
We build Claude with Claude.
这是其发布日志[1]里说的一句话。
现在AI模型的迭代,不仅仅是researcher的事,模型本身也参与到下个版本的迭代中了。
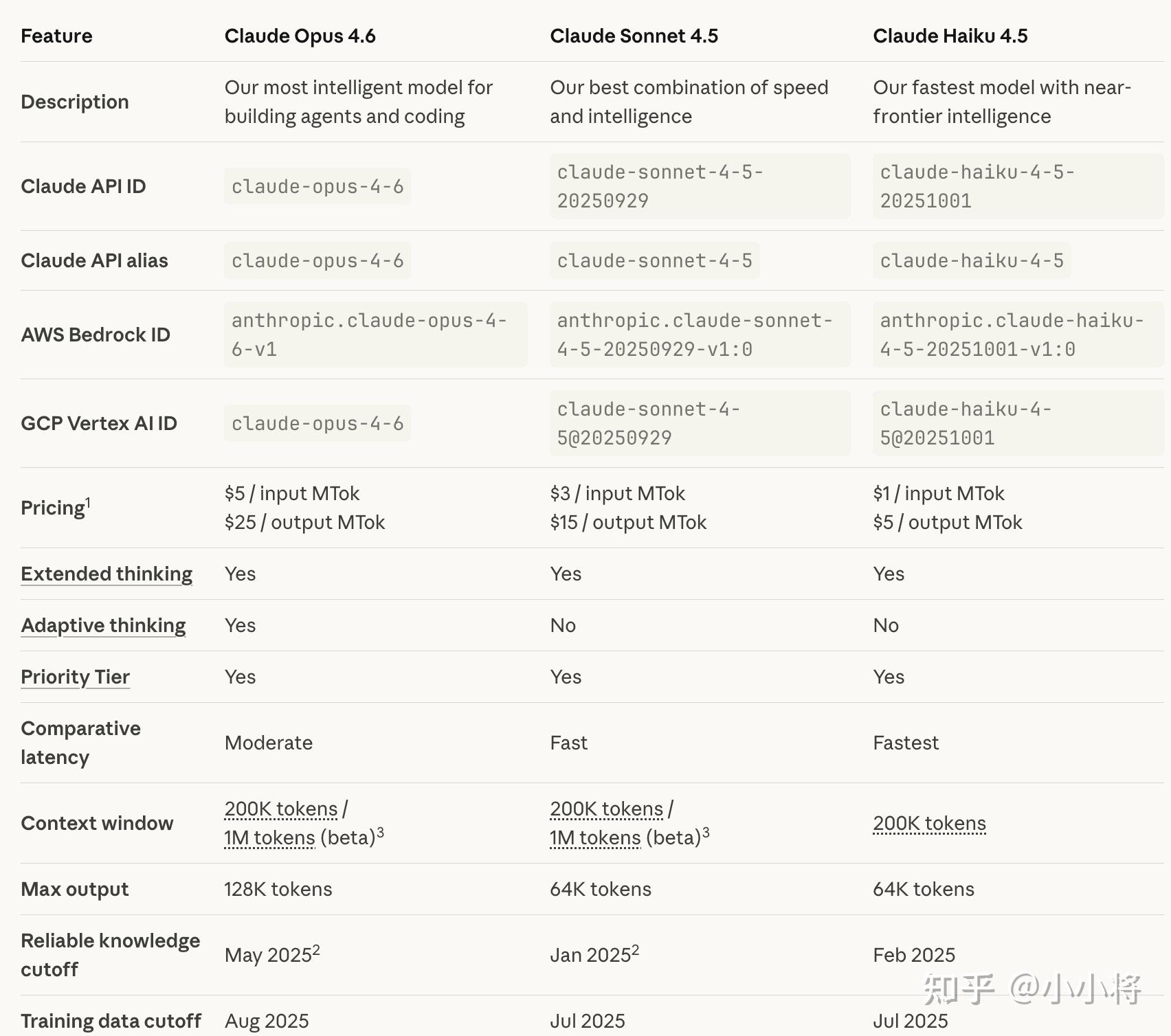
Claude Opus系列,coder最爱的模型。
虽然从4.6到4.5只是小版本号更新,质变不至于,但量变还是不少的,是一个「加量不加价」的升级。(话说Coding领域真是竞争白热化啊,与此同时,隔壁奥特曼家也一起发布了 GPT-5.3-Codex)
价格方面,还是和 Claude Opus 4.5 一样,输入\(5/1M token,输出\)25/1M token,一分钱没涨。
其提升主要在这四个方面。(顺便比较下刚发布的GPT-5.3-Codex如何)
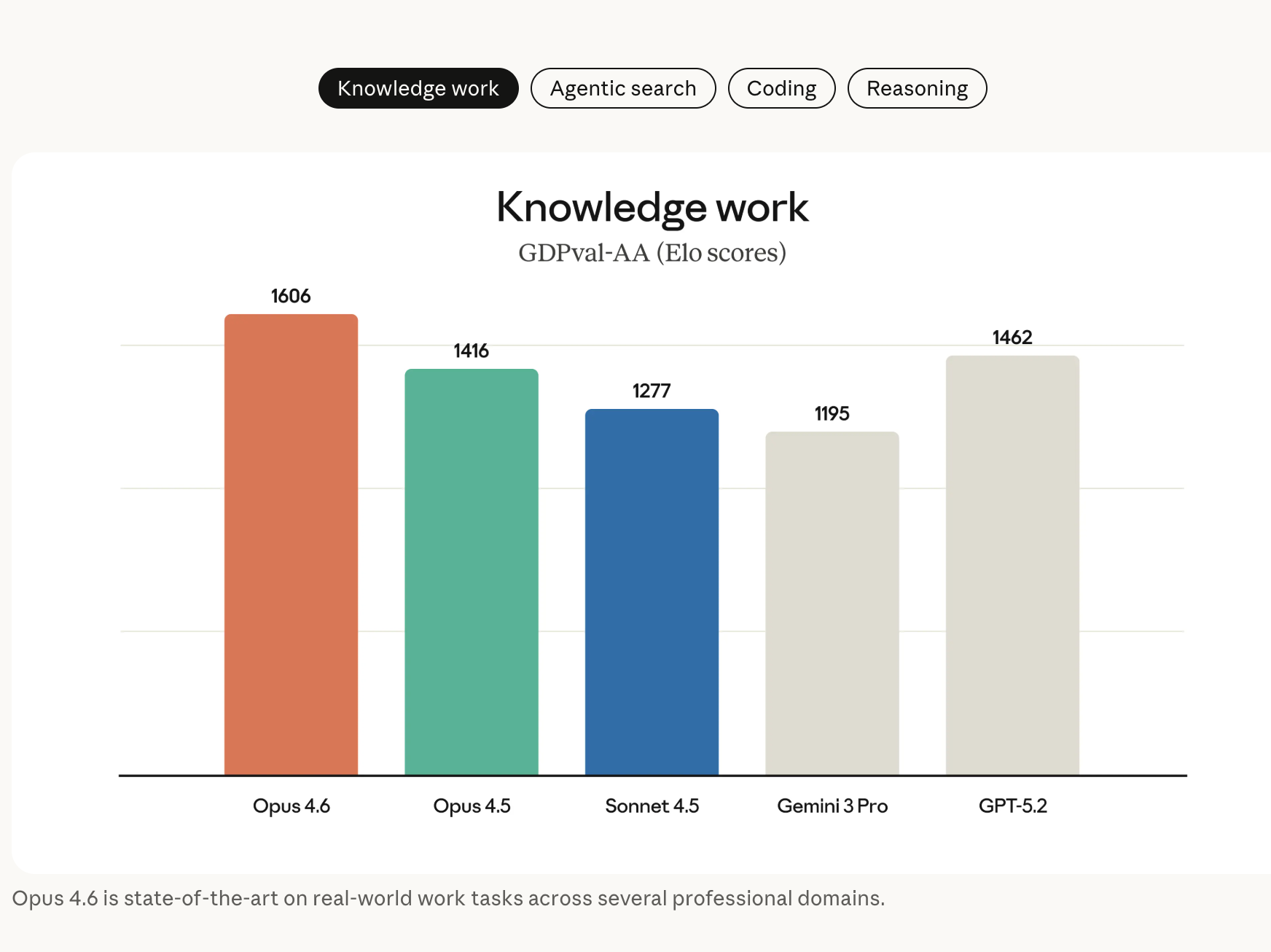
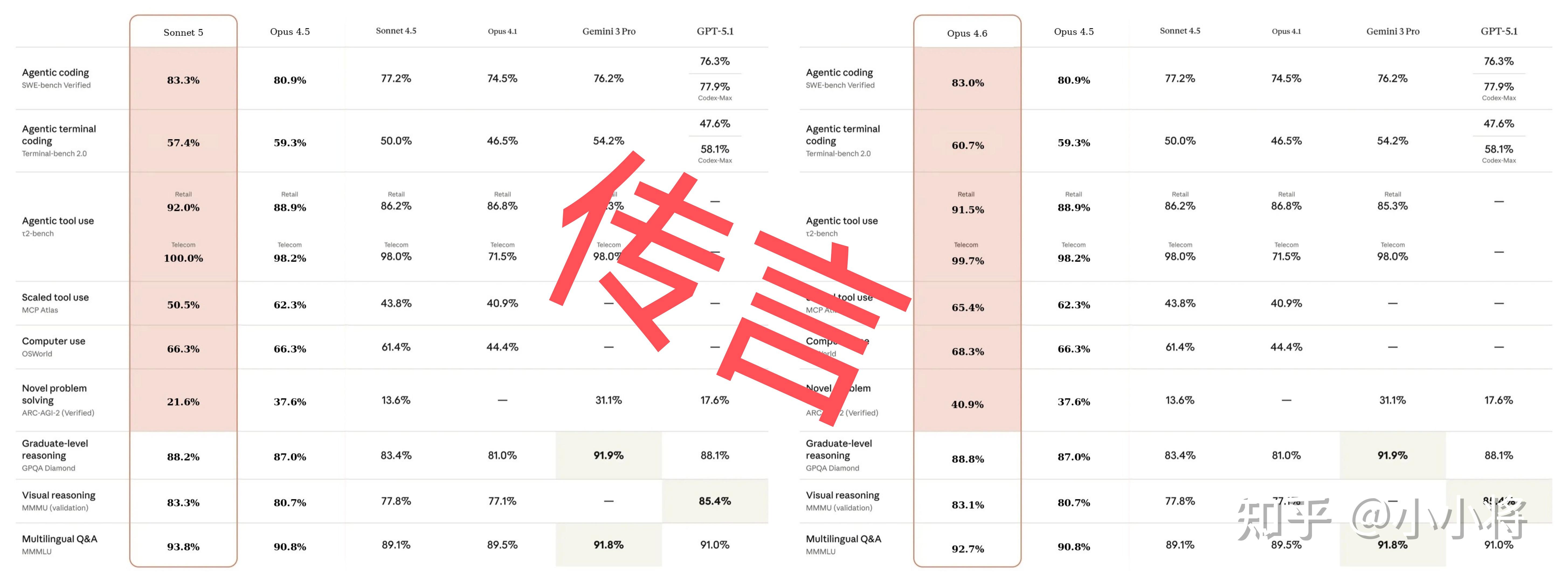
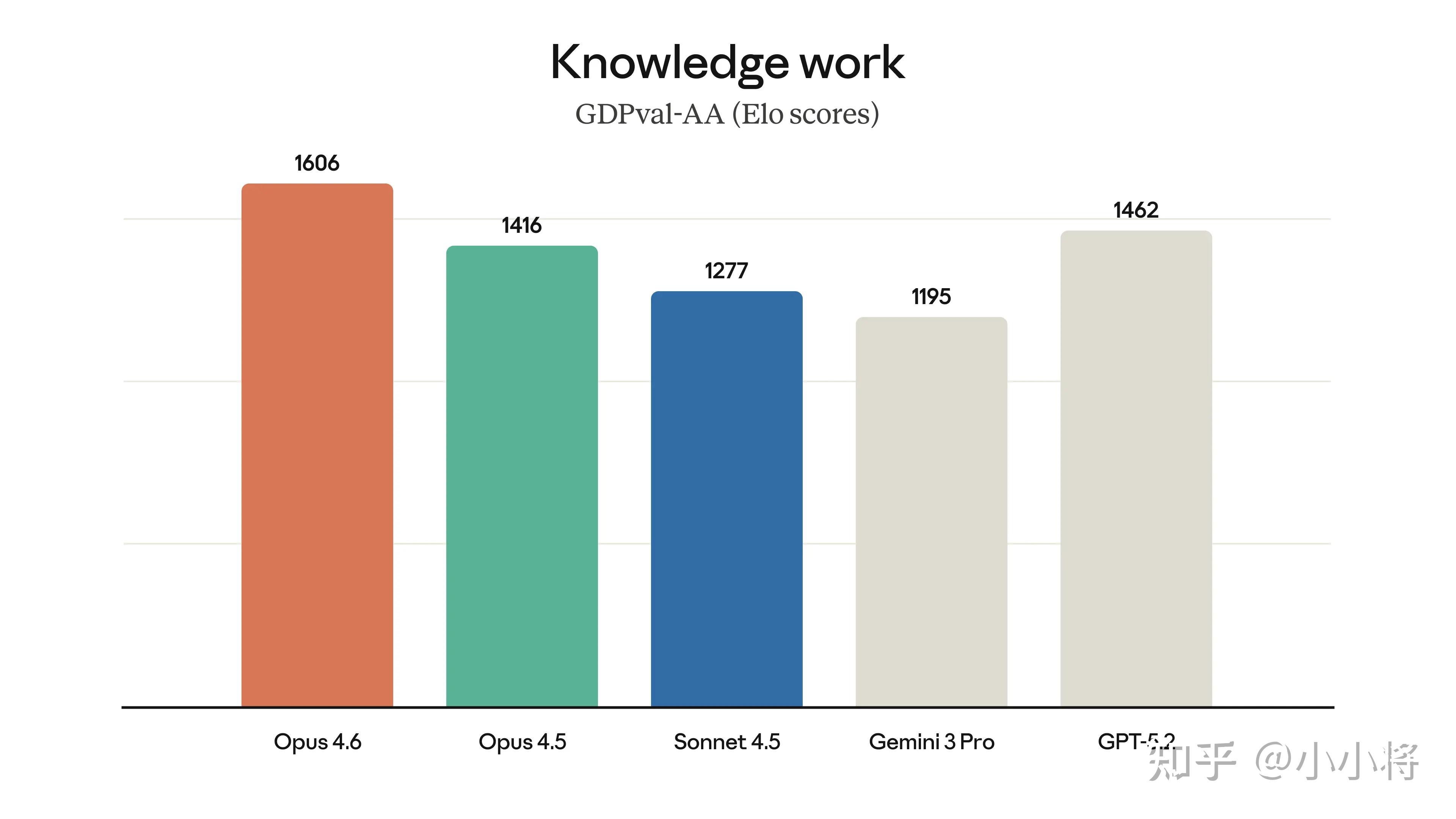
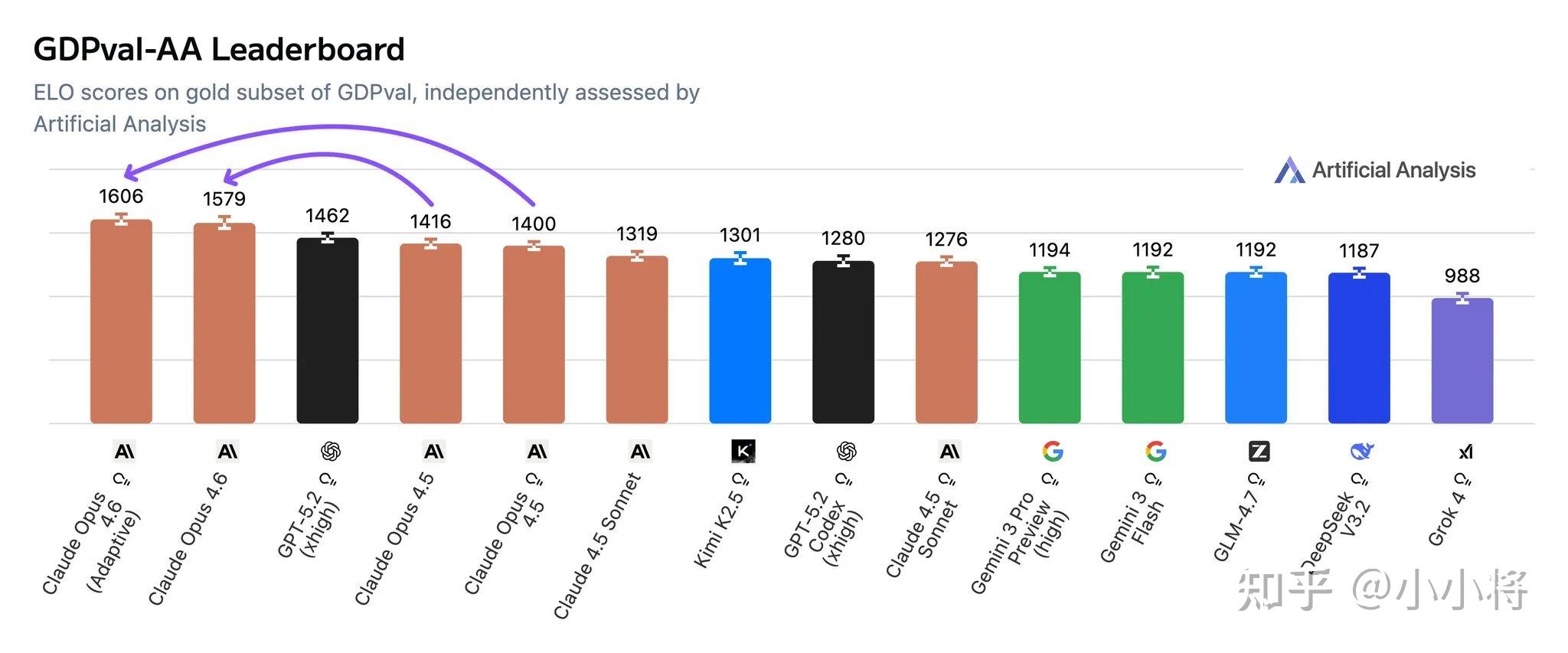
Claude Opus 4.6在处理财务分析、深度研究、文档 / 表格 / 演示文稿创建与使用的效率显著提升,适配了更多日常办公场景;具体得分如何呢?可以在其网站看到,在 GDPval-AA(金融、法律等经济价值知识任务评估)中,比 Opus 4.5 高出 190 Elo 分,专业领域表现更优;
(我去搜了下,GPT-5.3-Codex的分数暂时未更新上去, 晚点有分数了回来更新)
另外,这次还新增 Claude in PowerPoint,搭配升级后的 Claude in Excel,可实现数据处理与可视化全流程适配,匹配品牌规范自动生成演示文稿。
