
2024年底,DeepSeek发布了新一代大语言模型V3,同时宣布开源。测试结果显示,它的多项评测成绩超越了一些主流开源模型,并且还具有成本优势。
DeepSeek官网地址:https://www.deepseek.com/

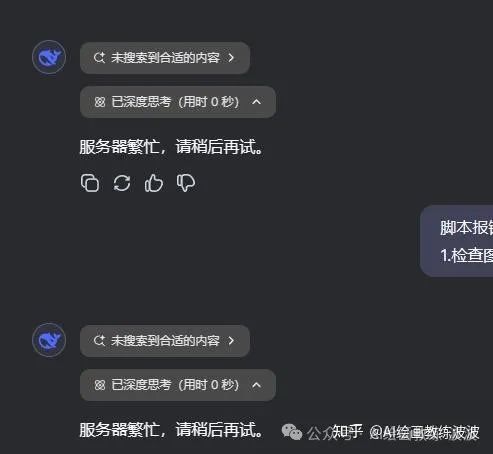
DeepSeek实在是太火了,最近一段时间DeepSeek反应时间巨长,甚至小圆圈转半天最后却提示“服务器繁忙,请稍后再试。”
本文通过在本地部署 DeepSeek+Dify,零成本搭建自己的私有知识库。学会搭建方法后,我们就可以把自己的个人资料,之间输出的文章、日记等所有个人信息上传到本地知识库,打造专属的AI数字助理。
当然,还有其他应用场景,比如搭建企业自有的客服平台,学习可以建立自己的智能题库等等。
一、下载并安装docker
docker网址:https://www.docker.com/
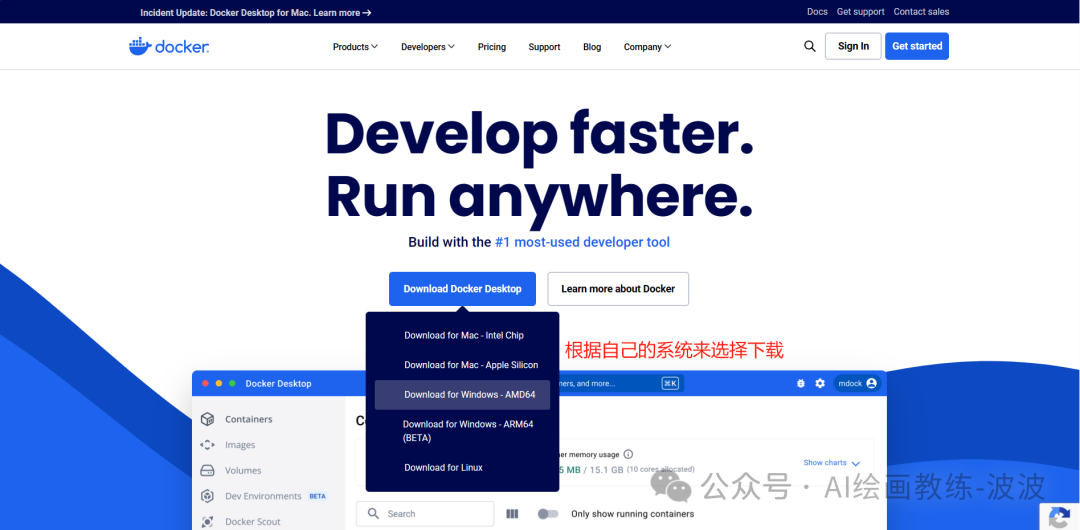
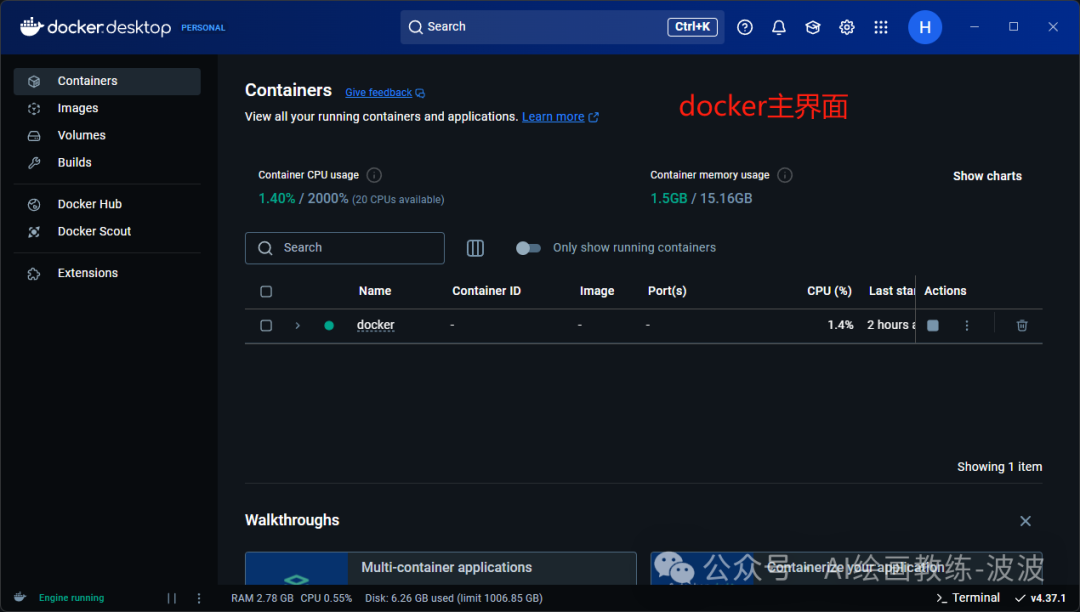
以上图片中docker是已经安装的镜像,刚安装的界面是空白的(特此说明)
二、下载Ollama并安装
Ollama是一个免费的开源工具,网址:https://ollama.com/,允许用户在他们的计算机上本地运行大型语言模型(LLM)。它适用于macOS、Linux和Windows。
