
花几个小时研究出来了UMU解析出答案的方法
两个文件:
browser.js是浏览器油猴插件,用于给UMU增加文本
讯享网
main.py是解析答案用的Python程序
先来看看效果
GIF:
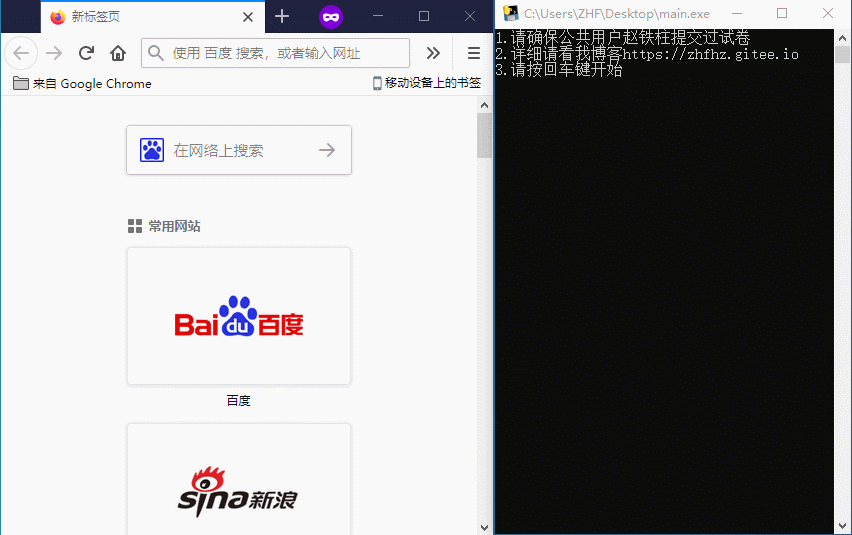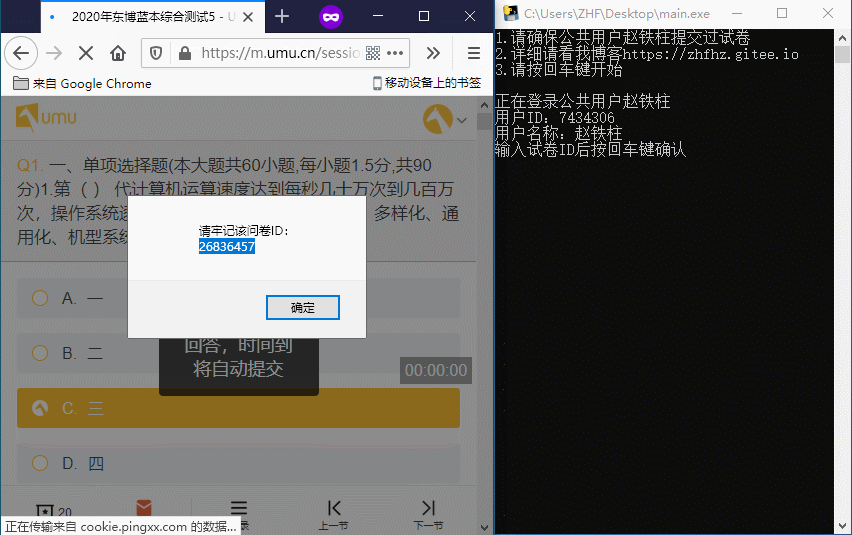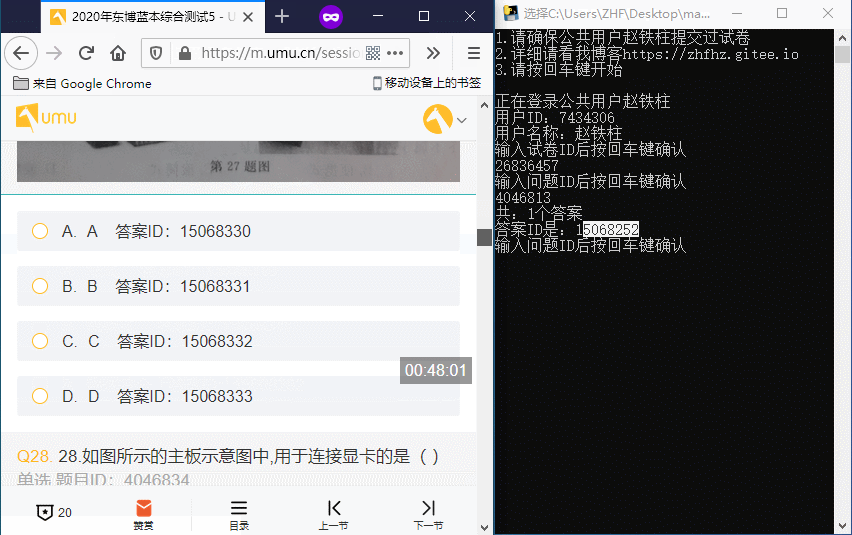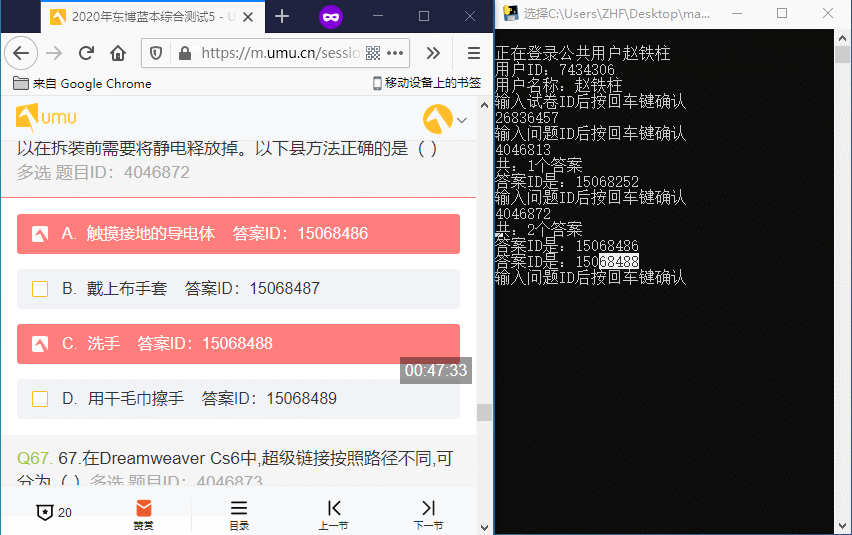
单选效果:
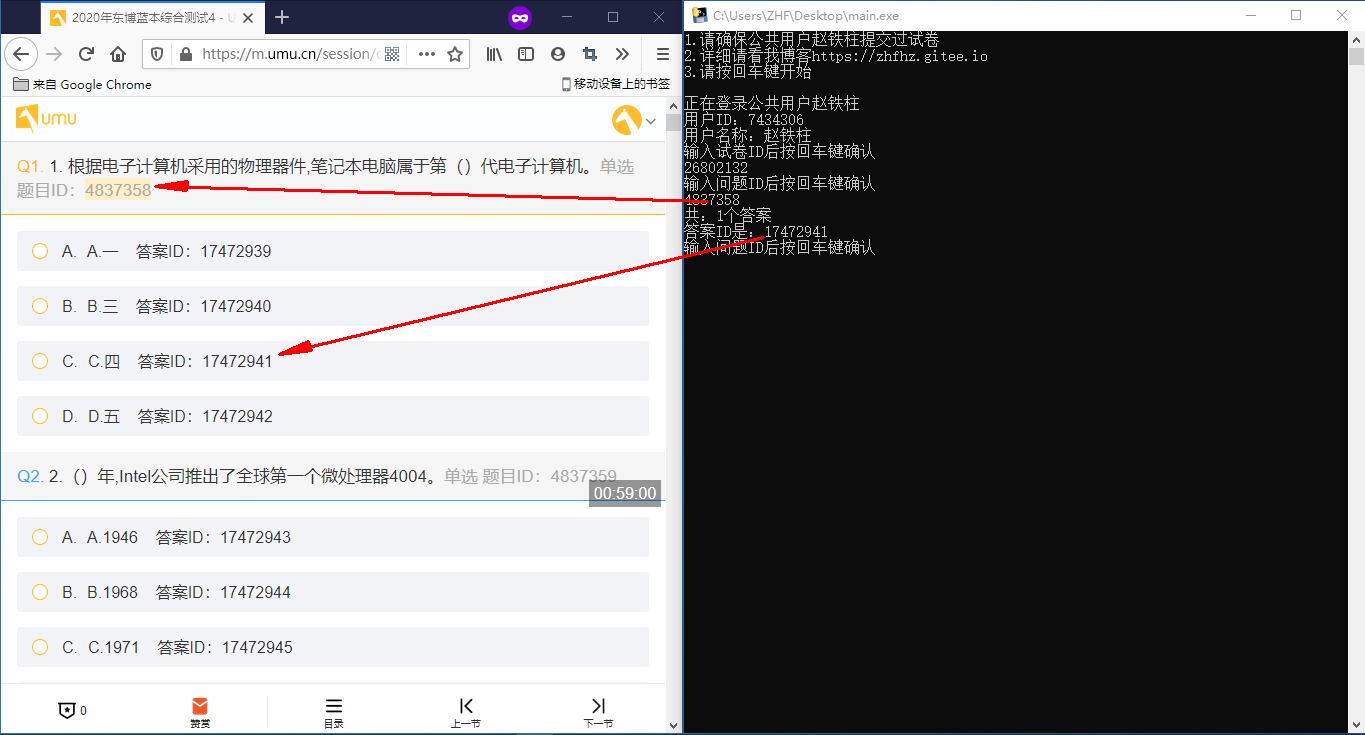
多选效果
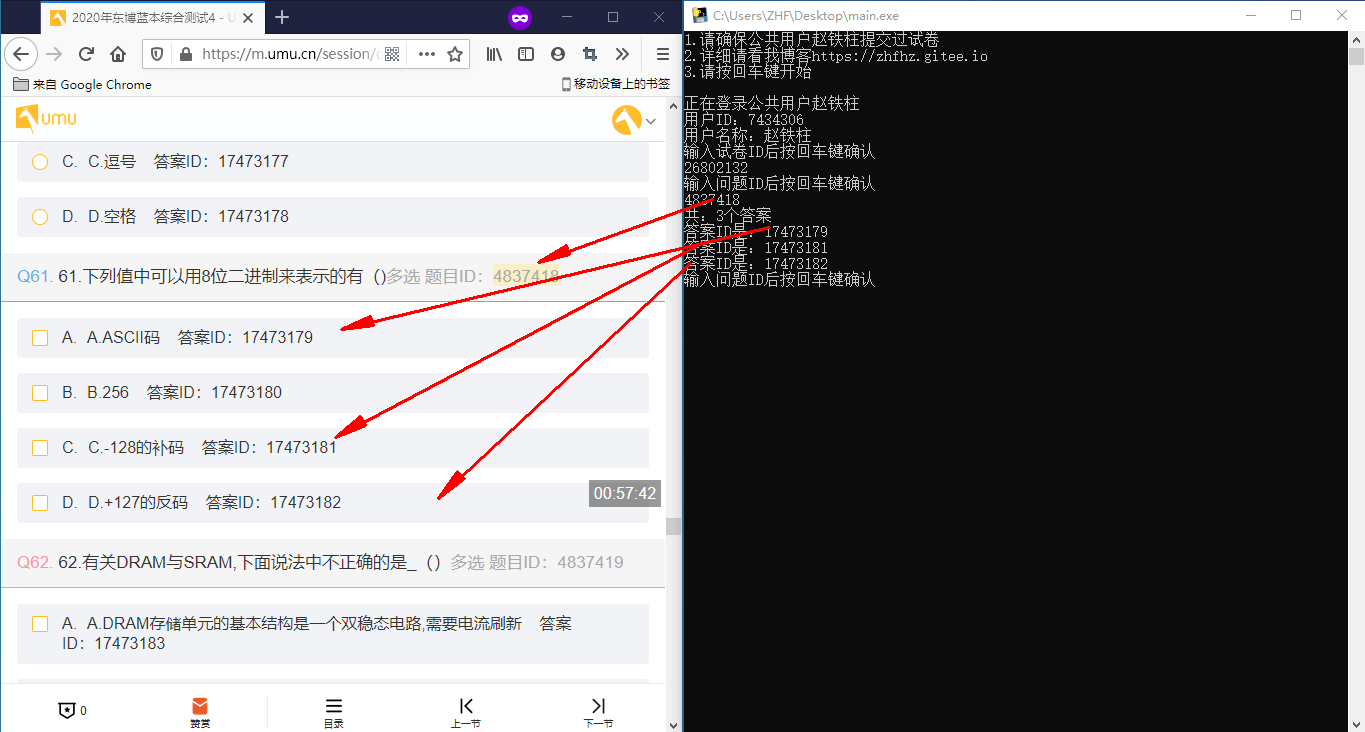
首先我们先整理一下思路:
早期UMU答案直接放在ID是__pageDataTemplate__的一个<script>中
// ==UserScript==
// @name UMU答案解析(已过时)
// @namespace Violentmonkey Scripts
// @match https://m.umu.cn/session/*
// @grant none
// ==/UserScript==
(function () {
window.onload = function () {
var source_code = $('#__pageDataTemplate__').html().toString();
//JSON.parse(source_code)
var questions;
var answer;
var ABC_options = new Array("A", "B", "C", "D");
var answer_txt;
var obj_source_code = JSON.parse(source_code); //提取json字符串
// var answer_position //答案位置
if (obj_source_code != "") {
alert("答案解析成功,点击确定开始下载");
for (questions = 0; questions <= obj_source_code.data.sectionArr.length - 1; questions++) { //遍历题目
