
在日常业务场景中,业界普遍使用 DeepSeek 全量版、阿里千问等大型语言模型。与此同时模型生态平台上,还存在大量轻量级模型,其参数规模仅为数 B 级别,甚至如 Qwen3 0.6B 这类更小规格的模型也有其生存空间,与 DeepSeek 671B 的全量版本形成非常大的差异。那么小型语言模型存在的价值和使用场景在哪里。要回答这一问题,企业可从以下维度评估自身实际情况:
- 数据安全合规性
业务场景中涉及的数据是否属于敏感范畴,是否需要满足本地私有化调用的合规要求。
- 任务类型适配性
当前模型调用的核心场景是处理简单指令型任务(如信息检索、基础问答,总结等),还是需要复杂逻辑推理的深度任务(如数据分析,代码生成等)。
- 成本效益分析
实际业务中的 Token 消耗规模如何,api 账单费用是否过高。
如果企业面临的是简单的指令型任务,且有数据本地存储的要求,那么就可以选择本地部署小模型去处理任务,或者作为agent 中的一个节点。
当企业确定适合采用小型语言模型后,模型微调将成为提升模型业务适配性的关键技术手段。模型微调是指在预训练模型的基础上,利用企业特定领域的标注数据,对模型参数进行针对性调整,使其更贴合业务需求。
具体而言,微调存在企业可收集与业务场景相关的文本数据,如行业文档、历史对话记录、产品知识库等,通过监督学习、强化学习等微调方法,优化模型在特定任务上的表现。例如,在智能客服场景中,通过微调可使小型语言模型更好地理解企业产品术语和服务流程,提升回答的准确性与专业性。
微调也可以应用在数据清洗领域,数据清洗是数据预处理的关键环节,其核心目标是将原始的、杂乱无章的文本数据转换为符合企业业务需求的结构化数据格式。通过模型微调技术,企业可训练小型语言模型自动识别文本中的关键信息,并按照预设规则进行结构化转换。
下面以一个客户投诉的场景演示qwen3-0.6B 模型微调和部署过程。
一、任务要求
假设企业有一个从客户投诉文本中抽取客户姓名,地址,联系方式,具体投诉内容的一个任务。
原始数据如下:
张三,上海市徐汇区 110,。要求晚上清空街道给我跑步!
需要以 json 格式返回:
{ “name”: “张三”, “address”: “上海市徐汇区 110”, “email”: “”, “question”: “要求晚上清空街道给我跑步!”}当然这个任务你可以使用 deepseek-R1 或者 Qwen3-235B这些大模型去完成,或者通过python 代码实现,本文以此为例重点介绍模型微调的方法。
二、数据准备
导入库from datasets import Datasetimport pandas as pdfrom transformers import AutoTokenizer, AutoModelForCausalLM, DataCollatorForSeq2Seq, TrainingArguments, Trainer, GenerationConfigfrom peft import LoraConfig, TaskType, get_peft_modelimport torch # 将JSON文件转换为CSV文件df = pd.read_json(‘fake_sft.json’)ds = Dataset.from_pandas(df)ds[:3] model_id = “Qwen/Qwen3-0.6B” tokenizer = AutoTokenizer.from_pretrained(model_id, use_fast=False)tokenizer对大语言模型进行 supervised-finetuning(sft,有监督微调)的数据格式如下:
{ “instruction”: “回答以下用户问题,仅输出答案。”, “input”: “1+1等于几?”, “output”: “2”}其中,instruction 是用户指令,告知模型其需要完成的任务;input 是用户输入,是完成用户指令所必须的输入内容;output 是模型应该给出的输出。有监督微调的目标是让模型具备理解并遵循用户指令的能力。因此,在构建数据集时,我们应针对我们的目标任务,针对性构建数据。
Qwen3 采用的 Chat Template格式如下:
messages = [ {“role”: “system”, “content”: “You are a helpful AI”}, {“role”: “user”, “content”: “How are you?”}, {“role”: “assistant”, “content”: “I‘m fine, think you. and you?”},] text = tokenizer.apply_chat_template( messages, tokenize=False, add_generation_prompt=True, enable_thinking=False)print(text)<|im_start|>systemYou are a helpful AI<|im_end|><|im_start|>userHow are you?<|im_end|><|im_start|>assistant<think>
