
本地部署大模型的核心优势:
- 数据隐私:所有数据本地处理,无隐私泄露风险
- 零成本使用:无需API密钥,一次部署无限使用
- 离线可用:摆脱网络依赖
- 完全控制:自定义参数和配置
- 内存:16GB以上(推荐32GB)
- 显卡:NVIDIA RTX 3060+(可选,显著提升性能)
- 存储:50GB+ 可用空间
对比主流本地部署工具:
工具 特点 适合场景
LM Studio 可视化界面,操作简单 学习入门、快速部署 Ollama 命令行工具,轻量级 开发者、服务器部署 Open WebUI Web界面,功能丰富 团队协作、高级用户
LM Studio 是学习的**选择:图形化界面、即装即用、模型管理简单。
- 访问官网:https://lmstudio.ai/
- 下载对应系统版本
- 按向导完成安装
推荐入门模型:
- Qwen1.5-7B-Chat:中文能力强,适合国内用户
- Mistral 7B:性能均衡
- Phi-3-Mini:体积小巧
以 Qwen1.5-7B-Chat 为例:
- 在模型市场搜索 "qwen1.5-7b-chat"
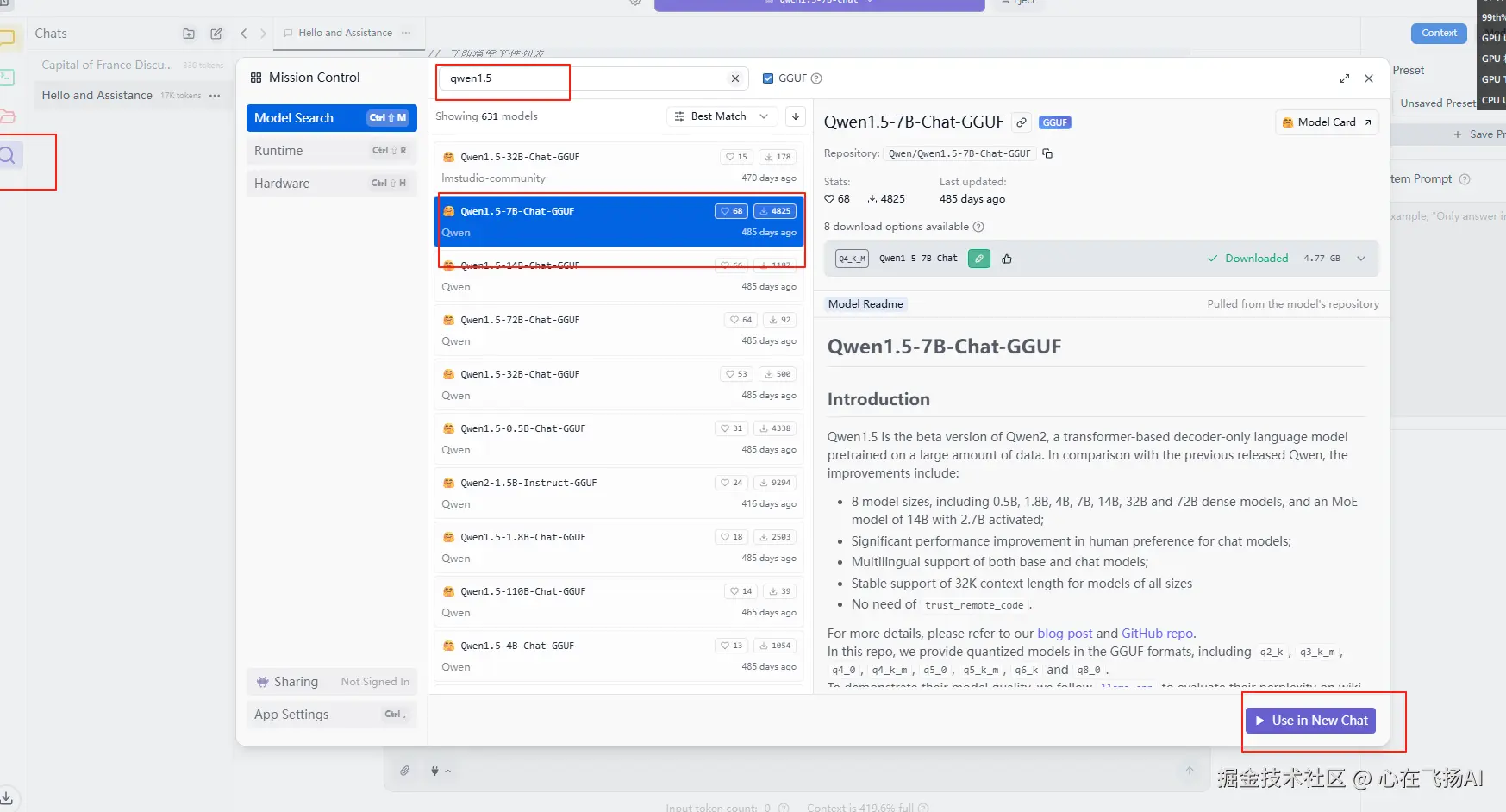
3. 点击下载(文件较大,请耐心等待)
- 下载完成后在 "Local" 标签页找到模型
- 找到下载的 Qwen1.5-7B-Chat 模型
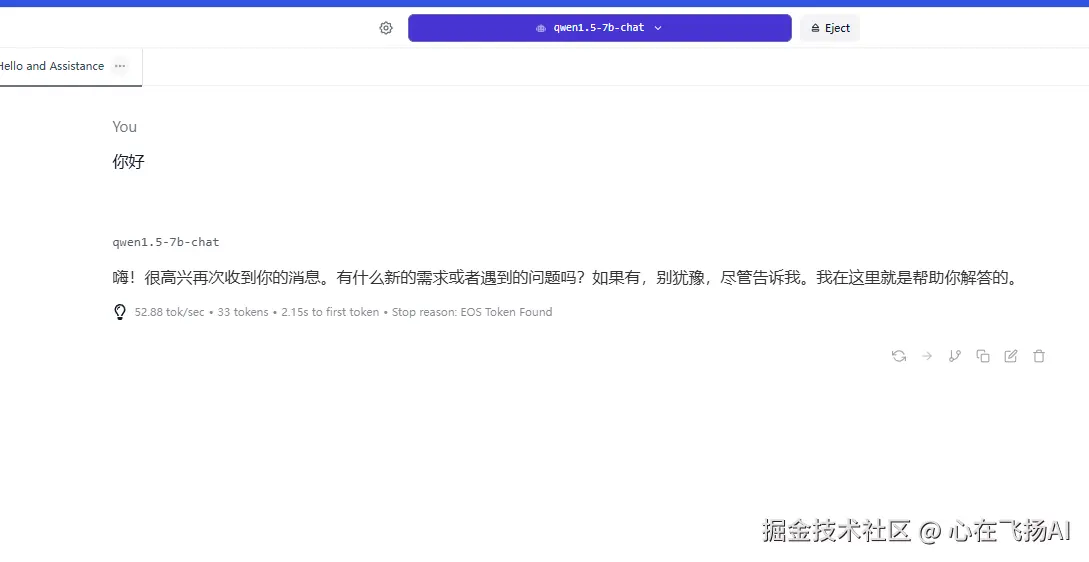
- 切换到 "Chat" 标签页
- 确认右上角显示已加载模型
- 输入问题,开始与本地大模型对话
- 启用GPU加速:有独显的用户务必开启
- 调整内存设置:根据系统内存合理分配
- 关闭无关程序:释放更多资源给模型
Q: 模型启动失败? A: 检查内存是否充足,尝试选择更小的模型
Q: 响应速度慢? A: 确认GPU加速已开启,关闭后台程序释放资源
Q: 想要更好的中文效果? A: 推荐 ChatGLM、Baichuan 等中文优化模型
LM Studio 启动模型后,会在本地 1234 端口提供 OpenAI 兼容的API接口。
