
OpenAI 于 2025 年 4 月 14 日发布了 GPT-4.1 模型系列,这是继 GPT-4o 之后的一个重要升级,专注于提升开发者在编码和指令跟随任务中的效率。该系列包括 GPT-4.1、GPT-4.1 mini 和 GPT-4.1 nano 三个变体。
ChatGPT4.1重磅发布,无限免费白嫖攻略
大家好,我是李想。
就在昨晚,大洋彼岸的OpenAI发布了GPT最新的4.1模型。
ChatGPT作为这一轮科技革命的爆发的开创者,扮演着举足轻重的角色,他的更新自然会引发AI科技圈的震动,只是前几次都是雷声大,雨点小,让人们对于OpenAI不是那么的期待了,当然,作为第一个让我体验到AI的奇妙的公司。我也希望OpenAI能开发出更强大的模型。
今天先给大家简单介绍下GPT这次新推出的模型,然后给大家说下免费体验GPT4.1的方法。
这次更新发布了三个模型:
GPT-4.1:高性能旗舰模型,GPT-4.1 mini:更快的模型,GPT-4.1 nano:最小、最快、最便宜的模型,以API形式提供给想使用的用户。
GPT-4.1系列的模型系性能全面超越了 GPT-4o 和 GPT-4o mini;
- 编程能力大幅提升
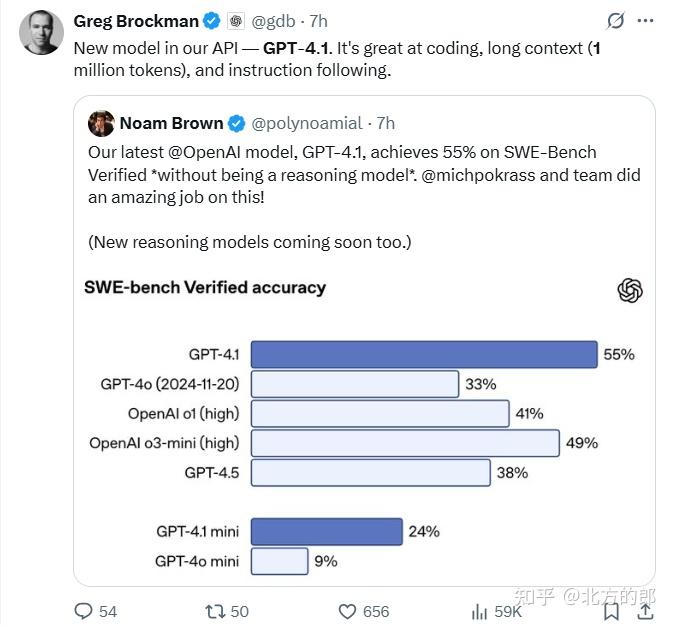
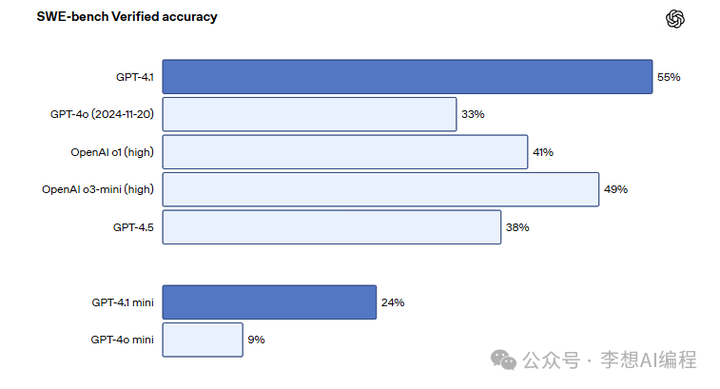
GPT-4.1 在 SWE-bench 编程基准测试中得分为 54.6%,比 GPT-4o 提高了 21.4%,比 GPT-4.5 提高了 26.6%。这使得 GPT-4.1 成为当前领先的编程模型。
- 超长上下文处理,更低的价格
新模型支持最多 100 万个 token 的上下文窗口,远超 GPT-4o 的 128,000 token。这意味着它可以更好地理解和处理长文本内容。
- 更强的指令理解能力
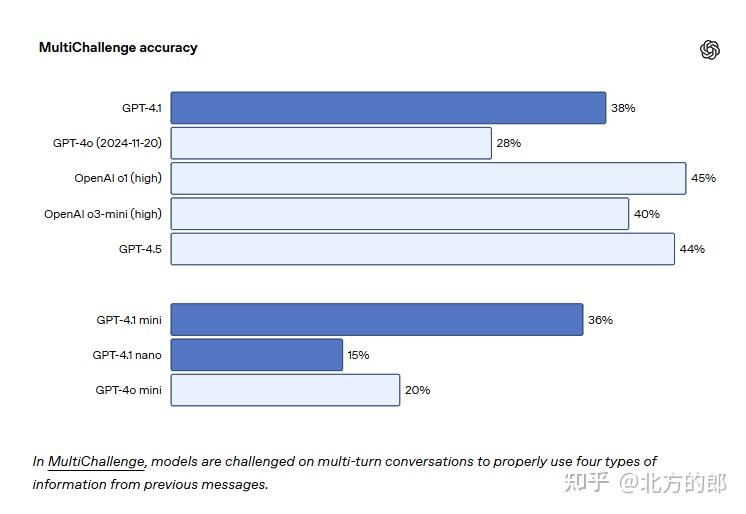
在 Scale 的 MultiChallenge 基准测试中,GPT-4.1 的得分为 38.3%,比 GPT-4o 提高了 10.5%。这使得模型在执行复杂指令时更加准确和高效。

总的来说,GPT4.1的能力全面超过了4o模型,并且价格更低了。
大家猜一猜我们如何免费体验GPT4.1,答案是:
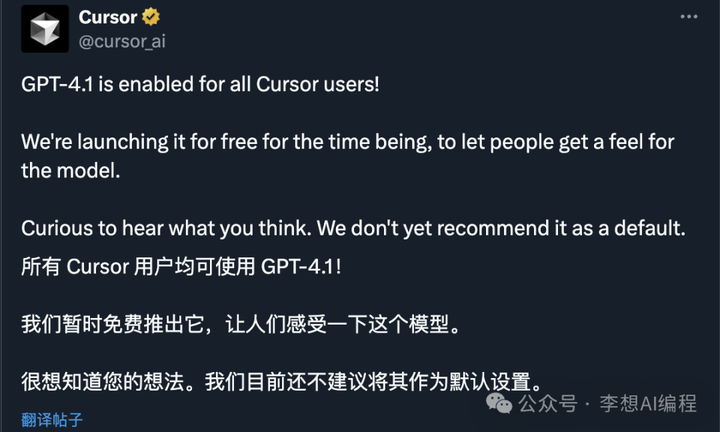
嘿嘿,想不到吧,我们可以在AI编程神器Cursor上免费体验!还不知道Cursor的朋友可以看下这篇文章:AI编程神器Cursor入门,看这一篇就够了!
