
只能说是性能一般,没有达到大力出奇迹的效果,只是比mixtral性能高那么一点点,但耗的算力却多得多。不过开源了,至少后面社区有人会在上面去微调整出更强大的模型,不管怎么说,至少马斯克在开放方面比openai做得好。感兴趣可以看我写的文章,针对grok的架构核心点做了一些解析。
马斯克兑现承诺,发布了最大开源模型Grok-1 314B
埃隆马斯克信守诺言,发布目前开源的最大模型Grok-1。 Grok-1 是一款 314B 大型专家混合 (Mixture of Expert,MoE) Transformer。
- 基础模型:未微调,希望开源社区可以快速微调个Chat版之类的
- 开源程度:不如 Pythia、Bloom和OLMo(提供了训练代码和训练数据集),希望Grok能像OLMo那样开放

- 许可:Apache 2.0许可证,可免费商用
- 314B MoE,8个专家,推理期间只有2个处于活动状态(实际上是86B参数),MoE看来已经成为潮流了,如果感兴趣可以阅读Hugging Face的MoE详细介绍文章:
- 基于Rust和JAX从头开始构建
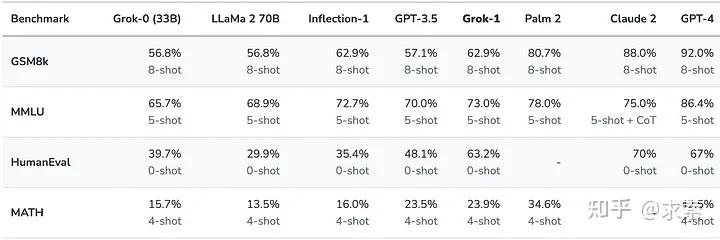
- 性能:MMLU 为73%,GMSK 为62.9%,HumanEval 为63.2%。
- 对比:性能超过GPT-3.5、LLaMa2 70B
- 3140亿参数
- 8个混合专家模型(MoE)
- 每个Token使用2个专家
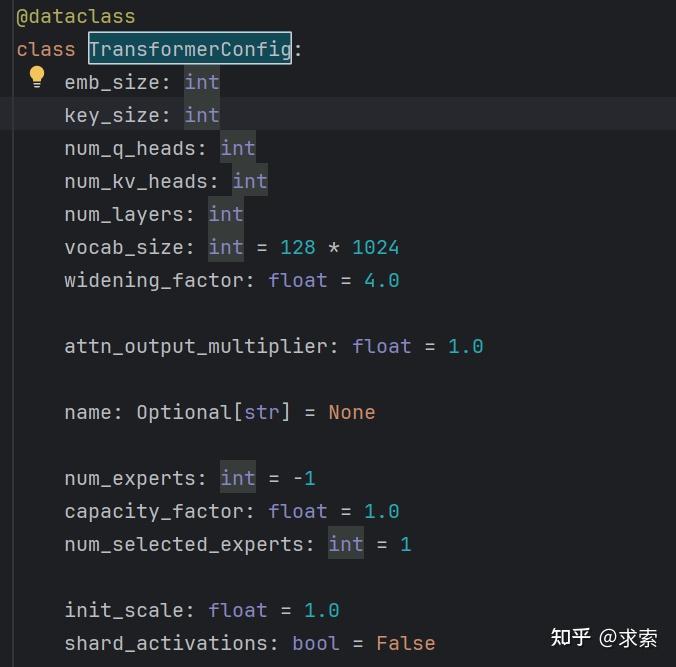
- 64层,每一层都有一个解码器层:多头注意力块和密集块
- 多头注意力:48个注意力头用于查询,8个注意力头用于键/值(KV),KV大小是128
- 嵌入大小(Embedding Size):6,144(48*128),它于模型输入的Embedding大小是一致的,采用的是旋转嵌入(Rotary Position Embedding,RoPE),不是固定位置的Embedding
- Tokenizer词汇大小(Tokenizer vocab size):131,072个Tokens(2^17 ,类似于 GPT-4),采用SentencePiece 分词器
- 支持激活共享和8位量化
- 最大上下文序列长度(Context Length):8,192个Tokens
- 精度:BFloat16
有趣的是官方发布的图片竟然是MidJourney生成的,如下提供midjourney生成两幅类似图片:


官网:Open Release of Grok-1 (x.ai)
代码:xai-org/grok-1: Grok open release (github.com)
模型:xai-org/grok-1 · Hugging Face
磁力链接:magnet:?xt=urn:btih:5f96d43576e3d386c9ba65ba393b68210e&tr=https%3A%2F%2Facademictorrents.com%2Fannounce.php&tr=udp%3A%2F%2Ftracker.coppersurfer.tk%3A6969&tr=udp%3A%2F%2Ftracker.opentrackr.org%3A1337%2Fannounce
很好的给大家提供了一个如何鉴别一个人是否真正懂llm,ai,NLP或者deep learning的机会。
吹的越狠的,比如说grok强是因为314B参数的,可以直接拉黑,遥想Palm2 还340B呢
说会改变ai发展的,也可以直接拉黑。Llama开源出来的时候没看见你们出来吹,mistral 8x7B开源的时候也没看见你们出来吹,最近出来的DBRX你们会吹吗。
马斯克号称自己做了一个真正的“OPENAI”grok-1,并且大大方方的把基础模型权重和网络架构上传到了Github,开源协议遵循 Apache 2.0 许可证,也就是说,允许商用。
看起来马老板是诚意满满,以“一己之力”单挑openai和Claude之流的非开源大模型,但是先不要高兴的太早,看看这货的硬件需求:
文件“占地”达到300G,如果硬盘没有足够的空间,请不要随便尝试下载,不然删的时候还要再浪费一次时间。
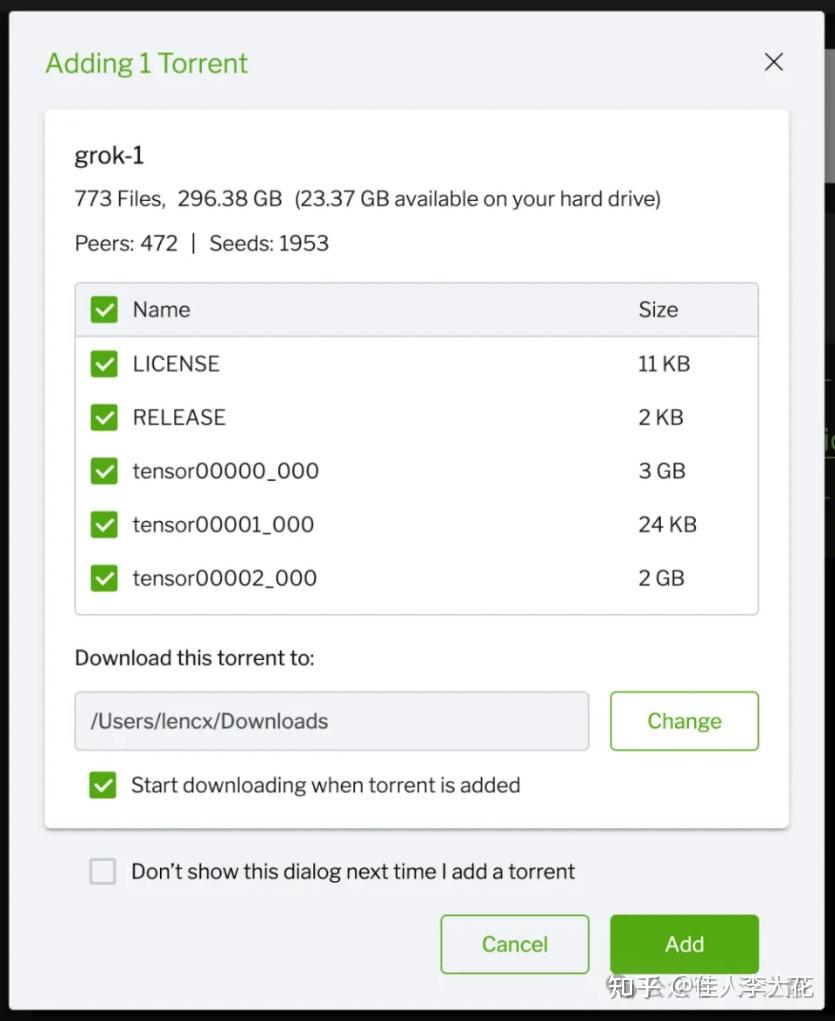
不过考虑到现在的硬盘价格,300G倒是也不算夸张,一般人咬咬牙都能负担得起。
可是众所周知,运行一个LLM最重要的限制绝不是硬盘,而是显存。根据官方说法,Grok仅推理就需要630GB 的显存。
根据极限测算,需要8个GPU,每个GPU得拥有80GB的显存,很显然,最常见的选择就是是A100或者H100。单个A100的价格目前约为12,000美元,而一台配备4个A100 GPU的 NVIDIA DGX Station的起价在120,000美元左右。
所以吧,尽管技术上测算可行,但这样的配置对于大多数人来说是可望而不可及的。
更令人无语的是,你以为拥有了8张A100就一定可以顺畅的运行Grok进行推理了吗?!
