
DINO学习笔记
DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection
Abstract
我们提出了DINO(DETR with Improved deNoising anchOr boxes),一种先进的端到端对象检测器。DINO采用对比的去噪训练方法、混合查询选择方法进行锚点初始化和两次前瞻的盒子预测方法,在性能和效率上都优于以往的类detrr模型。DINO在具有ResNet-50骨干和多尺度特征的COCO上实现了12 epochs 49.4AP和24 epochs 51.3AP,与之前最好的类detr模型DN-DETR相比,分别获得了+6.0AP和+2.7AP的显著改进。DINO在模型大小和数据大小上都具有很好的伸缩性。在没有附加功能的情况下,在使用SwinL主干的Objects365数据集上进行预训练后,DINO在COCO val2017 (63.2AP)和test-dev (63.3AP)上都获得了**结果。与排行榜上的其他模型相比,DINO显著减小了模型大小和预训练数据大小,同时获得了更好的结果。我们的代码可以在https: //github.com/IDEACVR/DINO上获得。
关键词:目标检测;检测变压器;端到端检测器
1 Introduction
目标检测是计算机视觉的一项基本任务。经典的基于卷积的目标检测算法 [31,35,19,2,12]已经取得了显著的进展。尽管这样的算法通常包括手工设计的组件,如锚生成和非最大抑制(NMS),但它们产生了**的检测模型,如DyHead [7], Swin[23]和SwinV2[22]与HTC++[4],这在COCO test-dev 排行榜[1]中得到了证明。
与经典的检测算法相比,DETR[3]是一种新的基于变压器的检测算法。它消除了手工设计组件的需求,并实现了与优化的经典检测器(如Faster RCNN[31])相当的性能。与以往的检测器不同,DETR将对象检测建模为集合预测任务,并通过二部图匹配分配标签。它利用可学习查询来探测对象的存在性,并结合来自图像特征映射的特征,其行为类似于软ROI池[21]。
DETR算法虽然具有良好的性能,但训练收敛速度慢,查询意义不明确。针对这一问题,人们提出了许多方法,如引入变形注意[41],解耦位置和内容信息[25],提供空间先验[11,39,37]等。最近,DAB-DETR[21]提出将DETR查询定义为动态锚框(DAB),弥合了传统基于锚点的检测器与类der检测器之间的差距。DN- detr[17]通过引入去噪(DN)技术,进一步解决了二部匹配的不稳定性问题。DAB和DN的结合使得类detr模型在训练效率和推理性能上与经典检测器具有竞争力。
