
使用的系统是:ubuntu 16.04, anaconda
一、安装
安装方式参考labelme 的gitbub上面的教程,我主要是在anaconda的虚拟环境下安装,安装步骤为:
conda create --name=labelme python=3.6 source activate labelme pip install labelme 讯享网
当要使用labelme的时候,在任意地方打开终端,然后激活labelme虚拟环境,然后输入labelme,回车即可打开。

讯享网
二、使用
讯享网labelme --help

- -h或-help显示帮助信息
- -V或–version显示labelme版本号
- –output: 指定输出标注文件的保存路径,如果路径以.json结尾,则保存为一个.json文件,否则默认保存为文件夹形式
- –labels:用于指定标签名称,可以是用逗号分隔的label list,也可以是包含标签的txt文件
- –nodata: 不保存图像到JSON文件
三、分割任务标注示例
终端激活虚拟环境labelme,然后直接输入labelme打开
source activate labelme labelme - open: 打开某一张图片
- openDir: 打开某一文件夹,加载其目录下的所有图片
通过open读取图片,选择create polygons手动进行勾画,全部完成后保存为json文件(在当前目录下):
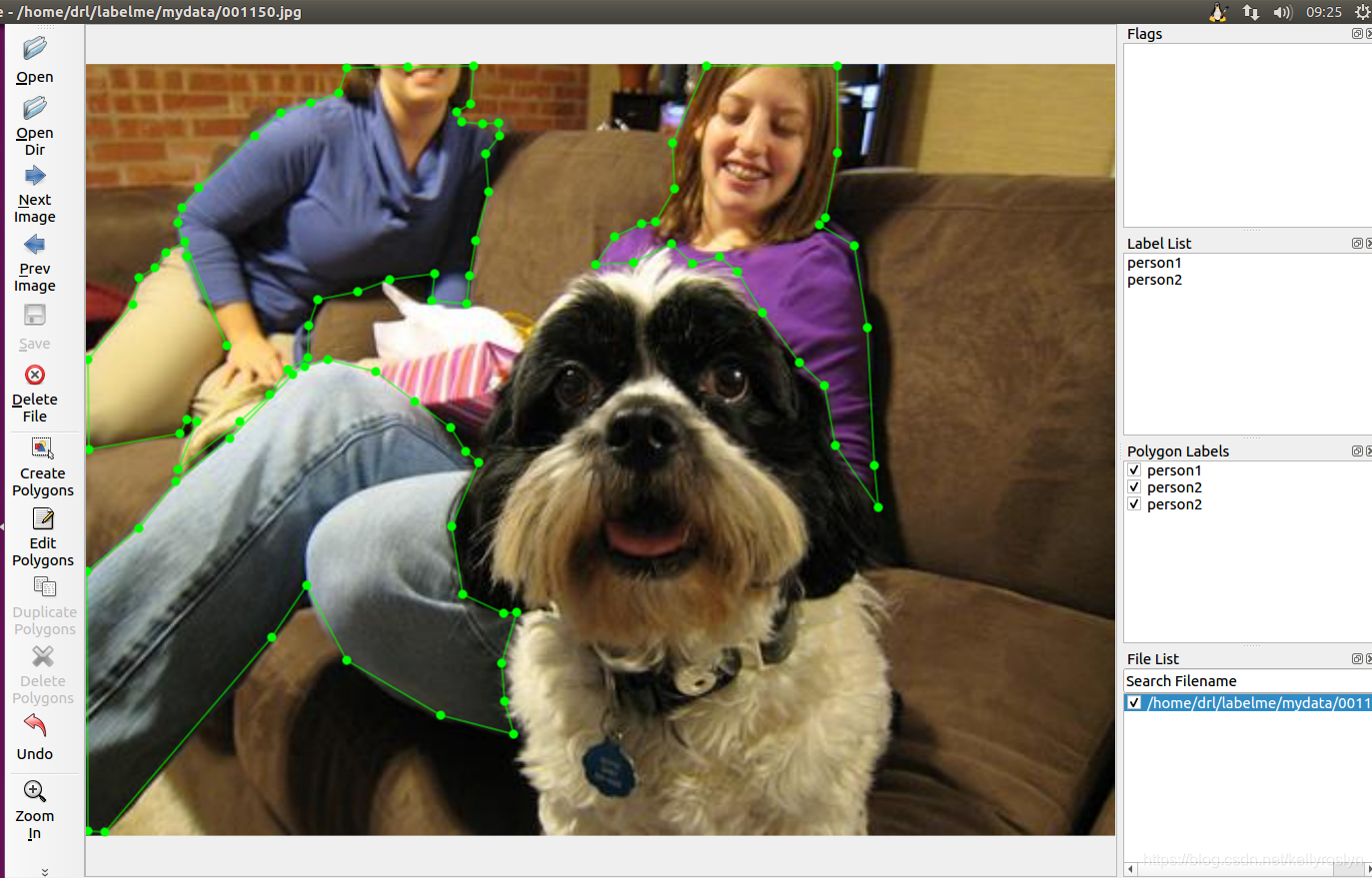
右键单击可以选择不同的标注方式,比如polygon用于分割,rectangle用于检测。
如果是实例分割,一个图像中有多个人,标签命名规则为:person1、person2, …, 如果是语义分割就不用区分了。
要得到label文件,需要将json转换为单通道的image,终端输入命令:
讯享网#进入json文件保存目录 cd /home/drl/labelme/mydata #转换 labelme_json_to_dataset <文件名>.json #比如 labelme_json_to_dataset 001150.json