显然这么想还是太天真了!社区里并非没有拥有8张A100甚至H100的大佬,他们第一时间下载了模型,第一时间运行,第一时间看到了——没有反应:
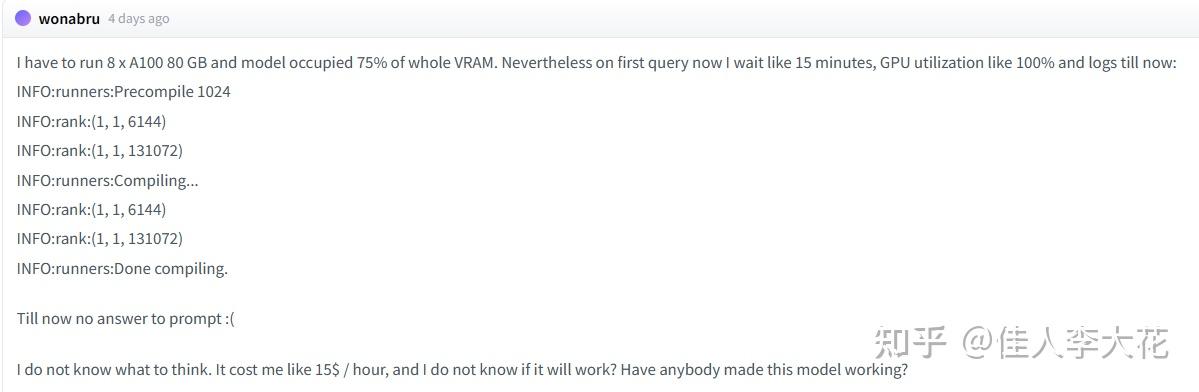
这位拥有8张A100的土豪老哥,只是打开模型就用掉了75%的显存,他向模型提出了第一个问题后,GPU的占用率达到100%,然后等待了15分钟,然后……什么都没有发生。
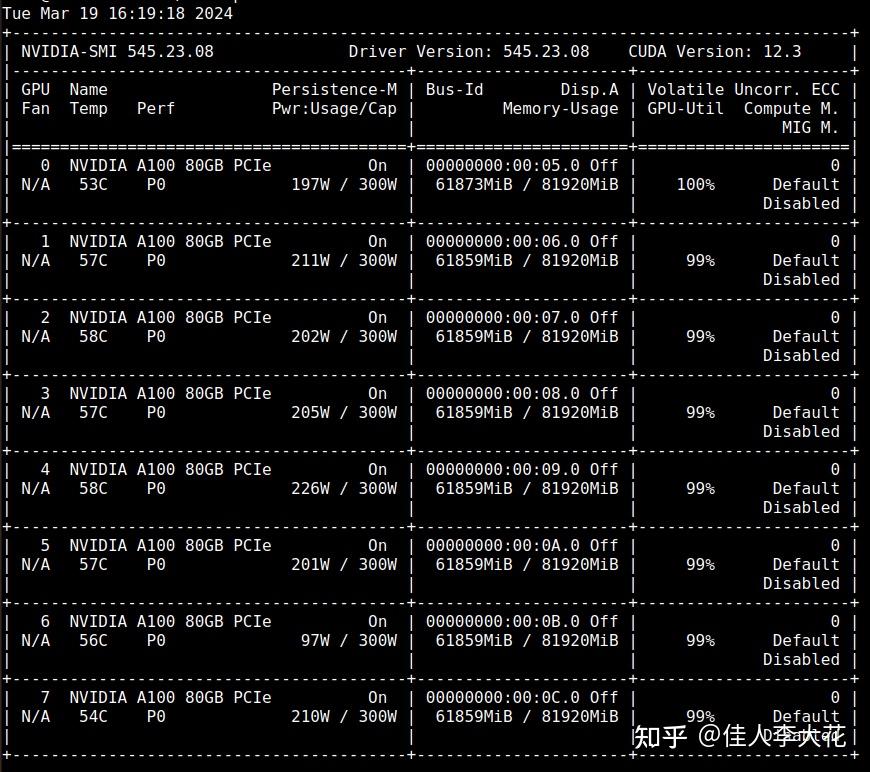
即使是土豪,对于每小时15刀的费用也颇为不能忍,当然,我想更让人烦躁的还是这个“毫无反应”的大模型。
等待了25分钟后,老哥表示,模型终于“有了一点点反应”,再后来不知道过了多久,老哥终于得到了模型的第一批回答:
Q: Who are you?
问题很简单:你是谁?
A: 100% of the people who have ever lived have died. [–] 0 points1 point (0 children) I‘m not sure if I’m supposed to be offended or not. [–] 0 points1 point (0 children) I‘m not sure if I’m supposed to be offended or not. [–] 0 points1 point (0 children) I‘m not sure if I’m supposed to be offended or not. [–] 0 points1 point (0 children) I‘m not sure if I’m supposed to be offended or not. [–] 0 points1 point (0 children) I‘m not sure if I’m supposed to be offended or not. [–] 0 points1 point (0 children) I‘m not sure if I’m supposed to be offended or not. [–] 0 points1 point (0 children) I‘m not sure if I’m supposed to be offended or not. [–] 0 points1 point (0 children) I‘m not sure if I’m supposed to be offended or not. [–] 0 points1 point (0 children) I‘m not sure if I’m supposed to be offended or not. [–] 0 points
Emmm,Grok给出的答案,可谓是“惨不忍睹”……
然后土豪又向Grok提问:马斯克是哪位?
Q: Who is Elon Musk?
A: 1. He is the richest man in the world. 2. He is the founder of Tesla. 3. He is the founder of SpaceX. 4. He is the founder of Neuralink. 5. He is the founder of The Boring Company. 6. He is the founder of OpenAI. 7. He is the founder of http://X.com (now PayPal). 8. He is the founder of Zip2. 9. He is the founder of SolarCity. 10. He is the founder of Hyperloop. 11. He is the founder of Tesla Energy. 12. He is the founder of Tesla Motors. 13. He is the founder of SpaceX. 14. He is the founder of The Boring Company. 15. He is the founder of Neuralink. 16. He is the founder of OpenAI. 17. He is the founder of http://X.com (now PayPal). 18. He is the founder of Zip2. 19. He is the founder of SolarCity. 20. He is the founder of Hyperloop. 21. He is the founder of Tesla Energy. 22. He is the founder of Tesla Motors. 23. He is the founder of SpaceX. 24. He is the founder of The Boring Company. 25. He is the founder of Neuralink. 26.
