
主成分分析
Principal Component Analysis PCA
- 一个非监督的机器学习算法
- 主要用于数据的降维
- 通过降维,可以发现更便于人类理解的特征
- 其他应用,可视化,去噪
原理:

讯享网
进行降维,保留特征1

进行降维,保留特征2
上面哪种方案更好?可以看出 保留特征1 的点与点之间的间距更大,拥有更好的可区分度。这种方案比较好
还可以有更好的方案吗?
将点映射到这条直线上


这种方案是不是和原来的更接近,也更有区分度
所以,变成: 如何找到这个让样本间间距最大的轴?
如何定义样本间间距?使用方差(Variance)
V a r ( x ) = 1 m ∑ i = 1 m ( x i − x ‾ ) 2 Var(x) = \frac{1}{m} \sum_{i=1}^m(x_i -\overline{x})^2 Var(x)=m1∑i=1m(xi−x)2
找到一个轴,使得样本空间的所有点映射到这个轴后,方差最大
第一步:将样本的均值归为0 (demean处理)
样本就变成如下图:

将所有样本进行demean处理
我们想要求一个轴的方向 w = (w1,w2),
使得我们所有的样本,映射到w以后,有:
V a r ( X p r r o j e c t ) = 1 m ∑ i = 1 m ( X p r o j e c t i − X ‾ p r o j e c t ) 2 Var(X_{prroject})=\frac{1}{m} \sum_{i=1}^m(X^i_{project}- \overline{X}_{project})^2 Var(Xprroject)=m1∑i=1m(Xprojecti−Xproject)2 最大
因为 X ‾ p r o j e c t \overline{X}_{project} Xproject = 0
所以: V a r ( X p r r o j e c t ) = 1 m ∑ i = 1 m ∣ ∣ X p r o j e c t i ∣ ∣ 2 Var(X_{prroject})=\frac{1}{m} \sum_{i=1}^m ||X^i_{project}||^2 Var(Xprroject)=m1∑i=1m∣∣Xprojecti∣∣2

