
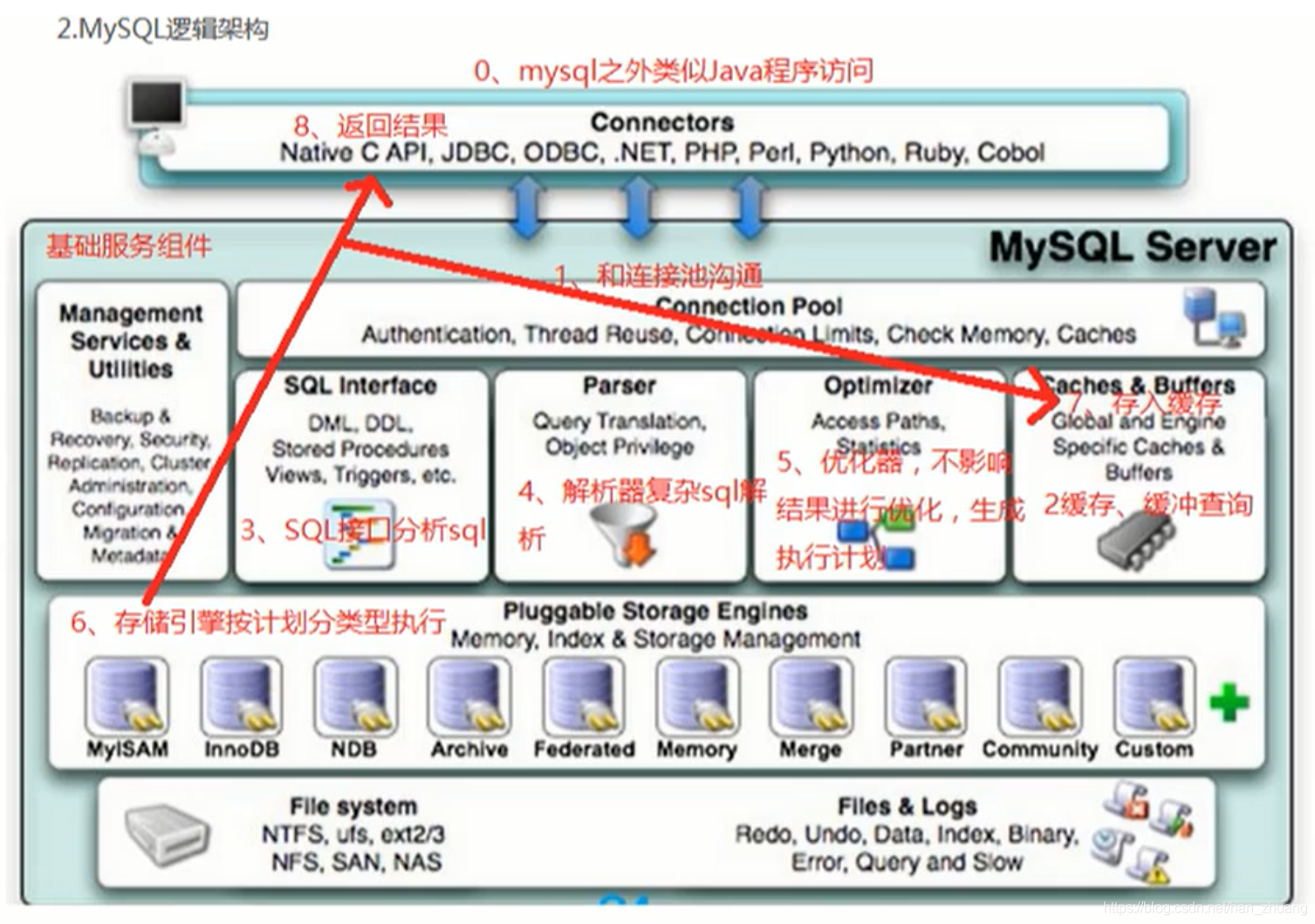
MySQL逻辑架构
1、连接层
MySQL的最上层是一些客户端和连接服务,包含本地socket通信和大多数基于客户端/服务器工具实现的类似于tcp/ip的通信。主要完成一些类似于连接处理、授权认证及相关的安全方案。MySQL在该层上引入了连接池的概念,为通过认证安全接入的客户端提供线程。在该层上同样实现类基于SSL的安全连接。服务器也会为安全接入的每个客户端验证它所具有的限权。
2、服务层
第二层架构主要完成大多数核心服务功能,如:SQL接口、缓存的查询、SQL的分析和优化以及部分内置函数的执行。所有跨存储引擎的功能也在这一层实现,如存储过程、函数等。在该层、服务器会解析查询和创建相应的内部解析树,并对其完成相应的优化,如确定查询表的顺序、是否存在利用索引等,最后完成相应的执行操作。如果是SELECT语句,服务器还会查询内部缓存。如果缓存空间足够大,在解决大量读操作的环境中能够很好的提升系统的性能。
3、引擎层
存储引擎层真正负责了MySQL中数据的存储和提取,服务器通过API和存储引擎进行通信。不同的存储引擎功能不同,这样我们可以根据我们的实际需求进行选取。
4、存储层
数据存储层主要是将数据存储在运行于裸设备的文件系统之上,并完成与存储引擎的交互。
存储引擎简介
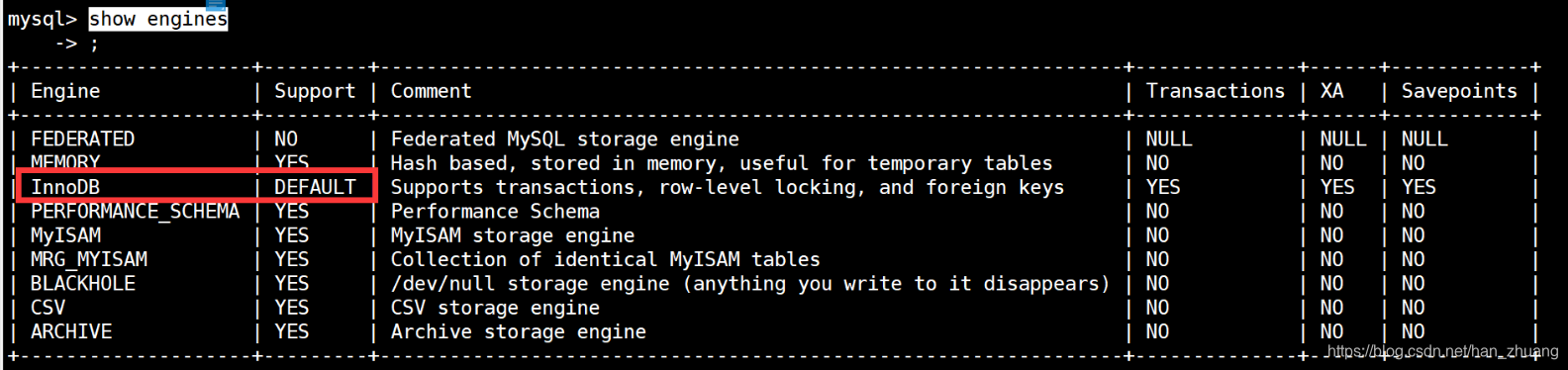
查看MySQL的当前的存储引擎
show engines;讯享网