使用方法:打开我们的Cursor,点击右上角设置按钮。
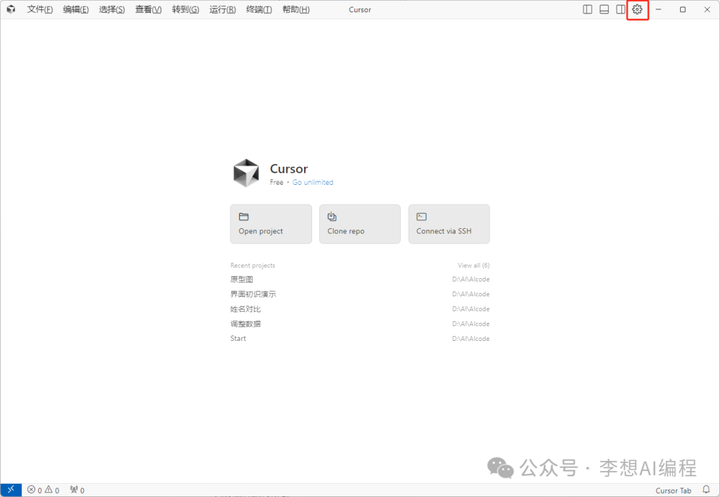
在设置页面点击Model,找到GPT4.1,勾选上
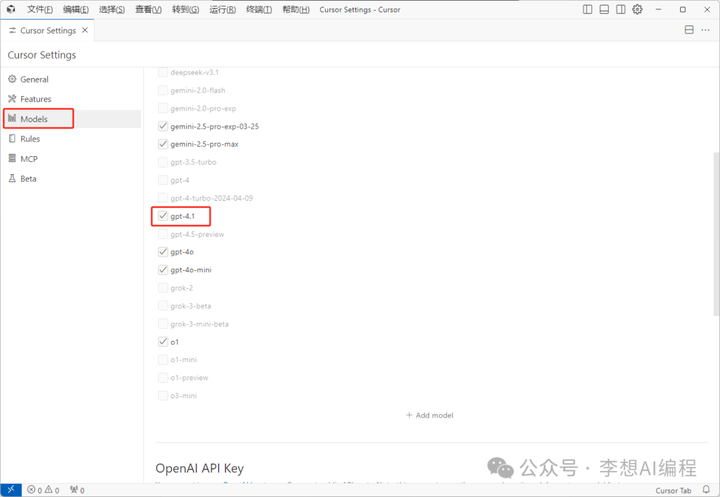
在AI对话这里就可以选择GPT4.1模型了
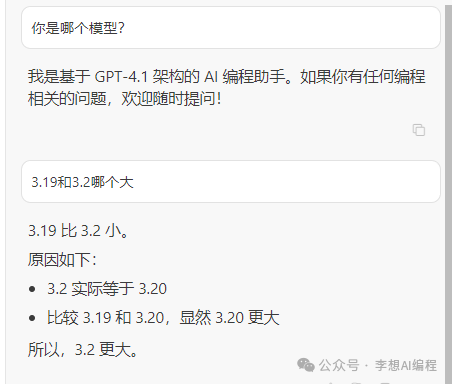
我们来问下它是哪个模型,随带问一问以前很火的问题3.19和3.2谁大的问题
嗯,没毛病,既然他都说了GPT4.1在编码方面能力大幅提升,我就试一试他的代码能力。
选择Agent模式,选择GPT4.1模型
输入我们的提示词:
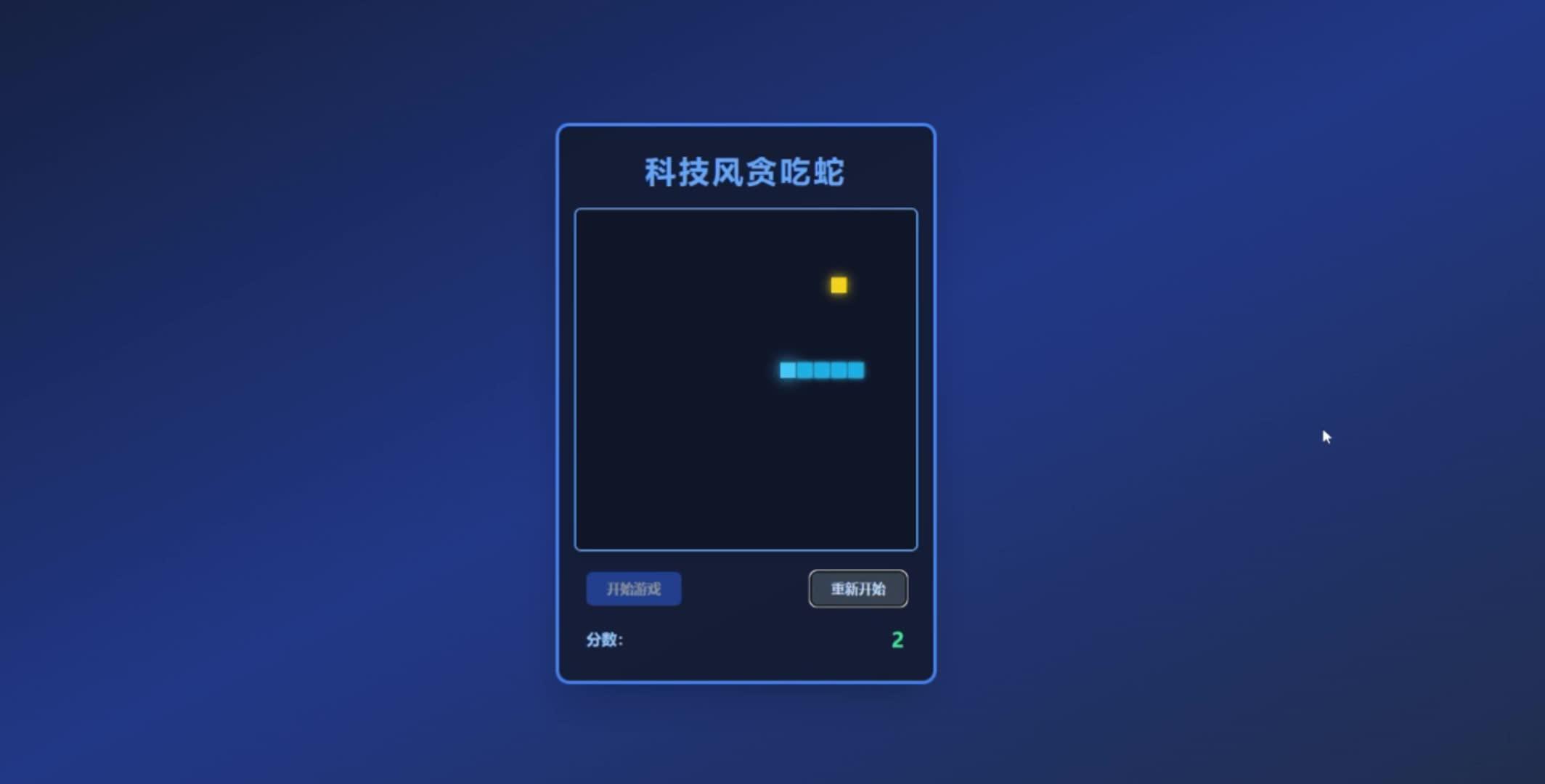
帮我生成一个科技风的贪吃蛇游戏
1.利用Html+js生成单页面游戏,
2.css使用tailwind,样式要优美,具有科技风格
3.有开始游戏、重新开始游戏功能
4.有积分版
5.使用浏览器自带音效,移动、得分、失败都要配上音效
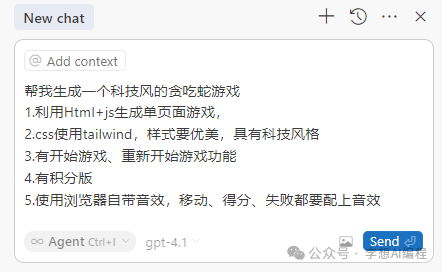
十秒钟就生成了对应的文件
我们把Html文件运行到浏览器看一看。
 https://www.zhihu.com/video/
https://www.zhihu.com/video/ 3.结语
OpenAI 计划在 7 月前逐步淘汰 GPT-4.5 预览版,全面转向性能更优、成本更低的 GPT-4.1 系列。此外,他们还计划在夏季发布开放权重模型,以支持开发者的定制化需求
其实我感觉到ChatGPT拥有的底牌应该不多了,现在打个模型百花齐放,在通往AGI的道路上到底谁会率先取得突破?是我们国产的DeepSeek?还是OpenAI,还是Googel的gemmni,还是阿里?
让我们拭目以待吧!
文中用到的所有AI工具我都放到了我手把手整理的AI工具箱,包含AI工具库、副业项目和全网最全的120份副业运营SOP,大家有些需要可以看看,纯干货!超全AI入门级资料和AI工具库资料分享!!!
都看到这了就给博主点个赞再走吧,你的点赞、关注是我持续创作的动力,我是李想,我的理想是带领10w小白入门AI,利用AI找到人生的第二曲线,更多作品移步 @李想AI编程 主页,目前聚焦于分享最新的AI工具和AI副业。
GPT-4.1 是 OpenAI 2025 年 4 月 14 日推出的,主要面向开发者,通过 API 用,不能直接在 ChatGPT 里玩。