think> I’m fine, think you. and you?<|im_end|><|im_start|>assistant
LoRA(Low-Rank Adaptation)训练的数据是需要经过格式化、编码之后再输入给模型进行训练的,我们需要先将输入文本编码为 input_ids,将输出文本编码为 labels,编码之后的结果是向量。首先定义一个预处理函数,这个函数用于对每一个样本,同时编码其输入、输出文本并返回一个编码后的字典:
def process_func(example): MAX_LENGTH = 1024 # 设置最大序列长度为1024个token input_ids, attention_mask, labels = [], [], [] # 初始化返回值 # 适配chat_template instruction = tokenizer( f“<|im_start|>system\n{example[‘system’]}<|im_end|>\n” f“<|im_start|>user\n{example[‘instruction’] + example[‘input’]}<|im_end|>\n” f“<|im_start|>assistant\n
\n\n
\n\n”, add_special_tokens=False ) response = tokenizer(f“{example[‘output’]}”, add_special_tokens=False) # 将instructio部分和response部分的input_ids拼接,并在末尾添加eos token作为标记结束的token input_ids = instruction[“input_ids”] + response[“input_ids”] + [tokenizer.pad_token_id] # 注意力掩码,表示模型需要关注的位置 attention_mask = instruction[“attention_mask”] + response[“attention_mask”] + [1] # 对于instruction,使用-100表示这些位置不计算loss(即模型不需要预测这部分) labels = [-100] * len(instruction[“input_ids”]) + response[“input_ids”] + [tokenizer.pad_token_id] if len(input_ids) > MAX_LENGTH: # 超出最大序列长度截断 input_ids = input_ids[:MAX_LENGTH] attention_mask = attention_mask[:MAX_LENGTH] labels = labels[:MAX_LENGTH] return { “input_ids”: input_ids, “attention_mask”: attention_mask, “labels”: labels } tokenized_id = ds.map(process_func, remove_columns=ds.column_names)tokenized_idtokenizer.decode(tokenized_id[0][‘input_ids’])tokenizer.decode(list(filter(lambda x: x != -100, tokenized_id[1][“labels”])))三、加载模型
加载模型并配置LoraConfig
model = AutoModelForCausalLM.from_pretrained(model_id, device_map=“auto”,torch_dtype=torch.bfloat16)modelQwen3ForCausalLM( (model): Qwen3Model( (embed_tokens): Embedding(, 1024) (layers): ModuleList( (0-27): 28 x