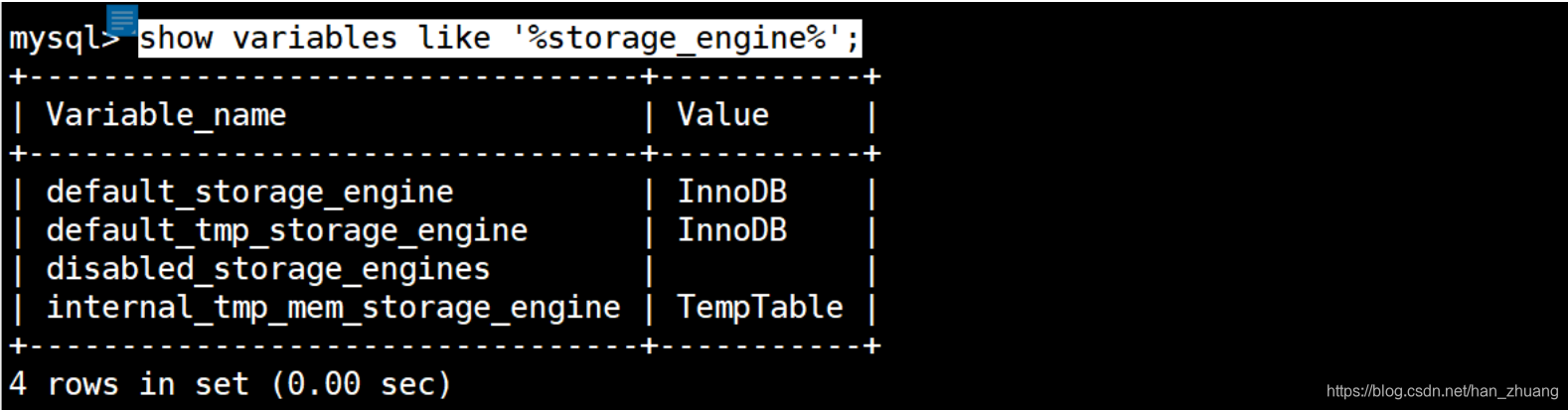
讯享网show variables like '%storage_engine%';
InnoDB存储引擎
InnoDB是MySQL的默认事务型引擎,它被设计用来处理大量的短期(short-lived)事务。除非有非常特别的原因需要使用其他的存储引擎,否则应该优先考虑InnoDB引擎。行级锁,适合高并发情况
- MyISAM引擎使用B+Tree作为索引结构,叶节点的data域存放的是数据记录的地址。MyISAM索引文件和数据文件是分离的,索引文件仅保存数据记录的地址。

- innodb 索引 使用 B+TREE ,在InnoDB中,表数据文件本身就是按B+Tree组织的一个索引结构,这棵树的叶节点data域保存了完整的数据记录。

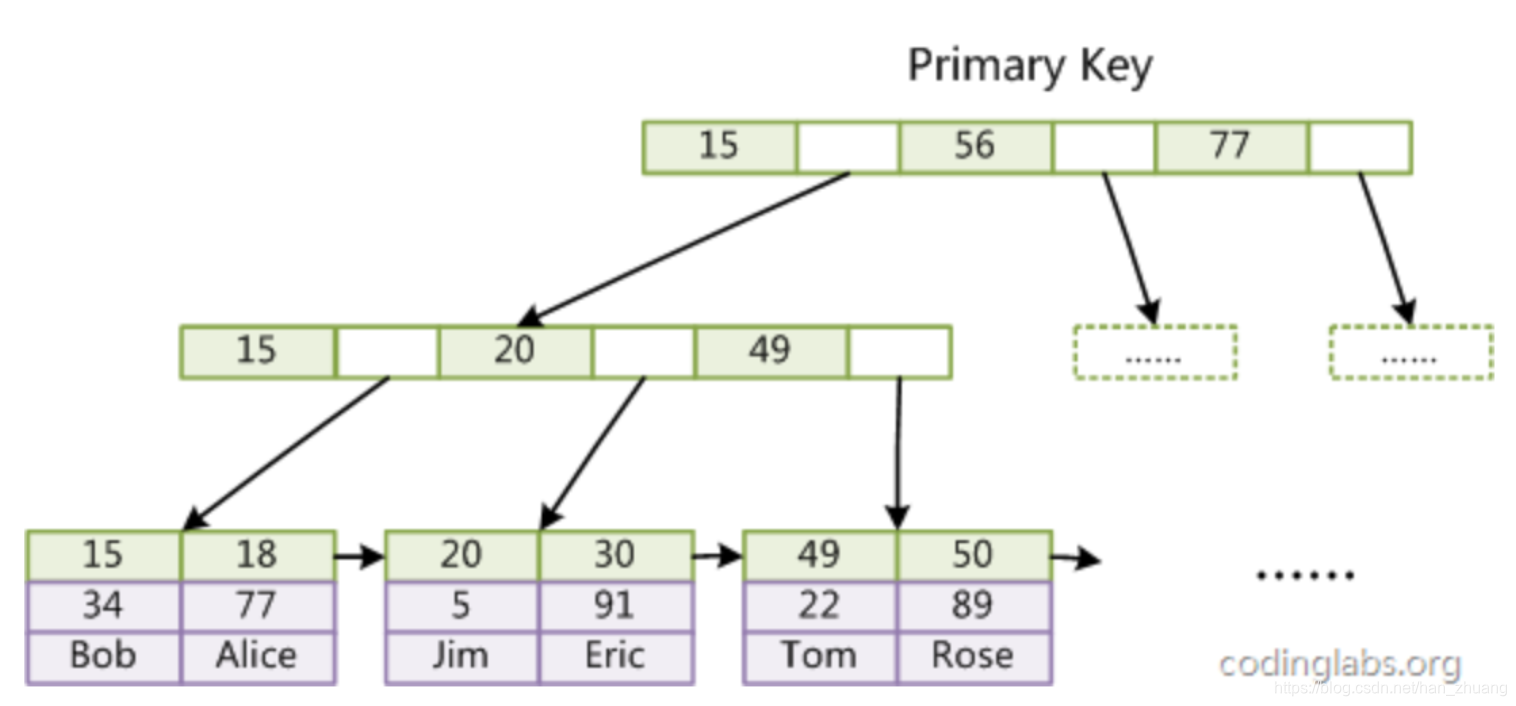
- innodb 主键为聚簇索引(叶节点包含了完整的数据记录,这种索引叫做聚集索引。相对的,MyISAM引擎索引文件仅保存数据记录的地址,称之为非聚簇索引)。如果没有设置主键,MySQL自动为InnoDB表生成一个隐含字段作为主键(这个字段长度为6个字节,类型为长整形)。基于聚簇索引的增删改查效率非常高。
MyISAM存储引擎
MyISAM提供了大量的特性,包括全文索引、压缩、空间函数(GIS)等,但MyISAM不支持事务和行级锁(myisam改表时会将整个表全锁住),有一个毫无疑问的缺陷就是崩溃后无法安全恢复。
MyIASM VS InnoDB★