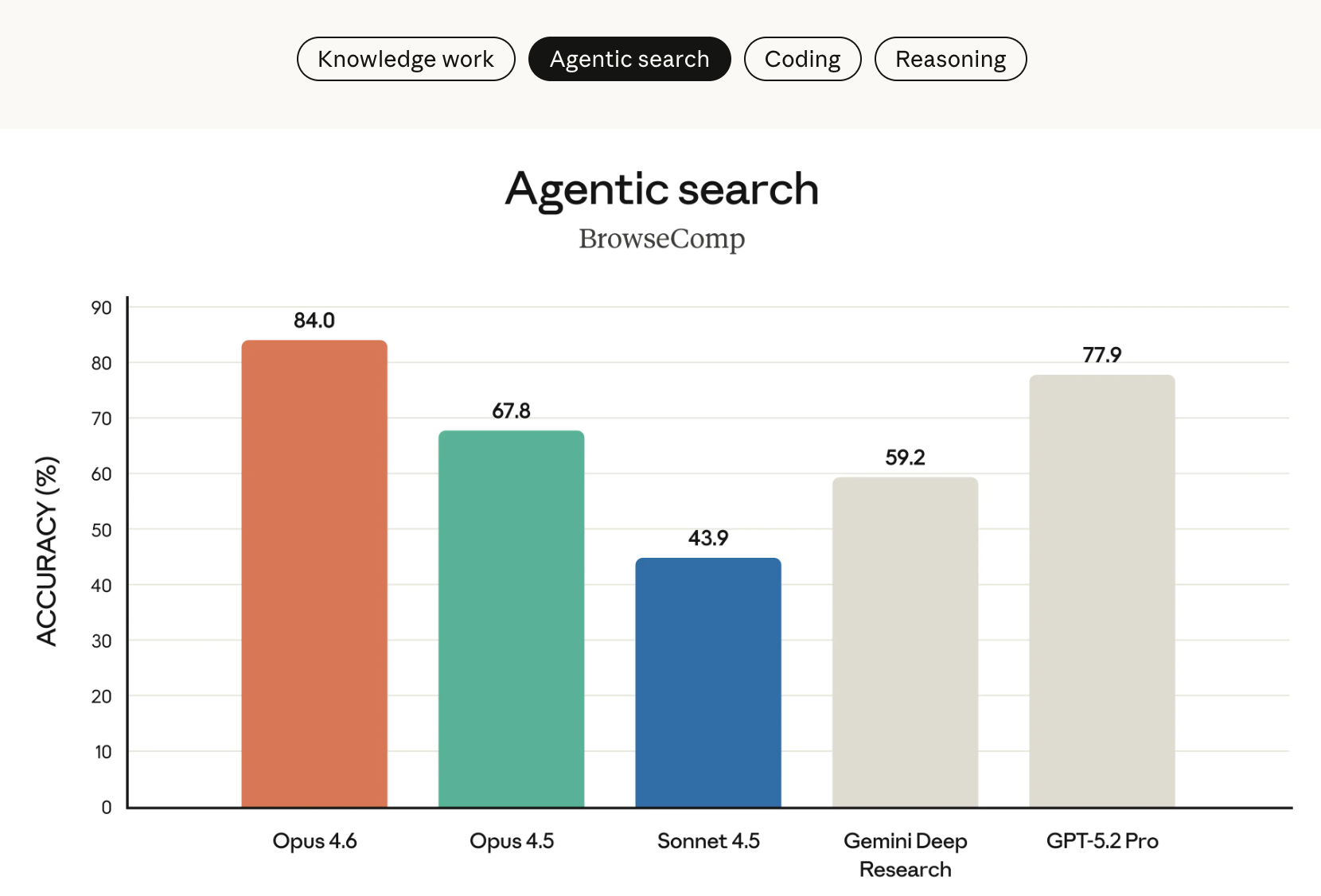
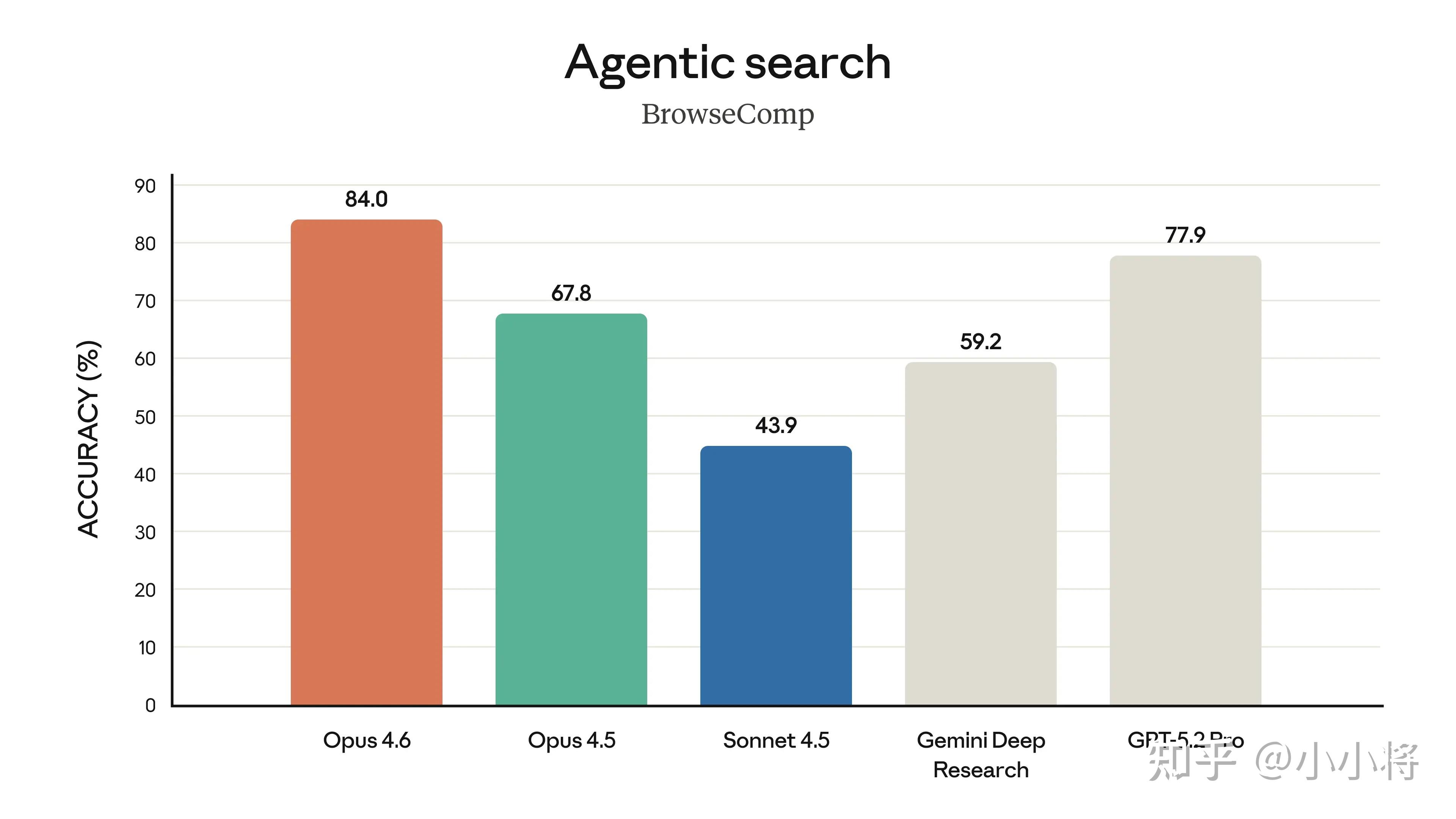
Claude Opus 4.6在这个方面,获行业最高评分,擅长深度、多步搜索,能精准定位网络上难获取的信息(BrowseComp 评测领先);支持多智能体协作搜索,搭配专用工具后 BrowseComp 评分达 86.8%,远超 Opus 4.5;结合 1M token 长上下文窗口,检索长文本时信息遗漏减少,「上下文衰减」问题大幅改善(MRCR v2 测试 76% 得分,4.5 仅 18.5%)。
(目前稳坐第一,GPT-5.3系列还没出现)browsecomp
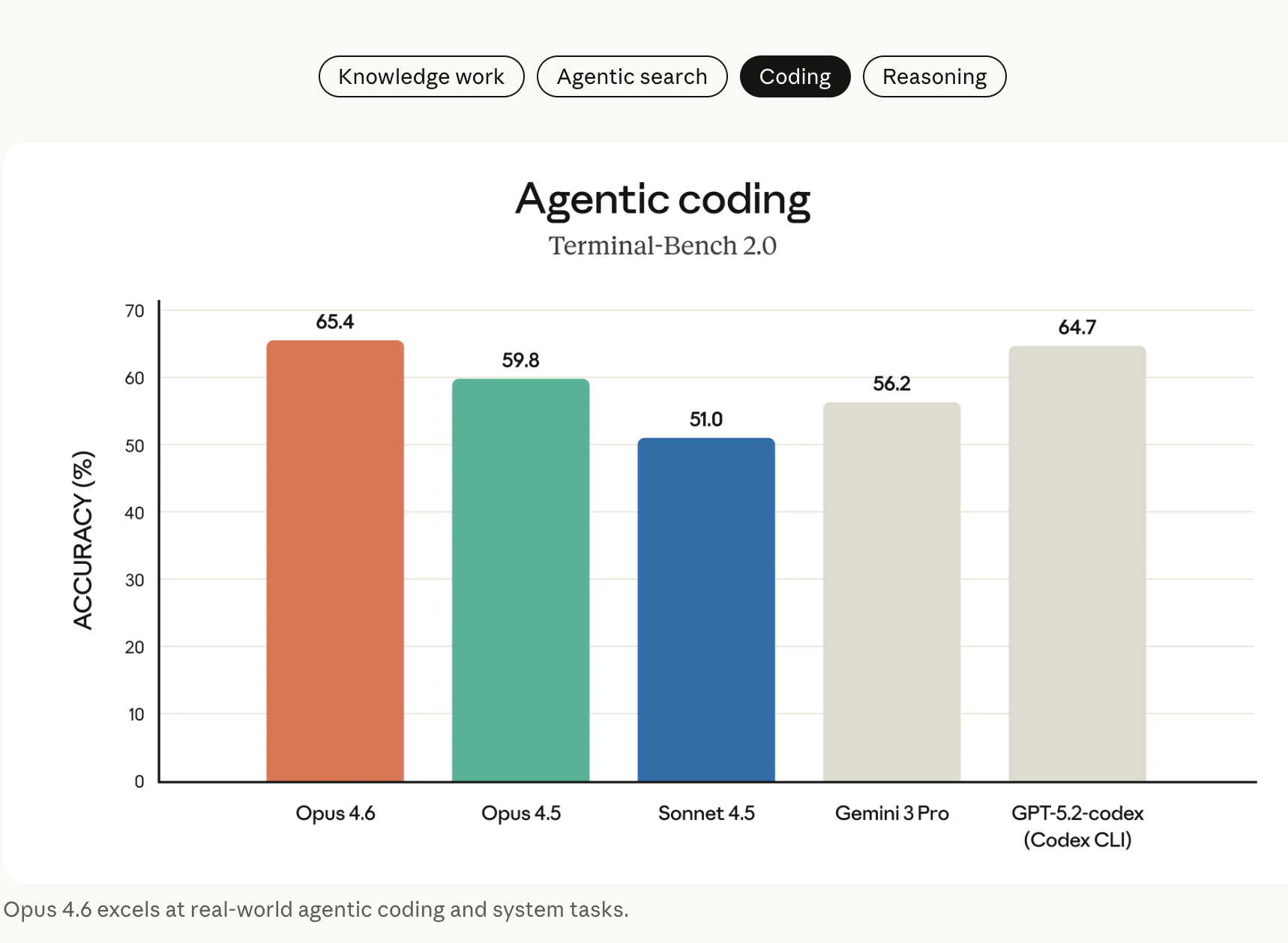
这就更是Opus 4.6的天下了。Opus 4.6规划更周密,可在大型代码库中稳定运行,代码审查、调试能力升级,能自主发现自身错误。(其实我感觉Opus 4.5这方面的能力已经强得很明显了)
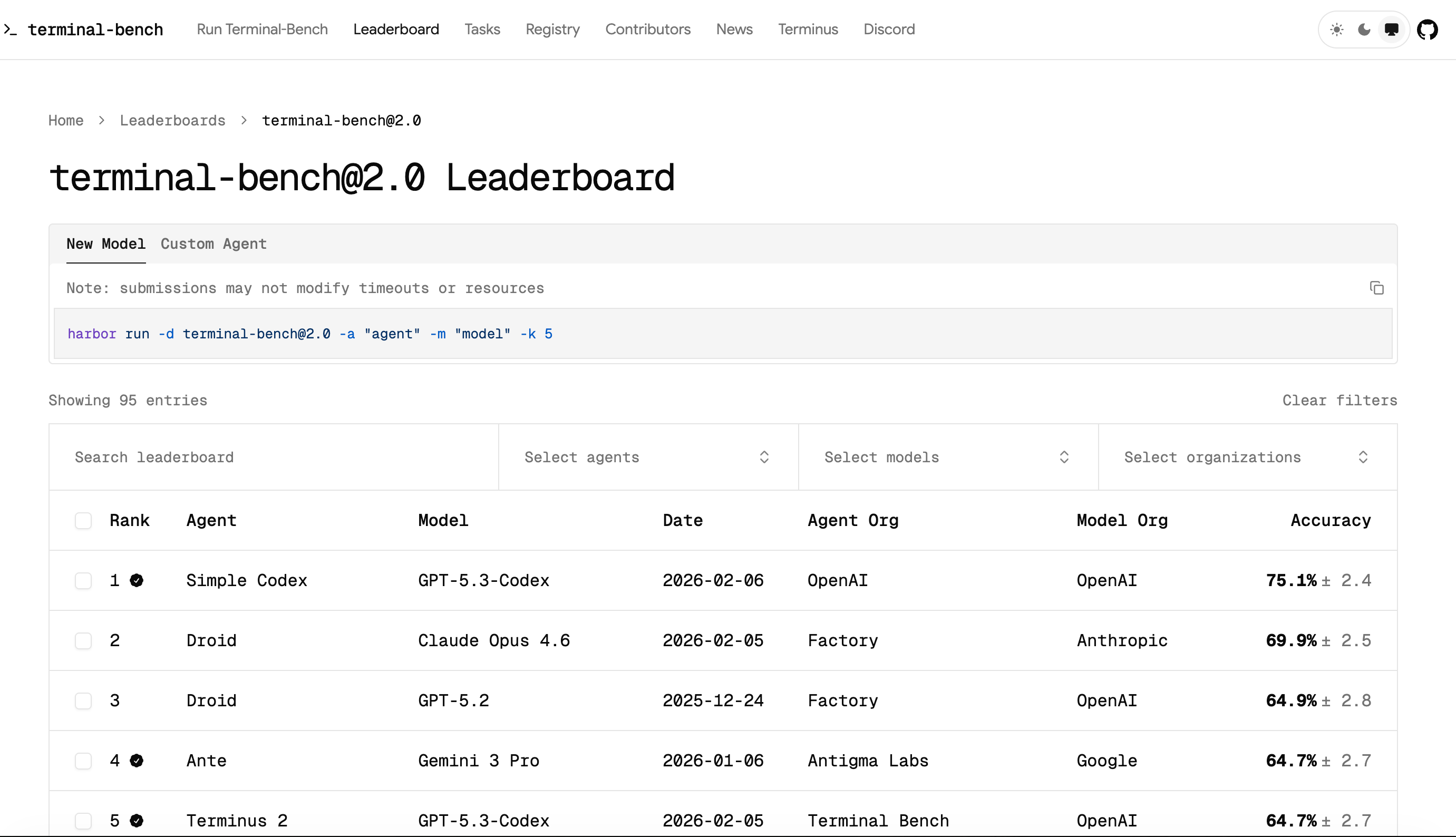
在 Terminal-Bench 2.0(智能体编码评测)中获最高分,支持多语言编码,可独立完成百万行代码库迁移(耗时减半);
除了Benchmark,Coding方面还介绍了研究预览阶段的Claude Code Agent Teams。简单说,就是能让多个 Opus Agent 组队干活,自主分工、并行协作。比如你要重构一个大型项目,可以让一个 Agent 负责分析代码结构,一个负责写核心逻辑,一个负责做单元测试,一个负责文档更新。更绝的是,你可以随时接管任意一个子 Agent,像用 tmux 一样切换控制,既享受自动化的效率,又不丢人工干预的灵活性,往「AI 软件工程团队」迈出的关键一步了。
