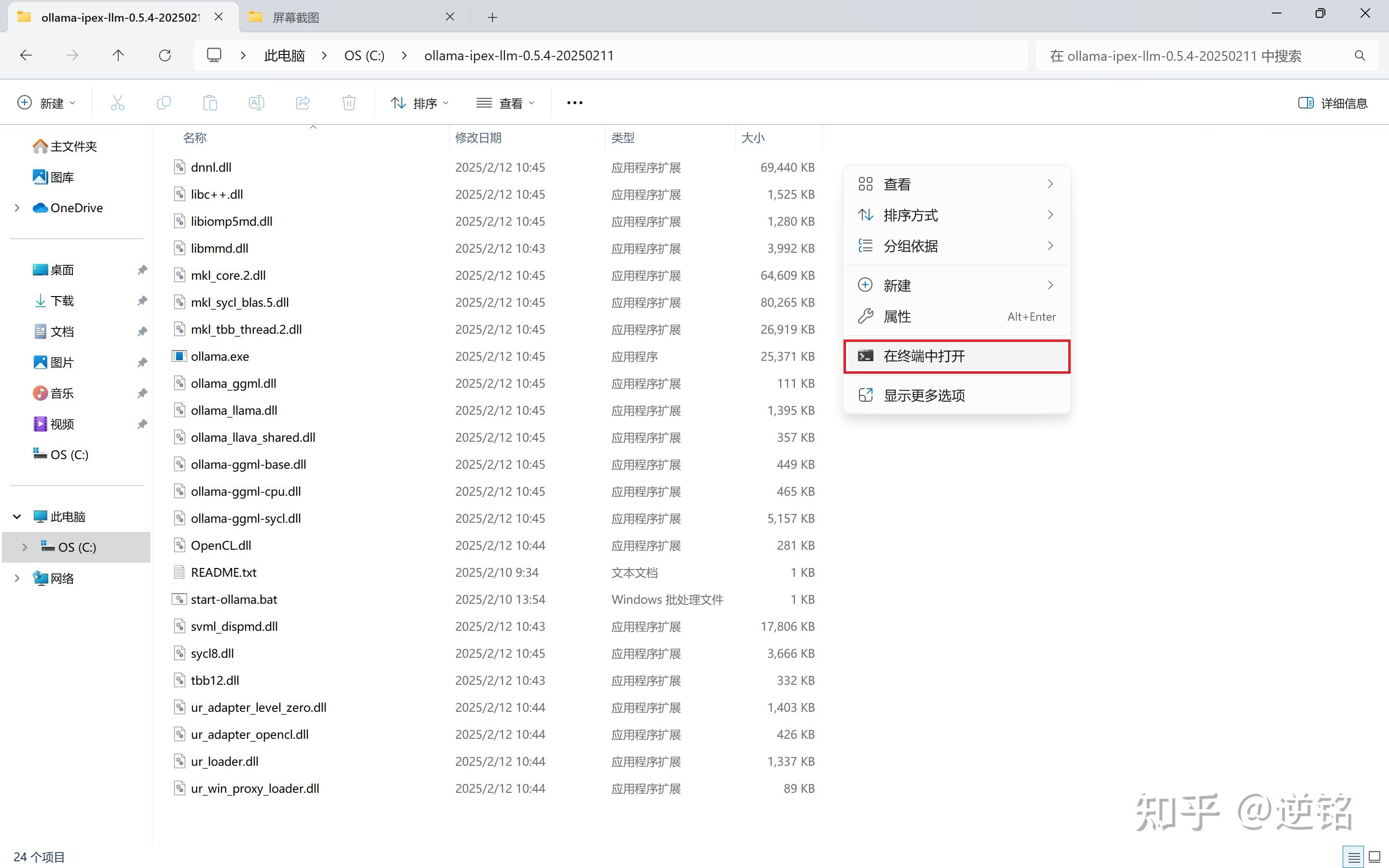
接下来回到解压ollama的界面,点击右键,会有一个在终端打开的选项,点击弹出命令行,如果没有,就只能从终端自己进到这个目录下了,这里不赘述。
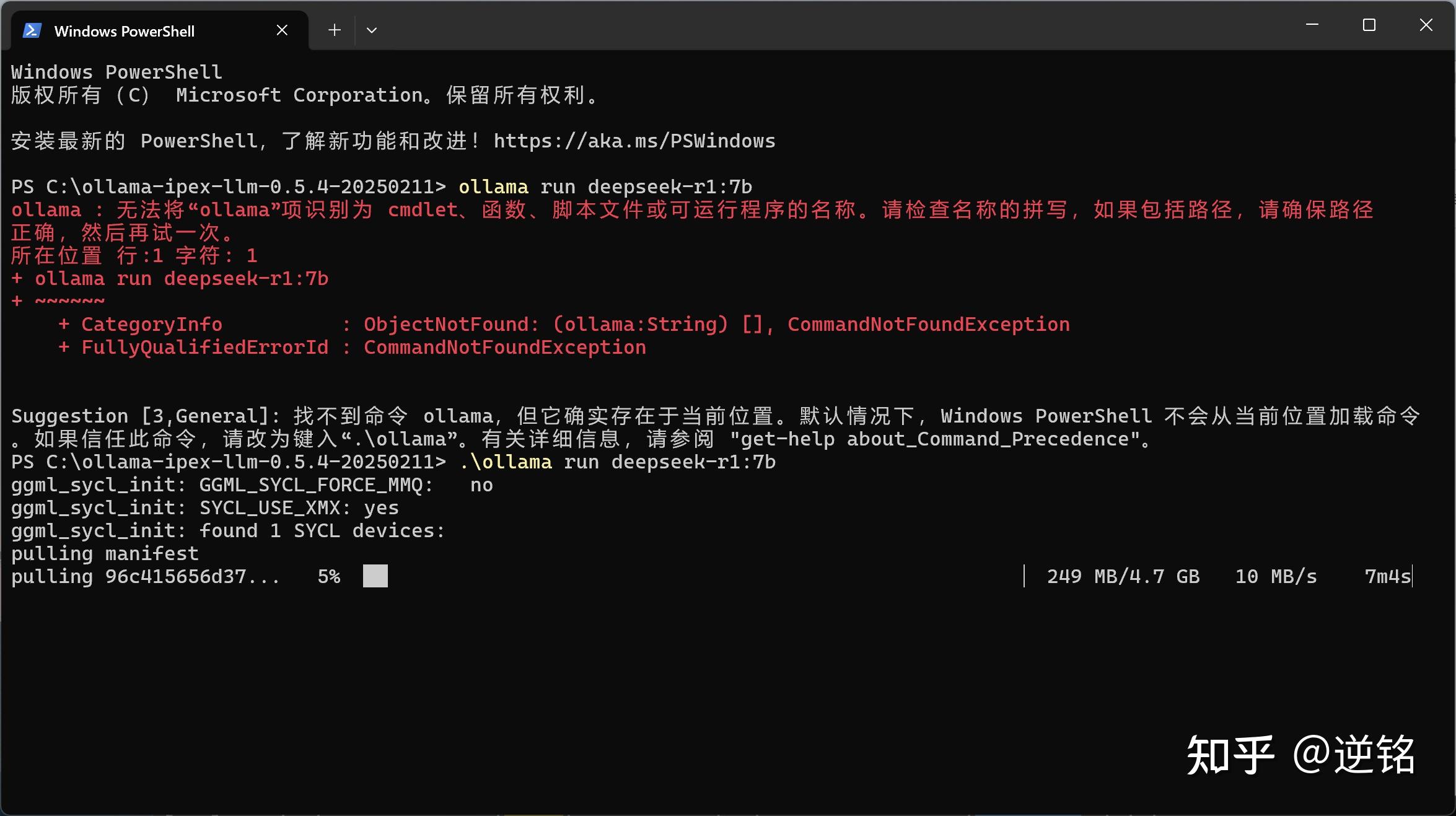
以7b模型为例,打开终端命令行之后,可以输入ollama rum deepseek-r1:7b来运行模型,也可以输入其他参数量加载其他模型。如果提示你找不到命令,说明目录没在环境变量里,可以输入.\ollama rum deepseek-r1:7b来正确运行。
运行之后,如果系统里没有模型,会自动开始下载,如果有模型,就会直接开始运行。
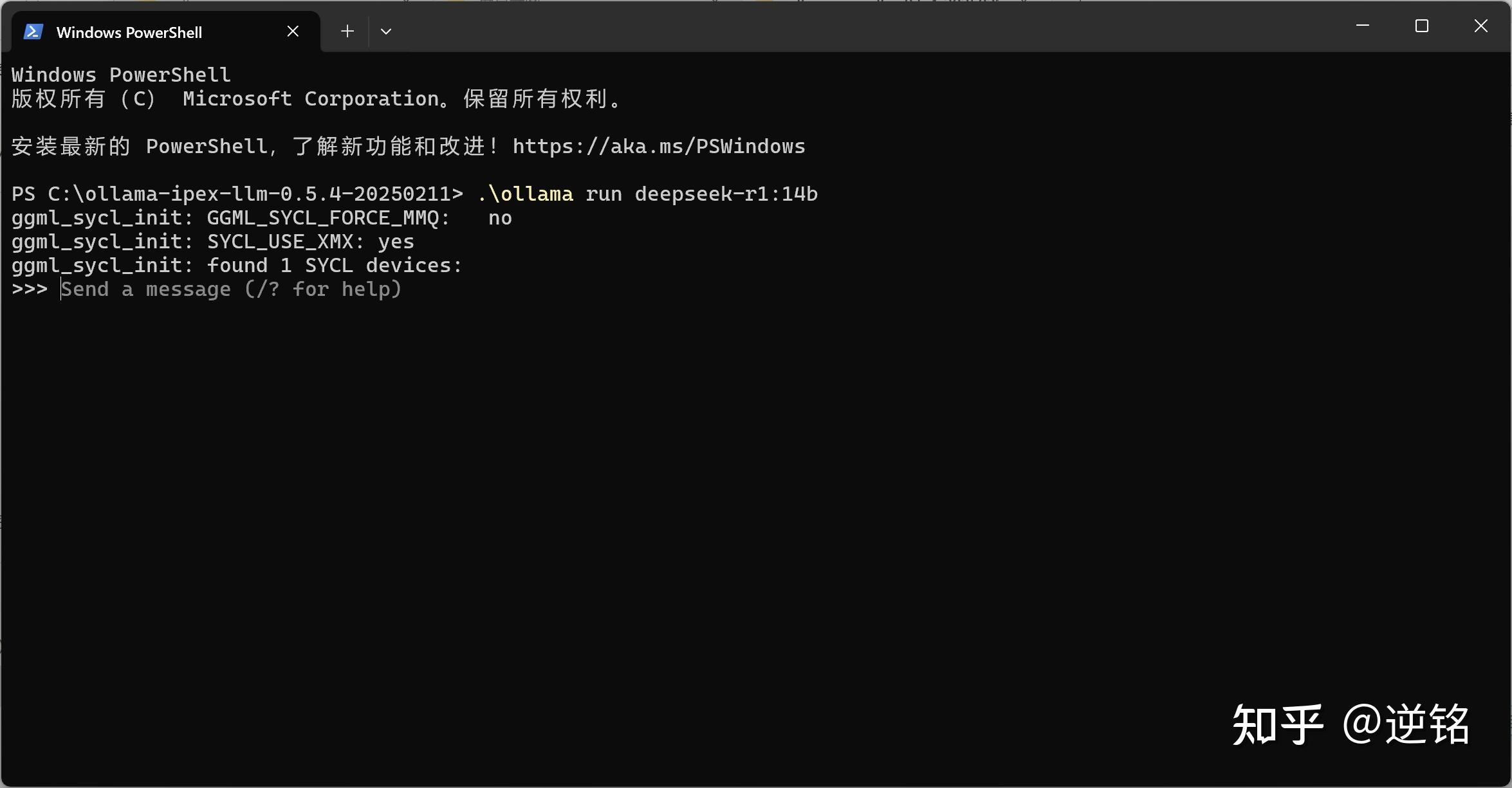
当你看到它提示你send a message,就说明大模型成功运行,你可以开启对话了。
至此,Deepseek-R1就算成功部署,我可以直接输入问题了。当然,这个界面看着有点简陋,毕竟是纯命令行,没有UI。