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-i3FUeA1V-1588476883503)(C:\Users\韩壮\AppData\Roaming\Typora\typora-user-images\image-20200430221558258.png)]](https://img-blog.csdnimg.cn/20200503114047717.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2hhbl96aHVhbmc=,size_16,color_FFFFFF,t_70)
索引★
引入
SQL语句查询慢的原因及解决:
- 数据过多:分库分表
- 没有充分利用索引:建立索引(一般效果最好)
- 关联查询太多join(设计缺陷或者业务需求):SQL优化
- 服务器调优及各个参数设置(缓存大小、线程数等):调整my.cnf
Join的七种类型
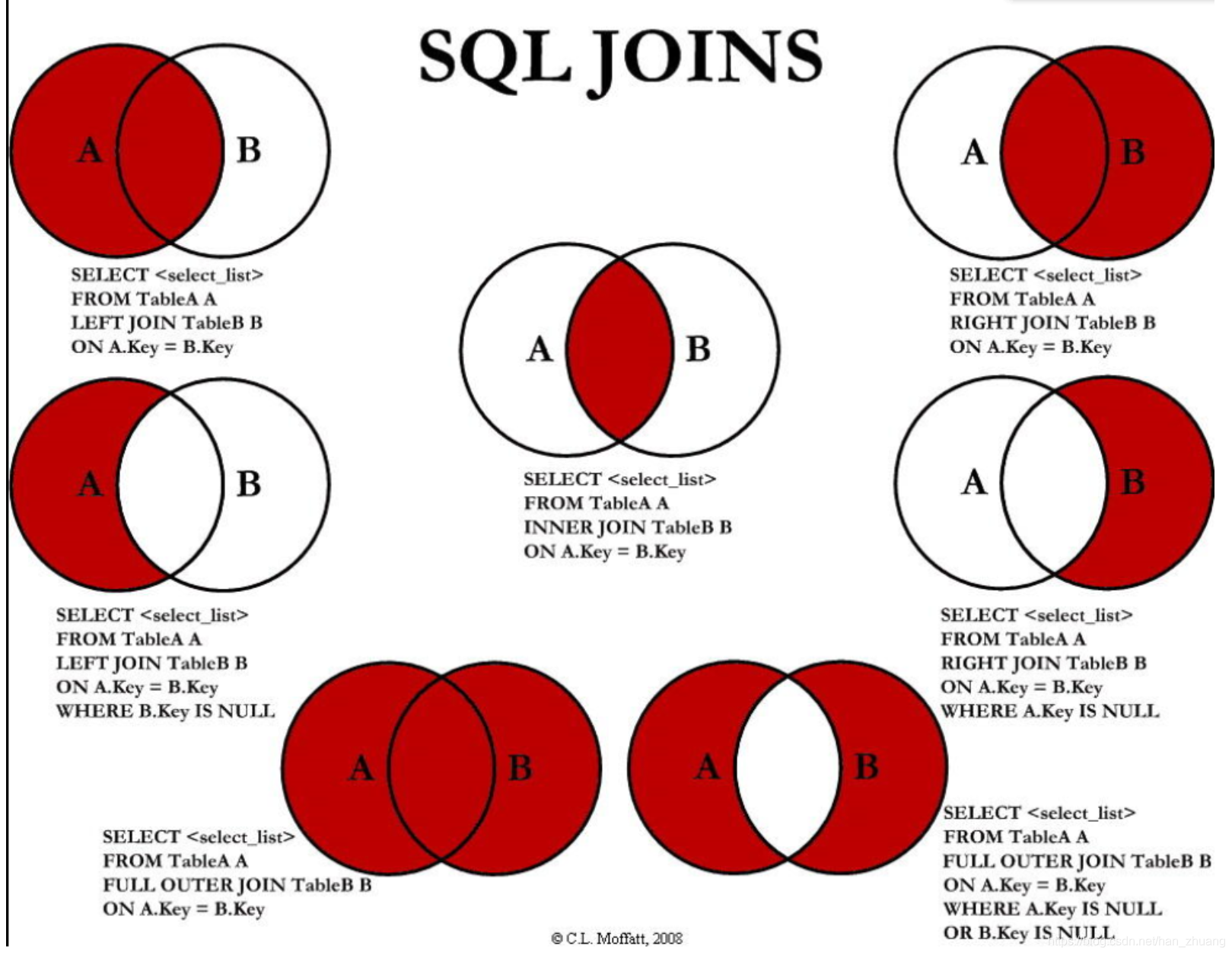
SQL语句的执行顺序:

定义
索引(Index)是帮助MySQL高效获取数据的数据结构,是对数据库表中一列或多列的值进行排序的一种结构,使用索引可快速访问数据库表中的特定信息。
特点:
- 一般来说索引本身很大,而且需要长期保存,所以不能全部放在内存中,因此所以往往以索引文件的形式存储在磁盘上
- Innodb 所使用的索引是B+树(B:balance)
优点:
- 类似图书馆的书目索引,能提高数据检索的效率,降低数据库IO成本
- 通过建立索引对数据进行排序,降低数据排序的成本,减少CPU的消耗
缺点:
- 实际上索引在逻辑上也上一张表,存储了主键,索引字段并指向实体表的记录,所以索引需要占用空间
- 虽然索引大大提高了查询速度,但是却会降低更新表的速度,如对表进行INSERT、UPDATE、DELETE。因为更新表时,MySQL不仅要保存数据,还要调整因为更新所带来的键值变化后的索引信息
MySQL索引的逻辑结构★
参考资料
B树
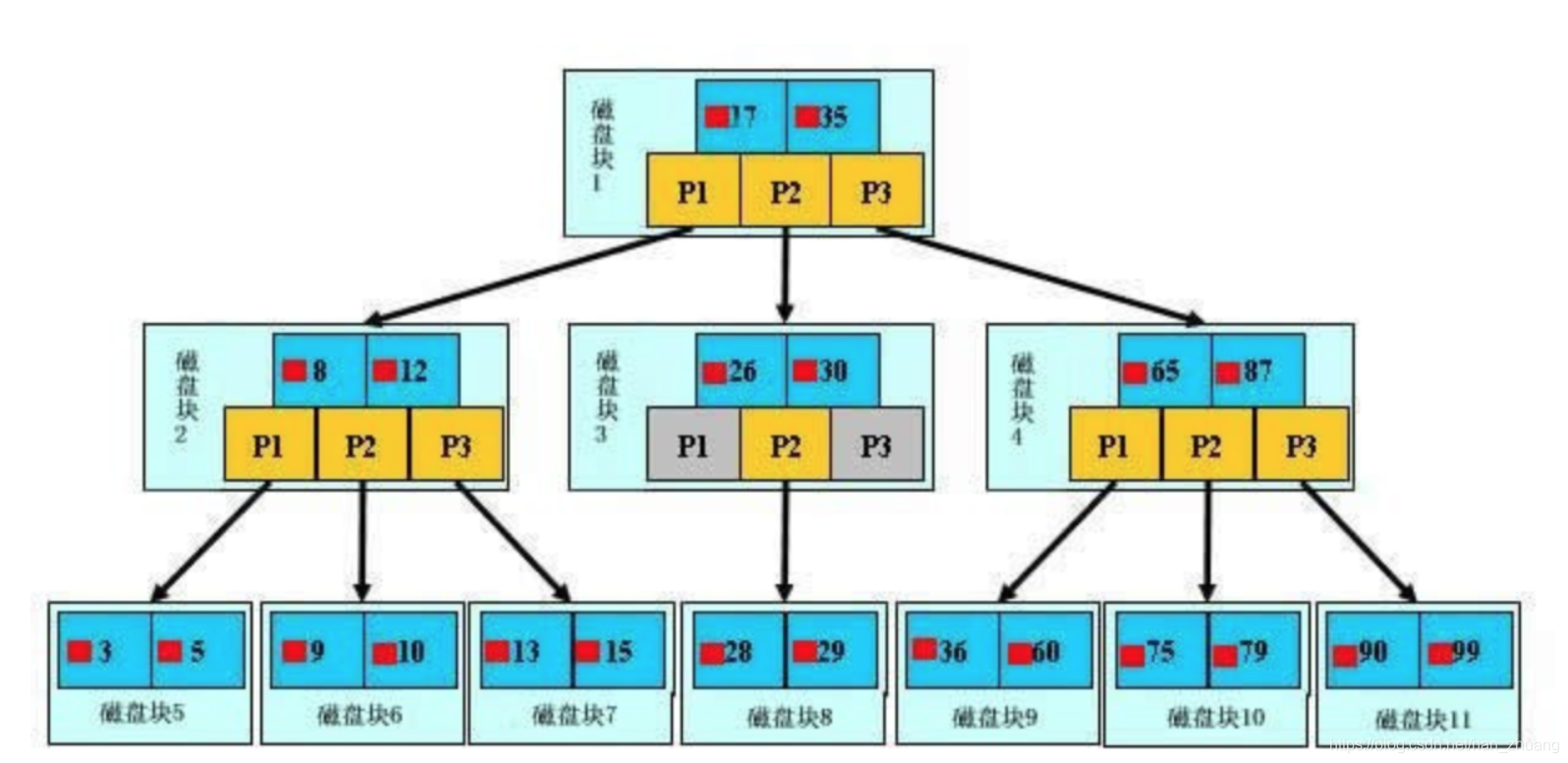
上图显示了一颗b树,浅蓝色的块我们称之为一个磁盘块,可以看到每个磁盘块包含几个数据项(深蓝色所示)和指针(黄色所示)。
- 如磁盘块1包含数据项17和35,包含指针P1、P2、P3。
- P1表示小于17的磁盘块,P2表示在17和35之间的磁盘块,P3表示大于35的磁盘块。
B+树
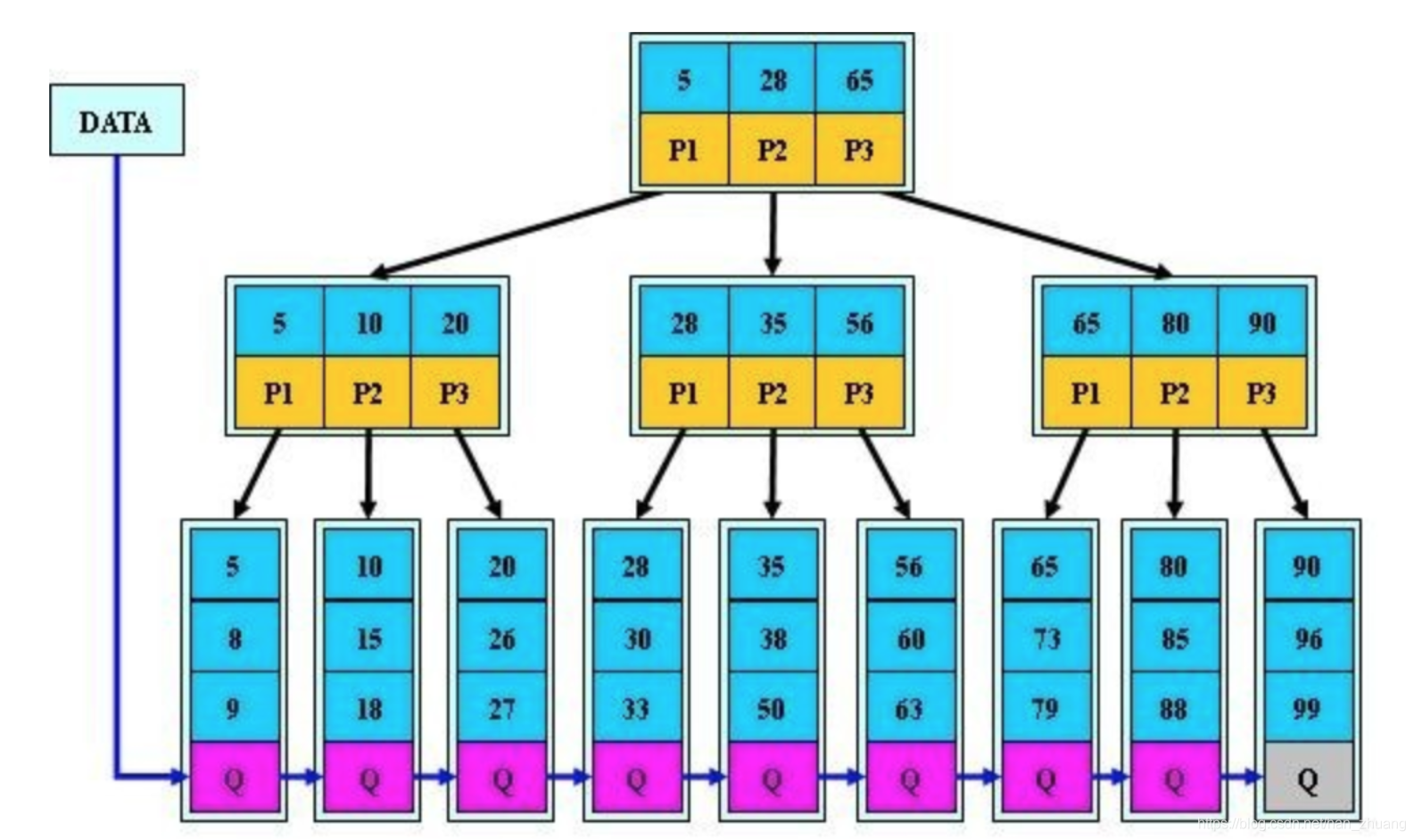
特点:
- 所有的叶子结点中包含了全部关键字的信息,及指向含有这些关键字记录的指针,且叶子结点本身依关键字的大小自小而大的顺序链接。 (而B 树的叶子节点并没有包括全部需要查找的信息)
- 所有的非终端结点可以看成是索引部分,结点中仅含有其子树根结点中最大(或最小)关键字。 (而B 树的非终节点也包含需要查找的有效信息)
B树 VS B+树
为什么B+树比B树更适合实际应用中操作系统的文件索引和数据库索引?
