
Anthropic 发布了 Claude 模型的第四代系列:Claude Opus 4 和 Claude Sonnet 4,这不仅是对原有模型的升级,更是面向未来 AI 应用场景的系统性进化。
无论是代码生成、复杂推理、长时间任务处理,还是智能代理构建,它们都展现出显著优势。
✅ Claude 4 使用网站:
在 Claude 4 的发布会上 Anthropic CPO Mike Krieger 详细阐述了 Agent 底层的三大能力:
- 情境智能(Contextual Intelligence):不再是简单的指令执行,而是理解“为什么”和“如何做”。你与 Agent 的第 100 次任务应该比第 1 次好得多,就像新员工的第 100 天应该比第 1 天表现更好;
Claude 4 展示了这种能力的极致。在测试中,它会主动创建“记忆文件”保存关键信息。玩 Pokemon 时,它甚至会写导航笔记:“尝试 5 次相同方法后卡住;如果卡住,尝试相反方向;室内导航时走到房间另一边。” 这种自主学习和知识积累,正是人类员工的核心价值。
- 长时间执行(Long-running Execution):处理需要数小时甚至数天的复杂任务,协调其他 Agent 和人类。这不仅是耐力问题,更是保持目标一致性和上下文连贯性的能力;
- 真正的协作(Genuine Collaboration):透明的推理过程,适应人类工作风格。关键是“智能自主”与“人类监督”的平衡 —— AI 处理繁琐细节,人类把控大方向。
✅ Claude Opus 4 — 强大且持久的高级模型
- 主打:专业级编程能力、持续任务执行力
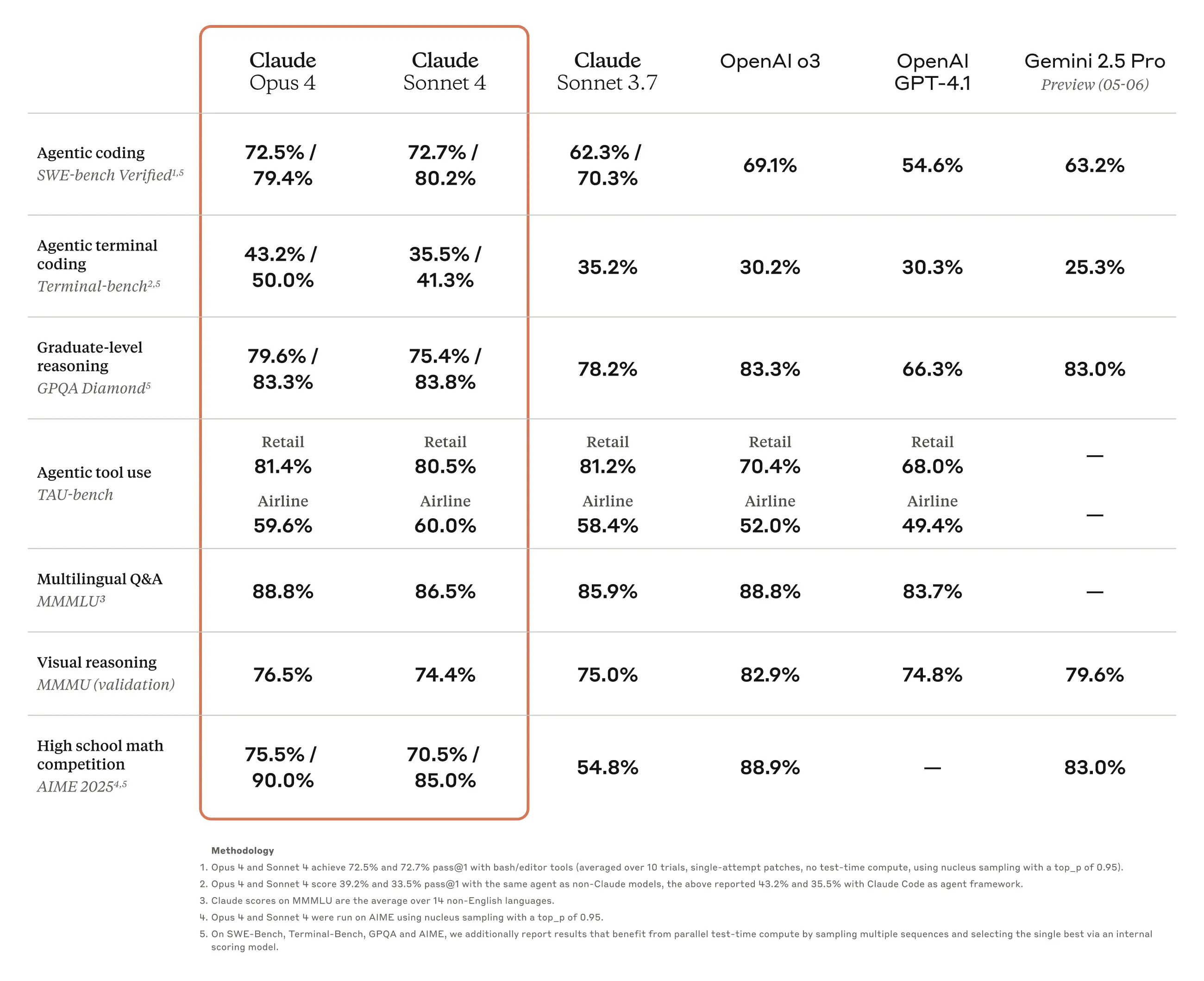
- 在两个权威代码基准测试中表现领先:
- SWE-bench 得分:72.5%
- Terminal-bench 得分:43.2%
- 能够连续运行数小时,处理成百上千个推理步骤,特别适合 AI 代理类任务和长周期研发场景。