如果你想加一个好看点的界面,这里教大家两个方式。第一,你可以去edge的拓展商店,搜索下载page assist插件。
Page Assist - A Web UI for Local AI Models - Microsoft Edge Addons
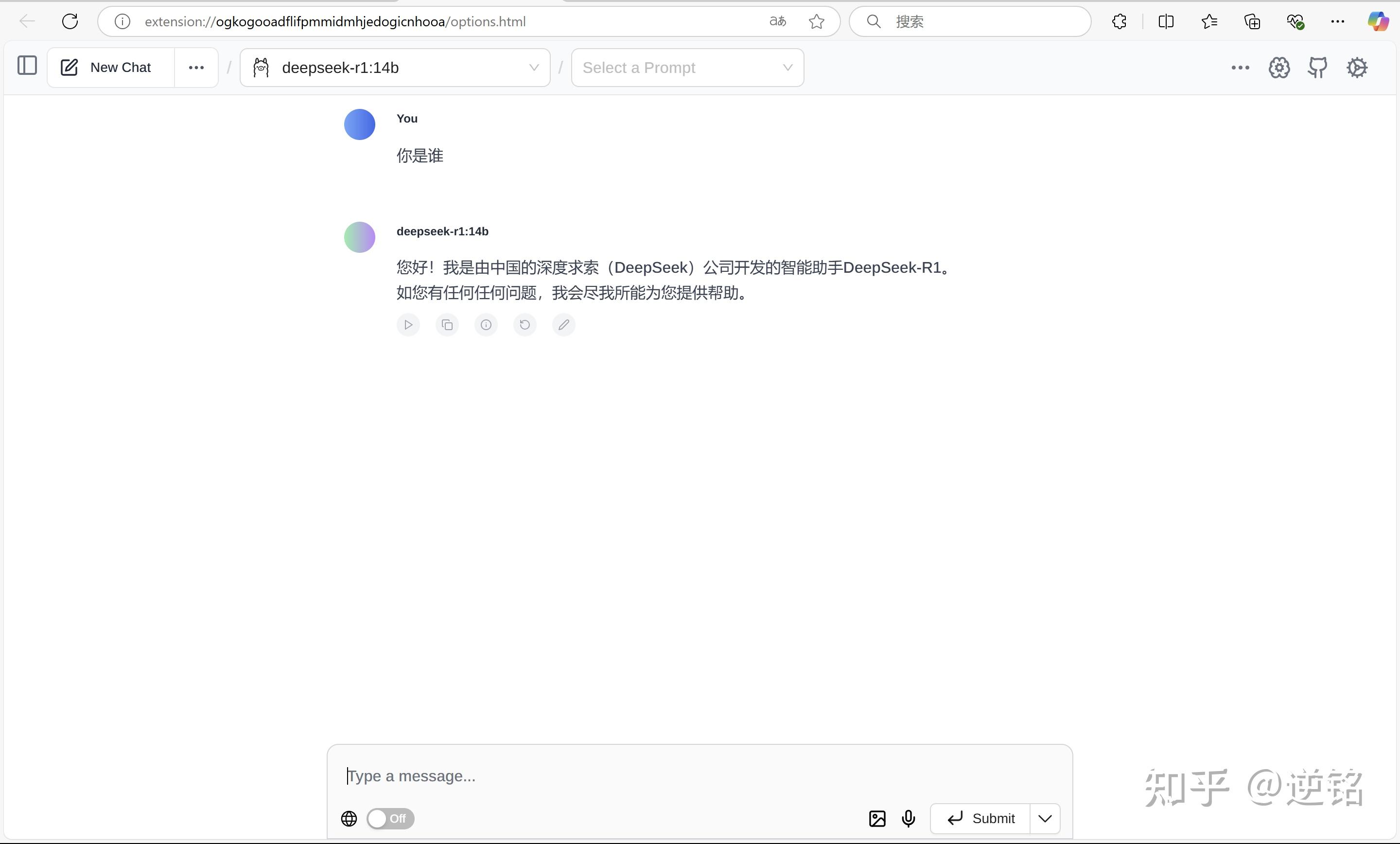
下载后打开插件,就可以看到一个和云端大模型差不多的界面,你可以在顶部选择你想要的模型,然后开始对话,所有数据都在本地运转。
不想用网页,也可以使用本地软件,像chat BOX,大家可以去下面的官网下载。
Chatbox AI官网:办公学习的AI好助手,全平台AI客户端,官方免费下载下载安装打开之后,选择使用自己的本地模型,然后选择Ollama。
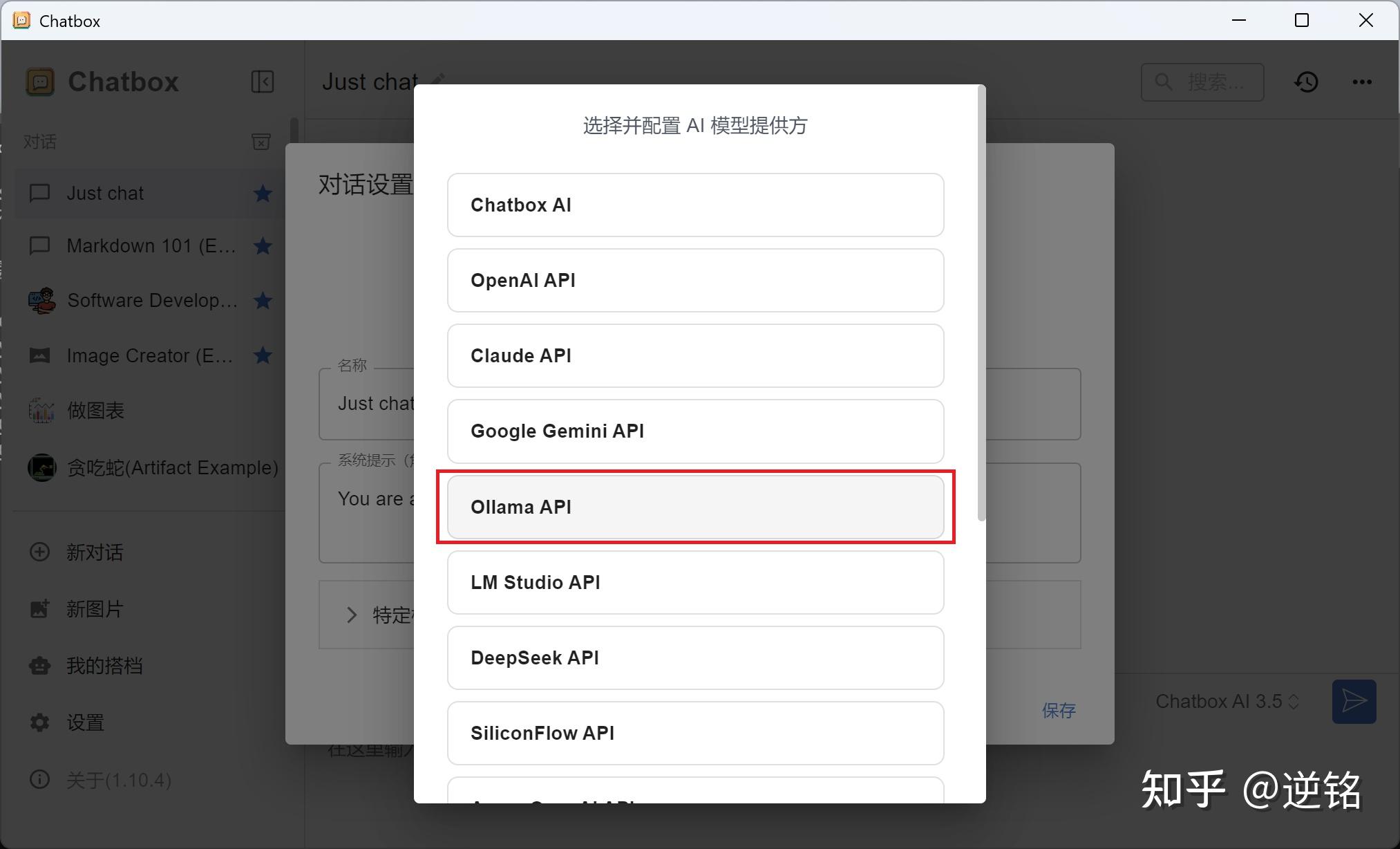
然后你就可以选择想要的模型,开启对话了。
