
汇编笔记
大部分内容可能是在说32位的情况下,有时候说的是64位的情况下
(记得比较杂,比较详细,也比较随意,当时的水平也没现在高,如有疏漏还请多多包含)
(关于编写,推荐各位使用MASM,不要再搞个沙盒开DOS系统了,这真的很麻烦)
(笔记使用Intel语法)
(初期整理自,后期整理自《汇编语言:基于x86处理器》,不包含现代x86汇编的内容)
(现代x86汇编主要是提供了SIMD指令以提高数据级并行能力,同时采用MMX寄存器替代FPU寄存器来处理浮点数,现有的编译器都会使用MMX寄存器来处理浮点数。Intel长期的兼容策略依旧在现有的处理器上保留了FPU)
内存与高速缓存与寄存器
- 一个内存地址存放8个比特
- 地址线的条数决定能访问的内存数量, n n n条地址线能访问 2 n 2^{n} 2n个地址
32位计算机的地址线数量为32根,最大寻址空间为 2 32 B y t e s = 1024 ∗ 1024 ∗ 1024 ∗ 4 B y t e s 2^{32}Bytes=1024*1024*1024*4Bytes 232Bytes=1024∗1024∗1024∗4Bytes,这是为什么32位计算机内存最大为4G,同理,64位计算机的最大寻址空间为 2 64 B y t e s = 2 30 G B ∗ 2 34 = T B = 16384 P B 2^{64}Bytes=2^{30}GB*2^{34}=TB=16384PB 264Bytes=230GB∗234=TB=16384PB
从P6开始的32位处理器,使用了扩展物理寻址的技术,可以寻址的内存空间增加到64GB。
- 内存的接口上,除了地址线负责选择访问的地址外,还应有读写控制
- 早期的内存是由磁芯存储的,是否有磁代表1和0
- 在x86处理器上,按小端序存储和检索数据(在VS调试窗口里观察内存的变动情况也可以发现这一点)
动态随机访问存储器DRAM
每个比特的存储是依靠极其微小的晶体管和电容来完成的。电容很容易泄露电荷,组成这种内存的电容泄露电荷非常快,所以需要定期补充电荷以维持原先存储的内容,这个过程叫动态刷新,这种存储器成为动态随机访问存储器(DRAM)。
随机访问的意思是访问任何一个内存单元的所花的时间和它的位置(地址)无关。
- 读取内存
从内存中读取一个值吗,需要经过四个步骤
- 将想要读取值的地址放到地址总线上
- 将处理器的RD(读)引脚置为有效
- 等待一个时钟周期,以便存储器芯片给予响应
- 将数据从数据总线复制到目的操作数
上述每一步一般需要一个时钟周期。
读取内存的速度与访问寄存器相比慢多了,访问寄存器通常只需要一个时钟周期。
由于读取内存的速度慢,便产生了cache。预先将后续的一些指令加载到cache中,这种行为是基于这些指令很快就会被用到的假设,比如一个循环。由此也产生了两个概念,叫cache命中和cache缺失。
寄存器是直接位于CPU内从高速存储位置,访问速度远高于传统存储器。当为了提高速度而优化一个循环时,循环计数器会保存在寄存器中而不是在变量中。
指令
- 操作数是直接包含在指令中的,是指令的组成部分,这样的操作数是立即数:它是直接包含在指令中的,可以立即从指令中得到
- 指令除非发生了跳转,总是从内存的低端执行到内存的高端
程序
程序可以分为代码段和数据段
处理器中IPR的值,始终是下一条即将执行的指令
当前指令的地址+当前指令的长度=下一条指令的地址
在程序中使用绝对地址(物理地址)会产生重定位问题,能够重定位是对程序的基本要求
电脑内的存储器地址可被分为若干逻辑段。每个逻辑段的起始地址称为段地址。
偏移地址是指段内相对于段起始地址的偏移值。
为了适用偏移地址,在处理器中增加了数据段寄存器DSR(DS)
(代码段寄存器CS)
(R是寄存器的意思)
处理器

Intel 8086

Intel 8086的通用寄存器有AX,BX,CX,DX,SI,DI,SP,BP八个,都是16位
只有AX,BX,CX,DX可以分为两个小寄存器
以AX为例,可以分为两个小寄存器,0到7属于AL,8到15属于AH。
1个字=2个字节
AH是AX的高字节部分,AL是AX的低字节部分
低端字节序&高端字节序
Intel 8086的内存访问困境与策略
Intel 8086有16根数据线,20根地址线,最多可以访问个内存单元(字节),即1MB
CS和DS都是16位的,容纳不了20位的物理地址
策略:将 地 址 H 地址_{H} 地址H除以 1 0 H 10_{H} 10H,然后放入寄存器
由于8086代码段寄存器和数据段寄存器的限制,只有十六进制形势下末尾为0的地址可以作为代码段和数据段,为此引入了IP(指令指针寄存器)
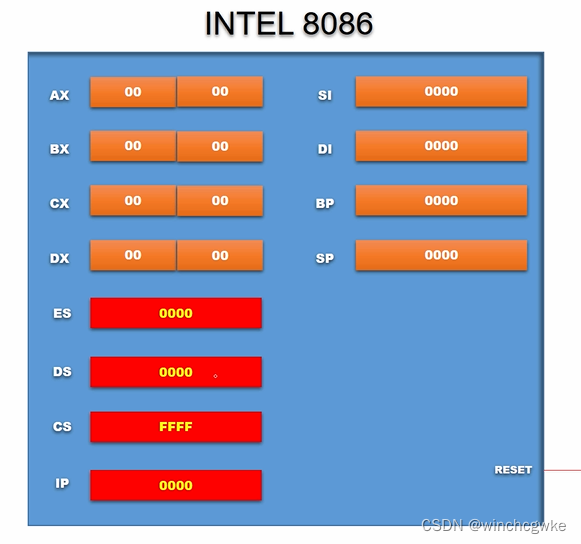
在IP中存储指令相对于CS的偏移量
ES是附加段寄存器,其出现是因为有时会在段之间来回操作,一个段寄存器不够用
8086加电与复位(该策略在之后没有延续)
8086在加电与复位后,代码段寄存器预置为FFFF,其余寄存器都预置0,然后取指令执行指令。
代码段寄存器FFFF,指令指针寄存器0000,相加FFFF0,取到的第一条指令就是FFFF0

ROM BIOS的内容即使掉电也不会消失,但是很难改变。有些ROM的内容在写入之后永远无法再重写和擦除,但是有些ROM的内容可以使用紫外线或加电来擦除和重写。ROM只读存储器,BIOS基本输入输出系统
在FFFF0到FFFF4这五个字节上,存储了一条跳转指令,EA 5B E0 00 F0即jmp 0xF000:E05B,跳转到0xF000:E05B,执行这条指令后,CS的内容为F000,IP的内容为E05B,FE05B仍为BIOS的内容,这里内置了计算机的检测和初始化程序。
在ROM BIOS里还固化了从硬盘和U盘中读取的代码,从而启动操作系统
32位x86处理器
架构

指令执行周期

操作模式
x86处理器主要有三个模式:保护模式、实地址模式和系统管理模式。 虚拟8086模式是保护模式的一种特殊情况
- 保护模式
处理器的本地状态。在这种模式下,所有的指令和特性都是可用的。程序都被分配了称为段的独立内存区域,而处理器会阻止发程序访问其被分配段之外的内存。保护模式最可靠、最强大的,但是它对应用程序直接访问系统硬件有着严格的限制。在保护模式下,程序之间禁止意外访问其他程序的代码和数据。MS-Windows和Linux运行在保护模式下
- 虚拟8086模式
在保护模式下,处理器可以安全地执行实地址模式软件,如MS-DOS程序(个人理解:比如虚拟机上跑一个DOS系统,然后去运行一些东西),其运行在类似于沙箱的环境,称为虚拟8086模式
- 实地址模式
实地址模式实现了早期Intel处理器的编程环境,但增加了一些额外的特性,如切换到其它模式的功能。当程序需要直接访问系统内存和硬盘设备时,这种模式就很有用。当前版本的Windows操作系统不支持实地址模式。实地址模式的程序只能寻址1GB。
- 系统管理模式
系统管理模式向其宿主机操作系统提供了实现诸如电源管理和系统安全等功能的机制。这些功能通常是由计算机制造商实现的,他们会为了一个特定的系统设置而定制处理器。
通用寄存器

某些寄存器有特殊的用法:
- 乘法指令和除法指令自动使用EAX。它常常被称为扩展的累加寄存器(Extended Accumulator Register)。
- CPU自动使用ECX作为循环计数器
- ESP用于寻址堆栈上的数据(Extended Stack Pointer Register)
- ESI和EDI用于高速内存传输指令。Extended Source Index Register(扩展的源变址寄存器),Extended Destination Index Register(扩展的目的变址寄存器)
- EBP(Extened Base Pointer)被高级语言用来访问堆栈中的函数参数和局部变量。除了高级编辑,它不应该用于一般的算数运算和数据传送。它常常被称为Extended Frame Pointer Register(扩展的帧指针寄存器)。EBP寄存器用于指向当前栈帧的基址,作为函数调用过程中局部变量和参数的参考点。栈帧是用来管理函数调用的内存区域,包括函数的局部变量、参数以及与函数调用有关的其他数据。RBP寄存器在函数调用时被用来保存上一个栈帧的RBP值,并设置为当前栈帧的基址,以便在当前函数中访问局部变量和参数。
段寄存器
都是16位的
- CS
- SS
- DS
- ES
- FS
- GS
指令指针寄存器 EIP
EFLAGS
这个寄存器包含特殊的二进制位,用于控制CPU的操作,或是反映一些CPU操作的结果。
- 控制标志
- 状态标志
其余组成部分
参考汇编语言第八版第29页
64位x86-64处理器
- 向后兼容x86指令集
- 可以使用64位通用寄存器
- 比x86多了8个通用寄存器
- 使用48位的物理地址空间,支持高达256TB的RAM。之前记载的TB是使用了64位的物理空间地址,即理论值。
当处理器运行于本地64位模式时,是不支持16位实模式或虚拟8086模式的
兼容模式
当运行在兼容模式(32位模式)下时,现有的16位和32位程序不用重新编译就可以运行
与32位处理器的区别
- 16个64位通用寄存器
- 8个80位浮点计数器
- 1个64位状态标志寄存器
- 1个64位指令指针寄存器
- 8个64位MMX寄存器
- 16个128位XMM寄存器
汇编语言
汇编语言与机器语言是一对一的关系:每一条汇编语言指令对应一条机器语言指令。
高级语言,如C++、Java,利用语法规则来减少意外的逻辑错误,而这是以限制低层数据访问为代价的。Java不允许访问具体的内存地址,可以使用Java本地接口类来调用C函数以绕过这个限制,但产生的程序不易维护;汇编语言能访问任何内存地址,这种自由的代价也很高:汇编语言程序员要花大量时间进行调试。
使用Microsoft Macro Assembler(Microsoft宏汇编器,MASM)进行编程,需要使用到VS中的Visual C++,除了其中的ml.exe外,还需要irvine相关的库,否则就会报错。
基本语言元素
最安全也是最无用的指令是NOP,它在程序空间中占有一个字节,但是不做任何操作。对于x86处理器的设计,从均匀的双字地址处加载代码和数据更快,所以有时会使用NOP来将下一条指令的地址对其到双字地址。
.model告诉汇编器使用哪一种内存类型。32位程序总是使用平面内存类型(flat memory model),它与处理器的保护模式相关联。
.model flat, stdcall 讯享网
.model伪指令必须出现在.stack、.code、.data之前。参数stdcall在调用过程是告诉汇编器如何管理运行时堆栈
讯享网.stack 4096
数值4096可能比要用到的字节数多,但是对处理器的内存管理系统而言,这正好对应一个内存页的大小。
// ctmd,这Marktext的存储依托答辩,reload然后写的东西就丢了 讯享网.data? ;声明未初始化数据,这种操作可以减小程序在编译之后的大小 .data smallArray DWORD 10 DUP(0) bigArray DWORD 5000 DUP(?) ;这种方式会比下面的这一种多使用20000个字节 .data smallArray DWORD 10 DUP(0) .data? bigArray DWORD 5000 DUP(?)