将在mydata文件夹下生成一个名为:001150_json的文件夹,里面包含四个文件:
- img.png: 原始图像
- label.png: 标签,uint8
- label_viz.png: 可视化的带标签图像
- label_names.txt: 记录了标签的名称
img.png :
 label.png:
label.png:
 label_viz.png:
label_viz.png:

四、其他说明
(1)启动labelme的方式:
#直接打开labelme labelme #打开某个文件夹,加载该文件夹下及其子文件夹下的所有图片 #labelme path/to/imgfile/ #比如: labelme /home/drl/labelme/mydata/ 

讯享网#直接打开指定的图片 cd /home/drl/labelme/mydata/ labelme 001150.jpg

#标注保存为json文件同时自动关闭gui窗口 labelme 001150.jpg -o 001150.jpg.json #指定label list labelme 001150.jpg \ --labels person1, person2, dog #或者传入文件形式的label list --labels labels.txt 
(2)将JSON文件转换为image和label
讯享网#在当前目录下生成一个文件夹001150_json labelme_json_to_dataset 001150.json #指定生成文件夹的名字为001150data labelme_json_to_dataset 001150.json -o 001150data



(3)可视化json文件
source activate labelme cd /home/drl/labelme/mydata/ labelme_draw_json 001150.json 

五、加载标签png
label.png用scipy.misc.imread或者skimage.io.imread读取可能会出错,推荐用PIL.Image.open读取:
讯享网>>>import numpy as np >>>import PIL.Image >>>label_png = '/home/drl/labelme/mydata/001150_json/img.png' #设置标签文件路径 >>>lbI = np.asarray(PIL.Image.open(label_png)) >>>print(lbI.dtype) >>>np.unique(lbI) >>>lbI.shape (375, 500, 3)
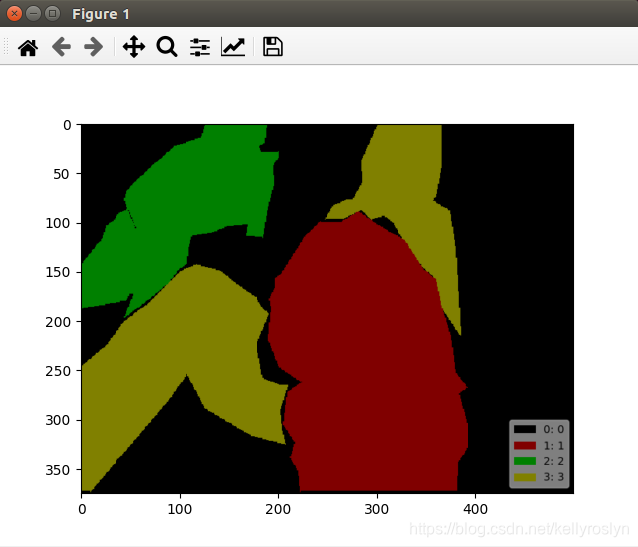
 查看label.png:
查看label.png:
#终端输入 labelme_draw_label_png /home/drl/labelme/mydata/001150_json/label.png 
六、生成VOC格式的标签数据
在下载的labelme的zip包里,路径labelme/examples/instance_segmentation下,data_annotated是原图和对应的JSON文件,data_dataset_voc是VOC格式的输出结果,labelme2voc.py是转换的主函数,labels.txt是标签类别。
1)文件组织形式如下:
- *_annotated 存放原图和已经生成的对应的JSON文件
- 将labelme工程文件下的labelme2voc.py复制过来
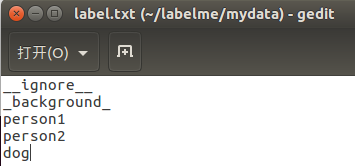
- 自己写一个*.txt文件,内容是分割的标签,最前面加上__ignore__和_background_


