
从GPT-1到GPT-4,每一个版本经历了显著的演进,每个版本都为自然语言处理(NLP)领域带来了新的可能性和技术突破。以下是这些模型的简单回顾和比较。
| 模型 | 年份 | 关键创新 | 训练集 | 参数数量 | 上下文窗口 |
| GPT-1 | 2018 | Transformer 解码器, 自监督训练 + 微调 | 4.5 GB | 117M | 512 |
| GPT-2 | 2019 | 修改的归一化层, | 40 GB | 1.5B | 1,024 |
| GPT-3 | 2020 | 稀疏注意力层,支持零样本 | 57 TB | 175B | 2,048 令牌 |
| GPT-4 | 2023 | 多模态输入(文本 + 图像) | ? | 1.76T | 32,000 令牌 |
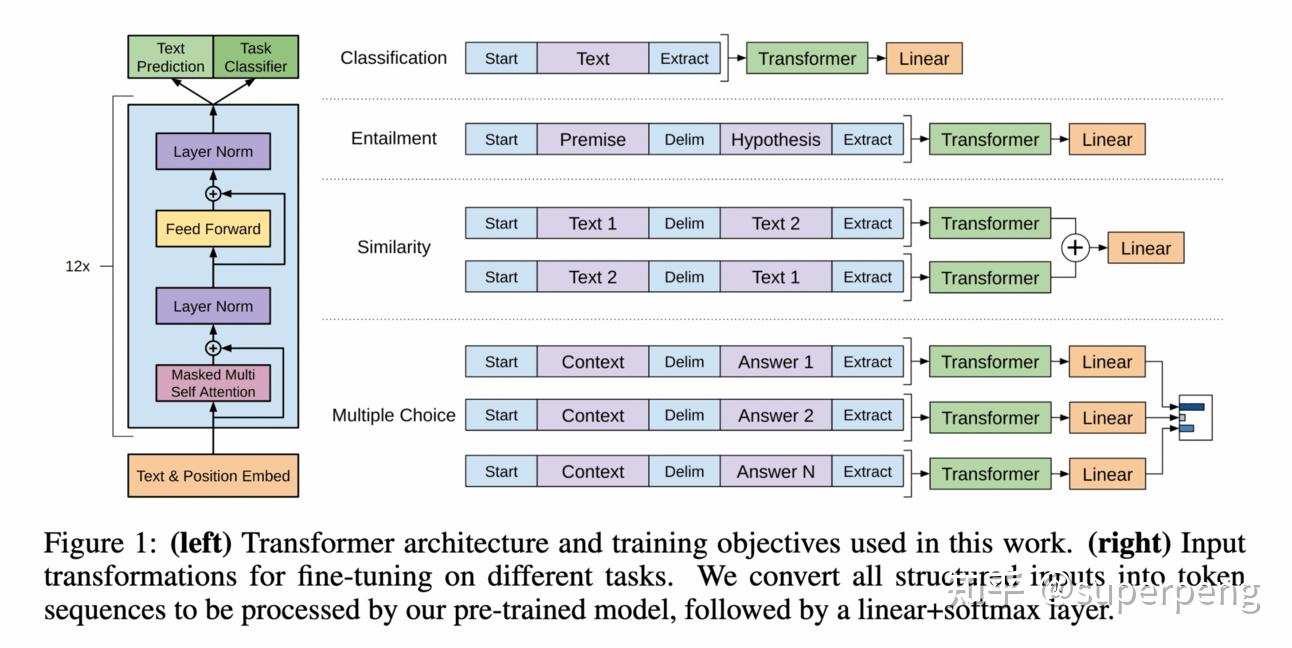
GPT-1是OpenAI在2018年推出的,GPT-1是一个重要的里程碑,因为它采用了一种生成式、仅解码器的Transformer架构。这种架构的选择使得模型能够创造性和连贯地生成文本。
为了训练GPT-1,采用了一种混合方法。他们首先以无监督的方式预训练模型,让它接触大量的原始文本数据。这个预训练阶段使模型能够理解自然语言中存在的统计模式和结构。接下来,模型经历了一个监督微调阶段,其中它在具有标签数据的特定任务上得到了进一步的改进。这个两步过程使GPT-1能够充分利用自监督学习的力量和人类标签数据的指导。GPT-1具备生成连贯、语法正确的句子的能力,对语言翻译和文本摘要等任务具有一定的应用价值。
微调是指将预训练的机器学习模型应用于特定任务或数据集以提高其性能的过程。
2019年,Google研究人员推出的BERT在NLP领域引起了一场范式转变。BERT的影响深远,因为它结合了多种创新的想法,将NLP的性能推向了新的高度。
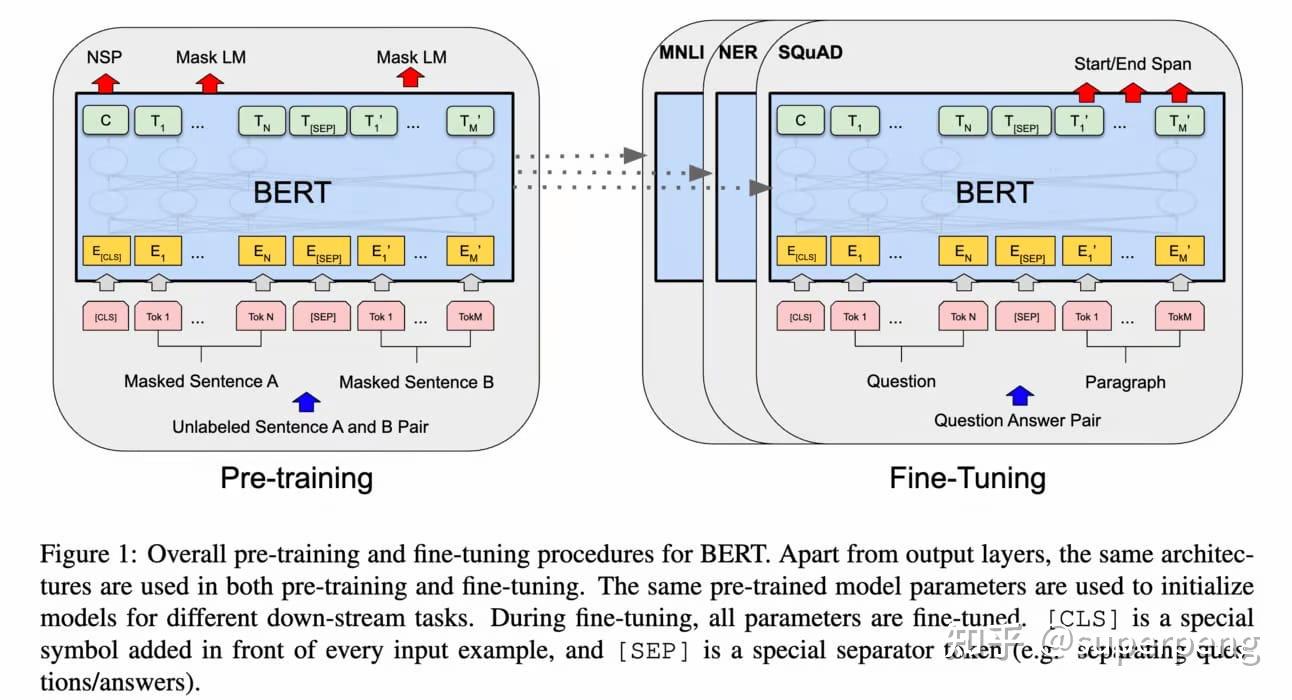
BERT的关键进步之一是它的双向性质,它在做出预测时可以考虑输入和输出上下文。这种双向方法显著提高了模型理解单词之间关系和捕获语言细微差别的能力。它的全面考虑上下文提高了BERT在各种NLP任务上的性能。