不过,第一的宝座还没捂热,就被GPT-5.3-Codex抢去了,惨。
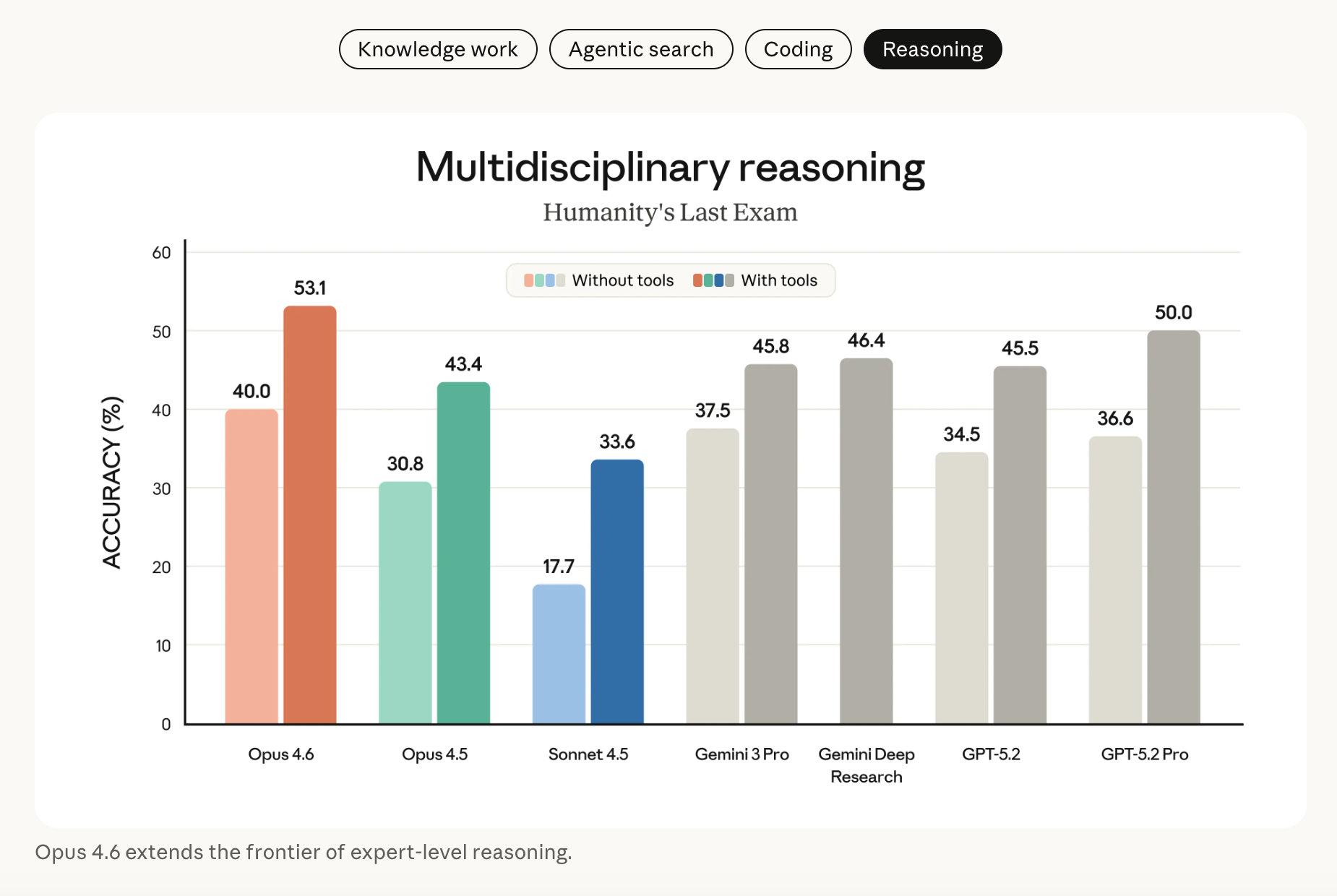
Opus 4.6 在多学科推理测试 Humanity’s Last Exam 中领跑所有前沿模型,能考虑其他模型遗漏的边缘案例;专家级推理能力强化,法律领域 BigLaw Bench 评分达 90.2%,生命科学(计算生物学、有机化学等)测试表现比 4.5 快近 2 倍;长上下文推理连贯性提升,可吸收海量信息后保持精准推理,无明显性能漂移。
害,看来Claude 5应该在年前不会发布了,大家可以松口气(或把熬夜的机会留给DeepSeek V4)。
从版本号我们能看的出来,这次更新不是大更新,算是一次小更新吧,所以没必要过度解读,不过这次小更新也有不少亮点:
首先就是发布节奏快了, Opus 4.5 在去年11月发布到现在的4.6只间隔了两个多月。
然后就是上下文窗口扩展到100万 token了,虽然这是Opus 的改进,但是 Sonnet 4⁄4.5 也是100万,所以只能说是持平了,不过这样Opus 这种更强大的模型能够有更长的上下文肯定会得到更好的结果,这是肯定的。
比较大的更新有下面几个:
自适应思考(Adaptive Thinking) 这个算是是架构层面的创新了,让模型能动态调整“思考深度”,这不是简单的参数调整,而是推理机制的改变。
ARC AGI 2 测试从37.6% → 68.8% 几乎翻了1倍,这种大幅提升说明模型在通用智能方面有实质性进步。
代理团队(Agent Teams) 这块更像是应用层面的功能封装,我个人理解还是任务分解和调度,不算底层技术突破。
编程能力提升(Terminal-Bench、OSWorld等) 依然领先,这个应该是没啥问题的,因为Opus 目前来说就是最强的编程模型。