到这里,模型的部署就算完成了,比我想象中要简单太多,基本属于傻瓜式操作。可见英特尔对于AI生态的开发还是有点东西的,他们的确非常重视。
上面教了大家如何部署模型,下面用酷睿Ultra9 285H跑一跑部署好的模型,看看现在的轻薄核显本能到什么样的水平。
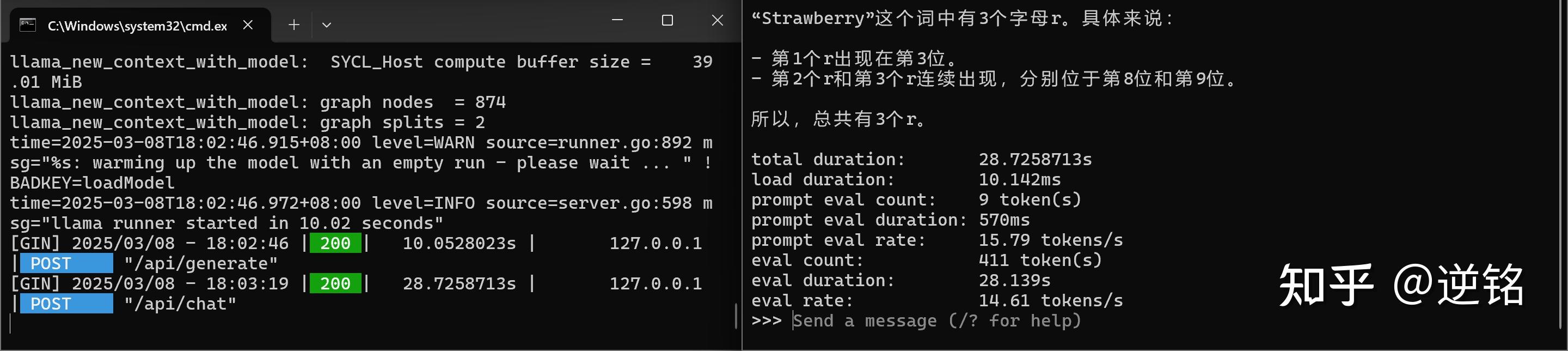
一开始,我试了下Deepseek-R1-7b的模型,问它草莓的英文单词里有几个r,没想到,跑出来的结果,竟然能到14.6tokens每秒,生成非常流畅,大大超出了我对轻薄本处理器的预期。
既然如此,那就将参数量抬起来,升到14b看看。
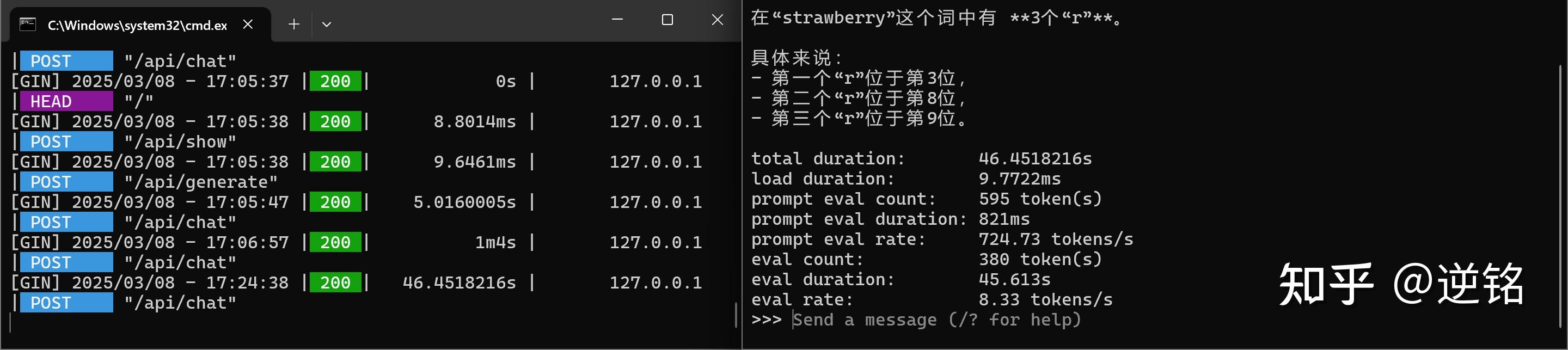
结果依然让人惊讶,在参数量翻倍的情况下,生成速度依然能到每秒8.3tokens,只要不是特别长的内容,生成速度依然可以接受,实际体感和网页上用云端大模型差不多。
14b模型跑起来了,我就把目光放到了32b的模型上,可惜的是,由于32b模型需要20G以上的显存,核显从内存里分到的16g虚拟显存有些不够用,最终没跑起来。当然,这样的结果已经很好了。
