
从机器学习算法本身来看,可分为监督学习、非监督学习、半监督学习、增强学习。
针对于本次自学的内容,主要以回归、分类的集成学习问题为主,因此主要学习监督学习:
监督学习:给机器的训练数据拥有标记或标签的学习方式是监督学习。监督学习主要处理分类、回归问题,最常见的监督学习算法主要有以下几种:
1. 朴素贝叶斯(Naive Bayes Classifier)
朴素贝叶斯算法(NBC) 是应用最为广泛的分类算法之一。NBC假设了数据集属性之间是相互独立的,常用于文本分类。
2. 决策树(Decision Tree)
决策树算法采用树形结构,使用层层推理来实现最终的分类。
决策树通常由根节点、内部节点、叶节点三个元素构成,ID3、C4.5、CART是决策树常用的三种典型算法。
讯享网3. 支持向量机(SVM)
支持向量机把分类问题转化为寻找分类平面的问题,并通过最大化分类边界点距离分类平面的距离来实现分类。
SVM可以解决高维问题,也能够解决小样本下机器学习问题。
4. 逻辑回归(Logistic Regression)
逻辑回归是用于处理因变量为分类变量的回归问题,常见的是二分类或二项分布问题,也可以处理多分类问题,它实际上是属于一种分类方法,用来表示某件事情发生的可能性。
逻辑回归实现简单,分类时计算量非常小、速度很快、存储资源低,主要应用于工业问题上。
5. 线性回归(Linear Regression)
线性回归是处理回归任务最常用的算法之一。该算法的形式十分简单,它期望使用一个超平面拟合数据集(只有两个变量的时候就是一条直线)。
线性回归建模速度快,不需要很复杂的计算,在数据量大的情况下运行速度依然很快,同时可以根据系数给出每个变量的理解和解释。
逻辑回归与线性回归主要有以下不同点:
6. 回归树(Regression Tree)回归树,顾名思义,就是用树模型做回归问题,每一片叶子都输出一个预测值。
回归树通过将数据集重复分割为不同的分支而实现分层学习,分割的标准是最大化每一次分离的信息增益。这种分支结构让回归树很自然地学习到非线性关系。
7. K邻近(K-Nearest Neighbor)
K邻近算法是最简单的机器学习算法。
该方法的思路是:在特征空间中,如果一个样本附近的K个最近(即特征空间中最邻近)样本的大多数属于某一个类别,则该样本也属于这个类别。
K邻近算法理论相对成熟,思想简单,既可以用来做分类也可以用来做回归。
8. AdaBoost
AdaBoost目的就是从训练数据中学习一系列的弱分类器或基本分类器,然后将这些弱分类器组合成一个强分类器。
AdaBoost有一个很突出的特点就是精度很高。
9. 神经网络
神经网络从信息处理角度对人脑神经元网络进行抽象,建立某种简单模型,按不同的连接方式组成不同的网络。
在人工智能领域,神经网络通常指人工神经网络,即ANNs。
引自:https://www.cnblogs.com/manfukeji/p/11976831.html



回归
下面以Boston房价数据集对监督学习中的回归进行问题举例:
# 引入相关科学计算包 import numpy as np import pandas as pd import matplotlib.pyplot as plt %matplotlib inline plt.style.use("ggplot") import seaborn as sns 讯享网
讯享网from sklearn import datasets boston = datasets.load_boston() # 返回一个类似于字典的类 X = boston.data y = boston.target features = boston.feature_names boston_data = pd.DataFrame(X,columns=features) boston_data["Price"] = y boston_data.head()

sklearn中所有内置数据集都封装在datasets对象内,返回的对象有:
- data:特征X的矩阵(ndarray)
- target:因变量的向量(ndarray)
- feature_names:特征名称(ndarray)
上面代码中,我们利用boston = datasets.load_boston()得到的一个类似于字典的类,经过查阅是Bunch类,本质上的数据类型是dict,属性有:
DESCR:数据描述。
target_names:标签名。可自定义,默认为文件夹名。
filenames:文件名。
target:文件分类。如猫狗两类的话,与filenames一一对应为0或1。
data:数据数组。
sns.scatterplot(boston_data['NOX'],boston_data['Price'],color="r",alpha=0.6) plt.title("Price~NOX") plt.show() 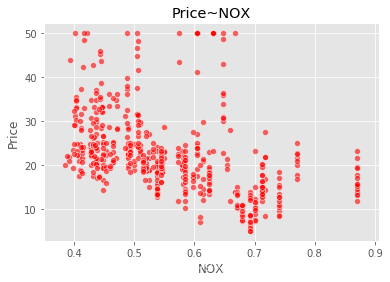
可以看到,数据给定任务所需要的因变量,因变量为波士顿房价Price是一个连续型变量,所以这是一个回归的例子。
分类
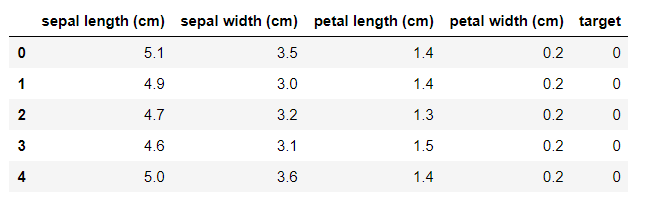
讯享网from sklearn import datasets iris = datasets.load_iris() X = iris.data y = iris.target features = iris.feature_names iris_data = pd.DataFrame(X,columns=features) iris_data['target'] = y iris_data.head()
# 可视化特征 marker = ['s','x','o'] for index,c in enumerate(np.unique(y)): plt.scatter(x=iris_data.loc[y==c,"sepal length (cm)"],y=iris_data.loc[y==c,"sepal width (cm)"],alpha=0.8,label=c,marker=marker[c]) plt.xlabel("sepal length (cm)") plt.ylabel("sepal width (cm)") plt.legend() plt.show() 
我们可以看到:每种不同的颜色和点的样式为一种类型的鸢尾花,数据集有三种不同类型的鸢尾花。因此因变量是一个类别变量,因此通过特征预测鸢尾花类别的问题是一个分类问题。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/121124.html