将一个向量映射到另一个向量上,就是两个向量 ⋅ \cdot ⋅ 点乘 的定义, 就是两个向量的相乘然后乘以两个向量之间的夹角
X i ⋅ w = ∣ ∣ X i ∣ ∣ ⋅ ∣ ∣ w ∣ ∣ ⋅ c o s θ X^i \cdot w = ||X^i|| \cdot ||w|| \cdot cos\theta Xi⋅w=∣∣Xi∣∣⋅∣∣w∣∣⋅cosθ
w w w可以用方向向量来表示就可以,所以可以使其为 w w w=1
X i ⋅ w = ∣ ∣ X i ∣ ∣ ⋅ c o s θ X^i \cdot w = ||X^i|| \cdot cos\theta Xi⋅w=∣∣Xi∣∣⋅cosθ
↓ \downarrow ↓
X i ⋅ w = ∣ ∣ X p r o j e c t i ∣ ∣ X^i \cdot w = ||X^i_{project}|| Xi⋅w=∣∣Xprojecti∣∣
所以 V a r ( X p r r o j e c t ) = 1 m ∑ i = 1 m ∣ ∣ X i ⋅ w ∣ ∣ 2 Var(X_{prroject})=\frac{1}{m} \sum_{i=1}^m ||X^i \cdot w||^2 Var(Xprroject)=m1∑i=1m∣∣Xi⋅w∣∣2 ,
↓ \downarrow ↓
目标: 求 w w w,使得 V a r ( X p r r o j e c t ) = 1 m ∑ i = 1 m ( X i ⋅ w ) 2 Var(X_{prroject})=\frac{1}{m} \sum_{i=1}^m (X^i \cdot w)^2 Var(Xprroject)=m1∑i=1m(Xi⋅w)2 最大
V a r ( X p r r o j e c t ) = 1 m ∑ i = 1 m ( X 1 i w 1 + X 2 i w 2 + . . . + X n i w n ) 2 Var(X_{prroject})=\frac{1}{m} \sum_{i=1}^m (X^i_1w_1+X^i_2w_2+...+X^i_nw_n)^2 Var(Xprroject)=m1∑i=1m(X1iw1+X2iw2+...+Xniwn)2
V a r ( X p r r o j e c t ) = 1 m ∑ i = 1 m ( ∑ j = 1 n X j i w j ) 2 Var(X_{prroject})=\frac{1}{m} \sum_{i=1}^m (\sum_{j=1}^n X^i_jw_j)^2 Var(Xprroject)=m1∑i=1m(∑j=1nXjiwj)2
一个目标函数的最优化问题,使用梯度上升法解决
主成分分析 和 线性回归的区别
这是主成分分析,是多个特征之间的,是垂直于这个轴的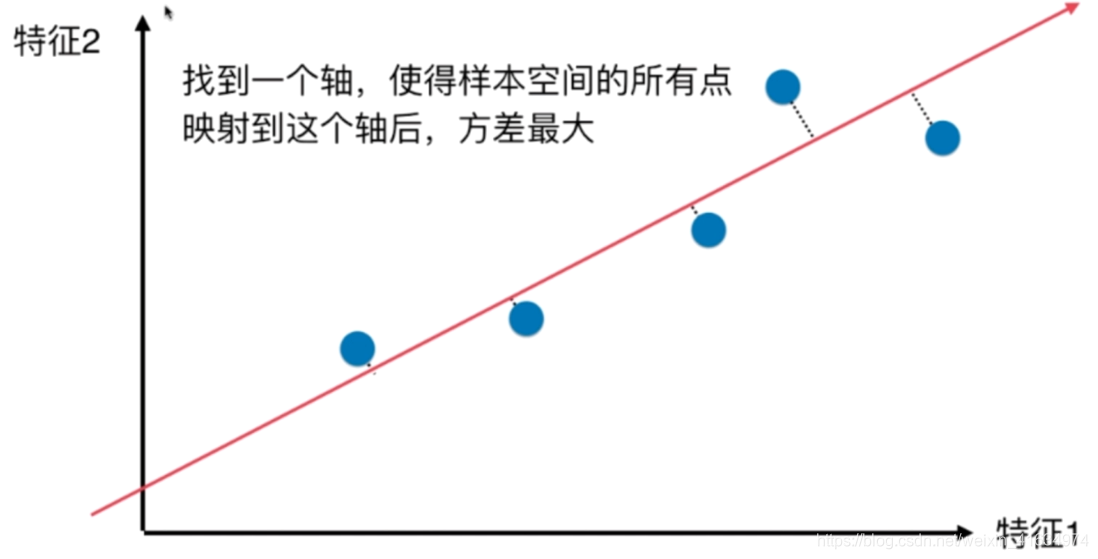
线性回归是一个标记结果和特征之间的,是垂直于特征的,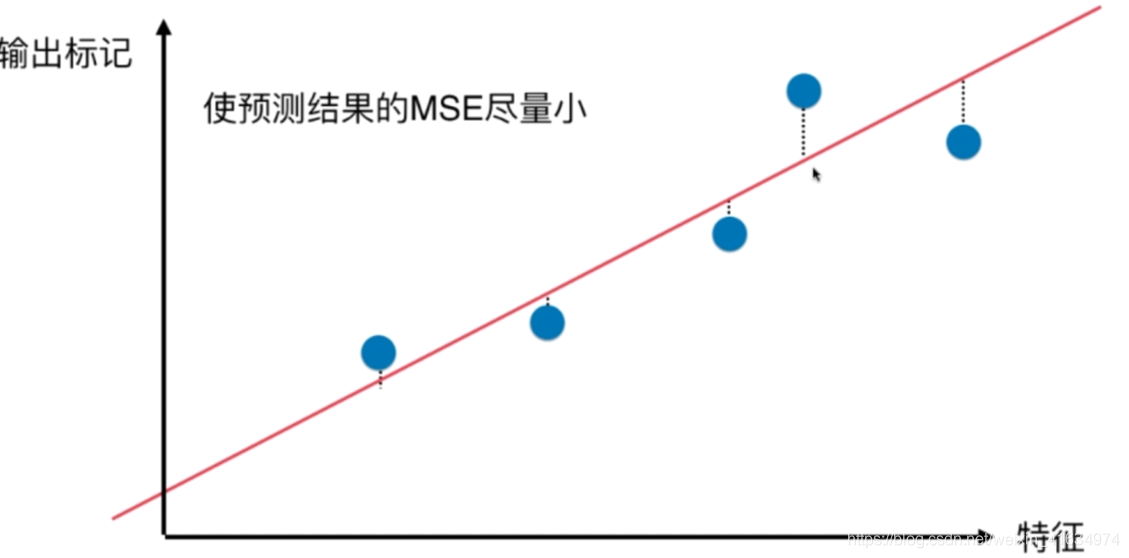
使用梯度上升法来解决PCA问题
目标:求w,使得 f ( X ) = 1 m ∑ i = 1 m ( X 1 i w 1 + X 2 i w 2 + . . . + X n i w n ) 2 f(X) =\frac{1}{m} \sum_{i=1}^m (X^i_1w_1+X^i_2w_2+...+X^i_nw_n)^2 f(X)=m1∑i=1m(X1iw1+X2iw2+...+Xniwn)2 最大




