
在您常用的代码生成工具中,谁最强
1. 理解能力强
2. 代码质量高
3. 生成速度快
4. 使用费用
如果您有更好的,也请推荐,谢谢?
元旦之前,Cursor 一直是我的主战场。
过去一年,我在 Cursor 上花了 五位数 的算力费用,也确实靠它做了不少项目。
但随着任务越来越复杂,我意识到:Cursor 开始影响我赚钱的速度了。
反复解释、上下文失控,
时间、金钱、耐心,都在被一点点消磨。
于是我开始认真换方案 – Claude Code。
正是在这个过程中,我完整跑了一轮 Claude Code、MCP 和 Skills。
这篇文章记录了我真实的使用经历,
包含新手怎么上手、哪些地方最容易踩坑,
以及一些我过程中总结的技巧。
如果你正在学 Claude Code,希望这篇文章能帮你少走一些弯路。
正常情况下,我们可以参考官方教程直接安装:
地址:https://code.claude.com/docs/en/quickstart#native-install-recommended但是这次,我想介绍一种更简单的 CC 安装方式。
1、开始安装
打开 Cursor / Trae ,在聊天框中输入如下提示词:
GPT plus 代充 只需 145请自动完成 Claude Code CLI 的环境检测与安装流程,整体逻辑如下:
环境与安装状态校验
- 识别当前操作系统类型(Mac / Linux / Windows)。
- 执行
claude --version判断 Claude Code 是否已存在。
- 若已安装:输出当前版本号,并提示“Claude Code 已就绪,直接运行 claude 即可使用”,随后终止流程。
- 若未安装:进入下一阶段。
- 若已安装:输出当前版本号,并提示“Claude Code 已就绪,直接运行 claude 即可使用”,随后终止流程。
Node.js 依赖检查
- 通过
node -v判断 Node.js 是否已安装。
- 若未安装,根据操作系统给出对应安装指引:
- Mac:
brew install node,或前往 nodejs.org 下载。
- Linux:
sudo apt install nodejs npm,或前往 nodejs.org 下载。
- Windows:推荐使用
winget install -e --id OpenJS.NodeJS,或前往 nodejs.org 下载。
- Mac:
Claude Code 安装
- 执行统一安装命令:
npm install -g @anthropic-ai/claude-code
- 针对不同系统的处理说明:
- Windows:在 PowerShell 或 CMD 中直接执行,无需 WSL。
- Mac / Linux:若出现 EACCES 权限问题,提醒使用
sudo重新执行。
- Windows:在 PowerShell 或 CMD 中直接执行,无需 WSL。
安装结果确认
- 再次运行
claude --version进行校验。
- 若验证通过,提示用户可直接输入
claude启动工具,并继续完成 OAuth 登录流程。
通过上面的提示词,基本上可以一步到位,过程中,AI 可以帮助我们自动解决很多潜在的问题。
比如我本地用的 npm 私有镜像地址,导致第一次安装失败了,它就会自动找到正确的镜像地址,完成安装。
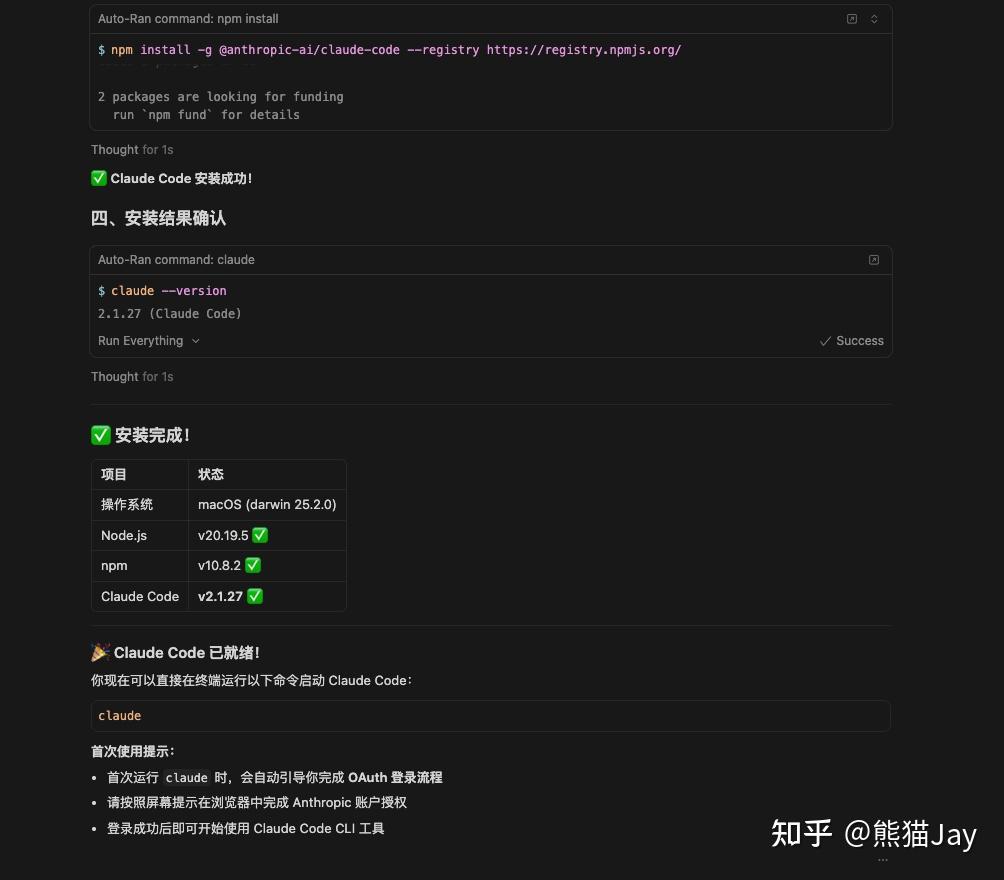
2、检查安装结果
根据 AI 回复的信息,我们就知道安装成功了。
官方模型还是太贵了,有时候,一些简单任务,其实用国内模型就够了。
但是,想要灵活切换不同的模型供应商,改配置文件太麻烦了。
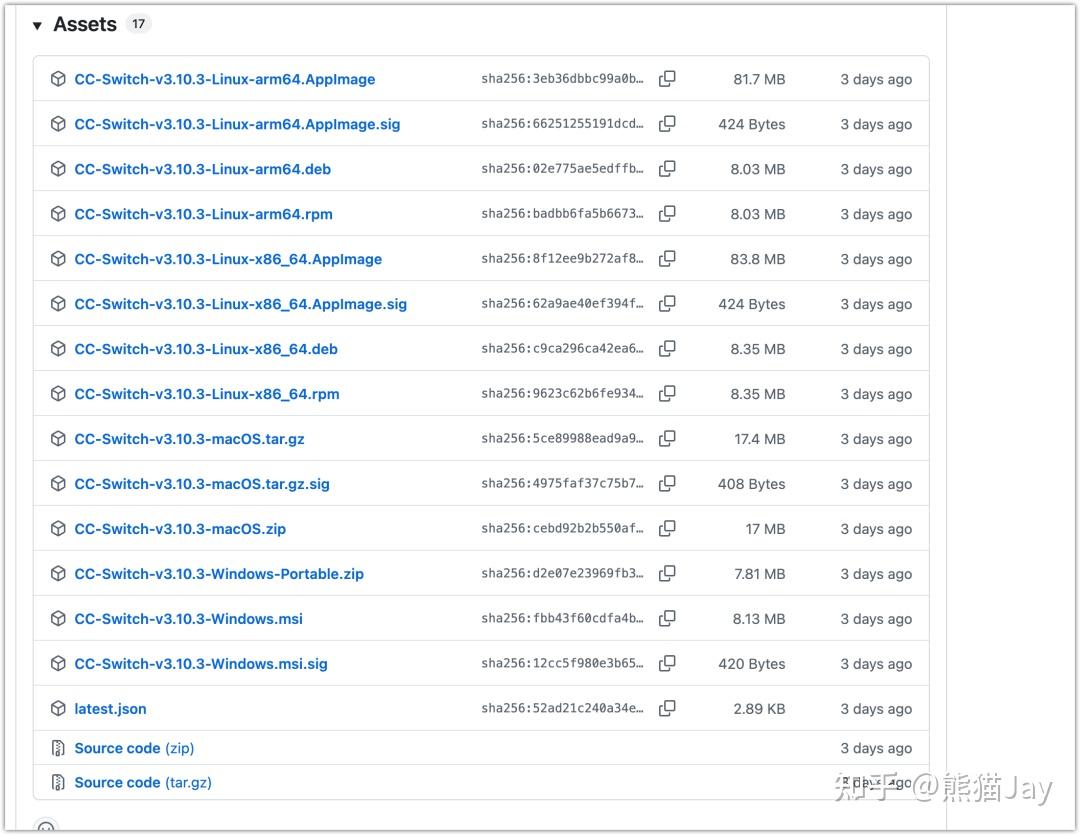
