
本文是一篇从实际应用的角度出发,探讨如何在智能体应用中配合使用DeepSeek-OCR和docling进行PDF文档解析的实践教程。
通过阅读本文章,你将学会如何在实际编码中使用DeepSeek-OCR模型。同时,我还会将DeepSeek-OCR解析的结果和传统OCR模型的解析结果进行比对,为你揭示DeepSeek-OCR的效果,到底有多好。
本文包含该项目的完整源码,你可以在文章的末尾获得它。
DeepSeek-OCR最近真是火出圈了,网上铺天盖地的文章和视频全都是介绍它的,毕竟使用上下文光学压缩(Contexts Optical Compression)来替代文字编码token的概念看起来太过美好了。
然而深入阅读这些文章你就会发现,它们基本都是把官方博客的那几张图表转发过来,然后开始夸这个模型怎么怎么好,光学压缩将如何改变大模型对于上下文的理解之类的blah…blah…
对于具体怎么在实际项目中使用这个模型却是一点都没有讲。
所以它只在实验室中美好而不能在实际项目中使用吗?那可不行。
在今天的文章里,我会从实际编码的角度,为你讲解如何在docling的VlmPipeline中使用DeepSeek-OCR来进行PDF解析的方法。
我选用英伟达2026财年Q2财务报告来作为测试文件,下面是解析效果截图:
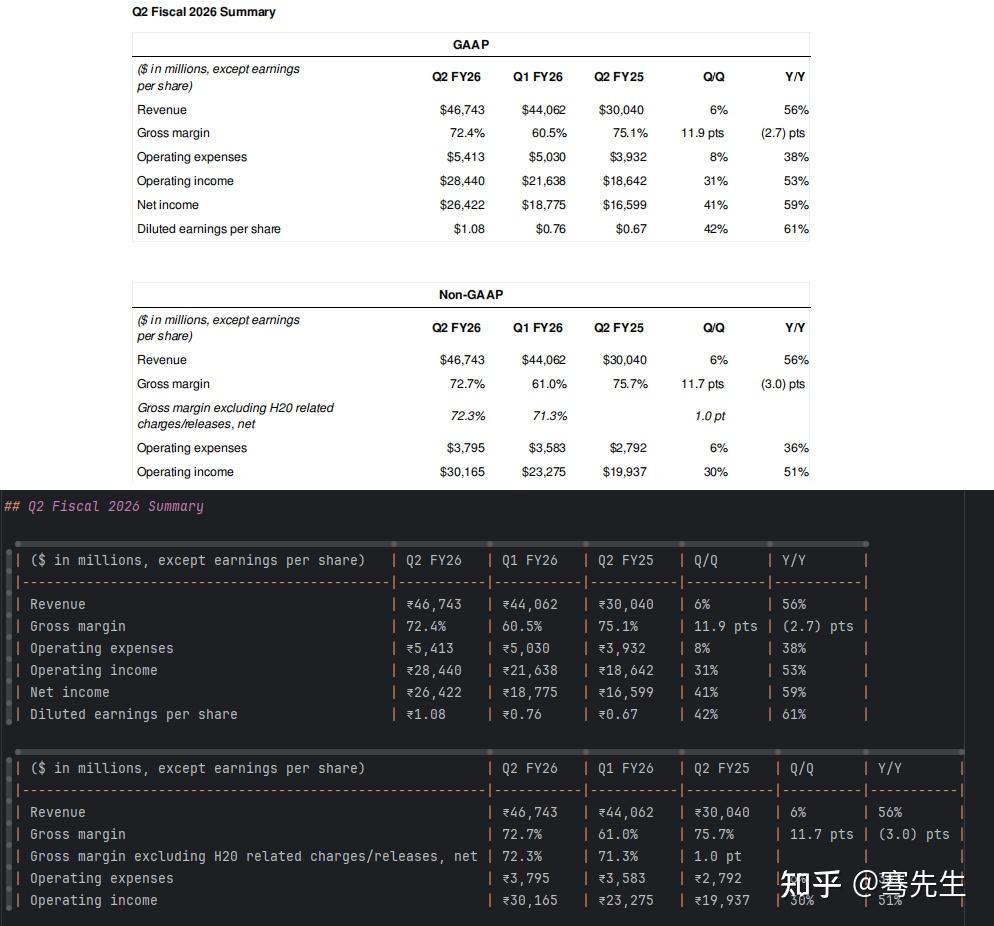
我还会配合cognee,实现对解析后的文本进行Agentic RAG的能力。
虽然DeepSeek-OCR主打的是上下文光学压缩这个概念,但是我认为对PDF的OCR精准性是对一个vlm模型的基本要求。
DeepSeek团队在官方博客中提到他们使用PaddleOCR进行数据标注,因此在文章的后半部分,我会将DeepSeek-OCR的PDF解析效果与PaddleOCR的效果进行对比,让你更直观地评估DeepSeek-OCR是否真有传说中的那么有效。
系好安全带,Let‘s Go.