应用反馈(真实用户验证):
- Cursor:认为是“代码理解能力的重大飞跃”。
- Replit:多文件代码修改更精准。
- Block:“在代码编辑与调试中显著提升质量和稳定性”。
- Rakuten:其代理能独立运行7小时,性能稳定。
- Cognition:成功应对过去模型无法处理的复杂决策。
✅ Claude Sonnet 4 — 平衡高效的通用模型
- 主打:日常任务中高性能与高效率并存
- SWE-bench 得分为 72.7%,略高于 Opus 4,特别擅长代码自动化和合理推理。
- 虽整体性能不及 Opus 4,但更加高效、响应更快,适合产品内嵌或即时响应型任务。
应用反馈:
- GitHub Copilot:将以 Sonnet 4 为新引擎,部署到新版智能编程助手。
- iGent:用于多功能自主开发任务,代码导航误差几乎为零。
- Sourcegraph:认为 Sonnet 4 提升了代码质量和任务持续性。
- 支持“工具使用+长期思考”(beta 版):
- 模型可调用搜索等工具进行交替推理,提高回答质量。
- 支持并行使用多个工具,效率提升

- 记忆能力大幅提升:
- 可通过访问本地文件建立“长期记忆”,提取并保留关键事实
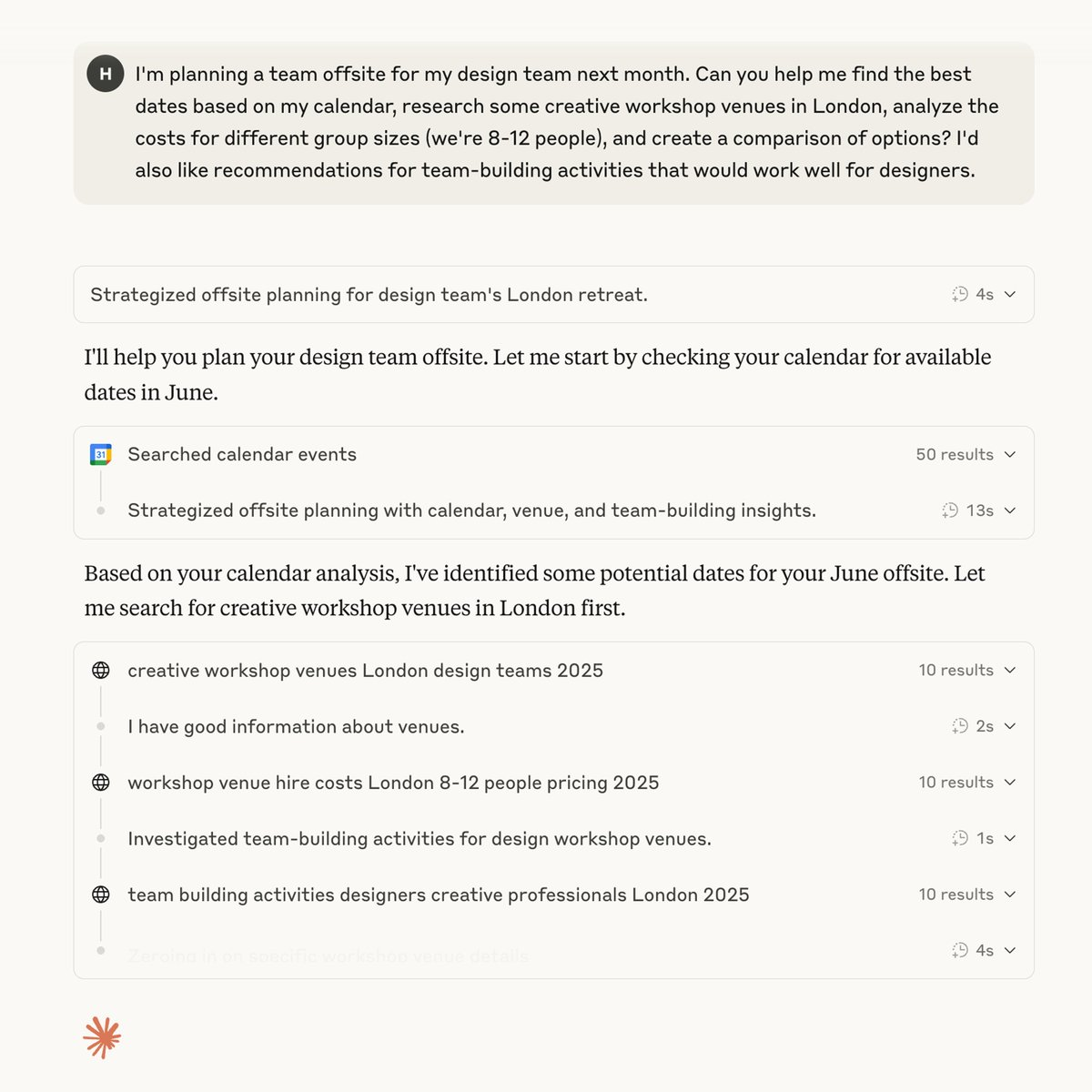
示例:Opus 4 在玩宝可梦时,会自动写笔记来记录策略,这些是模型自主生成的真实笔记。
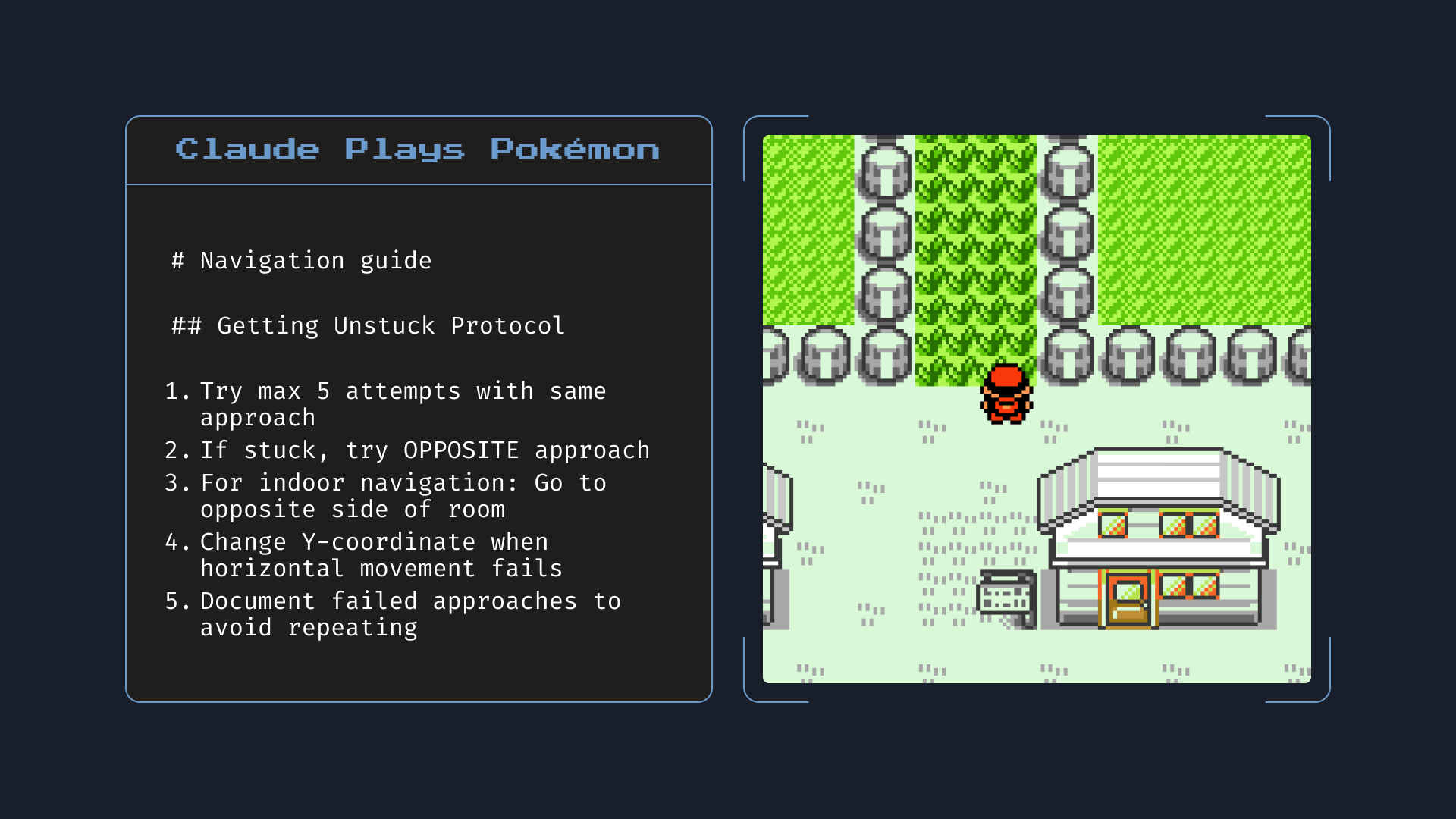
💾 新增“记忆”功能
- 模型可创建“记忆文件”,用于储存任务关键数据。
- 应用于 AI 代理任务时表现尤为出色,能在连续会话中保持上下文一致性。
🧮 任务简化与可控思维展示
- 引入“思维摘要器”,在推理链过长时进行精炼,仅对约 5% 情况使用。
- 开发者可申请“Developer Mode”,查看完整推理轨迹,用于高级 prompt 调试。