目前最好的检测模型是基于改进的经典检测器,如DyHead[8]和HTC[4]。例如,SwinV2[22]中呈现的**结果是使用HTC++[4,23]框架进行训练的。造成这种现象的主要原因有两个:1)以前的类detr模型不如改进的经典探测器。大多数经典的探测器都得到了很好的研究和高度优化,与新开发的类detr模型相比,性能更好。例如,目前表现最好的detr类模型仍然在COCO上低于50 AP。2)类detr模型的可扩展性研究还不够深入。目前还没有关于detr类模型在扩展到大型骨干和大规模数据集时的表现的报告结果。本文旨在解决这两个问题。
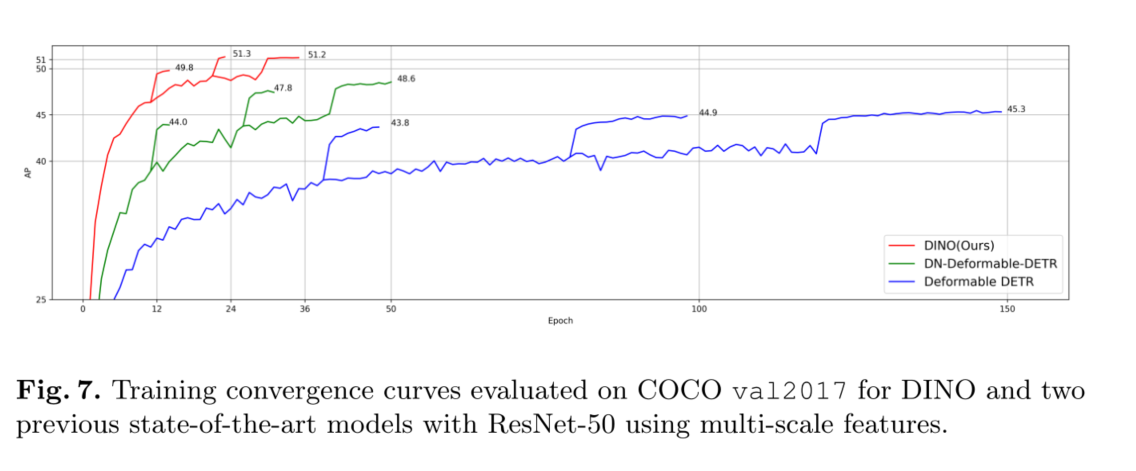
具体来说,通过改进去噪训练、查询初始化和盒预测,我们设计了一个新的基于DN-DETR[17]、DAB-DETR[21]和变形DETR[41]的类DETR模型。我们将我们的模型命名为DINO(带改进去噪锚盒的DETR)。如图1所示,通过对COCO的比较,可以看出DINO的性能优越。特别是,DINO展示了良好的可扩展性,在COCO测试开发排行榜[1]上创下了63.3 AP的新记录
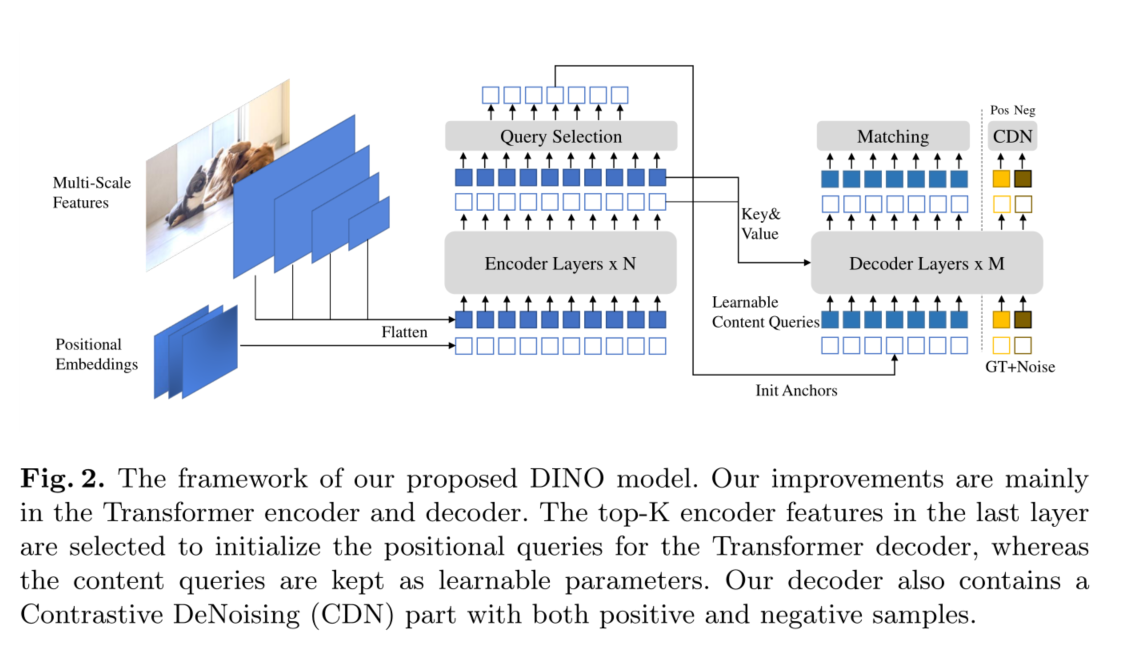
作为一个类detr模型,DINO包含一个主干、一个多层Transformer编码器、一个多层Transformer解码器和多个预测头。根据DAB-DETR[21],我们将解码器中的查询制定为动态锚框,并在解码器层中逐步改进它们。在DN-DETR[17]之后,我们在Transformer解码器层中添加了ground truth标签和带噪声的框,以帮助稳定训练过程中的二部匹配。为了提高计算效率,我们还采用了变形注意[41]。此外,我们提出了以下三种新方法。首先,为了改进一对一匹配,我们提出了一种对比去噪训练,即同时添加相同基础真理的正样本和负样本。将两个不同的噪声添加到同一个地面真值框后,我们将较小噪声的框标记为正噪声,另一个标记为负噪声。对比去噪训练有助于模型避免相同目标的重复输出。其次,查询的动态锚盒公式将detr类模型与经典的两阶段模型联系起来。因此,我们提出了一种混合查询选择方法,它有助于更好地初始化查询。我们从编码器的输出中选择初始锚框作为位置查询,类似于[41,39]。然而,我们让内容查询像以前一样是可学习的,鼓励第一个解码器层专注于空间优先级。第三,为了利用后期层的盒子信息来优化邻近早期层的参数,我们提出了一种新的前馈两次方案,利用后期层的梯度来修正更新后的参数。
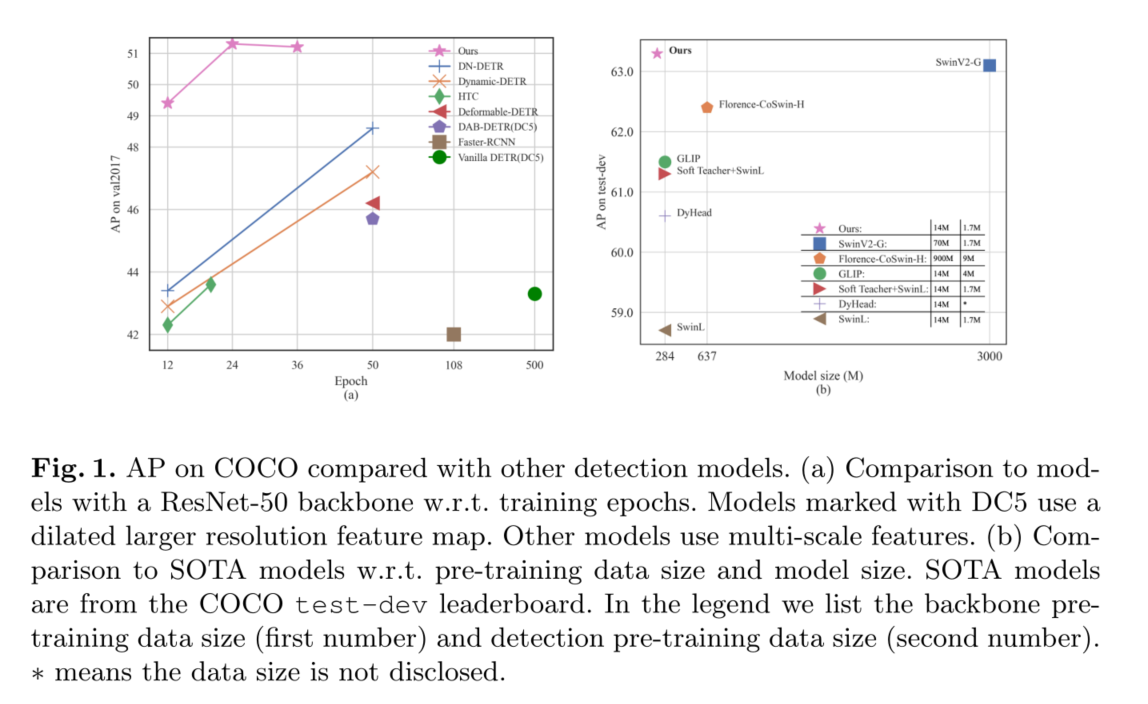
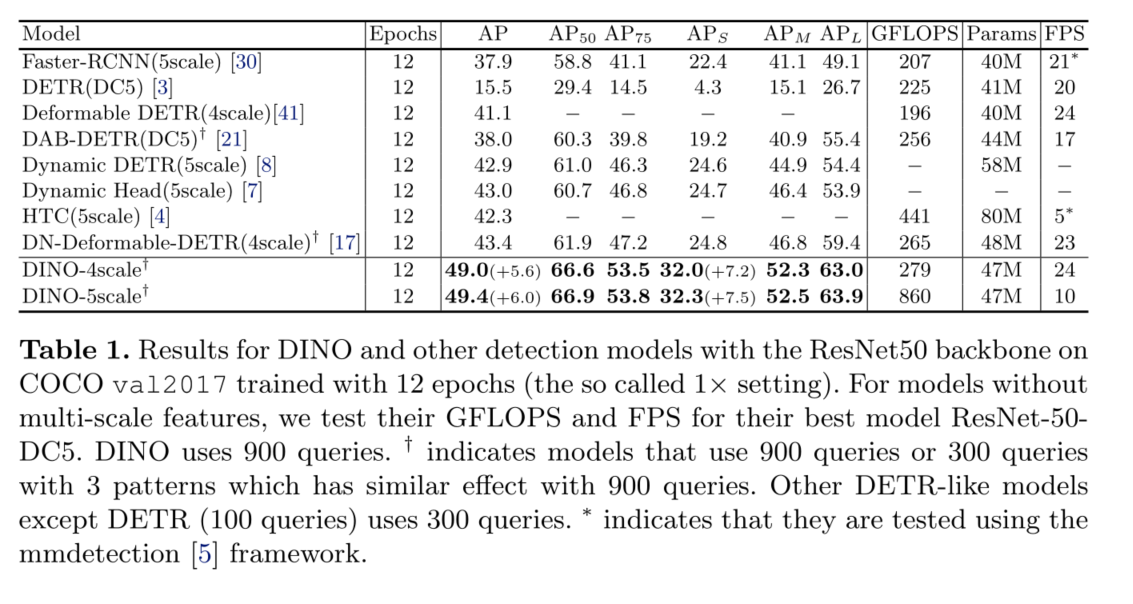
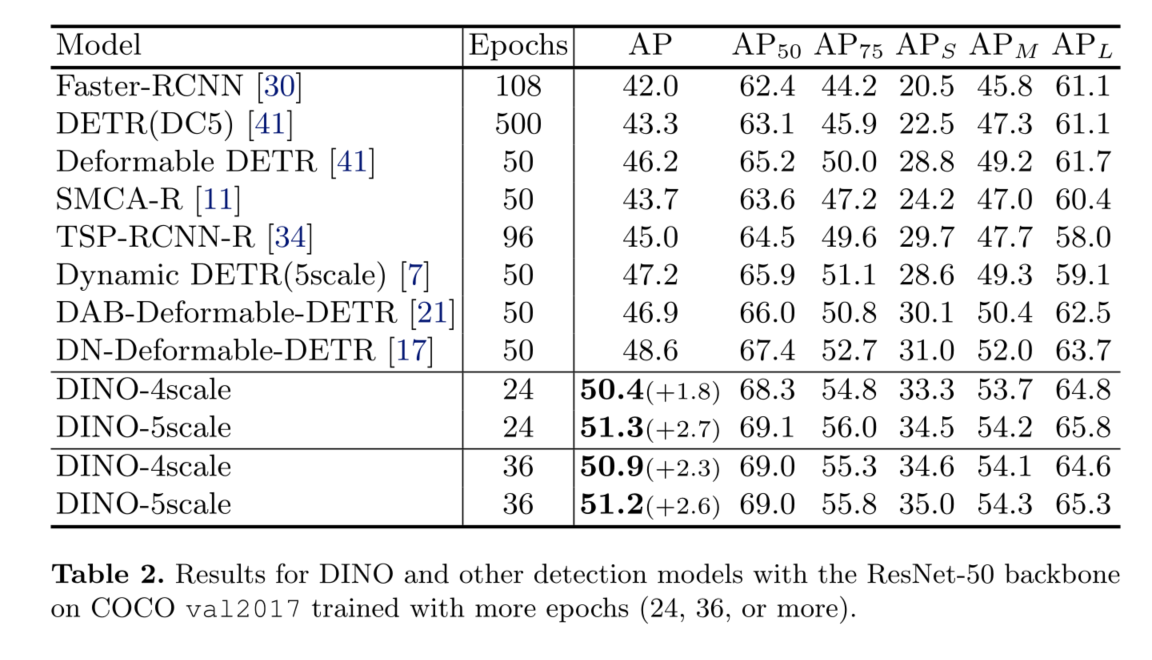