在编码开始前,我们需要安装一些使用docling和DeepSeek-OCR所必须的依赖项。
由于我采用vllm server的方式部署DeepSeek-OCR模型来使用,所以本地项目中我不必再安装vllm相关的依赖。
你只需要安装docling,docling[vlm]和hf-xet这三个依赖即可。
要配合cognee进行Agentic RAG,你需要安装cognee>=0.3.6和starlette>=0.48这两个依赖。注意版本号,低于0.48版本的starlette会导致cognee报错。
我们需要使用PaddleOCR对比DeepSeek-OCR的PDF解析效果。为了方便使用,我们选用了onnxruntime版本的rapidocr实现。因此你还需要安装这两个依赖。
不用担心,在我的源码库的pyproject.toml文件里,对这些依赖项都已经处理好了,你只需要执行pip install –upgrade -e .就可以自动安装。
我使用以OpenAI api兼容模式部署的DeepSeek-OCR模型(当然你也可以找一个可以提供模型服务的供应商),所以我需要在.env文件里配置一下API KEY和BASE URL:
OCR_MODEL=“deepseek-ai/DeepSeek-OCR” OCR_API_KEY=
OCR_BASE_URL=
为了与传统的LLM客户端相区分,我选择使用OCR_API_KEY和OCR_BASE_URL这两个key。你也可以在后续的代码里自定义这两个key。
为了使用cognee,你还需要增加LLM和Embedding model相关的配置,由于不是本文的重点,因此不过多介绍,你可以在这里了解详情:
# Cognee LLM Provider setup LLM_PROVIDER=“openai” LLM_MODEL=“openai/Qwen/Qwen3-30B-A3B-Instruct-2507” LLM_API_KEY=
LLM_ENDPOINT=
LLM_RATE_LIMIT_ENABLED=“true” LLM_RATE_LIMIT_REQUESTS=“600” LLM_RATE_LIMIT_INTERVAL=“60”
Cognee Embedding model setup
EMBEDDING_PROVIDER=“custom” EMBEDDING_MODEL=“openai/BAAI/bge-m3” EMBEDDING_DIMENSIONS=“1024” EMBEDDING_API_KEY=
虽然网上已经有了一些使用DeepSeek-OCR进行PDF解析的代码示例,但是大多是只停留notebook上试验性代码。
我希望我们的解析程序是正经的,适合企业级应用部署的,所以我会以一种非常模块化的方式来设计代码。
对于企业级应用来说,从头开始写如何分割PDF文件,转化为图片再交给视觉模型来识别的代码有点太蠢了,我们应该充分利用手头已有的工具,在这里我指的是docling。
因此,我们整个模块的运行流程应该由如下这个示意图所示:
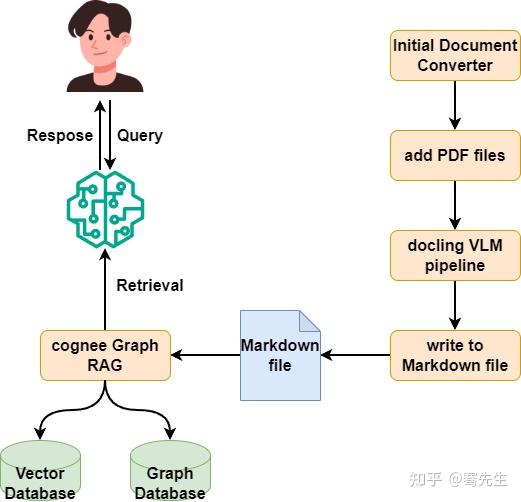
cognee是可选的,你可以随意更换其他RAG模块。
我们以面向对象的方式组织代码,该代码存放在源代码仓库的ocr_agentic_rag.py文件里。
首先定义一个OCRAgenticRAG类,所有解析操作都会在这个模块内进行。
import os import asyncio from pathlib import Path from tempfile import gettempdirfrom dotenv import load_dotenv from docling.datamodel.base_models import InputFormat from docling.datamodel.pipeline_options import (
VlmPipelineOptions ) from docling.datamodel.pipeline_options_vlm_model import (
ApiVlmOptions, ResponseFormat ) from docling.document_converter import (
DocumentConverter, PdfFormatOption ) from docling.pipeline.vlm_pipeline import VlmPipeline import cognee from cognee.infrastructure.databases.vector.embeddings.config import EmbeddingConfig
from common.utils.project_path import get_project_root, get_current_directory
load_dotenv(get_project_root() / “.env”)
class OCRAgenticRAG:
...最核心的方法有两个:_openai_compatible_vlm_options和_get_docling_converter。
由于我们不采用requests的方式直接与DeepSeek模型进行通讯,而是交由docling的pipeline去完成,所以我们需要在_openai_compatible_vlm_options方法里完成vlm模型客户端的配置:
class OCRAgenticRAG: ... @staticmethod def _openai_compatible_vlm_options( model: str = "", prompt: str = "Convert these pdf pages to markdown.", response_format: ResponseFormat = ResponseFormat.MARKDOWN, base_url: str = "", temperature: float = 0.7, max_tokens: int = 4096, api_key: str = "", skip_special_token = False, ): ocr_model = model or os.getenv("OCR_MODEL") headers = {} if api_key: headers["Authorization"] = f"Bearer {api_key}" headers["Content-Type"] = "application/json" options = ApiVlmOptions( url=f"{base_url}/chat/completions", params=dict( model=ocr_model, max_tokens=max_tokens, skip_special_token=skip_special_token, ), headers=headers, prompt=prompt, timeout=90, scale=1.0, temperature=temperature, response_format=response_format, ) return options接着,我们要在_get_docling_converter方法里,配置docling的pipeline_options,让docling能够使用刚刚定义的vlm配置来处理PDF文件:
class OCRAgenticRAG: ... def _get_docling_converter( self, api_key: str = "", base_url: str = "", ) -> DocumentConverter: pipeline_options = VlmPipelineOptions( enable_remote_services=True ) pipeline_options.vlm_options = self._openai_compatible_vlm_options( api_key=api_key, base_url=base_url ) doc_converter = DocumentConverter( format_options={ InputFormat.PDF: PdfFormatOption( pipeline_options=pipeline_options, pipeline_cls=VlmPipeline, ) } ) return doc_converter定义完docling PDF converter后,我们要在_ocr_pdf方法里将PDF文件解析为Markdown格式的md文件。该方法支持一次处理多个PDF文件。为了方便评估和跟踪效果,我会把处理好的md文件暂存到一个临时目录里。
class OCRAgenticRAG: ... def _ocr_pdf(self, source_data: str | list[str]) -> list[str]: if not isinstance(source_data, list): source_data = [source_data] output_files = [] for source_file in source_data: result = self.converter.convert(source_file) markdown_str = result.document.export_to_markdown() source_filename = result.input.file.stem out_file = self._write_to_file(self.temp_dir, source_filename, markdown_str) output_files.append(out_file) return output_files最后是添加文件处理的入口方法:
class OCRAgenticRAG: ... async def add(self, files: str | list[str]): temp_files = self._ocr_pdf(files) print("All the PDF files have been successfully parsed.")至此,让docling和DeepSeek-OCR协同工作的代码就全部准备好了。如果你还希望添加cognee模块来启用Agentic RAG能力,可以添加以下代码:
class OCRAgenticRAG: ... @staticmethod async def clear(): await cognee.prune.prune_data() await cognee.prune.prune_system(metadata=True) async def add(self, files: str | list[str]): temp_files = self._ocr_pdf(files) print("All the PDF files have been successfully parsed.") await self.clear() await cognee.add(temp_files) await cognee.cognify() @staticmethod async def search(query: str) -> str: results = await cognee.search( query_text=query ) return "\n".join([str(result) for result in results])接下来我们就写个简单的main方法来测试这个解析模块的运行效果。
if __name__ == "__main__": ocr_rag = OCRAgenticRAG(temp_dir=get_current_directory()/"temp") async def main(): source_dir = get_current_directory() / "temp" pdf_files = [ source_dir / "NVIDIAAn.pdf" ] await ocr_rag.add(pdf_files) result = await ocr_rag.search(query="How much was Nvidia’s revenue in Q2 Fiscal 2025?") print(result) asyncio.run(main())我们选择英伟达2026财年Q2的财务报告来进行解析,对于金融数据分析来讲,对财报进行解读是ai agent最典型的应用场景。
我会搜索一个问题来评估cognee是否已经索引到正确的文本:

但是,咦,明明英伟达2025财年Q2的营收这个数据在PDF里是有的,为什么cognee为找不到?
