
<p>本文节选自林子雨编著《Spark编程基础(Scala版)》(教材官网:http://dblab.xmu.edu.cn/post/spark/)</p> 讯享网
Spark Streaming是用来进行流计算的组件,可以把Kafka(或Flume)作为数据源,让Kafka(或Flume)产生数据发送给Spark Streaming应用程序,Spark Streaming应用程序再对接收到的数据进行实时处理,从而完成一个典型的流计算过程。这里仅以Kafka为例进行介绍。这里使用的软件版本是:kafka_2.12-2.6.0,Spark3.2.0(Scala版本是2.12.15)。
Kafka是一种高吞吐量的分布式发布订阅消息系统,为了更好地理解和使用Kafka,这里介绍一下Kafka的相关概念:
(1)Broker:Kafka集群包含一个或多个服务器,这些服务器被称为Broker。
(2)Topic:每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个Broker上,但用户只需指定消息的Topic,即可生产或消费数据,而不必关心数据存于何处。
(3)Partition:是物理上的概念,每个Topic包含一个或多个Partition。
(4)Producer:负责发布消息到Kafka Broker。
(5)Consumer:消息消费者,向Kafka Broker读取消息的客户端。
(6)Consumer Group:每个Consumer属于一个特定的Consumer Group,可为每个Consumer指定Group Name,若不指定Group Name,则属于默认的Group。
访问Kafka官网下载页面(https://kafka.apache.org/downloads),下载Kafka稳定版本kafka_2.12-2.6.0.tgz。为了让Spark Streaming应用程序能够顺利使用Kafka数据源,在下载Kafka安装文件的时候要注意,Kafka版本号一定要和自己电脑上已经安装的Scala版本号一致才可以。本教材安装的Spark版本号是3.2.0,Scala版本号是2.12,所以,一定要选择Kafka版本号是2.12开头的。例如,到Kafka官网中,可以下载安装文件kafka_2.12-2.6..0.tgz,前面的2.12就是支持的Scala版本号,后面的2.6.0是Kafka自身的版本号。假设下载后的文件被放在“~/Downloads”目录下。执行如下命令完成Kafka的安装:
讯享网
首先需要启动Kafka。请登录Linux系统(本教材统一使用hadoop用户登录),打开一个终端,输入下面命令启动Zookeeper服务:
讯享网
这样,Kafka就会在后台运行,即使关闭了这个终端,Kafka也会一直在后台运行。不过,采用这种方式时,有时候我们往往就忘记了还有Kafka在后台运行,所以,建议暂时不要用这种命令形式。
再打开第三个终端,然后输入下面命令创建一个自定义名称为“wordsender”的Topic:
讯享网
然后,可以执行如下命令,查看名称为“wordsender”的Topic是否已经成功创建:
再新开一个终端(记作“监控输入终端”),执行如下命令监控Kafka收到的文本:
讯享网
到这里,与Kafka相关的准备工作就顺利结束了。注意,所有这些终端窗口都不要关闭,要继续留着后面使用。
Kafka和Flume等高级输入源,需要依赖独立的库(jar文件),因此,需要为Spark添加相关jar包。访问MVNREPOSITORY官网(http://mvnrepository.com),下载spark-streaming-kafka-0-10_2.12-3.2.0.jar和spark-token-provider-kafka-0-10_2.12-3.2.0.jar文件,其中,2.12表示Scala的版本号,3.2.0表示Spark版本号。然后,把这两个文件复制到Spark目录的jars目录下(即“/usr/local/spark/jars”目录)。此外,还需要把“/usr/local/kafka/libs”目录下的kafka-clients-2.6.0.jar文件复制到Spark目录的jars目录下。
spark-streaming-kafka-0-10_2.12-3.2.0.jar的下载页面:https://mvnrepository.com/artifact/org.apache.spark/spark-streaming-kafka-0-10_2.12/3.2.0
spark-token-provider-kafka-0-10_2.12-3.2.0.jar的下载页面:https://mvnrepository.com/artifact/org.apache.spark/spark-token-provider-kafka-0-10_2.12/3.2.0