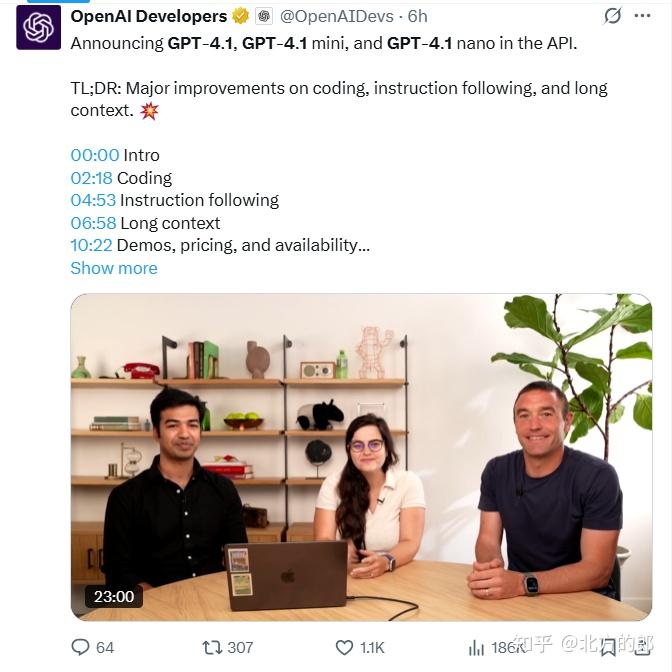
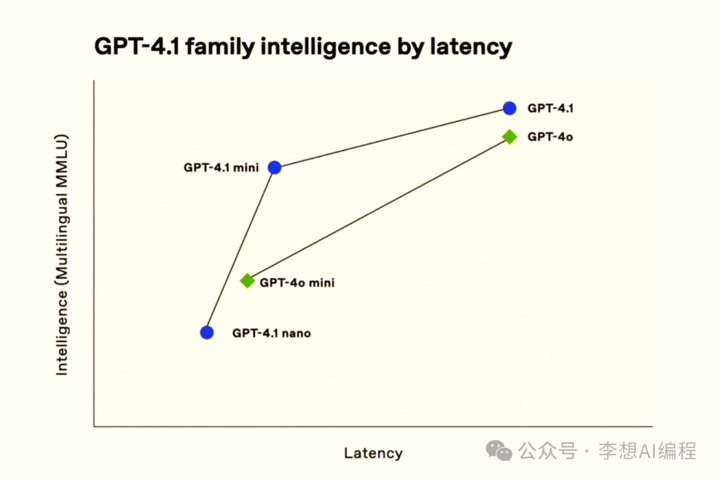
OpenAI 这次的目标很明确,就是想让它变成一个能干复杂编码活儿的“软件工程师助手”。简单说,就是帮程序员写代码,尤其是那种需要想好几步或者处理长文的场景。它最大的亮点是能一次处理 100 万个 token 的超长文本,这意味着你可以扔一大堆东西给它,它也能慢慢消化。另外,它还能搞定图片、声音和文字混搭的任务,用起来更灵活。
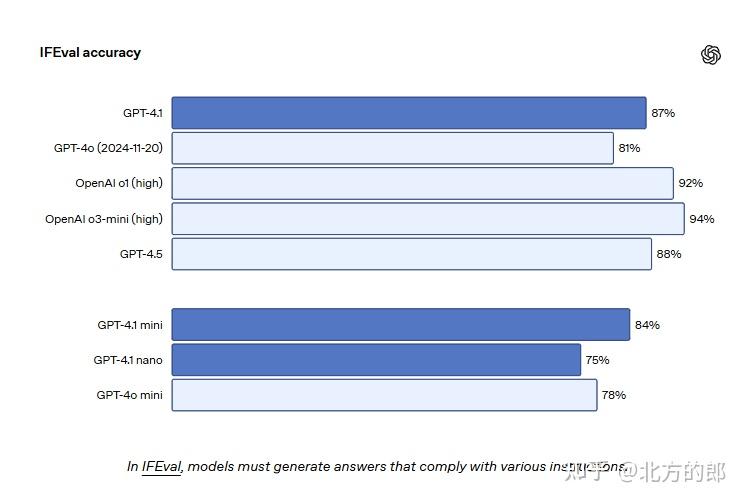
性能上,GPT-4.1 确实有进步。除了运行速度快之外。在 SWE-bench Verified 的编码测试里,它拿了 54.6% 的分数,比之前的 GPT-4o 高了 21.4%,这说明它写代码的本事确实强了不少。还有,它听话的能力也提升了,在 MultiChallenge 测试里得了 38.3%,IFEval 测试里得了 87.4%,都比老模型好。具体如下:
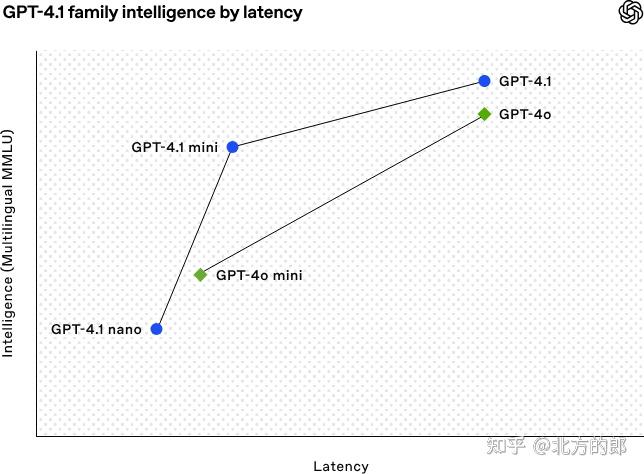
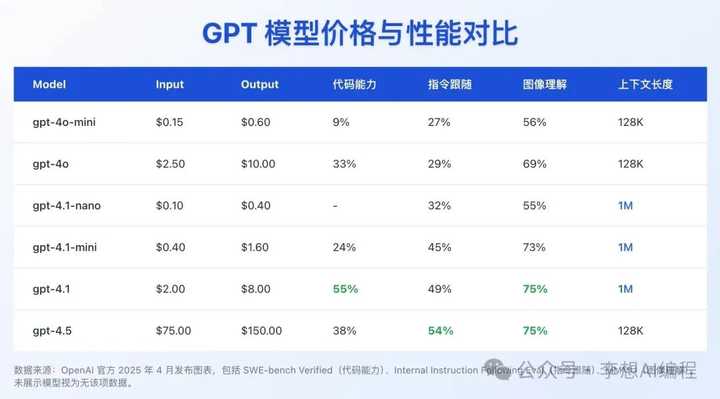
编码能力:在 SWE-bench Verified 测试中得分 54.6%,相较于 GPT-4o 提高了 21.4% 绝对值 。
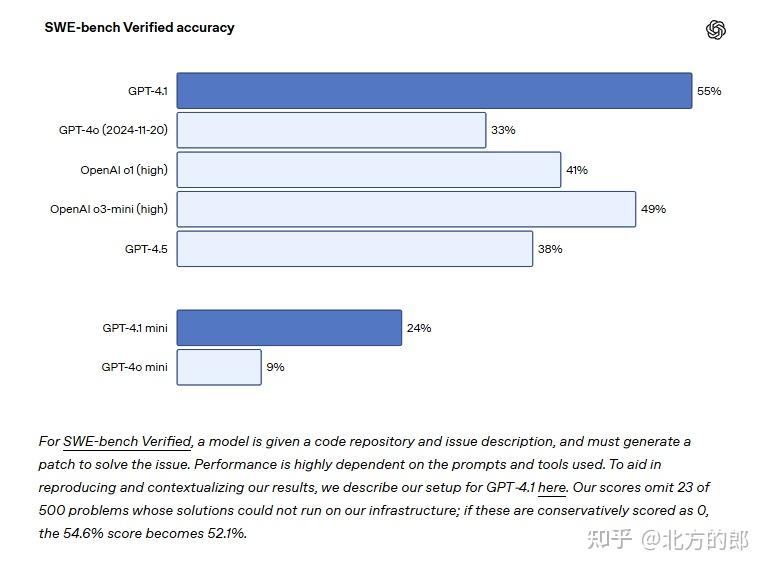
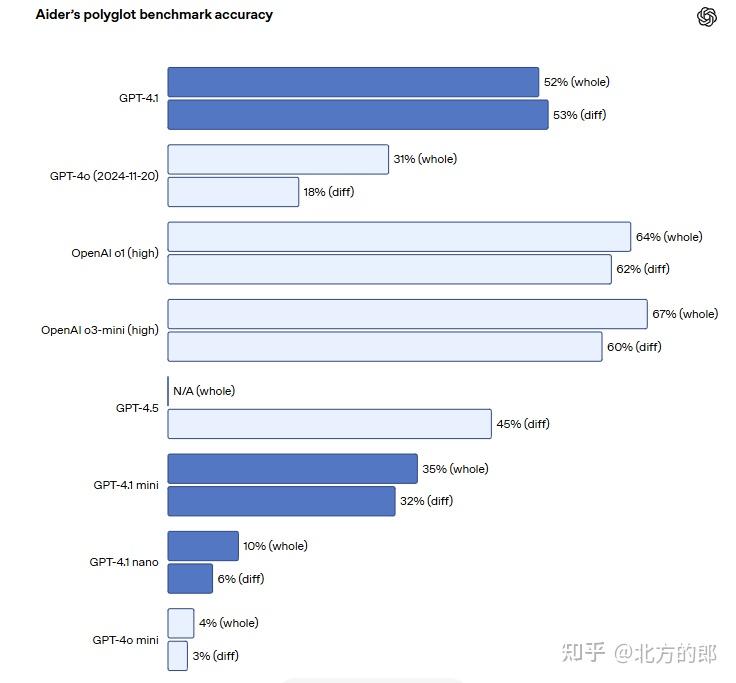
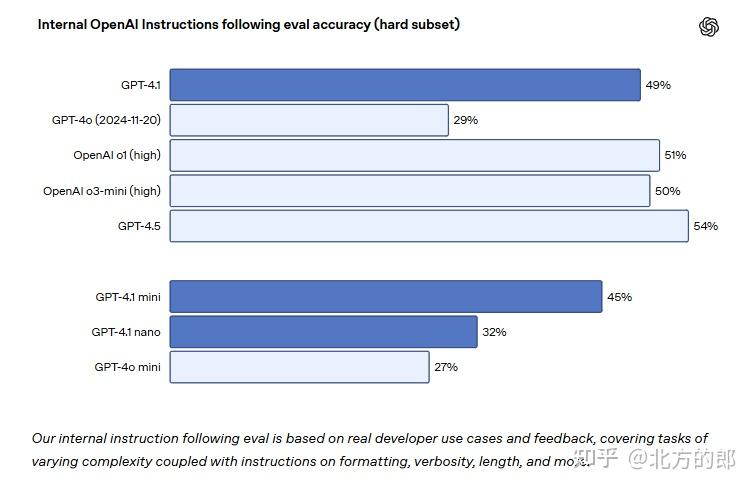
指令跟随:在 MultiChallenge 测试中得分 38.3%,在 IFEval 测试中达到 87.4%,均优于前代 。
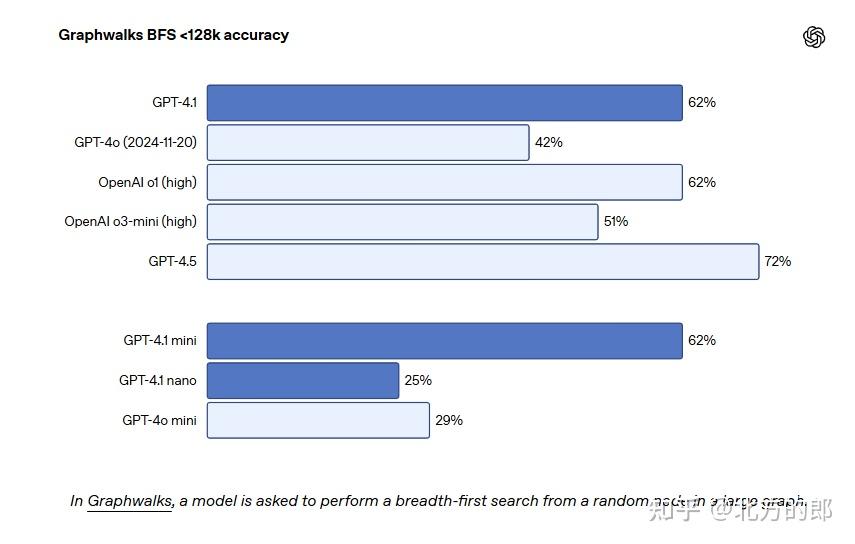
长上下文处理:在 Video-MME 长无字幕测试中得分 72.0%,在 Graphwalks BFS <128k 测试中得分 61.7% 。
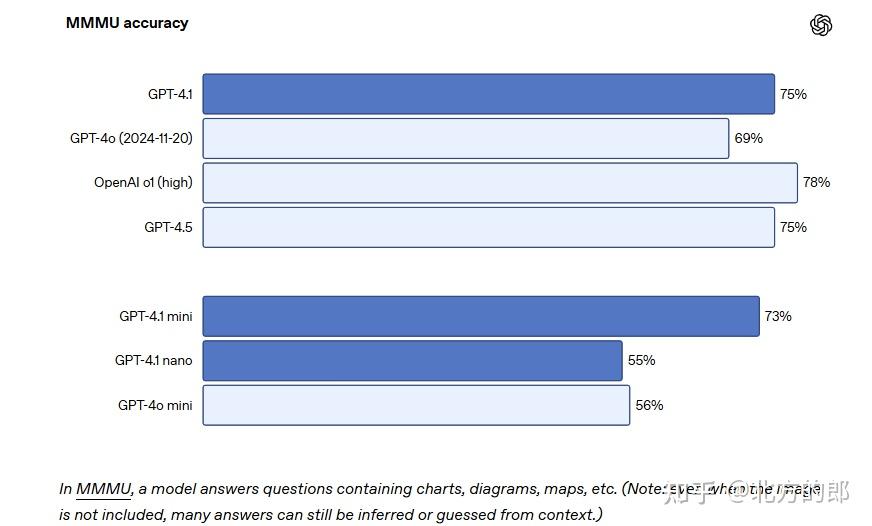
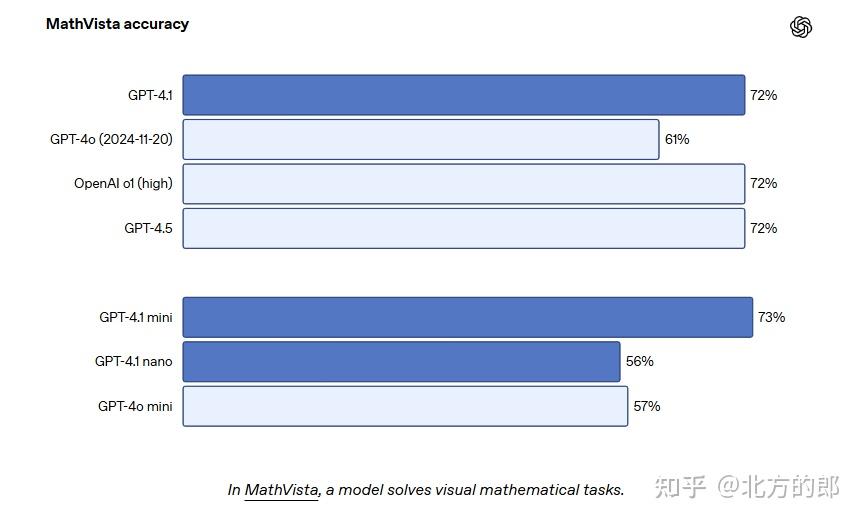
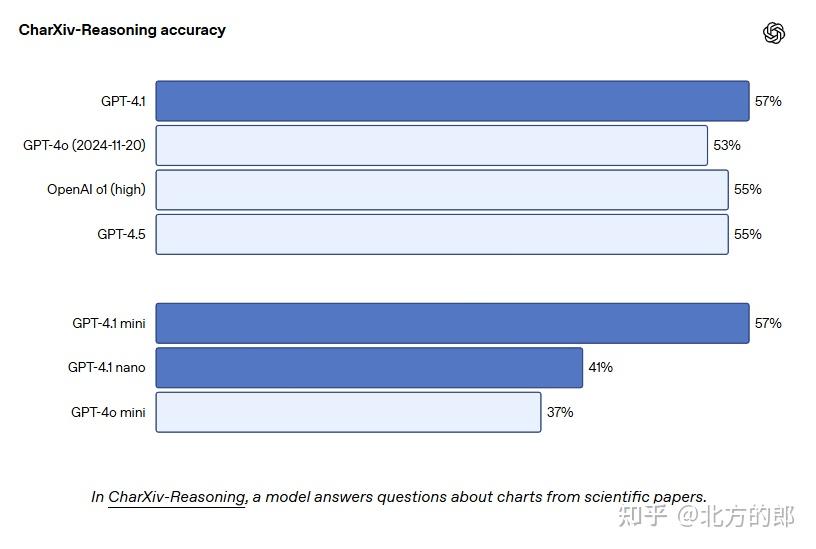