由于前面的RAG测试过程中,我们发现有文本索引不到的情况,所以我觉得我有必要检查一下DeepSeek-OCR解析出来的Markdown文件的质量。
经过与原始PDF文件的比对,我发现在文档的表格部分,Markdown文件出现了较多错误。特别是多表头表格,行缺失和列缺失都特别明显。
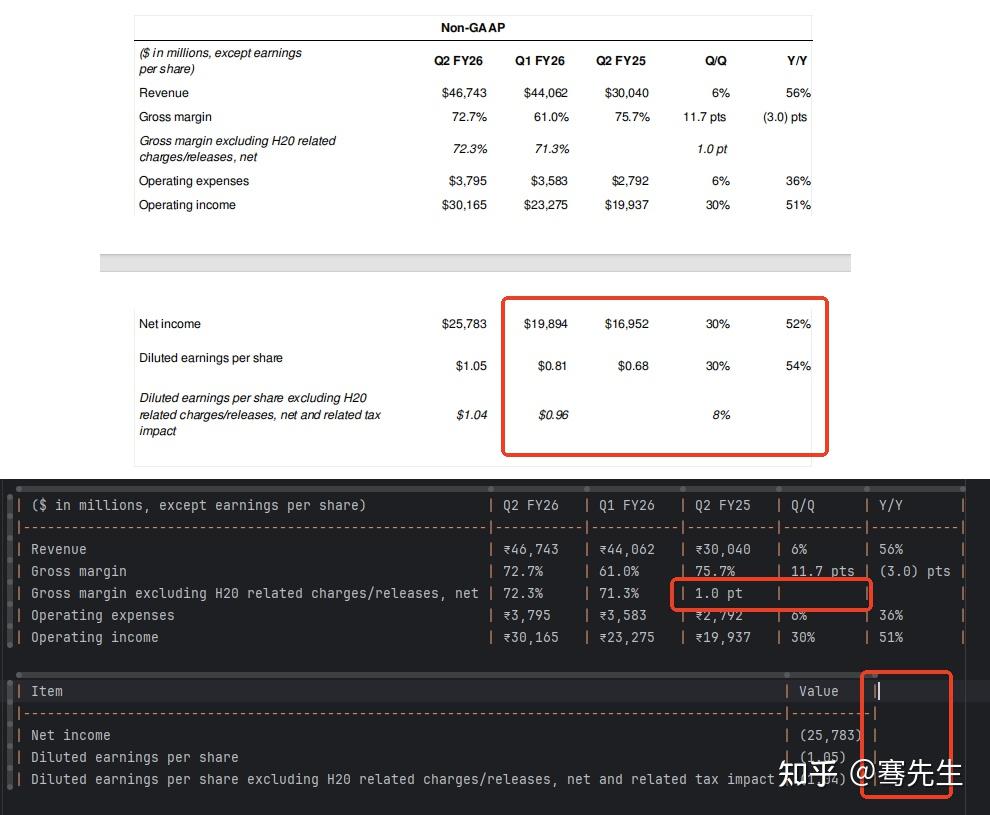
但是慢着,根据官方文档的说法,DeepSeek-OCR应该可以保证有97%的解析准确率,而且这个模型也不至于错的这么离谱吧?