answer_position = 0 //位置初始化
for (answer = 0; answer <= obj_source_code.data.sectionArr[questions].answerArr.length - 1; answer++) { //遍历答案
if (obj_source_code.data.sectionArr[questions].answerArr[answer].isRight == 1) {
var title_number = questions + 1;
//console.log("第" + title_number +"题的答案是:" + ABC_options[answer]);
answer_txt = answer_txt + "第" + title_number + "题的答案是:" + ABC_options[answer] + "\r\n";
}
}
}
download(obj_source_code.data.quizLegacyData.session_info.sessionTitle + "答案.txt", answer_txt);
//下载答案
function download(filename, text) {
var element = document.createElement('a');
element.setAttribute('href', 'data:text/plain;charset=utf-8,' + encodeURIComponent(text));
element.setAttribute('download', filename);
element.style.display = 'none';
document.body.appendChild(element);
element.click();
document.body.removeChild(element);
}
}else{
alert("答案获取失败");
}
}
})();
讯享网
后来UMU更新,把<script>的ID取消掉了,但可以通过绕过登录验证直接提交再查看答案来获取
讯享网// ==UserScript== // @name UMU不登录强行做题(看老师试卷设置) // @namespace Violentmonkey Scripts // @match https://m.umu.cn/session/quiz/* // @grant none // @version 1.0 // @author - // @description 2020/3/20 下午2:51:58 // ==/UserScript== window.onload = function(){ document.getElementsByClassName("dialog-mask")[0].remove() document.getElementsByClassName("dialog-main")[0].remove() }
原理是UMU设计有问题,弹出用户登录弹窗前试卷已经加载完成,通过定位弹窗直接remove就好了
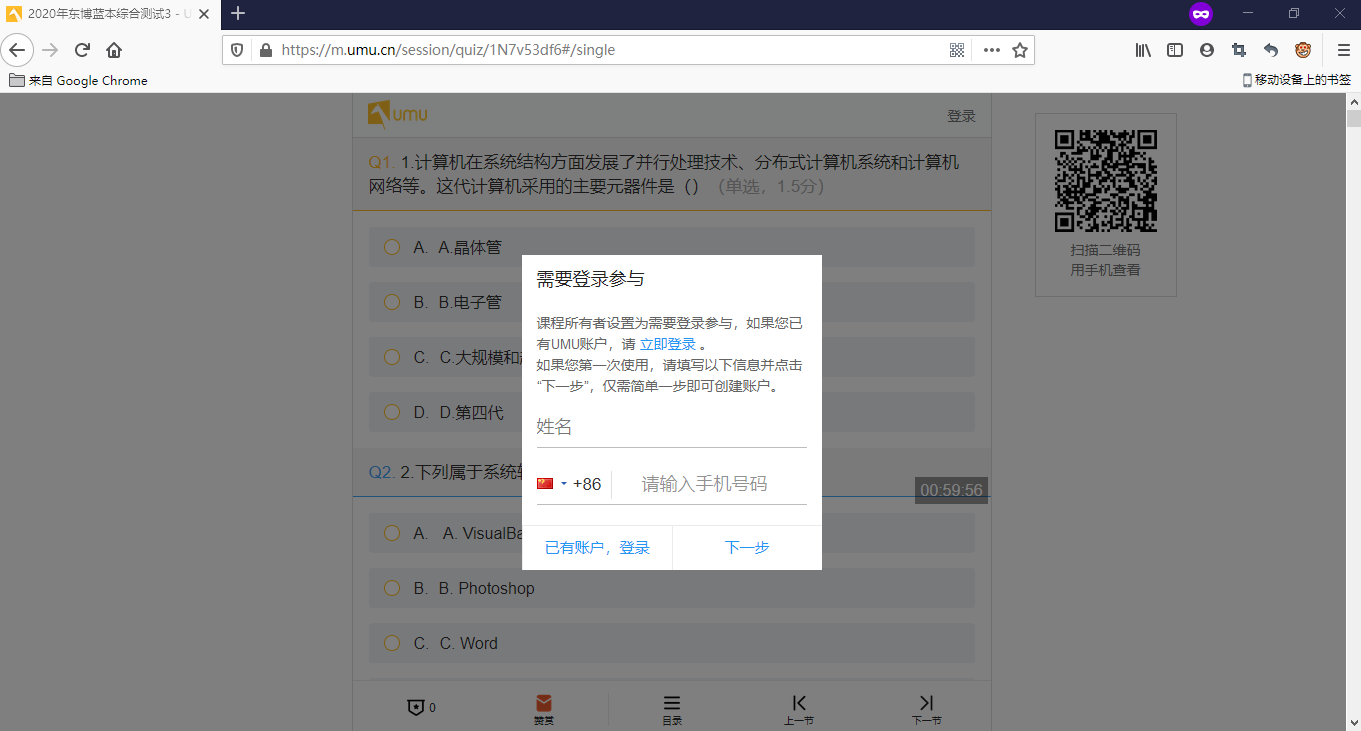
再后来UMU又更新到了现在的这个版本,<script>中不再存储答案,做题强制要求登录,并且试卷提交后不能查看答案
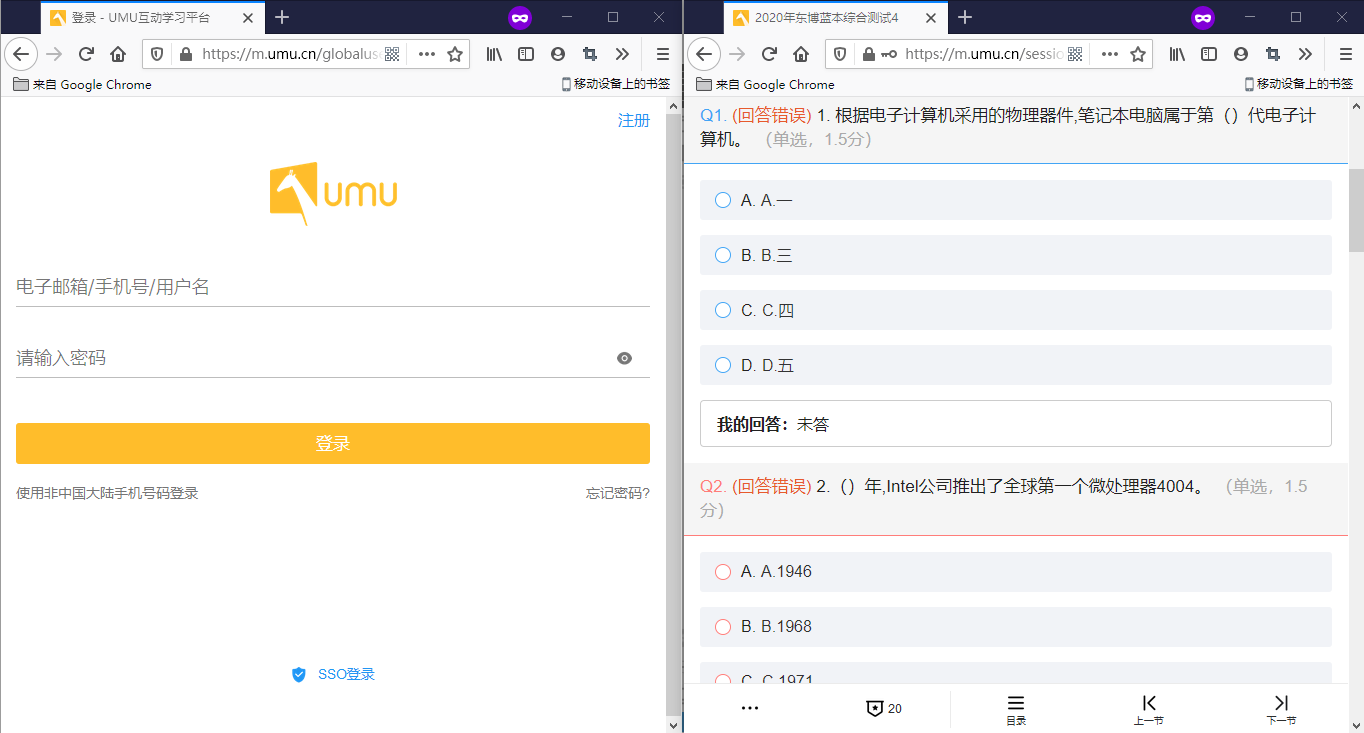
我的思路:
1.要获取答案首先得知道答案从哪里来
通过观察发现,如今的UMU前端ID为__pageDataTemplate__的<script>中只存储题目等信息
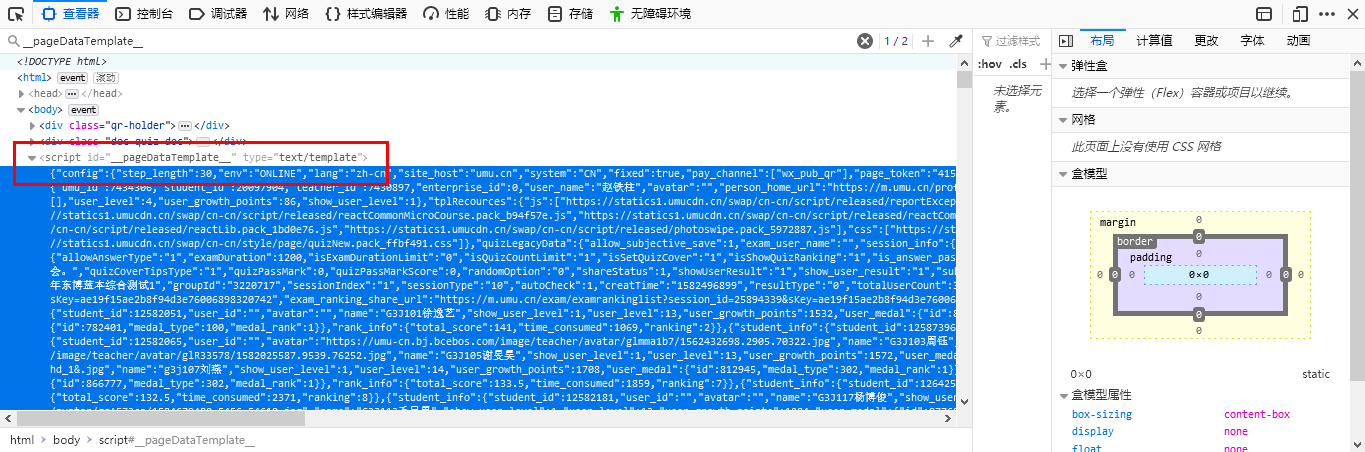
其中的JSON格式化之后
通过前端直接获取答案肯定不可能
观察发现,与答案有联系的只有提交后的网页
2.我们分析提交后网页发送了哪些请求
在提交试卷后,虽然不能直接在网页上显示答案,但是通过抓取数据包可以发现
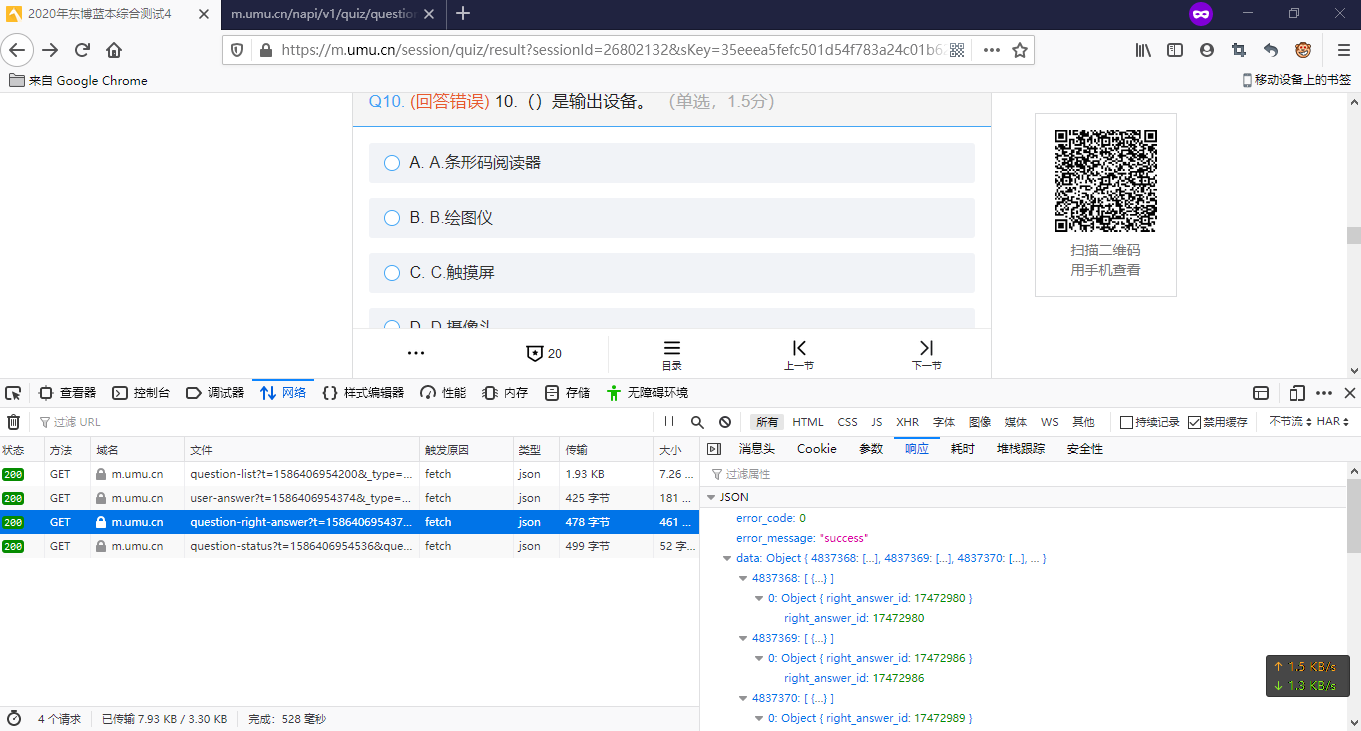
在加载回答情况答案时,会发送一个GET请求
https://m.umu.cn/napi/v1/quiz/question-right-answer?t=51&_type=1&element_id=&question_ids=%2C%2C%2C%2C%2C%2C%2C%2C%2C 返回的内容:
讯享网{ "error_code": 0, "error_message": "success", "data": { "": [{ "right_answer_id": }], "": [{ "right_answer_id": }], "": [{ "right_answer_id": }], "": [{ "right_answer_id": }], "": [{ "right_answer_id": }], "": [{ "right_answer_id": }], "": [{ "right_answer_id": }], "": [{ "right_answer_id": }], "": [{ "right_answer_id": }], "": [{ "right_answer_id": }] } }
把返回的数据和前端<script type="text/template" id="__pageDataTemplate__">中的内容对比发现:
//这是前端Json中的一部分 { "questionInfo": { "cid": "", "questionId": , "questionTitle": "11.系统总线的构成不包括()", "showIndex": 11, "pattern": 0, "level": 2, "domType": "radio", "desc": "", "multimedia_id": 0, "multimedia_type": 0, "multimedia_weight": 0, "extend": { "media_url": [], "pic_url": [] }, "setup": { "score": "1.5", "screenOrderType": "0" }, "questionExplain": { "desc": "", "pic_url": [] }, "creatTime": , "QuestionExplainPicUrlFromRandom": "[]", "sessionId": , "questionPrompt": { "desc": "", "pic_url": [] }, "right_user_count": 0, "totalCount": 0, "sortType": 0, "correct_rate": 0 }, "answerArr": [{ "answerId": , "questionId": , "answerContent": "A.