- B±tree的磁盘读写代价更低 :B±tree的内部结点并没有指向关键字具体信息的指针。因此其内部结点相对B 树更小。如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就越多。相对来说IO读写次数也就降低了。
- B±tree的查询效率更加稳定:由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
引申问题:
为什么不使用红黑树作为索引存储结构?红黑树这种结构,深度h明显要深的多。由于逻辑上很近的节点(父子)物理上可能很远,无法利用局部性,所以红黑树的I/O渐进复杂度也为O(h),效率明显比B-Tree差很多。
为什么不建议使用过长的字段作为主键?因为所有辅助索引都引用主索引,过长的主索引会令辅助索引变得过大。
为什么用非单调的字段作为主键在InnoDB中不是个好主意?因为InnoDB数据文件本身是一颗B+Tree,非单调的主键会造成在插入新记录时数据文件为了维持B+Tree的特性而频繁的分裂调整,十分低效,而使用自增字段作为主键则是一个很好的选择。因此,只要可以,请尽量在InnoDB上采用自增字段做主键。
索引的分类
按存储类型分类
- 聚集索引(主键索引):聚集索引就是按照每张表的主键构造一颗B+树,同时叶子节点中存放的即为整张表的记录数据。聚集索引的叶子节点称为数据页,聚集索引的这个特性决定了索引组织表中的数据也是索引的一部分。
- 辅助索引(二级索引):非主键索引,叶子节点=键值+书签。Innodb存储引擎的书签就是相应行数据的主键索引值。
按key分类
1、单值索引:一个索引只包含单个列,一个表可以有多个单值索引
2、唯一索引:索引列的值必须为(UNIQUE、PRIMERY KEY),但允许有空值
3、复合索引:一个索引包含多个列
4、主键索引:设定某个字段为主键之后,数据库会自动建立索引,innodb为聚簇索引
基本语法:
- 创建索引
create 【unique】 index 索引名 on 表名(字段名【,字段名...】);讯享网alter 表名 add 【unique】 index 索引名 on 表名(字段名【,字段名...】);
- 删除索引
drop index 索引名 on 表名;- 查看索引
讯享网show index from 表名;
索引的应用场景★
1、需要建索引的场景
- 主键自动建立唯一索引
- 频繁作为查询条件的字段应该建立索引
- 查询中与其他表进行关联的字段、外键关系需要建立索引
- 单值vs组合索引:一般情况下组合索引性价比更高
- 查询中排序的字段需要建立索引:排序字段通过索引访问可以大大调高排序速度
- 查询中统计或者分组字段
2、不要建索引的场景
- 表的记录太少,经验是记录数不超过 2000可以考虑不建索引,超过2000条可以酌情考虑索引。
- 经常增删改的字段或者表
- where条件用不到字段不适合创建索引
- 过滤性不好的字段不适合创建索引:例如性别‘男’,‘女’,只能将表分成两部分
性能分析:Explain★
使用Explain关键字可以模拟优化器执行SQL查询语句,从而知道MySQL是如何处理我们写的SQL语句,进而可以分析查询语句或者表结构的性能瓶颈。
使用Explain可以查看的信息:
- 表的读取顺序
- 数据读取操作的操作类型
- 哪些索引可以使用
- 哪些索引实际被使用
- 表之间的引用
- 每张表有多少行被物理查询
适用语法:
explain 查询语句返回结果:
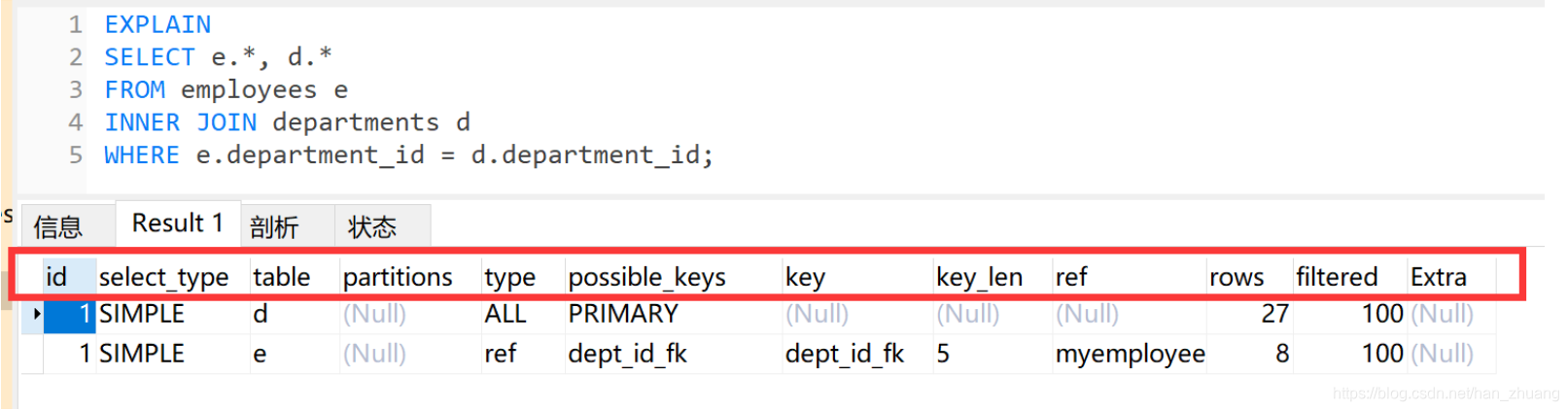
字段含义

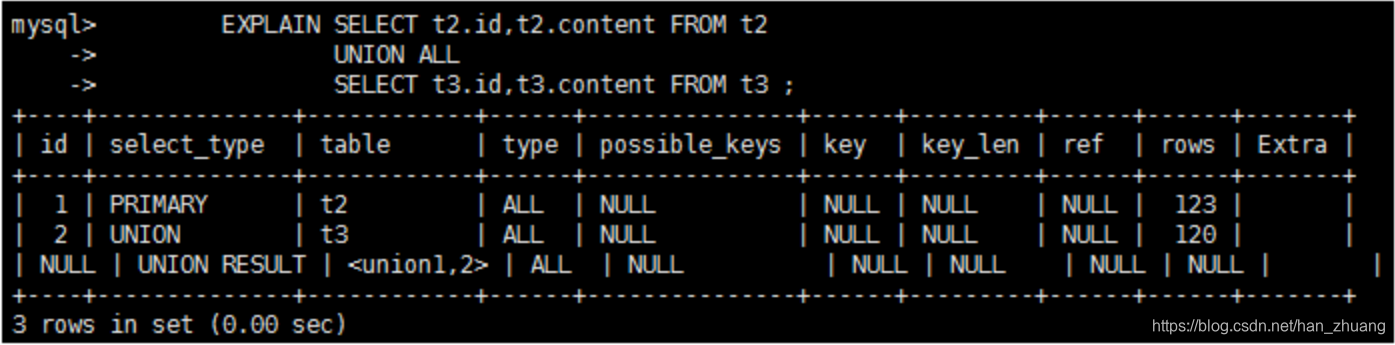
1、id★
id表示select的查询序号,包含一组数字,表示查询中执行select子句或操作表的顺序
id这一组数字有三种情况
- id相同,执行顺序由上至下
- id不同,如果是子查询,id的序号会递增,id值越大优先级越高,越先被执行
- 在所有组中,id值越大,优先级越高,越先执行;其中相同的id,可以认为是一组,从上往下顺序执行
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3oJvdyQq-1588476883546)(C:\Users\韩壮\AppData\Roaming\Typora\typora-user-images\image-20200501235220251.png)]](https://img-blog.csdnimg.cn/2020050311372836.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2hhbl96aHVhbmc=,size_16,color_FFFFFF,t_70)
上面的执行顺序时:id为2的t3表最先执行,然后由id为2的表衍生的id为1的< DERIVED2 >表在执行,最后id为1的t2表执行。
2、select_type
表示查询类型,主要是用于区别普通查询,联合查询,子查询等复杂查询
- simple:简单的select查询,查询中不包含子查询或者union
- primary:查询若包含任意子查询,则最外层查询部分被标记为primary
- derived:在from列表中包含的子查询部分被标记为derived(衍生),MySQL会递归地执行这些子查询,把结果放到临时表里

- subquery:在select或者where列表中包含的子查询
- dependent subquery:在select或者where列表中包含的子查询,且子查询中结果集为多值
- uncacheable subquery:查询条件中用到了系统变量,由于随时会变所以不能缓存
