
这是我们之前的课后作业,根据自己的想法对这个数据进行分析,只要求写出五个点出来就可以了,因此我就对这些数据进行了分析一番。涉及的python知识点还是挺多的,包括了python连接数据库,SQL提取数据并保存为csv格式,pandas处理数据,matplotlib画图以及购物篮分析与关联分析。
python数据分析集合:python数据分析
现有一张表,描述了某个大型超市的订单数据,记录了某时刻的订单。数据大小16G,一亿条数据。老师给我们的是一个csv文件,我当时下载完成后想都没想,就直接打开csv文件,电脑差点炸了,死机死了半天,最后还是屈服了,重新开机了。如果我们不会python和数据库的话,我们连这个csv里装的什么都不知道。所以学点东西还是很有必要的。
- 字段名包含:数据库名 门店代码 门店时间 购物篮 购物篮序号 产品代码 产品数量 具体的产品种类 一级分类代码 一级分类名称 …… 五级分类代码 五级分类名称 产品数量单位
0、导入相关库
import sqlite3 # 数据库 sqlite3是我们老师推荐的,它可以较快处理大数据量的数据库 import pandas as pd # 数据处理利器 import matplotlib.pyplot as plt # 图库 from mlxtend.frequent_patterns import apriori # 关联分析 from mlxtend.frequent_patterns import association_rules # 关联规则 plt.rcParams['font.sans-serif'] = ['SimHei'] # 解决画图不显示文字的问题 plt.rcParams['axes.unicode_minus'] = False # 解决画图不显示负号的问题 讯享网
1、连接数据库并读取数据
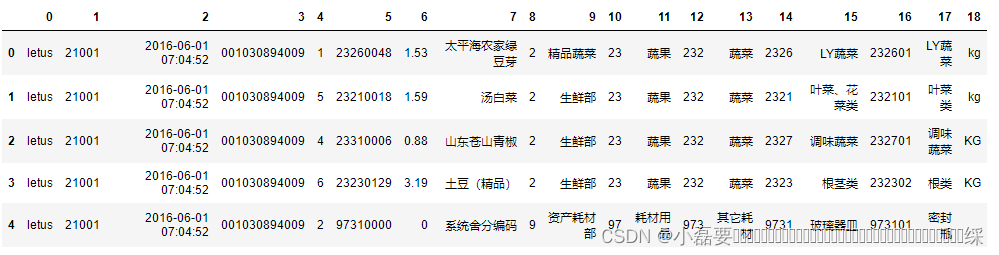
讯享网# 连接数据库 运行时改变数据库文件路径 con = sqlite3.connect('E:/letus/letus.db') # csv怎么转成数据库参考网上的做法的,CSDN上也有我就不写了 下载一个sqlite3.exe 就可以了 # 创建游标 靠他才能执行SQL语句 cur = con.cursor() print('成功读取') # 若输出'成功读取' 表示已经连接到数据库 # 利用cur.execute(sql语句)执行SQL语句 tableA表的名称 cur.execute('select * from tableA limit 5') # 必须要提交命令 才会执行成功 con.commit() # fetchall() 提取数据 并显示 b = cur.fetchall() pd.DataFrame(b) # 各字段:数据库名 门店代码 门店时间 购物篮 购物篮序号 产品代码 产品数量 具体的产品种类 一级分类代码 一级分类名称 …… 五级分类代码 五级分类名称 单位
2、SQL提取数据并保存为CSV文件
sqlite3的日期格式转换函数为strftime(转换格式,日期)与MYSQL的datef_ormat(日期,转成格式)参数相反

# 1、计算每年的销量 sql1 = """ SELECT strftime('%Y',shop_datetime), COUNT(*) from tableA GROUP BY STRFTIME('%Y',shop_datetime) """ cur.execute(sql1) con.commit() b = cur.fetchall() df1 = pd.DataFrame(b, columns=['year', 'count']) df1.to_csv('按年分组.csv', sep=',', header=True, index=False) 讯享网# 2、计算每月的销量 sql2 = """ SELECT strftime('%Y-%m',shop_datetime), COUNT(*) from tableA GROUP BY STRFTIME('%Y-%m',shop_datetime) """ cur.execute(sql2) con.commit() b = cur.fetchall() df2 = pd.DataFrame(b, columns=['month', 'count']) df2.to_csv('按月分组.csv', sep=',', header=True, index=False)
# 3、计算每年的产品一级分类销量 sql3 = """ select STRFTIME('%Y',shop_datetime),category_desc1,count(*) from tableA group by STRFTIME('%Y',shop_datetime),category_desc1 order by STRFTIME('%Y',shop_datetime),category_desc1 """ cur.execute(sql3) con.commit() a = cur.fetchall() df3 = pd.DataFrame(a, columns=['year', 'desc1', 'desc2', 'desc3', 'count']) df3.to_csv('种类分组.csv', sep=',', header=True, index=False) 讯享网# 4、按购物篮分组(选取2019年11月的数据) 求购物篮系数 sql4 = """ SELECT bask_code, COUNT(*) FROM "tableA" WHERE STRFTIME('%Y-%m', shop_datetime) = '2019-11' GROUP BY bask_code """ cur.execute(sql4) con.commit() a = cur.fetchall() df4 = pd.DataFrame(a, columns=['bask','count']) df4.to_csv('购物篮分组.csv', sep=',', header=True, index=False)
# 5、按购物篮和第一类别分类(因数据太大,在此选取了2019年11月30日一天的数据) sql5 = """ SELECT bask_code, category_desc1 FROM "tableA" WHERE STRFTIME('%Y-%m-%d', shop_datetime) = '2019-11-30' AND bask_code IN ( SELECT bask_code FROM tableA WHERE STRFTIME('%Y-%m-%d', shop_datetime) = '2019-11-30' GROUP BY bask_code HAVING COUNT(*) > 1) # 提取2019-11-30的购物篮(不同产品数>1) ORDER BY bask_code """ cur.execute(sql5) con.commit() a = cur.fetchall() df5 = pd.DataFrame(a, columns=['bask_code','category_desc1']) df5.to_csv('bask_desc1.csv', sep=',', header=True, index=False) 3、统计2016年到2019年的年销售数量
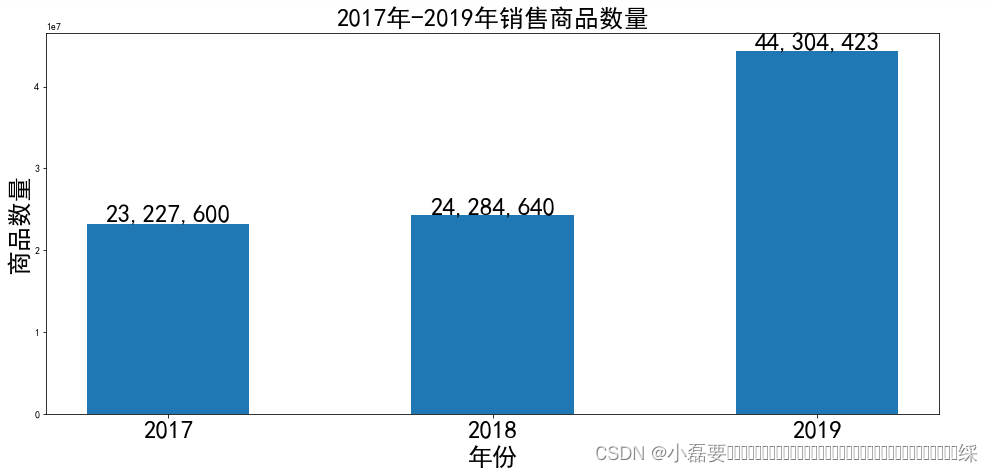
讯享网# 读取数据 df1=pd.read_csv('按年分组.csv', sep=',') df1 year count 0 2016 1 2017 2 2018 3 2019 # 2016年只有半年,故不显示在图中 x = df1['year'][1:4] y = df1['count'][1:4] plt.figure(figsize=[16,7]) # 画布大小 plt.bar(x, y, width=0.5) # 柱状图 plt.xticks(range(2017,2020,1),fontsize=25) # x轴刻度显示 plt.xlabel('年份',fontsize=25) # x和y轴标签 plt.ylabel('商品数量',fontsize=25) plt.title('2017年-2019年销售商品数量',fontsize=25) # 标题 for i,j in zip(x,y): # 显示商品数量 plt.text(i,j,format(j,","),ha='center',fontsize=25) plt.show()
