
随着 AI 应用的普及,以及图片、视频、语音、文本等非结构化数据的快速增长,向量检索成为数据分析相关应用中的重要技术。近年来,学术界对该技术的兴趣日益浓厚,在上一届人工智能领域全球顶级学术会议 NeurIPS 上,就举办了国际首届向量检索比赛。为了更好地理解海量非结构化数据,Zilliz 主办了一场向量检索研讨会,邀请来自学术界和企业界的多位专家学者共同探讨该领域的前沿技术与未来发展。
在研讨会上,香港科技大学广州分校的王炜教授分享关于近似最近邻搜索的研究综述,NeurlPS 检索比赛中的快手团队与 Zilliz 团队分享冠军方案,Zilliz 合伙人、Milvus 工程总监栾小凡分享 Milvus 向量数据库设计理念与未来方向,亿贝团队分享向量检索在工业界的实践。
产、学、研、用跨界对话,将会碰撞出怎样的火花?让我们一起来看看吧:
Approximate Nearest Neighbor Queries for High Dimensional Data
嘉宾:王炜教授,香港科技大学广州分校
王炜老师介绍了三种向量检索的基本方法,即:局部敏感哈希(Locality Sensitive Hashing)、乘积量化(Product Quantization,PQ)、图索引,并引导观众思考一些开放性的问题:如何更好地理解高维数据?现有的图索引方法为什么是有效的?evaluation 和系统支持应该如何优化?
更多详情请戳视频 👇
比赛简介与获奖方案分享
此次比赛是被人工智能领域全球顶级学术会议 NeurIPS'21 接收的国际首届向量检索比赛,旨在促进向量检索领域的新技术发展,并展示其价值,并为相关研究者们提供合作平台,共同推动该领域发展。
早期,向量检索的方法大多已在百万级数据集上验证,而随着数据类型和数量不断增长、应用场景不断丰富,实际生产中向量的数据级别已达到十亿、百亿,甚至更高的级别。在更大的数据集上,原来的方法是否还有效?会不会有一些新的方法诞生?为了验证各类方案在现实场景中的效果,此次比赛首次使用了六个十亿级别的数据集,Facebook、Microsoft Turing、Microsoft Bing、Yandex 专门为本次比赛发布了四个新数据集,并且引入统一的 benchmark 测试。
比赛一共分为三个赛道,此次研讨会着重介绍纯内存方案赛、磁盘方案两个赛道。
关于比赛详细信息,请参见:http://big-ann-benchmarks.com/index.html
Track 1:Standard hardware w/limited DRAM
嘉宾:乔禹,快手多模态检索工程师
第一赛道要求参赛队伍针对 6 个十亿规模的数据集中的至少三个,达到在 10000 QPS 以上性能的同时,相对基准方案 Faiss 的 IVFPQ 方法尽可能提高召回率。快手团队的方案在四个数据集上都比 baseline 高 5% - 10%,最终获得赛道第一。
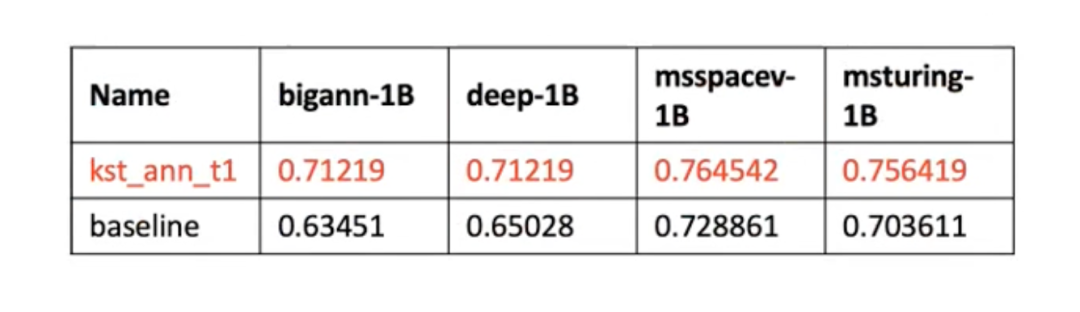
快手方案针对 IVFPQ 方法进行了全方面的优化,具体的优化思路如下:
- IVF 优化:使用基于 Graph 的索引提升 IVF 层的搜索效率
- PQ 优化:学习数据分布,semi-end-to-end training method