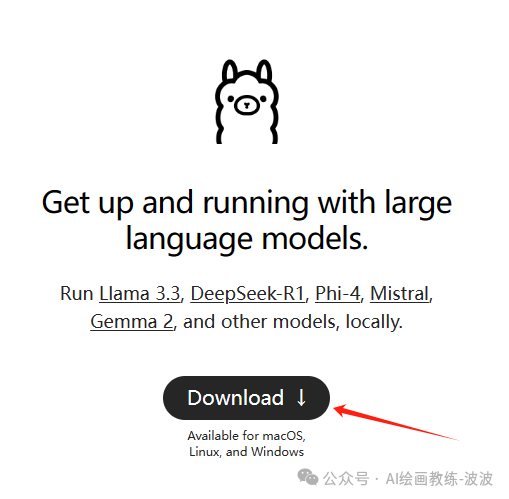
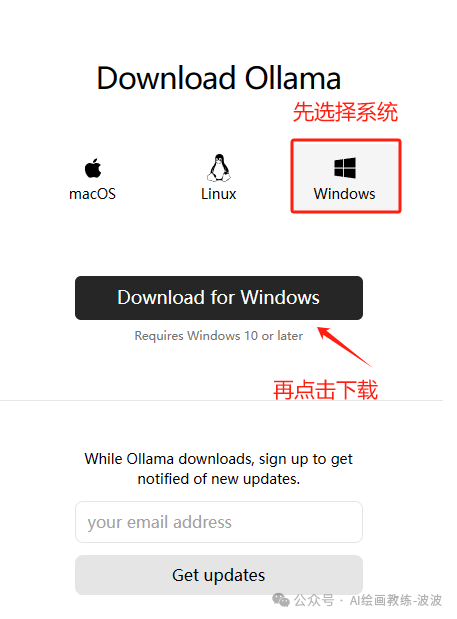
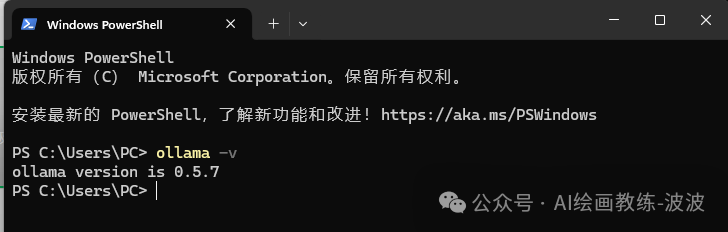
下载完成后,直接进行安装,版本查看:
三、安装deepseek-r1模型
在ollama官网首页的搜索框,点击一下即可看到deepseek-r1在第一个位置,可以看到模型有根据参数分为1.5b,7b,8b,14b,32b,70b,671b等,我们需要根据自己电脑选择下载对应参数的模型。
1、GPU和显存要求
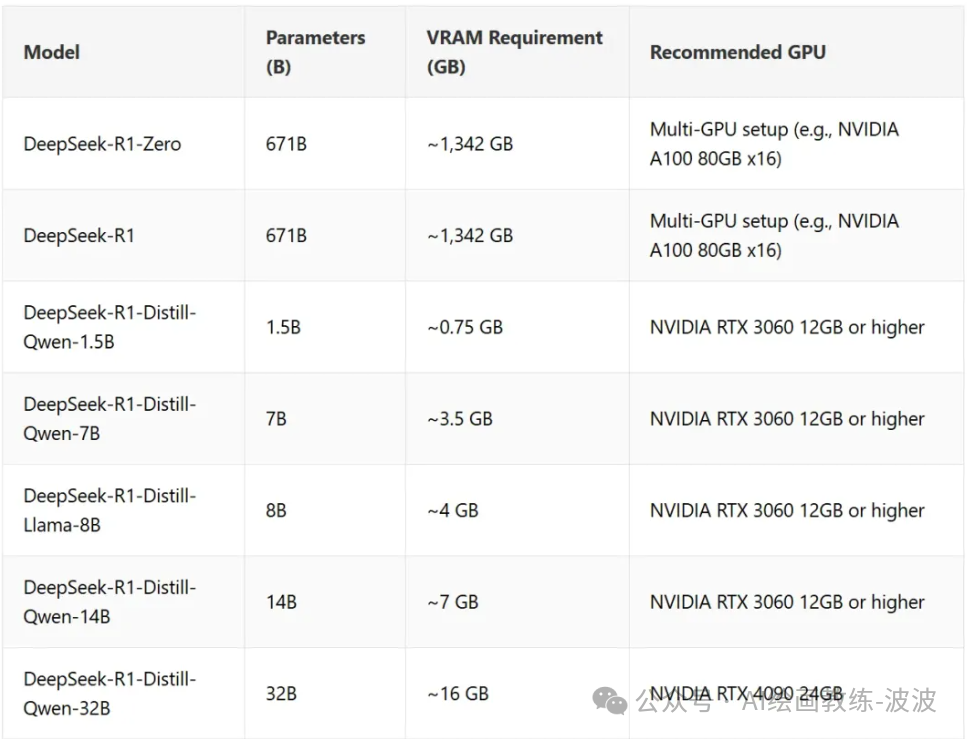
关于显存使用的关键说明:
- 大模型的分布式 GPU 设置:运行 DeepSeek-R1-Zero 和 DeepSeek-R1 需要大量显存,因此需要分布式 GPU 配置(例如,在多 GPU 设置中使用 NVIDIA A100 或 H100)以获得**性能。
- 精简模型的单 GPU 兼容性:精简模型已经优化,可在显存需求较低的单个 GPU 上运行,最低要求仅为 0.7 GB。
- 额外的内存使用:激活、缓冲区和批处理任务可能会消耗额外的内存。
2、根据自己电脑的配置,选择要安装的版本
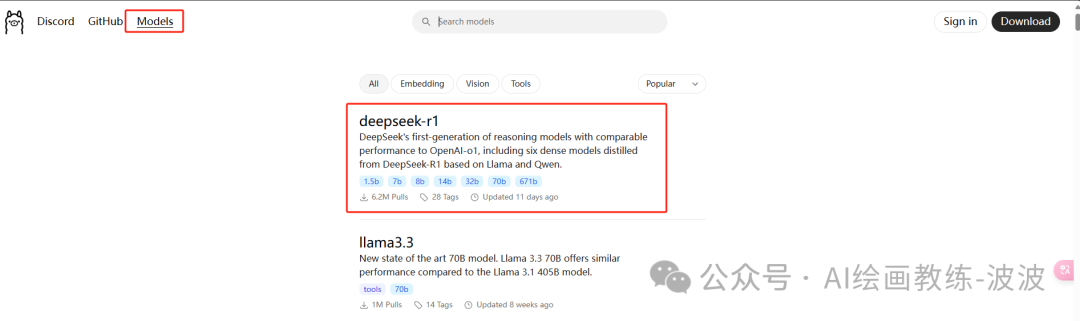
先在主页中点击“models”,然后看到一个就是deepseek-r1,直接点击进去,