BERT更为出色的是它在多样化的非结构化数据上的预训练。这个预训练阶段使模型具备了全面理解单词关系的能力,使其能够捕捉语言使用的细微差别。通过从大量未标记的数据中学习,BERT学习到了关于自然语言中的统计模式和语义关系。
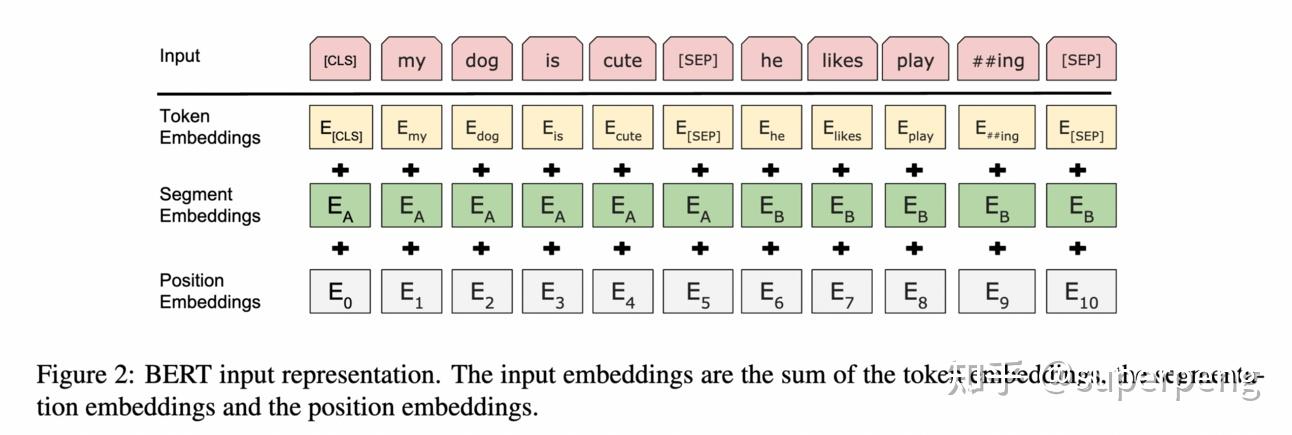
BERT模型的开源也使得在研究者和工业界中欢迎方面发挥了关键作用。预训练模型可以通过添加一个输出层轻松地进行特定任务的微调。这种微调的简单性和效果使BERT成为了NLP应用的首选。它使学术界和工业界的相关人员能够在广泛的任务范围内实现最先进的结果,进一步推动了该领域的进步。
研究人员使用了Transformer模型的变体,在多样化的互联网文本语料库上训练GPT-2。该模型生成的连贯和上下文相关的句子的能力确实非常出色。其输出往往让人们质疑是由人类还是模型本身创作的。GPT-2的多功能性确实令人震惊,它可以毫不费力地处理包括写作、回答问题、语言翻译甚至诗歌创作在内的广泛任务,GPT-2能生成更长、更复杂的句子,对于语言翻译和文本摘要等任务表现得更好,相比GPT-1,它训练了更大的数据集,从而能更好地理解人类语言的细微差别
2020年,OpenAI推出了GPT-3,,它训练了超过45TB的文本数据,能生成非常类似人类的文本,它以惊人的1750亿参数超越了其前任GPT-2,成为这个系列的八个模型中最大的模型。GPT-3不仅能生成连贯的段落,而且能生成整篇与上下文相关、风格一致的文章,这些文章通常与人类编写的内容无法区分。GPT-3具有零样本学习的能力,即使在没有经过特定训练的情况下,也能执行特定任务,它的出现使得AI语言模型的应用得到了广泛的推广。
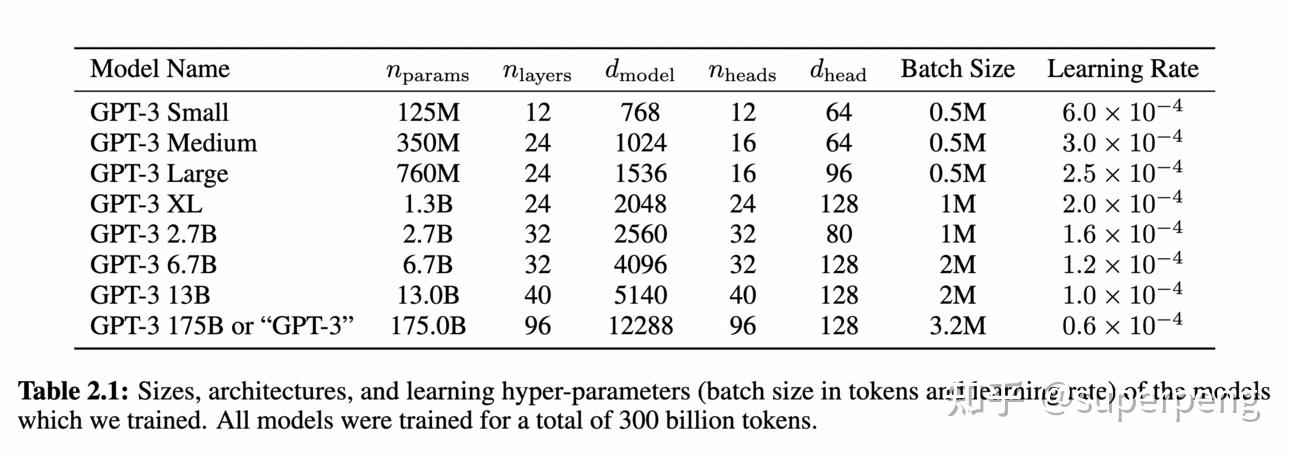
GPT-3开创了使用LLMs进行少样本学习的概念,而无需大量特定任务的数据或参数更新。随着模型规模的增加,随后的LLMs如GLaM、LaMDA、T5、Gopher和Megatron-Turing NLG进一步推动了少样本学习,实现了各种任务上的最先进性能。
- InstructGPT和GPT-3.5在2022年初推出,它们都是基于GPT-3的,但是有所不同。InstructGPT是为了执行特定指令而设计的,而GPT-3.5则是一个在人类价值观方面与人类更为一致的模型。