我们通过COCO[20]检测基准上的大量实验验证了DINO的有效性。如图1所示,在ResNet-50和多尺度特征下,DINO在12个epoch实现49.4AP,在24个epoch实现51.3AP,与之前最好的der -like模型相比,分别显著提高了+6.0AP和+2.7AP。此外,DINO在模型大小和数据大小上都具有很好的伸缩性。在使用SwinL[23]骨干对Objects365[33]数据集进行预训练后,DINO在COCO val2017 (63.2AP)和test-dev (63.3AP)基准测试上都取得了**结果,如表3所示。与排行榜[1]上的其他模型相比,我们将模型大小减少到SwinV2-G[22]的1/15。与Florence[40]相比,我们减少了预训练检测数据集为1/5,骨干预训练数据集为1/60,同时获得更好的结果。
我们将我们的贡献总结如下。
1)我们设计了一种新的端到端类detr对象检测器,该检测器采用了多种新技术,包括对比DN训练、mixed query selection和对DINO模型的不同部分进行两次look forward。
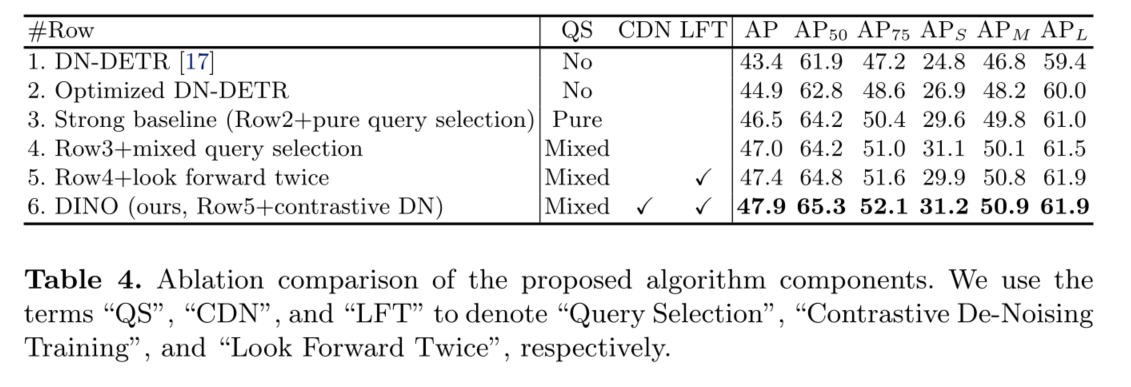
2)我们进行了密集的消融研究,以验证DINO中不同设计选择的有效性。结果,在ResNet-50和多尺度特征下,DINO在12个epoch实现49.4AP,在24个epoch实现51.3AP,显著优于之前最好的detr类模型。特别是经过12期训练的DINO在小物体上表现出更显著的改进,提高了+7.5AP。
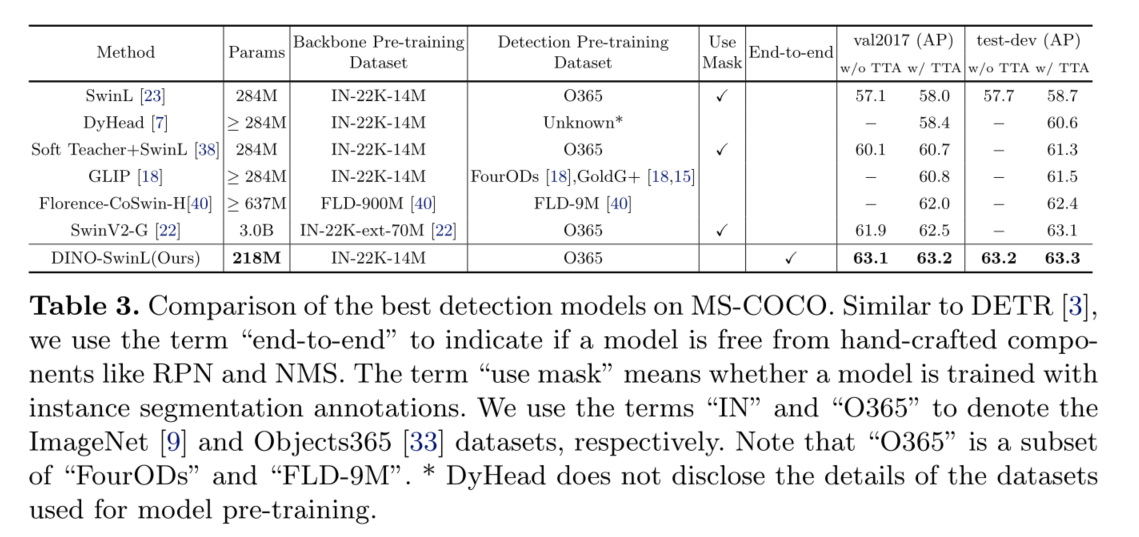
3)我们证明,在没有 bells and whistles的情况下,DINO可以在公共基准上实现**性能。在使用SwinL[23]骨干对Objects365[33]数据集进行预训练后,DINO在COCO val2017 (63.2AP)和test-dev (63.3AP)基准测试上都取得了**结果。据我们所知,这是第一次端到端Transformer检测器在COCO排行榜[1]上优于最先进的(SOTA)模型。
2 Related Work
2.1 Classical Object Detectors
早期基于卷积的对象检测器是两级或一级模型,基于手工制作的锚或参考点。两阶段模型[30,13]通常使用区域建议网络(region proposal network, RPN)[30]提出潜在盒,然后在第二阶段对潜在盒进行细化。一级模型,如YOLO v2[28]和YOLO v3[29]直接输出相对于预定义锚的偏移量。最近,一些基于卷积的模型,如HTC++[4]和Dyhead[7]在COCO 2017数据集[20]上取得了**性能。然而,基于卷积的模型的性能取决于它们生成锚点的方式。此外,它们需要手工设计的组件(如NMS)来删除重复的框,因此不能执行端到端优化。
2.2 DETR and Its Variants