- union:union后面的select语句被标记为union
- union result:union联合的select结果
3、table
显示这一行数据时关于哪个表的
4、partitions
表示分区表中的命中情况,非分区表值为null
5、type★

type显示的是访问类型,是较为重要的一个指标。
常见的type类型及含义:
- system:表中只有一条记录(通常为系统表),是const类型的特例
- const:表示通过一次索引就可以找到,const用于判断条件为primary key或者unique索引时。如where的判断条件为主键,而且匹配条件为常量
- eq_ref:使用了唯一性索引,对于每一个索引键,表中只有一条记录与之匹配
- ref:非唯一性的索引扫描,返回匹配单独值的所有行
- range:使用了索引检索给定范围的行,key列显示了使用哪些索引。一般是where语句中出现了使用索引的in、between、< 、>等查询。这种范围扫描效率比全表扫描高。
- index:使用了索引,但是没有用索引进行过滤。一般是使用了覆盖索引或者是利用索引进行排序分组
- all:full table scan,将遍历全表以找到匹配的行
访问类型排序:system>const>eq_ref>ref>range>index>ALL
一般来说,得保证查询至少达到range级别,最好能达到ref。
6、possible key
显示可能用到这张表上的索引,一个或者多个。查询涉及到的字段如果有索引则被列出,但不一定被实际使用。
7、key★
实际被使用的索引,如果为null,则表示没有索引被使用。查询中若使用了覆盖索引,则该索引和查询select字段重叠:当查询具体某一字段时,且那个字段有索引时,key 值会显示为索引。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-idQx5nvR-1588476883563)(C:\Users\韩壮\AppData\Roaming\Typora\typora-user-images\image-20200502113501451.png)]](https://img-blog.csdnimg.cn/2020050311362872.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2hhbl96aHVhbmc=,size_16,color_FFFFFF,t_70)
8、key_lens★
表示索引使用的字节数,可通过该列计算查询中使用的索引的长度。key_lens字段能够帮你检查是否充分用上了索引。在复合索引的情况下,一般越长越好,越长说明用到的索引越多。
9、ref
显示索引的哪一列被使用了,可能的话是一个常数。哪些列或者常量被用于查找索引列上的值
10、rows
显示MySQL预测它执行查询时必须检查的行数,越少越好
11、extra★
包含一些其他十分重要的信息
- using filesort(×):mysql无法使用表内的索引顺序进行排序,而是使用了外部的文件排序。常见于order by和group by,需要建索引。
- using temporary(×):mysql对查询结果排序时使用了临时表。常见于order by和group by,需要建索引。
- using join buffer(×):使用了连接缓存,出现在当两个连接时,驱动表(被连接的表,left join 左边的表。inner join 中数据少的表) 没有索引的情况下。给驱动表建立索引可解决此问题。且 type 将改变成 ref。
- using index(√):表示利用索引进行了分组和排序,效果还不错
- using where(√):表示使用了where过滤
- impossible where(×):where条件总是false,不能用来获取任何元组
- select tables optimized away:在没有group by子句的情况下,基于索引优化max/min
- distinct:优化了distinct,找到第一个就结束查询同样的值
索引使用策略及优化★
单表使用索引及常见的索引失效
1、尽量构造复合索引,这样既能够减少索引的数量也能够尽可能多的命中字段
讯享网create index idx_emp_age_deptId_name on emp(age,deptId,name); explain SELECT SQL_NO_CACHE * from emp where emp.age=30 and deptId=4 and emp.`name` = 'abcdef'
根据key_len字段值为73可以看出三个字段全部命中索引
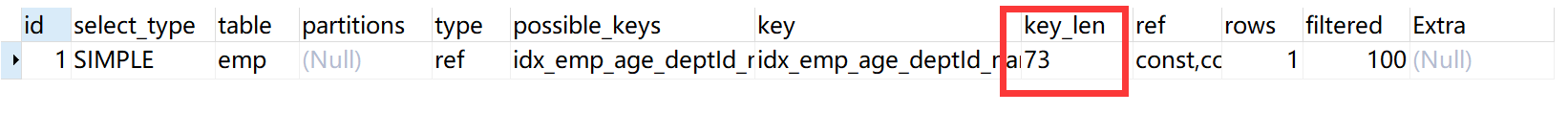
2、最左前缀匹配
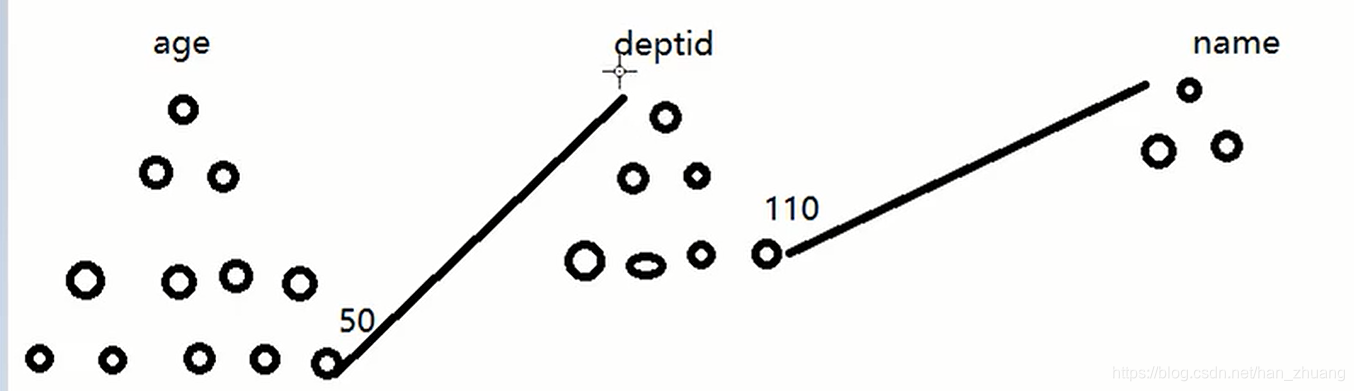
由于innodb的索引存储结构问题,联合索引查询必须按照字段顺序,如果中间某一个字段无法命中,则其后面的字段均无法命中。
#创建索引 create index idx_emp_age_deptId_name on emp(age,deptId,name);a、上面的索引idx_emp_age_deptId_name只命中了一个age字段
讯享网explain SELECT SQL_NO_CACHE * from emp where emp.age=30 and emp.`name` = 'abcdef'
 b、上面的索引idx_emp_age_deptId_name一个字段都没有命中
b、上面的索引idx_emp_age_deptId_name一个字段都没有命中