4、对2017、2018、2019年销售量按月分别进行分析(每月销售量环比)
- 其实这里还可以做同比,不同年份的同月增长情况
df2 = pd.read_csv('按月分组.csv', sep=',') df2['rate']=df2['count'].pct_change()*100 # 计算环比 df2.head() month count rate 0 2016-06 NaN 1 2016-07 9. 2 2016-08 9. 3 2016-09 -7. 4 2016-10 14. df2["month"]=pd.to_datetime(df2["month"]) # 将month列转成日期类型 df2 = df2.set_index('month').to_period('M') # 该表索引月格式 默认xxxx-xx-01 df2.index PeriodIndex(['2016-06', '2016-07', '2016-08', '2016-09', '2016-10', '2016-11', '2016-12', '2017-01', '2017-02', '2017-03', '2017-04', '2017-05', '2017-06', '2017-07', '2017-08', '2017-09', '2017-10', '2017-11', '2017-12', '2018-01', '2018-02', '2018-03', '2018-04', '2018-05', '2018-06', '2018-07', '2018-08', '2018-09', '2018-10', '2018-11', '2018-12', '2019-01', '2019-02', '2019-03', '2019-04', '2019-05', '2019-06', '2019-07', '2019-08', '2019-09', '2019-10', '2019-11', '2019-12'], dtype='period[M]', name='month', freq='M') 讯享网# 将每年的数据单独拎出来 df2_2017=df2['2017-01':'2017-12'] df2_2018=df2['2018-01':'2018-12'] df2_2019=df2['2019-01':'2019-12'] # 设置x轴刻度显示 x_tick = ['一月','二月','三月','四月','五月','六月','七月','八月','九月','十月','十一月','十二月'] # 将每年的销量和环比形成列表,方便后面循环 y1 = [df2_2017['count'],df2_2018['count'],df2_2019['count']] y2 = [df2_2017['rate'],df2_2018['rate'],df2_2019['rate']] # 画图 fig = plt.figure(figsize=(14,9)) for i in range(1,4): # 3年 循环三次 ax = fig.add_subplot(3,1,i) # 子图位置 3行1列 第i个子图 plt.bar(range(12),y1[i-1].values,color='skyblue') # 柱状图 销量 plt.ylabel('销售数量(件)',fontsize=15) for x,y in enumerate(y1[i-1].values): # 文字显示 plt.text(x,y,format(y,","),ha='center',fontsize=12) axn = ax.twinx() # 共用x轴 