从上述案例也不难看出,代码与数据很有可能可以来回切换,事情也的确是这样,依我高级语言书写的习惯,这是不错的,但却在汇编里被认为是会导致程序变得难以阅读的。
| 类型 | 用法 |
|---|---|
| BYTE | 8位无符号整数 |
| SBYTE | 8位有符号整数 |
| WORD | 16位无符号整数 |
| SWORD | 16位有符号整数 |
| DWORD | 32位无符号整数 |
| SDWORD | 32位有符号整数 |
| FWORD | 48位整数(保护模式中的远指针) |
| QWORD | 64位整数 |
| TBYTE | 80位(10字节)整数,T代表10字节 |
| REAL4 | 32位IEEE短实数 |
| REAL8 | 64位IEEE长实数 |
| REAL10 | 80位IEEE扩展实数 |
压缩的BCD数据->TBYTE,范围-999,999,999,999,999,999到999,999,999,999,999,999
$当前位置计数器可以返回当前语句的偏移量
似乎可以用这种方式写一个死循环?(雾
;example1 list BYTE 10, 20, 30, 40 listSize = ($ - list) ;example2 myString BYTE "This is a long string, containing" BYTE "aby number of characters";书上的例句,什么沙雕句子 myString_len = ($ - myString) ;不要手动计算字符串的长度,让汇编器做这件事! 当要计算元素数量的数组中包含的不是字节时,就应该用数组总的大小(按字节计)除以单个元素的大小。 比如WORD应该除以2,DWORD应该除以4
讯享网COMMENT & 块注释,COMMENT后的内容不唯一,可以随便放 & COMMENT ! 不唯一 !
.386 .model flat, stdcall .stack 4096 ;这三条语句在64位中不需要 ExitProcess PROTO 位中不PROTO语句不带参数 不管是编写多少位的程序时,都要记得将VS导航栏中的Debug或者Release的目标平台检查一次,这是非常重要的,算是避雷了
汇编基本元素
MOV
mov指令将数据从源操作数复制到目的操作数。
- 操作数必须是同样大小
- 两个操作数不能都是内存操作数
也就是说内存到内存需要先存到寄存器里,再从寄存器复制到内存里
- 指令指针寄存器(IP、EIP或RIP)不能作为目的操作数
啊这
讯享网MOV reg, reg MOV mem, reg MOV reg, mem MOV mem, imm MOV reg, imm ;带符号的扩展传送 movsx ;不带符号的扩展传送 movzx
LAHF和SAHF
LAHF指令将EFLAGS寄存器的低字节复制到AH,被复制的标志有:符号标志、零标志、辅助进位标、奇偶标志及进位标志
.data saveFlags BYTE ? .code lahf mov saveFlags, ah SAHF指令将AH复制到EFLAGS寄存器的低字节
讯享网mov ah, saveFlags sahf
XCHG
交换两个操作数的内容
; 仅支持以下三种形式 xchg reg, reg xchg reg, mem xchg mem, reg 如果要交换两个内存操作数
讯享网mov ax, val1 xchg ax, val2 mov val1, ax
直接-偏移量操作数
arrayB BYTE 10h, 20h, 30h, 40h, 50h ; example ;自动传送数组的第一个字节 mov al, arrayB ;访问数组的第二个字节 mov al, [arrayB + 1] MASM没有内置的有效地址范围检查,在检查数组引用时要格外小心
在16位的数组中,每个数组元素的偏移量比前一个元素多两个字节(16位)
讯享网.data arrayW WORD 100h, 200h, 300h .code mov ax, arrayW ; result: AX = 100h mov ax, [arrayW + 2] ; result: AX = 200h
类似地,在双字数组中,第一个元素偏移量加4才能指向第二个元素
INC和DEC
INC递增,DEC递减
ADD
SUB
NEG
非
加减法影响的标志
- 进位标志表明无符号整数溢出
- 溢出标志表明有符号整数溢出
- 零标志表明操作结果位0
- 符号标志表明操作产生的结果为负数
- 奇偶标志表明在执行一条算数或布尔运算指令后,目的操作数最低有效字节中1的个数是否为偶数
- 当目的操作数的最低有效字节中的位3有进位时,辅助进位标志置1
OFFSET
返回一个变量与其所在段起始地址之间的距离
PTR
可以覆盖操作数的默认大小
.data myDouble DWORD h wordList WORD 5678h, 1234h .code mov ax, myDouble ; 错误 mov ax, WORD PTR myDouble ; 正确,将低位字(5678h)送入了AX mov eax, DWORD PTR wordList ; EAX = h 只有在试图用不同于汇编器认定的大小属性来访问操作数时,这个操作符才是必须的
保护模式任何一个32位通用寄存器用括号括起来就成为间接操作数。
讯享网.data byteVal BYTE 10h .code mov esi, OFFSET byteVal mov al, [esi] ; AL = 10h
一个操作数的大小可能无法从指令的上下文看出来,可能产生"operand must hava size"(操作数必须有大小)报错
inc BYTE PTR [esi] TYPE
返回一个操作数或数组按字节计算的大小
LENGTHOF
数组中元素的个数
讯享网.data byte1 BYTE 10, 20, 30 array1 WORD 30 DUP(?), 0, 0 array2 WORD 5 DUP(3 DUP(?)) array3 DWORD 1, 2, 3, 4 digistStr BYTE "", 0
| 表达式 | 值 |
|---|---|
| LENGTHOF byte1 | 3 |
| LENGTHOF array1 | 30+2 |
| LENGTHOF array2 | 5*3 |
| LENGTHOF array3 | 4 |
| LENGTHOF digistStr | 9 |
SIZEOF
数组初始化时使用的字节数
SIZEOF返回值等于LENGTHOF与TYPE的返回值之积
ALIGN
将一个变量对齐到字节边界、字边界、双字边界或段落边界
ALIGN bound ; bound可以取1、2、4、8或16 当取值为1时,下一个变量对齐于1字节边界
当取值为2时,下一个变量对齐于偶数地址
当取值为4时,下一个变量地址为4的倍数
当取值为16时,下一个变量地址为16的倍数,即一个段落的边界
CPU处理偶数地址的数据比处理奇数地址的数据快
LABEL
LABEL伪指令可以插入一个标号并定义它的大小,但不为这个标号分配存储空间。通常用法是,为在数据段中定义的下一个变量提供另一个变量名称和大小属性
讯享网.data val16 LABEL WORD val32 DWORD h .code mov ax, val16 ; AX = 5678h mov dx, [val16 + 2] ; DX = 1234h ; val16与val32共享一个内存位置
数组
间接操作数是步进遍历数组的理想工具
.data arrayB Byte 10h, 20h, 30h .code mov esi, OFFSET arrayB mov al, [esi] ; AL = 10h inc esi mov al, [esi] ; AL = 20h inc esi mov al, [esi] ; AL = 30h 讯享网data arrayD DWORD 10000h, 20000h, 30000h .code mov esi, OFFSET arrayD mov eax, [esi] ; EAX = 10000h ; 注意是DWORD,应该加4而不是加1 add esi, 4 mov eax, [esi] ; EAX = 20000h add esi, 4 mov eax, [esi] ; EAX = 30000h
变址操作数
在寄存器上加上常量,从而产生一个有效地址。任何32位通用寄存器都可用作变址寄存器。
constant[reg]或[constant + reg]两种格式。
变址操作数非常适合用于数组处理。在访问第一个数组元素前,变址寄存器应初始化为0
.data arrayB BYTE 10h, 20h, 30h .code mov esi, 0 mov al, arrayB[esi] 讯享网.data arrayW WORD 1000h, 2000h, 3000h .code mov esi, OFFSET arrayW mov ax, [esi] ; AX = 1000; mov ax, [esi + 2] ; AX = 2000; mov ax, [esi + 4] ; AX = 3000; mov ax, [4 + esi] ; AX = 3000;
.data arrayD DWORD 1, 2, 3, 4 .code mov esi, 3 ; 第4个元素的下标为3 mov EAX, arrayD[esi*TYPE arrayD] ; EAX = 4 指针
一个变量如果包含的是另一个变量的地址,则该变量就称为指针。
讯享网.data arrayB byte 10h, 20h, 30h, 40h ptrB DWORD arrayB ;或者 ptrB dword OFFSET arrayB
TYPEDEF
; example PBYTE TYPEDEF PTR BYTE JMP&LOOP
JMP
讯享网; 一个死循环 jmploop: jmp jmploop
LOOP
LOOP指令正式的名称是根据ECX计数器循环将语句块重复执行特定次数。