实现梯度上升法求解主成分分析
import numpy as np import matplotlib.pyplot as plt X = np.empty((100,2)) X[:,0] = np.random.uniform(0,100,size=100) X[:,1] = 0.75 * X[:,0] + 3.+np.random.normal(0,10,size=100) plt.scatter(X[:,0],X[:,1]) plt.show() # demean def demean(X): return X - np.mean(X,axis=0) # 减去每一列的均值 X_demean = demean(X) plt.scatter(X_demean[:,0],X_demean[:,1]) plt.show() def f(w,f): return np.sum((X.dot(w)2))/ len(X) def df_math(w,X): #梯度的算法 return X.T.dot(X.dot(w)) *2 /len(X) def direction(w): # 求一个向量的单位向量 # 因为在推导公式时候需要 w的模等于1 ,所以此处需要将 w进行处理 return w/np.linalg.norm(w) def gradient_ascent(df, X, initial_w, eta, n_iters=1e4, epsilon=1e-8): w = direction(initial_w) # 因为在推到公式时候需要 w的模等于1 ,所以此处需要将 w进行处理 cur_iter=0 while cur_iter < n_iters: gradient = df(w,X) last_w = w w = w + eta * gradient w = direction(w) # 使用pca 求解梯度法需要注意的,需要将w转为单位向量。 if (abs(f(w,X) - f(last_w,X)) < epsilon): break cur_iter +=1 return w initial_w = np.random.random(X.shape[1]) # 初始向量不能为0, 不能从0 开始 eta = 0.001 # 注意不能使用 standardScaler 标准化数据,因为 standardScaler 本来就是将数据标准化,使方差为1, # 而 pca 求的就是将方差最大值。 demean w = gradient_ascent(df_math, X_demean, initial_w, eta) plt.scatter(X_demean[:,0], X_demean[:,1]) plt.plot([0,w[0]*30], [0,w[1]*30], color='r') plt.show() 讯享网
注意事项:
- 先对数据进行 demean 处理
- 不要对数据进行 standardScaler 标准化处理,因为pca求得就是最大方差,standardScaler 就是使得方差变成1
- 在给 w初始化值的时候,不能为0向量,可以进行非0随机化处理
- 在梯度上升计算中,要是w变成w的单位向量
求前n个主成分
上面代码将两个特征轴变成了一个特征轴,
求出第一主成分后,如何求出下一个主成分呢?
将数据进行改变,将数据在第一个主成分上的分量去掉