2022年3月,OpenAI发布了InstructGPT模型和一篇名为“Training language models to follow instructions with human feedback”的论文,当时并没有引起太多关注。这个模型不仅仅是GPT-3语言能力的延伸;它通过赋予它遵循指令的能力,从根本上改变了架构。本质上说,InstructGPT将GPT-3的语言能力与新的任务焦点遵从性相结合,为未来的语言模型开发设定了新的标准。为了更好地理解书面指令,另一种革命性技术,即来自人类反馈的强化学习(RLHF)被用来微调GPT-3!
2022年11月,OpenAI推出了ChatGPT。
ChatGPT是基于GPT系列(GPT-3.5和GPT-4)的对话模型,其训练方法类似于它的InstructGPT,但特别侧重于优化对话。与InstructGPT不同,ChatGPT的训练数据包括人类生成的对话,其中用户和AI角色都得以展现。这些对话与InstructGPT数据集中的指令相结合,形成了训练ChatGPT的庞大数据集。
ChatGPT推出后也遭遇了一些批评,因为它的输出有时会成为虚假或误导性的信息的来源。尽管如此,它仍然被公认为一个强大的语言模型,可用于各种各样的任务,尤其是那些需要理解和解释文本的任务。
2023年openai推出了GPT4,GPT-4是在GPT-3.5基础上进一步发展的,它能处理更长的提示和对话,也不会像GPT-3.5那样产生许多事实错误,但是GPT-3.5在生成响应方面更快。GPT-4在多模态功能上也有显著的进步,能够处理图像和文本的组合,打开了NLP应用的新可能性。
谢邀~
这是个好问题,但是要详论GPT的发展,个人感觉还是要读OpenAI的论文。毕竟是一群精英算法工程师们花费很大精力写出来的技术文章。
但是OpenAI的论文动辄大几十页,读起来确实很费劲。
为此我整理出了论文中的核心内容,并做了相关的笔记。对GPT感兴趣的可以看我整理的论文笔记。
GPT-1是一种半监督的语言模型,它巧妙地结合了无监督预训练和有监督微调,以优化语言理解任务。其目标是学习一种通用的语言表示,只需微调,就能在各种任务中灵活迁移。GPT-1首先利用大量未标注文本进行预训练,然后针对特定任务进行有监督的微调。它采用了Transformer作为模型架构,这种架构提供了更加结构化的记忆,以便处理文本中的长期依赖关系,从而实现了卓越的迁移性能。在迁移训练过程中,GPT1能够在最小化模型结构更改的同时,有效地进行微调。