所以下面,我就用14b模型体验了本地部署的Deepseek-R1各方面的表现。
先让它写首诗,没啥问题,出品很不错。
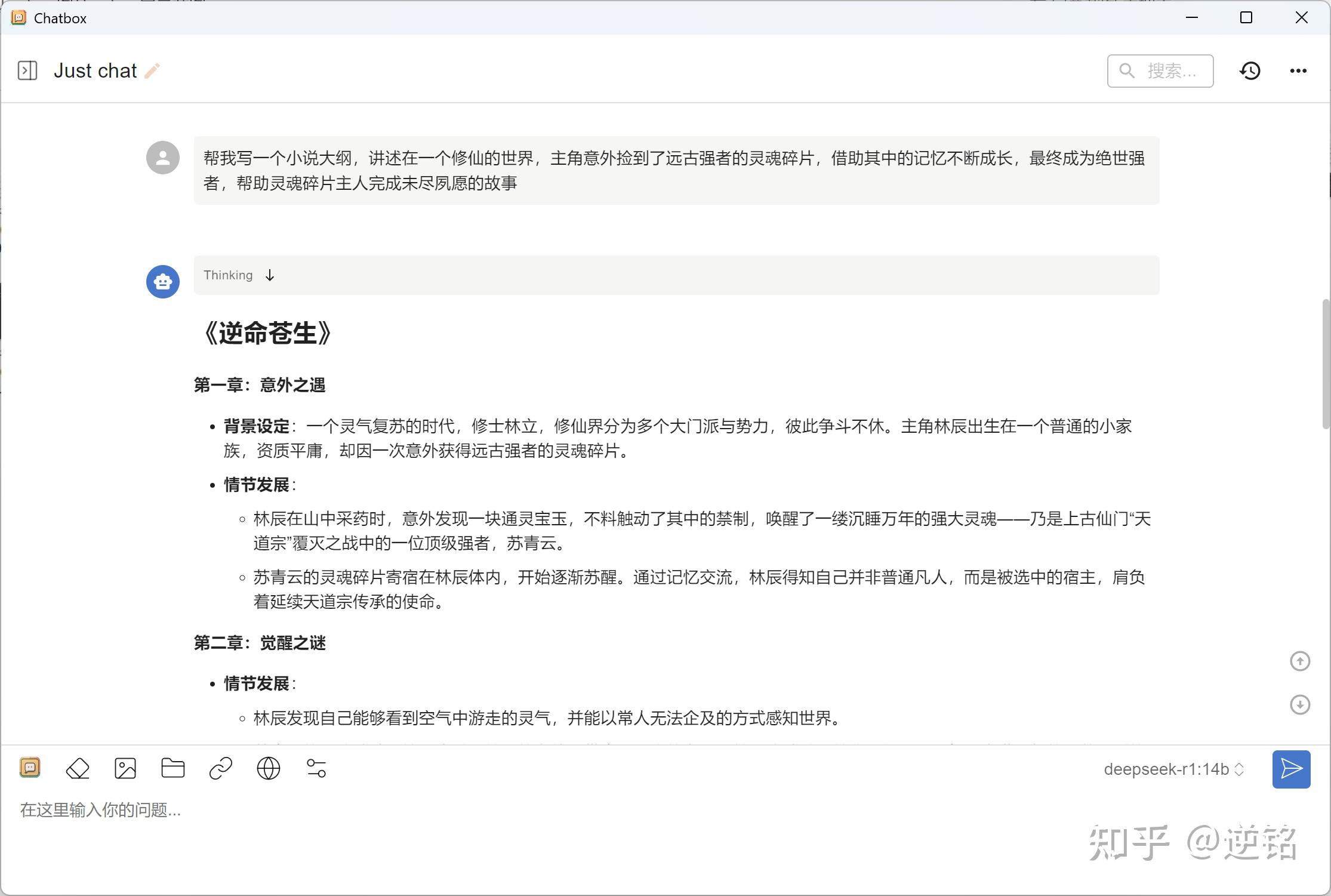
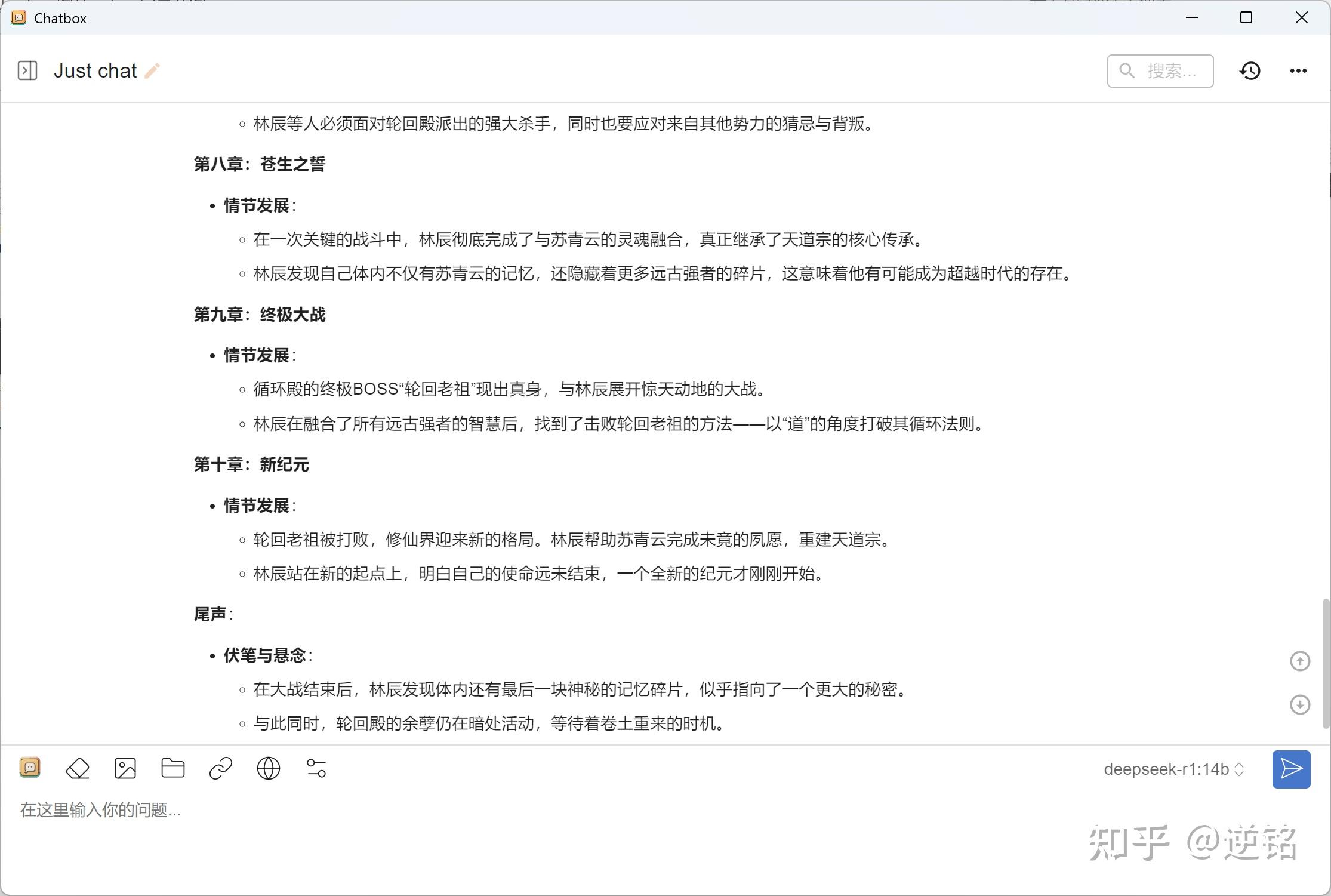
接下来上一点强度,帮我写一个小说大纲。从输出结果上看,Deepseek-R1给出的故事非常完整,说实在的,我看下来就知道,它非常熟练地运用了玄幻小说的各种套路,味儿太浓了,以至于既视感不断,当然这也是因为我给他的提示本就是照着已有的经典故事脉络来的。
这确实让我很震惊,我怎么也想不到,就这样一台笔记本,我给他简单一句背景,他就能给我一个完整的故事大纲,起承转合齐全,而且逻辑完整,叙事流畅。这个生成速度,至少已经把我给打败了。
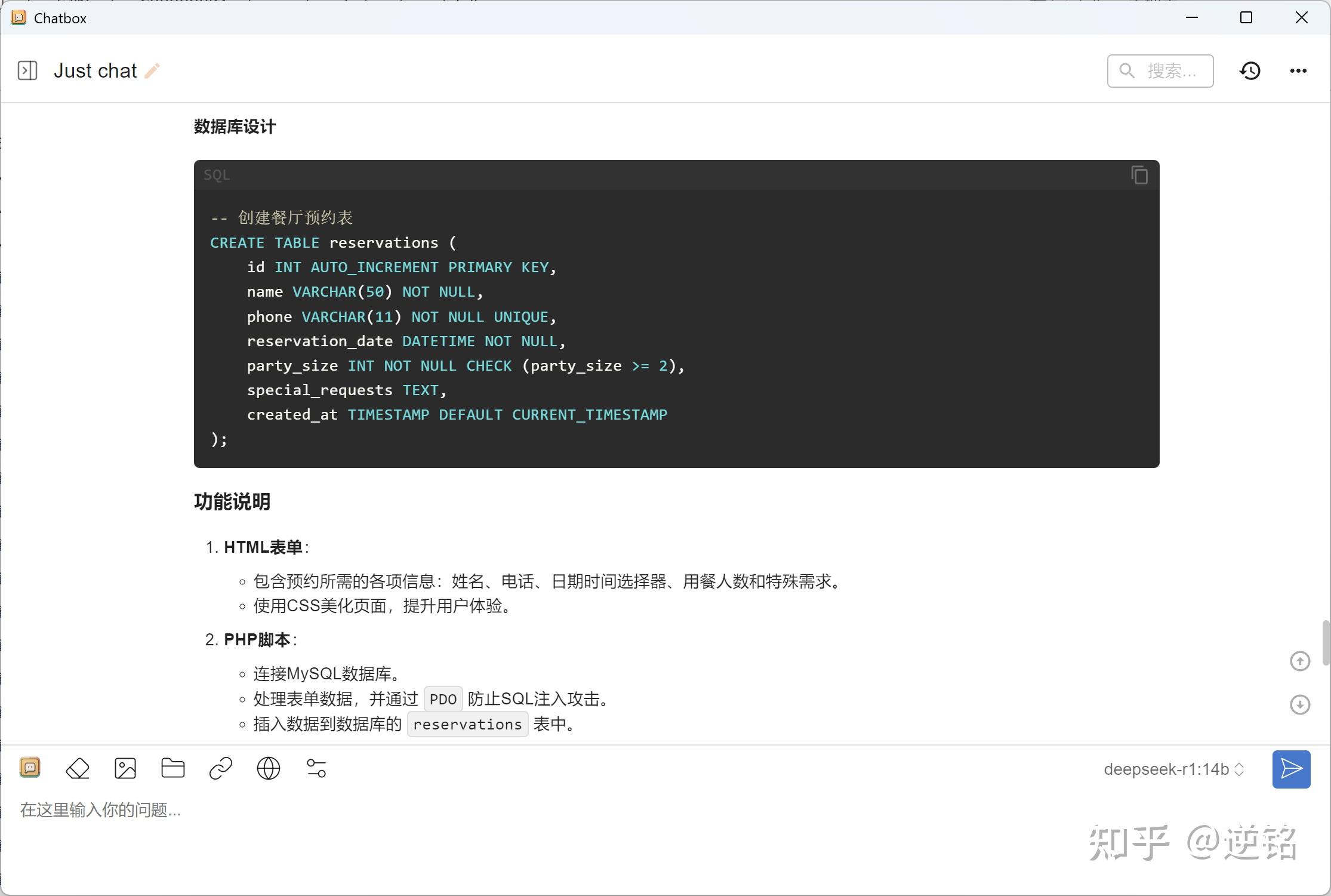
下面来个和大学生关系比较密切的,让它写代码,看看它能不能帮我们完成一些比较常见的作业。我让它帮我写一个餐厅预约网页,结果竟然真的写出来了。