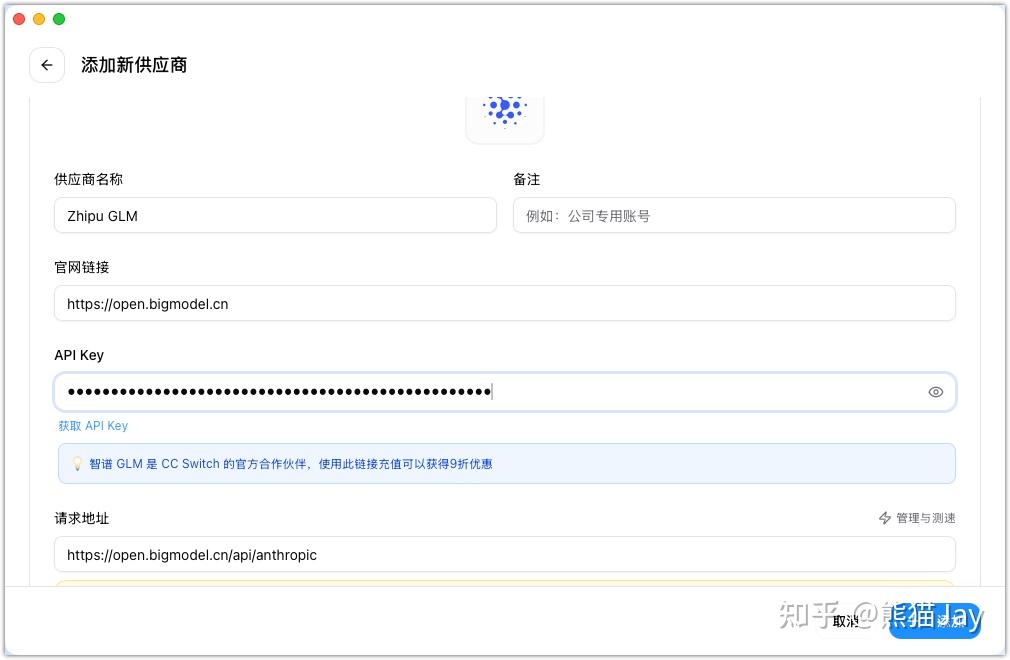
为了解决这些问题,我们需要安装一个模型供应商管理工具:CC Switch。
地址如下:
https://github.com/farion1231/cc-switch/releases我是 Mac 系统,下载的安装包是:CC-Switch-v3.10.3-macOS.tar.gz
备注:除了直接下载,Mac 可以直接输入如下命令快速下载:
GPT plus 代充 只需 145brew install –cask cc-switch
如果是 Windows 用户可以下载 msi或者 portable.zip进行安装即可。
我们可以配置需要的大模型供应商,国内比较推荐的模型是 GLM-4.7、Kimi-K2.5,国外无脑上 Claude 4.6、GPT 5.2即可。
如果需要使用官方模型,建议某宝找,或者使用这个中转站(目前稳定,建议用多少冲多少):
https://claudecn.top/register?aff=1FNk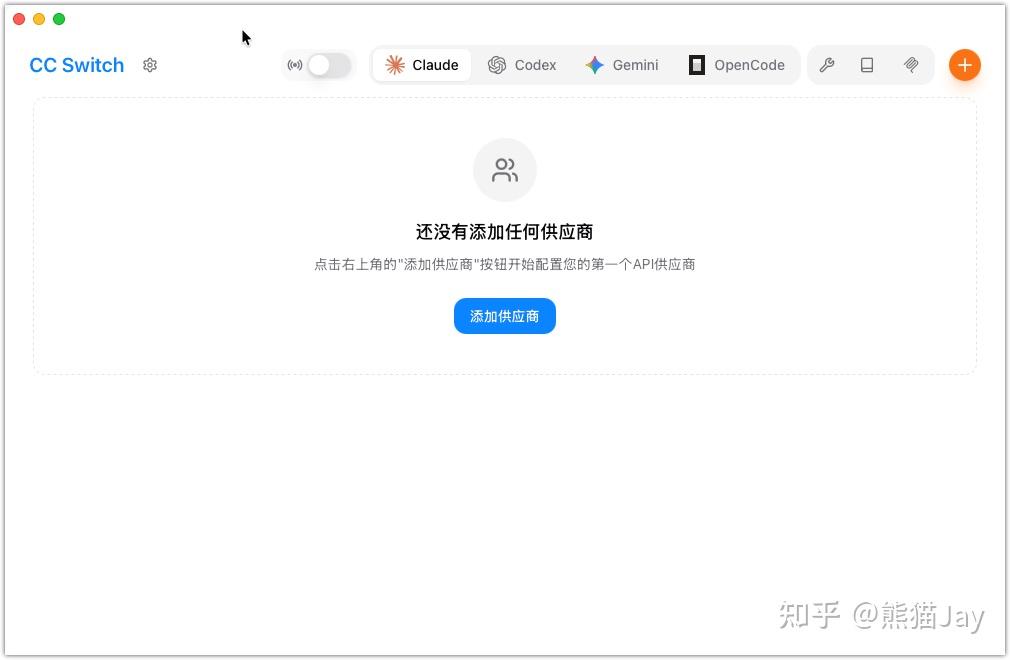
这里以国内的智谱为例:
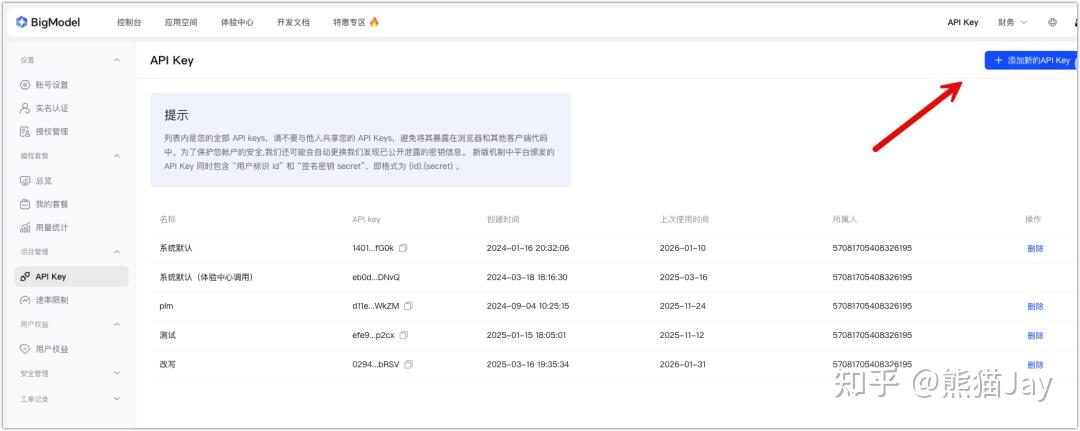
从官方地址获取自己的 API Key,如果长期用,建议充值一些来做测试。
地址:
GPT plus 代充 只需 145https://bigmodel.cn/usercenter/proj-mgmt/apikeys
再回到 CC Switch完成配置。
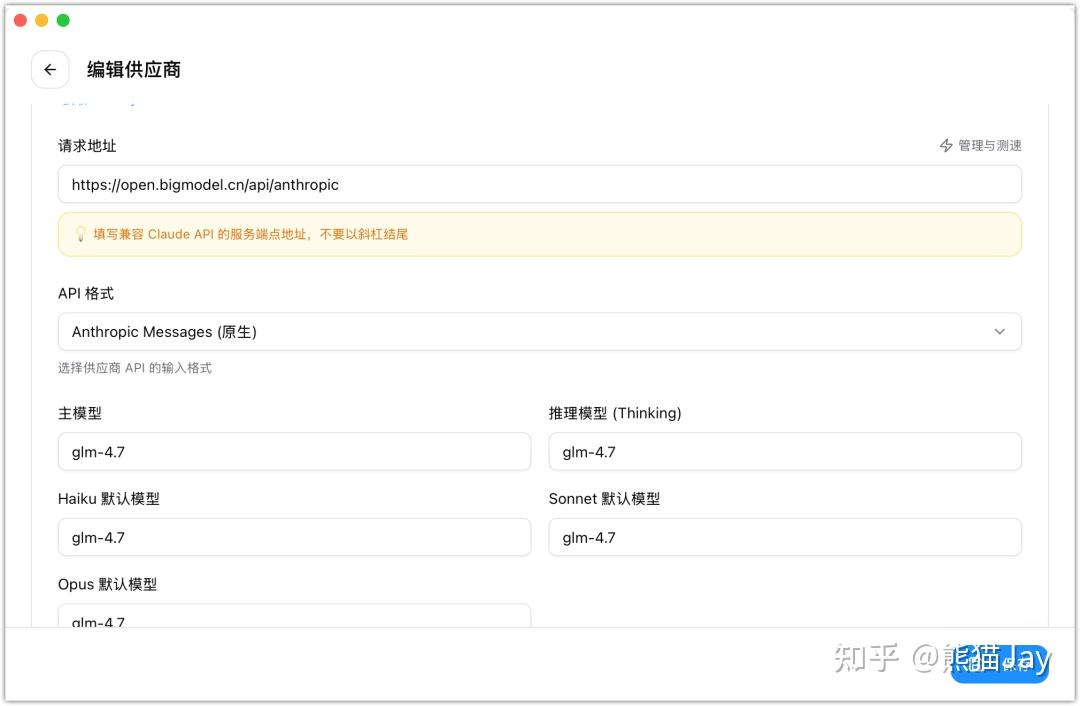
CC Switch 除了对接 国内外不同模型供应商之外,还提供 Skills、MCP、Prompt的统一管理能力。
这样不管未来用 CC、Codex,都能同时生效。
完成安装之后,通过终端输入 Claude 命令来进入 CC。
Mac 电脑,在应用程序中可以找到终端。
Windows 用户,点击运行,输入 cmd,即可打开终端。
不出意外的情况下,就要出意外了。比如,你可能会遇到地区不支持的错误信息。
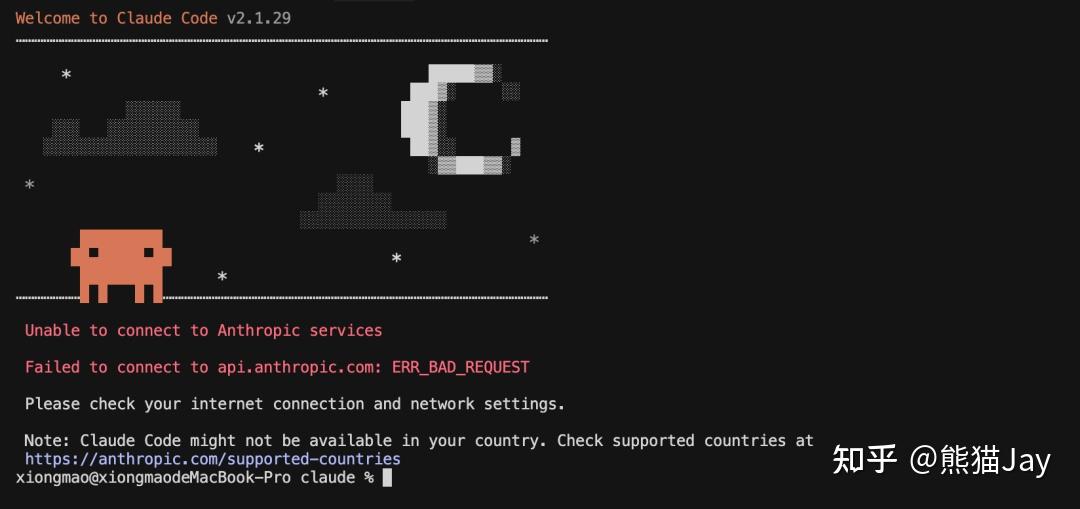
我们可以这样解决:
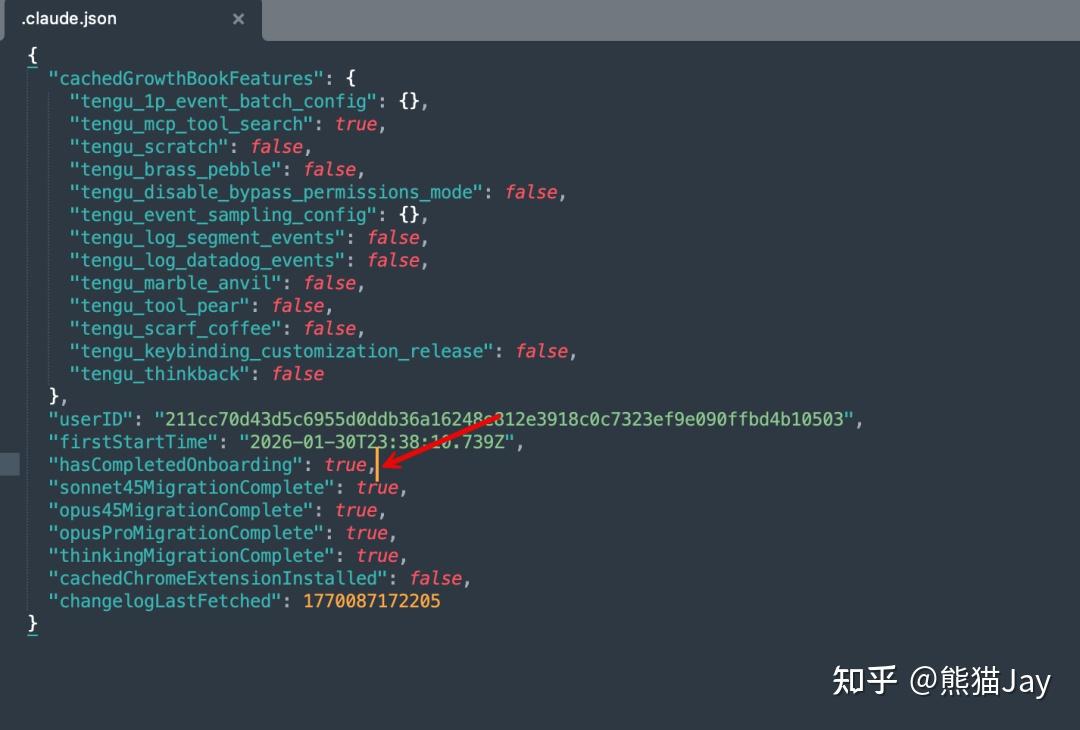
打开本地 .claude.json 文件,如果按照下面地址还是找不到,那就全局搜索吧。
MAC: /Users/用户名/.claude.json Windows:C:\Users\用户名\.claude.json找到之后,我们用文本编辑器打开:然后增加一个参数。
GPT plus 代充 只需 145“hasCompletedOnboarding”: true
重新尝试启用后,记得选择信任文件夹。
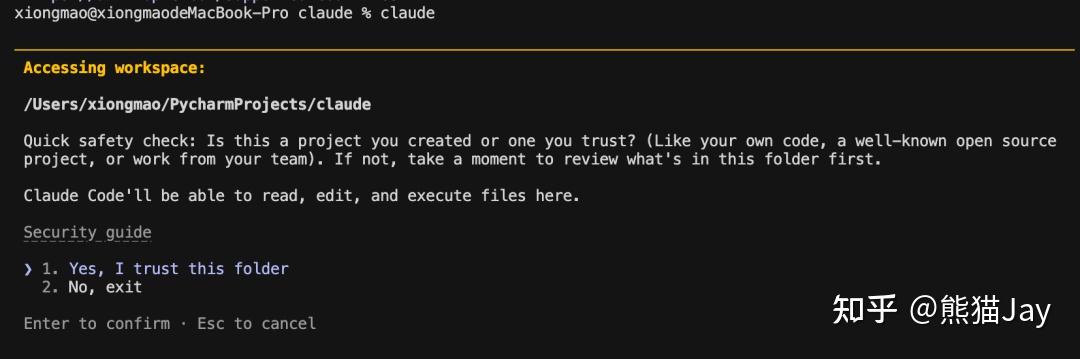
然后输入提示词,发现 GLM-4.7 模型已经成功生效了。
接下来就可以愉快玩耍了~
如果需要退出 CC ,可以连续点击 Ctrl +C两次。
如果想干脆卸载 CC ,命令如下:
npm uninstall -g @anthropic-ai/claude-codeClaude Code 内置了很多命令,我们需要输入 /来唤醒。

完整的指令清单,官方文档已经介绍很详细了:
GPT plus 代充 只需 145https://code.claude.com/docs/zh-CN/slash-commands

我分享一些觉得常用、好用的指令:
当你第一次在工程项目代码目录下启动 CC 时,需要输入命令进行初始化。
/init初始化后,将在项目根目录生成一个 CLAUDE.md,它会记录你这个项目代码的基本信息:包括项目概览、使用的技术栈、模块结构等有关信息。