如果要说关注点和更新的排序的话,我觉得应该是这样:
- 真正的创新:自适应思考、ARC-AGI的突破
- 亮眼但非核心:网络安全能力
- 追赶和优化:其他功能
其实更应该关注的是Opus 4.6发布以后,OpenAI立刻发布了GPT-5.3-Codex 这俩是杠上了。
两个模型对比见这个回答,因为GPT-5.3-Codex 是后发的,对比之类的就写在这里了
OpenAI 正式发布 GPT-5.3-Codex,与其他版本相比,它在哪些方面有所改进?最后再多说一句,谷歌自家的antigravity反应还是太慢了,下午更新了一下copilot,已经有opus 4.6了,antigravity还只有4.5,这第二大金主当的有点不称职啊
之前有传闻称将发布 Claude Sonnet 5 以及 Opus 4.6:
但实际上本次只推出了 Claude Opus 4.6。
 https://www.zhihu.com/video/0
https://www.zhihu.com/video/0 Claude Opus 4.6的主要亮点:
- 能力提升显著:在编程、Agent 操作和计算机使用场景中,相比 Opus 4.5 有明显提升。在代理式编程评测集 Terminal-Bench 2.0 上,Opus 4.6 的表现超过 GPT-5.2,达到了 SOTA 水平。
- 支持超大上下文:Opus 4.6 是首个支持 100 万 token 上下文的 Opus 系列模型(Beta 版本),最大输出长度也从 64K 升级至 128K。
- 自适应思考(Adaptive Thinking):模型可以动态决定何时思考以及需要思考多少。思考等级(Effort)新增 max 级别,目前共有四档:low、medium、high(默认)和 max。