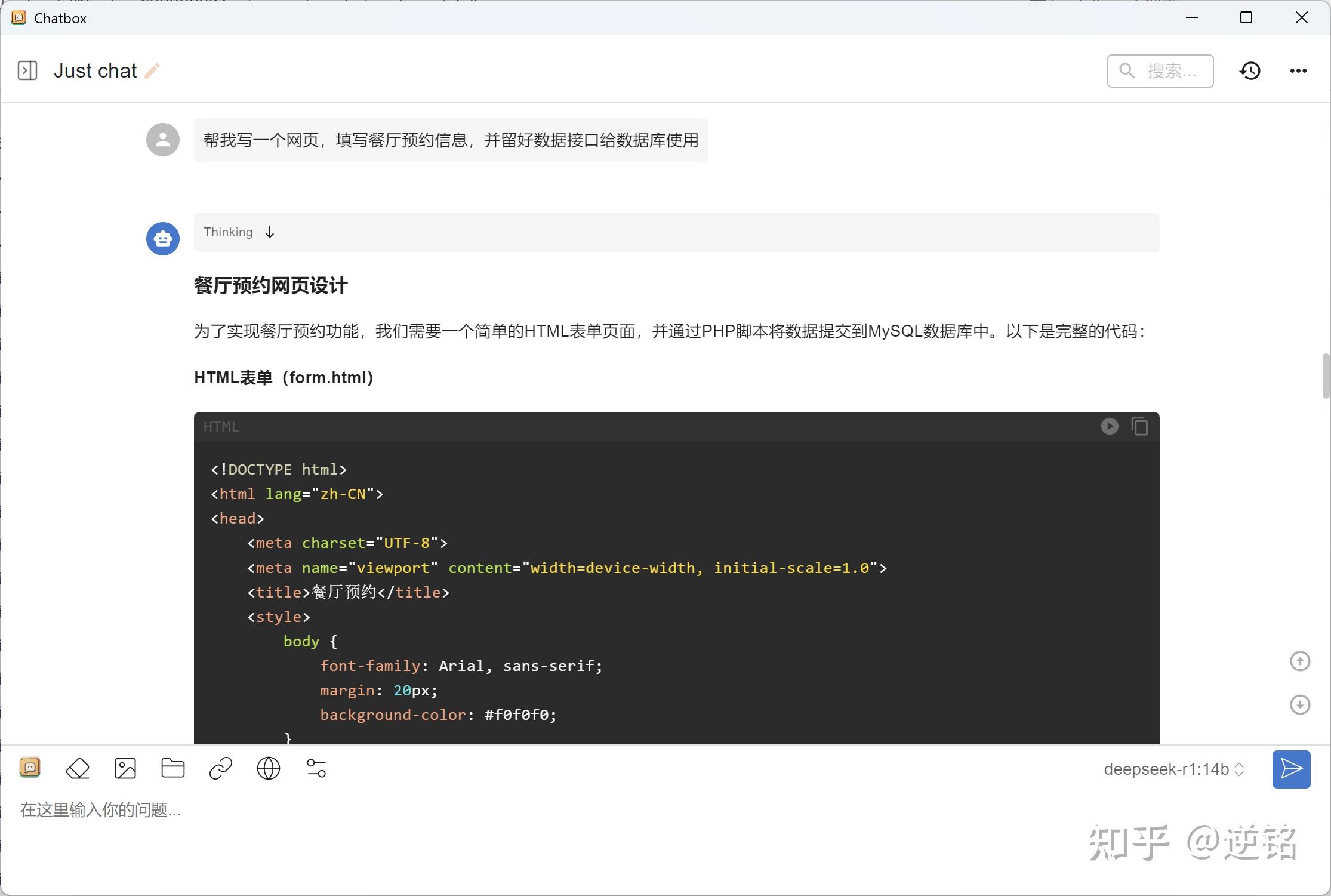
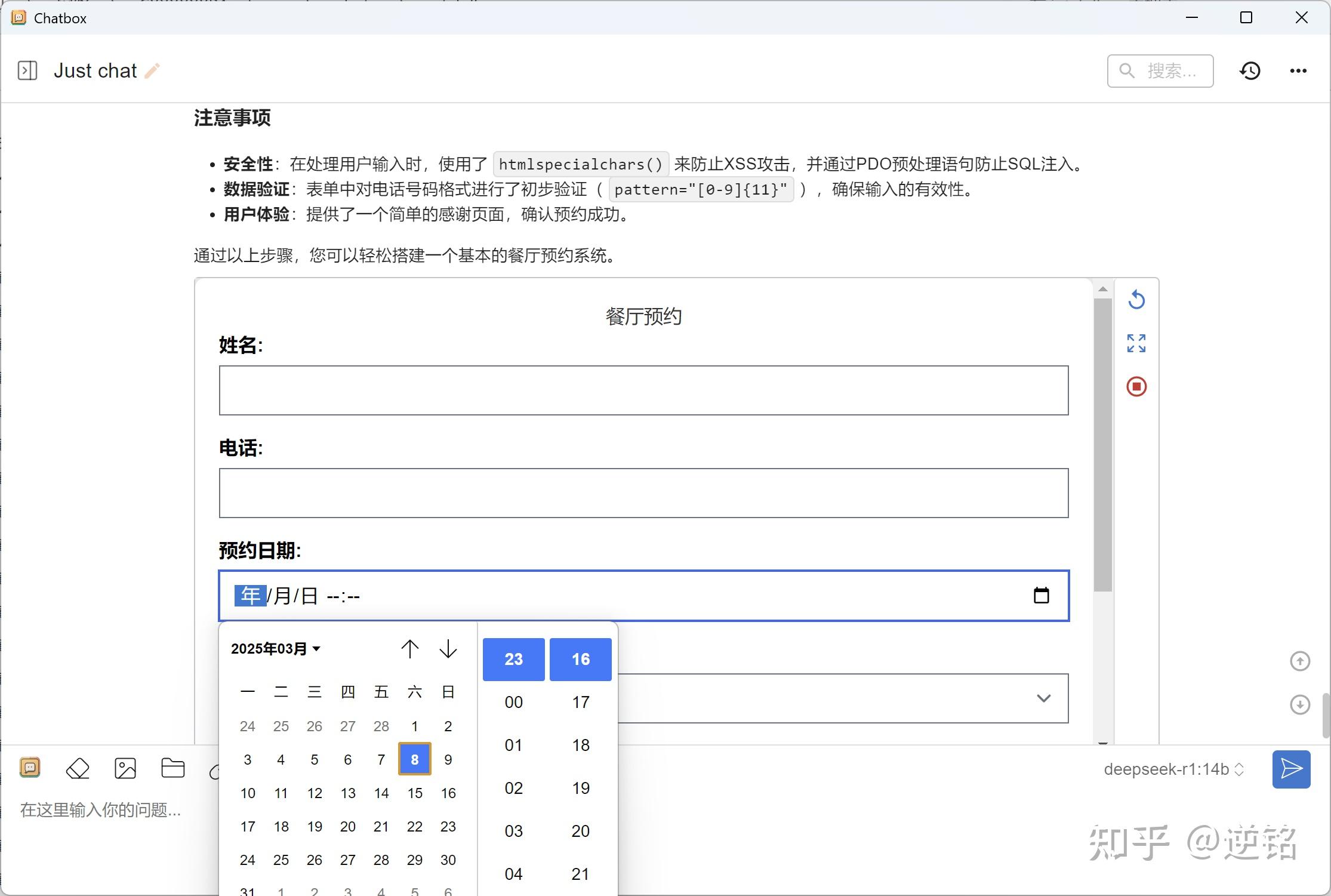
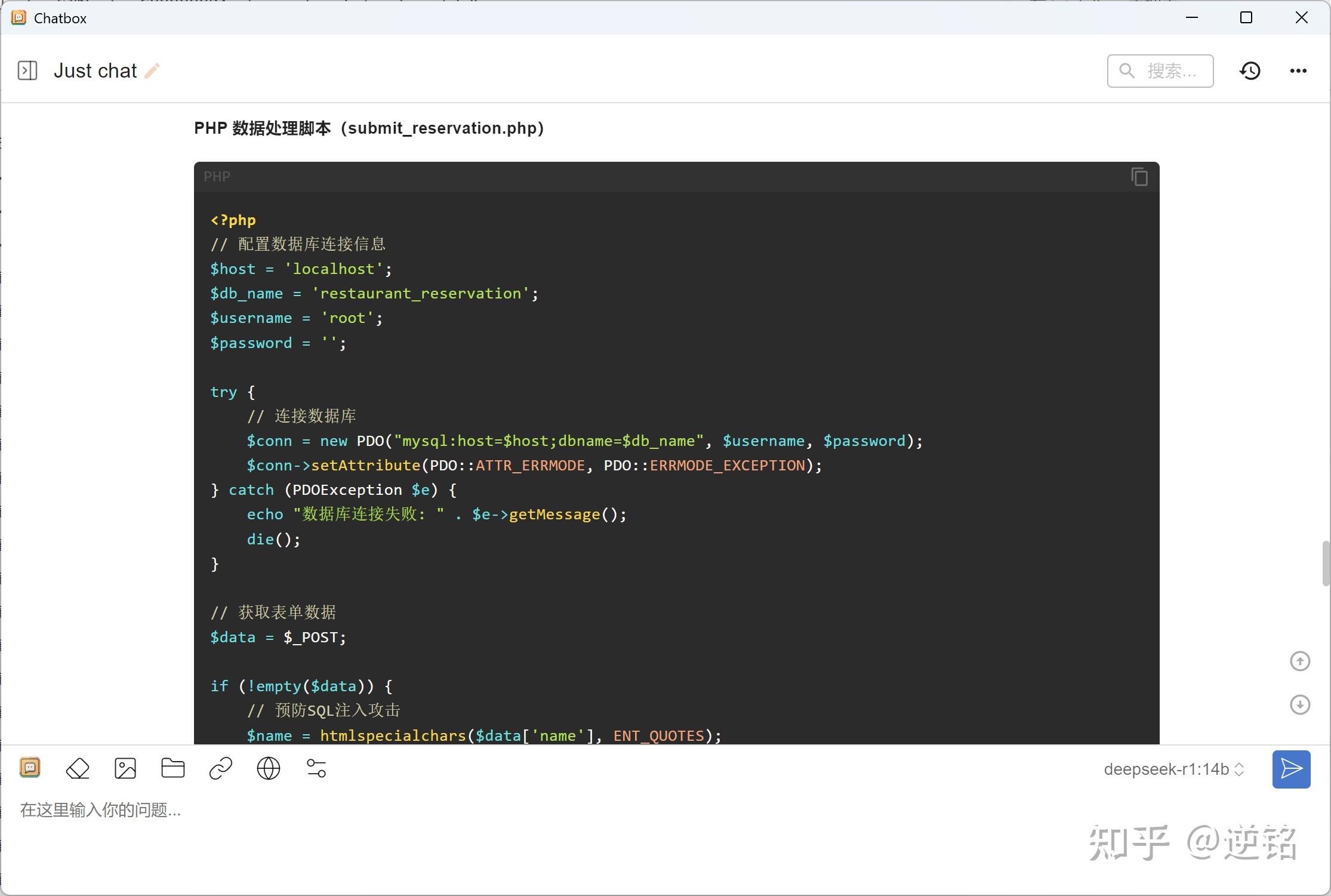
让我惊讶的是它不仅写了网页,还写了个数据库的php脚本,甚至还设计了数据库,结果非常可用,令人惊喜。
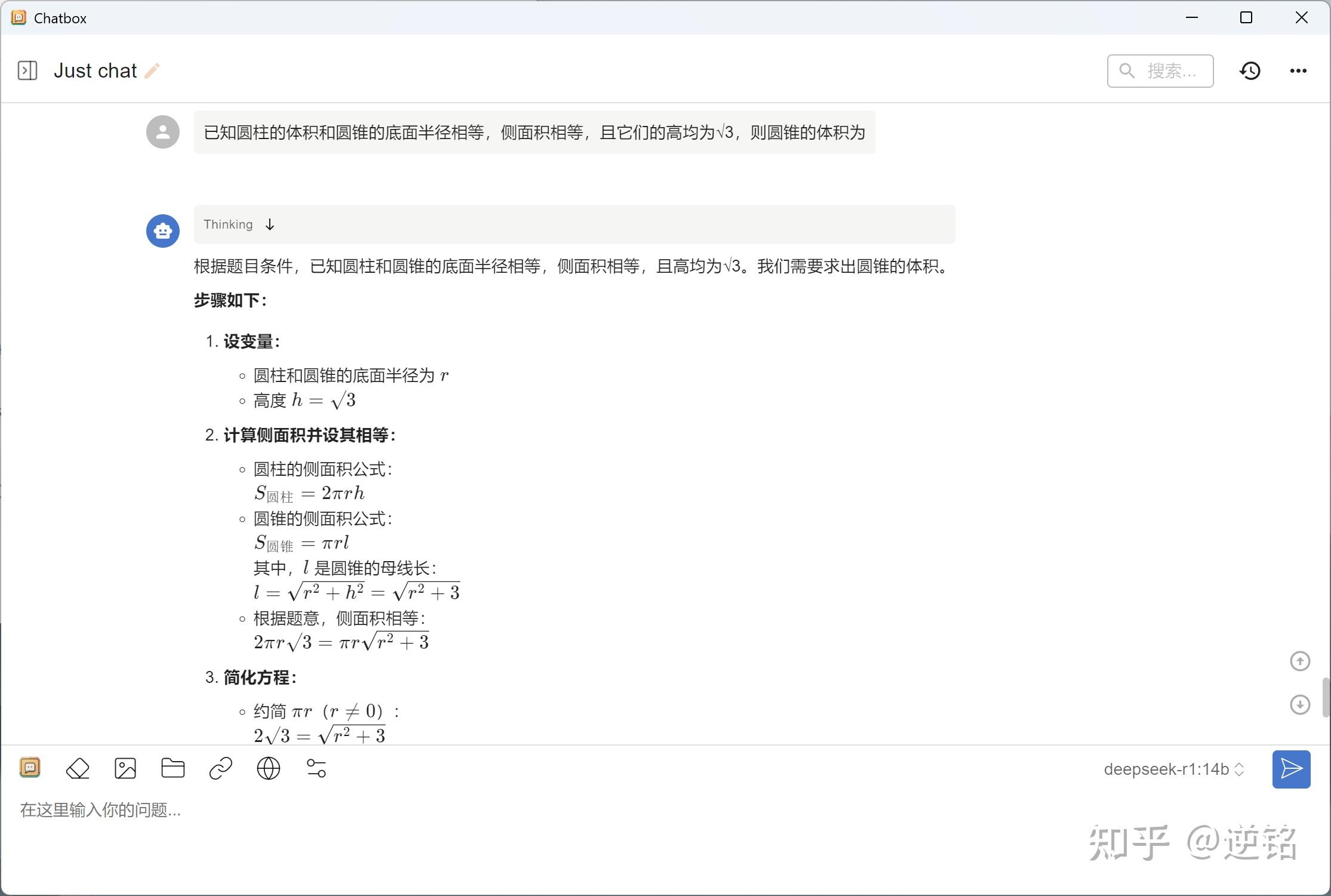
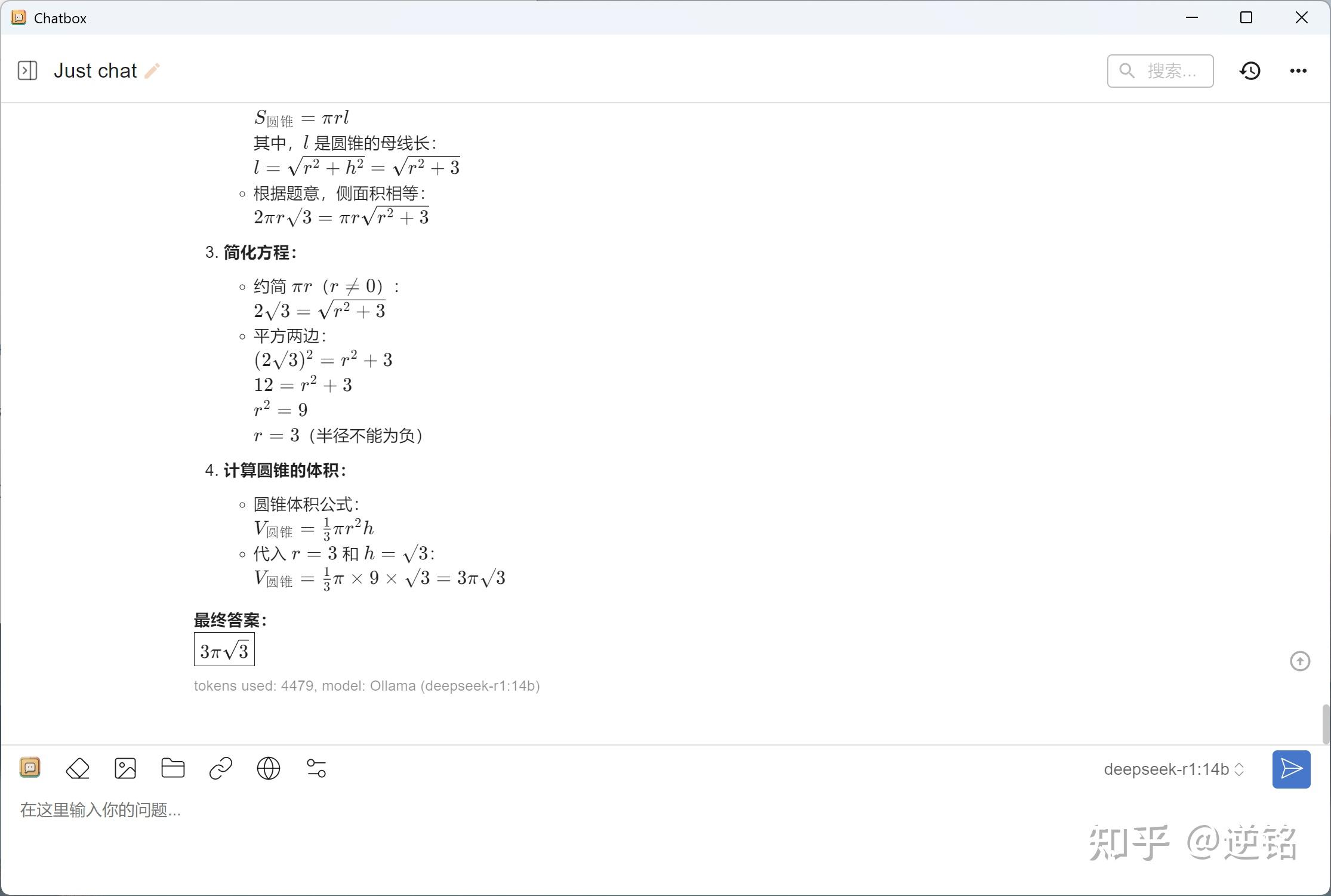
最后我还让他解析了一道数学题,看看它能不能做一些家庭辅导,我给了2024年的全国高考数学题,没想到它解出来了,不仅答案准确,还有完整的过程,太可用了。
用到这里,我差不多可以得出一个结论,本地部署的Deepseek-R1在多数场景下确实足够好用,并且我不需要登录网页,不需要上传信息,随时随地,有网没网都能用,不管是隐私性还是便利性,都相当可以。