mov ax, 0 mov ecx, 5 L1: inc ax loop L1 讯享网ExitProcess proto .data ; 在这里添加数据 i QWORD 0 j QWORD 4 .code main proc ; 从这里编写汇编代码 mov RAX, 0 ; 初始化RAX mov RCX, 3 ; 设置外层循环次数 L1: mov i, RCX ; 保存外层循环次数到内存 mov RCX, j ; 加载内层循环次数到寄存器 L2: inc RAX ; 操作 loop L2 ; 检查并执行内层循环 mov RCX, i ; 加载外层循环次数到寄存器 loop L1 ; 检查并执行外层循环 stop: jmp stop mov RCX, 0 call ExitProcess main endp end
嵌套循环不是不可以实现,只需要将计数器的值保存在变量中即可实现,但是这种操作不利于维护,所以如果需要使用深层的循环嵌套,可以将一些内层循环用子例程来实现
子例程又被称为子程序、过程、方法、函数等
子例程
堆栈
运行时堆栈
- 由CPU直接管理的内存数组,用于跟踪子例程的返回地址、过程参数、局部变量,以及其它与子例程相关的数据。
这一堆栈与数据结构中的堆栈抽象数据类型(Abstract Data Type)不同。运行时堆栈工作于系统层,管理子例程调用;ADT是编程结构,用于实现基于后进先出的算法。
在32位模式下,ESP寄存器存放的是堆栈中某个位置的32位偏移量。
我们很少直接操作ESP,而是通过如CALL、RET、PUSH和POP这样的指令对其间接修改。
- 运行时堆栈在内存中是向下生长的,即从高地址向低地址扩展。SP之下的堆栈区域在逻辑上是空白的,当前程序下一次执行任何将数值入栈的指令都可以覆盖这个区域。
- 堆栈的应用
- 当寄存器用于多个用途时,堆栈可以作为寄存器的一个方便的临时保存区。
- 当执行CALL时,CPU将当前子例程的返回地址保存在堆栈中。
- 当调用子例程时,其输入数值被称为参数,通过将其压入堆栈来实现参数传递
- 堆栈为子例程内的局部变量提供临时存储区域
PUSH和POP指令
PUSH
PUSH首先减少堆栈指针的值,再将源操作数复制到堆栈。如果操作数是16位,则ESP减2;如果操作数是32位,则ESP减4
PUSH operationNum POP
POP指令首先将堆栈指针指向的堆栈元素内容复制到一个目的操作数中,再增加堆栈指针的值。
讯享网POP operationNum
PUSHFD&POPFD
PUSHFD将32位的EFLAGS寄存器内的内容压入堆栈,POPFD将栈顶单元内容弹出到EFLAGS
PUSHAD&POPAD
PUSHAD按照RAX、ECX、EDX、EBX、ESP(执行PUSHAD之前的值)、EBP、ESI及EDI的顺序,将所有32位通用寄存器压入堆栈。
POPAD按照相反的顺序将寄存器弹出堆栈。
PUSHA&POPA
PUSHA按照AX、CX、DX、BX、SP、BP、SI及DI的顺序将16位通用寄存器压入堆栈。在16位模式下,只能使用PUSHA与POPA指令
定义与使用子例程
PROC
过程用PROC和ENDP伪指令来声明。
main proc ; code main endp 当要创建的过程不是程序的启动过程时,用RET指令来结束它。RET强制CPU返回到该过程被调用的地方。
讯享网sample proc ; code ret sample endp
默认情况下,代码标号只在其被声明的过程内可见,除非使用全局标号,即在名字后面加双冒号
Destination:: CALL&RET
CALL指令执行时,将调用之后的地址压入堆栈,然后把被调用的过程的第一条指令的地址装入指令指针寄存器。
RET指令执行时,由ESP指向的值
USES
在很多过程中要修改寄存器的值,USES能方便地存储与恢复寄存器的值
讯享网ArraySum proc USES esi ecx mov eax, 0 L1: add eax, [esi] add esi, TYPE DWORD loop L1 ret ArraySum endp
链接到外部库
x64调用规约
Microsoft x64调用规约,该规约被C/C++编译器和Windows引用变成接口(API)所采用。
- 由于地址长度为64位,CALL指令将RSP(堆栈指针)寄存器减8
- 传递给过程的前四个参数依序放入RCX、RDX、R8及R9寄存器中。其他额外参数,则按照从左到右的顺序压入堆栈。
- 主调程序在运行时堆栈上分配至少32个字节的影子空间
- 至少预留32字节的影子空间,其实是在调用系统外部链接库和和其他外部库时用的,而一般自定义的调用过程不用如此。因为我们无法改动外部链接库,所以在调用库过程之前无法保证PUSH使用之后调用外部库过程返回后PUSH指令的堆栈顺序还能依旧与POP成对使用,因为无法保证在外部过程中PUSH和POP的成对使用
- 影子空间留少了并不会报错,只会让程序异常退出:程序“[0x2FAC] x64 Assembly Project.exe”已退出,返回值为 1 (0x1)。
- 当调用子例程时,RSP必须对齐到16字节边界(16的倍数)。CALL指令将8个字节的返回地址压入堆栈,此时就需要考虑为rsp减去8以将RSP对其到16字节的边界。
- 长度小于64位的参数不进行零扩展,因此,其高位的值是不确定的
- 被调子例程结束后,主调程序从堆栈中移除所有的参数和影子空间。
- 大于64位的返回值被置于堆栈中,由RCX指向其位置
- 寄存器RBX、RBP、RDI、RSI、R12、R13、R14及R15的值必须由子例程保存
条件处理
布尔和比较命令
AND、OR、XOR、NOT、TEST
AND
标志
AND指令总是清零溢出标志和进位标志,并根据目的操作数来修改符号标志、零标志和奇偶标志。
扩展
AND提供了一种简单的方法将ASCII码中的小写字母转换为大写字母
0 1 1 0 0 0 0 1 = 61h (‘a’)
0 1 0 0 0 0 0 1 = 41h (‘A’)
只有位5不同,所以只需将字符串中的每一个字符都与相与,就可以转换为大写了
.data array BYTE 50 DUP(?) .code mov ecx, LENGTHOF array mov esi, OFFSET array L1: and BYTE PTR [esi], b inc esi loop L1 位映射集
XOR
一个位如果与0异或则保持不变,与1异或则取反
标志
OR指令总是清零进位标志和溢出标志,并根据目的操作数的值来修改符号标志、零标志和奇偶标志
NOT
TEST
TEST指令在两个操作数的对应位之间进行隐含的AND运算,并根据目的操作数的值设置符号标志、零标志和奇偶标志。
TEST指令与AND指令唯一的不同之处是,TEST指令不修改目的操作数。当要查明操作数中单个位是否置位时,TEST指令非常有用。
CMP
CMP指令比较整数。CMP指令执行从目的操作数中减去源操作数的隐含减法运算,并且不修改任何操作数。
标志
当比较无符号操作数时
| CMP结果 | ZF | CF |
|---|---|---|
| 目的操作数 < 源操作数 | 0 | 1 |
| 目的操作数 > 源操作数 | 0 | 0 |
| 目的操作数 = 源操作数 | 1 | 0 |
当比较有符号操作数时
| CMP结果 | 标志 |
|---|---|
| 目的操作数 < 源操作数 | SF≠OF |
| 目的操作数 > 源操作数 | SF=OF |
| 目的操作数 = 源操作数 | ZF=1 |
CMP指令后紧跟条件跳转指令时,称为IF语句的汇编语言等价体。
条件跳转
执行条件结构需要两个步骤:修改CPU的状态标志;用条件跳转指令来测试标志,并使程序分支到一个新的地址
基于特定标志值的跳转
| 助记符 | 描述 | 标志/寄存器 |
|---|---|---|
| JZ | 如果为零则跳转 | ZF=1 |
| JNZ | 如果非零则跳转 | ZF=0 |
| JC | 如果有进位则跳转 | CF=1 |
| JNC | 如果无进位则跳转 | CF=0 |
| JO | 如果有溢出则跳转 | OF=1 |
| JNO | 如果无溢出则跳转 | OF=0 |
| JS | 如果符号位为1则跳转 | SF=1 |
| JNS | 如果符号位为0则跳转 | SF=0 |
| JP | 如果奇偶标志为1(奇偶性为偶)则跳转 | PF=1 |
| JNP | 如果奇偶标志为0(奇偶性为奇)则跳转 | PF=0 |
基于相等性的跳转
| 指令 | 描述 |
|---|---|
| JE | 如果相等(leftOp=rightOp)则跳转 |
| JNE | 如果不相等(leftOp≠rightOp)则跳转 |
| JCXZ | 如果CX=0则跳转 |
| JECXZ | 如果ECX=0则跳转 |
| JRCXZ | 如果RCX=0则跳转 |
基于无符号比较的跳转
| 指令 | 描述 | 指令 | 描述 |
|---|---|---|---|
| JA | 如果多于则跳转(leftOp > rightOp) | JB | 如果少于则跳转(leftOp < rightOp) |
| JNBE | 如果不是少于或等于则跳转(与JA相同) | JNAE | 如果不是多于或等于则跳转(与JB相同) |
| JAE | 如果多于或等于则跳转(leftOp ≥ rightOp) | JBE | 如果少于或等于则跳转(leftOp ≤ rightOp) |
| JNB | 如果不少于则跳转(与JAE相同) | JNA | 如果不多于则跳转(与JBE相同) |
基于有符号数比较的跳转
jle:jump when lower or equel
jge:jump when greater or equel
| 指令 | 描述 | 指令 | 描述 |
|---|---|---|---|
| JG | 如果大于则跳转(leftOp > rightOp) | JL | 如果小于则跳转(leftOp < rightOp) |
| JNLE | 如果不是小于或等于则跳转(与JG相同) | JNGE | 如果不是大于或等于则跳转(与JL相同) |
| JGE | 如果大于或等于则跳转(leftOp ≥ rightOp) | JLE | 如果小于或等于则跳转(leftOp ≤ rightOp) |