- 价格不变:API 定价与 Opus 4.5 保持一致,每百万 token 输入 \(5,输出 \)25(但是比Claude Sonnet 4.5 贵1.5倍多)。
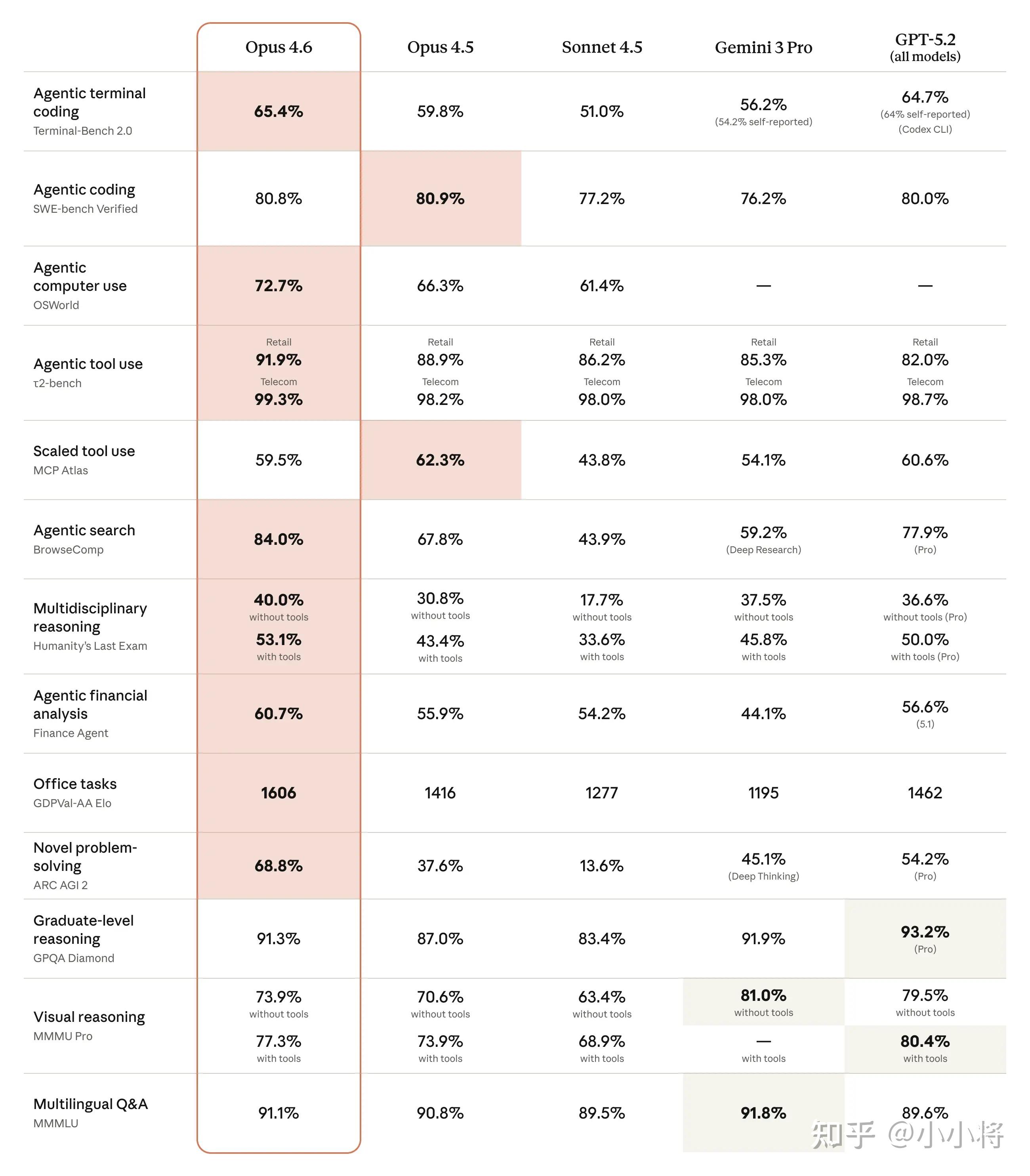
在知识更新方面,Claude Opus 4.6 的知识截止日期为 2025 年 5 月。在金融、法律等领域经济价值型任务评测集 GDPval-AA 上,Opus 4.6 的表现比业界第二名模型(OpenAI GPT-5.2)高约 144 Elo,比自家前代模型 Opus 4.5 高 190 Elo。
在 BrowseComp(评估模型在线查找难以定位信息能力的测试)上,Opus 4.6 的表现同样优于所有其他模型。
Opus 4.6的agentic编程能力也有明显提升,在代理式编程评测 Terminal-Bench 2.0 上超过 GPT-5.2 取得了最高分。
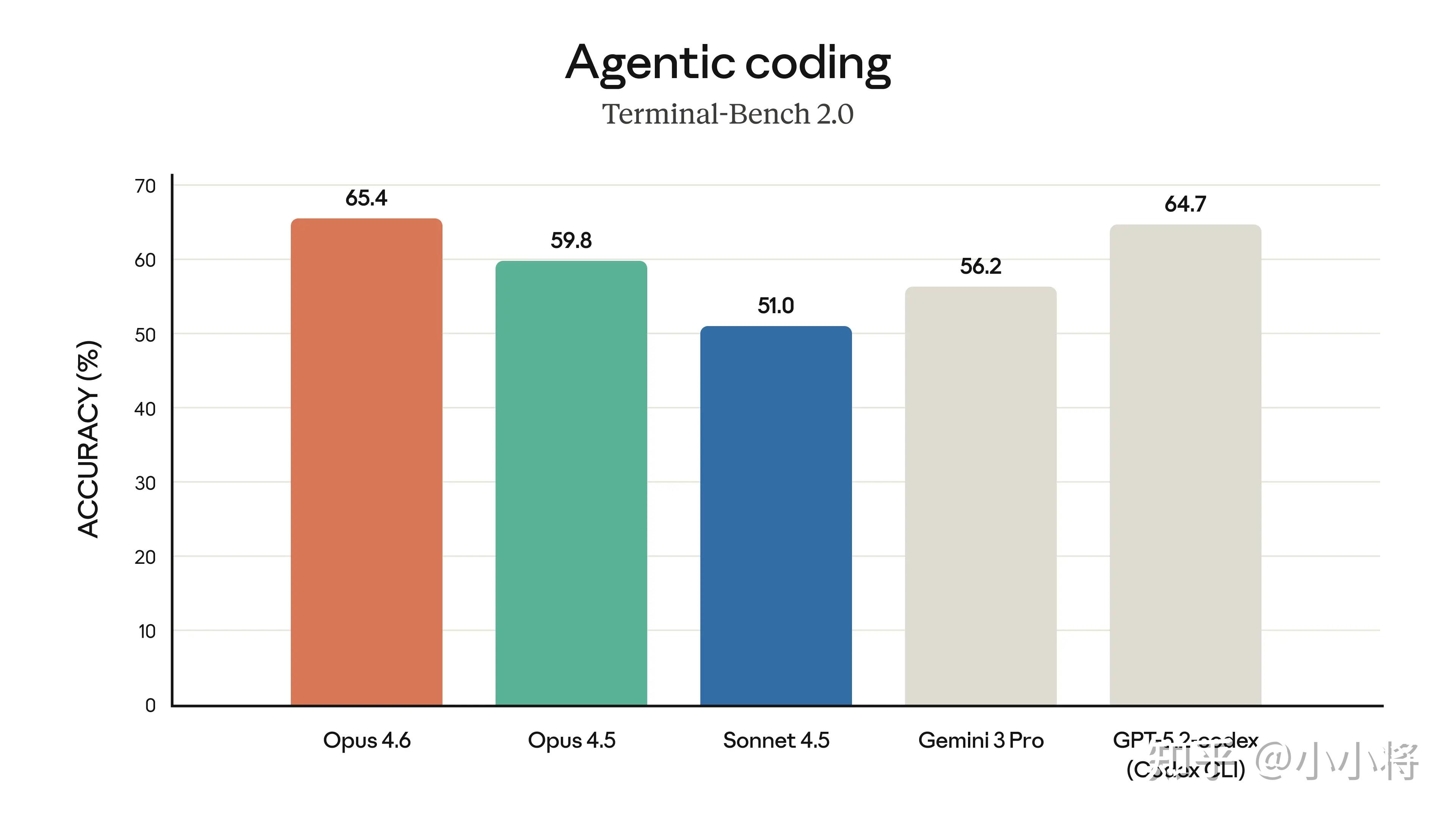
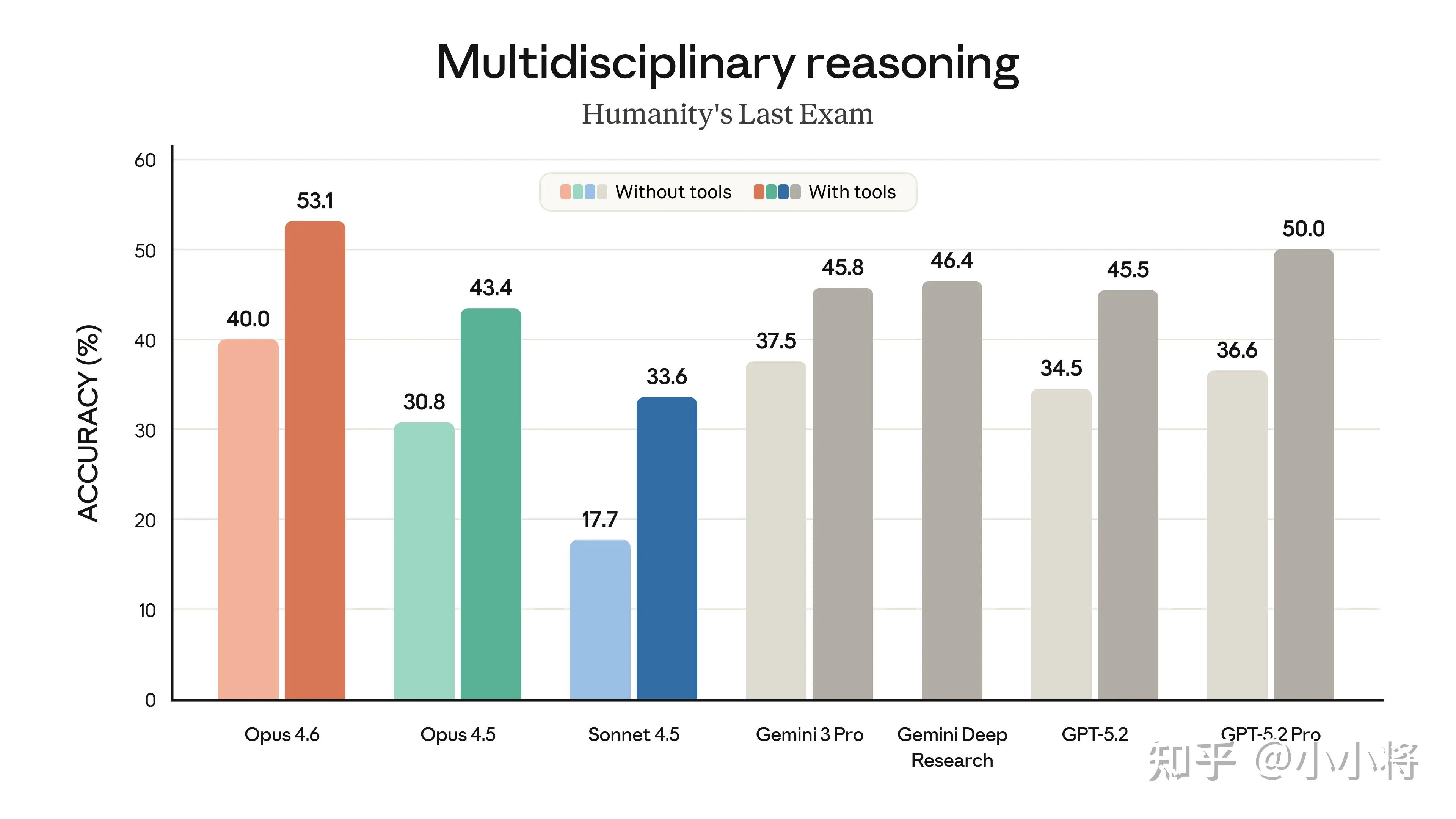
在复杂的多学科推理测试 Humanity’s Last Exam 上,也领先所有其他前沿模型(超过 GPT-5.2 Pro)。
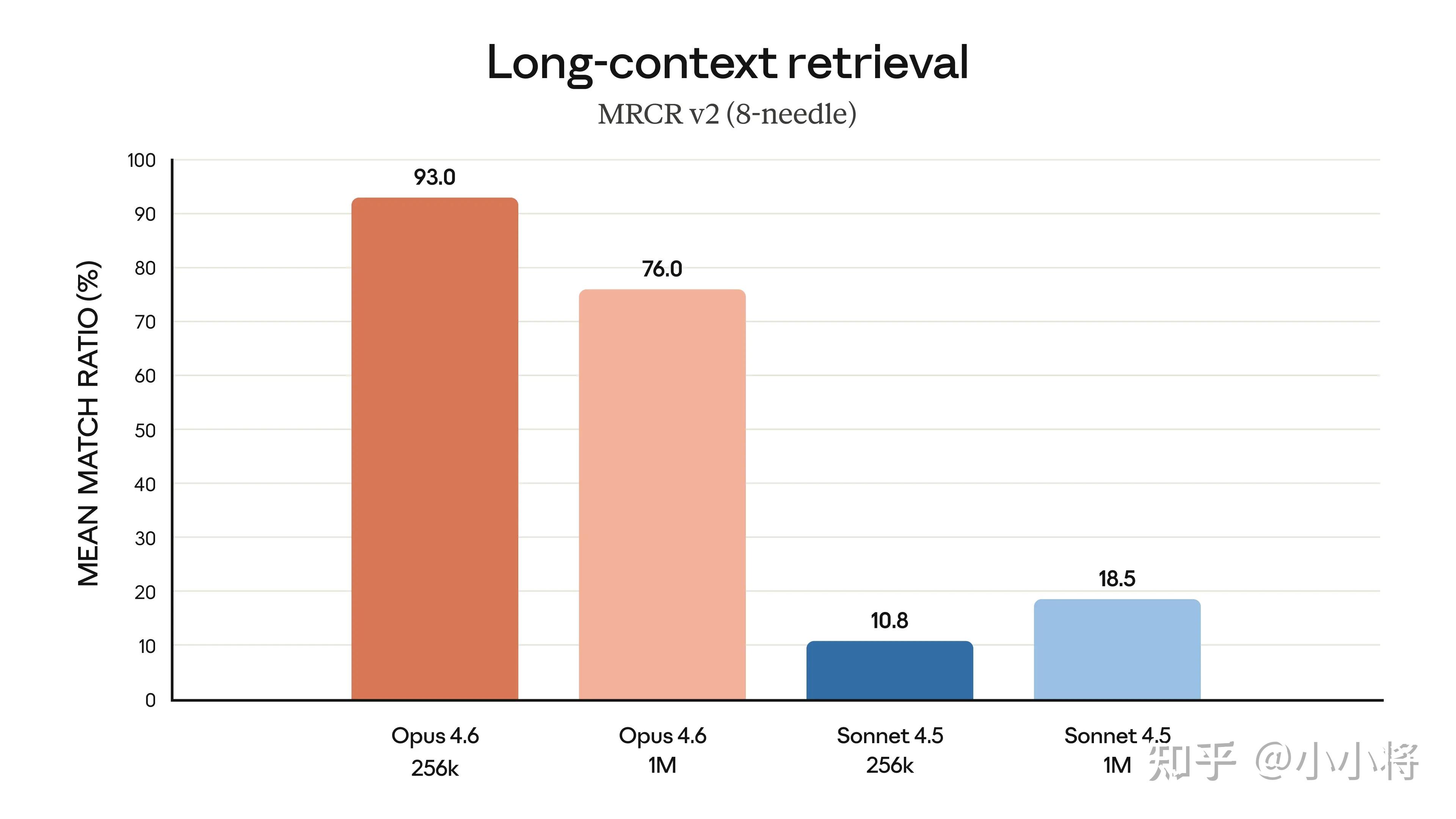
Claude Opus 4.6 的另外一大亮点是支持1M上下文(beta版本,默认还是200K),更重要的是,它在长上下文任务上的实际可用性有了明显提升:不仅能在数十万 token 的输入中更稳定地保持关键信息,减少“上下文腐化”(context rot),还能更准确地从大量文档中检索相关内容。相比前代模型,Opus 4.6 在超长文本中找信息、基于长上下文继续推理的能力都有质的提升,这使得它更适合用于大型文档分析、长对话 agent 和复杂研究任务。