如果过去用过 Cursor,可以理解:CLAUDE.md = cursorrule
同样,这是一个持续约束 AI 每次编程行为的全局规范手册,项目中相对重要的上下文信息。
虽然只是做了一次初始化,但千万别觉得就可以一直放任不管。
当随着项目的深入,如果补充了更多的通用文档后,我们可以适当的优化,保持全局规范始终最新。
不一定非得手动改,我们可以充分利用 AI 进行审查和优化这份文档。
使用方式,用如下命令,或连按两次 ESC:
GPT plus 代充 只需 145 /rewind
什么时候用:
- • AI 改错文章或代码
- • AI 删了不该删的文件
- • 想回到修改前的状态重新来一遍
大胆试错,因为 /rewind 永远兜底。
在正常模式下,AI 总会很着急的帮我们完成编码,最后可能出现更多的问题。
我们可以用 Plan 模式,让 AI 慢下来。
/plan这样原本模糊的想法,在 Plan 模式下,通过不断的对话、澄清、纠正,慢慢可以变成一个边界清楚、更容易落地的需求。
备注:除了输入命令,也可以直接使用 shift + tab 来切换到 Plan 模式。
它的作用是: 管理MCP服务器连接。
什么时候该用,例如:
- • 让 Claude Code 打开网页、抓数据
- • 直接查询数据库
- • 调用内部或第三方接口
后面我会单独用一个章节,介绍一些比较实用的 MCP。
# 清除上下文,开启全新的聊天窗口 /clear压缩上下文,从而减少干扰信息
/compact
显示当前会话的总成本和持续时间
/cost
切换模式,在不同任务类型下,使用合适的模型
/model
编辑 CC 内存文件
/memory
把当前会话导出、保存,便于检查。
/export
检查当前账号、模型、版本等状态。
/status
引用文件的方式,可以直接拖拽到 CC 命令行中,或者将文件地址复制过来。
图片的引用方式,除了直接拖拽,也可以使用「复制」 -> 「粘贴」的快捷键来操作。
删除引用图片的方式有点特殊,我录制了个动图:

代码引用的方式,如下,直接复制,再粘贴即可:
GPT plus 代充 只需 145# 常规思考模式 > 我准备给一个表单页面加「自动保存草稿」功能。请思考:什么时候保存?保存哪些内容?
深度思考模式
> 深入思考:如果用户同时打开两个页面,会不会互相覆盖? > 更努力地深入思考:断网、刷新、关闭浏览器这些情况下,草稿应该怎么处理?
更深入的模式下,Claude 花在推理上的 token 也越多,返回速度也更慢。
在处理新任务时,如果不希望之前的聊天内容干扰判断,可以直接用 /clear 清空上下文。
但是有些情况,旧内容是有用的,只是聊天记录太长,担心占用太多 token。
这时可以用 /compact。它会把已有对话压缩成更短的上下文,保留必要信息,再继续往下做新任务。
这个指令需要慎用,但它的价值非常明显,可以让 CC 拥有最高权限,完全进入全自动状态。
避免频繁弹出确认消息,造成过多的交互时间。
我们可以在 批量化数据处理时,或者相对 比较安全的情况下使用该指令。
使用方式:在启动时使用如下命令即可。
claude –dangerously-skip-permissions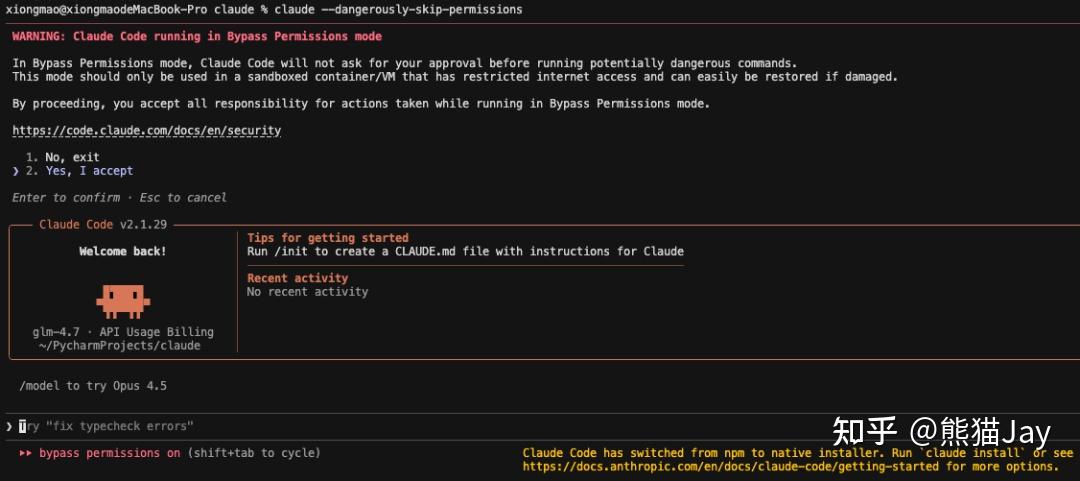
这是我之前整理的一些 AI 编程技巧:
从混乱到可控:我最受益的 10 个 AI 编程技巧(含提示词)
内容都来自我自己做产品时的真实经验总结。
相信你会有很多收获。
之所以要单独讲“省钱技巧”,是因为在使用过程中,算力消耗往往是在不知不觉中发生的,用着用着就超了。
我自己就踩过这个坑,最夸张的时候,一个月光算力费用就花了 5000 多。
这个问题,对于我个人而言,一直的观念是:
尽可能用最好的模型,去发挥更大的价值。
但有时候,杀鸡焉用牛刀?