Carion等人[3]提出了一种名为DETR (DEtection TRansformer)的基于变压器的端到端对象检测器,而不使用锚点设计和NMS等手工设计的组件。许多后续论文试图解决解码器交叉注意引起的DETR训练收敛速度慢的问题。例如,Sun et al.[34]设计了一个仅编码器的DETR,而不使用解码器。Dai等人[7]提出了一种动态解码器,可以从多个特征层次关注重要区域。
另一个工作方向是深入理解DETR中的解码器查询。许多论文从不同的角度将查询与空间位置联系起来。Deformable DETR[41]预测二维锚点,并设计一个Deformable 注意模块,只关注参考点周围的某些采样点。Efficient DETR[39]从编码器的密集预测中选择前K位,以增强解码器查询。DAB-DETR[21]进一步扩展了2D锚点到4D锚框坐标,以表示查询并动态更新每个解码器层中的框。最近,DN-DETR[17]引入了去噪训练方法来加速DETR训练。它将噪声添加的ground-truth标签和盒子输入到解码器中,并训练模型重建原始的标签和盒子。本文的DINO算法是基于DAB-DETR和DN-DETR算法的,为了提高计算效率,采用了Deformable 注意算法。
2.3 Large-scale Pre-training for Object Detection
大规模的预培训对自然语言处理[10]和计算机视觉[27]都有很大的影响。目前最好的性能检测器大多是通过在大规模数据上预先训练的大型骨干来实现的。例如,Swin V2[22]将其骨干尺寸扩展到30亿参数,并使用70M私人收集的图像预训练模型。Florence[40]首先用900M私有策划的图像-文本对预训练它的主干,然后用带有注释或伪框的9M图像预训练它的检测器。相比之下,DINO只使用公开的SwinL[23]主干和公共数据集Objects365 [33] (1.7M带注释的图像)来实现SOTA结果。
3 DINO: DETR with Improved DeNoising Anchor Boxes
3.1 Preliminaries
通过对Conditional DETR[25]和DAB-DETR[21]的研究,可以清楚地看到,在DETR[3]中的查询由两个部分组成:位置部分和内容部分,本文将其称为位置查询和内容查询。DAB-DETR[21]显式地将DETR中的每个位置查询定义为4D锚框(x, y, w, h),其中x和y是框的中心坐标,w和h对应其宽度和高度。这种显式的锚框公式使得在解码器中一层一层地动态优化锚框变得很容易。
DN- detr[17]引入了一种去噪(DN)训练方法来加速类detr模型的训练收敛。结果表明,二部匹配的不稳定性是导致DETR算法收敛速度慢的主要原因。为了缓解这个问题,DN-DETR建议将有噪声的ground-truth(GT)标签和盒子输入到Transformer解码器中,并训练模型重建ground-truth的标签和盒子。