比如在 MRCR v2 的 8-needle 1M 版本测试中(一个“大海捞针”式基准,用于评估模型在海量文本中找出被“隐藏”信息的能力),Opus 4.6 的得分为 76%,而 Sonnet 4.5 仅为 18.5%。
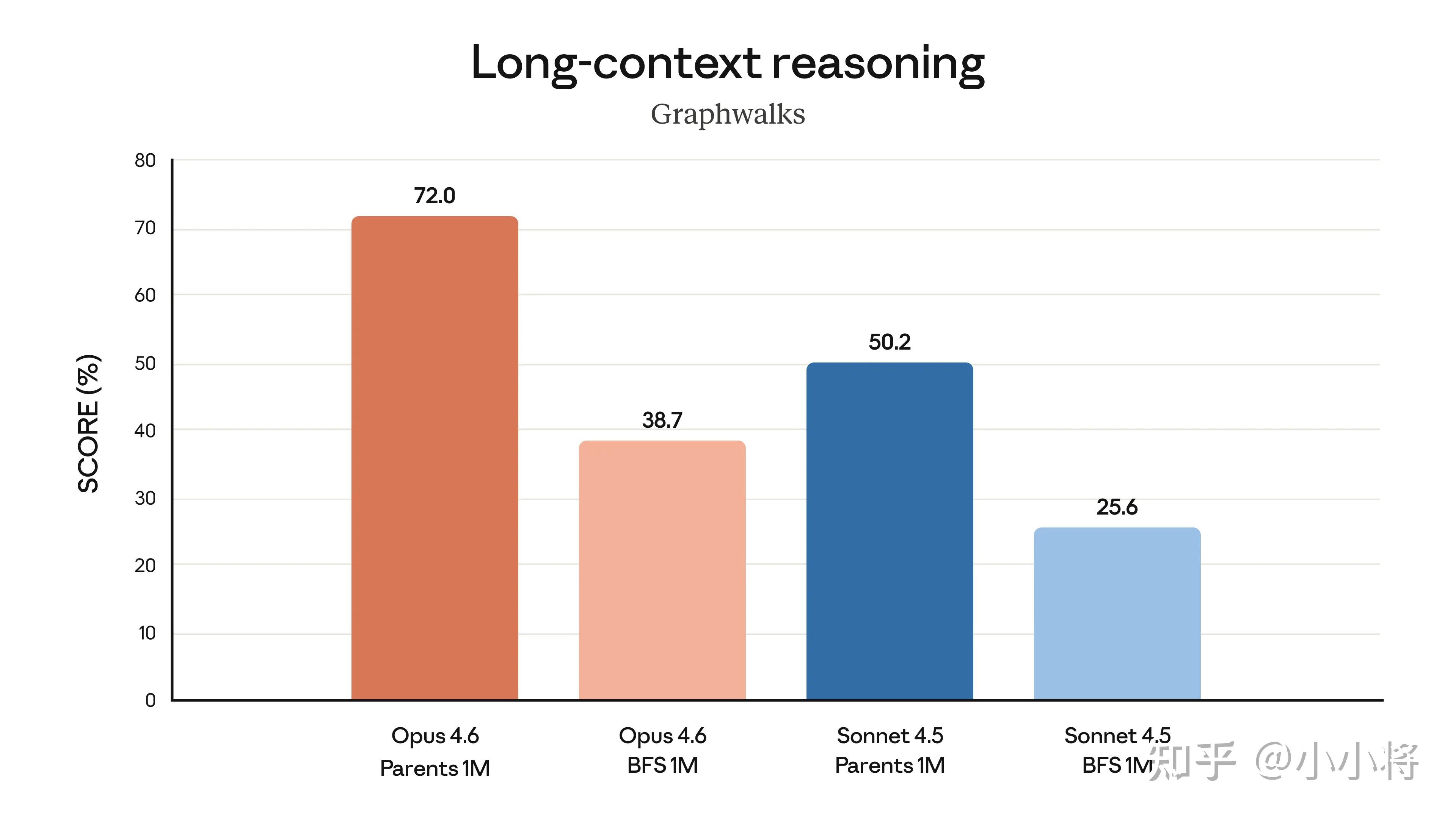
而且,Opus 4.6 在长上下文中也表现出色的深度推理能力,在长下文推理评测集Graphwalks上也明显优于 Sonnet 4.5。
除此之外,Claude Opus 4.6 在软件工程能力、多语言编程能力、长期上下文连贯性、网络安全能力 以及 生命科学知识等领域也有出色表现。
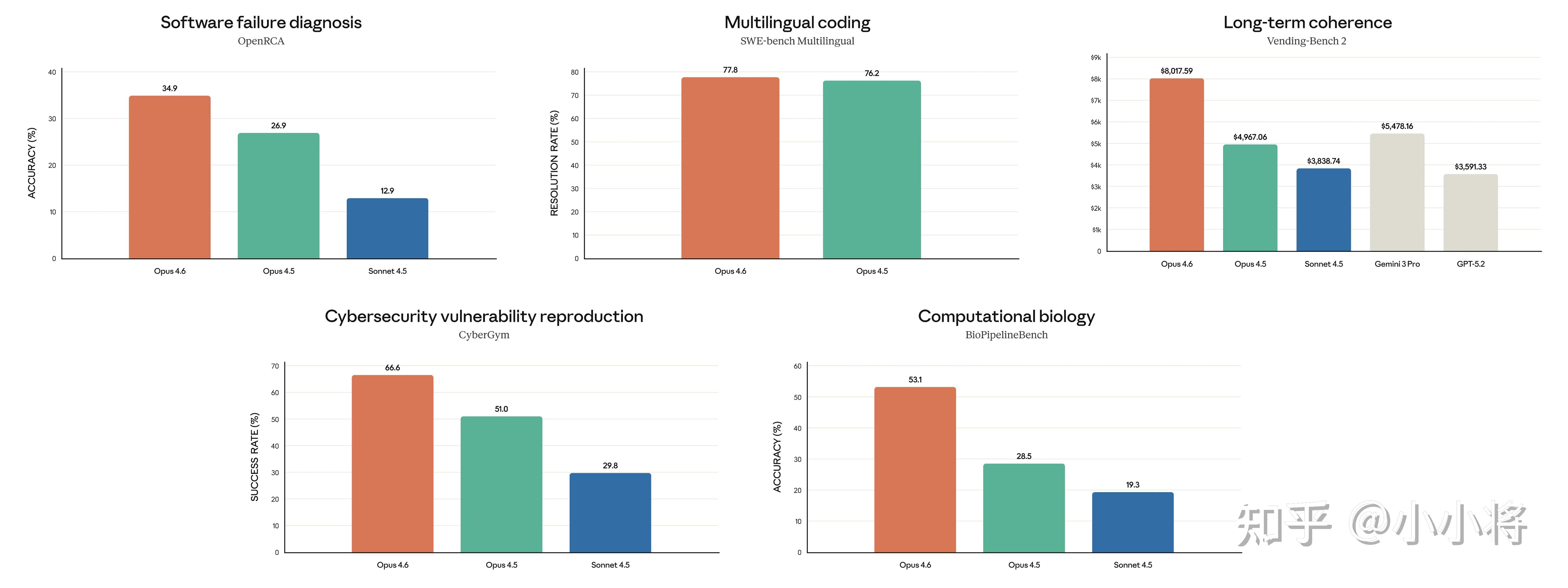
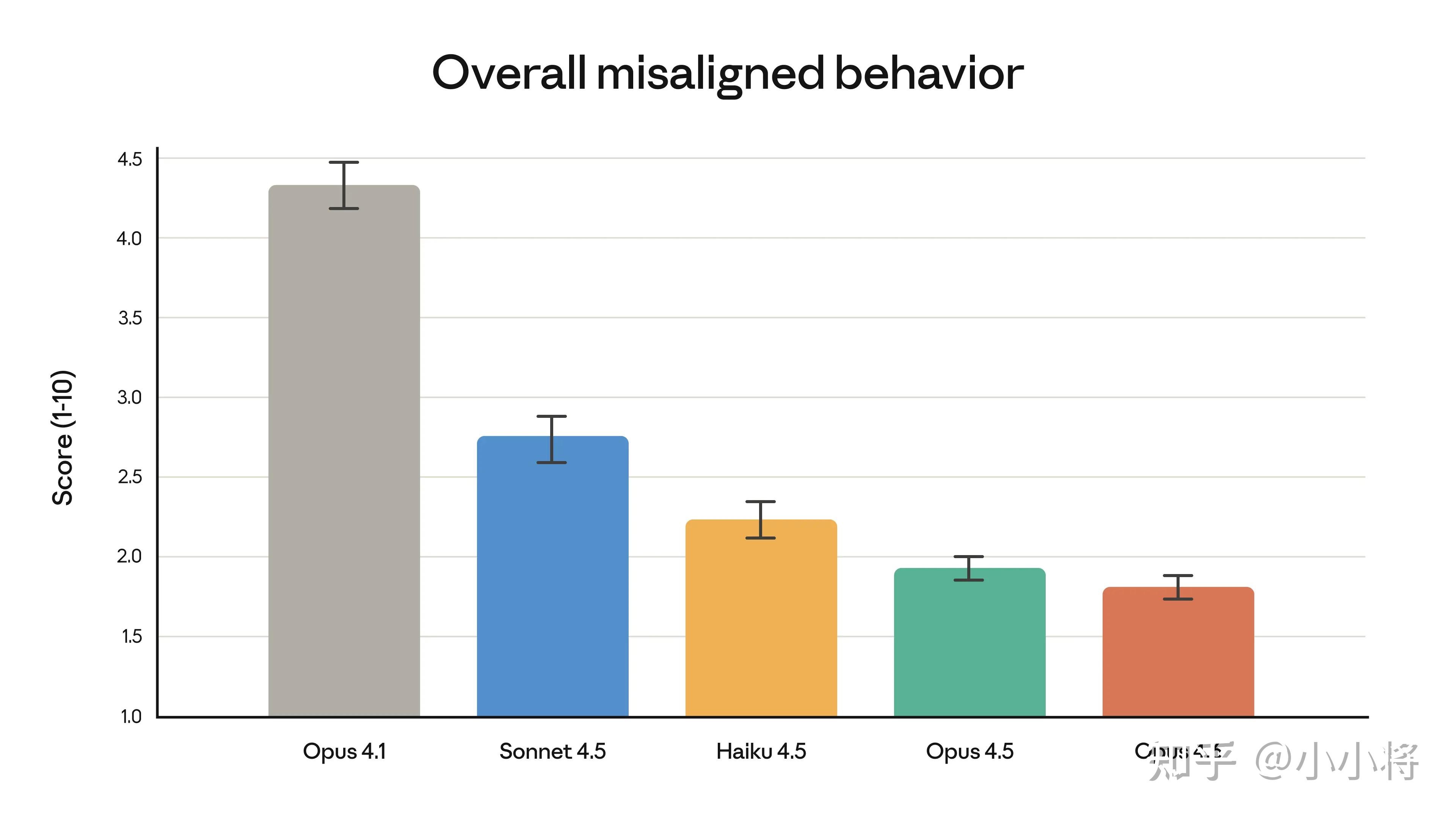
Claude Opus 4.6 在智能能力提升的同时,还保持了高水平的安全性:它在误导、谄媚、鼓励妄想及配合滥用等不当行为上的出现频率低,过度拒答率也是近期 Claude 模型中最低。
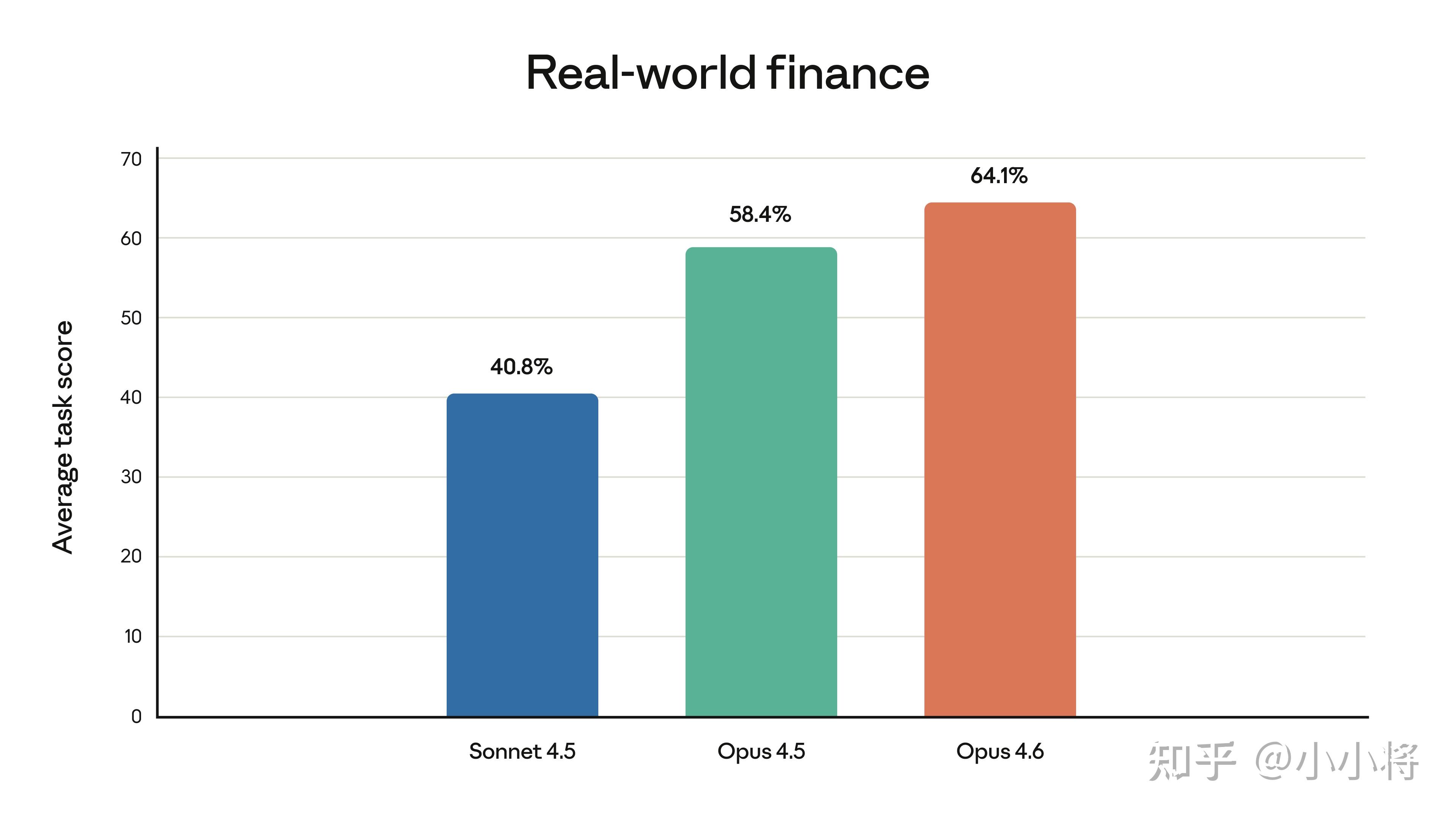
特别地,Claude Opus 4.6 在金融 AI 领域取得显著进展,能够帮助专业人士基于准确分析做出决策,并生成高质量成果。它在金融推理、多任务处理和长周期任务专注度上优于市场上其他模型。内部评测显示,Claude Opus 4.6 在约 50 个金融分析用例上的表现,比前代模型 Claude Sonnet 4.5 提升超过 23 个百分点。
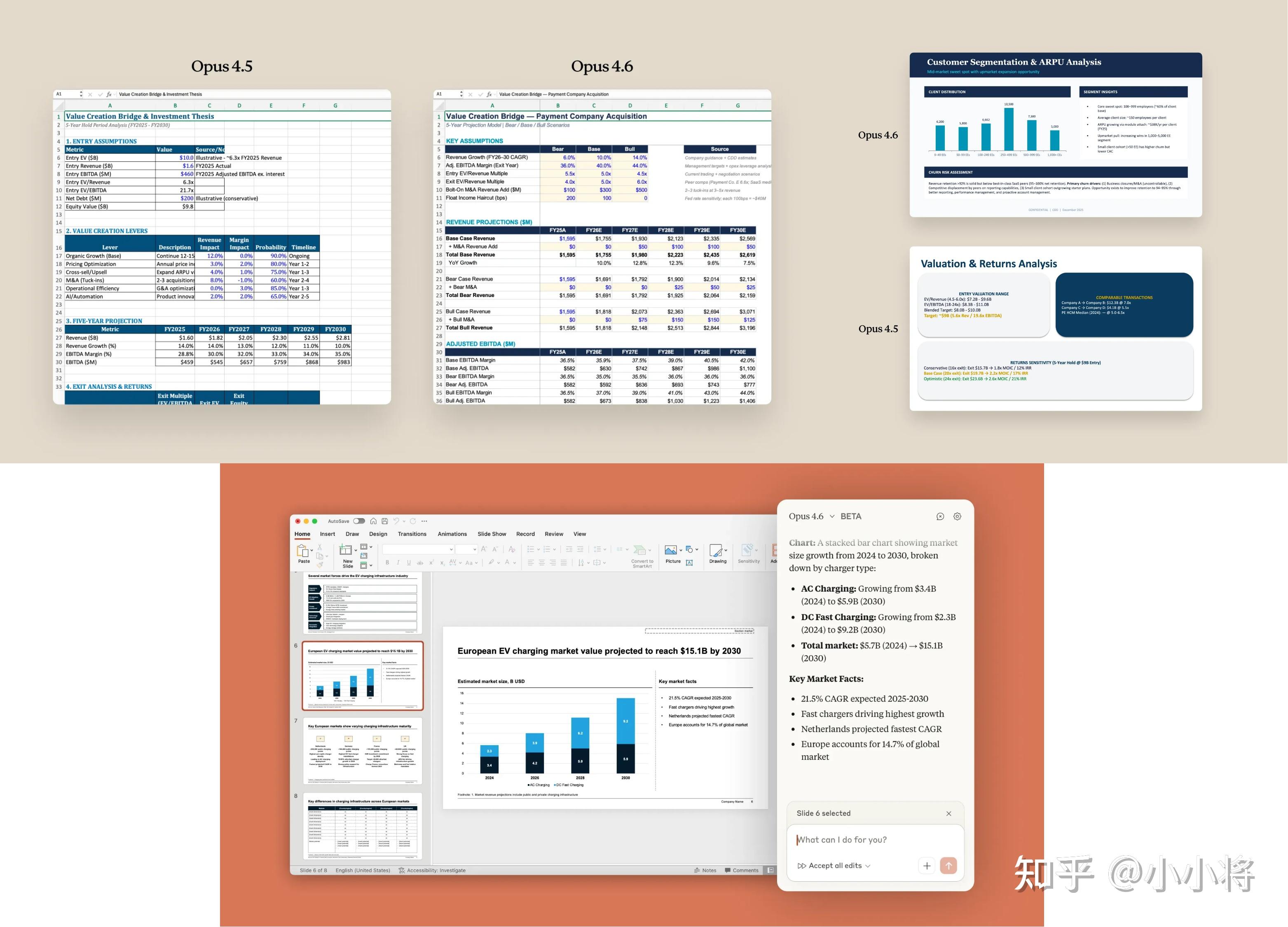
配合 Cowork、升级的Claude in Excel 和新推出的 Claude in PowerPoint,分析师可以更高效地完成财务模型、演示文稿和文档生成等工作。