| JNL | 如果不小于则跳转(与JGE相同) | JNG | 如果不大于则跳转(与JLE相同) |
条件循环指令
LOOPZ&LOOPE
LOOPZ为零寻缓缓
LOOPE相等循环
LOOPNZ&LOOPNE
LOOPNZ非零循环
LOOPNE不等循环
整数算术运算
| 助记符 | 描述 |
|---|---|
| SHL | 左移 |
| SHR | 右移 |
| SAL | 算术左移 |
| SAR | 算术右移 |
| ROL | 循环左移 |
| RIR | 循环右移 |
| RCL | 带进位的循环左移 |
| RCR | 带进位的循环右移 |
| SHLD | 双精度左移 |
| SHRD | 双精度右移 |
SHL
将目的操作数左移一位,最低位用0填充,最高位移入进位标志,进位标志中原来的值被丢弃
SHR
将目的操作数右移一位,最高位用0填充,最低位移入进位标志
SAL和SAR
SAL与SHL一样。
SAR符号位不变,其余与SHR一样
ROL和ROR
ROL按位循环左移,最高位复制到最低位和进位标志
ROR按位循环右移,最低位复制到最高位和进位标志
RCL&RCR
RCL带进位循环左移,将每一位都向左移,进位标志复制到最低位LSB,最高位MSB复制到进位标志
RCR……
SHLD和SHRD
讯享网SHLD destination, source, count
SHLD将目的操作数左移指定位数,目的操作数的最高位移入进位标志,最低位由源操作数的最高有效位填充。不改变源操作数。
SHRD destination, source, count SHRD将目的操作数右移指定位数,目的操作数的最低位移入进位标志,最高位由源操作数的最低有效位填充。不改变源操作数。

应用
使用移位而非MUL可以获得更好的性能。
当乘数是2的幂时,SHL指令执行的就是无符号乘法。
一个无符号乘法可以被定义为多个2的幂与一个数相乘之和,如 E A X × 36 = E A X × 2 5 + E A X × 2 2 = E A X × 32 + E A X × 4 EAX×36=EAX×2^{5}+EAX×2^{2}=EAX×32+EAX×4 EAX×36=EAX×25+EAX×22=EAX×32+EAX×4, E A X × 3 = E A X × 2 1 + E A X × 2 0 = E A X × 2 + E A X × 1 EAX×3=EAX×2^{1}+EAX×2^{0}=EAX×2+EAX×1 EAX×3=EAX×21+EAX×20=EAX×2+EAX×1。
乘法和除法指令
进行乘法运算时,注意检查进位标志
MUL(无符号整数除法)
| 被乘数 | 乘数 | 乘积 |
|---|---|---|
| AL | reg/mem8 | AX |
| AX | reg/mem16 | DX:AX |
| EAX | reg/mem32 | EDX:EAX |
| RAX | reg/mem64 | RDX:RAX |
IMUL(有符号整数除法)
IMUL会保留乘积的符号,实现的方法是将乘积低半部分的最高位符号扩展到乘积的高半部分。
单操作数模式
讯享网IMUL reg/mem
乘积存放在AX、DX:AX、EDX:EAX或RDX:RAX中
双操作数模式
IMUL reg, reg/mem/imm 第一个操作数中存放乘积,第二个操作数是乘数
三操作数模式
讯享网IMUL reg, reg/mem, imm
第一个操作数中存放乘积,第二个操作数是被乘数,第三个操作数是乘数
DIV(无符号整数除法)
| 被除数 | 除数 | 商 | 余数 |
|---|---|---|---|
| AX | reg/mem8 | AL | AH |
| DX:AX | reg/mem16 | AX | DX |
| EDX:EAX | reg/mem32 | EAX | EDX |
| RDX:RAX | reg/mem64 | RAX | RDX |
在执行DIV之前,必须将DX中的值清零!
IDIV(有符号整数除法)
符号扩展指令(CBW、CWD和CDQ)
CBW
将AL的符号位扩展到AH
CWD
将AX的符号位扩展到DX
CDQ
将EAX的符号位扩展到EDX
注意
指令DIV和IDIV后,所有算术运算的状态标志值都没有意义。
如果除法操作数产生的商无法装入目的操作数,则会导致除法溢出,这将引起处理器异常并暂停当前程序。使用32位除数和64位被除数可以减少出现除法溢出的概率。
扩展的加减法
ADC(带进位加法)
该指令的格式与ADD一样,且操作数的大小必须相同。
SBB(带借位减法)
ASCII和非压缩十进制算术运算
AAA(加法后的ASCII调整)
AAS(减法后的ASCII调整)
AAM(乘法后的ASCII调整)
AAD(除法前的ASCII调整)
压缩十进制的算数运算
DAA(加法后的十进制调整)
DAS(减法后的十进制调整)
高级过程
堆栈帧
堆栈参数
在32位模式下,堆栈参数总是由Windows API函数使用;而在64位模式下,Windows函数接收的是寄存器参数和堆栈参数的组合。
堆栈帧(或称活动记录)是一块堆栈的保留区域,用于存放被传递的参数、子例程的返回地址、局部变量以及被保存的寄存器。
创建堆栈帧的步骤:
- 如果有被传递的参数,则将其压入堆栈
- 调用子例程,使该子例程的返回地址被压入堆栈
- 当子例程开始执行时,EBP被压入堆栈
- 设置EBP等于ESP。从这时开始,EBP就作为该子例程所有参数的引用基址。
- 如果有局部变量,就递减ESP以便在堆栈中为这些变量预留空间
- 如果需要保存寄存器,就将其压入堆栈
程序的内存模型及其对参数传递规约的选择直接影响堆栈帧的结构。
寄存器参数的缺点
- 多年来,Microsoft在32位程序中采用的一种参数传递规约,称为fastcall:只要在调用子例程之前简单地将参数放入寄存器中,就会提升某些运行效率。
- 典型的参数寄存器有EAX、EBX、ECX和EDX,不常用的有EDI和ESI。
遗憾的是,这些寄存器也用于存放数据值,如循环计数值以及参与计算的操作数。因此在被过程调用之前,任何作为参数的寄存器必须先被压入堆栈,然后再向其赋值过程参数,并在过程返回后恢复其原始值。这些额外的入栈和出栈操作不仅会让代码混乱容易出错,还有可能消除性能优势。并且这样的错误不容易定位,需要耗费很多时间检查代码
- 典型的参数寄存器有EAX、EBX、ECX和EDX,不常用的有EDI和ESI。
- 另一种方式是将参数压入堆栈,但执行得慢一些。
在调用子例程时,两种常规类型的参数会被压入堆栈:
- 值参数(常量和变量的值)
- 引用参数(变量的地址)
值传递
当一个参数通过数值传递时,该值的副本会被压入堆栈。
.data val1 DWORD 5 val2 DWORD 6 .code push val2 push val1 call AddTwo 在执行CALL指令前,堆栈如下所示
| val2 | 6 | |
|---|---|---|
| val1 | 5 | <-RSP |
用C++编写的等效函数调用则为
讯享网int sum = AddTwo(val1, val2);
引用传递
通过引用来传递的参数包含的是对象的地址(偏移量)
push OFFSET val2 push OFFSET val1 call Swap 在调用Swap之前,堆栈如下所示
| offset(val2) | |
|---|---|
| offset(val1) | <-RSP |
在C/C++中,等效函数调用传递的是参数val1和val2的地址
讯享网Swap(&val1, &val2);
传递数组
高级语言总是通过引用向子例程传递数组,也就是说,它们将数组的地址压入堆栈,然后子例程从堆栈获得该地址,并用其访问数组。没用通过值来传递数组的原因显而易见,因为要将数组的每个元素分别压入堆栈,这种操作不仅速度很慢,而且会耗尽宝贵的堆栈空间。
一个传递数组的示例
.data array DWORD 50 DUP(?) .code push OFFSET array call ArrayFill 访问堆栈参数
在程序调用期间,高级语言有多种方式初始化和访问参数。以C和C++为例,程序以序言(prologue)开始,其中包含一些语句,用来保存EBP寄存器并将EBP指向栈顶。这些语句还可能将某些寄存器压入堆栈,并且在函数返回时恢复其值。在函数的收尾部分,恢复EBP寄存器,并用RET指令返回到主调程序。
讯享网int AddTwo(int x, int y) {
return x + y; }
用汇编实现
虽然但是,C调用规约和STDCALL调用规约都是32位的调用规约,下列代码中的参数依旧为64位的,64位应该遵循64位调用规约
C调用规约调用AddTwo
; x64 AddTwo proc push rbp mov rbp, rsp mov rax, [rbp + 16] add rax, [rbp + 24] pop rbp ret AddTwo endp main proc push y push x call AddTwo add rsp, 16 ; 往RSP指针上加16回到初始位置 main endp STDCALL调用规约下的AddTwo
讯享网; x64 AddTwo proc push rbp mov rbp, rsp mov rax, [rbp + 16] add rax, [rbp + 24] pop rbp ret 16 ; STDCALL调用规约有返回值 AddTwo endp main proc push y push x call AddTwo main endp
局部变量
局部变量在堆栈上创建,通常位于基址指针(BP)之下
x_local EQU DWORD PTR[ebp-4] y_local EQU DWORD PTR[ebp-8] MySub proc push ebp mov ebp, esp sub esp, 16 mov x_local, 10 mov y_local, 20 mov esp, ebp pop ebp ret MySub proc 引用参数