光是每次都能稳稳生成,不会出现网络异常稍后再试,就已经舒服多了。
上面的内容看下来,相信大家对Deepseek的表现印象深刻,下面就来介绍一下我使用的轻薄本平台,或许更能让大家惊喜。我这次部署Deepseek使用的平台是2025年新品,华硕灵耀14 ,厚度13.9mm,重量1.19kg的它是一个非常标准的轻薄本,外出能随时带在身边那种。

它搭载了英特尔最新的酷睿Ultra9 285H处理器,有着6P+8E+2LPE一共16核16线程的规格,取消了超线程之后,能耗表现有所提升,这对于散热受限的轻薄本来说,反而是件好事,从CPU-Z的跑分来看,单核多核都比上代有进步。
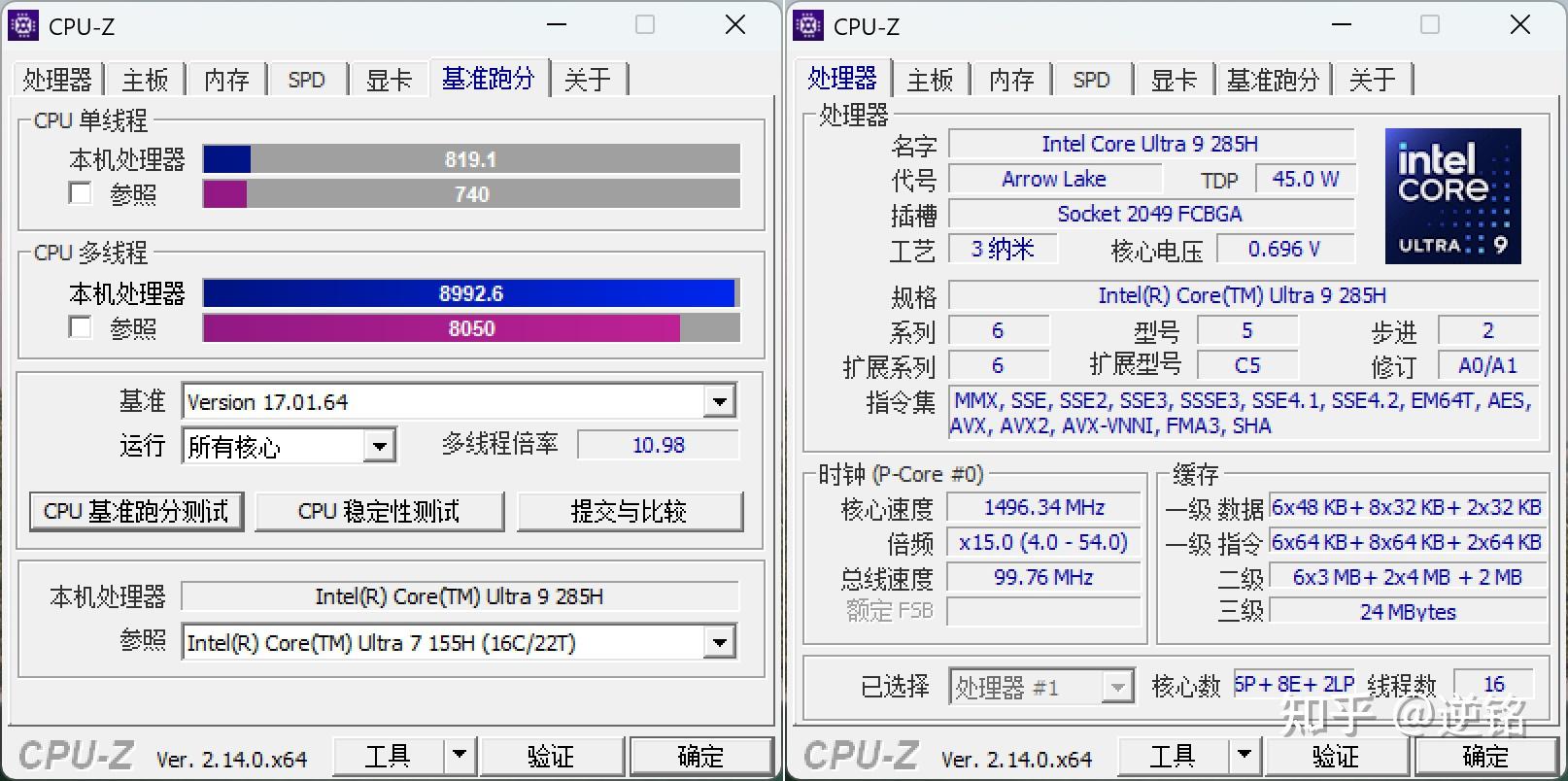
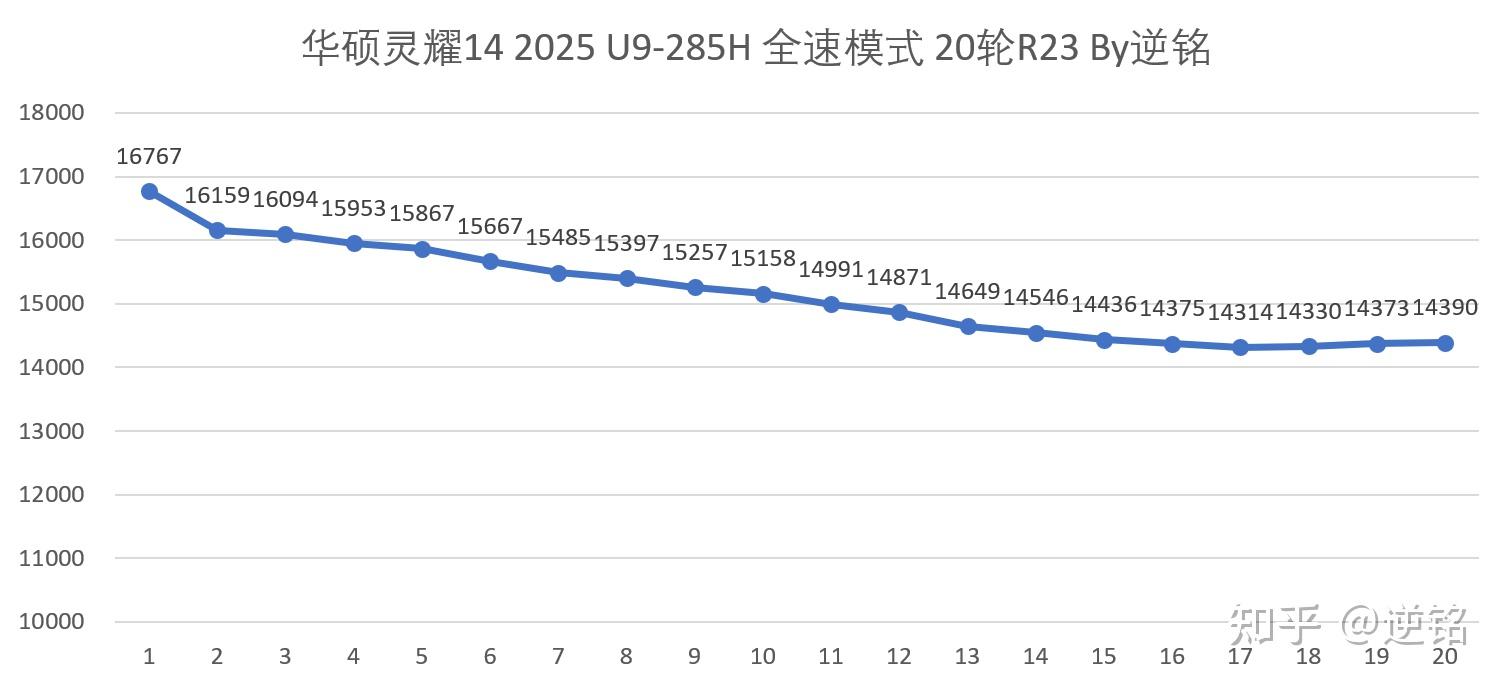
得益于能耗比的进步,即使灵耀14 2025只有峰值60W,稳定30W的性能释放水平,Ultra9 285H依然表现出不错的性能,20轮R23成绩从接近16800逐渐稳定到14400,对比上代的峰值14000稳定11000,成绩要高很多。