 https://www.zhihu.com/video/
https://www.zhihu.com/video/
Claude Opus 4.6 的API也有升级,支持1M上下文,输出支持128K,最大亮点是支持了自适应思考(adaptive thinking)。在自适应模式下,模型的思考是可选的。Claude 会评估每个请求的复杂度,并决定是否以及需要思考多少。
在默认的 high 思考等级下,Claude 几乎总会进行思考;而在较低的努力等级下,对于较简单的问题,Claude 可能会跳过思考。自适应思考还会自动启用交错思考(interleaved thinking),即 Claude 可以在调用工具的过程中进行思考,这使其在 Agent 工作流中表现尤为高效。

此外,Effort 参数(思考等级)现已全面开放(不再需要 Beta 标识),而且新增了 max 思考等级,这样就共有四档:low、medium、high(默认)和 max。
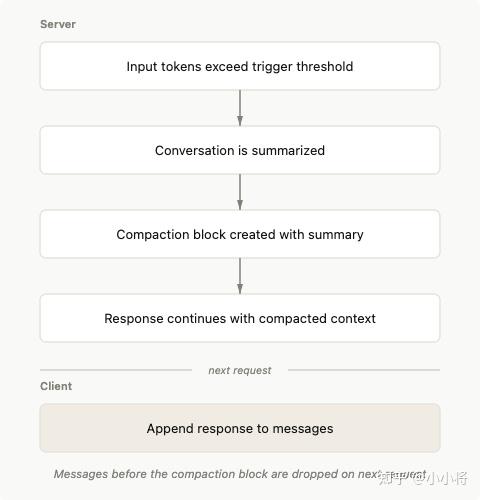
而且,Opus 4.6 还支持了上下文压缩(Beta阶段)。在长时间对话和 Agent 任务中,往往会达到上下文窗口的限制。上下文压缩会在对话接近可配置阈值时,自动总结并替换较早的上下文,从而让 Claude 在更长任务中持续运行而不受限制。
如果你想在国内更稳定地使用 Claude Opus 4.6 的 API,可以通过JieKou.AI(https://jiekou.ai/referral?invited_code=6K5X7J) 接入。目前已经同步上线 Claude Opus 4.6,同时也支持 ChatGPT、Grok、Gemini 等模型,一个接口就能切换不同模型使用。