Qwen3DecoderLayer( (self_attn): Qwen3Attention( (q_proj): Linear(in_features=1024, out_features=2048, bias=False) (k_proj): Linear(in_features=1024, out_features=1024, bias=False) (v_proj): Linear(in_features=1024, out_features=1024, bias=False) (o_proj): Linear(in_features=2048, out_features=1024, bias=False) (q_norm): Qwen3RMSNorm((128,), eps=1e-06) (k_norm): Qwen3RMSNorm((128,), eps=1e-06) ) (mlp): Qwen3MLP( (gate_proj): Linear(in_features=1024, out_features=3072, bias=False) (up_proj): Linear(in_features=1024, out_features=3072, bias=False) (down_proj): Linear(in_features=3072, out_features=1024, bias=False) (act_fn): SiLU() ) (input_layernorm): Qwen3RMSNorm((1024,), eps=1e-06) (post_attention_layernorm): Qwen3RMSNorm((1024,), eps=1e-06) ) ) (norm): Qwen3RMSNorm((1024,), eps=1e-06) (rotary_emb): Qwen3RotaryEmbedding() ) (lm_head): Linear(in_features=1024, out_features=, bias=False))
model.enable_input_requiregrads() # 开启梯度检查点时,要执行该方法
四、Lora 配置
LoraConfig这个类中可以设置很多参数,比较重要的如下
- ”>task_type :模型类型,现在绝大部分
decoder_only的模型都是因果语言模型CAUSAL_LM - target_modules :需要训练的模型层的名字,主要就是
attention部分的层,不同的模型对应的层的名字不同 - r :
LoRA的秩,决定了低秩矩阵的维度,较小的r意味着更少的参数 - lora_alpha :缩放参数,与
r一起决定了LoRA更新的强度。实际缩放比例为lora_alpha/r,在当前示例中是32 / 8 = 4倍 - lora_dropout :应用于
LoRA层的dropout rate,用于防止过拟合
from peft import LoraConfig, TaskType, get_peft_model config = LoraConfig( task_type=TaskType.CAUSAL_LM, target_modules=[“q_proj”, “k_proj”, “v_proj”, “o_proj”, “gate_proj”, “up_proj”, “down_proj”], inference_mode=False, # 训练模式 r=8, # Lora 秩 lora_alpha=32, # Lora alaph,具体作用参见 Lora 原理 lora_dropout=0.1# Dropout 比例)configmodel = get_peft_model(model, config)config
model.print_trainable_parameters()
五、Training Arguments
- output_dir :模型的输出路径
- per_device_train_batch_size :每张卡上的
batch_size - gradient_accumulation_steps : 梯度累计
- num_train_epochs :顾名思义
epoch
args = TrainingArguments( output_dir=“Qwen3_instruct_lora”, per_device_train_batch_size=4, gradient_accumulation_steps=4, logging_steps=1, num_train_epochs=3, save_steps=50, learning_rate=1e-4, save_on_each_node=True, gradient_checkpointing=True, report_to=“none”,)六、模型导入VLLM
进入微调后的文件夹Qwen3_instruct_lora 检查 checkpoint
(vllm) root@wuyou-Standard-PC-Q35-ICH9-2009:# cd Qwen3_instruct_lora/(vllm) root@wuyou-Standard-PC-Q35-ICH9-2009:/Qwen3_instruct_lora# lscheckpoint-50 checkpoint-57把微调后的qwen3 模型和原始模型合并,生成一个可以直接部署的模型。