数据总线", "isRight": 0, "extend": { "media_url": [], "pic_url": [] }, "type": 0, "count": 0, "answerIdx": 1, "ratio": 0, "sort": 0, "is_selected": 0 }, { "answerId": , "questionId": , "answerContent": "B.状态总线", "isRight": 0, "extend": { "media_url": [], "pic_url": [] }, "type": 0, "count": 0, "answerIdx": 2, "ratio": 0, "sort": 0, "is_selected": 0 }, { "answerId": , "questionId": , "answerContent": "C.地址总线", "isRight": 0, "extend": { "media_url": [], "pic_url": [] }, "type": 0, "count": 0, "answerIdx": 3, "ratio": 0, "sort": 0, "is_selected": 0 }, { "answerId": , "questionId": , "answerContent": "D.控制总线", "isRight": 0, "extend": { "media_url": [], "pic_url": [] }, "type": 0, "count": 0, "answerIdx": 4, "ratio": 0, "sort": 0, "is_selected": 0 }], "answered": null } 其中对应的是questionId(题目ID)
right_answer_id对应的是answerId(选项ID)
其中请求中question_ids后面跟着的是题目编号 + %2C + 题目编号
经过尝试,最多链接20个左右的题目编号
3.我们尝试在同一个浏览器上重复这个请求
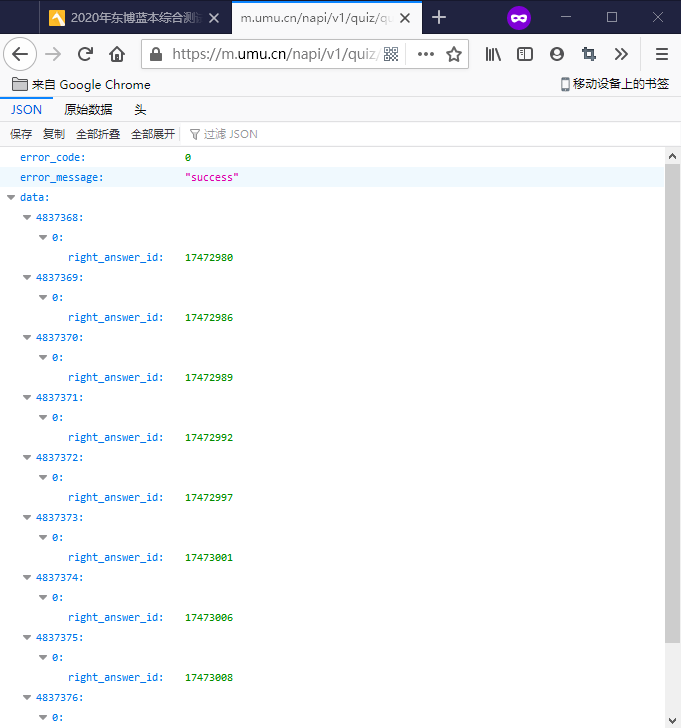
成功!