explain SELECT SQL_NO_CACHE * from emp where deptId=4 and emp.`name` = 'abcdef' c、可以全部命中上面的索引idx_emp_age_deptId_name,理论上索引对顺序是敏感的,但是由于MySQL的查询优化器会自动调整where子句的条件顺序以使用适合的索引
c、可以全部命中上面的索引idx_emp_age_deptId_name,理论上索引对顺序是敏感的,但是由于MySQL的查询优化器会自动调整where子句的条件顺序以使用适合的索引
讯享网explain SELECT SQL_NO_CACHE * from emp where deptId=4 and emp.age=30 and emp.`name` = 'abcdef'

3、如果where条件中使用计算(计算、函数、(自动或者手动)类型转换),会导致索引失效
#建立索引 create index idx_emp_name on emp(name);使用like对索引没有影响,索引命中
讯享网EXPLAIN SELECT SQL_NO_CACHE * FROM emp WHERE emp.name LIKE 'abc%'
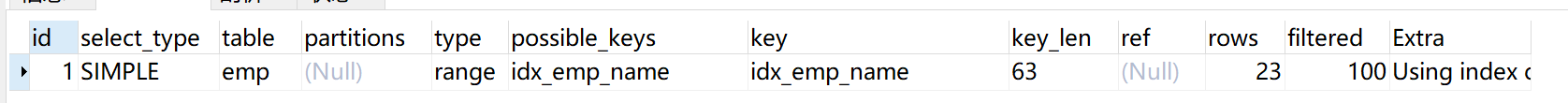 下面虽然功能相同,但是使用了LEFT函数,所以导致索引失效
下面虽然功能相同,但是使用了LEFT函数,所以导致索引失效
EXPLAIN SELECT SQL_NO_CACHE * FROM emp WHERE LEFT(emp.name,3) = 'abc'
4、索引中使用范围条件会使索引失效,导致该列后面的列无法使用索引
讯享网create index idx_emp_age_deptId_name on emp(age,deptId,name); EXPLAIN SELECT SQL_NO_CACHE * FROM emp WHERE emp.age=30 AND emp.deptId>20 AND emp.name = 'abc' ;
从key_len为10可以看出只命中了前两列
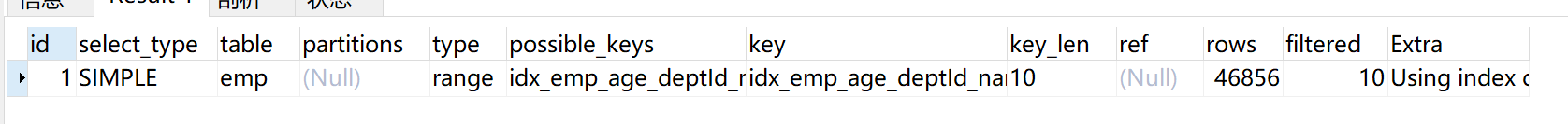
5、使用不等于(!=或者<>)会导致索引失效
CREATE INDEX idx_name ON emp(NAME) EXPLAIN SELECT SQL_NO_CACHE * FROM emp WHERE emp.name <> 'abc' 
6、s not null 会导致索引失效,但是is null 不会
讯享网EXPLAIN SELECT * FROM emp WHERE age IS NULL
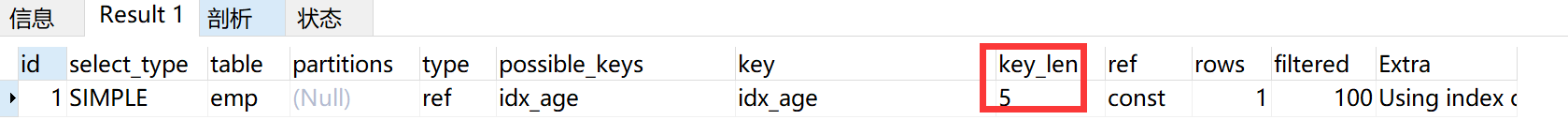
EXPLAIN SELECT * FROM emp WHERE age IS NOT NULL
7、like中以通配符(%、_)开头索引会失效
讯享网EXPLAIN SELECT SQL_NO_CACHE * FROM emp WHERE emp.name LIKE 'abc%'

EXPLAIN SELECT SQL_NO_CACHE * FROM emp WHERE emp.name LIKE '%abc%' 
8、符串不加引号索引会失效,因为进行了隐式的类型转换
讯享网EXPLAIN SELECT SQL_NO_CACHE * FROM emp WHERE emp.`name` = 123

案例总结:假设index(a,b,c)
| Where语句 | 索引是否被使用 |
|---|---|
| where a = 3 | Y,使用到a |
| where a = 3 and b = 5 | Y,使用到a,b |
| where a = 3 and b = 5 and c = 4 | Y,使用到a,b,c |
| where b = 3 或者 where b = 3 and c = 4 或者 where c = 4 | N |
| where a = 3 and c = 5 | 使用到a, 但是c不可以,b中间断了 |
| where a = 3 and b > 4 and c = 5 | 使用到a和b, c不能用在范围之后,b断了 |
| where a is null and b is not null is null | 支持索引 但是is not null 不支持,所以 a 可以使用索引,但是 b不可以使用 |
| where a <> 3 | 不能使用索引 |
| where abs(a) =3 | 不能使用 索引 |
| where a = 3 and b like ‘kk%’ and c = 4 | Y,使用到a,b,c |
| where a = 3 and b like ‘%kk’ and c = 4 | Y,只用到a |
| where a = 3 and b like ‘%kk%’ and c = 4 | Y,只用到a |
| where a = 3 and b like ‘k%kk%’ and c = 4 | Y,使用到a,b,c |
一般性建议
- 对于单值索引,尽量选择针对当前查询过滤性最好的索引(一般来说就是值得类型最多)
- 在选择联合索引的时候,当前query中过滤性最好的字段在索引位置中越靠前越好
- 在选择联合索引的时候,尽量选择能够包含query中where子句中更多字段的索引
- 在选择联合索引的时候,如果某个字段可能出现范围查询时,尽量把这个字段放到索引次序的最后面
- 书写sql语句时,尽量避免造成索引失效的情况
关键查询(JOIN)索引优化
关联查询时需要对一个驱动表每一行进行全表扫描,根据驱动表的每行条件查询被驱动表,所以被驱动表可以建立索引避免全表扫描。