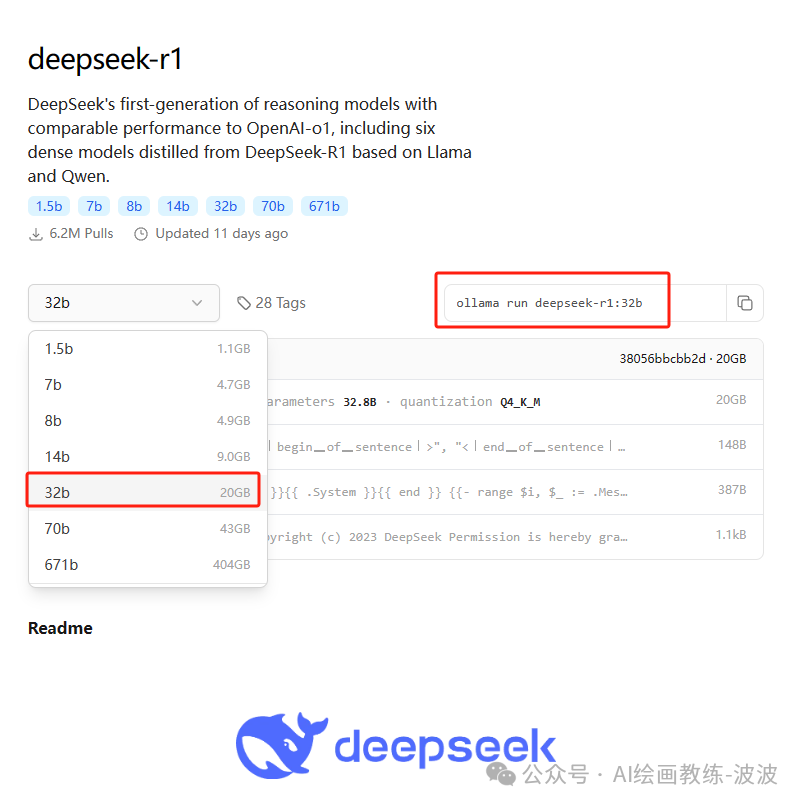
3、安装deepseek-r1模型
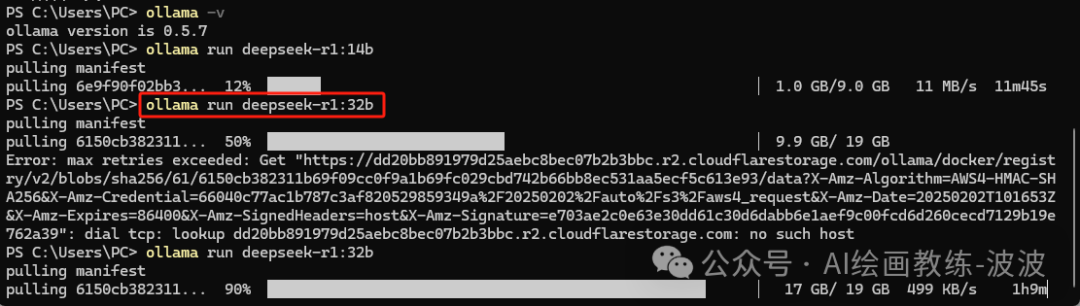
4、测试r1模型
四、安装Dify
Dify.AI 是一个开源的大模型应用开发平台,旨在帮助开发者轻松构建和运营生成式 AI 原生应用。该平台提供从 Agent 构建到 AI workflow 编排、RAG 检索、模型管理等全方位的能力,使开发者能够专注于创造应用的核心价值,而无需在技术细节上耗费过多精力。
1、下载dify项目压缩包
dify中github地址:https://github.com/langgenius/dify
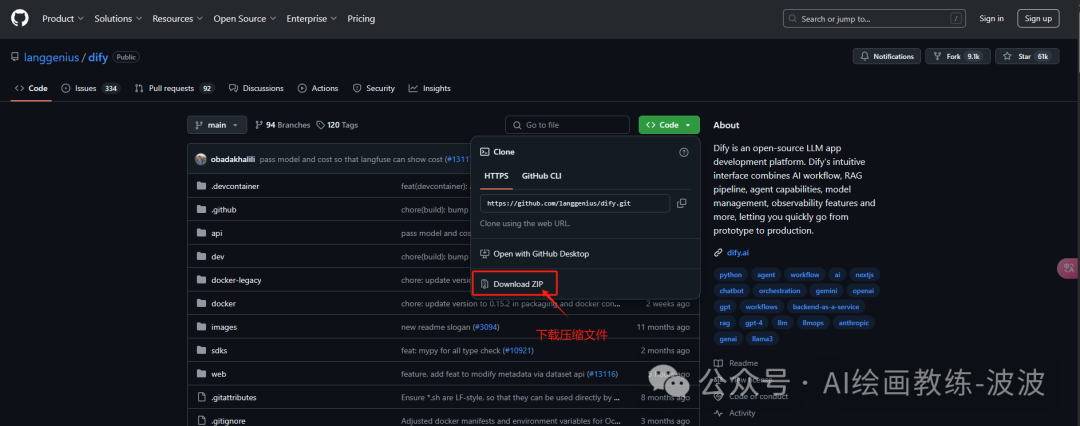
2、下载并解压,然后进入项目根目录找到docker文件夹,找到文件“.env.exmple”重命名“.env”
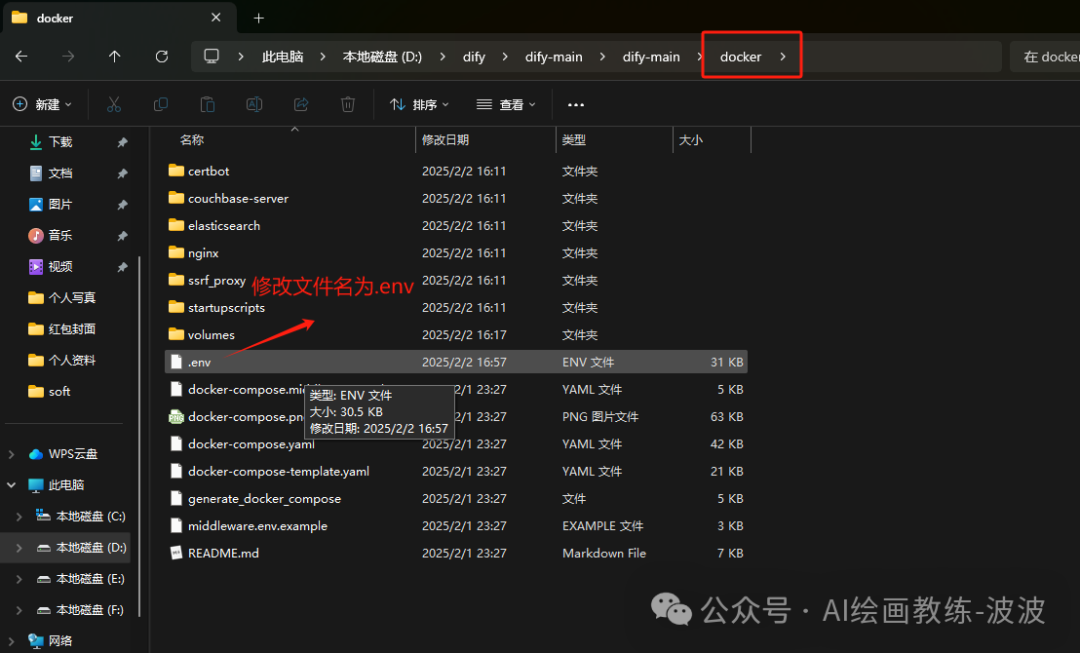
3、准备dify的docker环境
在该文件夹页面中点击鼠标右键,选择“在终端中打开”
输入命令:
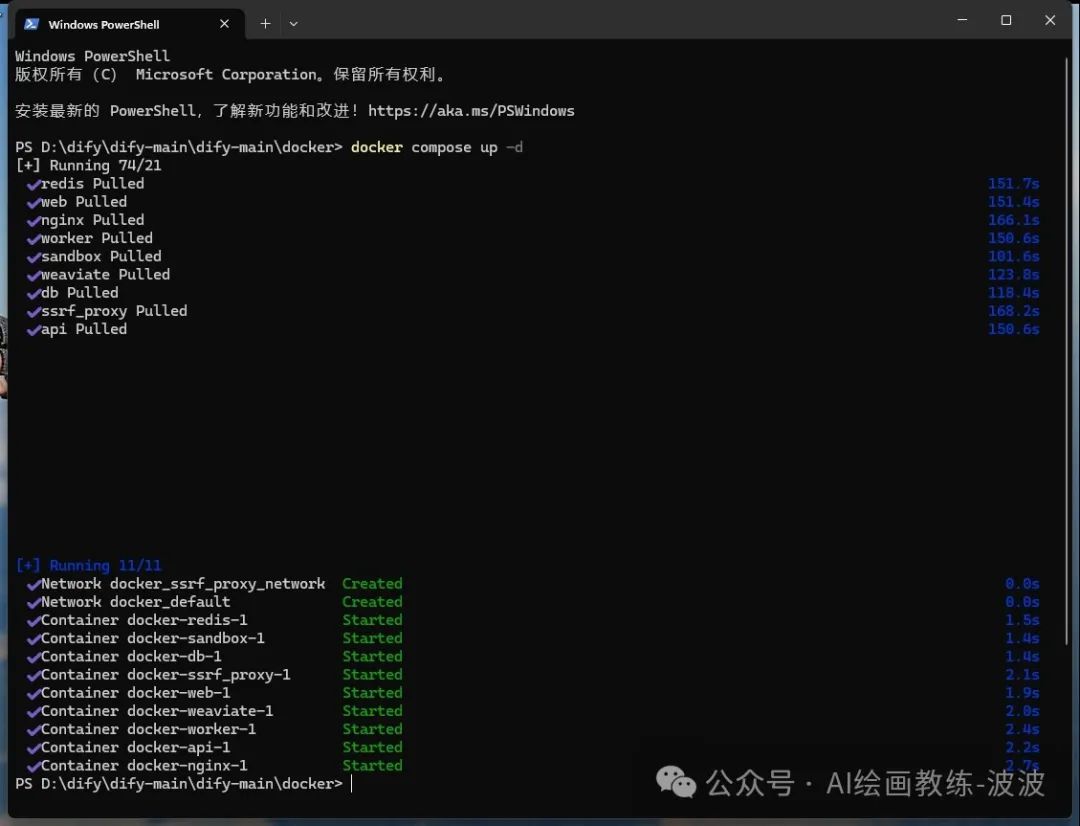
此时回到docker桌面客户端可看到,所有dify所需要的环境都已经运行起来了
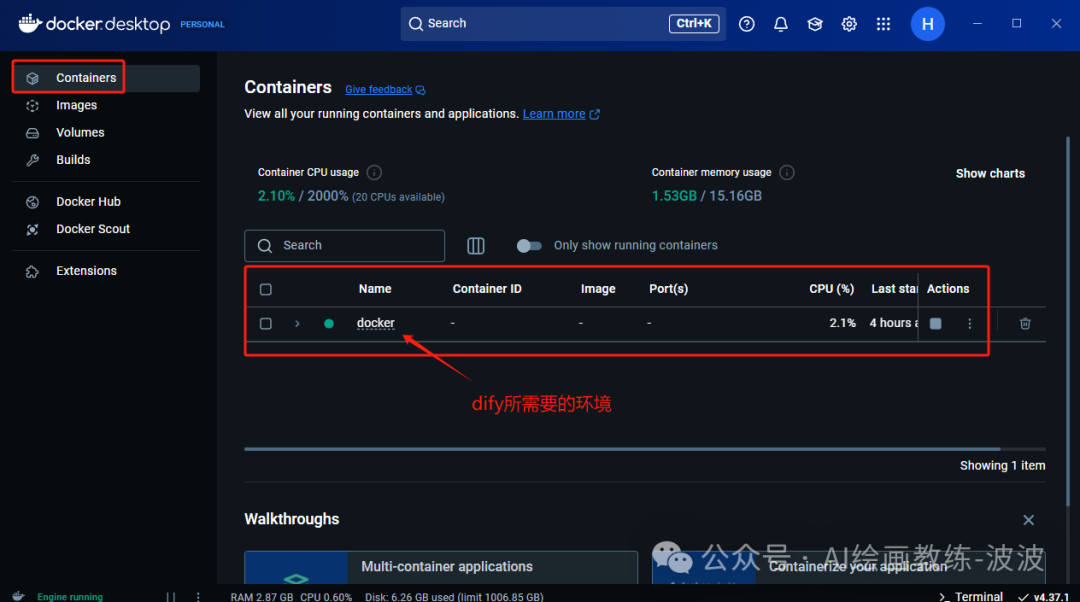