增加噪声(∆x,∆y,∆w,∆h)受以下因素的约束:|∆x| < λw/ 2, |∆y| < λh /2, |∆w| < λw, |∆y| < λh,其中(x, y, w, h)表示GT box 和λ(DN-DETR论文[17]使用λ1和λ2表示中心移动和盒缩放的噪声尺度,但设λ1 = λ2。在本文中,为了简单起见,我们用λ来代替λ1和λ2。)是控制噪声尺度的超参数。由于DN-DETR跟随DAB-DETR将解码器查询视为锚点,噪声GT框可以被视为带有GT框的特殊锚点,因为λ通常很小。除了原始的DETR查询之外,DN-DETR还添加了一个DN部分,将有噪声的GT标签和框输入到解码器中,以提供辅助DN丢失。DN损失有效地稳定和加速了DETR训练,并可以插入任何类der模型。
Deformable DETR[41]是另一个加速DETR收敛的早期工作。为了计算Deformable 注意,引入了参考点的概念,使Deformable 注意可以关注参考点周围的一小部分关键采样点。参考点的概念使得开发几种技术来进一步提高DETR性能成为可能。第一种技术是查询选择(在Deformable DETR论文中也被称为“两阶段”。由于“两级”的名称可能会使读者与经典的检测器混淆,我们在本文中使用术语“查询选择”来代替。),它从编码器中选择特征和参考框作为直接输入到解码器。第二种技术是迭代边界盒优化,在两个解码器层之间采用精心的梯度分离设计。在我们的论文中,我们称这种渐变脱离技术为“look forward once”。
在das - detr和DN- detr之后,DINO将位置查询制定为动态锚盒,并使用额外的DN损失进行训练。注意,DN-DETR还采用了Deformable DETR的一些技术来实现更好的性能,包括它的变形注意机制和“look forward once”实现在层参数更新。DINO进一步采用了Deformable DETR的查询选择思想,以更好地初始化位置查询。在这个强基线的基础上,DINO引入了三种新的方法来进一步提高检测性能,将分别在第3.3节、第3.4节和第3.5节进行描述
3.2 Model Overview
作为一个类似detr的模型,DINO是一个端到端体系结构,它包含一个主干、一个多层Transformer[36]编码器、一个多层Transformer解码器和多个预测头。整个管道如图2所示。给定一幅图像,我们用ResNet[14]或Swin Transformer[23]等骨干提取多尺度特征,然后将它们输入到带有相应位置嵌入的Transformer编码器中。在使用编码器层进行特征增强之后,我们提出了一种新的混合查询选择策略,将锚作为解码器的位置查询初始化。注意,此策略不初始化内容查询,而是使它们可以学习。关于混合查询选择的更多细节见第3.4节。使用初始化的锚和可学习的内容查询,我们使用Deformable 的注意力[41]来组合编码器输出的特征,并逐层更新查询。最后的输出由精细化的锚框和精细化的内容特征预测的分类结果组成。如同在DN- detr[17]中,我们有一个额外的DN分支来执行去噪训练。在标准DN方法之外,我们提出了一种考虑硬负样本的新的对比去噪训练方法,这将在第3.3节中介绍。为了充分利用后期层的细化框信息来帮助优化其相邻早期层的参数,提出了一种新的前向两次方法来在相邻层之间传递梯度,该方法将在第3.5节中描述。