讯享网.data count = 20 array DWORD count DUP(?) arrayOffset DWORD OFFSET array .code fillZero proc push ebp mov ebp, esp pushad mov ecx, [ebp + 8] cmp ecx, 0 je Exit mov esi, [ebp+12] mov ax, 0 Fill: mov [esi], ax add esi, TYPE DWORD loop Fill Exit: popad pop ebp ret 8 fillZero endp main proc push OFFSET array push count call fillZero invoke ExitProcess, 0 main endp end main
LEA
LEA指令返回间接操作数的地址。
用OFFSET获取堆栈参数的地址是不可能的,因为OFFSET只适用于编译时的已知地址。
ENTER和LEAVE
ENTER指令为被调过程自动创建堆栈帧。第一个参数是为局部变量保留堆栈空间的字节数,第二个参数为指定过程的词法嵌套级
- 将EBP压入堆栈(push ebp)
- 将EBP设置为堆栈帧的基址(mov ebp, esp)
- 为局部变量保留空间(sub esp, numbytes)
enter 0, 0 ; 与下列语句等效 push ebp mov ebp, esp LEAVE结束一个过程的堆栈帧,恢复被调用时ESP和EBP的值。
LOCAL
ENTER的高级替代,通过名字声明一个或多个变量,并赋予其大小属性。它必须紧跟在PROC伪指令后面的行上。
讯享网LOCAL varlist
varlist是变量定义的列表,用逗号分隔表项,可跨越多行。
label:type 讯享网MySub proc local var1:BYTE, var2:WORD
递归
INVOKE、ADDR、PROC和PROTO
INVOKE
ADDR
PROC
label PROC [attributes] [USES reglist], paramter_list attributes是distance、langtype、visibility、prologuearg的任意内容
| 属性 | 描述 |
|---|---|
| distance | NEAR或FAR。指定汇编生成器生成的RET指令类型 |
| langtype | 指定调用规约。覆盖由.MODEL伪指令指定的语言 |
| visibility | 本过程对其它模块的可见性。PRIVATE、PUBLIC(默认)及EXPORT |
| prologuearg | 指定一些会影响序言和收尾代码生成的参数 |
PROTO
字符串和数组
字符串原语指令
MOVSB, MOVSW, MOVSD
| 指令 | 作用 | ESI和EDI增加或减少的值 |
|---|---|---|
| MOVSB | 传送字节 | 1 |
| MOVSW | 传送字 | 2 |
| MOVSD | 传送双字 | 4 |
CMPSB, CMPSW, CMPSD
比较字节,比较字,比较双字
若要比较多个双字,则清零方向标志(正向),ECX初始化,对CMPSD使用重复前缀
讯享网mov esi, OFFSET source mov edi, OFFSET target cld mov ecx, LENGTHOF source repe cmpsd
SCASB, SCASW, SCASD
将AL/AX/EAX中的值与EDI寻址的一个字节/字/双字进行比较。可用于在字符串或数组中寻找数值。结合REPE(REPZ)前缀,当ECX>0且AL/AX/EAX的值匹配于内存中每个连续的值时,就继续扫描字符串或数组。REPNE前缀也进行扫描,直到AL/AX/EAX与内存数值匹配或者ECX=0.
; 扫描是否有匹配字符 .data string BYTE "ABCDEFGHIJ", 0 .code mov edi, OFFSET string mov al, 'F' mov ecx, LENGTHOF string cld repne scasb jnz quit;ECX=0且没有找到 dec edi; 发现字符则EDI后退,EDI指向匹配字符后面一个的位置 STOSB, STOSW, STOSD
将AL/AX/EAX的内容存入EDI指向的内存偏移量处。EDI根据方向标志的状态递增或递减。与REP前缀使用,可用于实现同一个值填充字符串或数组的全部元素
LODSB, LODSW, LODSD
从ESI指向的内存地址向AL/AX/EAX装入字节/字/双字。ESI根据方向标志的状态进行递增或递减。LODS很少与REP前缀一起使用,因为装入累加器的值会覆盖原来的内容;一般被用于装入单个数值。
二维数组
行列顺序
行主序、列主序
基址-变址操作数
将两个寄存器的值相加,生成一个偏移地址
[base + index]
按主行序访问一个二维数组时,一般把行偏移量放在基址寄存器中,列偏移量放在变址寄存器中
讯享网; 计算一行之和 calc_row_sum PROC USES ebx ecx edx esi mul ecx add ebx, eax mov eax, 0 mov esi, 0 L1: movzx edx, BYTE PTR[ebx + esi] add eax, edx inc esi loop L1 ret calc_row_sum ENDP
基址-变址-位移操作数
结合一个基址寄存器、一个变址寄存器、一个位移,以及一个可选的比例因子来生成有效地址
[base + index + displacement]
displacement[base + index]
整数数组的查找和排序
冒泡排序
BubbleSort PROC USES eax ecx esi, pArray:PTR DWORD, ; 指向数组的指针 Count:DWORD ; 数组大小 mov ecx, Count dec ecx L1: push ecx ; 保存外循环计数 mov esi, pArray ; 指向第一个元素 L2: mov eax, [esi] cmp [esi+4], eax jg L3 ; [esi]<=[esi+4]则跳过交换 xchg eax, [esi+4] ; 交换 mov [esi], eax L3: add esi, 4 ; 前移指针 loop L2 ; 内循环 pop ecx ; 取出外循环计数值 loop L1 ; 外循环 ret BubbleSort ENDP 折半查找
讯享网
结构和宏
结构
定义结构
name STRUCT field-declarations name ENDS 为了获得最好的I/O性能,结构成员应按其数据类型进行地址对齐,否则CPU就会花费更多时间来访问这些成员。
| 成员类型 | 对齐方式 | 成员类型 | 对齐方式 |
|---|---|---|---|
| BYTE, SBYTE | 对齐到8位边界 | REAL4 | 对齐到32位边界 |
| WORD, SWORD | 对齐到16位边界 | REAL8 | 对齐到64位边界 |
| DWORD, SDWORD | 对齐到32位边界 | structure | 任何成员的最大对齐要求 |
| QWORD | 对齐到64位边界 | union | 第一个成员的对齐要求 |
声明结构对象
identifier structureType <initializer-list>
讯享网; example point1 COORD <5, 10> point2 COORD <> ; 默认的初始化值 point3 COORD {5, 10}
结构数组
; example NumPoints = 3 AllPoints COORD NumPoints DUP(<0, 0>) 对齐结构对象
讯享网; example .data ALIGN DWORD person Employee <>
引用结构对象
TYPE和SIZEOF操作符可以引用结构变量和结构名称
对成员的引用
; example .code mov dx, worker.Years OFFSET
获得结构中一个字段的地址
讯享网; example mov edx, OFFSET worker.LastName
间接和变址操作数
; example mov esi, OFFSET worker mov ax, (Employee PTR [esi]).Years 变址操作数
讯享网.data department Employee 5 DUP(<>) .code mov esi, TYPE Employee mov department[esi].Years, 4
结构包含结构
声明和使用联合
unionname UNION union-fields unionname ENDS 如果联合嵌套在结构内
讯享网structurename STRUCT structure-fields UNION unionname union-fields ENDS structurename ENDS
宏
概述
宏过程是一个命名的汇编语句块。当调用宏时,其代码的副本被直接插入到程序中,这种自动代码插入也被称为内联展开。
宏在汇编器的预处理阶段被展开。汇编器的预处理阶段对程序的源代码进行初始扫描,寻找任何用于源代码展开的特殊伪指令。在这个阶段中,预处理程序读取宏定义并扫描剩余的源代码。每当到了宏被调用的位置,汇编器就将宏的源代码插入到程序中。
汇编器在对任何宏调用进行汇编之前,必须先找到宏定义。如果程序定义了宏却从未调用,则编译后的程序中不会出现宏代码。
定义宏
宏定义通常出现在程序源代码的开始位置,或是放在独立的文件中,并用INCLUDE伪指令复制到程序里。
macroname MACRO parameter-1, paramter-2... statement-list ENDM 建议对宏名使用前缀m,形成易识别的名称,如mPutChar,mWriteString和mGotoxy。
宏形参
宏形参是命名的占位符,对应于主调程序传递的文本实参。
实参实际上可能是整数、变量名或其它值,但预处理程序将它们都当作文本。
形参不包含类型信息,所以,汇编器的预处理程序不检查实参类型是否正确。如果发生类型不匹配,则会在宏展开之后,被汇编器捕获。
调用宏
讯享网macro argument-1, argument-2,...