4、注册dify
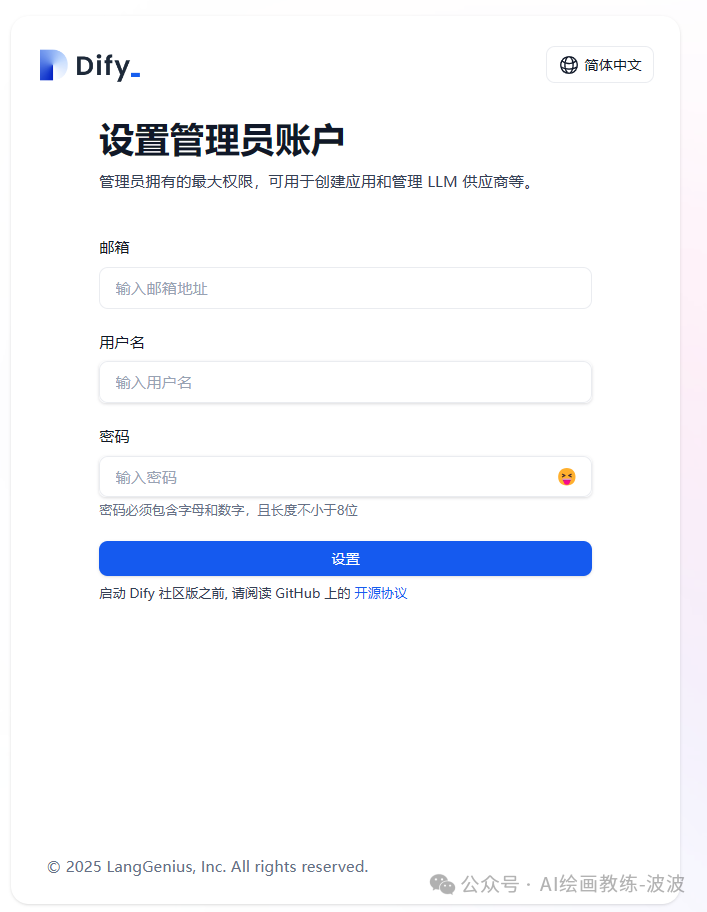
在浏览器地址栏输入:
五、将本地大模型与dify关联起来
由于dify是通过docker部署的,ollama也是运行在本地,要想dify能够访问ollama提供的服务,需要获取到本地的内网IP即可。
1、配置docker下的env文件(文件末尾)
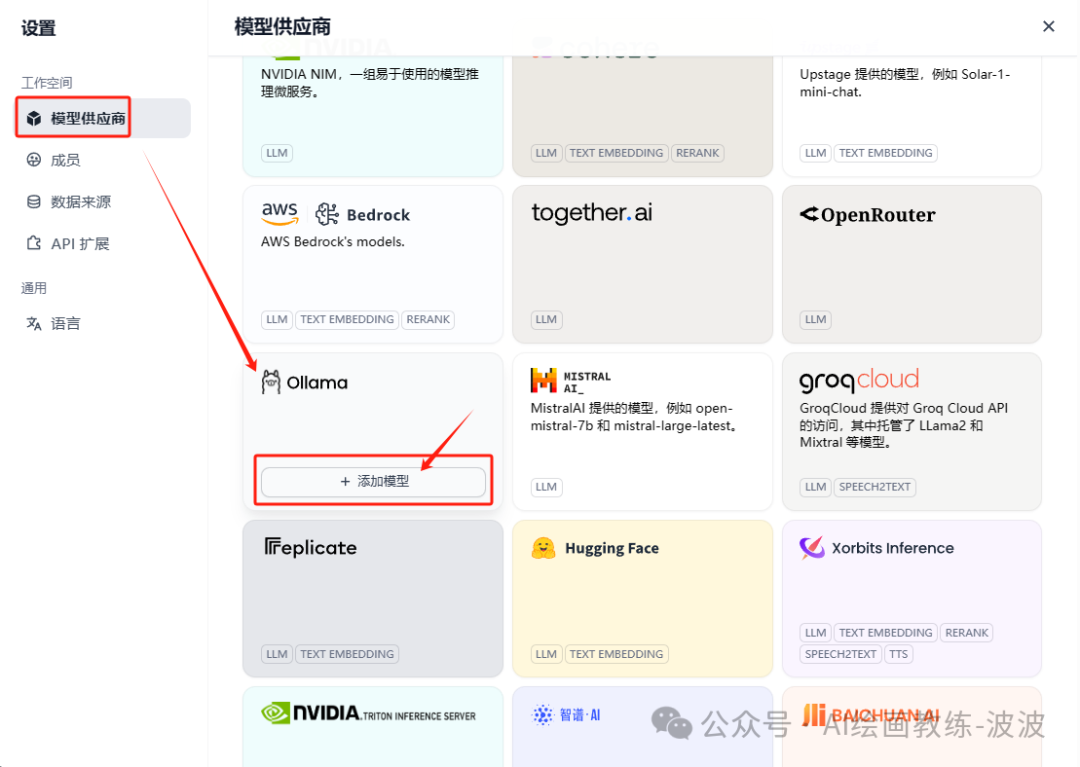
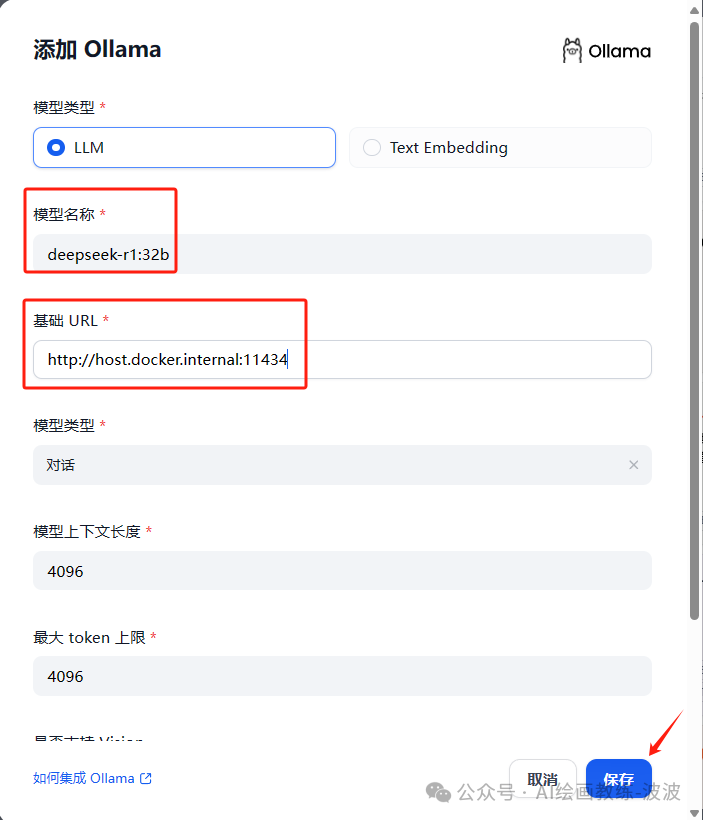
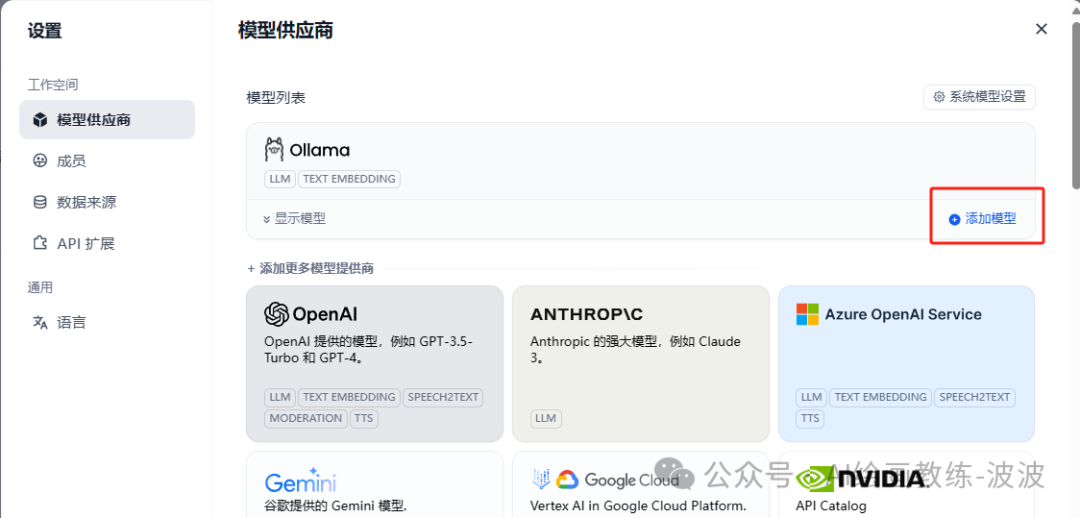
2、配置大模型
3、设置系统模型
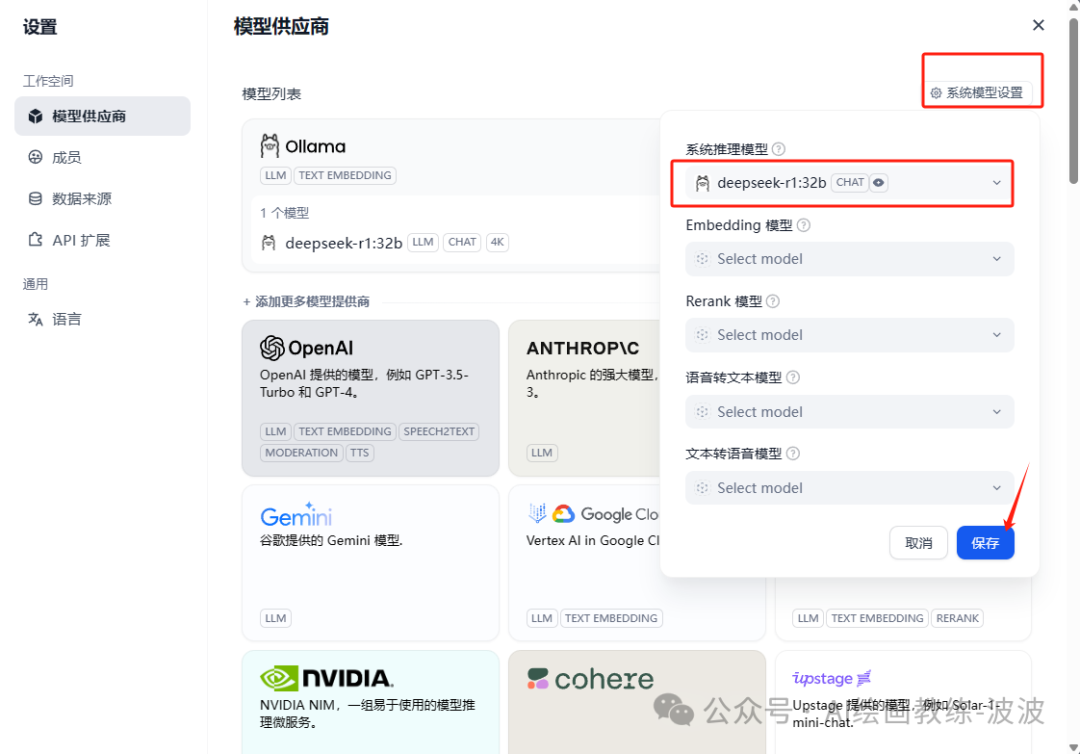
到此,dify就与前面部署的本地大模型关联起来了
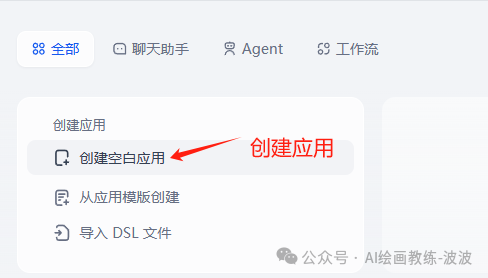
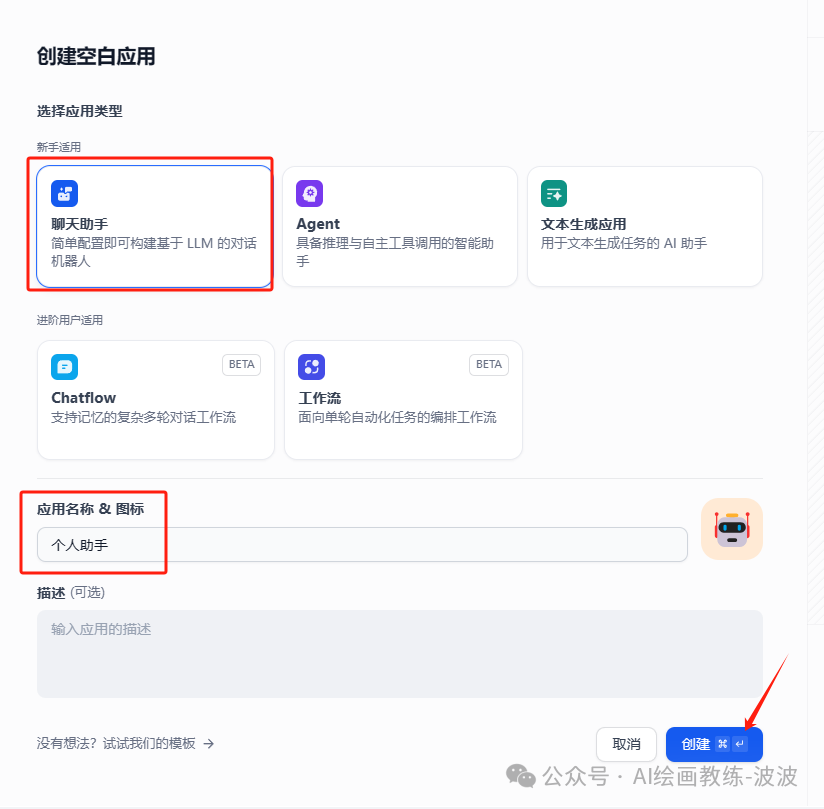
六、创建应用
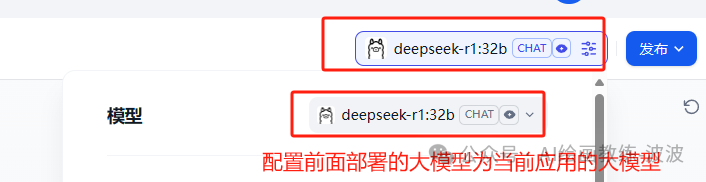
进行测试:
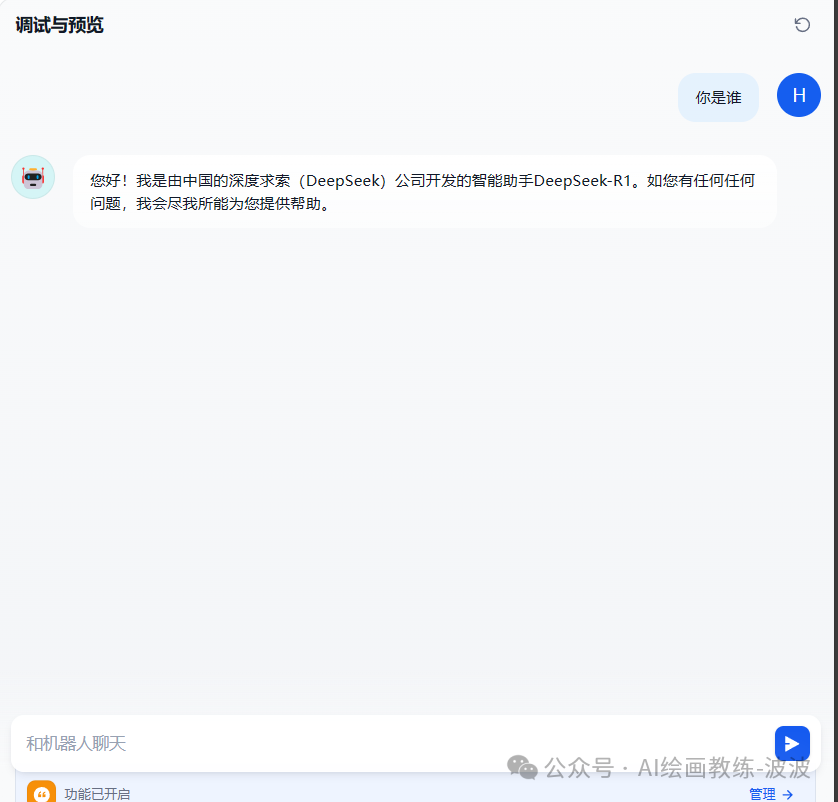
这表明,dify与本地部署的大模型deepseek-r1连通了,但是,我想让他的回答是基于我的私有知识库作为上下文来和我聊天怎么办?这就需要用到本地知识库了