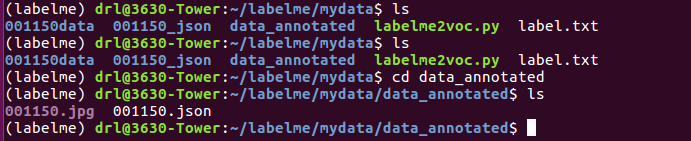
2) 转换为VOC数据格式
讯享网#终端输入 ./labelme2voc.py [图像路径] ·[voc文件夹名称] --labels [label list] #比如 ./labelme2voc.py data_annotated data_annotated_voc --labels label.txt
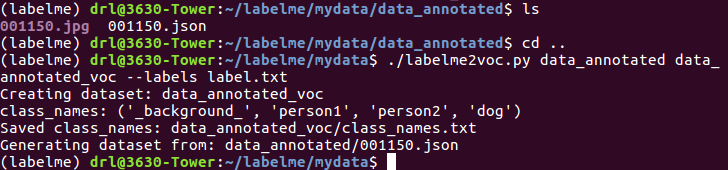
在当前目录下自动生成data_annotated_voc文件夹(转换前确保不要有重名文件夹,否则会报错)

data_annotated_voc文件夹内容:
 转换为COCO数据格式,同样的套路:
转换为COCO数据格式,同样的套路:
./labelme2coco.py data_annotated data_annotated_coco --labels label.txt 九、实现labelme批量json_to_dataset方法
labelme可以帮助我们快速地实现Mask R-CNN中数据集json文件的生成,然而还需要我们进一步地将json转成dataset,可以直接在终端输入 labelme_json_to_dataset 001150.json实现,但是这个过程需要我们一个一个json文件地去生成,效率很慢。
1)找到json_to_dataset.py文件,该文件位于从github下载的labelme文件夹下的labelme/labelme/cli/json_to_dataset.py
 这里面提供将json转成dataset的代码,所以我们只需要在好这个基础上更改即可。
这里面提供将json转成dataset的代码,所以我们只需要在好这个基础上更改即可。
2) 代码实现
复制json_to_dataset.py,代码更改为:
讯享网import argparse import json import os import os.path as osp import warnings import PIL.Image import yaml from labelme import utils import base64 def main(): warnings.warn("This script is aimed to demonstrate how to convert the\n" "JSON file to a single image dataset, and not to handle\n" "multiple JSON files to generate a real-use dataset.") parser = argparse.ArgumentParser() parser.add_argument('json_file') parser.add_argument('-o', '--out', default=None) args = parser.parse_args() json_file = args.json_file if args.out is None: out_dir = osp.basename(json_file).replace('.', '_') out_dir = osp.join(osp.dirname(json_file), out_dir) else: out_dir = args.out if not osp.exists(out_dir): os.mkdir(out_dir) count = os.listdir(json_file) for i in range(0, len(count)): path = os.path.join(json_file, count[i]) if os.path.isfile(path): data = json.load(open(path)) if data['imageData']: imageData = data['imageData'] else: imagePath = os.path.join(os.path.dirname(path), data['imagePath']) with open(imagePath, 'rb') as f: imageData = f.read() imageData = base64.b64encode(imageData).decode('utf-8') img = utils.img_b64_to_arr(imageData) label_name_to_value = {'_background_': 0} for shape in data['shapes']: label_name = shape['label'] if label_name in label_name_to_value: label_value = label_name_to_value[label_name] else: label_value = len(label_name_to_value) label_name_to_value[label_name] = label_value # label_values must be dense label_values, label_names = [], [] for ln, lv in sorted(label_name_to_value.items(), key=lambda x: x[1]): label_values.append(lv) label_names.append(ln) assert label_values == list(range(len(label_values))) lbl = utils.shapes_to_label(img.shape, data['shapes'], label_name_to_value) captions = ['{}: {}'.format(lv, ln) for ln, lv in label_name_to_value.items()] lbl_viz = utils.draw_label(lbl, img, captions) out_dir = osp.basename(count[i]).replace('.', '_') out_dir = osp.join(osp.dirname(count[i]), out_dir) if not osp.exists(out_dir): os.mkdir(out_dir) PIL.Image.fromarray(img).save(osp.join(out_dir, 'img.png')) #PIL.Image.fromarray(lbl).save(osp.join(out_dir, 'label.png')) utils.lblsave(osp.join(out_dir, 'label.png'), lbl) PIL.Image.fromarray(lbl_viz).save(osp.join(out_dir, 'label_viz.png')) with open(osp.join(out_dir, 'label_names.txt'), 'w') as f: for lbl_name in label_names: f.write(lbl_name + '\n') warnings.warn('info.yaml is being replaced by label_names.txt') info = dict(label_names=label_names) with open(osp.join(out_dir, 'info.yaml'), 'w') as f: yaml.safe_dump(info, f, default_flow_style=False) print('Saved to: %s' % out_dir) if __name__ == '__main__': main()
然后另存为json_to_dataset_mine.py文件,该文件仍然位于labelme/labelme/cli/json_to_dataset_mine.py
3) 批量生成json的dataset
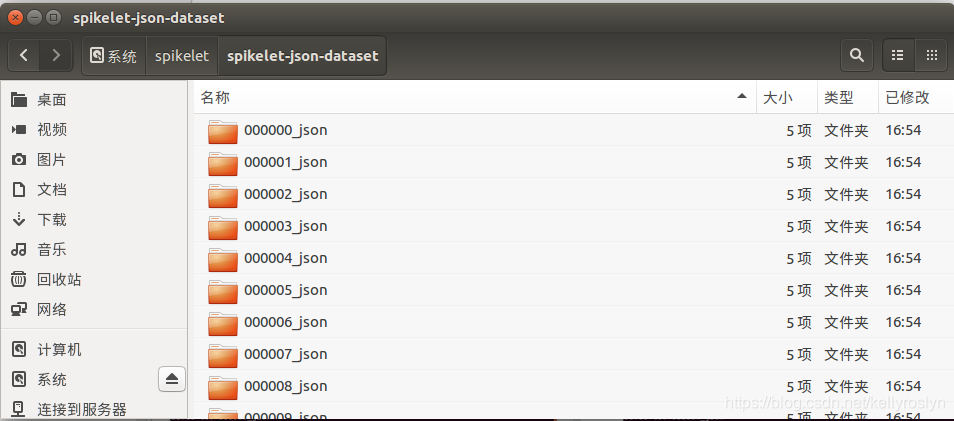
首先我的原图是存放在spikelet-image文件夹下,json文件存放在Instance-Annotations文件夹下,在执行批量json_to_dataset_mine.py文件之前,先在spikelet文件夹下新建一个用于存放生成的dataset的文件夹,命名为:spikelet-json-dataset
 然后在json文件所在文件夹
然后在json文件所在文件夹spikelet-json-dataset下右键打开终端,并激活labelme虚拟环境:
source activate labelme python /home/drl/labelme/labelme/cli/json_to_dataset_mine.py /media/drl/系统/spikelet/Instance-Annotations  然后看
然后看spikelet-json-dataset文件夹下生成了和每一个json文件对应的dataset文件。

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/18315.html