尝试构造其他请求
讯享网https://m.umu.cn/napi/v1/quiz/question-right-answer?t=51&_type=1&element_id=&question_ids=
返回结果:
{ "error_code": 0, "error_message": "success", "data": { "": [{ "right_answer_id": }] } } 换一个浏览器进行尝试
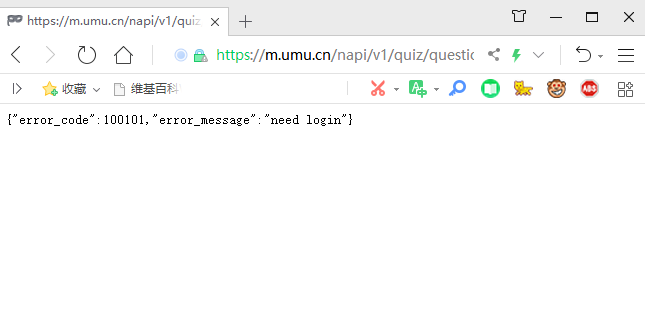
提示需要的登录
既然要登录,我们先考虑从Cookie入手
猜测JSESSID和umuU是验证用户身份用的
进行尝试

成功在另一个浏览器上通过这修改这两个参数成功登录了用户
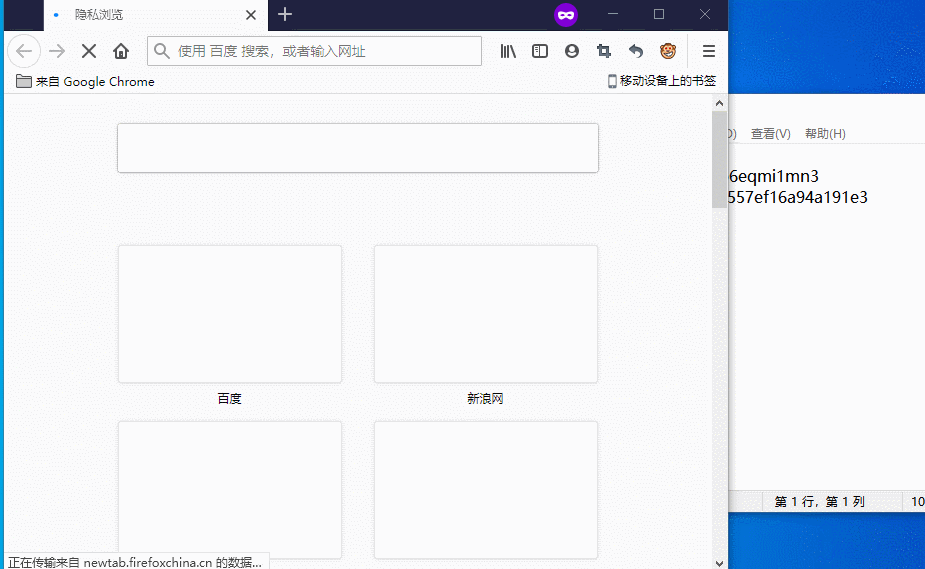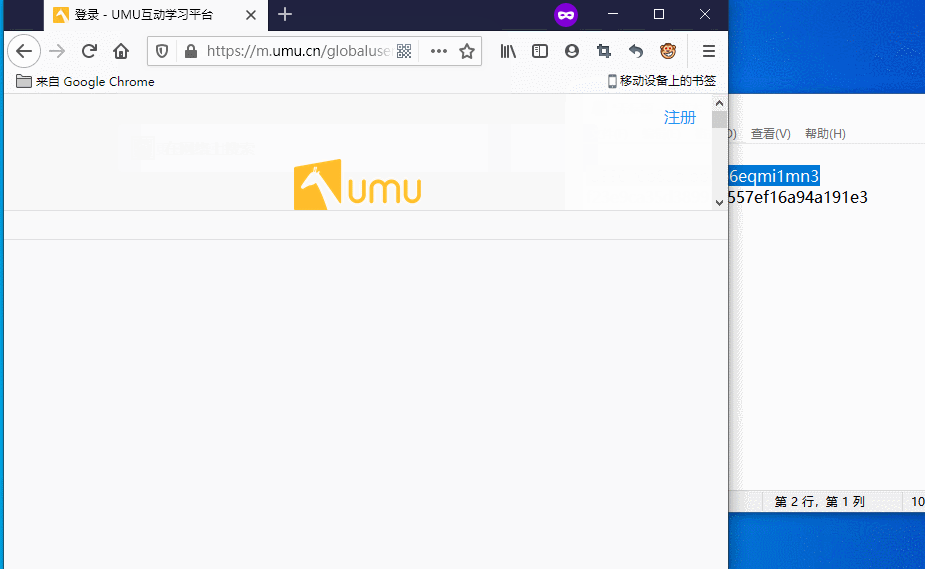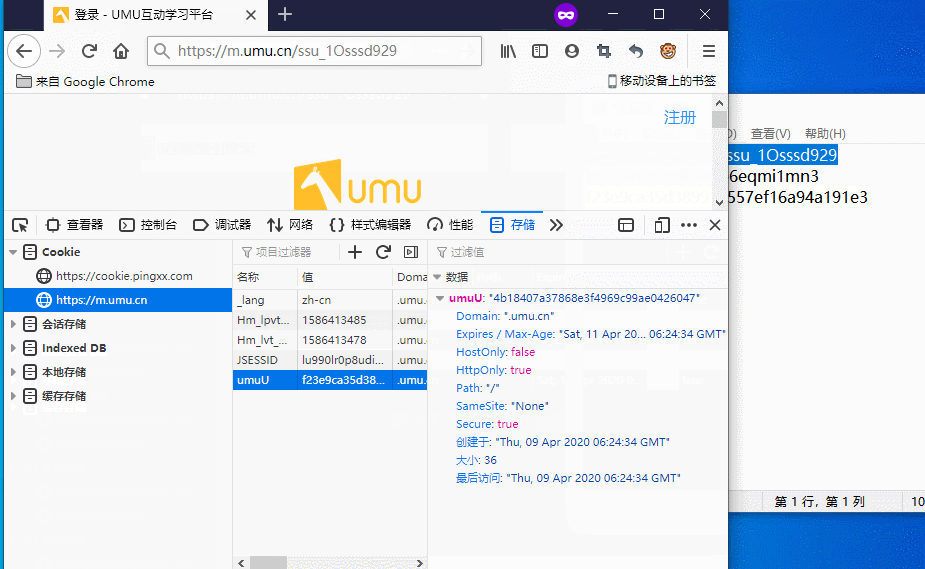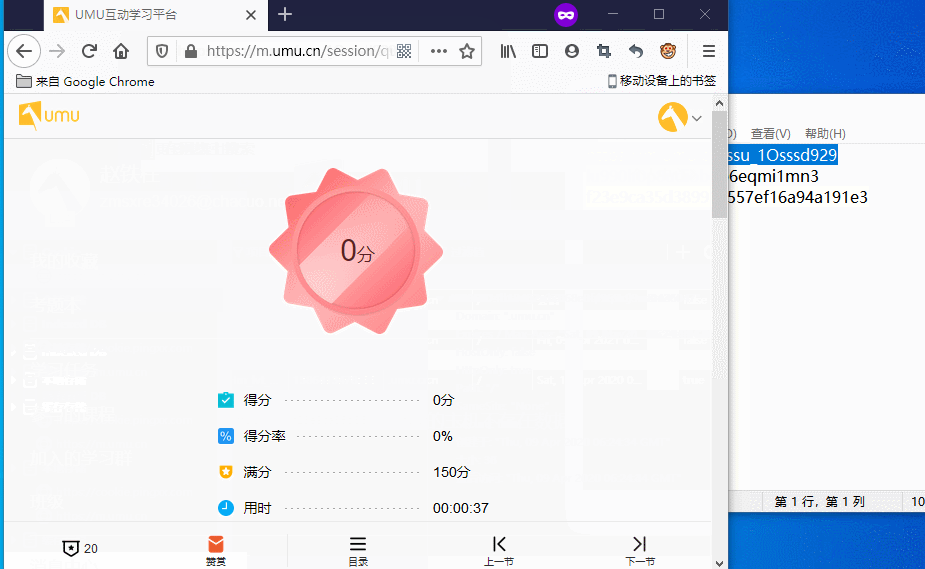
非常好
接下来用Python发送请求并解析返回的数据
解析JSON就不多说了
讯享网sessionId = input("输入试卷ID后按回车键确认\n") # 试卷ID 26802132
questionId = input("输入问题ID后按回车键确认\n") # 问题ID 4837358
while questionId != "":
page_url = "https://m.umu.cn/napi/v1/quiz/question-right-answer?t=1586269428055&_type=1&element_id=" + sessionId + "&question_ids=" + questionId
cookies = {"umuU": "f23e9ca35d389910557ef16a94a191e3", "JSESSID": "lu990lr0p8udiobqb6eqmi1mn3",
"_lang": "zh-cn",
"Hm_lvt_0dda0edb8e4fbece1e49e12fc49614dc": "1586319220",
"Hm_lpvt_0dda0edb8e4fbece1e49e12fc49614dc": "1586319427"}
response = requests.get(page_url, cookies=cookies)
response.encoding = 'utf-8'
html = response.text
data_json = json.loads(html)
msg_len = len(data_json['data'][questionId])
print("共:" + str(msg_len) + "个答案")
for msg_id in range(msg_len): #循环所有答案
print("答案ID是:" + str(data_json['data'][questionId][msg_id]['right_answer_id']))
questionId = input("输入问题ID后按回车键确认\n")
发现每次重新登录后JSESSID和umuU都会改变,如果继续使用上一次的JSESSID和umuU就会验证失败
所以我们需要模拟用户登录来获取实时的JSESSID和umuU
首先抓取登录界面的数据:
因为登录后网页会跳转,所以我们通过HTTPDebugger来进行抓包
今天在写这篇文章的时候,想要重现抓包过程,但是发现HTTPDebugger怎么都抓不到POST请求的数据包,于是换成了Fiddler
我们登陆用户赵铁柱并抓包
请求:
POST https://m.umu.cn/passport/ajax/account/login HTTP/1.1 Host: m.umu.cn User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:75.0) Gecko/ Firefox/75.0 Accept: application/json Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2 Accept-Encoding: gzip, deflate, br X-Requested-With: XMLHttpRequest Content-Type: application/x-www-form-urlencoded umu-b: 1 umu-p: wap Content-Length: 52 Origin: https://m.umu.cn Connection: keep-alive Referer: https://m.umu.cn/globaluser/loginpage Cookie: umuU=7574f2a8da1dd89daec6276f47626dd8; JSESSID=tgoalklikkdihgn72bfpq2hrt6; Hm_lvt_0dda0edb8e4fbece1e49e12fc49614dc=,,,; estuid=u; estuidtoken=dab74b9230b0fd4ed0eeaf5cba7af30; _lang=zh-cn; Hm_lpvt_0dda0edb8e4fbece1e49e12fc49614dc= username=zmsxre34026%40chacuo.net&passwd=zmsxre34026 返回:
讯享网HTTP/1.1 200 OK Date: Thu, 09 Apr 2020 12:24:43 GMT Content-Type: application/json;charset=UTF-8 Connection: keep-alive Vary: Accept-Encoding Expires: Thu, 19 Nov 1981 08:52:00 GMT Cache-Control: no-store, no-cache, must-revalidate Pragma: no-cache Set-Cookie: _lang=zh-cn; path=/; domain=umu.cn; secure SESSION_ID: grio Set-Cookie: lk=deleted; expires=Thu, 01-Jan-1970 00:00:01 GMT; Max-Age=0; path=/; domain=umu.cn; secure; HttpOnly Set-Cookie: umuU=4be4d141a4e47e3d5485e1c53fef12c6; expires=Sat, 11-Apr-2020 12:24:43 GMT; Max-Age=; path=/; domain=umu.cn; secure; HttpOnly Set-Cookie: JSESSID=hvti97qjg6jceor6kk9me9an65; expires=Sat, 16-Mar-2120 12:24:43 GMT; Max-Age=; path=/; domain=umu.cn; secure; HttpOnly Set-Cookie: estuid=u; path=/; domain=umu.cn; secure; HttpOnly Set-Cookie: estuidtoken=7fb5f75960a62f7b41ff50a413d5d9c; path=/; domain=umu.cn; secure; HttpOnly Server: Apache/2.2.21/web20 Strict-Transport-Security: max-age=; includeSubdomains; preload server_number: 92 Content-Length: 733 { "status": true, "errno": 0, "error": "success", "data": { "user_info": { "student_id": "", "umu_id": "", "user_name": "赵铁柱", "avatar": "", "home_url": "https:\/\/m.umu.cn\/profile\/432ba2d0ae256eb86a6aa730", "phone": "", "email": "", "user_mark": "", "medal_info": { "show_user_level": 1, "user_level": 4, "user_growth_points": 96 } }, "teacher_info": { "umu_id": "", "teacherId": "", "student_id": "", "enterprise_id": "0", "bind_phone": "", "bind_area_code": "", "register_step": 4, "register_from": "1", "need_bind_mobile": 0 } }, "token": "hvti97qjg6jceor6kk9me9an65", "page_token": "||070fdc", "config": { "step_length": 30, "env": "ONLINE", "lang": "zh-cn", "site_host": "umu.cn", "system": "CN", "fixed": true } }
接下来只要用Python模拟请求,并从返回的数据中获取我们要的cookie就好了
import requests
import json
page_url = 'https://m.umu.cn/passport/ajax/account/login'
payload = {"username": 'zmsxre34026@chacuo.net', "passwd": "zmsxre34026"} # 值以字典的形式传入
response = requests.post(page_url, data=payload)
response.encoding = 'utf-8'
html = response.text
user_cookie = response.cookies # 获取cookies
user_json = json.loads(html) # 用户信息
print("正在登录公共用户赵铁柱")
print("用户ID:" + user_json['data']['user_info']['umu_id'])
print("用户名称:" + user_json['data']['user_info']['user_name'])
if user_json['data']['user_info']['umu_id'] == "赵铁柱":
print("用户登录成功!")