plt.plot(range(12),y2[i-1].values,color='r',marker='o') # 折线图 环比 for x,y in enumerate(y2[i-1].values): plt.text(x,y-15,'%.1f%%' % y,ha='center',fontsize=12) plt.ylim(-100,150) # y轴刻度范围 plt.xticks(range(12),x_tick) # 重置x轴刻度显示 plt.ylabel('增长率(%)',fontsize=15) # y轴标签 plt.title('%d年销售数量及环比增长率' % (i+2016),fontsize=15) plt.tight_layout(3) plt.show()
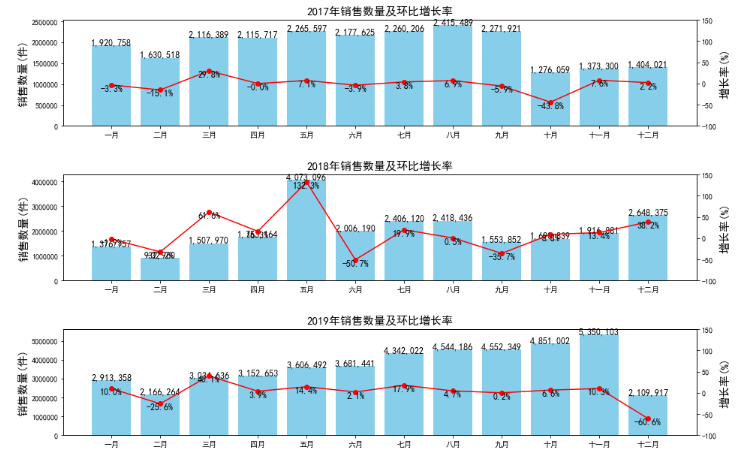
从2017年销售数量及环比增长率中可以看出,一月到九月的销售数量是比较平稳的;十月的销售数量照比九月下降了43.8%,但十月、十一月、和十二月的销售数量还是较平稳的。 从2018年销售数量和环比增长率中可以看出,五月的销量在全年中达到了顶峰,六月—九月的销量相比其他月份较高,十月—十二月销量逐渐增高。 从2019年销售数量和环比增长率中可以看出,从一月到十一月的销售数量是一直增加的;十二月份的增长率和销售数量在这里不予考虑,因为数据中的十二月份只统计了1号到11号的销售数据,所以没有统计价值。 5、按每年的商品种类分类进行分析
讯享网df3 = pd.read_csv('种类分组.csv',sep=',') df3.dropna(inplace=True) df3.head() year desc1 desc2 desc3 count 0 2016 生鲜部 园艺 宠物 4 1 2016 生鲜部 园艺 节庆用品 329 2 2016 生鲜部 园艺 花木 7 3 2016 生鲜部 日配 冷冻 52997 4 2016 生鲜部 日配 冷藏
# 提取出每年的数据 df3_2016 = df3[df3['year']==2016] df3_2017 = df3[df3['year']==2017] df3_2018 = df3[df3['year']==2018] df3_2019 = df3[df3['year']==2019] # 按照一级分类分组对销量求和 df3_2016=pd.DataFrame(df3_2016.groupby('desc1')['count'].sum()) df3_2017=pd.DataFrame(df3_2017.groupby('desc1')['count'].sum()) df3_2018=pd.DataFrame(df3_2018.groupby('desc1')['count'].sum()) df3_2019=pd.DataFrame(df3_2019.groupby('desc1')['count'].sum()) # 一级分类标签 labels = ['生鲜部','税率为0商品','精品蔬菜','资产耗材部','重点水果','非食部','食品部','鲜果切'] plt.figure(figsize=[16,10]) df33 = [df3_2016,df3_2017,df3_2018,df3_2019] for i,j in enumerate(df33): ax1 = plt.subplot(2,2,i+1) x = j['count'] plt.pie(x, # 销量数据 labels=labels, # 标签 autopct='%1.2f%%', # 保留小数位数 radius=1, # 半径 explode = (0,0,0,0,0.2,0.4,0,0)) # 突出程度 plt.title('%d年一级分类商品占比情况' % (i+2016)) # 子图标题 plt.show() 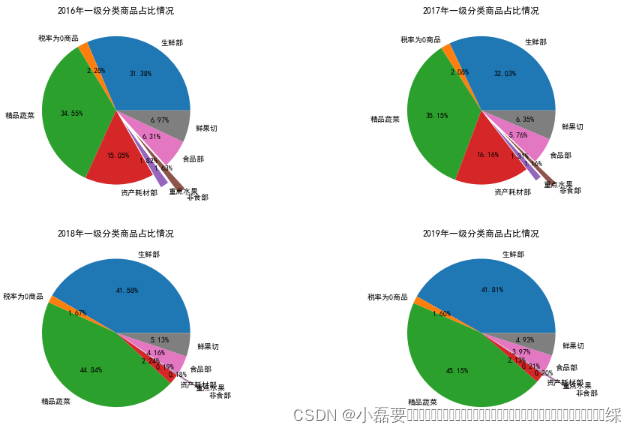
讯享网从四年的销售占比中可以看出,精品蔬菜和生鲜部的销售占比最高,且在2018年和2019年,二者占总销售的80%以上; 而资产耗材部的占比由15%左右降到了2%左右,下降幅度过大。其余种类的变化幅度不是很大。