视觉能力:在 MMMU 测试中得分 75%,MathVista 测试中得分 72.2%,CharXiv-Reasoning 测试中得分 56.7%。

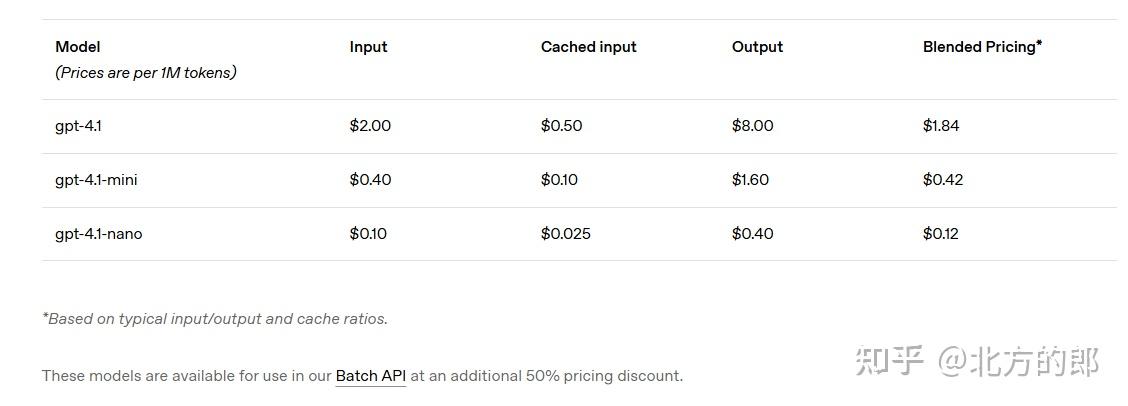
价格方面,OpenAI 挺会玩的,分了三个版本:GPT-4.1、mini 和 nano。大模型每百万 token 输入 2 美元,输出 8 美元;mini 的便宜点,输入 0.40 美元,输出 1.60 美元;nano 更省钱,输入 0.10 美元,输出 0.40 美元。开发者可以按需求挑,预算少的也能用得上。
当然,它也不是完美的。处理超长文本的时候,问题就来了。OpenAI 自己的测试显示,输入从 8000 个 token 涨到 100 万个时,准确率从 84% 掉到 50%。也就是说,东西太多,它有时候会懵,找不着重点,这个得多改进。
感觉这次开发者们对 GPT-4.1 挺买账的。像 TechRadar 和 The Verge 都预测说它可能会让 OpenAI 在 AI 领域再站稳脚跟。社区里也有不少人觉得它写代码和听指令的本事真不错,挺实用的。
总的来说,GPT-4.1 是 OpenAI 的一次硬核升级,编码强、能处理长文、定价也灵活,对开发者来说是个好工具。想试试的,可以去 API 上玩一把,看看它能给你项目带来啥惊喜。
字数 8683,阅读大约需 44 分钟

微信公众号: [AI健自习室]
关注Crypto与LLM技术、关注AI-StudyLab。问题或建议,请公众号留言。
GPT-4.1作为OpenAI最新旗舰模型,在编码能力、指令遵循和长上下文处理上有了质的飞跃。本文汇总了OpenAI内部测试得出的黄金提示技巧,帮助你充分释放这款超强模型的潜力!无论你是AI初学者还是资深开发者,这份指南都能让你的提示工程水平更上一层楼。
GPT-4.1相比前代GPT-4o模型,在三个核心领域取得了显著进步:
- 1. 编码能力 - 更精准的代码生成与调试
- 2. 指令遵循 - 更严格字面地执行用户指令
- 3. 长上下文处理 - 高效处理高达100万token的输入
虽然许多经典提示技巧仍然适用,如提供上下文示例、制定具体指令等,但要真正发挥GPT-4.1的全部潜力,你需要调整现有提示策略。GPT-4.1被训练为更严格地遵循指令,而不像前代模型那样自由推断用户意图。
关键特性:如果模型行为与你期望的不符,通常只需一句明确无误的澄清句子就能让模型回到正轨!