上图中的 X ‘ i X^{`i} X‘i就是新的数据。
在新的数据上求第一主成分

讯享网# 根据上面的运算 继续 X2 = np.empty(X.shape) for i in range(len(X)): X2[i] = X[i] - X[i].dot(w)*w # 将样本在第一主成分上相应的分量去掉的结果 # 上面公式 可以进行向量化 X2= X - X.dot(w).reshape(-1,1) * w plt.scatter(X2[:,0],X2[:,1]) plt.show() w2 = gradient_ascent(df, X2, initial_w, eta) w2 w.dot(w2)
前n个主成分计算
def first_component(X, initial_w, eta, n_iters=1e4, epsilon=1e-8): w = direction(initial_w) # 因为在推到公式时候需要 w的模等于1 ,所以此处需要将 w进行处理 cur_iter=0 while cur_iter < n_iters: gradient = df(w,X) last_w = w w = w + eta * gradient w = direction(w) # 使用pca 求解梯度法需要注意的,需要将w转为单位向量。 if (abs(f(w,X) - f(last_w,X)) < epsilon): break cur_iter +=1 return w def first_n_components(n, X,n_iters=1e4, epsilon=1e-8): X_pca = X.copy() X_pca = demean(X_pca) res = [] for i in range(n): initial_w = np.random.random(X_pca.shape[1]) w = first_component(X_pca, initial_w, eta) res.append(w) X_pca = X_pca - X_pca.dot(w).reshape(-1,1) * w return res 对数据进行降维
高维数据向低维数据映射
降维:
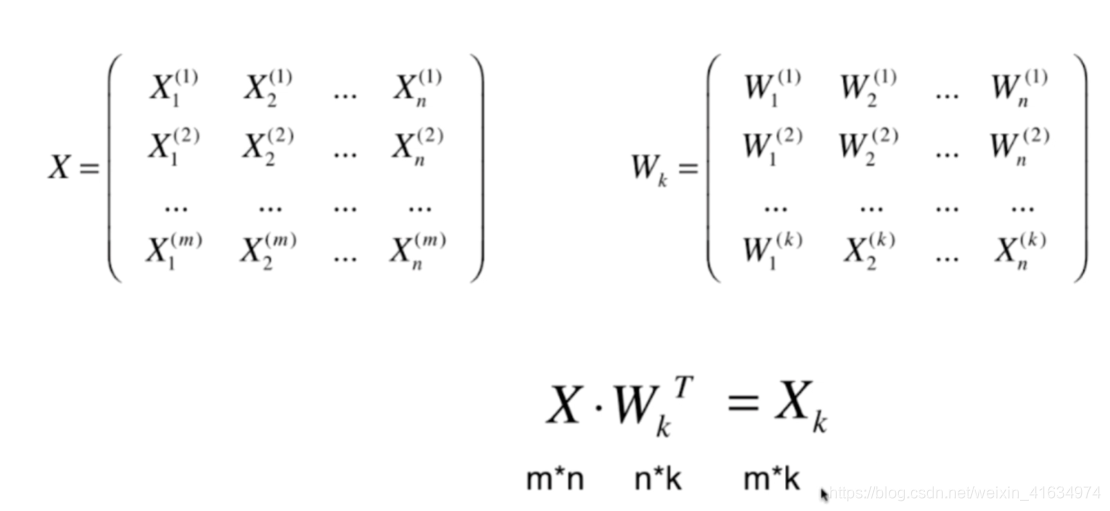
低维映射会高维 但是 生成的数据和原来的高维数据不一样,在降维过程中会丢失一些数据,所以无法恢复回来