更多细节见如下链接:
我有魔法:一文读懂GPT-1:生成式预训练如何提升语言理解GPT-2是自然语言处理领域的重要里程碑作品,采用了Transformer模型,展现出强大的语言生成能力。作为OpenAI开发的杰出之作,GPT-2令人惊叹。它的模型规模达到了15亿,并通过在大规模语料库WebText 上进行自监督学习进行了训练。
GPT-2的设计思想是通过大量网络文本数据的学习,以无监督的方式掌握语言的模式和结构。在没有具体任务指导的情况下,GPT-2能够生成与人类书写风格相似且连贯的文本,并回答输入文本中提出的问题。
更多细节见如下链接:
我有魔法:GPT-2:基于无监督多任务学习的语言模型GPT-3是一个拥有1750亿模型参数的自回归语言模型。与GPT-2相比,GPT-3的参数量翻了116倍。与此同时,GPT-3采用了GPT-1最初提出的Few-shot设置,即模型在处理子任务时不再依赖大量样例,而是在可控范围内给出一些样本。这种设置的成本非常低,但却能为模型提供足够的信息。最令人惊叹的是,GPT-3在任何任务上都无需任何梯度更新或微调,只需通过与模型的文本交互来指定任务和展示少量样本。
GPT-3在多个自然语言处理任务中展现出了惊艳的性能,如翻译、问答和填空,同时还能够应对那些需要即时推理或领域适应的挑战,如拼写校正、引入新词和进行三位数算术运算。OpenAI 的科研人员发现,增加语言模型的规模可以极大地提升任务无关的少样本学习性能,有时甚至能够与当前最领先的微调方法媲美,这一突破在当时引发了极大的关注和赞誉。
更多细节见如下链接:
我有魔法:GPT-3解读:惊艳世界的模型原来是暴力出奇迹ChatGPT采用了与InstructGPT相同的方法,只是在数据集在些许差异。如下所示是ChatGPT在OpenAI官网上的介绍:
• ChatGPT is a sibling model to InstructGPT, which is trained to follow an instruction in a prompt and provide a detailed response.