进入下载页面以后,如下图所示,点击红色箭头指向的“jar”,就可以下载JAR包了。
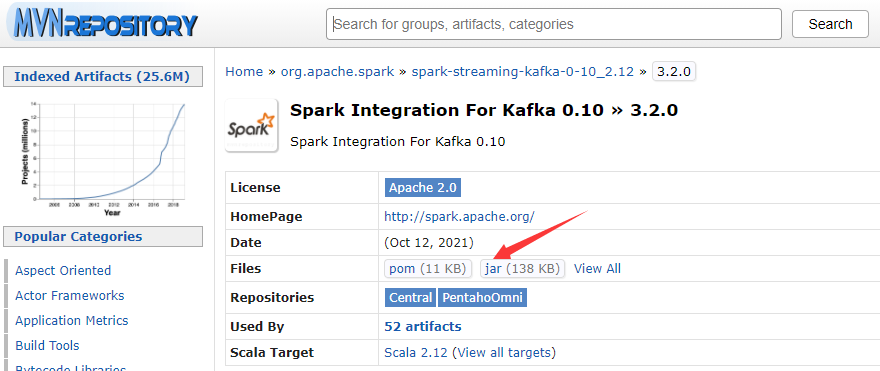
讯享网

请新打开一个终端,然后,执行如下命令创建代码目录和代码文件:
这里使用vim编辑器新建了KafkaWordProducer.scala,它是用来产生一系列字符串的程序,会产生随机的整数序列,每个整数被当作一个单词,提供给KafkaWordCount程序去进行词频统计。请在KafkaWordProducer.scala中输入以下代码:
讯享网
在“/usr/local/spark/mycode/kafka/src/main/scala”目录下创建代码文件KafkaWordCount.scala,用于单词词频统计,它会把KafkaWordProducer发送过来的单词进行词频统计,代码内容如下:
在KafkaWordCount.scala代码中,ssc.checkpoint()用于创建检查点,实现容错功能。在Spark Streaming中,如果是文件流类型的数据源,Spark自身的容错机制可以保证数据不会发生丢失。但是,对于Flume和Kafka等数据源,当数据源源不断到达时,会首先被放入到缓存中,尚未被处理,可能会发生丢失。为了避免系统失败时发生数据丢失,可以通过ssc.checkpoint()创建检查点。但是,需要注意的是,检查点之后的数据仍然可能发生丢失,如果要保证数据不发生丢失,可以开启Spark Streaming的预写式日志(WAL:Write Ahead Logs)功能,当采用预写式日志以后,接收数据的正确性只在数据被预写到日志以后Receiver才会确认,这样,当系统发生失败导致缓存中的数据丢失时,就可以从日志中恢复丢失的数据。预写式日志需要额外的开销,因此,在默认情况下,Spark Streaming的预写式日志功能是关闭的,如果要开启该功能,需要设置SparkConf的属性"spark.streaming.receiver.writeAheadLog.enable"为"true"。ssc.checkpoint()在创建检查点的同时,系统也把检查点的文件写入路径“file:///usr/local/spark/mycode/kafka/checkpoint”作为预写式日志的存放路径。
经过前面的步骤,现在在“/usr/local/spark/mycode/kafka/src/main/scala”目录下,就有了如下3个代码文件:
KafkaWordProducer.scala
KafkaWordCount.scala
StreamingExamples.scala
然后,请执行下面命令新建一个simple.sbt文件:
讯享网
在simple.sbt中输入以下代码:
然后执行下面命令,进行编译打包:
讯享网
打包成功后,就可以执行程序测试效果了。
启动Hadoop成功以后,就可以测试刚才生成的词频统计程序了。
要注意,之前已经启动了Zookeeper服务和Kafka服务,因为之前那些终端窗口都没有关闭,所以,这些服务一直都在运行。如果不小心关闭了之前的终端窗口,那就参照前面的内容,再次启动Zookeeper服务,启动Kafka服务。
然后,新打开一个终端,执行如下命令,运行“KafkaWordProducer”程序,生成一些单词(是一堆整数形式的单词):
讯享网
注意,上面命令中,“localhost:9092 wordsender 3 5”是提供给KafkaWordProducer程序的4个输入参数,第1个参数“localhost:9092”是Kafka的Broker的地址,第2个参数“wordsender”是Topic的名称,我们在KafkaWordCount.scala代码中已经把Topic名称写死掉,所以,KafkaWordCount程序只能接收名称为“wordsender”的Topic。第3个参数“3”表示每秒发送3条消息,第4个参数“5”表示每条消息包含5个单词(实际上就是5个整数)。
执行上面命令后,屏幕上会不断滚动出现类似如下的新单词:
3 3 6 3 4
9 4 0 8 1
0 3 3 9 3
0 8 4 0 9
8 7 2 9 5
……
不要关闭这个终端窗口,让它一直不断发送单词。然后,再打开一个终端,执行下面命令,运行KafkaWordCount程序,执行词频统计:
运行上面命令以后,就启动了词频统计功能,屏幕上就会显示如下类似信息:
(4,134)
(8,117)
(7,144)
(5,128)
(6,137)
(0,158)
(2,128)
(9,134)
(3,139)
(1,131)
……
这些信息说明,Spark Streaming程序顺利接收到了Kafka发来的单词信息,并进行词频统计得到结果。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/167211.html