讯享网import numpy as np class PCA: def __init__(self, n_components): assert n_components >=1, 'n_components must be valid' self.n_components = n_components self.components = None def fit(self, X, eta=0.01, n_iters=1e4): assert self.n_components <= X.shape[1], 'n_components must not be greater than the feature number of X' def f(w,X): return np.sum((X.dot(w)2))/len(X) def df(w,X): return X.T.dot(X.dot(w))*2/len(X) def demean(X): return X- np.mean(X,axis=0) def direction(w): return w/np.linalg.norm(w) def first_component(X, initial_w, eta=0.01, n_iters=1e4, epsilon=1e-8): w = direction(initial_w) cur_iter= 0 while cur_iter < n_iters: gradient = df(w,X) last_w = w w = w + eta * gradient w = direction(w) if abs(f(w,X) - f(last_w, X)) < epsilon: break cur_iter +=1 return w X_pca = demean(X) self.components_ = np.empty(shape=(self.n_components,X.shape[1])) for i in range(self.n_components): initial_w = np.random.random(X_pca.shape[1]) w = first_component(X_pca, initial_w, eta, n_iters) self.components_[i,:] =w X_pca = X_pca - X_pca.dot(w).reshape(-1,1)*w return self # 降维 会丢失一些信息 def transform(self,X): assert X.shape[1] == self.components_.shape[1] return X.dot(self.components_.T) # 升维 只是在高维空间里表达低维的信息 def inverse_transform(self,X): assert X.shape[1] == self.components_.shape[0] return X.dot(self.components_) def __repr__(self): return f'PCA(n_components={self.n_components})'
scikit-learn 中 PCA
from sklearn.decomposition import PCA pca =PCA(n_components=1) pca.fit(X) pca.components_ X_reduction = pca.transform(X) X_restore = pca.inverse_transform(X_reduction) 使用digits数据
讯享网import numpy as np import matplotlib.pyplot as plt from sklearn import datasets digits = datasets.load_digits() X = digits.data y = digits.target from sklearn.model_selection import train_test_split X_train, X_test, y_train,y_test = train_test_split(X,y,random_state=666) %%time from sklearn.neighbors import KNeighborsClassifier knn_clf = KNeighborsClassifier() knn_clf.fit(X_train, y_train) # Wall time: 2 ms # KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski', metric_params=None, n_jobs=None, n_neighbors=5, p=2, weights='uniform') knn_clf.score(X_test, y_test) # 0.66667 from sklearn.decomposition import PCA pca = PCA(n_components=2) pca.fit(X_train) X_train_reduction = pca.transform(X_train) # 多数据进行降维处理 X_test_reduction = pca.transform(X_test) %%time knn_clf = KNeighborsClassifier() # 再使用knn 处理 knn_clf.fit(X_train_reduction, y_train) # Wall time: 1 ms # KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski', metric_params=None, n_jobs=None, n_neighbors=5, p=2, weights='uniform') knn_clf.score(X_test_reduction,y_test) # 0.66667 # 上面因为将64维降成2维,很多数据丢失,所以准确率低 # pca 为我们提供了一个很好的接口, pca = PCA(0.95) # 这里的0.95表示我们如果想要将64维数据压缩成保留全部数据的95%的数据,pca内部会为我们计算出合适的 维度 pca.fit(X_train) pca.n_components_ # 28 pca 计算出 保留95%数据时,应该选取维度是28 # 此时转换 数据 X_train_reduction = pca.transform(X_train) X_test_reduction = pca.transform(X_test) # 将数据进行knn操作 %%time # 2ms knn_clf = KNeighborsClassifier() knn_clf.fit(X_train_reduction, y_train) knn_clf.score(X_test_reduction,y_test) # 0.98 维度增加,时间提升,但是准确率也提升了
有时数据由很多维降到2维也是很有效的
pca =PCA(n_components=2) pca.fit(X) X_reduction = pca.transform(X) X_reduction.shape for i in range(10): plt.scatter(X_reduction[y==i,0], X_reduction[y==i,1], alpha=0.8) plt.show() 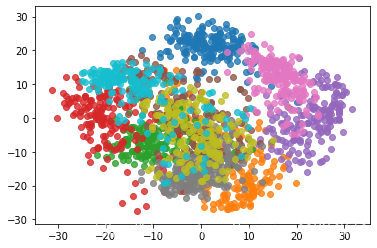
可以看出启动蓝色和紫色的数据区分很明显。不需要高维数据也可以区分。
我们可以通过 pca.explained_variance_ratio_ 来查看多维数据 每一维所占的总数据比例:
讯享网pca = PCA(n_components=64) pca.fit(X_train) pca.explained_variance_ratio_ #array([1.e-01, 1.e-01, 1.e-01, 8.e-02, 5.e-02, 5.e-02, 4.e-02, 3.e-02, 3.e-02, 3.0e-02, 2.e-02, 2.e-02, 1.e-02, 1.e-02, 1.e-02, 1.e-02, 1.e-02, 1.e-02, 1.0e-02, 9.0e-03, 8.e-03, 7.e-03, 7.e-03, 7.e-03, 6.e-03, 5.e-03, 5.e-03, 5.0e-03, 4.e-03, 4.e-03, 3.e-03, 3.e-03, 3.e-03, 3.e-03, 3.0e-03, 2.e-03, 2.e-03, 2.e-03, 2.e-03, 1.e-03, 1.e-03, 1.e-03, 1.e-03, 1.e-03, 1.e-03, 1.0e-03, 9.e-04, 9.00017642e-04, 5.e-04, 3.e-04, 2.e-04, 8.e-05, 5.e-05, 5.e-05, 1.0e-05, 4.0e-06, 1.e-06, 1.0e-06, 6.0e-07, 5.e-07, 7.e-34, 7.e-34, 7.e-34, 7.e-34]) # 画图看下各个维度的数据占比 plt.plot([i for i in range(X_train.shape[1])], [np.sum(pca.explained_variance_ratio_[:i+1]) for i in range(X_train.shape[1])]) plt.show()
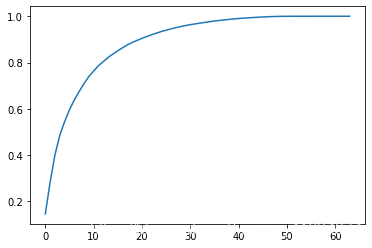
MNIST 数据集 处理
降维能很大的节省处理时间
import numpy as np from sklearn.datasets import fetch_mldata mnist = fetch_mldata("MNIST original") X,y = mnist['data'], mnist['target'] 这个数据中已经处理好。前60000个是训练数据,后面10000个是测试数据 X_train = np.array(X[:60000],dtype=float) y_train = np.array(y[:60000],dtype=float) X_test = np.array(X[60000:],dtype=float) y_test = np.array(y[60000:],dtype=float) # 直接使用 knn from sklearn.neighbors import KNeighborsClassifier knn_clf = KNeighborsClassifier() %time knn_clf.fit(X_train, y_train) # 13s %time knn_clf.score(X_test, y_test) # 8min 59s 0.9688 # 使用pca降维, 然后使用knn # 时间明显降低 from sklearn.decomposition import PCA pca = PCA(0.9) pca.fit(X_train) X_trian_reduction = pca.transform(X_train) knn_clf = KNeighborsClassifier() %time knn_clf.fit(X_trian_reduction, y_train) # 291 ms %time X_test_reduction = pca.transform(X_test) #68.1 ms %time knn_clf.score(X_test_reduction, y_test) # 1min 4s 0.9728 pca 对数据的降噪处理
讯享网import numpy as np import matplotlib.pyplot as plt X = np.empty((100,2)) X[:,0] = np.random.uniform(0,100,size=100) X[:,1] = 0.75 *X[:,0]+3+np.random.normal(0,5,size=100) plt.scatter(X[:,0],X[:,1]) plt.show()