• We trained this model using Reinforcement Learning from Human Feedback (RLHF), using the same methods as InstructGPT, but with slight differences in the data collection setup.
语言模型的规模增大并不能保证其更好地遵循用户的意图。较大规模的语言模型可能会产生不真实、有害或对用户毫无用处的输出,与用户意图背道而驰。
为了解决这一问题,研究人员通过使用人类反馈,使语言模型在各种任务中能够与用户意图保持一致。首先,通过收集标注员编写或OpenAI API提交的prompts来微调GPT-3以满足所需行为。接着,利用人类对模型输出进行排序的数据集,采用强化学习进行进一步微调,最终形成了InstructGPT模型。
人类评估结果显示,相较于具有1750亿参数的GPT-3模型,InstructGPT模型在参数量减少100倍的情况下,其输出也更受欢迎。此外,InstructGPT在生成真实性方面有所提高,并减少了生成有害输出的情况。
由于ChatGPT的技术原理与InstructGPT一模一样,所以借由InstructGPT的技术可对ChatGPT的技术有清晰的认知。
更多细节如下链接所示:
我有魔法:InstructGPT论文精读:大模型调教之道(ChatGPT学习必读)关于GPT4,虽然OpenAI发布了技术报告,但在报告中并未阐述任何模型、相关的信息,此间猜测众多,众说纷纭,在此暂不做赘述。
如果你也对AIGC感兴趣的话,欢迎关注我们的微信公众号“我有魔法WYMF”,我们会定期更新AIGC热门资讯和经典论文精读分享,欢迎大家一起交流~~
甚至可以不负责任的认为,OpenAI的GPT系列,本质上是:
在15年“ Semi-supervised Sequence Learning”的基础上,
采用Transformer结构
进行的“大规模”(模型参数x数据量x算力)的工作
从NLP的范式:
- 过去:每个Downstream Task都有自己的 数据-样本-训练-推理 的流程;Task间迁移成本贼高,比较隔离
- 未来:(2018当时的未来,其实就是现在),首先预训练一个“big”模型,然后小成本地在诸多下游任务间使用,只需“微调”甚至“zero-shot”
所以,GPT系列的核心思路,就是围绕于此,不断探索“PreTrain + FineTune”的核心范式
GPT-1,奠定了 “模型框架+训练框架”
模型结构采用Transformer+DecoderOnly、训练范式采用两阶段范式
GPT-2,在上述框架下,继续探索:
- 不强制依赖 downstream task-specific,仅通过预训练行不行?
- “大”是重要的:大的模型容量 x 大的数据量 x 大的训练算法
GPT-3,探索的是 零少样本学习的 极致境界:“ICL/情境学习”
- 继续做“大”,数据量已经到了TB级,模型参数到了175B
- 接1,模型具有了ICL Instruction的能力,通过少量“demonstration/示例”就可完成任务
由此,我们回顾,面对诸多NLP downstream tasks时,GPT-3最终完成了“NLP新范式”这个命题,交出了完美的答卷:
1、预训练一个超大模型,预料够大X模型够大X算力充足;而且别怕,不需人工标注,全是非监督训练的。
2、基于该大模型,直接用Prompt即可完成下游NLP task;如果response不对,那就结合该task的少量示例,在Prompt ICL里提示它,就会答得对。
这是一个极其美妙的场景。
5篇论文简记,请见:
AI采英:大模型·OpenAI(1):GPT-1/2/3,GPT时代来临
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/214916.html