会不会是这个PDF文件本身就难以解析呢?我觉得我应该建立一个对照组。
由于DeepSeek团队在他们的Blog上提到过他们使用PaddleOCR进行训练数据的标注。所以我打算只用PaddleOCR对测试文档再解析一次,看看是否真的是文档的问题。
docling没有直接提供对PaddleOCR的支持,但是docling支持的RapidOCR模型其实就是PaddleOCR的onnxruntime版本的实现,只是精度会稍微差一点,所以我选择docling加RapidOCR的方式来进行测试。
由于官方文档已经提供了示例,所以这里我就不对代码进行解读了,源码我放在paddle_ocr_docling.py文件里:
from docling.datamodel.base_models import InputFormat from docling.datamodel.pipeline_options import (
PdfPipelineOptions, RapidOcrOptions, ) from docling.document_converter import DocumentConverter, PdfFormatOption
from common.utils.project_path import get_current_directory
def main():
pdf_file = get_current_directory() / "temp/NVIDIAAn.pdf" pipeline_options = PdfPipelineOptions() pipeline_options.do_ocr = True pipeline_options.do_table_structure = True pipeline_options.table_structure_options.do_cell_matching = True ocr_options = RapidOcrOptions( force_full_page_ocr=False, ) pipeline_options.ocr_options = ocr_options converter = DocumentConverter( format_options={ InputFormat.PDF: PdfFormatOption( pipeline_options=pipeline_options, ) } ) doc = converter.convert(pdf_file).document md = doc.export_to_markdown() with open(get_current_directory() / "temp/NVIDIAAn_rapid.md", "w", encoding="utf8") as f: f.write(md) if name == “main”:
main()让我们看看使用RapidOCR解析后的Markdown文件,特别是表格部分。
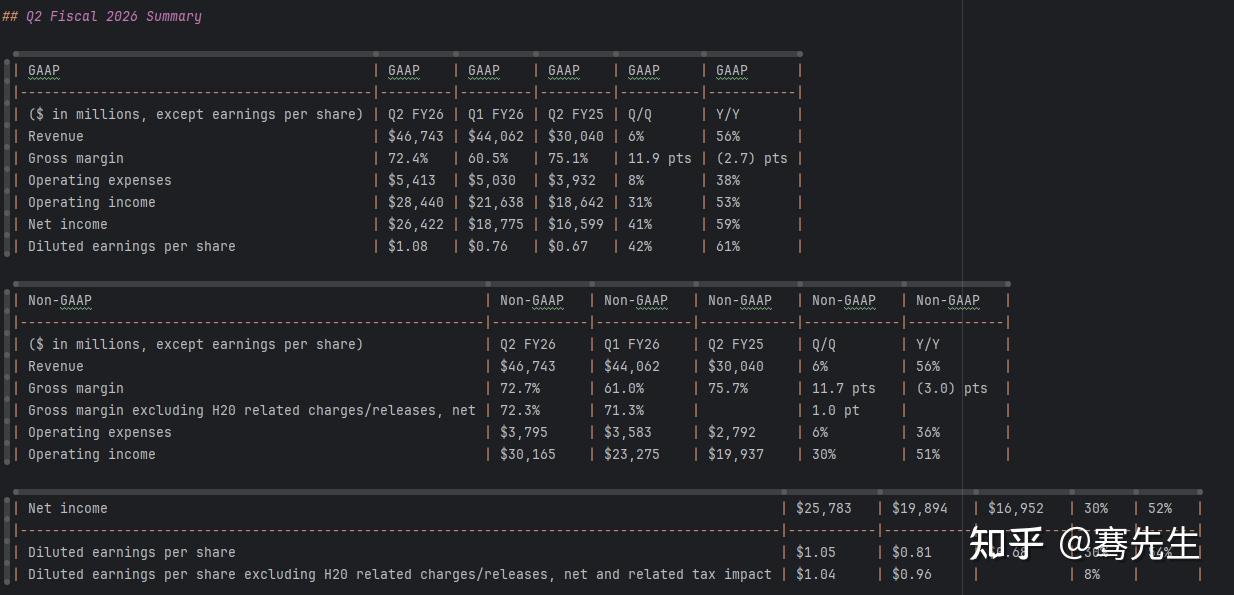
可以看到RapidOCR解析后的Markdown文本,表格数据精度要高很多,基本没有出现数据错位或者丢失。
DeepSeek太过成功了,以至于只要DeepSeek团队有什么新发布,必然会引起一阵轰动。
像这次DeepSeek-OCR模型提出的上下文光学压缩的概念,如果最终证明可行,必然会引起大模型相关技术的又一次革新。
但目前网络上的资料基本以讨论DeepSeek-OCR的概念性文章为主,如何在实际项目中使用该模型的教程还比较少。
所以今天的教程的目标就是为你展示如何在实际项目中结合docling等开源框架来对PDF文件进行解析。
同时我们也需要注意到,作为一个OCR模型,无论是文本型PDF,还是扫描型PDF,DeepSeek-OCR在表格数据处理上暂时都差强人意。这限制了该模型在数据科学领域的使用。
希望后续能够更多的实践出来,诠释DeepSeek-OCR的应用场景。同时如果你有什么看法,也欢迎留言与我讨论。
本文是我的一篇数据科学相关的中文原创文章。
欢迎大家点赞,评论,转发。转发请注明出处。
本文的英文原始版本发表于我的个人博客Data Leads Future。
以下是本教程的源码部分,你可以随意阅读或使用:
https://github.com/qtalen/agentic-ai-playground/tree/main/08_DeepSeek_OCR_Agentic_RAG
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/222950.html