七、创建本地知识库
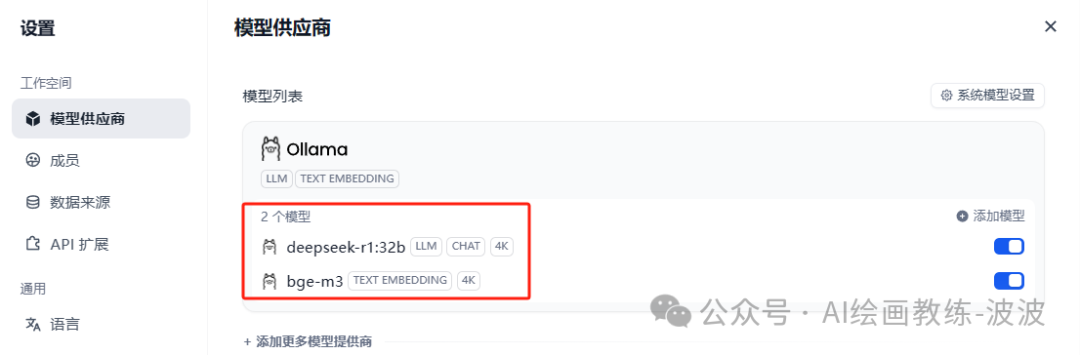
1、添加Embedding模型
Embedding模型的作用是将高维数据(如文本、图像)转换为低维向量。
我们上传的资料要通过Embedding模型转换为向量数据存入向量数据库,这样回答问题时,才能根据自然语言,准确获取到原始数据的含义并召回,因此我们需要提前将私有数据向量化入库。
Embedding 模型那么多,个人感觉bge-m3对中文场景支持效果更好,当然还有其他的Embedding可以选择,这里就以bge-m3举例。
下载命令:
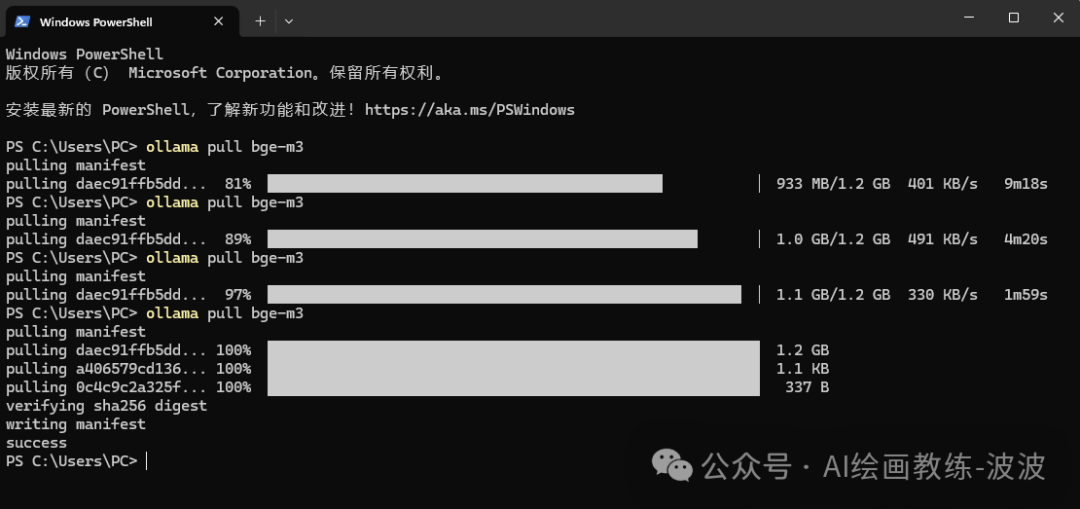
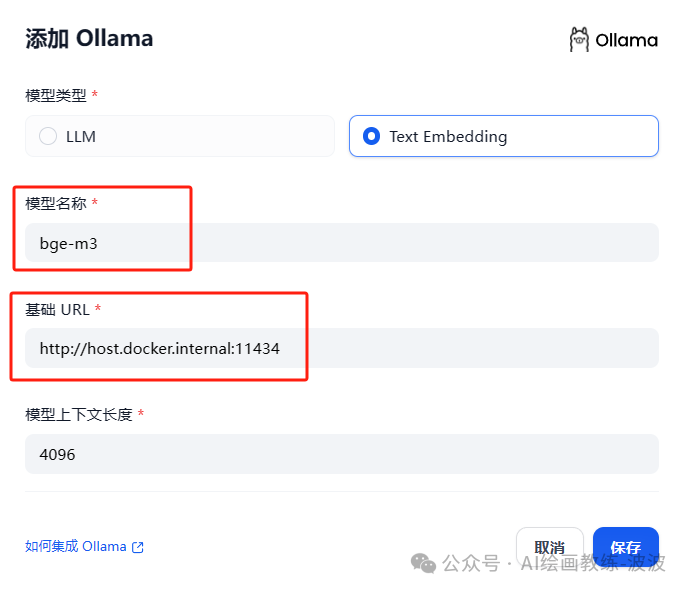
2、配置 Embedding 模型
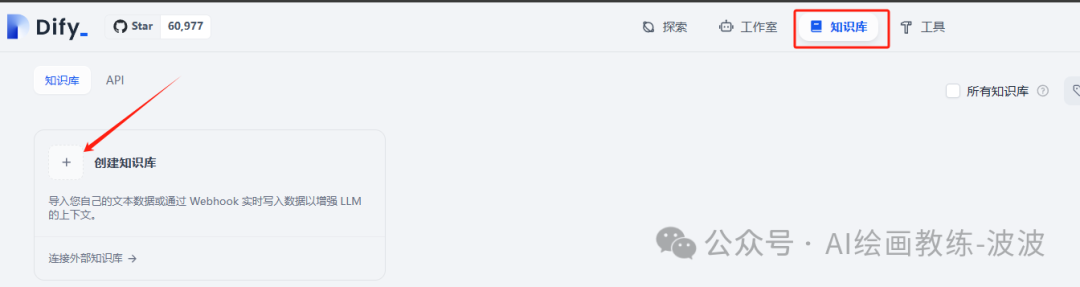
3、创建知识库
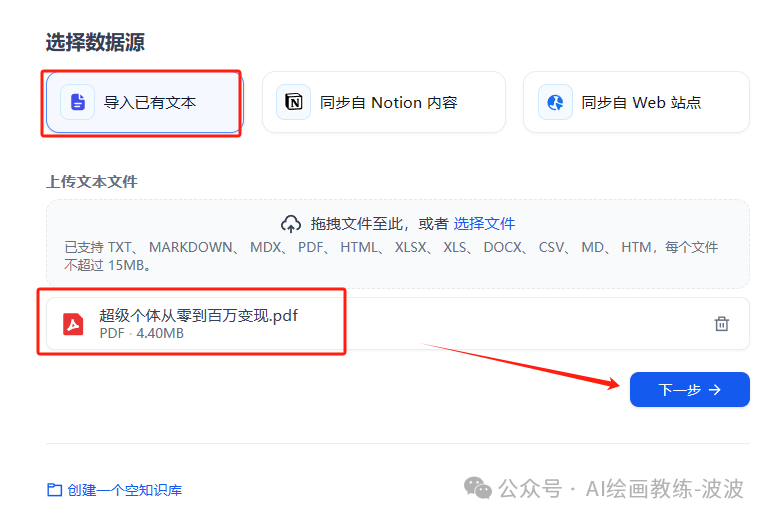
4、上传资料并设置参数
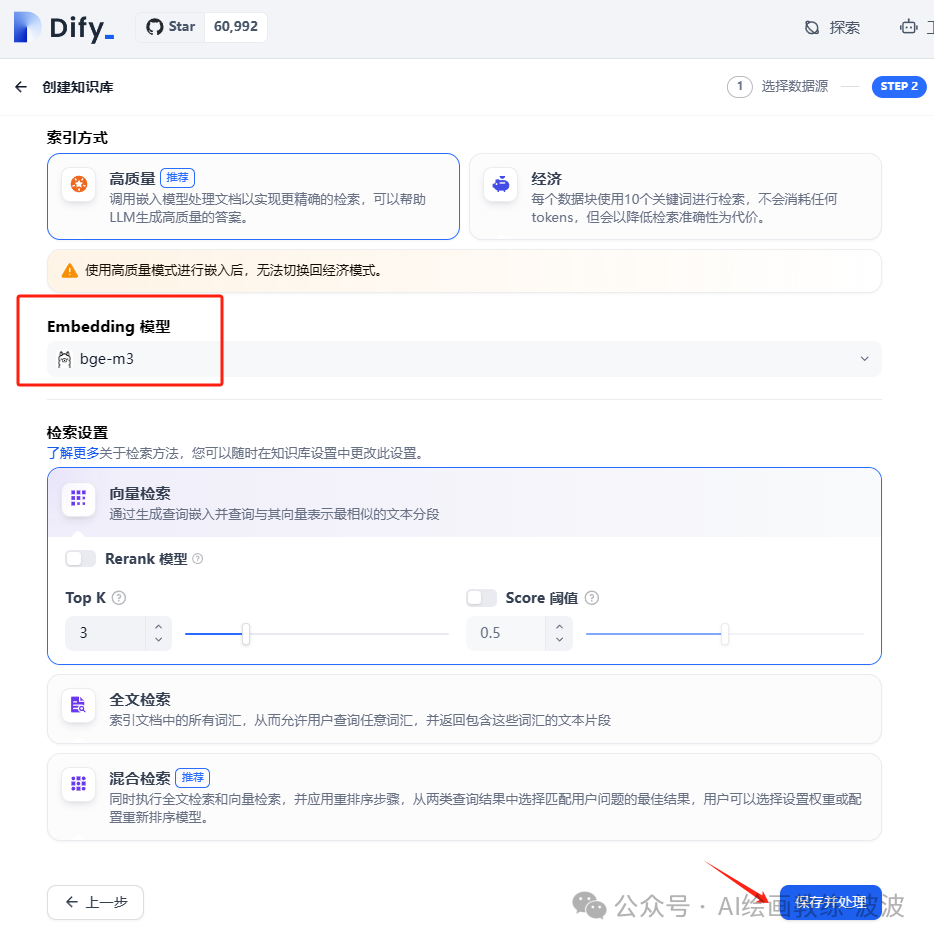
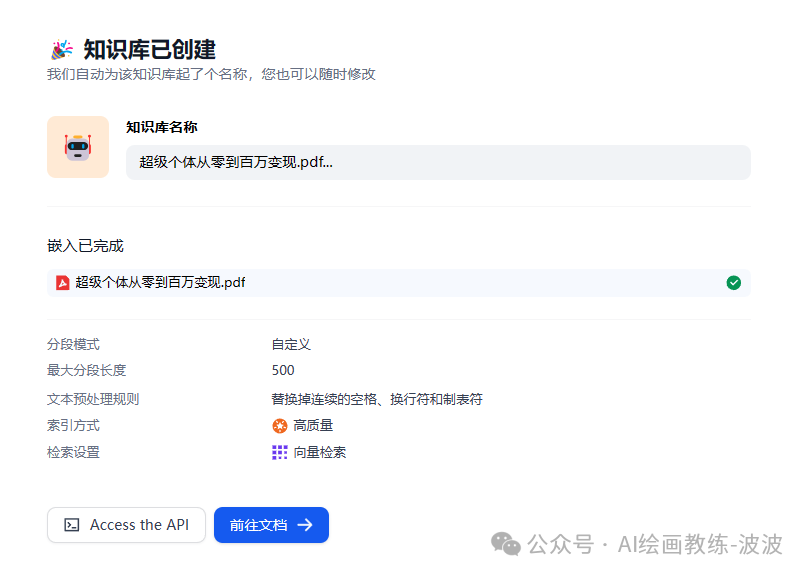
4、知识库创建完成
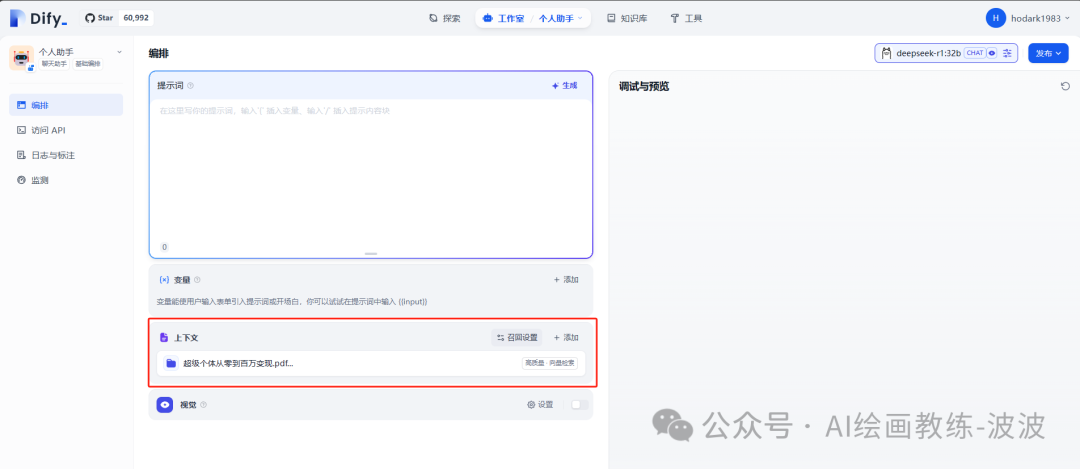
八、在对话上下文中添加知识库