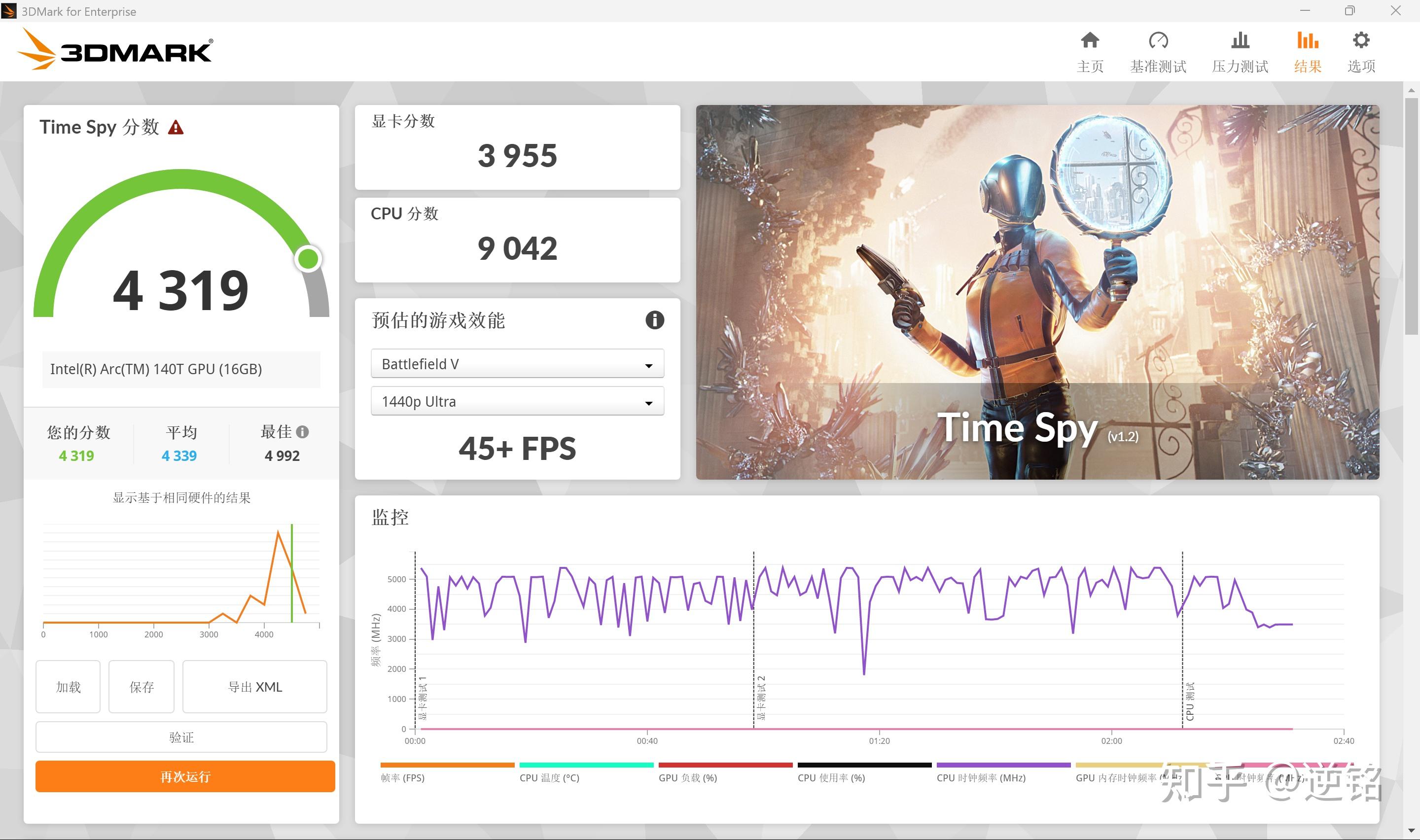
核显跑分如下,虽然没有换代,但得益于增加了XMX单元数和缓存容量的Xe-LPG+架构,成绩依然有一些进步。
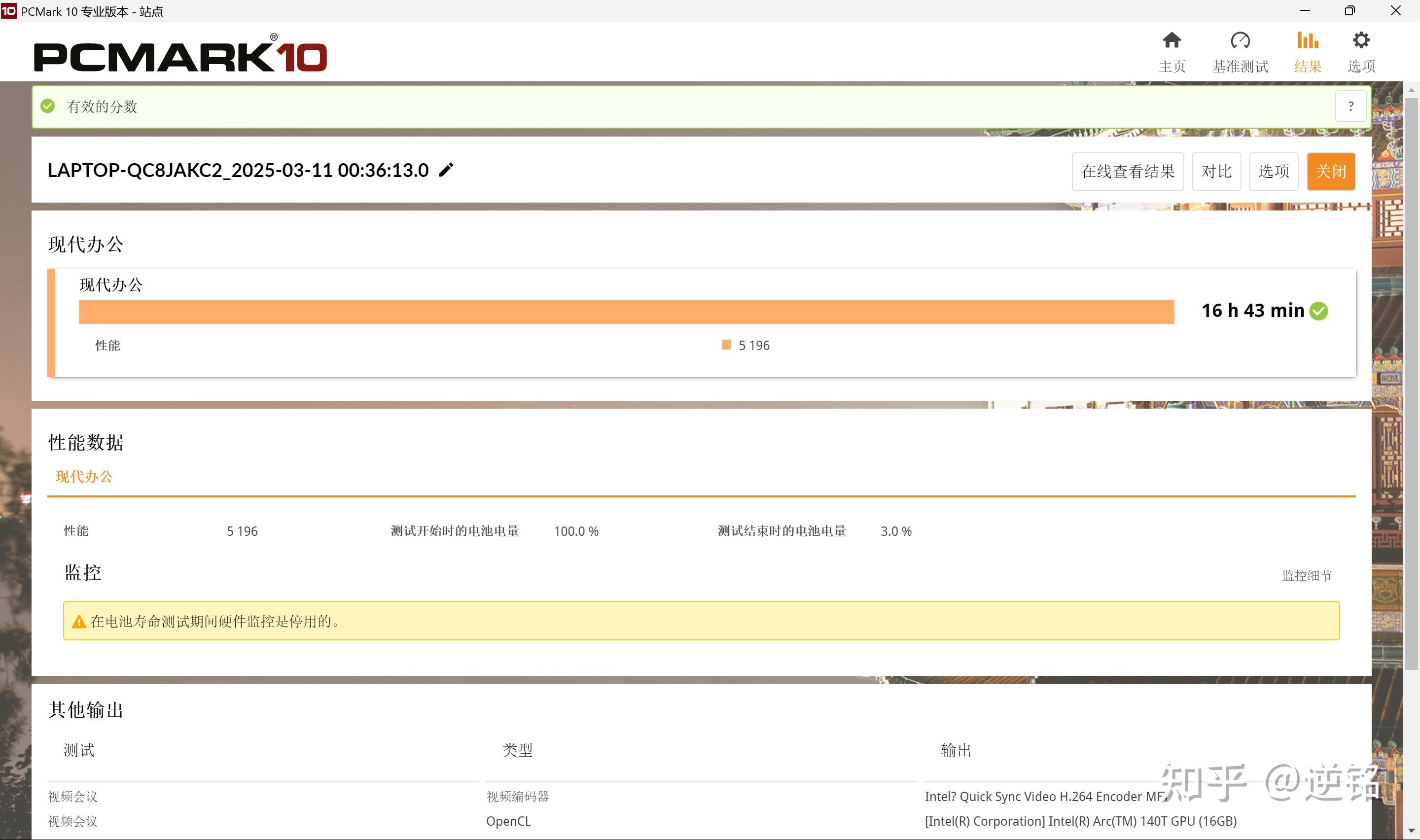
能耗比的进步在续航方面同样有体现,得益于处理器较低的功耗和灵耀14内部有着75Wh的大电池,PCMark10现代办公续航成绩能达到接近17个小时,确实非常强,带出去中轻度办公用一天没啥问题。
其他的还有2.8K的120Hz OLED屏、两个雷电接口、全金属机身等等,这里就不多赘述,作为一个轻薄本,灵耀14 2025的产品力还是很足的。
下面来讲讲它的AI性能。Ultra9 285H整颗芯片一共有99TOPS的算力,这里面的主力是它的ARC GPU,有77TOPS,在核显里算非常强大的了。