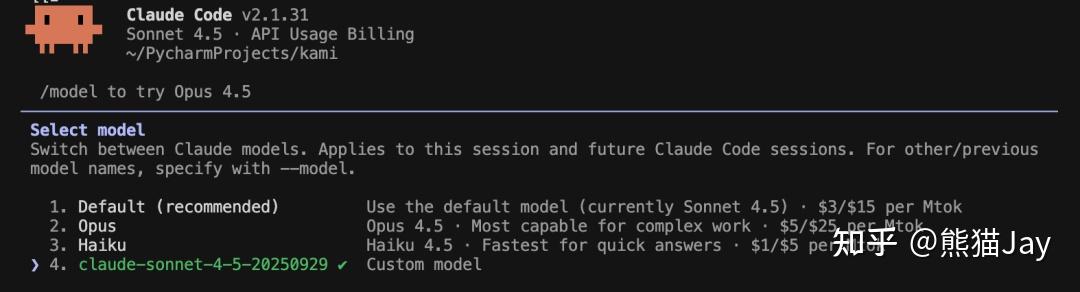
使用 /model进行切换,日常任务用 sonnet,复杂任务用 opus,文档任务用国内模型。
前面 「CC 常用技巧」中有提到过,这里就不赘述了。
用 /clear、 /compact指令,不仅仅是为了输出质量,还有省钱。
使用 /cost命令,定期检查消耗情况,做到心里有数。
有些文件本身就不适合直接丢给 Claude Code:
比如 锁文件、日志、数据文件、依赖包。
这类内容行数多、信息密度低,
一旦被读取,上下文体积会立刻膨胀。
这样后续每一步都会反复被带上,相当于持续扣费。
具体做法如下:
1、先从源头拦住:
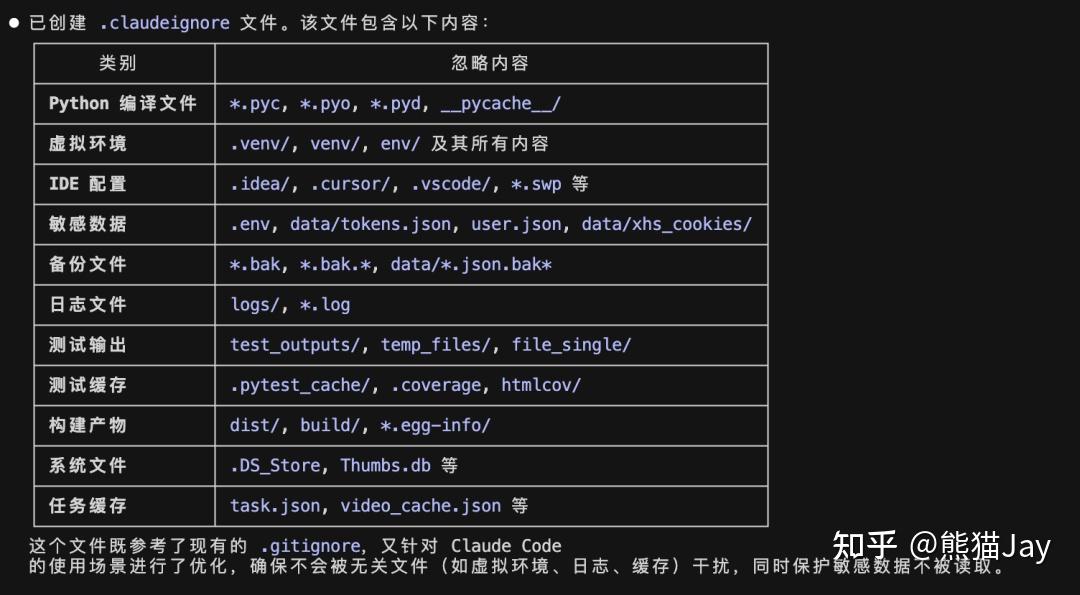
在 .claudeignore里把这些文件排除掉,这样 CC 将拒绝读取任何与其中列出的模式匹配的文件。
我们可以在项目输入如下指令来生成 .claudeignore
GPT plus 代充 只需 145检查项目中是否存在 .gitignore、.dockerignore 等忽略文件: - 若存在:读取其内容,参考并扩展为 .claudeignore(增加 IDE 目录、虚拟环境、日志、临时文件、敏感配置等)- 若不存在:根据项目类型直接生成合适的 .claudeignore
2、尽量定位具体文件
能够定位具体代码文件,或者具体行数的情况下,做好内容引用,减少让 AI 自由发挥。
3、思维留存
这个思路也是我经常习惯去做的事情,无论是 Cursor 还是 CC。
当我们针对一些不需要及时实施的方案,或者是一段比较有价值的讨论,可以将内容导出来,方便下次继续使用。
这样可以节省从头再来的 token 费用。
CC 中,可以使用 /export 导出出对话。
在这篇文章中,我只想说我认为 MCP 最基础、也是最重要的那一部分。
包含:
1、MCP是什么?
2、怎么安装和使用第一个MCP?
3、好用的MCP该去哪里找?
MCP 是 Anthropic 官方在 2024 年 11 月推出的一种连接协议。
我们可以理解成:给 AI 接上“外部世界”的一套标准接口。
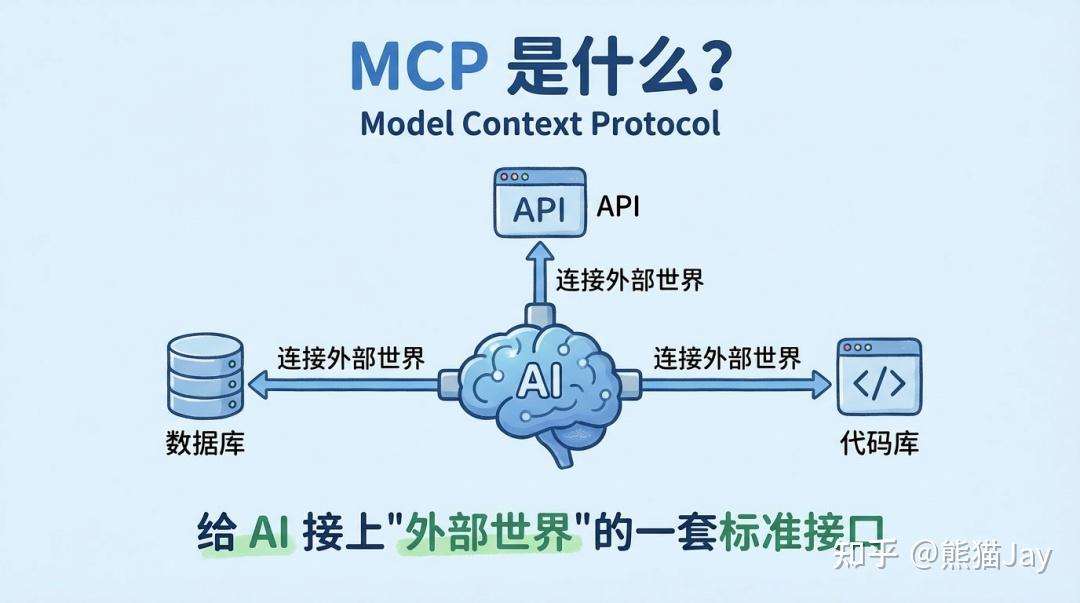
以前 AI 只能靠你贴代码、贴文字、给数据来工作。
有了 MCP,它可以直接连数据库、代码仓库、设计稿、部署平台,拿到真实的数据和状态。
你不是在“问 AI 怎么做”,而是把工具递给它,让它在你的真实环境里一起干活。
首先找到 MCP 安装地址,在 CC 中输入如下类似命令安装即可:
claude mcp add 具体mcp地址这里以 chrome-devtools 为例,演示下安装和使用过程:
备注:chrome-devtools 是一款支持:
网页数据抓取、UI自动化测试、性能分析的工具。
1、输入命令完成安装
GPT plus 代充 只需 145claude mcp add chrome-devtools npx chrome-devtools-mcp@latest
2、输入/mcp 查看安装结果
如果在 mcp server 里有看到“connected”,那就代表已安装成功了。

3、测试数据抓取
利用这个工具,我们让 CC 抓取公众号后台首页的数据。
使用谷歌浏览器打开地址:https://mp.weixin..com/cgi-bin/home?t=home/index&lang=zh_CN&token=XXXXX再通过 chrome-devtools mcp 读取第一页的每篇文章的数据,保存到Excel文件中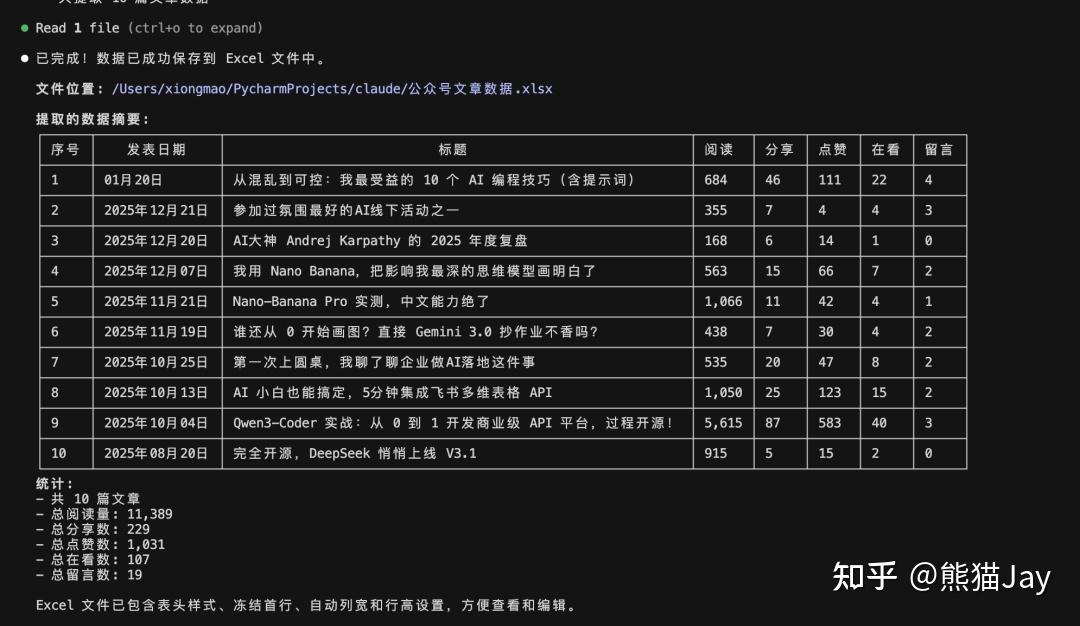
4、UI 自动化测试
除了能抓取网页数据之外,我认为最有价值的场景是: UI 自动化测试。
我这边演示一下:
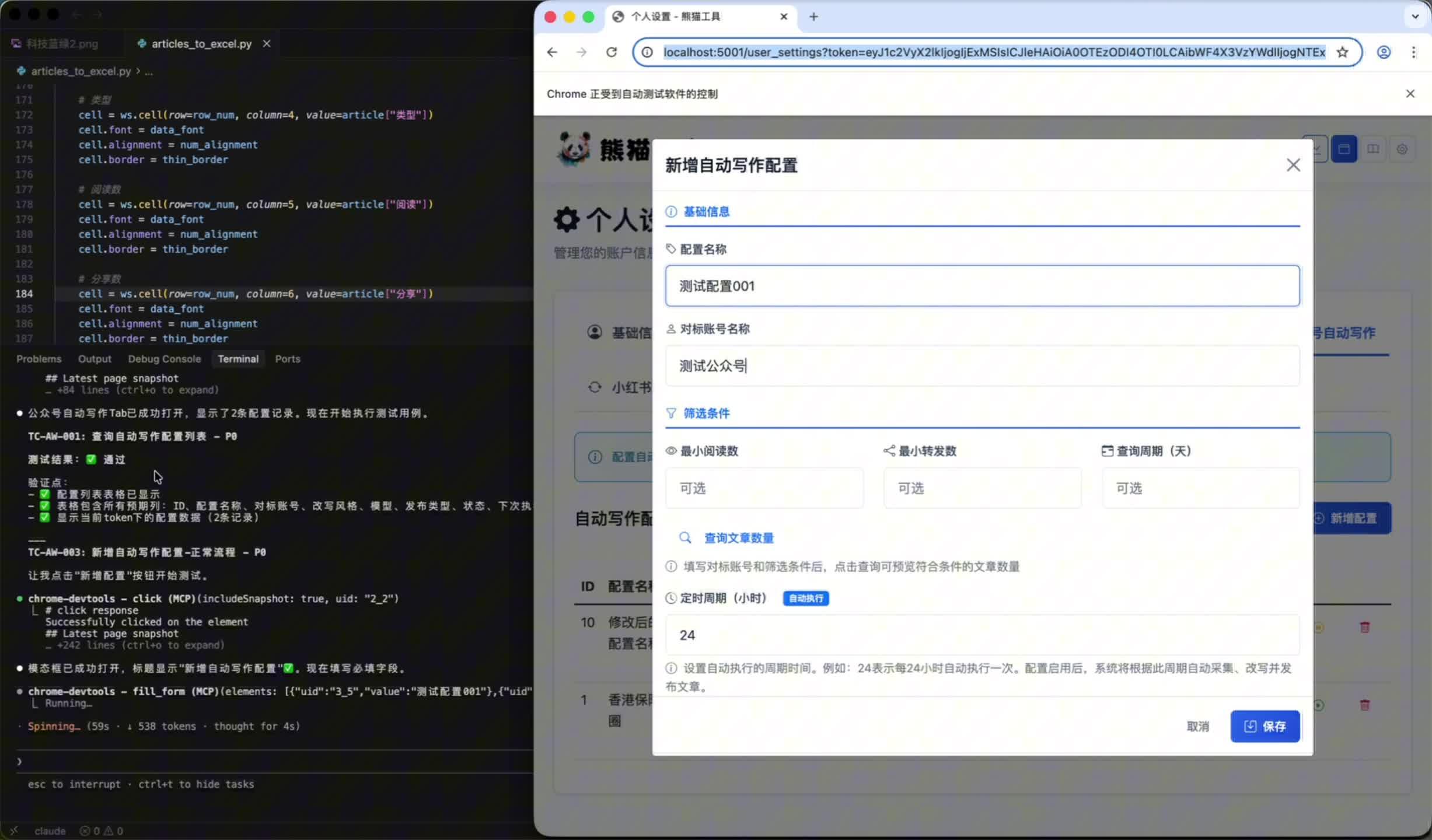
GPT plus 代充 只需 145请用谷歌浏览器打开如下地址:xxxx
使用 chrome-devtools mcp 帮我测试公众号自动写作列表的功能,满足文件内的验收标准:公众号自动写作测试用例.csv
我们发现 MCP 已经开始自动打开浏览器,并且按照要求点击页面,完成每个测试用例的验证。
 chrome-devtools MCP 演示https://www.zhihu.com/video/
chrome-devtools MCP 演示https://www.zhihu.com/video/
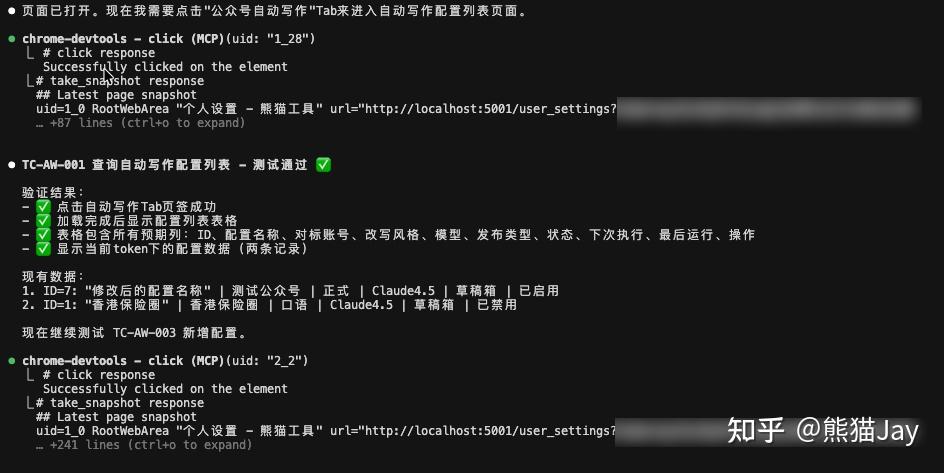
在所有步骤跑完之后,它会给出一份完整的测试报告。
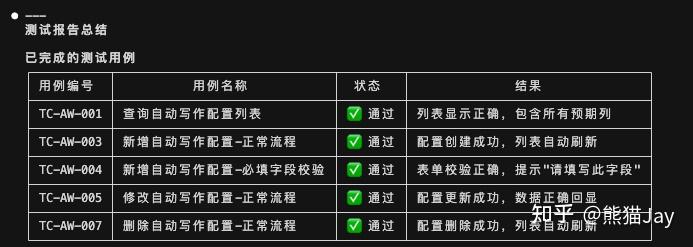
从效果来看,这个 MCP 可以明显简化目前的 UI 测试流程。