其它宏特性
必要形参
使用REQ限定符,可以指定必须的宏形参。如果一个宏有多个必要形参,则每个都要使用REQ限定符。
宏注释
宏定义中的注释行一边出现在每次宏展开的时候。如果项忽略宏展开时的注释,需要使用双分号(;;)。
ECHO伪指令
ECHO伪指令写一个字符串到标准输出。
Visual Studio控制台窗口不会捕获ECHO伪指令的输出,除非在建立程序时将其配置为生成详细输出。一种方法是Tools->Options->Peojects and Solution->Build and Run->MSBuild project build output verbosity选择Detailed。另一种方法是用命令提示符并汇编程序。
虽然但是,我照着这个操作坐下来还是没看到ECHO的输出
LOCAL
下列代码会产生错误
makeString MACRO text .data string BYTE text, 0 ENDM makeString "Hello" makeString "Goodbye" 讯享网makeString "Hello" 1 .data 1 string BYTE "Hello", 0 makeString "Goodbye" 1 .data 1 string BYTE "Goodbye", 0
为了避免标号重定义带来的问题,可以对宏定义内的标号应用LOCAL伪指令。
makeString MACRO text .data LOCAL string BYTE text, 0 ENDM 生成出的代码会替换成位移的标识符
讯享网makeString "Hello" 1 .data 1 ??0000 BYTE "Hello", 0 makeString "Goodbye" 1 .data 1 ??0001 BYTE "Goodbye", 0
嵌套宏
被其他宏调用的宏称为嵌套宏。
在创建宏时采用模块化的方式,并保持宏的简短性,以便将其组合成更复杂的宏。这样做有助于减少程序中的代码复制量。
条件汇编伪指令
| 伪指令 | 描述 |
|---|---|
| IF expression | 若expression为真则允许汇编 |
| IFB | 若argument为空则允许汇编,实参名必须用尖括号括起来 |
| IFNT | 若argument为非空则允许汇编,实参名必须用尖括号括起来 |
| IFIDN, | 若两个实参相等则允许汇编。采用区分大小写的比较 |
| IFIDNI, | 若两个实参亮灯则允许汇编。采用不区分大小写的比较 |
| IFDIF, | 若两个实参不相等则允许汇编,采用区分大小写的比较 |
| IFDIFI, | 若两个实参不相等则允许汇编,采用不区分大小写的比较 |
| IFDEF name | 若name已定义则允许汇编 |
| IFNDEF name | 若name未定义则允许汇编 |
| ENDIF | 结束以条件汇编伪指令开始的伪代码 |
| ELSE | 若条件为真,则终止汇编之前的语句;若条件为假,则ELSE汇编语句直到下一个ENDIF |
| ELSEIF expression | 若之前条件伪指令指定的条件为假,而当前表达式为真,则汇编全部语句直到出现ENDIF |
| EXITM | 立即退出宏,阻止任何后续宏语句的展开 |
检查缺失的参数
通常,若宏接收到空实参,则预处理程序在宏展开时会出现无效指令。
为了防止因操作数缺失而导致的错误,可以使用IFB(if blank)伪指令,若宏实参为空,则其返回值为真。IFNB(if not blank),若宏实参不为空,则其返回值为真。
默认参数初始化值
paramename := <agrument> 讯享网; example mWriteln MACRO text:=<" "> mWrite text call Crlf ENDM
布尔表达式
LT 小于
GT 大于
EQ 等于
NE 不等于
LE 小于等于
GE 大于等于
特殊操作符
| 操作符 | 描述 |
|---|---|
| & | 替换操作符 |
| <> | 字面文本操作符 |
| ! | 字面字符操作符 |
| % | 展开操作符 |
替换操作符
替换操作符解决对宏内参数名的有歧义引用
; 调用示例 .code mShowRegister ECX 讯享网mShowRegister MACRO regName .data tempStr BYTE " ®Name=", 0
展开操作符
展开操作符展开文本宏或将常量表达式转换为其文本形式。当与TEXTEQU一起使用时,%操作符计算常量表达式,并将结果转换为整数,
count = 10 sumVal TEXTEQU &(5 + count) 如果宏要求的实参是整数常量,%操作符就为传递一个整数表达式提供了灵活性。
讯享网mGotoxyConst %(5 * 10), %(3 + 4)
当展开操作符是一行源代码的第一个字符时,它指示预处理程序展开该行上的所有文本宏和宏函数。
TempStr TEXTEQU %(SIZEOF array) % ECHO The array cotains TempStr bytes 产生的输出
The array contains 32 bytes
字面文本操作符
字面文本操作符将一个或多个字符和符号组合成一个字面文本,以防止预处理程序把列表中的成员解释为独立的参数。当字符串包含特殊字符时,该操作符尤其有用,否则,如逗号、百分号、与号以及分号这些特殊的字符就有可能被解释为有分隔符或者其它操作符。
讯享网mWrite <"Line three", 0dh, 0ah>
字面字符操作符
字面字符操作符的目的与字面文本操作符的几乎完全一样。
BadYValue TEXTEQU <Warning: Y-coordinate is !> 24> 宏函数
宏函数类似于宏过程,也为一列汇编语言语句赋予一个名字。不同的地方在于,宏函数总是通过EXITM伪指令返回一个常量(整数或字符串)。
讯享网IsDefined MACRO symbol IFDEF symbol EXITM <-1> ELSE EXITM <0> ENDIF ENDM
调用宏函数时,其实参列表必须用括号括起来
ReadMode = 1 讯享网IF IsDefined(RealMode) mov ax, @data mov ds, ax ENDIF
定义重复语句块
WHILE
WHILE constExpression statements ENDM REPEAT
讯享网REPEAT constExpression statements ENDM
FOR
FOR parameter, <arg1, arg2, arg3, ...> statements ENDM 在第一次循环迭代中,parameter取arg1的值;在第二次循环迭代中,parameter取arg2的值;以此类推,直到列表的最后一个实参。
FORC
讯享网FORC parameter, <string> statements ENDM
在第一次循环迭代中,parameter等于字符串的第一个字符;在第二次循环迭代中,parameter等于字符串的第二个字符;以此类推,直到字符串的结尾。
MS-Windows编程
Win32控制台编程
背景信息
控制台有一个输入缓冲区以及一个或多个屏幕缓冲区
- 输入缓冲区包含一组输入记录,每个记录包含一个关于输入事件的数据。键盘输入、鼠标点击、用户对控制台窗口大小的调整等都是输入事件。
- 屏幕缓冲区是一个字符和颜色数据的二维数组,它会影响控制台窗口中文本的外观。
Win32 API参考信息
微软文档,请
MSDN
字符集和Windows API函数
当调用Win32 API中的函数时,使用两类字符集:8位的ASCII/ANSI字符集和16位的Unicode字符集。
用于处理文本的Win32函数通常有两种版本:一种以字母A结尾(用于8位ANSI字符),另一种以W结尾(用于宽字符集,包括Unicode)。下面是一个例子:
- WriteConsoleA
- WriteConsoleW
在近期的所有Windows版本中,Unicode都是原生字符集。例如,如果调用函数WriteConsoleA,则操作系统就会将字符从ANSI转换为Unicode,并调用WriteConsoleW。
高级别和低级别访问
- 高级控制台函数从控制台的输入缓冲区读取字符流,并将字符数据写入控制台的屏幕缓冲区。输入和输出都可以重定向到文本文件。
- 低级控制台函数检索键盘和鼠标事件,以及用于与控制台窗口交互的详细信息。这些函数还允许对窗口的大小和位置以及文本颜色进行详细控制。
Windows数据类型
Win32函数使用C/C++程序员的函数声明来制作文档。所有函数的参数类型要么基于标准C类型,要么基于MS-Windows预定义的类型之一。注意,这是针对32位,只能作为大致参考,64位的相关说明往下翻。
| MS-Windows类型 | MASM类型 | 描述 |
|---|---|---|
| BOOL, BOOLEAN | DWORD | 布尔值 |
| BYTE | BYTE | 8位无符号整数 |
| CHAR | BYTE | 8位Windows ANSI字符 |
| COLORREF | DWORD | 作为颜色值的32位数值 |
| DWORD | DWORD | 32位无符号整数 |
| HANDLE | DWORD | 对象句柄 |
| HFILE | DWORD | 用OpenFile打开的文件句柄 |
| INT | SDWORD | 32位有符号整数 |
| LONG | SDWORD | 32位有符号整数 |
| LPARAM | DWORD | 消息参数,由窗口过程和回调函数使用 |
| LPCSTR | PTR BYTE | 32位指针,指向由8位Windows(ANSI)字符组成的以空结束的字符串常量 |
| LPCVOID | DWORD | 指向任何类型常量的指针 |
| LPSTR | PTR BYTE | 32位指针,指向由8位Windows(ANSI)字符组成的以空结束的字符串 |
| LPCTSTR | PTR WORD | 32位指针,指向对Unicode和双字节字符集可移植的字符串常量 |
| LPTSTR | PTR WORD | 32位指针,指向对Unicode和双字节字符集可移植的字符串 |
| LPVOID | DWORD | 32位指针,指向未指定类型 |
| LRESULT | DWORD | 窗口过程和回调函数返回的32位数值 |
| SIZE_T | DWORD | 一个指针可以指向的最大字节数 |
| UNIT | DWORD | 32位位无符号整数 |
| WNDPROC | DWORD | 32位指针,指向窗口过程 |
| WORD | WORD | 16位无符号整数 |
| WPARAM | DWORD | 作为参数传递给窗口过程或回调函数的32位值 |
Win32控制台函数
MSDN,请
Win32控制台函数
Win32 API函数不保存EAX、EBX、ECX和EDX!
控制台输入
获取句柄时的参数应为-10
控制台输入缓冲区
像ReadConsole这样的高级输入函数会对输入数据进行过滤和处理,并只返回一个字符流。
ReadConsoleA&ReadConsoleW
当调用ReadConsole时,在输入缓冲区中要包含两个额外的字节用来存放行结束字符。也就是说,下面返回的lpNumberOfCharsRead会比用户输入的值大2.