而且都是走官方 API 通道,国内网络可以直接访问,不需要额外配置,也支持支付宝付款。最近还新出了订阅包,用订阅包的方式算下来,价格大约是官方 API 的 75 折,对个人开发者和小团队更友好。无论是做 Agent 工作流,还是日常内容生成、代码和分析任务,都可以作为统一入口来用。
现在已经可以在JieKou.AI 上体验 Claude Opus 4.6 的自适应思考和 1M 上下文能力。注册时用这个(6K5X7J),还可以领取 3 刀试用券,用来实际测试模型效果。
除了推出Opus 4.6,Claude Code也支持了新功能:agent teams(研究预览阶段)。用户现在可以启动多个并行协作的 Agent,并实现自主协调:最适合需要拆分为独立、以阅读为主的任务,如代码库审查。agent teams 适合独立操作的并行任务,而对于顺序任务、同文件编辑或依赖复杂的工作,单会话或subagents 更高效。
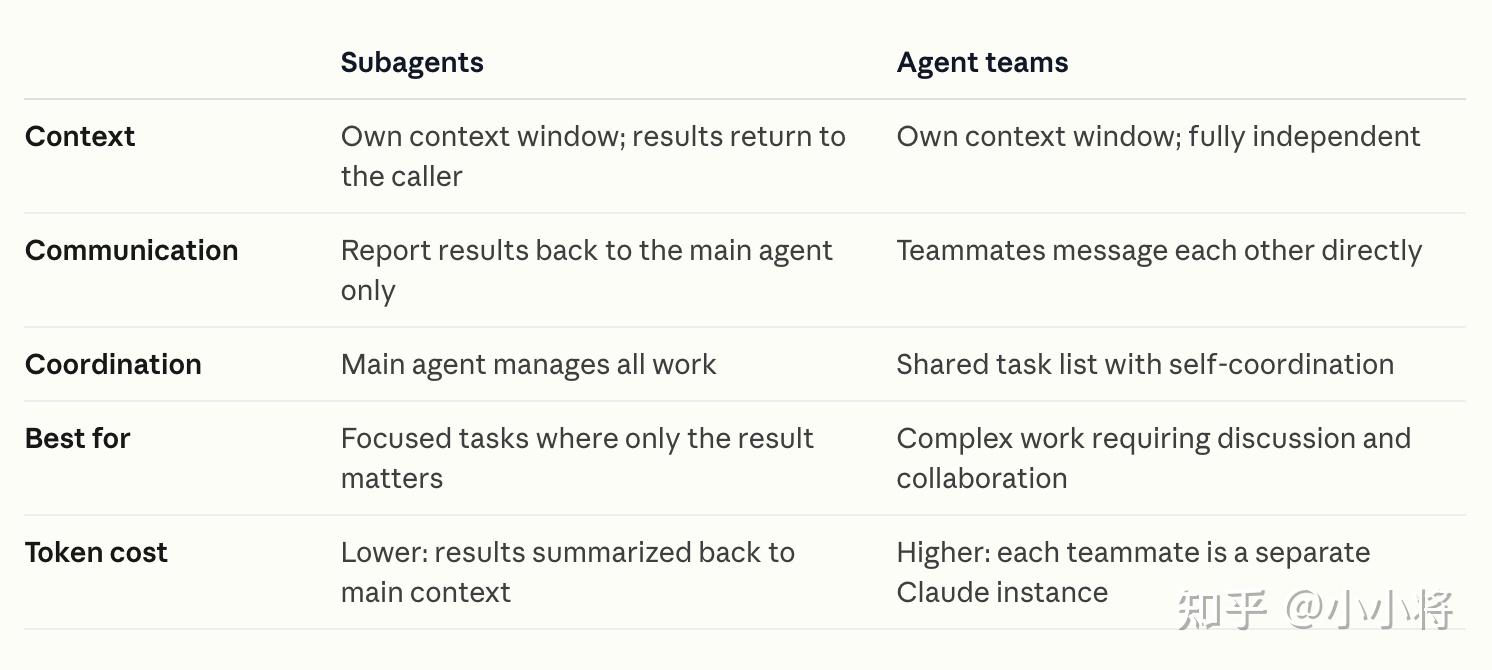
这里还举了一个很牛逼的例子:拿Opus 4.6 通过agent teams来构建一款 C 编译器。然后几乎放手不管,两周后,它居然可以在 Linux 内核上运行。看起来未来不久AI自主开发软件将成为现实。
 https://www.zhihu.com/video/
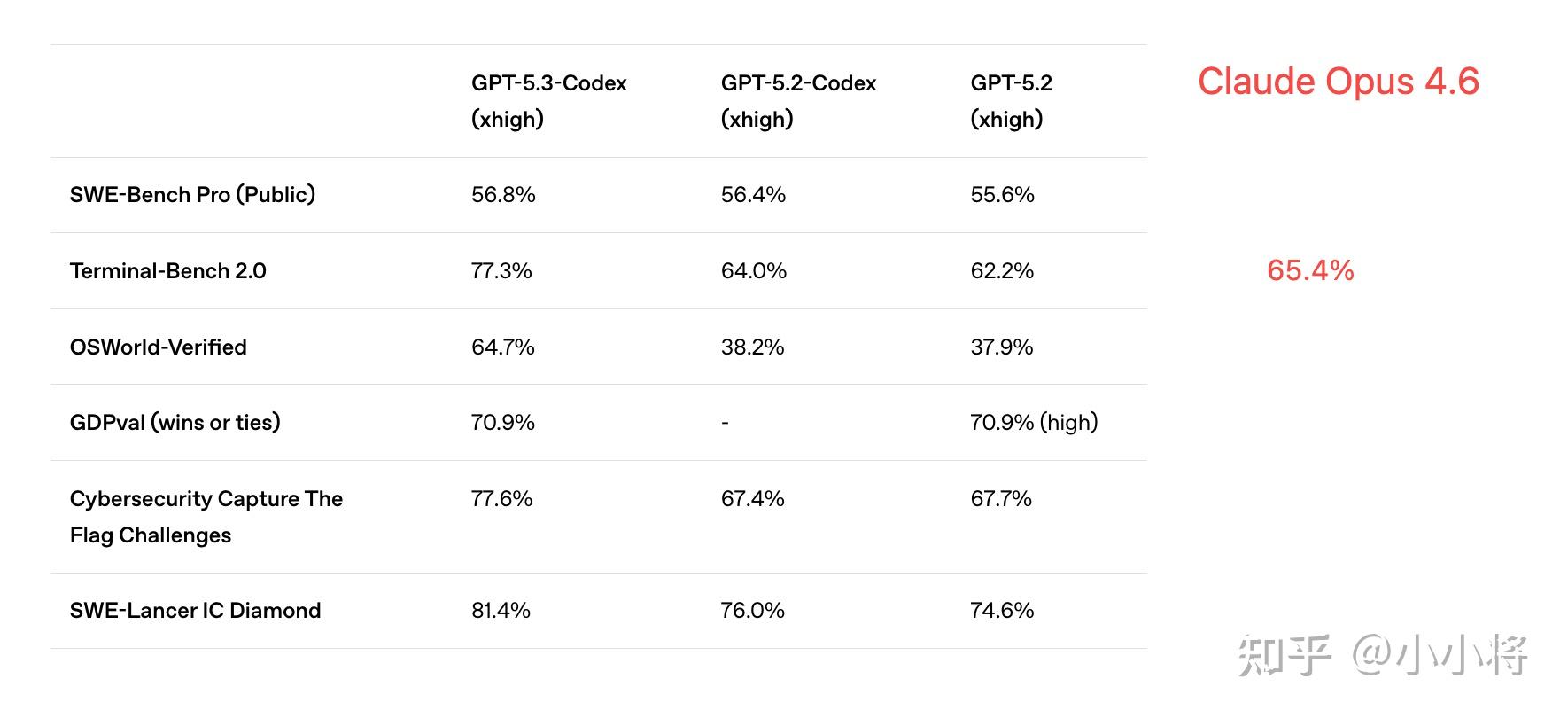
https://www.zhihu.com/video/ 不过,在Opus 4.6的推出的同时,OpenAI也在昨晚发布了GPT-5.3-Codex,在 Terminal-Bench 2.0 上,GPT-5.3-Codex 达到了77.3%,显著超过了Opus 4.6。Anthropic和OpenAI真是一对冤家。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/215100.html