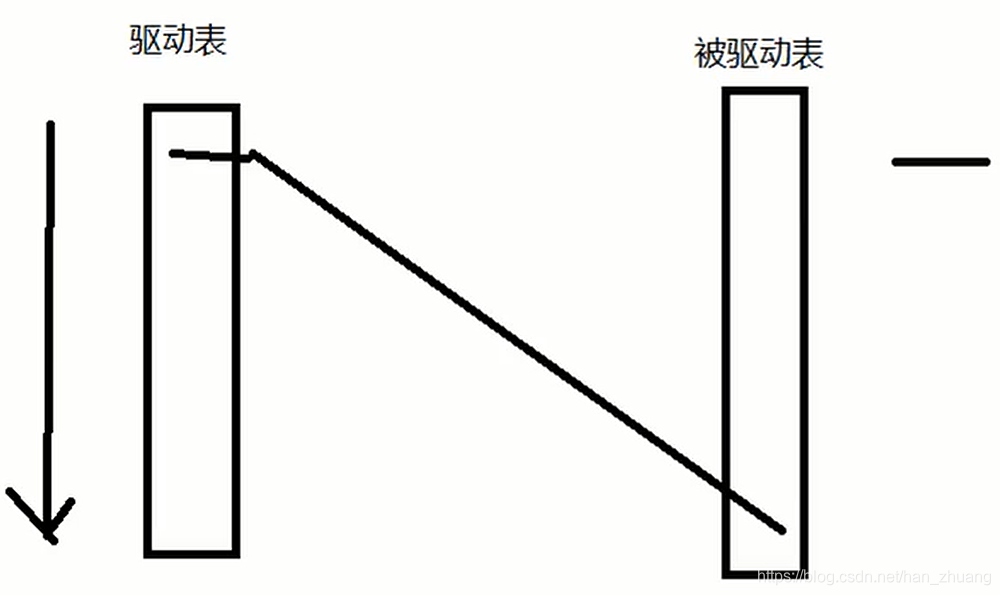
- 保证被驱动表得join字段已经建立索引
- 其中left join的left左侧是驱动表,右侧是被驱动表(right join的right右侧是驱动表,左侧是被驱动表)。所以left join时,尽量选择小表作为驱动表,大表作为被驱动表
- inner join时,MySQL会自动选择结果集小的表作为驱动表
- 子查询尽量不要放在被驱动表处,否则无法用到索引
- 能够直接关联的尽量直接关联,不用子查询
- 保证小表驱动大表
子查询优化
尽量不要用not in (子查询)或者 not existss(子查询),可以使用left join on xxx is null 代替。
排序优化
order by排序没有使用索引情况下会出现using filesort,速度会很慢。应该尽量使用索引排序,减少filesort排序。
explain select SQL_NO_CACHE * from emp order by age,deptid; 
讯享网explain select SQL_NO_CACHE * from emp order by age,deptid limit 10;

2、顺序错,必排序:order by使用索引时同样遵循最左前缀匹配,由于order by中的字段的顺序不能交换(与where不同),所以在order by中字段的顺序必须与索引顺序一致才能使用索引
#创建索引,注意索引的顺序 create index idx_age_deptid_name on emp (age,deptid,name)讯享网#部分列只要遵循最左前缀匹配也可以使用索引 explain select * from emp where age=45 order by deptid;
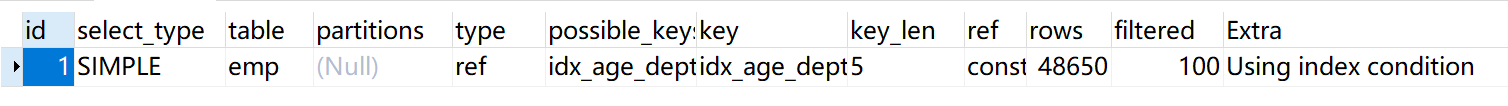
#顺序与索引顺序相同用到了索引 explain select * from emp where age=45 order by deptid,name; 
讯享网#顺序与索引顺序不相同,没有用到了索引 explain select * from emp where age=45 order by name,deptid;

3、方向反,必排序:排序时所有字段必须保持相同的顺序(
升序、或者降序),才能用到索引。否则索引失效
#都是降序,可以使用索引 explain select * from emp where age=45 order by deptid desc, name desc ; 
讯享网#一个升序一个降序,索引失效 explain select * from emp where age=45 order by deptid asc, name desc ;

4、当范围条件和group by 或者 order by 的字段出现二)选一时 ,优先观察条件字段的过滤数量,如果过滤的数据足够多,而需要排序的数据并不多时,优先把索引放在范围字段上。反之,亦然。
#思考下面语句如何建立索引 #(由于ORDER BY在范围查询后面,所以empno和NAME字段建立索引时肯定是二选一,那么选哪个?) SELECT SQL_NO_CACHE * FROM emp WHERE age =30 AND empno < ORDER BY NAME ;讯享网#使用name,去除了using filesort,但是对4万多行进行了排序 CREATE INDEX idx_age_name ON emp(age,NAME);

#使用empno,虽然出现了using filesort,但是只对49行进行了排序 #而且从key字段可以看出MySQL默认也选择了empno。 #通常情况下MySQL字段选择的索引是没问题的。 create index idx_age_eno on emp(age,empno); 
5、如果字段不在索引列上,filesort有两种算法:双路排序和单路排序。
- 双路排序:从磁盘读取排序字段,在内存进行排序,再读取其他字段。需要两次IO。
- 单路排序:所有数据顺序读入内存,再根据字段进行排序。依次IO,而且将随机IO变为顺序IO。但是需要大量内存。
6、order by其他优化策略
- 增大sort_buffer_size参数设置:不管用哪种算法,提高这个参数都会提高效率,当然,要根据系统的能力去提高,因为这个参数是针对每个进程的。1M-8M之间调整
- 增大max_length_for_sort_data参数设置:提高这个参数, 会增加使用单路排序的概率。但是如果设的太高,数据总容量超出sort_buffer_size的概率就增大,明显症状是高的磁盘I/O活动和低的处理器使用率. 在1M-8M之间调整
- 减少select后面查询字段的个数,减少排序内存消耗。
Group BY优化
Group BY优化策略的原则几乎和order by一致,唯一区别是group by即使没有筛选条件也能够使用索引。(Group BY的实质就是先排序order by,再根据字段进行分组(包含筛选条件))
能用where的就不要用having
覆盖索引
能用覆盖索引的,尽量不要用select*表达
覆盖索引:是非聚集组合索引的一种形式,它包括在查询里的Select、Join和Where子句用到的所有列(即建立索引的字段正好是覆盖查询语句[select子句]与查询条件[Where子句]中所涉及的字段,也即,索引包含了查询正在查找的所有数据)。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/71616.html