回到刚才的聊天页面中,在上下文中添加知识库中文档信息,并发布更新
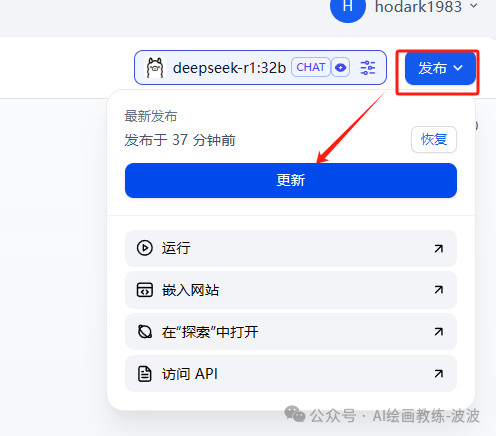
测试效果:
跟着以上的操作步骤,就可以在本地成功搭建自己的私有知识库了!
DeepSeek无疑是2025开年AI圈的一匹黑马,在一众AI大模型中,DeepSeek以低价高性能的优势脱颖而出。DeepSeek的上线实现了AI界的又一大突破,各大科技巨头都火速出手,争先抢占DeepSeek大模型的流量风口。
DeepSeek的爆火,远不止于此。它是一场属于每个人的科技革命,一次打破界限的机会,一次让普通人也能逆袭契机。
DeepSeek的优点

掌握DeepSeek对于转行大模型领域的人来说是一个很大的优势,目前懂得大模型技术方面的人才很稀缺,而DeepSeek就是一个突破口。现在越来越多的人才都想往大模型方向转行,对于想要转行创业,提升自我的人来说是一个不可多得的机会。
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “”“”等问题热议不断。
不如成为,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
大模型岗位需求越来越大,但是相关岗位人才难求,薪资持续走高,AI运营薪资平均值约18457元,AI工程师薪资平均值约37336元,大模型算法薪资平均值约39607元。