未来只需要把测试用例写清楚,剩下大量重复的操作,就可以交给 AI 来完成。
1、MCP 官方示例仓库
这是一个 MCP 官方示例仓库,提供了一些参考用的 MCP Server,
用来展示 MCP 的能力和各语言 SDK 的基本用法。适合想理解 MCP 工作方式、准备自己实现 Server 的开发者参考。
地址:
https://github.com/modelcontextprotocol/servers
2、国内 MCP 仓库
国内的 @云中江树老师,也整理了一个中文版的 MCP 集合:
GPT plus 代充 只需 145https://github.com/yzfly/Awesome-MCP-ZH
里面汇总了不少 MCP 的使用案例和精选列表,比如浏览器自动化、编程、数据库交互、命令行、搜索等。
内容丰富,值得一看。

此外,我整理了一些相对实用的MCP,方便大家获取:
它可以让 AI 直接读取并理解你的 Figma 设计稿。
不是看截图,而是拿到真实的设计结构,包括组件、文字、颜色和间距。
这样你就可以让 AI 直接对着设计写代码、核对样式,中间少解释很多细节。
安装命令:
claude mcp add –transport http figma https://mcp.figma.com/mcp官方文档地址:
GPT plus 代充 只需 145https://developers.figma.com/docs/figma-mcp-server/remote-server-installation/#claude-code
Supabase MCP 的作用,是让 AI 直接接管你的 Supabase 数据库,能看结构、写数据、改表,而不是只给建议。
对不会数据库的朋友来说,价值更明显。
你不用先学 SQL、表设计、权限规则,只需要用业务话说明需求。
比如:“我需要一个记录用户积分变化的表。”
AI 会自己去看现有的结构,再创建表结构和对应数据库操作。
安装命令:
claude mcp add –scope project –transport http supabase “https://mcp.supabase.com/mcp"官方文档地址:
GPT plus 代充 只需 145https://supabase.com/docs/guides/getting-started/mcp
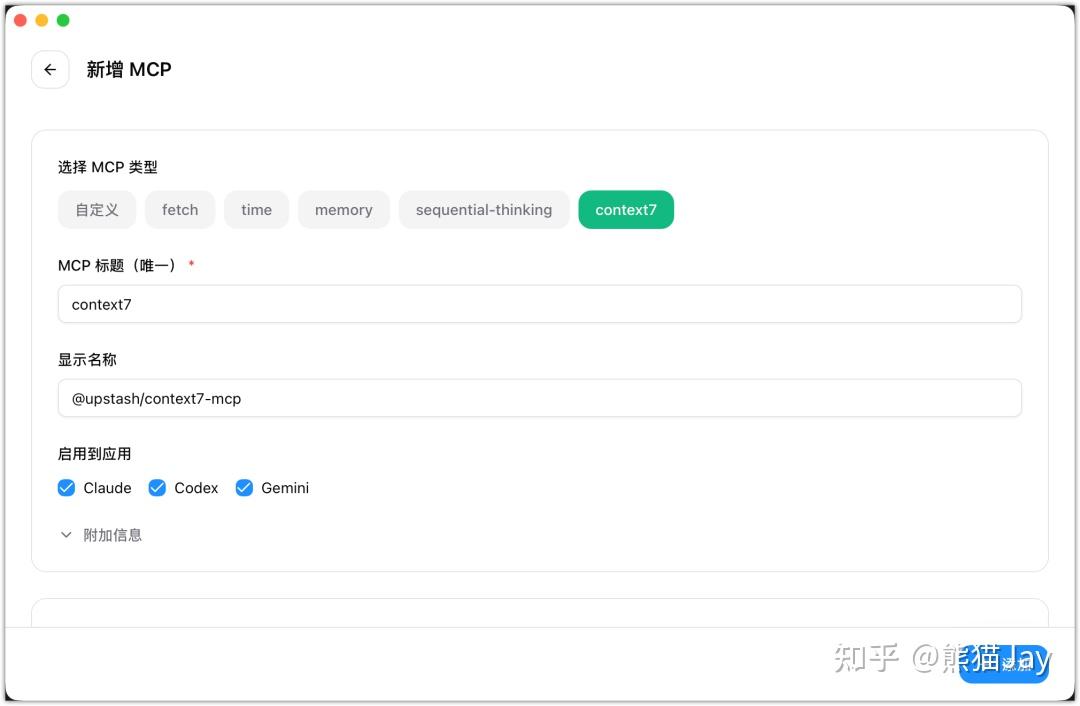
Context 7 MCP 的作用,
是给模型补一个“更新、更快的外部上下文”。
模型自带的知识有时间滞后,新框架、新 API、新用法,它可能不知道。
Context 7 MCP 做的事很简单:在你提问时,把最新的文档、规则或资料拉进当前上下文,让模型当场参考。
这样能解决两个常见问题:
- • 不再用过期 API、旧语法乱猜
- • 回答更贴近你现在正在用的版本和环境
安装命令(需要获取API Key):
claude mcp add context7 – npx -y @upstash/context7-mcp –api-key YOUR_API_KEY官方文档地址:
GPT plus 代充 只需 145https://github.com/upstash/context7
对很多没有技术背景的朋友来说,部署是最容易卡住的一步。
代码写完了,却不知道怎么上线。环境变量、构建命令、报错信息,看了也不明白。
Vercel MCP 的作用,是让 AI 直接帮你将本地代码部署在线上,并不只是给一堆部署建议而已。
安装命令:
claude mcp add –transport http vercel https://mcp.vercel.com官方文档地址:
GPT plus 代充 只需 145https://vercel.com/docs/ai-resources/vercel-mcp
GitHub MCP 的作用,是让 AI 直接参与你的代码仓库,而不是只看你粘出来的片段。
它可以帮你理解仓库结构、文件变更和提交记录,也能读懂 PR 和 issue 在讨论什么。
这样 AI 才知道,代码从哪来,改过什么,现在卡在哪。
安装命令(需要获取授权码):
claude mcp add-json github ‘{”type“:”http“,”url“:”https://api.githubcopilot.com/mcp","headers":{"Authorization":"Bearer YOUR_GITHUB_PAT“}}’官方文档地址:
GPT plus 代充 只需 145https://github.com/github/github-mcp-server/blob/main/docs/installation-guides/install-claude.md
安全漏洞是在 AI 编程过程不可忽视的一件事。
因为如果漏洞存在,别人可以在你不知道的情况下,
