
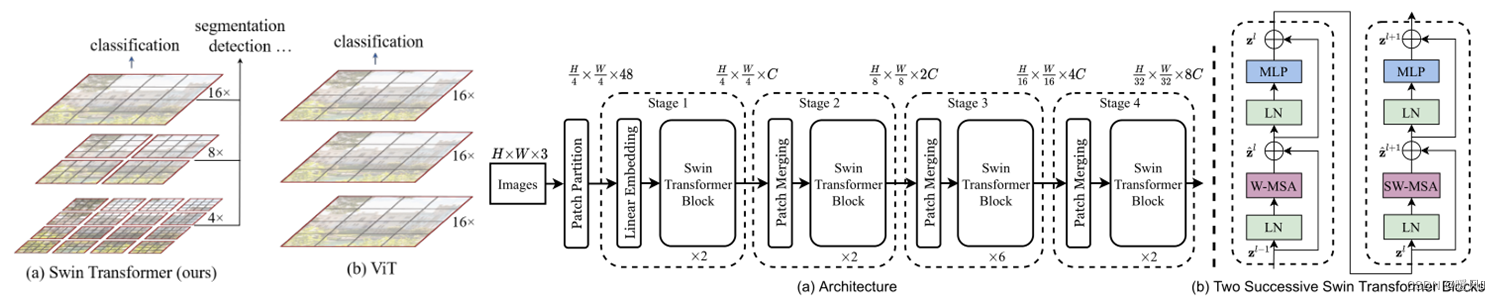
这篇文章结合了CNN的归纳偏置,基于局部窗口做注意力,并且逐步融合到深层transformer层中构建表征,来达到扩大感受野,并且极大降低了计算量。是一个特征提取的主干网络,backbone。构建了一种分层特征提取的方式,不断减小“feature map”的大小(token的数量),构造层次的特征映射。
关键部分是提出了Shift window移动窗口(W-MSA、SW-MSA),改进了ViT中忽略局部窗口之间相关性的问题。在ViT中使用不重叠的窗口进行self-attention计算,忽略了相邻窗口间的相关性,而Swin-T使用shfit windown移动(M/2)来桥接不同窗口间的信息。但这样会引入很大的计算量,于此作者又提出了cyclic-shift 循环位移,保证计算量不变,但是这样的移动又又又会使得不相关的部分拼接在一起。计算这些部分的注意力是没有意义的。于是提出了attention mask来遮盖无效的部分,使注意力权重为0 这部分的详细推导。还加入了相对位置偏置B。

获得了2021ICCV最优文章。
原文链接:Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
参考文献:
对Swin-T的输入输出不太清楚的可以看这篇:Swin Transformer详解
W-MSA和SW-MSA复杂度计算:MSA模块计算复杂度推导
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows[ICCV 2021]
- Abstract
- 1 Introduction
- 2 Method
-
- 2.1 Overview
- 2.2 Swin-T Block
- 2.2 Shifted Window based Self-Attention
- 3 Experiments
-
- 3.1 Image Classification on ImageNet-1K
- 3.2 Object Detection on COCO
- 3.3 Semantic Segmentation on ADE20K
- 3.4. Ablation Study
- 4 Conclusion
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/129296.html