那么,如何系统的去学习大模型LLM?
作为一名从业五年的资深大模型算法工程师,我经常会收到一些评论和私信,我是小白,学习大模型该从哪里入手呢?我自学没有方向怎么办?这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!这些问题啊,也不是三言两语啊就能讲明白的。
所以我综合了大模型的所有知识点,给大家带来一套全网最全最细的大模型零基础教程。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。
由于篇幅有限,⚡️ 朋友们如果有需要全套 《2025全新制作的大模型全套资料》,扫码获取~


第1周:基础入门
- 了解大模型基本概念与发展历程
- 学习Python编程基础与PyTorch/TensorFlow框架
- 掌握Transformer架构核心原理


第2周:数据处理与训练
- 学习数据清洗、标注与增强技术
- 掌握分布式训练与混合精度训练方法
- 实践小规模模型微调(如BERT/GPT-2)
第3周:模型架构深入
- 分析LLaMA、GPT等主流大模型结构
- 学习注意力机制优化技巧(如Flash Attention)
- 理解模型并行与流水线并行技术
第4周:预训练与微调
- 掌握全参数预训练与LoRA/QLoRA等高效微调方法
- 学习Prompt Engineering与指令微调
- 实践领域适配(如医疗/金融场景)
第5周:推理优化
- 学习模型量化(INT8/FP16)与剪枝技术
- 掌握vLLM/TensorRT等推理加速工具
- 部署模型到生产环境(FastAPI/Docker)
第6周:应用开发 - 构建RAG(检索增强生成)系统
- 开发Agent类应用(如AutoGPT)
- 实践多模态模型(如CLIP/Whisper)


第7周:安全与评估
- 学习大模型安全与对齐技术
- 掌握评估指标(BLEU/ROUGE/人工评测)
- 分析幻觉、偏见等常见问题
第8周:行业实战 - 参与Kaggle/天池大模型竞赛
- 复现最新论文(如Mixtral/Gemma)
- 企业级项目实战(客服/代码生成等)
第9周:前沿拓展
- 学习MoE、Long Context等前沿技术
- 探索AI Infra与MLOps体系
- 制定个人技术发展路线图
👉福利篇👈
最后呢,会给大家一个小福利,课程视频中的所有素材,有搭建AI开发环境资料包,还有学习计划表,几十上百G素材、电子书和课件等等,只要你能想到的素材,我这里几乎都有。我已经全部上传到CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

sdn.net/python12345_/article/details/145450272),如有侵权,请联系删除。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/222185.html