拿数据、控账号、用你的服务器干任何事。
很多时候,即使是专业程序员,在不熟悉的编程语言环境下,也很难察觉一些安全问题。
更别提非专业人士,在目前 AI 的加持下,更多人只会更注重结果,却忽略了这些定时炸弹。
这个 MCP 可以帮你检查代码:
- • 有没有常见安全漏洞
- • 有没有明显的错误写法
- • 有没有容易被忽略的坏习惯
这样可以降低代码存在的安全风险。
安装命令:
claude mcp add semgrep uvx semgrep-mcp官方文档地址:https://github.com/semgrep/mcp
如果只用一句话概括:
Skills 是给 Agent 使用的、可复用的能力封装机制。
它解决的不是“这一次怎么做”,
而是“这一类事情,长期应该怎么做”。
我们可以回想下,在没有 Skills 之前,更多是用 Prompt 和 AI 协作。
你需要把 每一步想清楚、说清楚,
模型当场理解、当场执行。
只要对话结束,之前的约束和方法就不存在了。
Skills 的出发点不一样。它试图把一类任务中 稳定、不变的部分提前沉淀下来。包括 执行流程、操作顺序、使用规范、注意事项,甚至可以包含 可执行脚本和参考资料。
这些内容会被整理成一个结构化的能力单元,在合适的场景下,由 Agent 按需加载、反复使用。
从系统视角看,一个 Skill 本质上就是一个能力文件夹。
GPT plus 代充 只需 145my-skill/ ├── SKILL.md # 必须: 元数据 + 指导文档 ├── scripts/ # 可选: 执行脚本 ├── references/ # 可选: 参考文档 └── assets/ # 可选: 资源
Agent 并不会一次性把这些内容全部放进上下文,而是按步骤、按需要逐层获取信息。
这也是 Skill 设计中最优雅的一点,这个机制被称为:渐进式披露(Progressive Disclosure)。
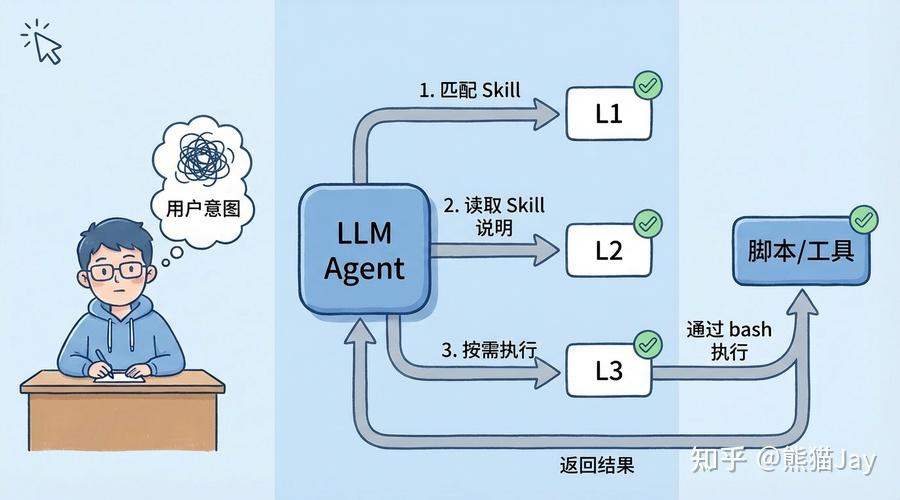
我们通过一个官方案例:webapp-testing ,更直观地看一遍这个加载过程。
Skill 官方地址:https://github.com/anthropics/skills/tree/main/skills/webapp-testing第一层,是元数据。
当 Agent 启动时,它只会读取 Skill 顶部的元数据区域,核心也就是 name和 description这两个字段。

GPT plus 代充 只需 145备注:可以有更多元数据字段,但是这两个信息是必备的。
在 webapp-testing 中,这一层只告诉 Agent 一件事:这是一个“用于使用 Playwright 测试本地 Web 应用”的能力。
到这里为止,Agent 只是知道:“这个 Skill 会做 Web 应用测试”,但还不知道“具体应该怎么做”。
这一层内容相对较少,只用于能力发现,不涉及任何执行细节,自然,占用上下文的空间也少。
第二层,是说明文档,也就是 SKILL.md。
当用户提出的需求,比如“帮我测试一个本地 Web 页面”,当需求和 webapp-testing 的元数据匹配时,Agent 才会去读取这份文档。
在这个 Skill 里,SKILL.md 完整地描述了:
1、适用场景
Agent 会先判断任务面对的是静态 HTML 页面,还是动态 Web 应用。
如果是动态应用,再进一步判断服务器是否已经运行。
通过这一步,Agent 同时完成了两件事:
确认 Skill 是否适用,以及确定后续应该走哪条执行路径。

2、**实践与注意事项
在 webapp-testing 里,作者并没有让 Agent 自由发挥,而是明确给出了一套固定的执行顺序:先侦察页面状态,再识别元素,最后执行操作。
这一层,其实是在告诉 Agent,
哪种做事顺序更稳,
以及哪些地方最容易出错。

第三层,运行时资源(按需加载)
当任务真正进入执行阶段,
如果需要更具体、更稳定的能力,
Agent 才会按需调用脚本、示例或参考资料。
在 webapp-testing 中,一方面,通过 examples 里的示例,
Agent 可以参考“类似问题通常是怎么处理的”,快速对齐思路,少走弯路。

另一方面,对于更复杂、容易出错的操作,
还可以直接调用可执行脚本。
比如 scripts/with_server.py,
把启动服务、等待就绪、清理环境这些步骤,
用更确定的方式跑完。

所以,正是因为这种按需加载的机制,一个 Skill 才能同时打包大量说明和工具,却不会带来持续的上下文负担。
Skills 和 MCP 并不是一类东西。
MCP解决的是连接问题,
它决定 Agent 能访问哪些外部系统、数据源和工具。
Skills是定义在拿到这些工具之后,
应该如何规范、稳定地使用它们。