3.3 Contrastive DeNoising Training
DN-DETR在稳定训练和加速收敛方面非常有效。在DN查询的帮助下,它学会基于附近有GT框的锚进行预测。但是,对于附近没有对象的锚,它缺乏预测“无对象”的能力。为了解决这个问题,我们提出了一种对比去噪(CDN)方法来拒绝无用的锚。

Implementation
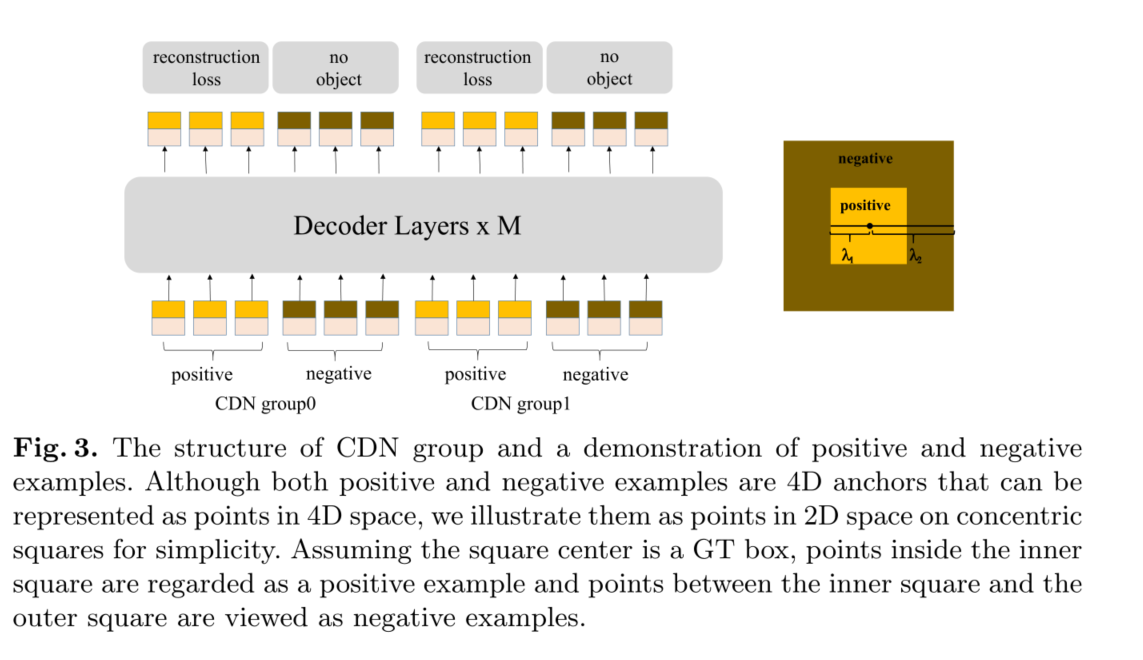
DN-DETR具有一个超参数λ来控制噪声尺度。生成的噪声不大于λ,因为DN-DETR希望模型从中等噪声的查询中重建ground truth (GT)。在我们的方法中,我们有两个超参数λ1和λ2,其中λ1 < λ2。如图3中的同心方格所示,我们生成了两种类型的CDN查询:正查询和负查询。内方格内的正查询的噪声尺度小于λ1,并被期望重构其对应的地面真值框。内外方格间否定查询的噪声尺度大于λ1,小于λ2。他们被期望预测“没有物体”。我们通常采用小λ2,因为硬阴性样品更接近GT盒更有助于提高性能。如图3所示,每个CDN组都有一组正面查询和负面查询。如果一幅图像有n个GT框,一个CDN组将有2 × n个查询,每个GT框产生一个正面查询和一个负面查询。与DN-DETR相似,我们也使用多个CDN组来提高方法的有效性。盒回归的重建损失为l1和GIOU损失,分类的病灶损失为[19]。将阴性样本分类为背景的损失也是焦点损失。
Analysis
我们的方法之所以有效,是因为它可以抑制混淆,并为预测边界框选择高质量的锚(查询)。当多个锚靠近一个对象时,就会出现混淆。在这种情况下,模型很难决定选择哪个锚。这种混淆可能会导致两个问题。第一个是重复预测。虽然类detr模型可以借助基于集合的损失和自我注意[3]抑制重复盒子,但这种能力是有限的。如图8的左图所示,当用DN查询替换我们的CDN查询时,箭头所指的男孩有3个重复的预测。通过CDN查询,我们的模型可以区分锚点之间的细微差别,避免重复预测,如图8右图所示。第二个问题是,可能会选择一个远离GT箱的多余锚。尽管去噪训练[17]改进了模型选择附近锚点的能力,但CDN通过教会模型拒绝更远的锚点进一步提高了这一能力。

Effectiveness