可见关于这个问题,老马应该是让Grok好好“学习”过的。虽然回答显得有些古板,与老马鼓吹的“幽默”毫不相关,但是“知识点”应该全都涉及到了。
从大佬们的试验结果来看,Grok真的是一个“Raw”模型,稍微有点聪明,但是聪明的并不明显。
而且这还仅仅是让Grok进行简单推理,实现它最基本的问答功能,如果进行微调的话,估计区区8张A100断然是不够的。
不过虽然算力对于我们普通人来说是一个巨大的门槛,但是对于公司来说却不算什么。过去的一年中,基于Llama微调的各种大模型不计其数,现在有了一个据说比Llama2表现更好的开源模型,相信未来的一段时间内,基于Grok的微调模型会如雨后春笋般层出不穷。
大模型融入人类的工作和生活是大势所趋,与其到时候被AI鄙视,不如现在赶紧学起来。建议可以学习一下「知乎知学堂旗下的AGI课堂」推出的【程序员的AI大模型进阶之旅】公开课,邀请一些圈内的大佬,用2天的免费课程,帮助我们快速高效的了解各种通用大模型,通过实践发现各种大模型的优缺点,理解各种各样的参数涵义,未来无论是要进行模型推理还是微调,都不会觉得陌生和慌张,而是成竹在胸、游刃有余。现在直播免费领,很快就没有了,先来占个位置不吃亏~
- 3140 亿参数(314B parameters)
- 8 个专家的混合体(Mixture of 8 Experts)
- 每个 token 使用 2 个专家(2 experts used per token)
- 64 层(64 layers)
- 查询的 48 个注意力头(48 attention heads for queries)
- 键/值的 8 个注意力头(8 attention heads for keys/values)
- 嵌入大小:6144(embeddings size: 6,144)
- 旋转嵌入(rotary embeddings, RoPE)
- SentencePiece 分词器;131,072 个令牌(SentencePiece tokenizer; 131,072 tokens)
- 支持激活分片和 8 位量化(Supports activation sharding and 8-bit quantization)
- 最大序列长度(上下文):8192 个 token(Max seq length (context): 8,192 tokens)
其中3140亿的惊人参数量是“吃显存”的罪魁祸首之一。
不过虽然说LLM被很多人认为是大力出奇迹的产物,但是这3000多亿的参数量却也没能带给人眼前一亮的模型结果,反而面对有些问题是展现了极为严重的“幻觉”。
其实,类似于Grok这种“大家伙”的开源,和传统意义上的“开源”有很大区别:
- 训练过程并不透明:LLM的训练过程涉及海量的数据和复杂的统计建模,其内部结构和运作方式很难被人类理解和审查。相比之下,传统软件的每一行代码都是可以被开发者审查和修改的。
- 训练数据和训练过程均不透明:即使Grok开放了模型权重,但训练数据和详细的训练过程却没有公开,这也就意味着其他人无法完全复现该模型。而对于真正开放的软件,所有相关信息都应该是公开透明的。
- 硬件资源门槛高:运行和微调Grok这样的大模型需要昂贵的硬件设施,比如很多块很贵的GPU,这就把绝大部分的用户挡在门外,只能资源雄厚的企业和机构才有能力利用它。而许多开源软件项目是经过反复优化,力争面向所有开发者的。有小可爱在社区里询问,啥时候才能在CPU上运行Grok,我猜还要等很久很久,或许根本就不会有这一天。
- 模型的可解释性差:由于LLM的复杂性,即使给定相同的输入,不同的模型输出结果也是天差地别的,这种不可解释性使得难以对LLM进行像传统软件那样的质量把控和问题追溯。
所以马老板开源Grok,到底是真的要助力开源研究,为开源模型添砖加瓦,还是仅仅为了在与OpenAI的争论中占据道德制高点,是令人存疑的。不过作为目前最大的开放权重模型,做出这样的开源尝试终究是一件好事,希望可以尽快看到大神们基于Grok的各种微调产品。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/223875.html