在理论测试中,酷睿Ultra9 285H的AI成绩还是不错的,比同类的轻薄本平台高很多,这为它独立跑Deepseek-R1,奠定了坚实的基础。
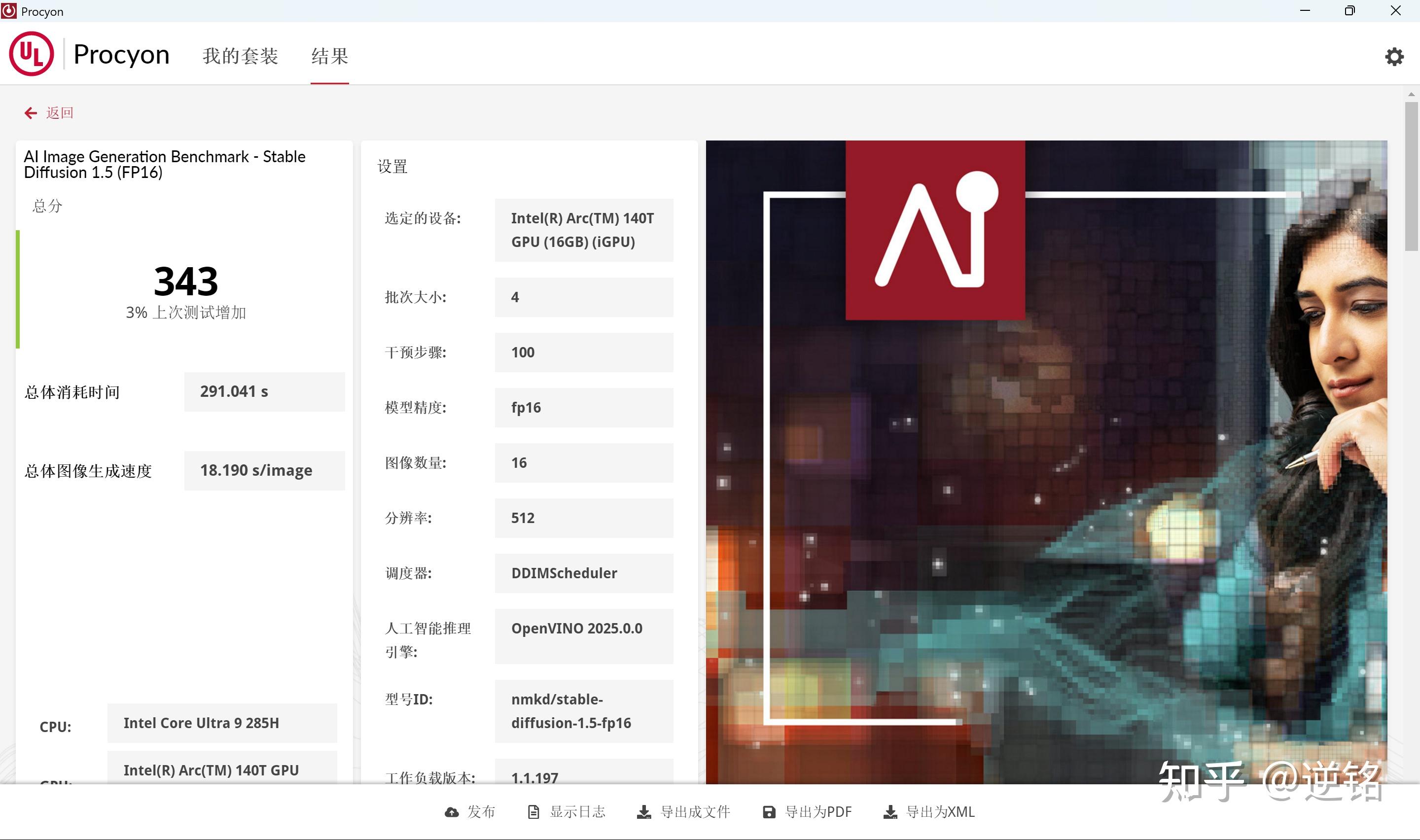
最后顺带提一下,上面的性能都是在文章发布前,我手头这台U9平台的灵耀14上测试的结果,或许后面经过更新成绩会有变化,仅供大家参考哈。
以上就是Deepseek-R1在轻薄全能本上部署的全过程,综合来看,我觉得目前的处理器平台已经完全可以脱离独显,做到独立运行大语言模型,运行的参数量还不低。
这波体验完,我突然理解了AI PC的含义,能独立跑大模型跑出这种效果,AI PC这名字可以说名副其实。可以预见,当未来的小到笔记本,大到游戏PC,都能以很好的效果运行各种AI应用,AI对社会的改变,或许会深入到目前无法想象的程度。
从这个角度看,AI PC的进化对于AI的普及,确实有着非同凡响的意义。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/225596.html