

本文使用的是星火大模型的接口,在此基础上进行Prompt测试,通过对学习内容来源的学习与总结,不断完善本博客。
首先使用以下代码,进行prompt测试,以下代码借鉴了官方源码,所以想要测试更多性能,参考官网代码。
官方源码:
使用prompt工程的代码:
藍原因:网络原因,多试几次藍
waringing:使用Spark lite大模型时要注意,此模型大概不支持prompt+文本的格式,支持单个字符串输入,因为会有报错。
sparkai.errors.SparkAIConnectionError: 'content'
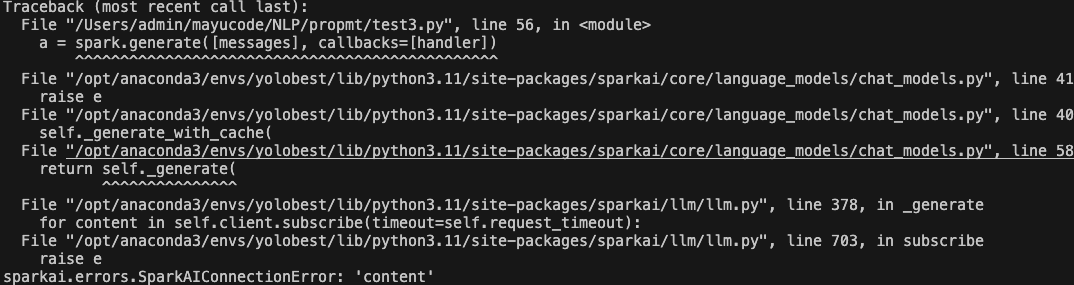
目前没有找到解决方案,大家可以在留言区讨论或者指正。
也就是使用已知答案,之后将已知答案与大模型生成的答案进行对比,让大模型自己进行评判对错。
解决方法:限制输出的文本长度
②直接输入的时候进行命令提示(本方法比较符合prompt工程)
解决方法:要求关注于某些方面
解决方式:要求它抽取信息并组织成表格,并指定表格的列、表名和格式,还要求它将所有内容格式化为可以在网页使用的 HTML。
单一文本的Prompt概括,可以直接从用户输入端限制输出长度。
通过输入文字,限定大模型输出的内容。
给大模型指定某些特定的信息进行提取。
多条文本概括,可以使用for循环,但是在例如多个PDF或者报告之类的文本时,for循环方法就显得鸡肋。
文本推断就是基于所给内容,使用大模型进行分析,推断其他信息的过程。
识别感情类型
指定感情类型识别
输出:
![]()
添加了原因之后,在进行输出,给出了更具体的原因。

如何让大模型只显示输出的结果,而不是整个结构,如包括输出长度、输出结构信息等?
会显示整个对象,内容包括:生成文本、token 使用、响应元信息、函数调用结构等,非常冗杂。
使用a.generations[0][0].text可以只显示大模型的标准输出格式。
优化前:

优化后:

原因:
也就是引用已知的文本,添加prompt提示词工程,提示大模型识别哪些内容,并进行输出,提示词应该进行严格且标准的格式。

也就是在prompt里面写入多个任务,让模型自动识别

从一段文本中让大模型自动推理出内容,并推理出主题等。
统计文本内的话题,并进行记录(注意这个前后顺序很重要)