为了证明CDN的有效性,我们定义了一个称为平均Top-K距离(ATD(k))的度量,并使用它来评估在匹配部分锚距目标GT盒的距离。在DETR中,每个锚点对应于一个可能与GT盒或背景匹配的预测。我们这里只考虑与GT箱配套的。假设我们有N个GT个边界框 b 0 , b 2 , … , b N − 1 b_0, b_2,…, b_{N−1} b0,b2,…,bN−1,其中 b i = ( x i , y i , w i , h i b_i = (x_i, y_i, w_i, h_i bi=(xi,yi,wi,hi)。为每一个bi,我们都可以找到它对应的锚点,并将其表示为 a i = ( x i ′ , y i ′ , w i ′ , h i ′ ) a_i = (x^{'}_i, y^{'}_i, w^{'}_i, h^{'}_i) ai=(xi′,yi′,wi′,hi′)。 a i a_i ai是解码器的初始锚盒,在匹配时将其在最后一层解码器后的细化盒分配给 b i b_i bi。然后是
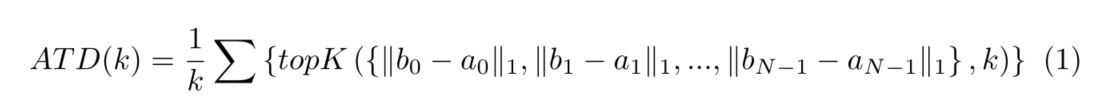
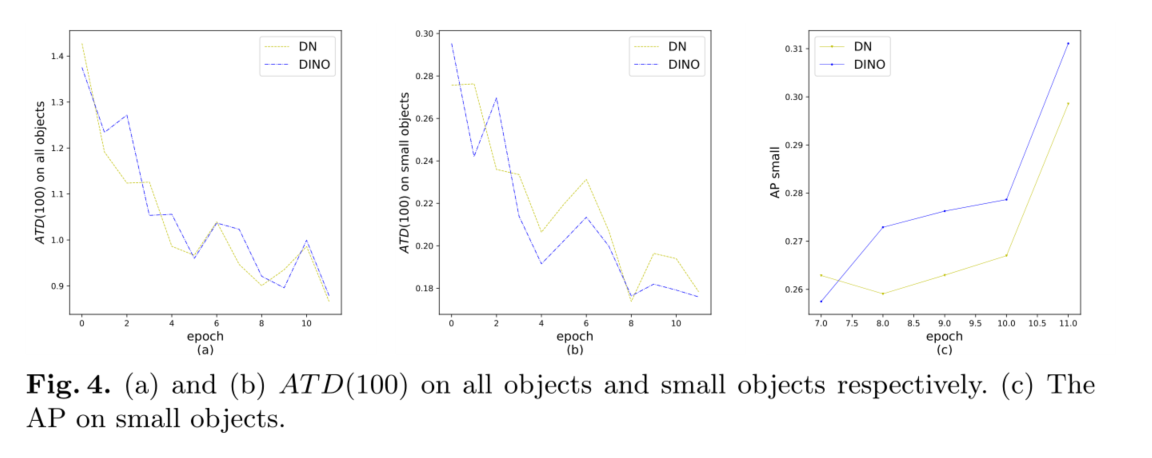
其中 ∥ b i − a i ∥ 1 ∥b_i−a_i∥_1 ∥bi−ai∥1为bi和ai之间的 l 1 l_1 l1距离,topK(x, k)是一个函数,返回x中最大的k个元素的集合。我们选择前k个元素的原因是,当GT箱与更远的锚匹配时,更容易发生混淆问题。如图4的(a)和(b)所示,DN对于总体上选择一个好的锚点是足够好的。然而,CDN为小对象找到了更好的锚。图4 ©显示,在ResNet-50和多尺度特征的12个时代中,CDN查询在小对象上比DN查询提高了+1.3 AP。
3.4 Mixed Query Selection
在DETR[3]和DN-DETR[17]中,解码器查询是静态嵌入,不从单个图像中获取任何编码器特征,如图5 (a)所示。解码器查询直接从训练数据中学习锚点(DN-DETR和DAB-DETR)或位置查询(DETR),并将内容查询设置为全部0向量。Deformable 的DETR[41]学习位置查询和内容查询,这是静态查询初始化的另一个实现。为了进一步提高性能,Deformable DETR[41]有一个查询选择变体(在[41]中称为“two - stage”),它从最后一个编码器层中选择前K个编码器特性作为先验,以增强解码器查询。如图5 (b)所示,位置查询和内容查询都是通过所选特征的线性变换生成的。此外,这些选择的特征被馈送到辅助检测头得到预测盒,用于初始化参考盒。同样,Efficient DETR[39]也会根据每个编码器特征的客观性(类)评分选择排名前K的特征。
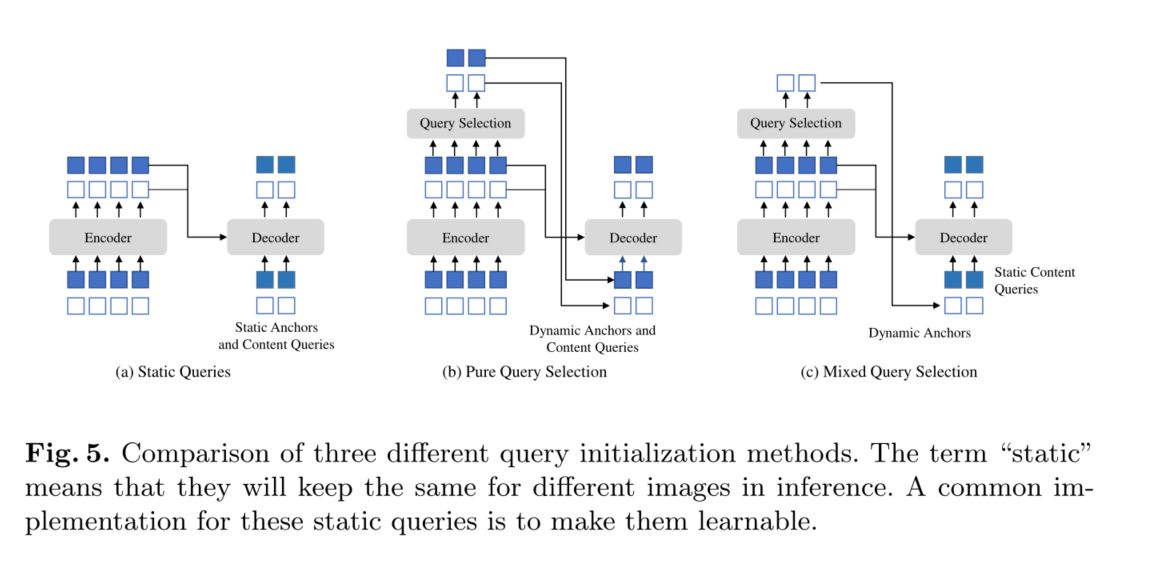
在我们的模型中查询的动态4D锚盒公式使其与解码器位置查询密切相关,可以通过查询选择来改进。我们遵循上述实践,并提出了一种混合查询选择方法。如图5 ©所示,我们只使用与所选top-K特征相关联的位置信息初始化锚框,而将内容查询与以前一样保持静态。注意,Deformable DETR[41]利用top-K特性来增强位置查询和内容查询。由于所选特征是未经进一步细化的初步内容特征,它们可能会对解码器产生歧义和误导。例如,一个选定的特性可能包含多个对象,或者只是对象的一部分。相比之下,我们的混合查询选择方法只使用top-K选择的特征增强位置查询,并保持内容查询和以前一样可学习。它帮助模型使用更好的位置信息,从编码器中汇集更全面的内容特征。