注意:使用 0.28 版本的 openai 库,新版本语法有变化。
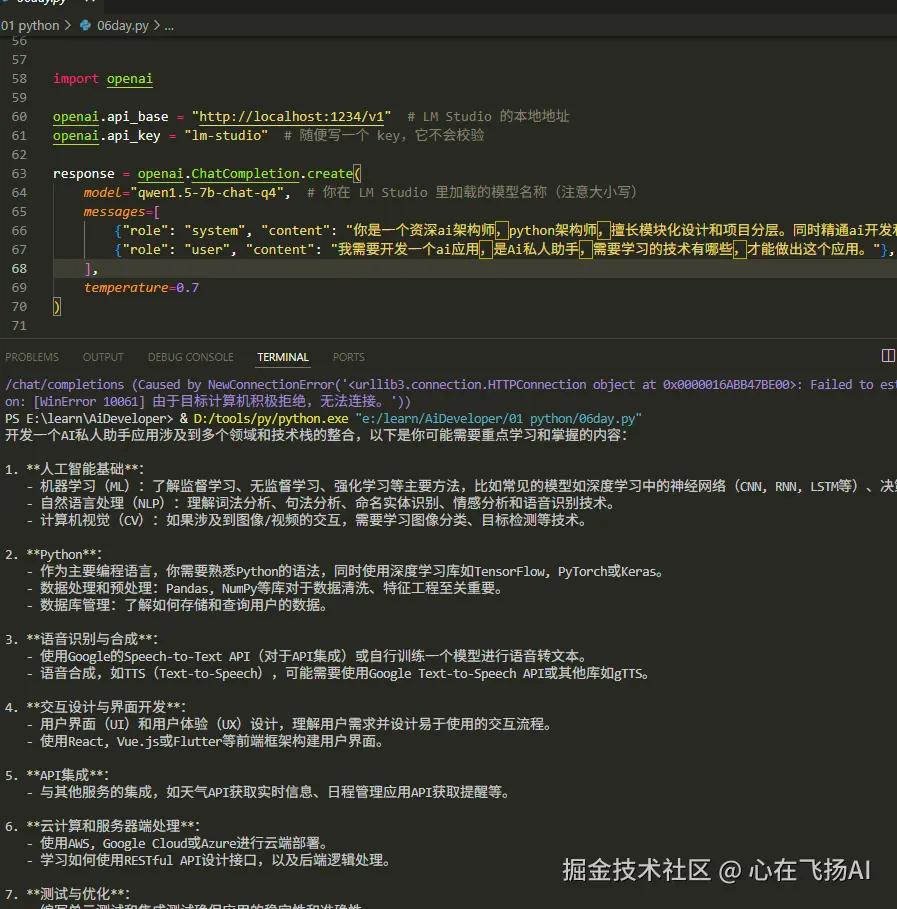
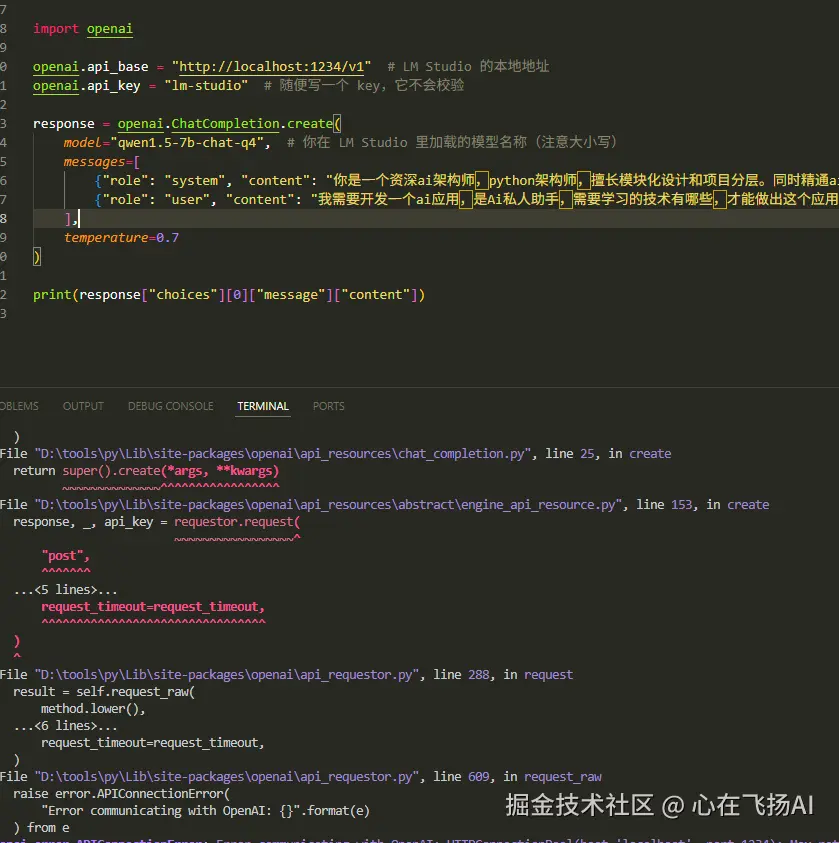
- api_base:本地服务地址,默认
- api_key:可以随意填写,LM Studio 不会验证
- model:必须与 LM Studio 中加载的模型名称完全一致(注意大小写)
- 切换到 OpenAI:只需修改 和 即可
这样就实现了从本地部署到API调用的完整流程,为AI应用开发奠定了基础。
通过 LM Studio + OpenAI API 的组合,我们可以快速搭建本地AI开发环境。这种方式既保证了数据隐私,又提供了与 OpenAI 完全兼容的接口,让AI应用开发变得更加灵活和经济。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/224764.html