ReadConsole语法
BOOL WINAPI ReadConsole( // 控制台输入缓冲区的句柄,可以用GetStdHandle返回。该句柄必须具有 GENERIC_READ 访问权限。 有关详细信息,请参阅控制台缓冲区安全性和访问权限。 _In_ HANDLE hConsoleInput, // 指向接收从控制台输入缓冲区读取的数据的缓冲区的指针。 _Out_ LPVOID lpBuffer, // 要读取的字符数。 lpBuffer 参数指向的缓冲区的大小应至少nNumberOfCharsToRead * sizeof(TCHAR)为字节。 _In_ DWORD nNumberOfCharsToRead, // 指向接收实际读取的字符数的变量的指针。 _Out_ LPDWORD lpNumberOfCharsRead, // 指向 CONSOLE_READCONSOLE_CONTROL 结构的指针,该结构指定一个控制字符以指示读取操作结束。 此参数可以为 NULL。 // 默认情况下,此参数需要 Unicode 输入。 对于 ANSI 模式,请将此参数设置为 NULL。 // 一般放0不用管 _In_opt_ LPVOID pInputControl ); 返回值
如果该函数成功,则返回值为非零值。
如果函数失败,则返回值为零。 要获得更多的错误信息,请调用 GetLastError。
控制台输出
获取句柄时的参数应为-11
WriteConsole
向控制台窗口的当前光标位置写一个字符串,并将光标停留在紧跟最后一个字符后边的位置上.
讯享网BOOL WINAPI WriteConsole( _In_ HANDLE hConsoleOutput, _In_ const VOID *lpBuffer, _In_ DWORD nNumberOfCharsToWrite, _Out_opt_ LPDWORD lpNumberOfCharsWritten, // 默认为0即可 _Reserved_ LPVOID lpReserved );
WriteConsoleOutputCharacter
从指定位置开始,向控制台屏幕缓冲区的连续单元复制一组字符
BOOL WINAPI WriteConsoleOutputCharacter( _In_ HANDLE hConsoleOutput, // 指向缓冲区的指针 _In_ LPCTSTR lpCharacter, // 缓冲区大小 _In_ DWORD nLength, // 第一个单元的坐标 _In_ COORD dwWriteCoord, // 输出的数量 _Out_ LPDWORD lpNumberOfCharsWritten ); 读写文件
使用64位Windows API
- 输入和输出句柄都是64位长的
- 在调用系统函数之前,主调程序必须保留至少32字节的影子空间。
- 当调用系统函数时,RSP应对齐到16-字节地址边界(末位数字是0的任何十六进制地址)。Win64 API没有强制执行这个规则,而在应用程序中对堆栈对齐进行精确控制往往是困难的。
- 在系统调用返回之后,主调程序必须恢复RSP的初始值,方法是将其加上函数调用前减去的数值。执行RET时,ESP最终必须指向子例程的返回地址。
- 整数参数用64位寄存器传递
- 不允许使用INVOKE。
- 系统函数使用RAX返回64位整数值
图形化Windows应用程序
| 文件名 | 描述 |
|---|---|
| WinApp.asm | 程序源代码 |
| GraphWin.inc | 头文件,包含了该程序要使用的结构、常量和函数原型 |
| kernel32.lib | MS-Windows API链接库 |
| user32.lib | 其它MS-Windows API函数 |
启动过程
通常被命名为WinMain.
- 获取当前进程句柄
GetModuleHandleA,进程句柄在后续会用到,需要保存 - 加载程序的图标和光标
LoadIconA和LoadCursorA - 注册程序的窗口
RegisterClassA - 创建窗口
CreateWindowExA - 显示并更新窗口
ShowWindow然后UpdateWindow - 开始接受和发送消息
GetMessageA,收到的Message需要通过DispatchMessageA转发给消息处理过程
消息处理过程
一般命名为WinProc
讯享网WinProc PROC, hWnd:DWORD, localMsg:DWORD, wParam:DWORD, lParam:DWORD
除此之外还有一些其它的过程,比如MessageBoxA
MessageBoxA PROTO, hWnd:DWORD, lpText:PTR BYTE, lpCaption:PTR BYTE, uType:DWORD 动态内存分配
动态内存分配也称堆分配,用于在创建对象、数组以及其它结构时预留内存。
C、C++、Java都有内置的运行时堆管理器来处理程序请求的存储空间的分配和释放。堆管理器一般是从操作系统中分配一大块内存,并为存储块指针创建空闲列表。当收到一个分配请求时,堆管理器就将适当大小的内存块标记为已预留,并返回指向该块的指针。之后,当接收到对同一个块的删除请求时,堆就释放该内存块,将其归还到空闲列表。每次接收到新的分配请求时,堆管理器就会扫描该空闲列表,寻找第一个容量足够大的可用内存块来响应该请求。
汇编语言有两种方式进行动态分配
- 进行系统调用,从操作系统获得内存块
- 自己实现堆管理器来服务对较小对象的请求
系统调用获得内存块
| 函数 | 描述 |
|---|---|
| GetProcessHeap | 返回程序现存堆区的32位整数句柄。成功返回句柄,失败返回NULL |
| HeapAlloc | 从堆中分配一块内存。成功返回地址,失败返回NULL |
| HeapCreate | 创建一个新的堆,并使其对主调程序可用。成功返回句柄,失败返回NULL |
| HeapDestroy | 销毁指定的堆,并使句柄无效。成功返回0 |
| HeapFree | 释放之前从堆中分配的内存块,该内存块由其地址和堆句柄标识。成功返回0 |
| HeapReAlloc | 对堆中的内存块进行再分配和调整大小。成功返回地址,失败且没有指定HEAP_GENERATE_EXCEPTIONS则返回NULL |
| HeapSize | 返回之前通过HeapAlloc或HeapReAlloc分配的内存块的大小。成功返回以字节计的被分配的内存块的大小,失败返回SIZE_T-1(SIZE_T等于指针能指向的最大字节数,如0xFFFFFFFFFFFE) |
32位x86存储管理
线性地址是整数,用于引用一个内存位置。如果禁用分页特性,则线性地址可以是目标数据的物理地址
物理地址是指计算机实际的随机访问存储器区的一个地址
分页
分页使计算机能运行一组无法装入内存的程序。
处理器在初始时只将程序的一部分加载到内存,而程序的其余部分仍然保留在硬盘上。程序使用的内存被划分成小单位,称为页,通常每页大小为4KB。
当每个程序运行时,处理器有选择地从内存中卸载不活跃的页,并加载其它立即就需要的页。
操作系统会维护一个页目录和一组页表来持续跟踪记录当前内存中所有程序使用的页。
当试图访问线性地址空间时,处理器会自动进行页转换。如果请求的页不在内存中,处理器就将程序中断并发出页故障,操作系统将被请求的页复制到内存,继续执行。
逻辑地址转换为线性地址
将段值与变量的偏移量相结合,生成线性地址

页转换
三种结构:页目录、页表、页
对于32位的情况,线性地址前十位是页目录,中间十位是页表,后十二位是偏移量

浮点数处理和指令编码
浮点数的二进制表示
浮点十进制数包含三个组成部分:符号、有效数字及阶数
IEEE二进制浮点数表示
| 单精度 | 32位:1位符号位,8位阶数,23位有效数字的小数部分。大致的规格化范围:2-126~2127 |
| 双精度 | 64位:1位符号位,11位结束,52位有效数字的小数部分。大致的规格化范围:2-1022~21023 |
| 扩展双精度 | 80位:1位符号位,15位阶数,1位整数部分,63位有效数字的小数部分。大致的规格化范围:2-16382~216384。也称为扩展实数。 |
阶数
单精度数的阶数存储为8位无符号数,并带有127的偏移,即该数的实际阶数必须加上127。
| 阶数(E) | 偏移阶数(E+127) | 二进制 |
|---|---|---|
| +127 | 254 | |
| 0 | 127 | 0 |
| -126 | 1 | 00000001 |
规格化二进制浮点数
大多数二进制浮点数都以规格化形式存放,以便将有效数字的精度最大化。给定任意二进制浮点数,可用通过将二进制小数点移位直至小数点左边只有一个“1”的方法对其进行规格化。阶数表示的是二进制小数点向左或向右移动的位数。
- 去规格化
- 规格化
创建IEEE表示
IEEE规范包括了若干种实数和非数值编码
- 正零和负零
- 非规格化有限数
- 规格化有限数
- 正无穷和负无穷
- 非数值(NaN(Not a Number))
- 不定数
| 数值 | 符号、阶数和有效数字 |
|---|---|
| 正零 | 0 00000000 0000000000000000000000 |
| 负零 | 1 00000000 00000000000000000000000 |
| 正无穷 | 0 00000000000000000000000 |
| 负无穷 | 1 00000000000000000000000 |
| QNaN | x 0xxxxxxxxxxxxxxxxxxxxxx |
| SNaN | x 0xxxxxxxxxxxxxxxxxxxxxx |
浮点单元
Intel 8086处理器的设计使之只能处理整数算术运算,尽管可以通过软件来模拟浮点运算,但性能损失严重。Intel发售了一款独立的浮点协处理器芯片8087,并将它与每一代处理器一起升级。随着Intel 486的出现,浮点硬件被集成到主CPU中,称为FPU。
x87
FPU寄存器栈
FPU 不使用通用寄存器 ,它有自己的一组寄存器,称为寄存器栈 (register stack)。数值从内存加载到寄存器栈,然后执行计算,再将堆栈数值保存到内存。