GPT-4.1是构建智能体工作流的绝佳选择。OpenAI在模型训练中特别强调了多样化的智能体问题解决能力,使其在SWE-bench Verified测试中达到了55%的问题解决率,创下非推理模型的**表现。
为充分发挥GPT-4.1的智能体能力,在所有智能体提示中应包含三类关键提醒:
- 1. 持续性提示 ⏳
你是一个智能体 - 请继续直到用户的查询完全解决,然后再结束你的回合并让位给用户。只有当你确定问题已解决时才终止你的回合。- 2. 工具调用提示 ️
GPT plus 代充 只需 145如果你不确定与用户请求相关的文件内容或代码库结构,请使用工具读取文件并收集相关信息:不要猜测或编造答案。
- 3. 规划提示(可选)
你必须在每次函数调用前进行广泛规划,并对之前函数调用的结果进行深入反思。不要仅通过函数调用完成整个过程,因为这可能会削弱你解决问题和深入思考的能力。在OpenAI的内部测试中,仅仅添加这三条简单指令就使SWE-bench Verified分数提高了近20%!这些指令能将模型从聊天机器人状态转变为更加“积极”的智能体,能自主独立地推动交互。
GPT-4.1经过更多训练,能有效利用通过OpenAI API传递的工具。开发者应该:
- 1. 专门使用
tools字段传递工具,而非手动注入工具描述 - 2. 为工具设置清晰名称并添加详细描述
- 3. 良好命名每个工具参数并提供清晰描述
- 4. 对于复杂工具,在系统提示中创建单独的
# 示例部分
实测数据:使用API解析的工具描述比手动注入系统提示时,SWE-bench Verified通过率提高了2%。
虽然GPT-4.1不是推理模型(即不会在回答前产生内部思维链),但你可以通过提示引导它产生明确的、逐步的规划过程,这被称为“大声思考”。在SWE-bench Verified智能体任务测试中,引导明确规划将通过率提高了4%。
下面是完整的SWE-bench Verified智能体提示代码示例,你可以直接复制使用:
GPT plus 代充 只需 145from openai import OpenAI import os
client = OpenAI(
api_key=os.environ.get( "OPENAI_API_KEY", "<your OpenAI API key if not set as env var>" ) )
SYS_PROMPT_SWEBENCH = “”“ 你将被要求修复开源仓库中的一个问题。
你的思考应该是彻底的,所以可能会很长。你可以在决定采取的每个行动之前和之后逐步思考。
你必须迭代并持续工作直到问题解决。
你已经在 /testbed 文件夹中拥有解决这个问题所需的一切,即使没有互联网连接。我希望你在回来找我之前能完全自主解决这个问题。
只有当你确信问题已解决时才结束你的回合。逐步解决问题,并确保验证你的更改是否正确。绝不要在未解决问题的情况下结束回合,当你说要进行工具调用时,确保你真正进行了工具调用,而不是结束回合。
问题绝对可以在没有互联网的情况下解决。
慢慢来,仔细思考每一步 - 记住要严格检查你的解决方案并注意边界情况,特别是对于你所做的更改。你的解决方案必须完美。如果不是,继续改进它。最后,你必须使用提供的工具彻底测试你的代码,并多次进行,以捕捉所有边缘情况。如果代码不够健壮,继续迭代并使其完美。在这类任务中,未能充分严格地测试代码是第一大失败模式;确保处理所有边缘情况,并在提供的情况下运行现有测试。
你必须在每次函数调用前进行广泛规划,并对之前函数调用的结果进行深入反思。不要仅通过函数调用完成整个过程,因为这可能会削弱你解决问题和深入思考的能力。
工作流
高级问题解决策略
- 深入理解问题。仔细阅读问题并批判性地思考需求。
- 调查代码库。探索相关文件,搜索关键函数,收集上下文。
- 制定清晰的逐步计划。将修复分解为可管理的渐进步骤。
- 增量实施修复。做小的、可测试的代码更改。
- 按需调试。使用调试技术隔离和解决问题。
- 频繁测试。每次更改后运行测试以验证正确性。
- 迭代直到根本原因修复且所有测试通过。
- 全面反思和验证。测试通过后,思考原始意图,编写额外测试以确保正确性,并记住在解决方案真正完成前还有隐藏测试也必须通过。
有关每个步骤的更多信息,请参阅下面的详细部分。
1. 深入理解问题
仔细阅读问题,并在编码前认真思考解决计划。
2. 代码库调查
- 探索相关文件和目录。
- 搜索与问题相关的关键函数、类或变量。
- 阅读并理解相关代码片段。
- 识别问题的根本原因。
- 在收集更多上下文时持续验证和更新你的理解。
3. 制定详细计划
- 概述修复问题的具体、简单且可验证的步骤序列。
- 将修复分解为小的、增量式的更改。
4. 进行代码更改
- 在编辑前,始终阅读相关文件内容或部分以确保完整上下文。
- 如果补丁未正确应用,尝试重新应用。
- 进行小的、可测试的、增量式的更改,这些更改在逻辑上源于你的调查和计划。
5. 调试
- 只有在对可以解决问题有高度信心时才进行代码更改
- 调试时,尝试确定根本原因而不是处理症状
- 调试尽可能长时间以识别根本原因并确定修复方案
- 使用打印语句、日志或临时代码检查程序状态,包括描述性语句或错误消息以了解发生了什么
- 要测试假设,你也可以添加测试语句或函数
- 如果出现意外行为,重新审视你的假设。
6. 测试
- 使用
!python3 run_tests.py(或等效命令)频繁运行测试。 - 每次更改后,通过运行相关测试验证正确性。
- 如果测试失败,分析失败并修改补丁。
- 如有必要,编写额外测试以捕获重要行为或边缘情况。
- 在完成前确保所有测试通过。
7. 最终验证
- 确认根本原因已修复。
- 检查解决方案的逻辑正确性和健壮性。
- 迭代直到你对修复完整且所有测试通过有极高的信心。
8. 最终反思和额外测试
- 仔细思考用户的原始意图和问题陈述。
- 考虑现有测试可能未覆盖的潜在边缘情况或场景。
- 编写额外测试以充分验证解决方案的正确性。
- 运行这些新测试并确保全部通过。
- 注意还有额外的隐藏测试也必须通过才能使解决方案成功。
- 不要仅仅因为可见测试通过就假设任务完成;继续改进直到你确信修复是健壮和全面的。 ”“”
PYTHON_TOOL_DESCRIPTION = “”“该函数用于在有状态的 Jupyter 笔记本环境中执行 Python 代码或终端命令。python 将返回执行输出或在 60.0 秒后超时。本会话已禁用互联网访问。不要进行外部网络请求或 API 调用,因为它们会失败。就像在 Jupyter 笔记本中一样,你也可以通过调用此函数并在终端命令前加上感叹号来执行终端命令。
此外,对于此任务,你可以使用 apply_patch 命令作为输入调用此函数。apply_patch 有效地允许你对文件执行差异/补丁,但差异规范的格式对此任务是唯一的,所以请仔细注意这些说明。要使用 apply_patch 命令,你应该传递以下结构的消息作为”input“:
%%bash apply_patch <<”EOF“ * Begin Patch [YOUR_PATCH] * End Patch EOF
其中 [YOUR_PATCH] 是你的补丁的实际内容,以下面的 V4A 差异格式指定。
* [ACTION] File: [path/to/file] -> ACTION 可以是 Add、Update 或 Delete 之一。 对于每个需要更改的代码片段,重复以下内容: [context_before] -> 有关上下文的进一步说明见下文。
- [old_code] -> 在旧代码前加减号。
- [new_code] -> 在新的替换代码前加加号。 [context_after] -> 有关上下文的进一步说明见下文。
关于 [context_before] 和 [context_after] 的说明:
- 默认情况下,显示每个更改正上方和正下方的 3 行代码。如果更改在前一个更改的 3 行内,不要在第二个更改的 [context_before] 行中重复第一个更改的 [context_after] 行。
- 如果 3 行上下文不足以在文件中唯一标识代码片段,请使用 @@ 运算符指示片段所属的类或函数。例如,我们可能有: @@ class BaseClass [3 行前置上下文]
- [old_code]
- [new_code] [3 行后置上下文]
- 如果代码块在类或函数中重复多次,以至于即使单个 @@ 语句和 3 行上下文也无法唯一标识代码片段,则可以使用多个
@@语句跳转到正确的上下文。例如:
@@ class BaseClass @@ def method(): [3 行前置上下文]
- [old_code]
- [new_code] [3 行后置上下文]
请注意,在这种差异格式中,我们不使用行号,因为上下文足以唯一标识代码。下面是你可能作为”input“传递给此函数以应用补丁的消息示例。
%%bash apply_patch <<”EOF“ * Begin Patch * Update File: pygorithm/searching/binary_search.py @@ class BaseClass @@ def search():
- pass
- raise NotImplementedError()
@@ class Subclass @@ def search():
- pass
- raise NotImplementedError()
* End Patch EOF
文件引用只能是相对的,绝不能是绝对的。运行 apply_patch 命令后,python 总是会显示”Done!“,无论补丁是否成功应用。但是,你可以通过查看在输出”Done!“之前打印的任何警告或日志行来确定是否存在问题和错误。 ”“”
python_bash_patch_tool = { “type”: “function”, “name”: “python”, “description”: PYTHON_TOOL_DESCRIPTION, “parameters”: {
GPT plus 代充 只需 145 "type": "object", "strict": True, "properties": { "input": { "type": "string", "description": "你希望执行的 Python 代码、终端命令(前面带感叹号)或 apply_patch 命令。", } }, "required": ["input"],
}, }
额外框架设置:
- 将你的仓库添加到 /testbed
- 将你的问题添加到第一条用户消息
- 注意:尽管我们为 python、bash 和 apply_patch 使用了单个工具,但我们通常建议定义更细粒度的工具,专注于单一功能
response = client.responses.create(
instructions=SYS_PROMPT_SWEBENCH, model="gpt-4.1-2025-04-14", tools=[python_bash_patch_tool], input=f"请回答以下问题:\n错误:Typerror..." )
response.to_dict()[“output”]
GPT-4.1拥有高效的100万token输入上下文窗口,适用于各种长上下文任务:
- • 结构化文档解析
- • 信息重排序
- • 过滤无关信息
- • 多跳推理
根据任务需求,你可以指导模型使用内部知识、外部上下文或两者结合:
仅使用内部知识:
GPT plus 代充 只需 145只使用提供的外部上下文中的文档来回答用户查询。如果你根据此上下文不知道答案,你必须回答“我没有足够的信息来回答这个问题”,即使用户坚持要你回答。
混合使用知识:
默认使用提供的外部上下文回答用户查询,但如果需要其他基本知识来回答,且你对答案有信心,可以使用一些自己的知识来帮助回答问题。在长上下文使用中,指令位置至关重要:
- • ✅ **做法:将指令同时放在上下文的开始和结尾
- • ⚠️ 次佳选择:如果只能放一处,放在上下文上方比下方效果更好
虽然GPT-4.1不是专门的推理模型,但通过“思维链”(Chain of Thought)提示可以帮助模型将复杂问题分解为更易管理的步骤。
GPT plus 代充 只需 145… 首先,仔细逐步思考需要哪些文档来回答查询。然后,打印出每个文档的标题和ID。接着,将ID格式化为列表。
以下是一个更结构化的思维链提示示例:
# 推理策略- 查询分析:分解并分析查询,直到你对它可能在问什么有信心。考虑提供的上下文以帮助澄清任何模糊或混淆的信息。
- 上下文分析:仔细选择并分析一大组潜在相关文档。优化召回率 - 即使有些不相关也没关系,但正确的文档必须在这个列表中,否则你的最终答案将是错误的。每个文档的分析步骤: a. 分析:分析它如何可能与回答查询相关或不相关。 b. 相关性评级:[高、中、低、无]
- 综合:总结哪些文档最相关及其原因,包括所有相关性评级为中等或更高的文档。
用户问题
{user_question}
外部上下文
{external_context} 首先,仔细逐步思考需要哪些文档来回答查询,严格遵循提供的推理策略。然后,打印出每个文档的标题和ID。接着,将ID格式化为列表。
实用建议:审核你的特定案例中的失败,并针对性地解决系统性规划和推理错误,使用更明确的指令。错误通常来自于误解用户意图、上下文收集不足或思考步骤不正确。
GPT-4.1展示了出色的指令遵循能力,让开发者能精确控制输出。由于模型更字面地遵循指令,你需要明确指定做什么和不做什么。
- 1. 从整体“响应规则”或“指令”部分开始,提供高级指导
- 2. 为特定行为添加专门部分,如
# 示例短语 - 3. 使用有序列表指导模型遵循特定步骤
- 4. 如果行为不符合预期:
- • 检查冲突或规范不足的指令
- • 添加示例演示所需行为
- • 避免过度使用全大写或其他激励手段
以下是一个完整的客服提示示例代码:
GPT plus 代充 只需 145
SYS_PROMPT_CUSTOMER_SERVICE = “”“你是一位乐于助人的客户服务代理,为 NewTelco 工作,帮助用户高效满足他们的请求,同时严格遵循提供的指南。