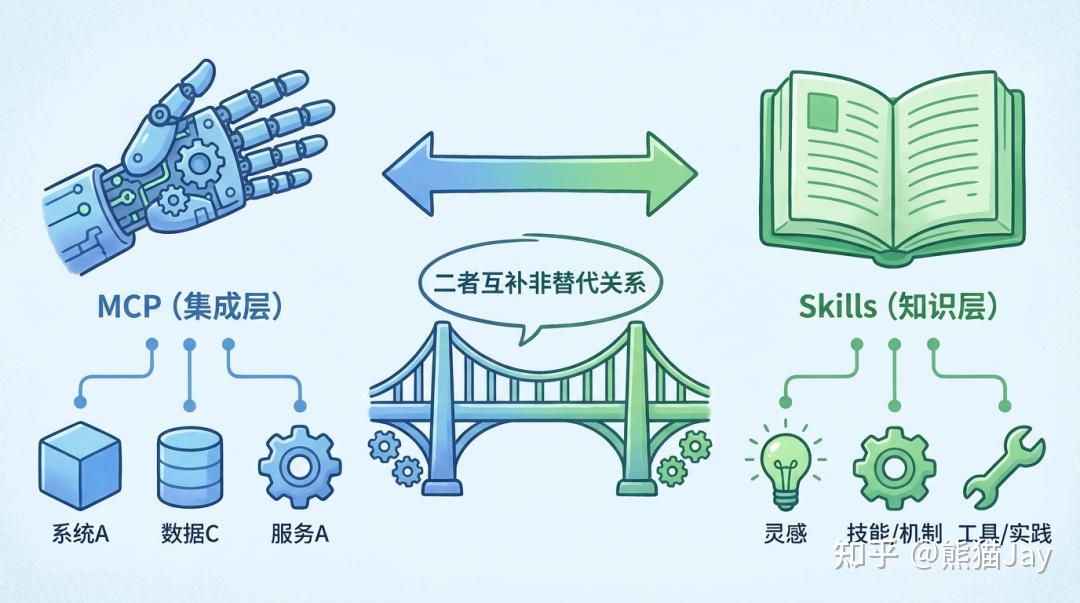
我们可以理解为:MCP 提供能力边界,Skills 约束能力使用方式。
下载 Skill 的方式一般分为两种:
手动下载、借助AI下载。
无论使用哪种方式下载,我们需要将 Skills 放对位置,否则 CC 无法成功加载。
| 平台 | 位置 |
| Claude Code | .claude/skills//SKILL.md |
| Codex | .codex/skills//SKILL.md |
| Cursor | .cursor/skills//SKILL.md |
| Antigravity | .agent/skills//SKILL.md |
1、手动下载
https://skillsmp.com/zh/search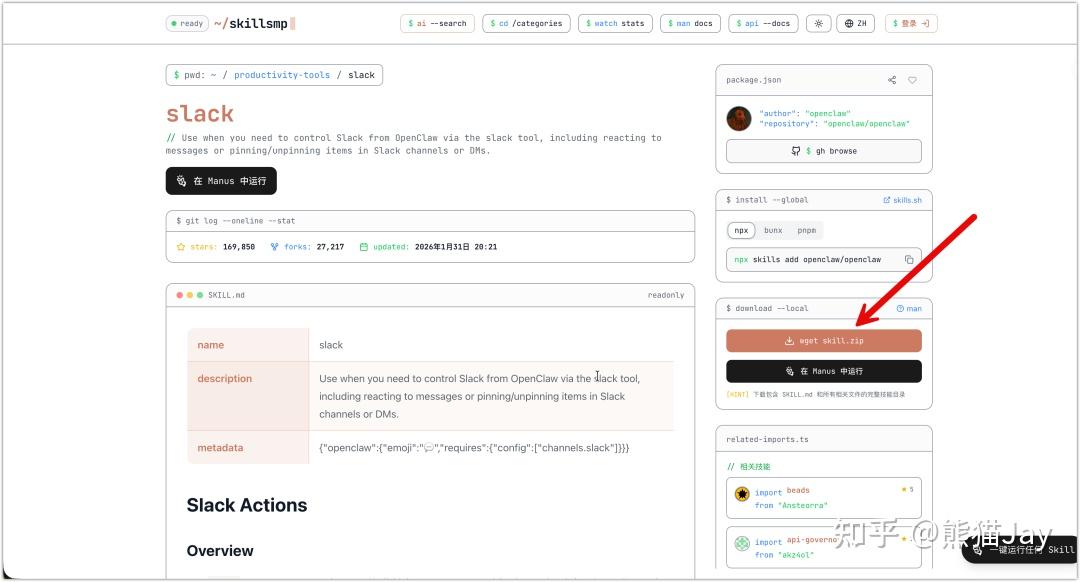
GPT plus 代充 只需 145https://github.com/anthropics/skills
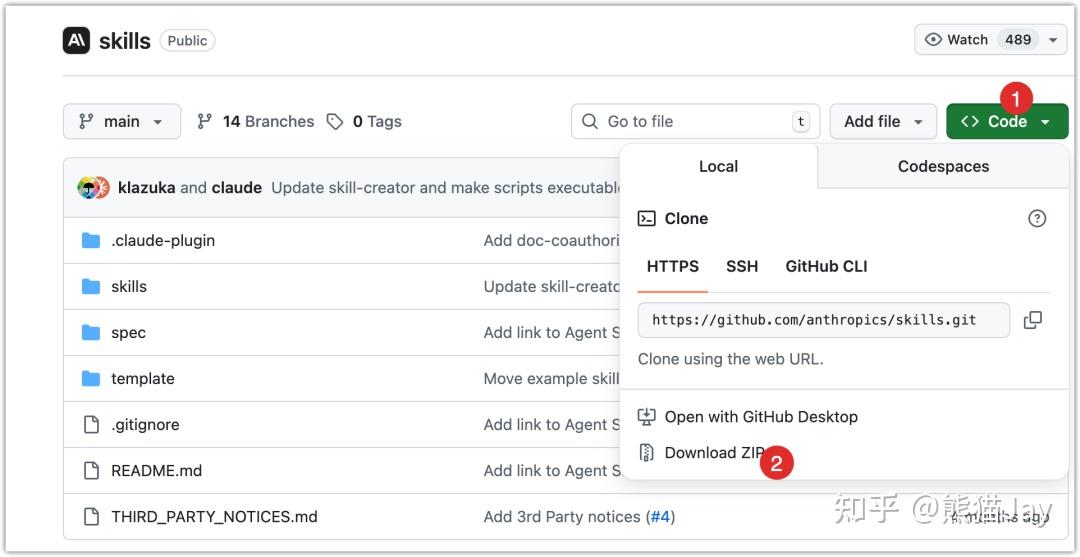
2、让 AI 自行下载
接下来,我们演示一下如何让 AI 下载 skill-creator,这是一个官方提供、用来帮助我们开发 Skill 的 Skill。
请帮我安装Skill,对应的项目地址为:https://github.com/anthropics/skills/tree/main/skills/skill-creator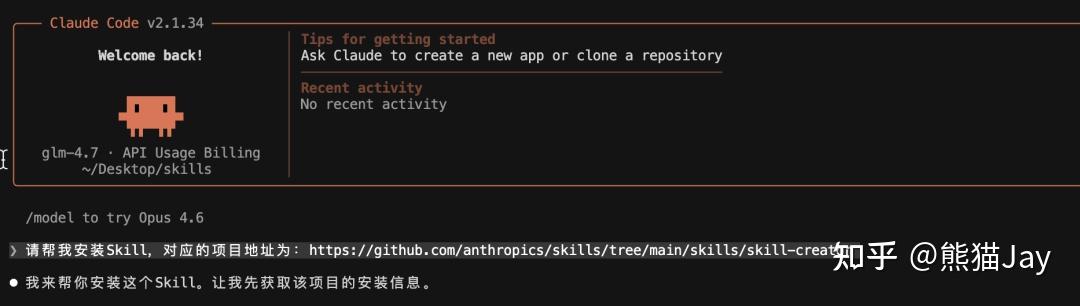
等待安装完成。
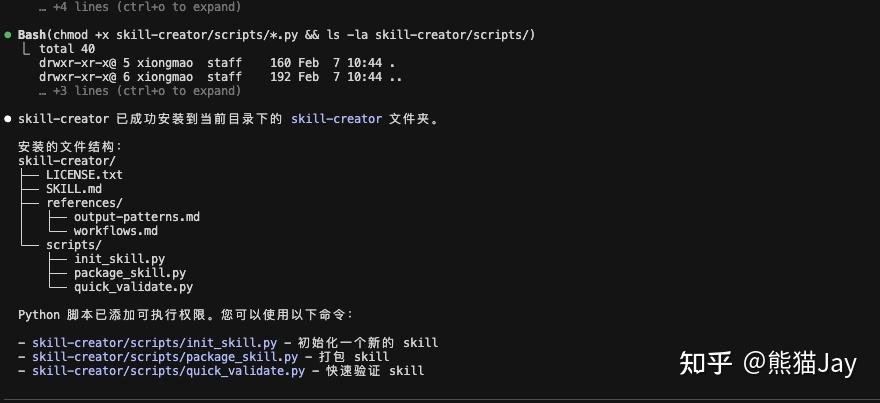
接下来我们利用 skill-creator 创建一个 skill,输入自己的需求:

输入需求后,CC 开始帮我创建 skill,最终包含一个压缩脚本。
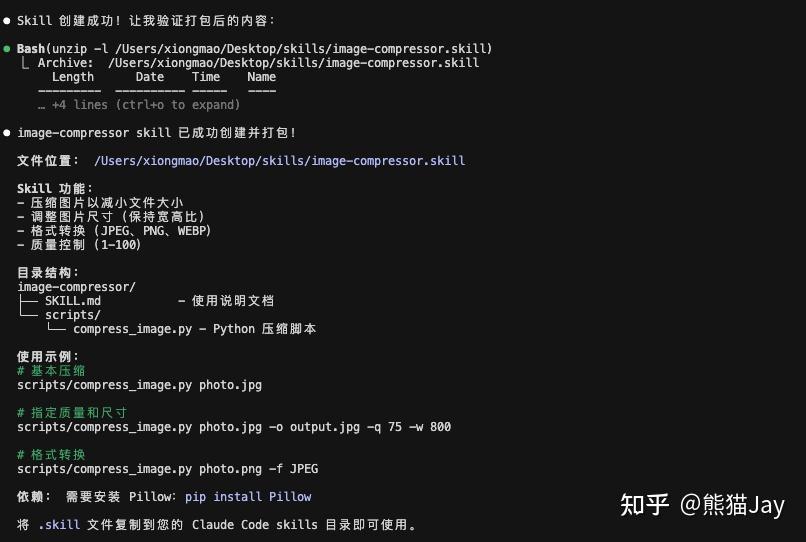
细心的朋友可以看到,这次脚本需要安装一个依赖包。
为了减少更多问题的出现,我建议直接让 CC 帮你完成安装。
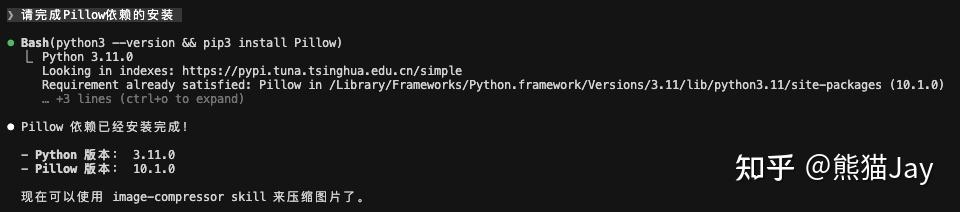
安装成功之后,该怎么使用呢?
除了AI 给出的命令示例,我们可以按照这样两种方式使用:
1、指明具体的 skill 名称
GPT plus 代充 只需 145请使用 image-compressor 压缩这张图片
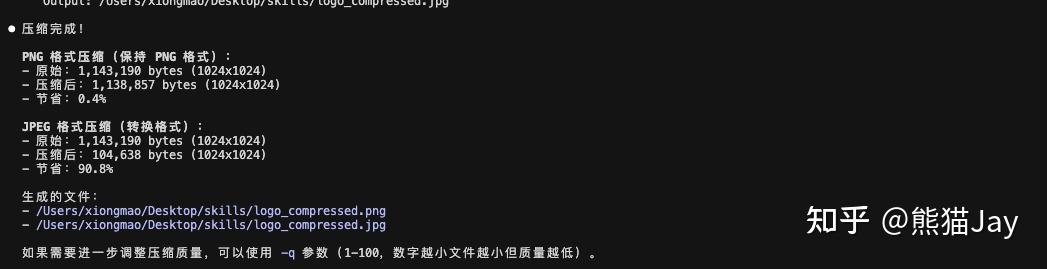
2、让 AI 自行分析和调用合适的 skill
请帮我压缩这张图片 当 AI 判断这次任务符合 image-compressor 的 Skill 定义时,
就会直接调用这个 Skill,
而不是自己再去写一套新的程序来完成任务。

写 Skill,第一步不是脚本,也不是流程。
而是元数据里的 名字和描述。
名称:推荐用「动词 + ing」的形式,直接描述行为。
正例:
GPT plus 代充 只需 1451. processing-pdfs2. writing-documentation
反例:
1. helper2. tools描述:定义做什么 + 什么时候用。
正例:
GPT plus 代充 只需 145从 PDF 文件中提取文本和表格、填充表单、合并文档。在处理 PDF 文件或用户提及 PDF、表单或文档提取时使用。
反例:
帮助处理文档以上案例摘自官方。
一个 Skill,尽量只做一件事,千万别贪多。
Skill 的职责越多,AI 越难判断什么时候该用它。
否则,最后的结果往往是:
- • 要么不用
- • 要么用错
比较好的判断方式是问自己一句话:
“这个 Skill,是不是一句话就能说清楚在干嘛?”
无论是案例、说明还是约束条件,
都不是越多越好,而是越精准越好。
官方建议:Skill.md 不要超过 500 行。
否则很有可能是:责任不清、信息堆叠。
测试下来,对 Skill 行为没有影响的内容,该删就删掉。
对于不同的任务类型,我们可以灵活设置不同的自由度。
偏开放的任务,比如:总结、改写、头脑风暴、方案生成。
这类任务本身没有唯一答案。
这种情况下,不用写太多限制条件。
给清楚目标和边界,让它自由发挥,
反而更能最大化模型的能力。
偏稳定的任务,比如:格式转换、数据处理。
对于这种追求确定性结果的任务,
我们需要明确步骤、写好脚本,
在合适的步骤上直接调用。
很多人一开始就犯一个错误:
一上来就写几百行的提示词,然后开始反复调。
这种方式很累。
更稳妥的方式,是先搭骨架。只写最基本的目标、输入和输出。
同一个 Skill,在不同模型下,表现会存在差异。所以不要指望一次写完。
持续验证、持续迭代,才是写好 Skill 的正确姿势。
这是最容易被忽略的一步。
很多 Skill 写完之后,没人知道:它算不算成功?