FPU 指令用后缀 (postfix) 形式计算算术表达式。如中缀表达式(A+B)*C等效的后缀表达式 A B + C *。后缀表达式的好处是不需要使用括号记录优先级。
在计算后缀表达式的过程中,用表达式堆栈来存放中间值。
计算后缀表达式5 6 * 4 -:

FPU 有 8 个独立的、可寻址的 80 位数据寄存器 R0〜R7,合称为寄存器栈。寄存器栈的栈顶TOP表示为一个三位的字段,当TOP等于011时,表示栈顶为R3,也被称为ST(0)或ST。

如果加载到堆栈的数值覆盖了寄存器栈内原有的数据,就会产生一个浮点异常(floating-point exception)。
专用寄存器
FPU有6个专用寄存器
- 操作码寄存器
- 控制寄存器
- 状态寄存器
- 标志寄存器
- 最后指令指针寄存器
- 最后数据指针寄存器

舍入
FPU 尝试从浮点计算中产生无限精确的结果。但是,在很多情况下这是不可能的,因为目标操作数可能无法精确表示计算结果。
四种舍入方法
- 舍入到最接近的偶数:舍入结果最接近于无限精确的结果(如果两个值同样接近,则取偶数值(LSB=0))
- 向 − ∞ -\infin −∞舍入:舍入结果小于或等于无限精确的结果
- 向 + ∞ +\infin +∞舍入:舍入结果大于或等于无限精确的结果
- 向 0 0 0舍入(截断法):舍入结果的绝对值小于或等于无限精确的结果
FPU控制字
- 00
舍入到最接近的偶数(默认)
- 01
向负无穷舍入
- 10
向正无穷舍入
- 11
向0舍入
浮点异常
6类异常条件
- #I(无效操作)
- #Z(用零除)
- #D(非规格化操作数)
- #O(数值上溢)
- #U(数值下溢)
- #P(不精确精度)
前三个在算术运算发生前进行检测,后三个在运算发生后检测。
每种异常都有对应的标志位和屏蔽位。当检测到浮点异常时,处理器将与之匹配的标志位置 1。每个被处理器标记的异常都有两种可能的操作:
- 如果相应的屏蔽位置 1,那么处理器自动处理异常并继续执行程序。
- 如果相应的屏蔽位清 0,那么处理器将调用软件异常处理程序。
大多数程序普遍都可以接受处理器的屏蔽(自动)响应。如果应用程序需要特殊响应,那么可以使用自定义异常处理程序。一条指令能触发多个异常,因此处理器要持续保存自上一次异常清零后所发生的全部异常。完成一系列计算后,可以检测是否发生了异常。
浮点指令集
- 数据传送
- 基本算术运算
- 比较
- 超越函数
- 常数加载(仅对专门预定义的常数)
- x87 FPU控制
- x87 FPU和SIMD状态管理
浮点指令名用字母F开头,以区别于CPU指令。指令助记符的第二个字母(通常为 B 或 I)指明如何解释内存操作数:B 表示 BCD 操作数,I 表示二进制整数操作数。如果这两个字母都没有使用,则内存操作数将被认为是实数。
FINIT(初始化)
将FPU控制字设置为037F,屏蔽了所有的浮点异常,并将舍入模式设置为最近偶数,将计算精度设置为64位。
FLD(加载浮点数值)
将浮点操作数复制到 FPU 堆栈栈顶(称为 ST(0))。操作数可以是 32 位、64 位、80 位的内存操作数(REAL4、REAL8、REAL10)或另一个 FPU 寄存器。
FLD支持的内存操作数类型与 MOV 指令一致(间接、变址、基址-变址等)。
讯享网FLD m32fp FLD m64fp FLD m80fp FLD ST(i)
FILD(加载Integer)
FILD(加载整数)指令将 16 位、32 位或 64 位有符号整数源操作数转换为双精度浮点数,并加载到 ST(0)。源操作数符号保留。
FILD 支持的内存操作数类型与 MOV 指令一致(间接、变址、基址-变址等)。
加载常数
- FLD1 加载1.0
- FLDL2T 加载 log 2 10 \log_210 log210
- FLDL2E 加载 log 2 e \log_2e log2e
- FLDPI 加载 π \pi π
- FLDLG2 加载 log 10 2 \log_{10}2 log102
- FLDLN2 加载 log e 2 \log_e2 loge2
- FLDZ 加载0
FST、FSTP(保存浮点数值)
FST指令将浮点操作数从 FPU 栈顶复制到内存。FST 支持的内存操作数类型与 FLD 一致。FST不弹出堆栈。
FSTP将 ST(0) 的值复制到内存并将 ST(0) 弹出堆栈。
算术运算指令
FCHS
符号取反
FABS
得到绝对值
FADD
相加。其中,m32fp 是 REAL4 内存操作数,m64fp 即是 REAL8 内存操作数,i 是寄存器编号:
FADD FADD m32fp FADD m64fp FADD ST(0), ST(i) FADD ST(i) , ST(0) 讯享网FADD ; 如果 FADD 没有操作数,则 ST(0)与 ST(1)相加,结果暂存在 ST(l)。然后 ST(0) 弹出堆栈,把加法结果保留在栈顶。
FADDP
相加并弹出堆栈
FIADD
加上整数
FSUB
FSUBP
FISUB
FMUL
FMULP
FIMUL
FDIV
FDIVP
FIDIV
比较浮点数值
FCOM
比较
| 指令 | 描述 |
|---|---|
| FCOM | 比较ST(0)与ST(1) |
| FCOM m32fp | 比较ST(0)与m32fp |
| FCOM m64fp | 比较ST(0)与m64fp |
| FCOM ST(i) | 比较ST(0)与ST(i) |
FCOMP
比较并弹出
FCOMPP
与FCOMP相同,但有两次弹出
| 条件 | C3(零标志) | C2(奇偶标志) | C0(进位标志) | 使用的条件跳转指令 |
|---|---|---|---|---|
| ST(0) > SRC | 0 | 0 | 0 | JA,JNBE |
| ST(0) < SRC | 0 | 0 | 1 | JB,JNAE |
| ST(0) = SRC | 1 | 0 | 0 | JE,JZ |
| 未规定 | 1 | 1 | 1 | (无) |
两个步骤
- 用FNSTSW指令将FPU状态字送入AX
- 用SAHF指令将AH复制到EFLAGS寄存器
异常同步
整数 (CPU) 和 FPU 是相互独立的单元,因此,在执行整数和系统指令的同时可以执行浮点指令。这个功能被称为并行性 (concurrency),当发生未屏蔽的浮点异常时,它可能是个潜在的问题。反之,已屏蔽异常则不成问题,因为,FPU 总是可以完成当前操作并保存结果。
发生未屏蔽异常时,中断当前的浮点指令,FPU 发异常事件信号。当下一条浮点指令或 FWAIT(WAIT) 指令将要执行时,FPU 检查待处理的异常。如果发现有这样的异常,FPU 就调用浮点异常处理程序(子程序)。
如果引发异常的浮点指令后面跟的是整数或系统指令,指令不会检查待处理异常,它们会立即执行。假设第一条指令将其输出送入一个内存操作数,而第二条指令又要修改同一个内存操作数,那么异常处理程序就不能正确执行。
设置 WAIT 和 FWAIT 指令是为了在执行下一条指令之前,强制处理器检查待处理且未屏蔽的浮点异常。这两条指令中的任一条都可以解决这种潜在的同步问题,直到异常处理程序结束。
屏蔽和非屏蔽异常
默认情况下,异常是被屏蔽的,因此,当出现浮点异常时,处理器分配一个默认值为结果,并继续平稳地工作。
如果 FPU 控制字没有屏蔽异常,那么处理器就会试着执行合适的异常处理程序。清除 FPU 控制字中的相应位就可以实现异常的未屏蔽操作。
| 位 | 描述 |
|---|---|
| 0 | 无效操作异常屏蔽 |
| 1 | 非规格化操作数异常屏蔽 |
| 2 | 除零异常屏蔽 |
| 3 | 上溢异常屏蔽 |
| 4 | 下溢异常屏蔽 |
| 5 | 精度异常屏蔽 |
| 8~9 | 精度控制 |
| 10~11 | 舍入控制 |
| 12 | 无穷控制 |
不想屏蔽除零异常, 则需要
- 将 FPU 控制字保存到 16 位变量。
- 清除位 2(除零标志位)
- 将变量加载回控制字。
x86指令编码
指令格式

单字节指令
| 指令 | 操作码 |
|---|---|
| AAA | 37 |
| AAS | 3F |
| CBW | 98 |
| LODSB | AC |
| XLAT | D7 |
| INC DX | 42 |
寄存器模式指令
高级语言接口
Visual C++命令行选项
| 命令行 | 列表文件的内容 |
|---|---|
| /FA | 只有汇编文件 |
| /FAc | 汇编文件和机器码 |
| /FAs | 汇编文件和源代码 |
| /FAcs | 汇编文件、机器码以及源代码 |
内联汇编代码
__asm statement __asm { statement-1 statement-2 ... statement-n } 尽量避免使用汇编风格的注释,因为可能干扰到C宏
讯享网__asm { ; text // text /* text */ }
内联汇编不能使用
- 数据定义伪指令
- 除PTR外的汇编器操作符
- STRUCT、RECORD、WIDTH以及MASK
- 宏伪指令和宏操作符
- 通过名字引用段
汇编语言代码链接到C/C++
方法
- 启用MASM
- 在VS解决方案中右键汇编文件,属性,”从生成中排除“改为”否“,“项类型”改为“Microsoft Macro Assembler”
- 编写汇编文件
- 添加头文件,在头文件中使用
extern引入函数,如果是C++,使用extern "C" - 引用函数
参数传递
按照RCX、RDX、R8、R9的顺序取参数,不要直接引用参数
返回值
常见的情况
- 整数用单个寄存器或寄存器组返回
- 主调程序可以在堆栈中为函数返回值预留空间
- 从函数返回前,浮点数通常被压入处理器的浮点堆栈
Microsoft Visual C++函数如何返回数值
- bool和char用AL返回
- short int用AX返回
- int和long int用EAX返回
- 指针用EAX返回
- float、double和long double分别以4字节、8字节和10字节数值压入浮点堆栈
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/122789.html