from sklearn.decomposition import PCA pca =PCA(n_components=1) pca.fit(X) X_reduction =pca.transform(X) # 先降维 X_restore = pca.inverse_transform(X_reduction) # 再还原 plt.scatter(X_restore[:,0],X_restore[:,1]) # 此时可以看到变成一条直线,进行了降噪 plt.show() 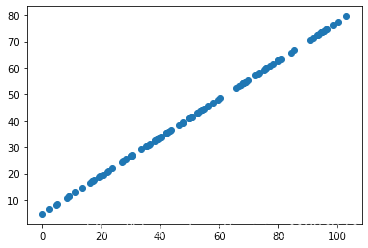
人脸识别和特征脸
讯享网import numpy as np import matplotlib.pyplot as plt # 获取数据 from sklearn.datasets import fetch_lfw_people faces = fetch_lfw_people() faces.keys() faces.data.shape faces.images.shape random_indexes = np.random.permutation(len(faces.data)) X = faces.data[random_indexes] example_faces =X[:36,:] # 获取36个图片数据 example_faces.shape def plot_faces(faces): fig, axes = plt.subplots(6,6,figsize=(10,10), subplot_kw={'xticks':[],'yticks':[]}, gridspec_kw=dict(hspace=0.1,wspace=0.1)) for i ,ax in enumerate(axes.flat): ax.imshow(faces[i].reshape(62,47),cmap='bone') plt.show() plot_faces(example_faces) # 显示图片数据 %%time # 查看数据的特征的重要性 from sklearn.decomposition import PCA pca = PCA(svd_solver='randomized') pca.fit(X) # 查看特征 数据 ,这些特征就是特征脸 pca.components_.shape plot_faces(pca.components_[:36,:])

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/16550.html