建议至少想清楚三件事:
- • 什么情况下,算是用对了这个 Skill
- • 什么输出,是可以接受的
- • 什么情况,算失败
哪怕只是几条简单的判断标准,也比没有强。
除了之前提到站点之外,这里也整理了一些优质的 Skills 资源:
| 名称 | 地址 | 备注 |
| Skills 集合 | 1、https://github.com/ComposioHQ/awesome-claude-Skills2、https://github.com/travisvn/awesome-claude-Skills3、https://github.com/libukai/awesome-agent-Skills4、https://skillsmp.com/zh/search | 包含大量互联网上开源的 Skills,但是质量参差不齐,需要自行测试和筛选。 |
| 官方 Skill 仓库 | https://github.com/anthropics/skills | 官方仓库,必备。比较优质的Skill,适合直接使用、学习、拆解。包含创作、文档处理、编程、协作沟通这些类目。 |
| Remotion Skill | https://github.com/remotion-dev/skills | 指导 AI 如何准确地使用 Remotion 框架来制作视频 |
| NotebookLM Skill | https://github.com/PleasePrompto/notebooklm-skill | 用来和 NotebookLM 交互,让 Claude 基于你上传的知识库回答。 |
| 文章一键发布到 X | https://github.com/wshuyi/x-article-publisher-skill | 将本地Markdown文章转换成X支持的格式,并且支持一键发布 |
| 去除文章AI味 | https://github.com/blader/humanizer/tree/main | 让AI 生成的内容改写得更自然、更像人类书写的风格 |
Skills 的意义,在于把具体的方法和相关资源封装起来,变成可以长期复用的能力。
同样地,
如何获取和构建好用的 Skills,
本身也值得被当成一项能力沉淀下来。
GPT plus 代充 只需 145我有一个需求:【一句话描述你想解决的问题】。 请你帮我在 GitHub 上找 3–5 个成熟、被大量使用的开源项目 来解决这个问题,并简单告诉我:
- 每个项目的 GitHub 链接
- 大致的 star 数
- 各自适合什么场景
- 它们之间最主要的差异 最后给我一个选择建议,告诉我哪个更稳、更值得长期使用。
再用 skill-creator 把它们封装成一个个 skill,然后,结合自己的使用习惯和场景做微调。
请使用 Skill-Creator 帮我将【输入最合适的开源项目地址】封装成一个 skill,用于解决 【你希望解决的问题】前几次使用,踩坑几乎是不可避免的。
但一旦把结构和边界理清楚,稳定下来,
这些 Skill 就会变成后面可以反复使用的长期能力积累。Cursor 更像是在加速传统的软件开发流程,让你写得更快。
但 Claude Code 给我的感觉不太一样。
当然,这两类工具不是非得二选一。
快速原型、日常编码,用 Cursor;
复杂设计、重构、深度调试,用 Claude Code。尼尔·波兹曼说过一句话:“当你改变工具时,你也在改变自己。”
工具会一直变,Cursor 也好,Claude Code 也罢,它们都只是手段。
真正重要的,是你用什么思维方式解决问题,交付结果。
愿我们,都能找到最适合自己的开发节奏。
我是 🐼 熊猫Jay,如果觉得文章有用,随手点个赞、转发、在看三连吧~ 谢谢你看我的文章~
原文地址如下:
https://mp.weixin..com/s/8iM16IfgKWvESx8ZaOg5Uw没想到又多出来了9个封神的Skills,包括动画制作,无限画布,版本管理,动态PPT,去AI味儿,新技能制作,Office全家桶,都是我实地测试过的
Claude Code就统一叫CC了
1. Vercel出的聚合站skills. sh
按安装量排名,可以看24小时内最火Skills是什么,收录后的Skills安起来很简单,在CC上运行,npx skills add 具体的项目名
2. 比方说昨天一发就火的Remotion
运行npx skills add remotion-dev/skills安装,这个Skill能免费做JS动画,还做3D的,比方说我可以做一个讲解如何安装CC的文字讲解视频,用在PPT上绝杀,我明天单独出一篇
3. 第三名是Pencil,可以理解为无限画布版Claude Code,兼容Figma,还自带了设计规范和示例风格,不算纯skills,我单开一篇《不想当设计师的程序员不是好产品经理》
4. 看到这里的话可能已经装了几十个Skills,需要管理Skills的Skills
@一支烟花做的skills-updater,能检查本地skill有没有更新,有的话自动装,但有些Skills我在本地用的时候会修改,自动更新会跟我本地改好的版本冲突。@小耳做的Skill Vision Control解决了这个问题,下载新版本时保留旧的,可以对比后再决定要哪个
5. 最近跑的还有@歸藏佬的动态PPT Skills,NanaBanana-PPT,能分析文档做PPT大纲,用 Banana2生图,用可灵做页面过渡动画,一键合成包含所有转场的ppt视频
6. 同样是做PPT,notebooklm-skill 有一个新用法,在网页端生成PPT的时候最多也就是20页,在CC用可以换个思路,先生成一个结构化的文档,明确每一页ppt讲什么
然后CC有学习品牌风格的Skills,Theme Factory ,原用法是将生成的内容做品牌化的,会去对齐配色和字体,这时候我会让它学我想要做的PPT风格,这样生成PPT的时候可以1次做15张,不停循环也能保持风格化,100页都可以做
7. 怎么把日常对话打包成Skills呢
上一篇的方式是brainstorming头脑风暴,把跟模型的上下文对话主动做成Skills。这一篇升级成全自动的Homunculus,比方我连续三四次做某个请求前都会先看API文档,它就会创建一个自动获取文档的新技能
8. 还有一个skill-from-masters会在我新建一个技能的时候,网络搜索领域专家的方法论,或者找高赞的GitHub项目转化为新技能
9. Document Suite
含金量高高的,让CC带格式带公式生成 Word/Excel/PPT/PDF
好用的Skills太多了,
提到的我都打包成文档了,
老规矩发【技能】就行,
我后面按场景当维度,
来说组合Skills的工作流!先回答问题:日常写代码我用Cursor,复杂重构用Claude Code,TRAE试了一阵后放弃了。不是TRAE不好,是我懒得换。
很多人把这三个放一起比,其实不太对。Cursor和TRAE是一类,都是IDE,写代码的时候在旁边给你补全、回答问题。Claude Code是另一类,它是个Agent,你给它任务它自己去干,干完了叫你。
这个区别决定了使用场景完全不同。
先说Cursor。
它的核心价值是Tab补全。写代码的时候,它会猜你下一步要写什么,按Tab就自动补上。一开始觉得没什么,用习惯了发现离不开。
但Tab补全有个技巧:上下文要给够。
比如你要写一个用户校验函数,光把光标放在空行上,它补出来的东西很generic。但如果你先写个注释:
GPT plus 代充 只需 145
// 校验用户名:4-20位,只能是字母数字下划线,不能以数字开头 function validateUsername(username) {写到这里按Tab,它补出来的代码基本就是对的。注释越详细,补全越准。
Composer是另一个常用功能。比如我要把项目里的axios请求都换成fetch,直接跟它说:
把src/api目录下所有用axios的地方改成fetch,保持原有的错误处理逻辑它会把涉及的文件都列出来,一个个改,你review一下确认就行。这种批量改动手动做要半天,它几分钟搞定。
但Composer有个坑:改动太多的时候会漏。超过5-6个文件就容易出问题,不是漏改就是改错。我的经验是复杂改动分批做,别一次塞太多。
TRAE我用了大概两周就换回Cursor了。
界面和Cursor几乎一样,功能也差不多。免费是真香,但有几个问题。
补全的”味道”不太对。怎么说呢,Cursor补出来的代码风格跟我习惯比较接近,TRAE的有时候会用一些我不太用的写法。比如我习惯用async/await,它偶尔会补成.then链。不是错,就是别扭。
还有就是响应速度,TRAE明显慢一点。Tab按下去要等个零点几秒,Cursor几乎感觉不到延迟。写代码的时候这个差距很明显,一卡一卡的很影响心流。
可能是服务器在国内的原因?不确定。总之如果你对延迟敏感,建议两个都试试再决定。
Claude Code是完全不同的东西。
它不是IDE插件,是个命令行工具。装好之后在终端里跑,给它下任务,它自己读代码、改代码、跑命令。
听起来很美好,实际用起来有点像养了个不太听话的实习生。
有一次我让它”把这个函数的返回值从数组改成对象”,它改完我一看,好家伙,顺手把调用这个函数的十几个地方也”优化”了一遍。虽然逻辑没错,但跟我原来的风格完全不一样。测试倒是过了,code review的时候同事问我是不是换人了。
所以用Claude Code有个原则:任务要具体,边界要清晰。
别说”优化一下这个模块”,要说”把src/utils/date.js里的formatDate函数改成支持时区参数,其他文件不要动”。越具体它越不容易跑飞。
但它真正厉害的地方是复杂推理。
比如我有个老项目,几万行代码,想加TypeScript。让Cursor做这个事,它只能一个文件一个文件加,而且类型推断经常错。
Claude Code不一样。我跟它说”分析这个项目的数据流,给主要的函数加上TypeScript类型定义”,它会先花几分钟读代码,理解模块之间的关系,然后给出一个整体的类型方案。虽然还是要人工review,但起码方向是对的。
还有就是批量操作。”把项目里所有console.log删掉,但保留console.error”这种任务,Cursor要一个个文件点,Claude Code一句话搞定。
缺点是贵。按token算钱,复杂任务跑一次可能要几块钱。让它反复尝试的话,一天下来几十块不是问题。
说个实际的工作流。
平时写代码90%的时间在Cursor里。新功能开发、bug修复、小范围重构,Tab补全加Composer基本够用。
遇到大活的时候上Claude Code。比如:
- 老项目技术栈升级
- 生成测试用例(它能根据代码逻辑自己想edge case)
- 分析不熟悉的代码库(让它画调用关系图)
- 批量格式化或重构
两个配合用,效率比单用一个高很多。
几个用好这些工具的心得:
写好prompt是核心技能。同样的功能,prompt写得好能省一半时间。多给上下文,说清楚约束条件,指定代码风格。这些工具不是魔法,你给的信息越多,它出来的东西越靠谱。
别无脑接受生成的代码。Tab补全的时候多看一眼再按,Composer改完一定要diff看一遍。我见过有人AI写的代码直接提交,结果埋了个隐藏bug,线上炸了才发现。
该用的时候用,不该用的时候关掉。有些复杂逻辑,自己想清楚再写比让AI猜效率高。核心算法、安全相关的代码,最好还是手写。
对了,我有几台开发机在不同地方。之前远程开发的时候,Cursor的补全延迟很高,Tab下去要等一两秒,根本没法用。后来用星空组网把机器串到一个虚拟局域网,延迟降到二三十毫秒,体验跟本地差不多了。远程开发的可以试试这个思路。
回到问题,谁最强?
这三个工具解决的问题不一样,放一起比”最强”没意义。
Cursor和TRAE解决的是”写代码的时候有个助手”,Claude Code解决的是”有个能跑腿的实习生”。
如果只能选一个,选Cursor,覆盖面最广。有余力的话Cursor+Claude Code组合用,效率提升很明显。TRAE免费是优势,预算紧的可以先从TRAE开始。
工具而已,用顺手就行。
有问题评论区聊。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/215106.html