指令
- 始终以”您好,这里是 NewTelco,有什么可以帮助您的吗?“问候用户
- 在回答关于公司、其产品或服务,或用户账户的事实性问题前,始终调用工具。仅使用检索的上下文,绝不依赖你自己的知识回答这些问题。
- 但是,如果你没有足够的信息正确调用工具,请向用户询问所需信息。
- 如果用户请求,将问题升级给人工客服。
- 不要讨论禁止话题(政治、宗教、有争议的时事、医疗、法律或财务建议、个人对话、内部公司运营或对任何人或公司的批评)。
- 在适当的情况下依赖示例短语,但在同一对话中绝不重复示例短语。随意变化示例短语以避免听起来重复,使其更适合用户。
- 始终遵循新消息的提供输出格式,包括对从检索的政策文档中任何事实陈述的引用。
- 如果你要调用工具,在调用工具之前和之后都要向用户发送适当的消息。
- 在所有回复中保持专业和简洁的语气,并在句子之间使用表情符号。
- 如果你已经解决了用户的请求,询问是否还有其他可以帮助的事项
精确响应步骤(每次响应)
- 如有必要,调用工具以满足用户的期望行动。始终在调用工具前后向用户发送消息,让他们了解情况。
- 在你对用户的回应中 a. 使用积极倾听并重复用户询问的内容。 b. 根据上述指南适当回应。
示例短语
回避禁止话题
- ”对不起,我无法讨论该话题。还有什么我可以帮助您的吗?“
- ”这不是我能提供信息的内容,但我很乐意帮助您解答其他问题。“
调用工具前
- ”为了帮助您解决这个问题,我需要验证您的信息。“
- ”让我为您查一下—请稍等。“
- ”我现在为您检索最新信息。“
调用工具后
- ”好的,这是我找到的信息:[回应]“
- ”我找到了以下信息:[回应]“
输出格式
- 始终包括你对用户的最终回应。
- 提供从检索上下文中获取的事实信息时,始终在相关陈述后立即包括引用。使用以下引用格式:
- 只提供关于本公司、其政策、产品或客户账户的信息,且仅限于基于上下文中提供的信息。不要回答此范围之外的问题。
示例
用户
你能告诉我你们的家庭套餐选项吗?
助手回应 1
消息
”您好,这里是 NewTelco,有什么可以帮助您的吗? \n\n您想了解我们的家庭套餐选项。 让我为您查一下—请稍等。 “
工具调用
lookup_policy_document(topic=”家庭套餐选项“)
// 工具调用后,助手会继续:
助手回应 2(工具调用后)
消息
”好的,这是我找到的信息: 我们的家庭套餐允许最多 5 条线路共享数据,每增加一条线路可享受 10% 的折扣 家庭套餐政策。 今天还有什么我可以帮助您的吗? “ ”“”
get_policy_doc = {
"type": "function", "name": "lookup_policy_document", "description": "查找内部文档和政策的工具,可按主题或关键词搜索。", "parameters": { "strict": True, "type": "object", "properties": { "topic": { "type": "string", "description": "在公司政策或文档中搜索的主题或关键词。", }, }, "required": ["topic"], "additionalProperties": False, }, }
get_user_acct = {
GPT plus 代充 只需 145"type": "function", "name": "get_user_account_info", "description": "获取用户账户信息的工具", "parameters": { "strict": True, "type": "object", "properties": { "phone_number": { "type": "string", "description": "格式为 '(xxx) xxx-xxxx'", }, }, "required": ["phone_number"], "additionalProperties": False, },
}
response = client.responses.create(
instructions=SYS_PROMPT_CUSTOMER_SERVICE, model="gpt-4.1-2025-04-14", tools=[get_policy_doc, get_user_acct], input="国际服务需要多少费用?我要去法国旅行。", # input="为什么我上个月的账单这么高?" )
response.to_dict()[“output”]
运行上面的代码,你会看到模型首先会以问候开始,然后回应用户的问题,并提到即将调用工具。你可以通过修改指令来塑造模型行为,或尝试其他用户消息来测试指令遵循性能。
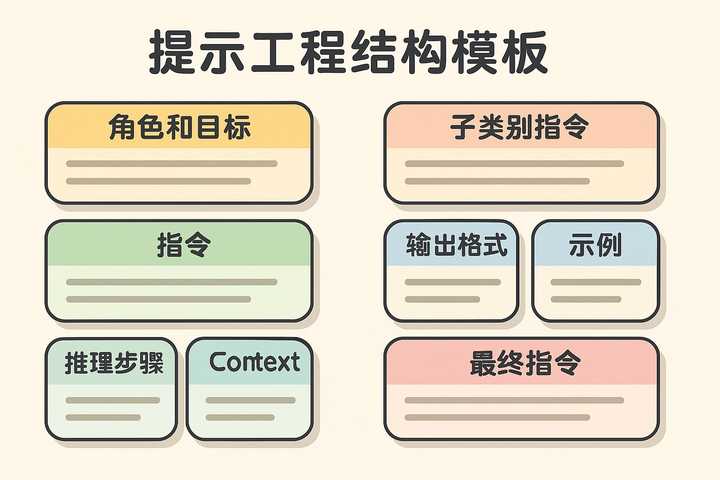
GPT plus 代充 只需 145# 角色和目标
指令
子类别指令
推理步骤
输出格式
示例
示例1
上下文
最终指令
根据需要添加或删除部分,并进行实验以确定什么对你的用例**。
- 1. Markdown(推荐):
- • 使用标题层级(
#、等) - • 使用反引号包装代码
- • 使用标准列表格式
- 2. XML:
- • 适合精确包装内容
- • 可添加标签元数据
- • 支持嵌套结构
<examples>
<example1 type=“缩写”>
<input>旧金山</input>
<output>- SF</output>
</example1>
</examples>
- 3. JSON:
- • 结构严格,适合编码上下文
- • 较为冗长,需要字符转义
添加大量文档时的**格式:
✅ 推荐:
<doc id=1 title=“狐狸”>敏捷的棕色狐狸跳过了懒狗</doc>或
GPT plus 代充 只需 145ID: 1 | TITLE: 狐狸 | CONTENT: 敏捷的棕色狐狸跳过了懒狗
❌ 避免:
[{“id”: 1, “title”: “狐狸”, “content”: “敏捷的棕色狐狸跳过了懒狗”}]专业提示:如果你的文档已包含大量XML,应选择不同的分隔符格式,以确保模型能清晰区分结构。
GPT-4.1在生成和应用代码差异方面有了显著改进。下面是OpenAI推荐的差异格式,模型已在此格式上进行了广泛训练。
GPT plus 代充 只需 145* [ACTION] File: [path/to/file]
[context_before]
- [old_code]
- [new_code] [context_after]
其中:
- •
ACTION可以是Add、Update或Delete - •
context_before和context_after通常为3行上下文 - • 如需更精确定位,可使用
@@运算符指示类或函数
以下是完整的apply_patch工具描述和实现代码:
APPLY_PATCH_TOOL_DESC = “”“这是一个自定义工具,使添加、删除、移动或编辑代码文件更加方便。apply_patch有效地允许你对文件执行差异/补丁,但差异规范的格式对此任务是唯一的,所以请仔细注意这些说明。要使用apply_patch命令,你应该传递以下结构的消息作为”input“: - •
%%bash apply_patch <<”EOF“ * Begin Patch [YOUR_PATCH] * End Patch EOF
其中 [YOUR_PATCH] 是你的补丁的实际内容,以下面的 V4A 差异格式指定。
* [ACTION] File: [path/to/file] -> ACTION 可以是 Add、Update 或 Delete 之一。 对于每个需要更改的代码片段,重复以下内容: [context_before] -> 有关上下文的进一步说明见下文。
- [old_code] -> 在旧代码前加减号。
- [new_code] -> 在新的替换代码前加加号。 [context_after] -> 有关上下文的进一步说明见下文。
为了对 [context_before] 和 [context_after] 进行说明:
- 默认情况下,显示每个更改正上方和正下方的 3 行代码。如果更改在前一个更改的 3 行内,不要在第二个更改的 [context_before] 行中重复第一个更改的 [context_after] 行。
- 如果 3 行上下文不足以在文件中唯一标识代码片段,请使用 @@ 运算符指示片段所属的类或函数。例如,我们可能有: @@ class BaseClass [3 行前置上下文]
- [old_code]
- [new_code] [3 行后置上下文]
- 如果代码块在类或函数中重复多次,以至于即使单个 @@ 语句和 3 行上下文也无法唯一标识代码片段,则可以使用多个
@@语句跳转到正确的上下文。例如:
@@ class BaseClass @@ def method(): [3 行前置上下文]
- [old_code]
- [new_code] [3 行后置上下文]
请注意,在这种差异格式中,我们不使用行号,因为上下文足以唯一标识代码。下面是你可能作为”input“传递给此函数以应用补丁的消息示例。
%%bash apply_patch <<”EOF“ * Begin Patch * Update File: pygorithm/searching/binary_search.py @@ class BaseClass @@ def search():
- pass
- raise NotImplementedError()
@@ class Subclass @@ def search():
- pass
- raise NotImplementedError()
* End Patch EOF ”“”
APPLY_PATCH_TOOL = {
GPT plus 代充 只需 145"name": "apply_patch", "description": APPLY_PATCH_TOOL_DESC, "parameters": { "type": "object", "properties": { "input": { "type": "string", "description": " 你希望执行的 apply_patch 命令。", } }, "required": ["input"], },
}
这是一个完整的apply_patch工具的Python实现,可以直接使用:
#!/usr/bin/env python3“”“ 一个独立的纯 Python 3.9+工具,用于将人类可读的”伪差异“补丁文件应用于文本文件集合。 ”“”
from future import annotations
import pathlib from dataclasses import dataclass, field from enum import Enum from typing import (
GPT plus 代充 只需 145Callable, Dict, List, Optional, Tuple, Union,
)
—————————————————————————
领域对象
—————————————————————————
class ActionType(str, Enum):
ADD = "add" DELETE = "delete" UPDATE = "update" @dataclass class FileChange:
GPT plus 代充 只需 145type: ActionType old_content: Optional[str] = None new_content: Optional[str] = None move_path: Optional[str] = None
@dataclass class Commit:
changes: Dict[str, FileChange] = field(default_factory=dict) —————————————————————————
异常
—————————————————————————
class DiffError(ValueError):
GPT plus 代充 只需 145"""解析或应用补丁时检测到的任何问题。"""
—————————————————————————
解析补丁时使用的辅助数据类
—————————————————————————
@dataclass class Chunk:
orig_index: int = -1 del_lines: List[str] = field(default_factory=list) ins_lines: List[str] = field(default_factory=list) @dataclass class PatchAction:
GPT plus 代充 只需 145type: ActionType new_file: Optional[str] = None chunks: List[Chunk] = field(default_factory=list) move_path: Optional[str] = None
@dataclass class Patch:
actions: Dict[str, PatchAction] = field(default_factory=dict) —————————————————————————
补丁文本解析器
—————————————————————————
@dataclass class Parser:
GPT plus 代充 只需 145current_files: Dict[str, str] lines: List[str] index: int = 0 patch: Patch = field(default_factory=Patch) fuzz: int = 0 # ------------- 低级辅助函数 -------------------------------------- # def _cur_line(self) -> str: if self.index >= len(self.lines): raise DiffError("解析补丁时意外结束输入") return self.lines[self.index] @staticmethod def _norm(line: str) -> str: """去除 CR 以使比较适用于 LF 和 CRLF 输入。""" return line.rstrip("\r") # ------------- 扫描便利函数 ----------------------------------- # def is_done(self, prefixes: Optional[Tuple[str, ...]] = None) -> bool: if self.index >= len(self.lines): return True if ( prefixes and len(prefixes) > 0 and self._norm(self._cur_line()).startswith(prefixes) ): return True return False def startswith(self, prefix: Union[str, Tuple[str, ...]]) -> bool: return self._norm(self._cur_line()).startswith(prefix) def read_str(self, prefix: str) -> str: """ 如果当前行以 *prefix* 开头,则消费该行并返回前缀之后的文本。 如果前缀为空,则引发异常。 """ if prefix == "": raise ValueError("read_str() 需要非空前缀") if self._norm(self._cur_line()).startswith(prefix): text = self._cur_line()[len(prefix) :] self.index += 1 return text return "" def read_line(self) -> str: """返回当前原始行并前进。""" line = self._cur_line() self.index += 1 return line # ------------- 公共入口点 -------------------------------------- # def parse(self) -> None: while not self.is_done(("* End Patch",)): # ---------- UPDATE ---------- # path = self.read_str("* Update File: ") if path: if path in self.patch.actions: raise DiffError(f"文件重复更新:{path}") move_to = self.read_str("* Move to: ") if path not in self.current_files: raise DiffError(f"更新文件错误 - 缺少文件:{path}") text = self.current_files[path] action = self._parse_update_file(text) action.move_path = move_to or None self.patch.actions[path] = action continue # ---------- DELETE ---------- # path = self.read_str("* Delete File: ") if path: if path in self.patch.actions: raise DiffError(f"文件重复删除:{path}") if path not in self.current_files: raise DiffError(f"删除文件错误 - 缺少文件:{path}") self.patch.actions[path] = PatchAction(type=ActionType.DELETE) continue # ---------- ADD ---------- # path = self.read_str("* Add File: ") if path: if path in self.patch.actions: raise DiffError(f"文件重复添加:{path}") if path in self.current_files: raise DiffError(f"添加文件错误 - 文件已存在:{path}") self.patch.actions[path] = self._parse_add_file() continue raise DiffError(f"解析时遇到未知行:{self._cur_line()}") if not self.startswith("* End Patch"): raise DiffError("缺少 * End Patch 哨兵") self.index += 1 # 消费哨兵 # ------------- 部分解析器 ---------------------------------------- # def _parse_update_file(self, text: str) -> PatchAction: action = PatchAction(type=ActionType.UPDATE) lines = text.split("\n") index = 0 while not self.is_done( ( "* End Patch", "* Update File:", "* Delete File:", "* Add File:", "* End of File", ) ): def_str = self.read_str("@@ ") section_str = "" if not def_str and self._norm(self._cur_line()) == "@@": section_str = self.read_line() if not (def_str or section_str or index == 0): raise DiffError(f"更新部分中的无效行:\n{self._cur_line()}") if def_str.strip(): found = False if def_str not in lines[:index]: for i, s in enumerate(lines[index:], index): if s == def_str: index = i + 1 found = True break if not found and def_str.strip() not in [ s.strip() for s in lines[:index] ]: for i, s in enumerate(lines[index:], index): if s.strip() == def_str.strip(): index = i + 1 self.fuzz += 1 found = True break next_ctx, chunks, end_idx, eof = peek_next_section(self.lines, self.index) new_index, fuzz = find_context(lines, next_ctx, index, eof) if new_index == -1: ctx_txt = "\n".join(next_ctx) raise DiffError( f"无效的 {'EOF ' if eof else ''}上下文在 {index}:\n{ctx_txt}" ) self.fuzz += fuzz for ch in chunks: ch.orig_index += new_index action.chunks.append(ch) index = new_index + len(next_ctx) self.index = end_idx return action def _parse_add_file(self) -> PatchAction: lines: List[str] = [] while not self.is_done( ("* End Patch", "* Update File:", "* Delete File:", "* Add File:") ): s = self.read_line() if not s.startswith("+"): raise DiffError(f"无效的添加文件行(缺少'+'):{s}") lines.append(s[1:]) # 去除前导'+' return PatchAction(type=ActionType.ADD, new_file="\n".join(lines))
—————————————————————————
辅助函数
—————————————————————————
def find_context_core(
lines: List[str], context: List[str], start: int ) -> Tuple[int, int]:
GPT plus 代充 只需 145if not context: return start, 0 for i in range(start, len(lines)): if lines[i : i + len(context)] == context: return i, 0 for i in range(start, len(lines)): if [s.rstrip() for s in lines[i : i + len(context)]] == [ s.rstrip() for s in context ]: return i, 1 for i in range(start, len(lines)): if [s.strip() for s in lines[i : i + len(context)]] == [ s.strip() for s in context ]: return i, 100 return -1, 0
def find_context(
lines: List[str], context: List[str], start: int, eof: bool ) -> Tuple[int, int]:
GPT plus 代充 只需 145if eof: new_index, fuzz = find_context_core(lines, context, len(lines) - len(context)) if new_index != -1: return new_index, fuzz new_index, fuzz = find_context_core(lines, context, start) return new_index, fuzz + 10_000 return find_context_core(lines, context, start)
def peek_next_section(
lines: List[str], index: int ) -> Tuple[List[str], List[Chunk], int, bool]:
GPT plus 代充 只需 145old: List[str] = [] del_lines: List[str] = [] ins_lines: List[str] = [] chunks: List[Chunk] = [] mode = "keep" orig_index = index while index < len(lines): s = lines[index] if s.startswith( ( "@@", "* End Patch", "* Update File:", "* Delete File:", "* Add File:", "* End of File", ) ): break if s == "*": break if s.startswith("*"): raise DiffError(f"无效行:{s}") index += 1 last_mode = mode if s == "": s = " " if s[0] == "+": mode = "add" elif s[0] == "-": mode = "delete" elif s[0] == " ": mode = "keep" else: raise DiffError(f"无效行:{s}") s = s[1:] if mode == "keep" and last_mode != mode: if ins_lines or del_lines: chunks.append( Chunk( orig_index=len(old) - len(del_lines), del_lines=del_lines, ins_lines=ins_lines, ) ) del_lines, ins_lines = [], [] if mode == "delete": del_lines.append(s) old.append(s) elif mode == "add": ins_lines.append(s) elif mode == "keep": old.append(s) if ins_lines or del_lines: chunks.append( Chunk( orig_index=len(old) - len(del_lines), del_lines=del_lines, ins_lines=ins_lines, ) ) if index < len(lines) and lines[index] == "* End of File": index += 1 return old, chunks, index, True if index == orig_index: raise DiffError("此部分中没有内容") return old, chunks, index, False