6、购物篮系数 (总销售量/总购物篮数) 只选取了2019年11月
df4 = pd.read_csv('购物篮分组.csv', sep=',') df4.head() bask_code count 0 16 1 1 2 2 3 3 4 4 a = df4.bask_code.count() # 计算购物篮的数量 b = df4['count'].sum() # 计算商品数量 round(b/a) # 购物篮系数 = 总数量/总篮子数 # 结果:说明每个购物篮中平均含有6件商品 6 7、购物篮分析(关联分析)
讯享网from mlxtend.frequent_patterns import apriori from mlxtend.frequent_patterns import association_rules #关联规则 data = pd.read_csv('bask_desc1.csv',sep=',') data = data.drop_duplicates() # 删除重复值 data.head() bask_code category_desc1 0 生鲜部 1 食品部 3 鲜果切 4 税率为0商品 5 精品蔬菜
retail = pd.crosstab(data['bask_code'],data['category_desc1']) # 交叉表 retail # 结果显示:由于上面删除了重复值,因此结果中有商品的记为1,没有商品的为0 # 若不去重,可能有大于1的值,若结果中有大于1的数值,必须将其转化为1 需符合关联分析数据格式 category_desc1 生鲜部 税率为0商品 精品蔬菜 资产耗材部 重点水果 非食部 食品部 鲜果切 bask_code 1 1 1 0 0 0 1 1 1 0 1 1 0 0 0 0 0 1 1 1 0 0 1 1 1 0 1 1 0 0 1 0 1 0 1 0 0 0 0 1 ... ... ... ... ... ... ... ... ... 53406 1 0 1 0 0 0 0 0 31705 1 0 1 0 0 0 0 0 14406 1 0 1 0 0 0 0 1 20290 1 0 1 0 0 0 0 0 13906 1 0 1 0 0 0 0 1 36392 rows × 8 columns 讯享网frequent_itemsets=apriori(retail,min_support=0.11,use_colnames=True) #设置最小支持度为0.1,求频繁项集,显示列标签名 rules_set=association_rules(frequent_itemsets,metric='lift',min_threshold=0.9) #'lift’大于0.5,求关联规则 rules_set
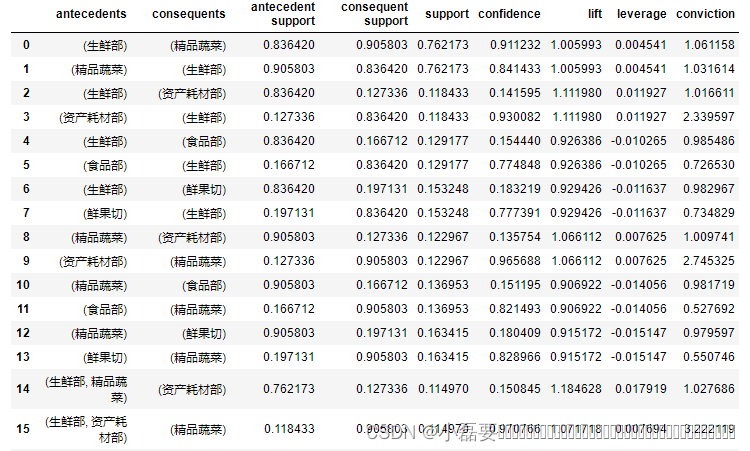
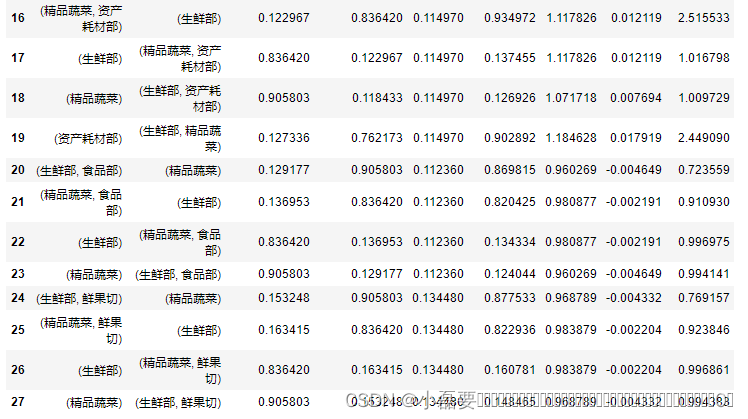
每一列的列名意思是:前件 后件 前件支持度 后件支持度 项集支持度 置信度 提升度 杠杆率 信念率;这里分析支持度和置信度。 从支持度结果可以看出: 1、一项集中支持度最大的是精品蔬菜和生鲜部,均达0.8以上;说明单独买精品蔬菜和生鲜部产品的概率最大, 2、二项集中支持度最大的是{精品蔬菜,生鲜部},高达0.762,说明一起购买精品蔬菜和生鲜部产品的概率最大,二者相关性较大; 次之为{鲜果切,精品蔬菜},达 0.163,但与{精品蔬菜,生鲜部}比,还差很多; 3、三项集中支持度最大的是{生鲜部,精品蔬菜,鲜果切},达0.134; 从置信度结果看:(置信度:x发生的条件下,y发生的概率) 最大的是{资产耗材部, 生鲜部, 精品蔬菜},达97%,说明在已经购买了资产耗材部和生鲜部的前提下,购买精品蔬菜的概率较大。 由此可以建议商场可以将精品蔬菜类和生鲜部类产品的位置放在一起,可以使顾客更容易买到这两类产品。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/85504.html