for item in user_cookie:
item = str(item)
if item.find("JSESSID") != -1:
JSESSID = item[item.find("JSESSID") + 8:item.find("for .umu.cn") - 1]
print("JSESSID="+JSESSID)
if item.find("umuU") != -1:
umuU = item[item.find("umuU") + 5:item.find("for .umu.cn") - 1]
print("umuU="+umuU)
结果:
讯享网正在登录公共用户赵铁柱 用户ID: 用户名称:赵铁柱 JSESSID=ujrmhuh1g64nbgb2ni7fehrpa5 umuU=c4ecd3a72ea6dd2e8637f6e9c3a34d38
最后和之前解析答案的代码合并到一起整理下逻辑就行了
main.py:
#1.1
#我的博客:https://zhfhz.gitee.io/
import requests
import json
operation = input("1.请确保公共用户赵铁柱提交过试卷\n2.详细请看我博客https://zhfhz.gitee.io\n3.请按回车键开始\n")
登录模块
page_url = 'https://m.umu.cn/passport/ajax/account/login'
payload = {"username": 'zmsxre34026@chacuo.net', "passwd": "zmsxre34026"} # 值以字典的形式传入
response = requests.post(page_url, data=payload)
response.encoding = 'utf-8'
html = response.text
user_cookie = response.cookies # 获取cookies
user_json = json.loads(html) # 用户信息
print("正在登录公共用户赵铁柱")
print("用户ID:" + user_json['data']['user_info']['umu_id'])
print("用户名称:" + user_json['data']['user_info']['user_name'])
if user_json['data']['user_info']['umu_id'] == "赵铁柱":
print("用户登录成功!")
for item in user_cookie:
item = str(item)
if item.find("JSESSID") != -1:
# print(item)
JSESSID = item[item.find("JSESSID") + 8:item.find("for .umu.cn") - 1]
if item.find("umuU") != -1:
# print(item)
umuU = item[item.find("umuU") + 5:item.find("for .umu.cn") - 1]
解析模块
sessionId = input("输入试卷ID后按回车键确认\n") # 试卷ID 26802132
questionId = input("输入问题ID后按回车键确认\n") # 问题ID 4837358
while questionId != "":
page_url = "https://m.umu.cn/napi/v1/quiz/question-right-answer?t=1586269428055&_type=1&element_id=" + sessionId + "&question_ids=" + questionId
cookies = {"umuU": umuU, "JSESSID": JSESSID,
"_lang": "zh-cn",
"Hm_lvt_0dda0edb8e4fbece1e49e12fc49614dc": "1586319220",
"Hm_lpvt_0dda0edb8e4fbece1e49e12fc49614dc": "1586319427"}
response = requests.get(page_url, cookies=cookies)
response.encoding = 'utf-8'
html = response.text
data_json = json.loads(html)
msg_len = len(data_json['data'][questionId])
print("共:" + str(msg_len) + "个答案")
for msg_id in range(msg_len): #循环所有答案
print("答案ID是:" + str(data_json['data'][questionId][msg_id]['right_answer_id']))
questionId = input("输入问题ID后按回车键确认\n")
其他提示
在使用Python requests.post()模块的时候,可能会有类似报错:
讯享网requests.exceptions.SSLError: HTTPSConnectionPool(host='XXX.XXXX.COM', port=443): Max retries exceeded with url: / (Caused by SSLError(SSLError(1, u'[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed (_ssl.c:581)'),))
解决方法是安装三个模块:
pip install cryptography
pip install pyOpenSSL
pip install certifi
浏览器端脚本
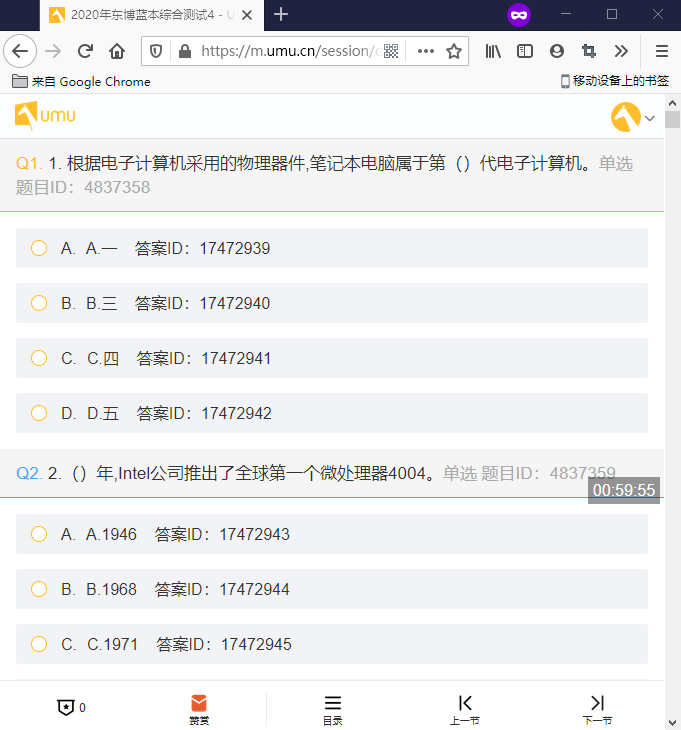
我们使用上面的程序可以做到输入问题ID返回答案ID的效果,但还是不方便我们查询,所以我写了浏览器端的脚本用来把问题ID与答案ID直接显示在题目上。
原理很简单,就是通过
document.getElementById("__pageDataTemplate__").innerHTML 获取前端题目的JSON并进行解析就好了
油猴脚本代码browser.js:
讯享网// ==UserScript== // @name UMU增加文字 // @namespace 咸鱼郑某的博客:https://zhfhz.gitee.io/ // @match *://m.umu.cn/session/quiz/* // @grant none // @version 1.0 // @author - // @description 2020/4/8 下午12:22:26 // ==/UserScript== window.onload = function() { var data_json = document.getElementById("__pageDataTemplate__").innerHTML //获取SB JSON var qustion_len = JSON.parse(data_json).data.sectionArr.length var qustion_arr = JSON.parse(data_json).data.sectionArr //所有问题数组 var qustion_num = 0 //选项序号 alert("请牢记该问卷ID:\n"+ JSON.parse(data_json).data.quizLegacyData.session_info.sessionId) for (var i = 0; i <= qustion_len - 1; i++) { var qustion_option =qustion_arr[i] //问题 //JSON.parse(document.getElementById("__pageDataTemplate__").innerHTML).data.sectionArr[0].questionInfo.questionId //增加题目编号 if(qustion_option.questionInfo.domType=="radio"){ //单选 document.getElementsByClassName("type-desc titleTypeDesc")[i].innerHTML = "单选 题目ID:" + qustion_option.questionInfo.questionId }else if(qustion_option.questionInfo.domType=="checkbox"){ //多选 document.getElementsByClassName("type-desc titleTypeDesc")[i].innerHTML = "多选 题目ID:" + qustion_option.questionInfo.questionId } for(var j=0;j<=qustion_option.answerArr.length-1;j++){ var answerId = qustion_option.answerArr[j].answerId //选项ID //给文字增加ID document.getElementsByClassName("option-detail")[qustion_num].innerHTML = document.getElementsByClassName("option-detail")[qustion_num].innerHTML + " 答案ID:" + answerId qustion_num = qustion_num + 1 //选项序号 +1 } } }
最终效果
GIF:
单选效果:
多选效果
创作时间:2020-04-09 20:46:45
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/71015.html