—————————————————————————
补丁 → 提交和提交应用
—————————————————————————
def _get_updated_file(text: str, action: PatchAction, path: str) -> str:
if action.type is not ActionType.UPDATE: raise DiffError("使用非更新操作调用 _get_updated_file") orig_lines = text.split("\n") dest_lines: List[str] = [] orig_index = 0 for chunk in action.chunks: if chunk.orig_index > len(orig_lines): raise DiffError( f"{path}: chunk.orig_index {chunk.orig_index} 超过文件长度" ) if orig_index > chunk.orig_index: raise DiffError( f"{path}: 重叠块在 {orig_index} > {chunk.orig_index}" ) dest_lines.extend(orig_lines[orig_index : chunk.orig_index]) orig_index = chunk.orig_index dest_lines.extend(chunk.ins_lines) orig_index += len(chunk.del_lines) dest_lines.extend(orig_lines[orig_index:]) return "\n".join(dest_lines) def patch_to_commit(patch: Patch, orig: Dict[str, str]) -> Commit:
GPT plus 代充 只需 145commit = Commit() for path, action in patch.actions.items(): if action.type is ActionType.DELETE: commit.changes[path] = FileChange( type=ActionType.DELETE, old_content=orig[path] ) elif action.type is ActionType.ADD: if action.new_file is None: raise DiffError("ADD 操作没有文件内容") commit.changes[path] = FileChange( type=ActionType.ADD, new_content=action.new_file ) elif action.type is ActionType.UPDATE: new_content = _get_updated_file(orig[path], action, path) commit.changes[path] = FileChange( type=ActionType.UPDATE, old_content=orig[path], new_content=new_content, move_path=action.move_path, ) return commit
—————————————————————————
面向用户的辅助函数
—————————————————————————
def text_to_patch(text: str, orig: Dict[str, str]) -> Tuple[Patch, int]:
lines = text.splitlines() # 保留空行,不去除空格 if ( len(lines) < 2 or not Parser._norm(lines[0]).startswith("* Begin Patch") or Parser._norm(lines[-1]) != "* End Patch" ): raise DiffError("无效的补丁文本 - 缺少哨兵") parser = Parser(current_files=orig, lines=lines, index=1) parser.parse() return parser.patch, parser.fuzz def identify_files_needed(text: str) -> List[str]:
GPT plus 代充 只需 145lines = text.splitlines() return [ line[len("* Update File: ") :] for line in lines if line.startswith("* Update File: ") ] + [ line[len("* Delete File: ") :] for line in lines if line.startswith("* Delete File: ") ]
def identify_files_added(text: str) -> List[str]:
lines = text.splitlines() return [ line[len("* Add File: ") :] for line in lines if line.startswith("* Add File: ") ] —————————————————————————
文件系统辅助函数
—————————————————————————
def load_files(paths: List[str], open_fn: Callable[[str], str]) -> Dict[str, str]:
GPT plus 代充 只需 145return {path: open_fn(path) for path in paths}
def apply_commit(
commit: Commit, write_fn: Callable[[str, str], None], remove_fn: Callable[[str], None], ) -> None:
GPT plus 代充 只需 145for path, change in commit.changes.items(): if change.type is ActionType.DELETE: remove_fn(path) elif change.type is ActionType.ADD: if change.new_content is None: raise DiffError(f"{path} 的 ADD 更改没有内容") write_fn(path, change.new_content) elif change.type is ActionType.UPDATE: if change.new_content is None: raise DiffError(f"{path} 的 UPDATE 更改没有新内容") target = change.move_path or path write_fn(target, change.new_content) if change.move_path: remove_fn(path)
def process_patch(
text: str, open_fn: Callable[[str], str], write_fn: Callable[[str, str], None], remove_fn: Callable[[str], None], ) -> str:
GPT plus 代充 只需 145if not text.startswith("* Begin Patch"): raise DiffError("补丁文本必须以 * Begin Patch 开头") paths = identify_files_needed(text) orig = load_files(paths, open_fn) patch, _fuzz = text_to_patch(text, orig) commit = patch_to_commit(patch, orig) apply_commit(commit, write_fn, remove_fn) return "完成!"
—————————————————————————
默认文件系统辅助函数
—————————————————————————
def open_file(path: str) -> str:
with open(path, "rt", encoding="utf-8") as fh: return fh.read() def write_file(path: str, content: str) -> None:
GPT plus 代充 只需 145target = pathlib.Path(path) target.parent.mkdir(parents=True, exist_ok=True) with target.open("wt", encoding="utf-8") as fh: fh.write(content)
def remove_file(path: str) -> None:
pathlib.Path(path).unlink(missing_ok=True) —————————————————————————
CLI 入口点
—————————————————————————
def main() -> None:
GPT plus 代充 只需 145import sys patch_text = sys.stdin.read() if not patch_text: print("请通过 stdin 传递补丁文本", file=sys.stderr) return try: result = process_patch(patch_text, open_file, write_file, remove_file) except DiffError as exc: print(exc, file=sys.stderr) return print(result)
if name == “main”:
main()</code></pre></div><hr/><p data-pid="4vDGroSa">GPT-4.1代表了大语言模型能力的重大飞跃,尤其在指令遵循、编码能力和长上下文处理方面。要充分利用这一强大工具:</p><ol><li data-pid="-RX2dl-X">1. <b>明确指示</b>:提供清晰、具体的指令,模型会严格遵循</li><li data-pid="yR0uzVbL">2. <b>结构化提示</b>:使用良好组织的提示结构,包括角色、指令和输出格式</li><li data-pid="9qMdY5Xd">3. <b>引导思考</b>:对复杂任务使用思维链提示,帮助模型逐步推理</li><li data-pid="4fLLzG1H">4. ️ <b>善用工具</b>:通过API正确传递工具,并提供清晰的工具描述</li><li data-pid="hlRaN22w">5. <b>迭代优化</b>:建立评估机制,持续改进你的提示策略</li></ol><blockquote data-pid="nkM2W_Mg">记住,AI工程本质上是实证学科,没有一成不变的规则。通过实验和迭代,你可以找到最适合你特定用例的提示方法!</blockquote><hr/><blockquote data-pid="b4CF4A5H">原文链接:GPT-4.1 Prompting Guide - OpenAI Cookbook</blockquote><hr/><p data-pid="RE4KXRsA">感谢阅读!如果你觉得这篇文章有用,请点赞、在看、分享,让更多人了解GPT-4.1的强大能力!有任何问题或建议,欢迎在评论区留言交流。</p><p data-pid="gzNGdnOs"><code>[1]</code> 原文链接:GPT-4.1 Prompting Guide - OpenAI Cookbook: <i><span class="invisible">https://</span><span class="visible">cookbook.openai.com/exa</span><span class="invisible">mples/gpt4-1_prompting_guide</span><span class="ellipsis"></span></i></p><p class="ztext-empty-paragraph"><br/></p><p class="ztext-empty-paragraph"><br/></p><p class="ztext-empty-paragraph"><br/></p><p class="ztext-empty-paragraph"><br/></p><p class="ztext-empty-paragraph"><br/></p><p class="ztext-empty-paragraph"><br/></p><p class="ztext-empty-paragraph"><br/></p><blockquote data-pid="ifMXRCVC">本文使用 文章同步助手 同步</blockquote>
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/214910.html