- 计算效率优化:使用 Avx512 指令集加速计算;Query batch 和 PQ 位宽的 trade off 调优(PQ 量化位宽越大,内存耗费越大,精度越高)
Track 2:Limited memory + inexpensive SSD
嘉宾:易小萌,Zilliz 高级研究员
第二赛道的 metrics 是在 93GB - 745GB 的数据机上进行搜索,性能要求是 QPS 在 1500 以上。整个方案分三个步骤:
- 数据在 SSD 中的存储优化,将向量数据分桶
- 在内存里维护一个图索引,通过图索引去找桶
- 向量搜索,每次找到相关的桶,随后对桶内向量逐一比对
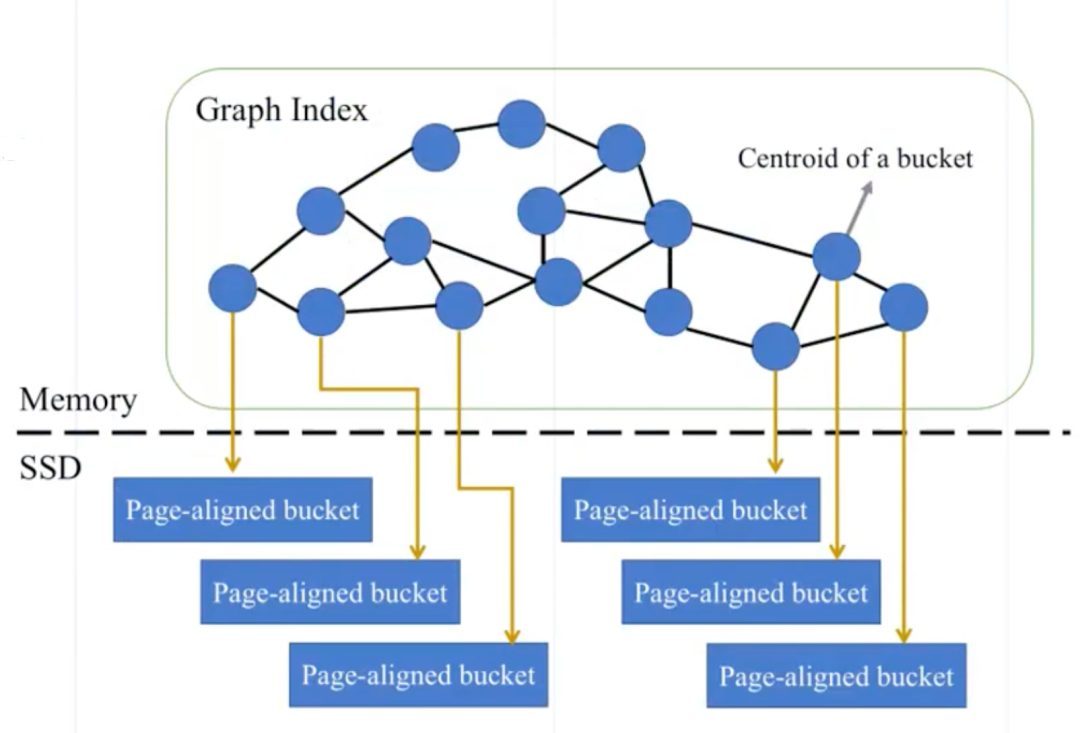

Zilliz 团队的方案使用图索引方法,用分层的 KMeans 加速训练过程,将每个桶与物理上的 SSD 对齐,提高读取效率。该方案最终获得赛道第一的好成绩,在 ssnpp 数据集上召回率提升 72.3%。
更多详情请戳视频 👇
Milvus 向量数据库设计理念与未来方向
嘉宾:栾小凡,Zilliz 合伙人、Milvus 工程总监
- 数据规模高达百亿,响应要求在毫秒级别
- 弹性扩所容,应对请求突增
- 面对海量数据,清洗,索引成本很高,系统复杂度提升
- 就数据实时性和处理效率而言,业务场景对于数据的可见性要求变高,向量索引通常对更新/删除不友好,另外,用户需要根据业务场景进行 tradeoff
- 就性能与成本而言,基于内存的向量索引方案成本过高,池化思想可以帮助最大化利用资源
- 数据孤岛问题
- 易用性问题
Milvus 数据库设计架构的初衷,就是解决上述问题,做出易于使用、易于部署、易于维护、易于对接上下游的数据库,解锁海量非结构化数据的隐藏价值。
Milvus 2.0 是面向向量数据的云原生数据库,提供基于 kubernetes 和线下部署多种模式,具有高可用和高扩展性。对于用户而言,Milvus 数据库除了提供完善的元信息管理和配置管理,还有丰富的工具和社区支持。
关于 Milvus 数据库更详细的设计理念和未来 roadmap,请戳视频 👇
Milvus 数据库在亿贝智能营销的实践
嘉宾:刘炼,亿贝技术负责人;高林华,亿贝资深软件开发工程师
亿贝有两类典型业务涉及到向量检索任务:第一类是是基于用户和商品的协同过滤做相似性推荐;第二类是当个人买家在拍卖中竞价失败时,亿贝会找到近似商品进行推荐。
离线状态下,通过 Spark 运行详细算法模型;在在线状态下,亿贝希望能有一个 QPS 达到千级以上,延迟在十几毫秒内的向量查询数据库。调研相关工具后,亿贝选择了开源向量数据库 Milvus。
刘炼与高林华分享了在业务中部署和维护 Milvus 数据库的经验,更多详细内容请戳视频 👇
在圆桌讨论环节,来自香港科技大学、华中科技大学、东华大学、南方科技大学的学者与专家共同探讨向量检索领域的前沿技术与未来发展。欢迎点击文末的阅读原文查看完整视频分享。

Zilliz 构建了 Milvus 向量数据库,以加快下一代数据平台的发展。Milvus 数据库是 LF AI & Data 基金会的毕业项目,能够管理大量非结构化数据集,在新药发现、推荐系统、聊天机器人等方面具有广泛的应用。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/128288.html