这在机器学习中有时被称为 Zero-Shot 学习算法,因为我们没有给它任何标记的训练数据。
可以手动添加相关代码,实现工程开发
文本转换包括将输入转换成不同的格式,文本翻译、拼写及语法纠正、语气调整、格式转换等。
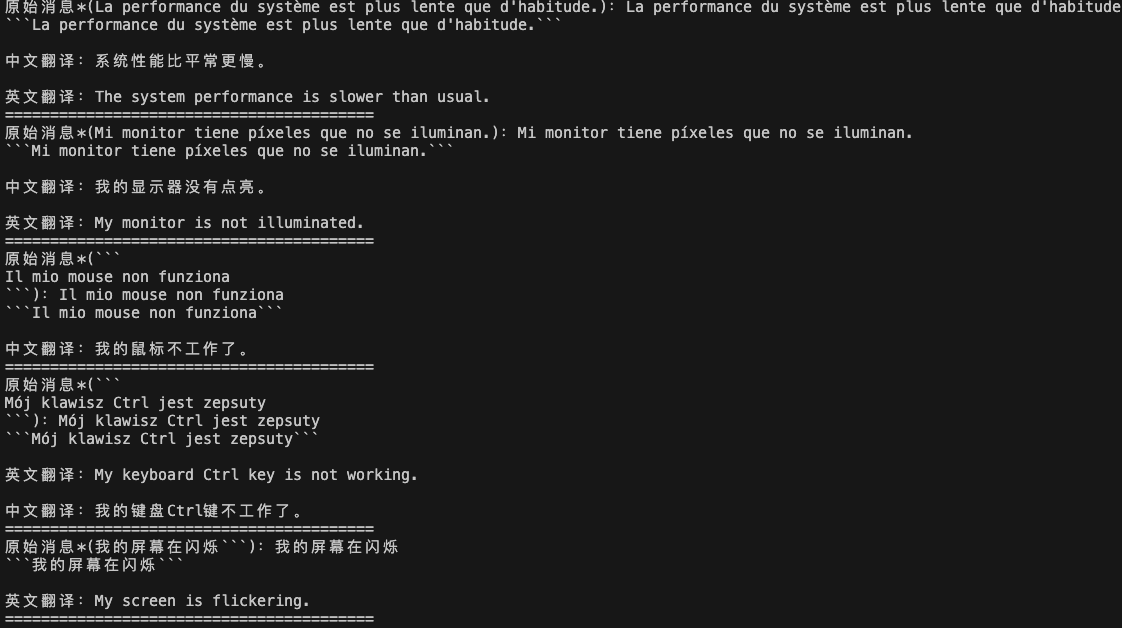
可以直接输入指令,将对应文本翻译成某种语言。
直接向大模型输入指令,识别某种语种
对同意文本进行多个语种输入,得到多个语种翻译结果
这个主要就是把文本进行翻译,并进行语气设置
这个就是相当于使用大模型完成一个小功能设计:
核心代码
结果输出:
大模型较擅长进行各种文件格式进行转换
直接让大模型对文本进行纠正
需要安装Jupyter内核,博主使用的是VS code,所以创建了一个.pynb文件,直接安装就可以使用。
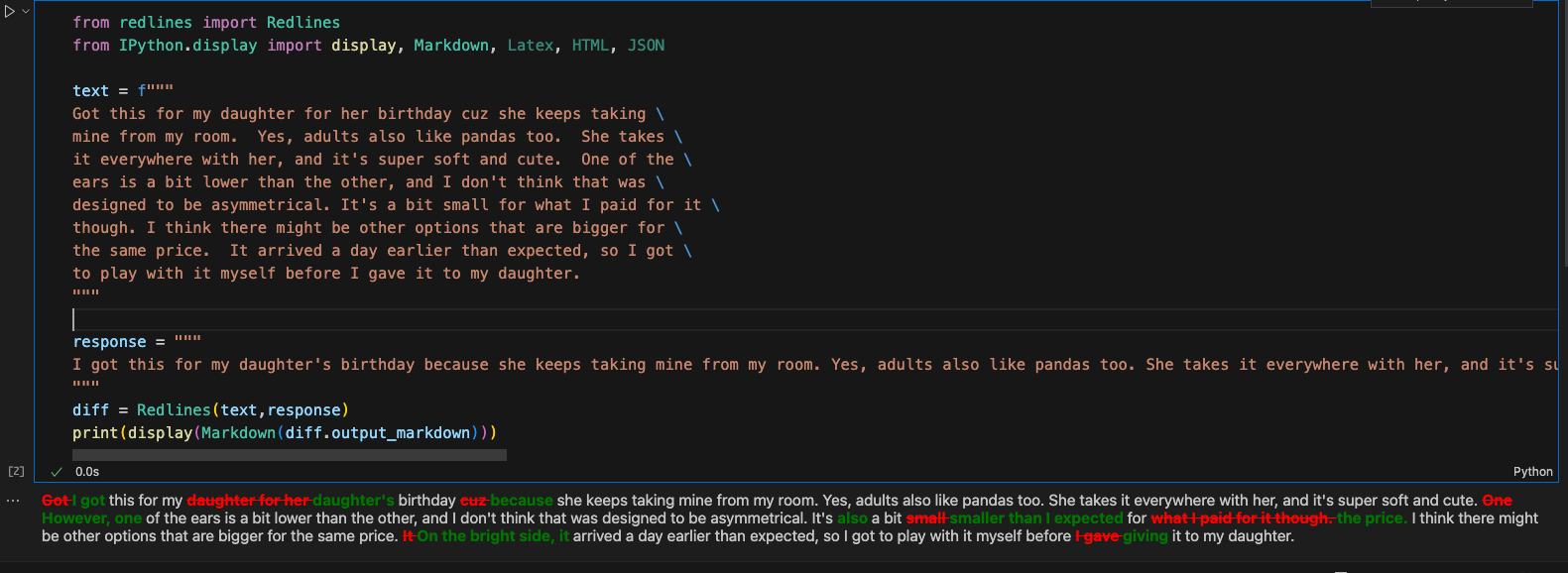
案例使用文本翻译+拼写纠正+风格调整+格式转换

我们可以首先定义邮件风格,然后内容,之后设定感情风格来生成指定内容

在接口调用或者本地化部署中,大模型输入参数都有temperature。
参数说明:参数设置越高,模型的输出更加随机。模型回答的更随机,更分散,但也许更有创造力。
输出结果:

使用接口来实现构建针对特定任务或者行为的聊天机器人进行延伸对话
因为之前使用的接口代码都是Prompt相当于单次对话,现在如果想要多轮对话,可以简单更改代码。
以上是使用OpenAI的格式进行的多轮对话,并且使用的是HTTP的调用方式,与WebSocket略有不同。
这里输出的话是把大模型所有信息都输出,以下代码能够只输出大模型输出部分,并且能够识别换行内容。
对比:
![]()
![]()
输出内容更简洁,易于查看。
这个大模型的主要作用是进行订餐信息的,可以直接提取用户消息,避免重新输入的繁琐操作。
以下函数是为了收集提示信息,并添加到列表中,每次调用模型则调取该上下文。
学习内容来源:
提示原则 | 面向开发者的 Prompt 工程(官方文档中文版)
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/224211.html