from transformers import AutoTokenizer, AutoModelForCausalLMfrom peft import PeftModel # 路径设置base_model_path = “/root/qwenmodels” # 本地原始模型lora_model_path = “/root/Qwen3_instruct_lora/checkpoint-57” # 微调后的 checkpoint 路径merged_model_path = “/root/Qwen3-0.6B-merged” # 合并后的新模型保存路径 # 加载基础模型model = AutoModelForCausalLM.from_pretrained(base_model_path, device_map=“cpu”, torch_dtype=“auto”) # 加载 LoRAmodel = PeftModel.from_pretrained(model, lora_model_path) # 合并 LoRA 权重model = model.merge_and_unload() # 保存合并后的模型model.save_pretrained(merged_model_path)tokenizer = AutoTokenizer.from_pretrained(base_model_path, use_fast=False)tokenizer.save_pretrained(merged_model_path) print(f“✅ LoRA 合并完成,模型已保存到: {merged_model_path}”)合并后的模型文件存放在/root/Qwen3-0.6B-merged,使用 VLLM 启动模型,8000 端口监听成功后,使用接口进行任务测试
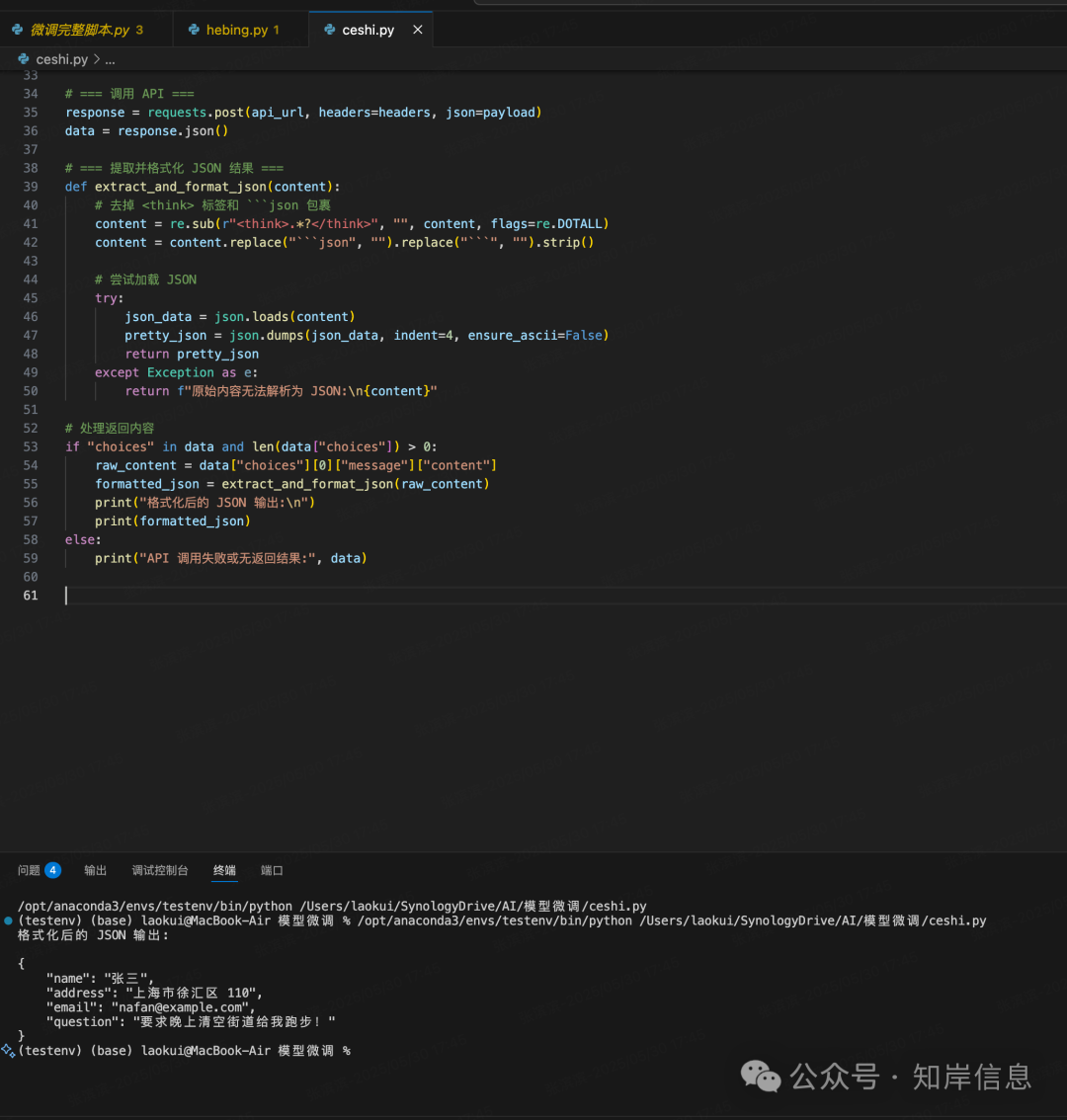
curl http://220.168.146.21:25325/v1/chat/completions \ -H “Authorization: Bearer token-abc123” \ -H “Content-Type: application/json” \ -d ‘{ “model”: “Qwen3-0.6B-merged”, “messages”: [ {“role”: “system”, “content”: “将文本中的name、address、email、question提取出来,以json格式输出,/no_think”}, {“role”: “user”, “content”: “张三,上海市徐汇区 110,。要求晚上清空街道给我跑步!”} ] }’接口返回结果,包含name,address,email,question 的json 格式。实现微调目标。
{“id”:“chatcmpl-99b7aa2c0ee44c7aa5d87a8a03ef61c3”,“object”:“chat.completion”,“created”:,“model”:“Qwen3-0.6B-merged”,“choices”:[{“index”:0,“message”:{“role”:“assistant”,“reasoning_content”:null,“content”:“
json\n{\n \"name\": \"张三\",\n \"address\": \"上海市徐汇区 110\",\n \"email\": \"\",\n \"question\": \"要求晚上清空街道给我跑步!\"\n}\n”,“tool_calls”:[]},“logprobs”:null,“finish_reason”:“stop”,“stop_reason”:}],“usage”:{“prompt_tokens”:61,“total_tokens”:119,“completion_tokens”:58,“prompt_tokens_details”:null},“prompt_logprobs”:null}json 格式化后效果
总结
微调后的 qwen3-0.6B 模型处理简单的指令型任务效率非常高,一张 3090 或者 4090 卡就可以跑的飞快;经过微调后的模型能准确的完成数据清洗的任务;本地部署能符合严苛的数据安全要求,且能为企业省下大笔 API 费用。
感谢你们的阅读和喜欢,作为一位在一线互联网行业奋斗多年的老兵,我深知在这个瞬息万变的技术领域中,持续学习和进步的重要性。
为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。
这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。
这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。如果你愿意花时间沉下心来学习,相信它们一定能为你提供实质性的帮助。
大模型:yyds!全网独一份的AI大模型学习教程资源!!为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/222181.html