
随着视频中基于图像和手势识别、语音识别、自然语言处理、推荐系统等领域的应用程序和服务越来越多,对高性能深度学习(DL)训练的需求正在加速增长。Habana® Gaudi®AI 处理器旨在最大限度地提高训练吞吐量和效率,同时为开发人员提供可扩展到许多工作负载和系统的优化软件和工具。Habana Gaudi软件的开发考虑到了最终用户,提供了多功能性和易于编程来满足用户专有模型的独特需求,同时允许将现有模型简单无缝地过渡到Gaudi。我们想让您开始使用Habana的Gaudi HPU(Habana处理器单元)。有许多新用户和现有用户可能有在GPU或CPU上运行工作负载的经验,本文的目标是引导您完成将现有AI工作负载和模型迁移到Gaudi HPU的过程。我们将向您介绍硬件架构、软件堆栈的基础知识,
Gaudi 架构和Habana SynapseAI®软件套件
我们将从基本架构的概述开始。Gaudi旨在加速DL训练工作负载。其异构架构包括一组完全可编程的张量处理核心(TPC)及其相关的开发工具和库,以及一个可配置的矩阵数学引擎。
TPC是一个VLIW SIMD处理器,具有为训练工作负载量身定制的指令集和硬件。它是可编程的,为用户提供了最大的创新灵活性,以及许多面向工作负载的功能,例如:
- GEMM运行加速
- 张量寻址
- 延迟隐藏功能
- 随机数生成
- 特殊功能的高级实现
TPC原生支持以下数据类型:FP32、BF16、INT32、INT16、INT8、UINT32、UINT16和UINT8。
Gaudi存储器架构在每个TPC中包括片上SRAM和本地存储器。此外,芯片封装集成了4个HBM器件,提供32GB容量和1TB/s带宽。PCIe接口提供主机接口,同时支持3.0代和4.0代模式。
Gaudi是第一个在片上集成RDMA over Converged Ethernet (RoCE v2)引擎的DL训练处理器。凭借高达2 Tb/s的双向吞吐量,这些引擎在训练过程中所需的处理器间通信中发挥着关键作用。RoCE的这种原生集成允许客户在服务器和机架内部使用相同的扩展技术(纵向扩展),以及跨机架扩展(横向扩展)。这些可以直接在Gaudi处理器之间连接,也可以通过任意数量的标准以太网交换机连接。图1显示了硬件框图:

图 1. Gaudi HPU框图

SynapseAI软件套件旨在促进在Habana的Gaudi加速器上进行高性能DL训练,可将神经网络拓扑高效地映射到Gaudi硬件上。软件堆栈包括Habana的图形编译器和运行时、TPC内核库、固件和驱动程序,以及用于定制内核开发的TPC SDK和SynapseAI Profiler 等开发人员工具。SynapseAI与流行的框架、TensorFlow和PyTorch集成,并针对Gaudi进行了性能优化。图2显示了SynapseAI软件套件的组件。为了轻松地将SynapseAI软件集成到您的工作环境中,Habana为TensorFlow和PyTorch提供了一组Docker镜像,其中包括创建运行模型的环境所需的所有成分。我们将探索如何将这些库集成到您的模型中。
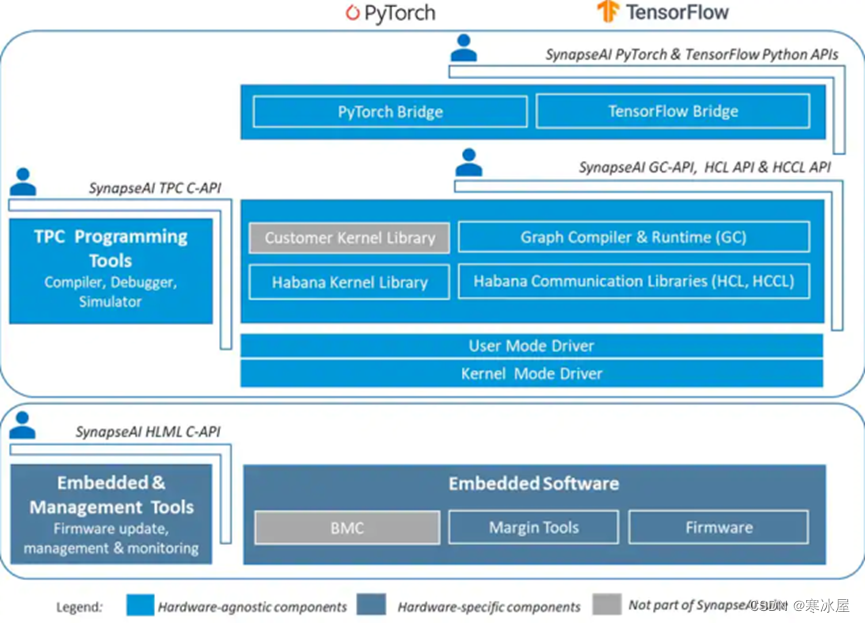
图 2. SynapseAI软件堆栈
设置环境
在本节中,我们将介绍如何设置环境,然后添加确保Gaudi HPU被框架识别并可以开始在您的模型中执行操作所需的简单步骤。除了Docker镜像之外,Habana在我们的ModelReferences GitHub存储库中还有一组参考模型和示例,可用作向模型添加适当组件的指南。
开始的第一步是确保您拥有完整的构建环境,其中包括Habana驱动程序、SynapseAI软件堆栈和框架。在大多数情况下,确保创建完整环境的**方法是使用Habana提供的预构建Docker镜像,这些镜像可在我们的Software Vault中找到。这些Docker镜像包含单节点和横向扩展二进制文件,不需要额外的安装步骤。如果您在基于云的环境中使用Gaudi,请务必选择您的云服务提供商提供的Habana Gaudi镜像,该镜像包含完整的驱动程序和相关框架。对于需要独立安装完整驱动程序和SynapseAI软件堆栈(作为本地安装)的用户,您可以参考专用的安装和安装GitHub存储库以获取详细说明。第二步是加载Habana库并以Gaudi HPU设备为目标。我们将在下一节解释如何为TensorFlow和PyTorch执行此操作
TensorFlow入门
对于TensorFlow,Habana将TensorFlow框架与SynapseAI集成到一个插件中,使用 tf.load_library和tf.load_op_library调用库模块和自定义操作/内核。框架集成包括三个主要组件:
- SynapseAI助手
- 设备
- 图形传递
TensorFlow框架控制图形构建或图形执行所需的大部分对象。SynapseAI允许用户在设备上创建、编译和启动图形。图形传递库通过模式匹配、标记、分割和封装(PAMSEN)操作优化TensorFlow图。它旨在操纵TensorFlow图以充分利用Gaudi的硬件资源。给定具有Gaudi实现的图形节点集合,PAMSEN尝试合并尽可能多的图形节点,同时保持图形的正确性。通过保留图语义并自动发现可以融合到一个实体中的子图,PAMSEN提供了与原生TensorFlow相当(或更好)的性能。
要准备模型,您必须加载Habana模块库。调用位于library_loader.py下的load_habana_module()。此函数加载在TensorFlow级别使用Gaudi HPU所需的Habana库:
import tensorflow as tf from habana_frameworks.tensorflow import load_habana_module load_habana_module() tf.compat.v1.disable_eager_execution() # if using tf.session讯享网
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/122161.html