

Midjourney最近推出了一项新功能:Omni-Reference。“Omni” 是一个源自拉丁语的前缀或词根,意思是 “全部、所有、无所不包”。所以从字面意思来说,Omni-Reference就是全能参考。按照Midjourney的官方说法,Omni-Reference可理解为一种“在图像中加入指定元素”的功能,适用于角色、物体、车辆或非人生物。这其实就是一种通用的主体参考生成。

而且Omni-Reference还支持风格化,也可以和个性化定制(Personalization )、风格参考(style references)及情绪板(moodboards)结合使用。

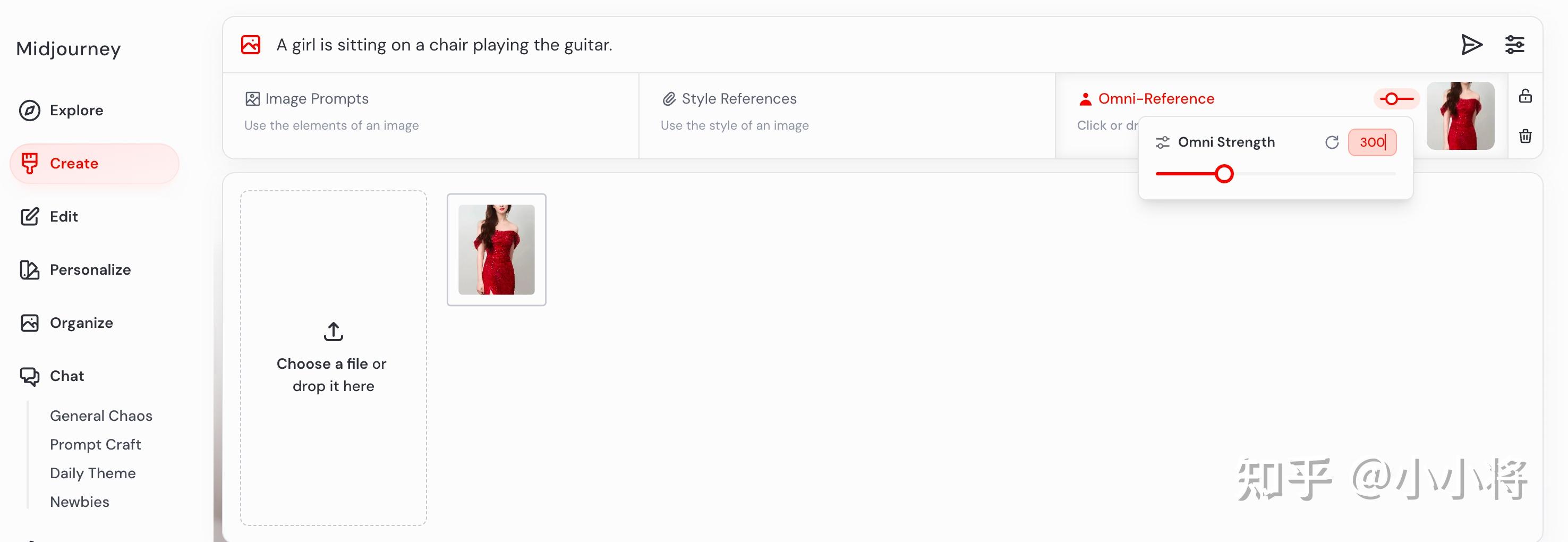
在网页端使用这个功能,只需要将图片拖拽至提示词输入框,放入标注“omni-reference”的区域,通过滑块调节强度。而在Discord 端:输入 –oref 图片链接,并用 –ow 参数控制强度。Omni-Reference提供一个权重系数omini strength(–ow)来控制参考图的严格程度,数值范围为 0-1000(默认100)。如果要进行风格如照片转动漫:降低权重(如 –ow 25),而如果要保留细节(如角色面部/服装):提高权重(如 –ow 400)。
下面我具体做了一些例子的测试。
首先,我拿真实人物进行了测试,输入是一张刘亦菲的全身图。

默认情况下omini strength=100,生成的图像如下所示,生成图像能够遵循文本提示词的指令,但是效果我觉得属于一般,人物的特征比如发型以及衣服基本是保持了,但是细节和原图是不一致的。

然后我又跑了不同omini strength,下面从左到右分别是100、300、500、800和1000。可以看到随着权重的增加,生图的一致性是有提升的,但是也无法做到比较完美的一致性。

接着我来测试一下不同文本提示词下的效果,这里测试了四个不同的提示词,可以看到模型可以很好地响应文本指令,就是一致性一般。
一个女孩站在窗边看书。
一个女孩在公园里和她的狗一起跑步。
一个女孩在树下画画。
一个女孩坐在椅子上弹吉他

那么,模型是否可以响应风格化提示词,这里我输入的是动漫风格,默认权重下,生成的图像是有一定的风格化效果的:

但是和不加任何参考的文生图结果还是相差甚远的,这说明主体参考其实还是会影响风格化文本提示词的响应的。

如果降低权重,比如ow=25,此时风格化效果会好很多,但是一致性变得更差了一些:

Omni-Reference是可以和Style Reference联合使用的,但是实测效果比较一般,可以需要调参数或者抽卡。

最后,补充一些更多样化主体的一些生成效果,包括动漫人物、动物、汽车以及商品。












整体测试下来,Omni-Reference是能够大体上参考输入图的主体的,但是一致性并没有那么完美,效果的随机性比较大,有概率出比较好的例子。
我看了一下Omni-Reference目前只在V6和V7版本支持,更早的版本比如V5是不支持的。我个人觉得Midjourney V6和Midjourney V7都是DiT架构,这里的Omni-Reference在实现上可以是直接将输入图送入VAE提取latents,然后转成latent tokens和noisy latent tokens拼接在一起来送入模型中。这种做法应该是现在DiT架构实现主体参考的主流做法。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/222794.html