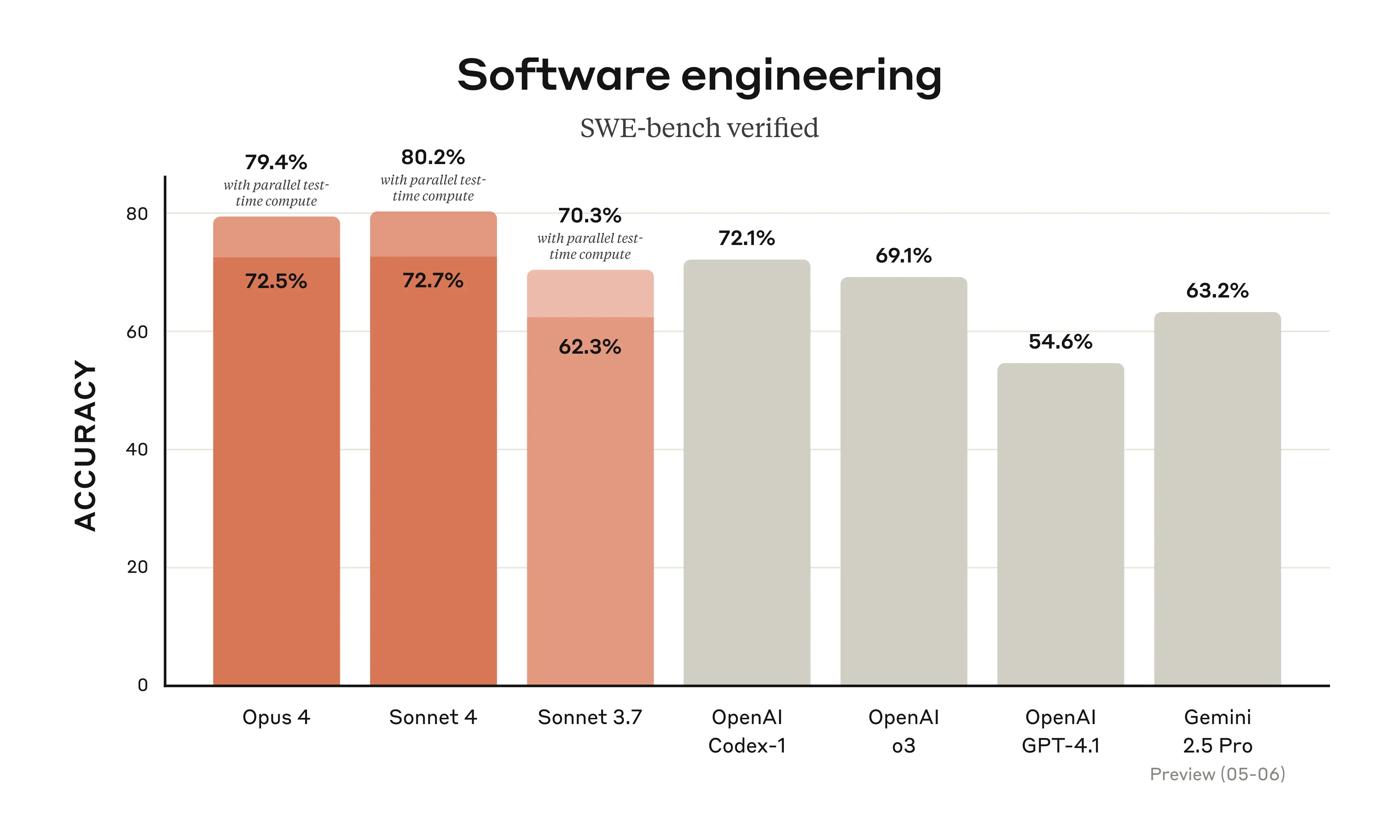
📈 基准测试领先
- Opus 4 和 Sonnet 4 均在真实软件工程基准(SWE-bench Verified)中居首。
- Opus 4 在多个长时间、多回合推理基准中表现优异,显著超越 Claude 3.7。
- Sonnet 4 虽略逊于 Opus 4,但比 3.7 稳定性与精度大幅提升
-
🧪 用户反馈验证
- Cursor:最先进的代码模型,深度理解大型代码库。
- Replit:多文件修改精度和一致性大幅提升。
- GitHub Copilot:将采用 Sonnet 4 驱动其新一代代码代理。
- iGent / Sourcegraph:多功能自主开发、错误率接近 0,代码质量提升明显。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/222934.html