3.5 Look Forward Twice
在这一节中,我们提出了一种新的盒子预测方法。在Deformable DETR[41]中迭代盒优化阻止梯度反向传播来稳定训练。我们将该方法命名为“look forward once”,因为第i层的参数仅基于盒 b i b_i bi的辅助损失进行更新,如图6 (a)所示。但我们推测,来自后一层的改进盒信息可能更有助于修正其邻近早期层的盒预测。因此,我们提出了另一种方法,称为look forward twice 更新box,其中layer-i的参数受layer-i和layer-(i +1)损失的影响,如图6 (b)所示。对于每个预测偏移量 ∆ b i ∆b_i ∆bi,将用它更新box两次,一次更新 b i ′ b^{'}_i bi′,另一次更新 b i + 1 ( p r e d ) b^{(pred)}_{ i+1} bi+1(pred),因此我们将方法命名为向前两次。
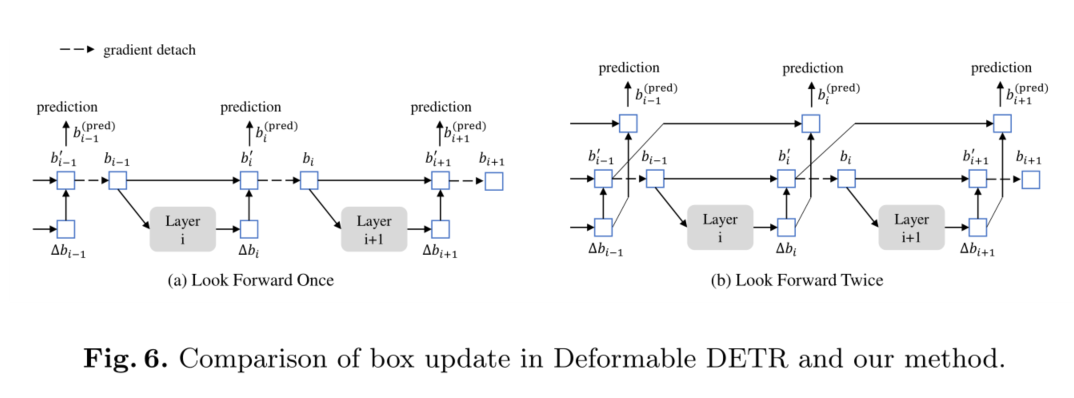
预测箱 b i ( p r e d ) b^{(pred)}_ i bi(pred)的最终精度由两个因素决定:初始箱 b i − 1 b_{i−1} bi−1的质量和箱 ∆ b i ∆b_i ∆bi的预测偏移量。向前看一次方案只优化了后者,因为梯度信息从layer-i分离到layer-(i−1)。相反,我们改善了初始盒bi−1和预测盒偏移∆bi。提高质量的一个简单方法是监督第i层的最终盒子 b i ′ b^{'}_i bi′,并使下一层的输出 ∆ b i + 1 ∆b_{i+1} ∆bi+1。因此,我们用 b i ′ b^{'}_i bi′和 ∆ b i + 1 ∆b_{i+1} ∆bi+1之和作为layer-(i +1)的预测框。
更具体地说,给定第i层的输入框 b i − 1 b_{i−1} bi−1,我们通过以下方法得到最终预测框 b i ( p r e d ) b^{(pred)}_ i bi(pred):
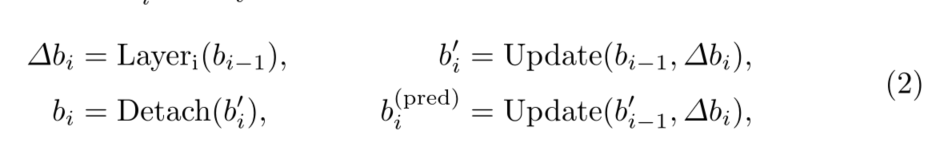
其中 b i ′ b^{'}_i bi′是 b i b_i bi的非分离版本。术语Update(·,·)是一个通过预测框偏移量 ∆ b i ∆b_i ∆bi细化框 b i − 1 b_{i−1} bi−1的函数。我们采用与可变形的DETR[41]相同的方法来处理update框。
4 Experiments
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/16601.html